-
|
I am trying to implement a physics-informed neural network (PINN) in JAX, but I am encountering issues when training with a jitted gradient update function.
Here is a simplified listing of the model: from jax import jit, vmap, value_and_grad, jacfwd
import jax.numpy as jnp
from jax.nn import softplus
from jax import random
from jax.experimental.optimizers import adam
from tqdm import tqdm
def initialize_mlp(sizes, key):
keys = random.split(key, len(sizes))
def initialize_layer(m, n, key, scale=1e-2):
w_key, b_key = random.split(key)
return scale * random.normal(w_key, (n, m)), scale * random.normal(b_key, (n,))
return [initialize_layer(m, n, k) for m, n, k in zip(sizes[:-1], sizes[1:], keys)]
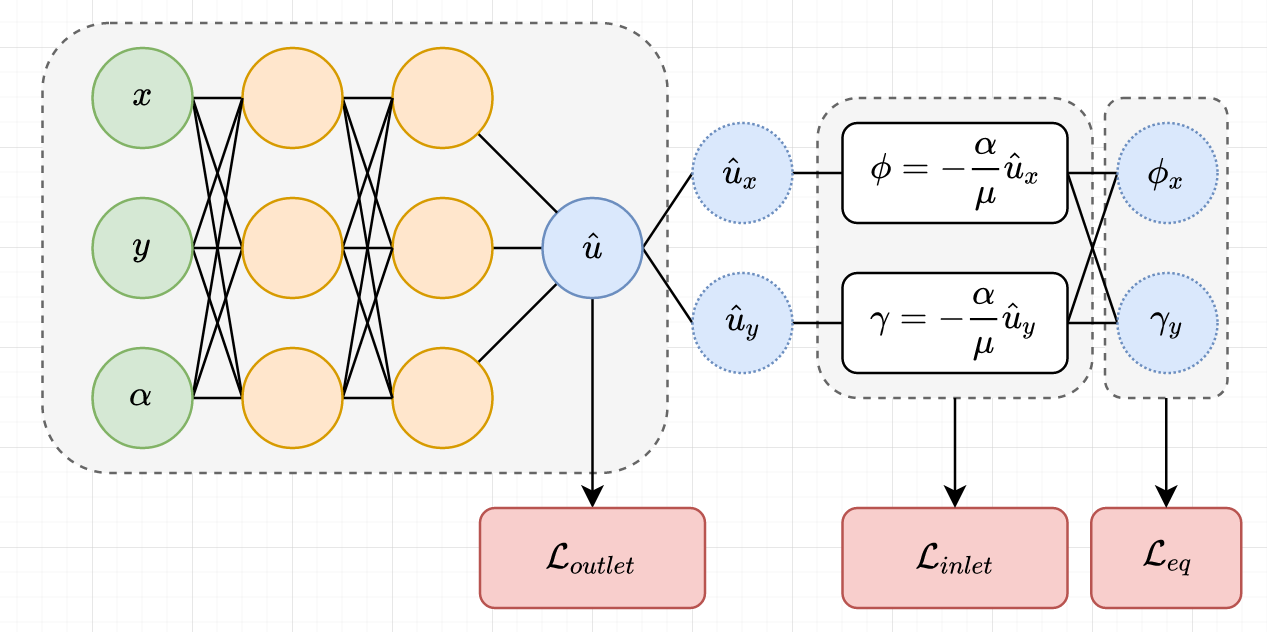
def predict_func(parameters, x, y, α, μ):
# forward pass through network
def f(parameters, x, y, α, μ):
activations = jnp.concatenate((x, y, α, μ))
for w, b in parameters[:-1]:
activations = softplus(jnp.dot(w, activations) + b)
w, b = parameters[-1]
u = jnp.sum(jnp.dot(w, activations) + b)
return u
# spatial derivatives of pressure
g = value_and_grad(f, argnums=[1, 2]) # returns u, (ux, uy)
# velocity using darcys law
def h(parameters, x, y, α, μ):
u, (ux, uy) = g(parameters, x, y, α, μ)
φ = -α / μ * ux # velocity in x direction
γ = -α / μ * uy # velocity in y direction
return u, φ, γ
# derivative of velocity
# possible use of https://github.com/kach/jax.value_and_jacfwd/blob/main/value_and_jacfwd.py
j = jacfwd(h, argnums=[1, 2])
(ux, uy), (φx, φy), (γx, γy) = j(parameters, x, y, α, μ)
u = f(parameters, x, y, α, μ)
return u, φx, φy, γx, γy
if __name__ == "__main__":
α = 1.0 # permeability
μ = 1.0 # viscousity
x_min = 0.0
x_max = 1.0
y_min = 0.0
y_max = 1.0
n_training_steps = 100
learning_rate = 1e-3
key = random.PRNGKey(1)
# construct network
layer_sizes = [4, 32, 1]
params = initialize_mlp(layer_sizes, key)
# training
opt_init, opt_update, get_params = adam(learning_rate)
opt_state = opt_init(params)
# training data
x_train = jnp.ones((10, 1))
y_train = jnp.ones_like(x_train)
α_train = jnp.ones_like(x_train) * α
μ_train = jnp.ones_like(x_train) * μ
# loss function
def loss_interior(params, x, y, α, μ):
u, φx, φy, γx, γy = predict_func(params, x, y, α, μ)
return jnp.linalg.norm(u - 1.0)
loss_fn_batched = jit(
vmap(
value_and_grad(loss_interior, argnums=0),
in_axes=(None, 0, 0, 0, 0),
out_axes=0,
)
)
# training loop
def update(step, opt_state):
params = get_params(opt_state)
loss, grads = loss_fn_batched(params, x_train, y_train, α_train, μ_train)
opt_state = opt_update(step, grads, opt_state)
return opt_state
for step in tqdm(range(n_training_steps), desc="training iteration"):
opt_state = update(step, opt_state)The training loop runs without jitting, albeit very slow. The use of the optimizer seems to be tied to the problem, since the jitted code works if the optimizer is removed from the code. Any help would be much appreciated :) |
Beta Was this translation helpful? Give feedback.
Replies: 1 comment
-
|
After some review, I realized that the losses for the individual samples were not being aggregated which is probably what leads to the error, not the jitting of the update function :) |
Beta Was this translation helpful? Give feedback.
After some review, I realized that the losses for the individual samples were not being aggregated which is probably what leads to the error, not the jitting of the update function :)