Replies: 6 comments 54 replies
-
|
I notice that you misunderstand the usage of num_batches = 100
batch_size = 512
assert jax.lax.scan(lambda n_batches, _: (n_batches + 1, None), 0, jnp.split(jnp.zeros(num_batches * batch_size), num_batches))[0] == batch_sizeNamely, your |
Beta Was this translation helpful? Give feedback.
-
|
There is no problem with num_batches = 100
batch_size = 512
assert jax.lax.scan(lambda n_batches, _: (n_batches + 1, None), 0, jnp.split(jnp.zeros(num_batches * batch_size), num_batches))[0] == batch_size |
Beta Was this translation helpful? Give feedback.
-
|
@samuela
https://jax.readthedocs.io/en/latest/pytrees.html
|
Beta Was this translation helpful? Give feedback.
-
|
Oh god you're right... That's so insanely confusing... talk about a foot-gun. Why in the world would scan ever do that? Well good catch! I'll put together a fixed version and profile that. |
Beta Was this translation helpful? Give feedback.
-
|
I recommend that use def make_batcher_in_paradise(num_examples: int, batch_size: int):
assert num_examples >= batch_size
num_batches = num_examples // batch_size
return lambda arr: jnp.reshape(arr[:num_batches * batch_size], (num_batches, batch_size))def step(train_state, p):
# See https://github.com/google/jax/issues/4564 as to why the array conversion is necessary.
p = jnp.array(p) # useless with reshape
images = ds_images[p, :, :, :]
labels = ds_labels[p]
images_transformed = vmap(train_transform)(augmax_rngs[p], images)
(l, num_correct), g = value_and_grad(batch_eval, has_aux=True)(train_state.params,
images_transformed, labels)
return train_state.apply_gradients(grads=g), (l, num_correct) |
Beta Was this translation helpful? Give feedback.
-
|
I've fixed and updated the gist. |
Beta Was this translation helpful? Give feedback.
-
|
Can you take a profile using |
Beta Was this translation helpful? Give feedback.
-
|
I tried wrapping my code in I'm using |
Beta Was this translation helpful? Give feedback.
-
|
That's (hopefully) a benign warning. Did a profile get produced? |
Beta Was this translation helpful? Give feedback.
-
|
Ah, yes I misunderstood. I've updated the gist with the new code (including profiling and the fix to the issue brought up by @YouJiacheng), and attaching the profile.tar.gz here. I did three epochs of burn-in and then profiled the training loop for 10 epochs. This was on a p3.2xlarge instance, same as the PyTorch implementation. |
Beta Was this translation helpful? Give feedback.
-
|
Your profile shows a step time of about 237-238 ms, dominated by cuDNN operations: (For context, the annotations in the top row are names of device kernels that are called, mostly inside cuDNN; the annotations in the middle are the names of XLA ops; and the annotations in the bottom row are the kernels currently being dispatched on the host, many steps ahead of time.) I would start by comparing the step time and cuDNN operations to a similar profile on the PyTorch side. |

Beta Was this translation helpful? Give feedback.
-
|
Ok, just managed to get a profile. It's 1 epoch after 3 epochs of burn-in. One thing to note is that profiling the code significantly slows down runtime: it's ~3.09s/epoch before profiling kicks in and about 12-13s/epoch with profiling. So the question remains... why is jax 10x slower? I have to go FaceTime the parents rn, but I'm hoping to start digging into the results later this evening. Don't hesitate to pester me if you'd like the exact code and experimental details to reproduce this trace. |
Beta Was this translation helpful? Give feedback.
-
|
I've been bumping into a few problems getting pytorch to profile the things I want and actually display them in a reasonable manner. I haven't been able to get flamegraphs working yet (GH issue forthcoming). However, I have gotten chrome-compatible traces. I've published my testing/profiling setup in my own fork here. For convenience, you can just download the saved traces here. The chrome traces can be inspect with
Does anyone know how I can assess the cuDNN kernel occupancy for comparison with JAX's 12.5%? I have not been able to find a comparable measurement thus far. |
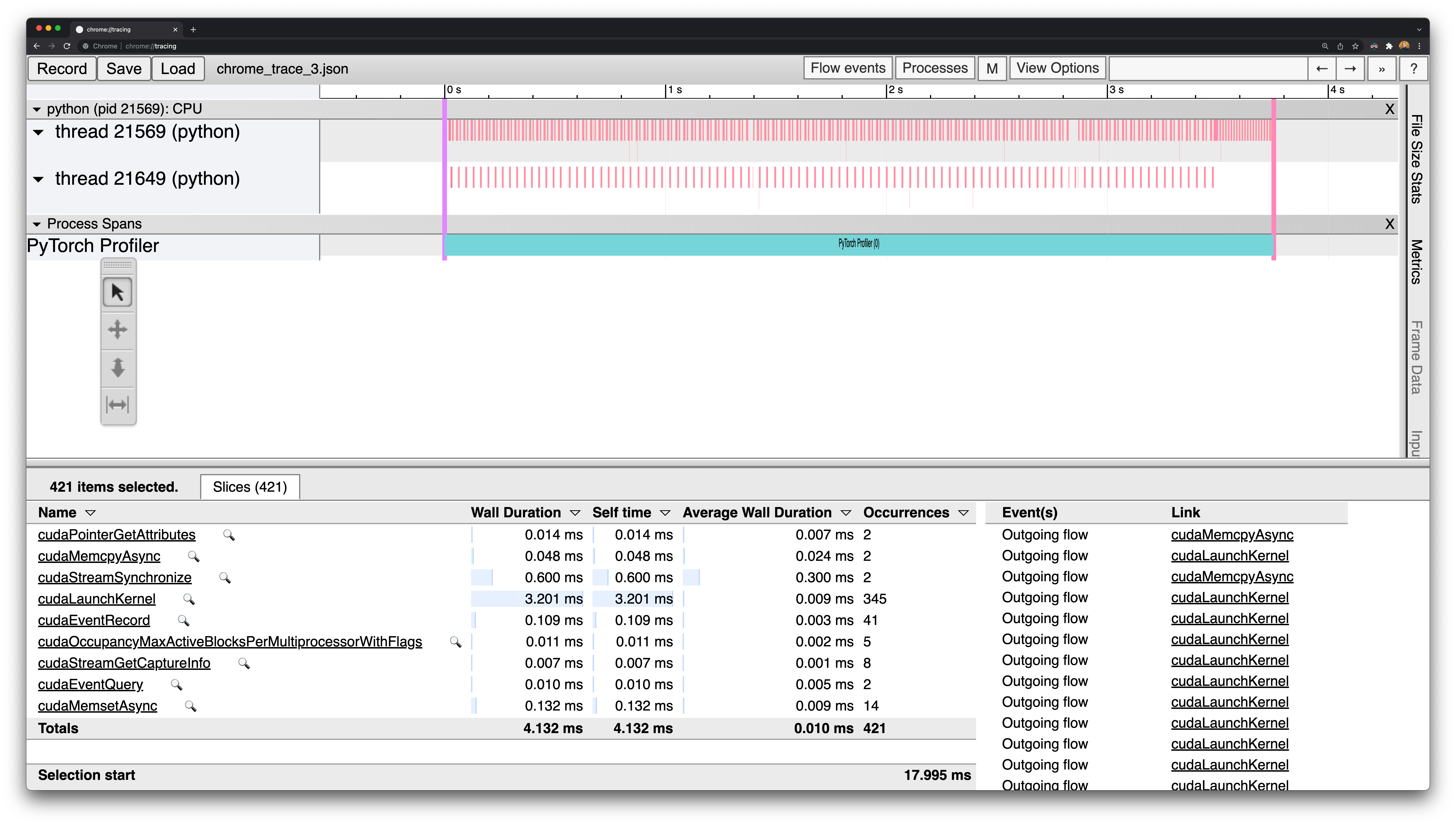
Beta Was this translation helpful? Give feedback.
-
|
Update: flamegraph issue created. |
Beta Was this translation helpful? Give feedback.
-
|
Just wanted to send a friendly ping on this. What can I do to get JAX to use the full cuDNN kernel occupancy available? |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @samuela . The last couple weeks were performance review week ("perf week") at Google so we were laden with administrative work and now we have a backlog. The pings are actually very helpful though. |
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
These are interesting points... Up to now I have been trying to I'll try running without data augmentation as that's pretty straightforward. I can try doing a python |
Beta Was this translation helpful? Give feedback.
-
|
Just tried without any data augmentation and it's the same speed. |
Beta Was this translation helpful? Give feedback.
-
|
I updated the gist to remove data augmentation and simplify a few other things. |
Beta Was this translation helpful? Give feedback.
-
|
I don’t think that augmentation or overheads related to scan are
problematic here; the profile suggested that virtually all your time is
spent in the device step. But none of us on the JAX team are experts in
cuDNN, and it really feels like the issue is something like cuDNN (via XLA)
selecting slow kernels.
…On Mon, Mar 7, 2022 at 8:18 PM Anselm Levskaya ***@***.***> wrote:
@samuela <https://github.com/samuela>
- do you have any sense how much time is spent in your on-device
augmentation vs the actual NN code? In all "production" code using JAX we
tend to use tf.data to set up the dataset augmentation pipeline since
tf.data is great at utilizing CPUs. Shoving augmentation computations onto
device is only going to hurt performance since you're leaving a lot of
compute on the table.
- I think a few of us are worried about scan potentially introducing
some inefficiencies here. In practice, we never scan a training loop. It
might be innocent of trouble, but it's a bit odd. Given jax's async
dispatch you don't really gain much by doing this.
—
Reply to this email directly, view it on GitHub
<#9669 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/ACZPRNSS335WINEJMPDUEG3U63IKPANCNFSM5PC7JETA>
.
You are receiving this because you commented.Message ID:
***@***.***>
|
Beta Was this translation helpful? Give feedback.
-
|
Not really, no - but I promise that I'll update you here as soon as I know anything new. |
Beta Was this translation helpful? Give feedback.
-
|
Hey @levskaya, any update from the XLA folks on this? |
Beta Was this translation helpful? Give feedback.
-
|
Sorry, I haven't heard anything from them yet on the issue... |
Beta Was this translation helpful? Give feedback.
-
|
@samuela sorry about the delay. I'm a member of the XLA GPU team and I'm on it! 😎 I'll let you know what I find. |
Beta Was this translation helpful? Give feedback.
-
|
Awesome, thanks so much @SandSnip3r ! Don't hesitate to reach out to me here or via email if there's anything I can do to be of assistance! |
Beta Was this translation helpful? Give feedback.
-
|
@samuela, I want to make absolutely sure that we're comparing apples-to-apples here. First thing I'm wondering about is the padding in the convolution. The Pytorch version uses Regardless, the discrepancy between the two paddings is a valid difference, right? |
Beta Was this translation helpful? Give feedback.
-
|
Yeah, I think this code is especially hairy... I went down the rabbit hole and I'm happy to report that AFAICT my original code was correct all along, with the minor exception that the pytorch version doesn't use a bias term on the final layer. So that's surely costing the JAX version a whole 1e-6ms/epoch. For anyone interested, there are a few confusing things in reading the pytorch code:
Here is the entry point for those brave souls who would like to stare into the abyss and experience the abyss staring back at you. |
Beta Was this translation helpful? Give feedback.
-
|
The Pytorch version is using Also, it's worth noticing that the JAX version is using NHWC data format, while PyTorch is using NCHW. This can be a source of other performance differences. |
Beta Was this translation helpful? Give feedback.
-
|
Ahhh great catch! That's very sneaky. I had no idea that pytorch by default sets stride = kernel size... Sure as shit, that brings down the time to 2.02s/epoch! Thank you so much @SandSnip3r! Very tricky indeed... |
Beta Was this translation helpful? Give feedback.
-
|
I updated your code to set stride to |
Beta Was this translation helpful? Give feedback.
-
|
That's entirely possible. My version doesn't do any batch norm, data aug, etc at the moment. I'm confident that with all the same tweaks it would get similar results. If not, then there are certainly other correctness bugs lurking, but hopefully no more performance ones! |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
The current # 8 record holder on the DAWNBench CIFAR-10 benchmark is a PyTorch ResNet by @davidcpage running on an EC2 p3.2xlarge instance (single V100 GPU). Record holders # 1-# 7 either use multiple GPUs or run on more esoteric cloud providers, so I'm not worrying about them for now.
My goal is to at least match the performance of this PyTorch implementation in JAX in terms of
seconds/epoch. However, I've found that even my somewhat carefully written JAX version is a shocking order of magnitude slower than the PyTorch version. On a p3.2xlarge instance, my JAX version (attached) clocks in at about 24.2s/epoch. The PyTorch version reports completing 24 epochs in 72s, which comes out to 3s/epoch.Some notes:
lax.scan.Original PyTorch implementation: https://github.com/davidcpage/cifar10-fast
JAX implementation (including my shell.nix for reproducibility): https://gist.github.com/samuela/78a3f0bbac759833a0464048aa499c98
What am I doing wrong here? What do I have to do to get competitive performance out of JAX?
cc @sharadmv
Beta Was this translation helpful? Give feedback.
All reactions