-
|
First of all, thanks Jax team. It's a great tool enabling much GPU-accelerated computing. Currently, I am trying to split some custom calculations over multiple GPUs to achieve pipeline parallelisms like GPipe and PipeDream. So I make a small experiment as the following: import jax
import jax.numpy as jnp
KEY = jax.random.PRNGKey(42)
GPUS = jax.devices("gpu")
print(GPUS) # yields [GpuDevice(id=0, process_index=0), GpuDevice(id=1, process_index=0)]
w0 = jax.device_put(jax.random.normal(KEY, shape=(100, 100)), device=GPUS[0])
fn0 = jax.jit(lambda x: jnp.dot(w0, x), device=GPUS[0])
w1 = jax.device_put(jax.random.normal(KEY, shape=(100, 100)), device=GPUS[1])
fn1 = jax.jit(lambda x: jnp.dot(w1, x), device=GPUS[1])
def version1(x):
y1 = fn0(x)
y2 = fn1(y1)
return y2
with jax.profiler.trace(str("./_tmp")):
inputs = jax.random.normal(KEY, shape=(100,))
result = version1(inputs)I expect the Is it able to explicitly control the transfer between devices? Or is possible to make Jax for more efficient memory transfer? I notice pjit, but the GSPMD paper suggest that it's basically for homogeneous model splitting and not suitable to my needs. I also notice #6014, but not sure if my case is related to that. I use Conda to control the environment on a Ubuntu 20.04 machine with multiple RTX 5000. The environment includes |
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 8 replies
-
|
Here are the raw trace_viewer in TensorBoard and an detailed examination: I also make a few other attempts like jit the version1_jitted = jax.jit(version1)
def version2(x):
return fn1(fn0(x))
version2_jitted = jax.jit(version2)
def version3(x):
y1 = fn0(x)
y1 = jax.device_put(y1, device=GPUS[1])
y2 = fn1(y1)
return y2
version3_jitted = jax.jit(version3) |
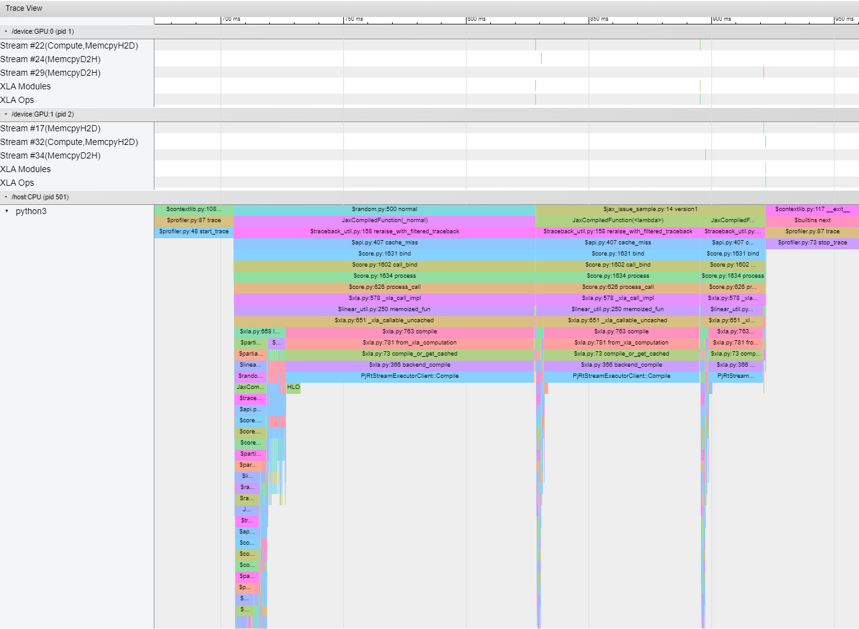
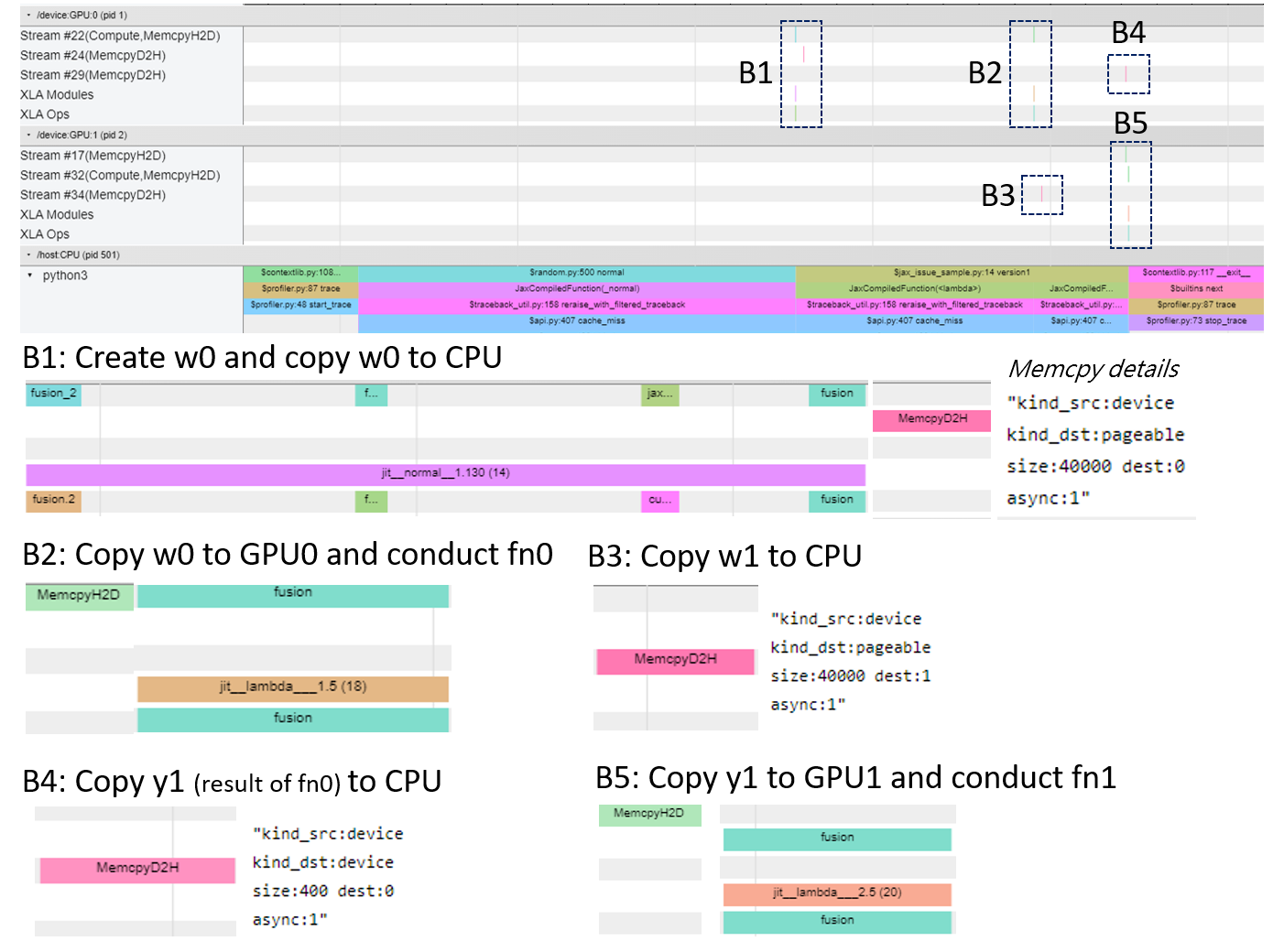
Beta Was this translation helpful? Give feedback.
-
|
The transfer B5 is apparently also a device-to-device transfer that is being bounced via the host. The jaxlib fix will avoid the host bounce here also. In general for JAX it can be hard to understand traces the first time they run, during JIT tracing/compilation. Can you, say, run the function a few more times to look at the steady state with no first-time JIT stuff? I think some of those transfer may not appear in the steady state. |
Beta Was this translation helpful? Give feedback.
-
|
I will do that and paste the result here, however, I think my question is well-answered and I mark this as such. Thanks for the information. |
Beta Was this translation helpful? Give feedback.
-
|
We just released jaxlib 0.1.74, which should contain the fix. Please try it out! |
Beta Was this translation helpful? Give feedback.
-
|
Thank you for notifying. I will. |
Beta Was this translation helpful? Give feedback.
-
|
I changed my test to do the And confirm that switching to jax==0.2.25 and jaxlib==0.1.74, the
|

Beta Was this translation helpful? Give feedback.
Here are the raw trace_viewer in TensorBoard and an detailed examination:
I also make a few other attempts like jit the
version1, or try to avoid they1&y2. But none of them give the desired result: