-  -
-  +
+
- smolagents - a smol library to build great agents!
+
+ A smol library to build great agents!
- smolagents - a smol library to build great agents!
+
+ A smol library to build great agents!
-  -
-
+  +
+
 @@ -115,4 +115,4 @@ Writing actions in code rather than JSON-like snippets provides better:
- **Composability:** could you nest JSON actions within each other, or define a set of JSON actions to re-use later, the same way you could just define a python function?
- **Object management:** how do you store the output of an action like `generate_image` in JSON?
- **Generality:** code is built to express simply anything you can have a computer do.
-- **Representation in LLM training data:** plenty of quality code actions is already included in LLMs’ training data which means they’re already trained for this!
+- **Representation in LLM training data:** plenty of quality code actions are already included in LLMs’ training data which means they’re already trained for this!
diff --git a/docs/source/en/conceptual_guides/react.md b/docs/source/en/conceptual_guides/react.mdx
similarity index 82%
rename from docs/source/en/conceptual_guides/react.md
rename to docs/source/en/conceptual_guides/react.mdx
index 417fb8590..b86c438e2 100644
--- a/docs/source/en/conceptual_guides/react.md
+++ b/docs/source/en/conceptual_guides/react.mdx
@@ -27,7 +27,7 @@ Initialization: the system prompt is stored in a `SystemPromptStep`, and the use
While loop (ReAct loop):
-- Use `agent.write_inner_memory_from_logs()` to write the agent logs into a list of LLM-readable [chat messages](https://huggingface.co/docs/transformers/en/chat_templating).
+- Use `agent.write_memory_to_messages()` to write the agent logs into a list of LLM-readable [chat messages](https://huggingface.co/docs/transformers/en/chat_templating).
- Send these messages to a `Model` object to get its completion. Parse the completion to get the action (a JSON blob for `ToolCallingAgent`, a code snippet for `CodeAgent`).
- Execute the action and logs result into memory (an `ActionStep`).
- At the end of each step, we run all callback functions defined in `agent.step_callbacks` .
@@ -38,11 +38,6 @@ For a `CodeAgent`, it looks like the figure below.
@@ -115,4 +115,4 @@ Writing actions in code rather than JSON-like snippets provides better:
- **Composability:** could you nest JSON actions within each other, or define a set of JSON actions to re-use later, the same way you could just define a python function?
- **Object management:** how do you store the output of an action like `generate_image` in JSON?
- **Generality:** code is built to express simply anything you can have a computer do.
-- **Representation in LLM training data:** plenty of quality code actions is already included in LLMs’ training data which means they’re already trained for this!
+- **Representation in LLM training data:** plenty of quality code actions are already included in LLMs’ training data which means they’re already trained for this!
diff --git a/docs/source/en/conceptual_guides/react.md b/docs/source/en/conceptual_guides/react.mdx
similarity index 82%
rename from docs/source/en/conceptual_guides/react.md
rename to docs/source/en/conceptual_guides/react.mdx
index 417fb8590..b86c438e2 100644
--- a/docs/source/en/conceptual_guides/react.md
+++ b/docs/source/en/conceptual_guides/react.mdx
@@ -27,7 +27,7 @@ Initialization: the system prompt is stored in a `SystemPromptStep`, and the use
While loop (ReAct loop):
-- Use `agent.write_inner_memory_from_logs()` to write the agent logs into a list of LLM-readable [chat messages](https://huggingface.co/docs/transformers/en/chat_templating).
+- Use `agent.write_memory_to_messages()` to write the agent logs into a list of LLM-readable [chat messages](https://huggingface.co/docs/transformers/en/chat_templating).
- Send these messages to a `Model` object to get its completion. Parse the completion to get the action (a JSON blob for `ToolCallingAgent`, a code snippet for `CodeAgent`).
- Execute the action and logs result into memory (an `ActionStep`).
- At the end of each step, we run all callback functions defined in `agent.step_callbacks` .
@@ -38,11 +38,6 @@ For a `CodeAgent`, it looks like the figure below.
 -
-
 -
- -
-You can see that the CodeAgent called its managed ToolCallingAgent (by the way, the managed agent could be have been a CodeAgent as well) to ask it to run the web search for the U.S. 2024 growth rate. Then the managed agent returned its report and the manager agent acted upon it to calculate the economy doubling time! Sweet, isn't it?
\ No newline at end of file
diff --git a/docs/source/en/tutorials/inspect_runs.mdx b/docs/source/en/tutorials/inspect_runs.mdx
new file mode 100644
index 000000000..4ade8427b
--- /dev/null
+++ b/docs/source/en/tutorials/inspect_runs.mdx
@@ -0,0 +1,193 @@
+
+# Inspecting runs with OpenTelemetry
+
+[[open-in-colab]]
+
+> [!TIP]
+> If you're new to building agents, make sure to first read the [intro to agents](../conceptual_guides/intro_agents) and the [guided tour of smolagents](../guided_tour).
+
+## Why log your agent runs?
+
+Agent runs are complicated to debug.
+
+Validating that a run went properly is hard, since agent workflows are [unpredictable by design](../conceptual_guides/intro_agents) (if they were predictable, you'd just be using good old code).
+
+And inspecting a run is hard as well: multi-step agents tend to quickly fill a console with logs, and most of the errors are just "LLM dumb" kind of errors, from which the LLM auto-corrects in the next step by writing better code or tool calls.
+
+So using instrumentation to record agent runs is necessary in production for later inspection and monitoring!
+
+We've adopted the [OpenTelemetry](https://opentelemetry.io/) standard for instrumenting agent runs.
+
+This means that you can just run some instrumentation code, then run your agents normally, and everything gets logged into your platform. Below are some examples of how to do this with different OpenTelemetry backends.
+
+Here's how it then looks like on the platform:
+
+
+
+
+You can see that the CodeAgent called its managed ToolCallingAgent (by the way, the managed agent could have been a CodeAgent as well) to ask it to run the web search for the U.S. 2024 growth rate. Then the managed agent returned its report and the manager agent acted upon it to calculate the economy doubling time! Sweet, isn't it?
+
+## Setting up telemetry with Langfuse
+
+This part shows how to monitor and debug your Hugging Face **smolagents** with **Langfuse** using the `SmolagentsInstrumentor`.
+
+> **What is Langfuse?** [Langfuse](https://langfuse.com) is an open-source platform for LLM engineering. It provides tracing and monitoring capabilities for AI agents, helping developers debug, analyze, and optimize their products. Langfuse integrates with various tools and frameworks via native integrations, OpenTelemetry, and SDKs.
+
+### Step 1: Install Dependencies
+
+```python
+%pip install smolagents
+%pip install opentelemetry-sdk opentelemetry-exporter-otlp openinference-instrumentation-smolagents
+```
+
+### Step 2: Set Up Environment Variables
+
+Set your Langfuse API keys and configure the OpenTelemetry endpoint to send traces to Langfuse. Get your Langfuse API keys by signing up for [Langfuse Cloud](https://cloud.langfuse.com) or [self-hosting Langfuse](https://langfuse.com/self-hosting).
+
+Also, add your [Hugging Face token](https://huggingface.co/settings/tokens) (`HF_TOKEN`) as an environment variable.
+
+```python
+import os
+import base64
+
+LANGFUSE_PUBLIC_KEY="pk-lf-..."
+LANGFUSE_SECRET_KEY="sk-lf-..."
+LANGFUSE_AUTH=base64.b64encode(f"{LANGFUSE_PUBLIC_KEY}:{LANGFUSE_SECRET_KEY}".encode()).decode()
+
+os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://cloud.langfuse.com/api/public/otel" # EU data region
+# os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://us.cloud.langfuse.com/api/public/otel" # US data region
+os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"Authorization=Basic {LANGFUSE_AUTH}"
+
+# your Hugging Face token
+os.environ["HF_TOKEN"] = "hf_..."
+```
+
+### Step 3: Initialize the `SmolagentsInstrumentor`
+
+Initialize the `SmolagentsInstrumentor` before your application code. Configure `tracer_provider` and add a span processor to export traces to Langfuse. `OTLPSpanExporter()` uses the endpoint and headers from the environment variables.
+
+
+```python
+from opentelemetry.sdk.trace import TracerProvider
+
+from openinference.instrumentation.smolagents import SmolagentsInstrumentor
+from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
+from opentelemetry.sdk.trace.export import SimpleSpanProcessor
+
+trace_provider = TracerProvider()
+trace_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter()))
+
+SmolagentsInstrumentor().instrument(tracer_provider=trace_provider)
+```
+
+### Step 4: Run your smolagent
+
+```python
+from smolagents import (
+ CodeAgent,
+ ToolCallingAgent,
+ DuckDuckGoSearchTool,
+ VisitWebpageTool,
+ HfApiModel,
+)
+
+model = HfApiModel(
+ model_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"
+)
+
+search_agent = ToolCallingAgent(
+ tools=[DuckDuckGoSearchTool(), VisitWebpageTool()],
+ model=model,
+ name="search_agent",
+ description="This is an agent that can do web search.",
+)
+
+manager_agent = CodeAgent(
+ tools=[],
+ model=model,
+ managed_agents=[search_agent],
+)
+manager_agent.run(
+ "How can Langfuse be used to monitor and improve the reasoning and decision-making of smolagents when they execute multi-step tasks, like dynamically adjusting a recipe based on user feedback or available ingredients?"
+)
+```
+
+### Step 5: View Traces in Langfuse
+
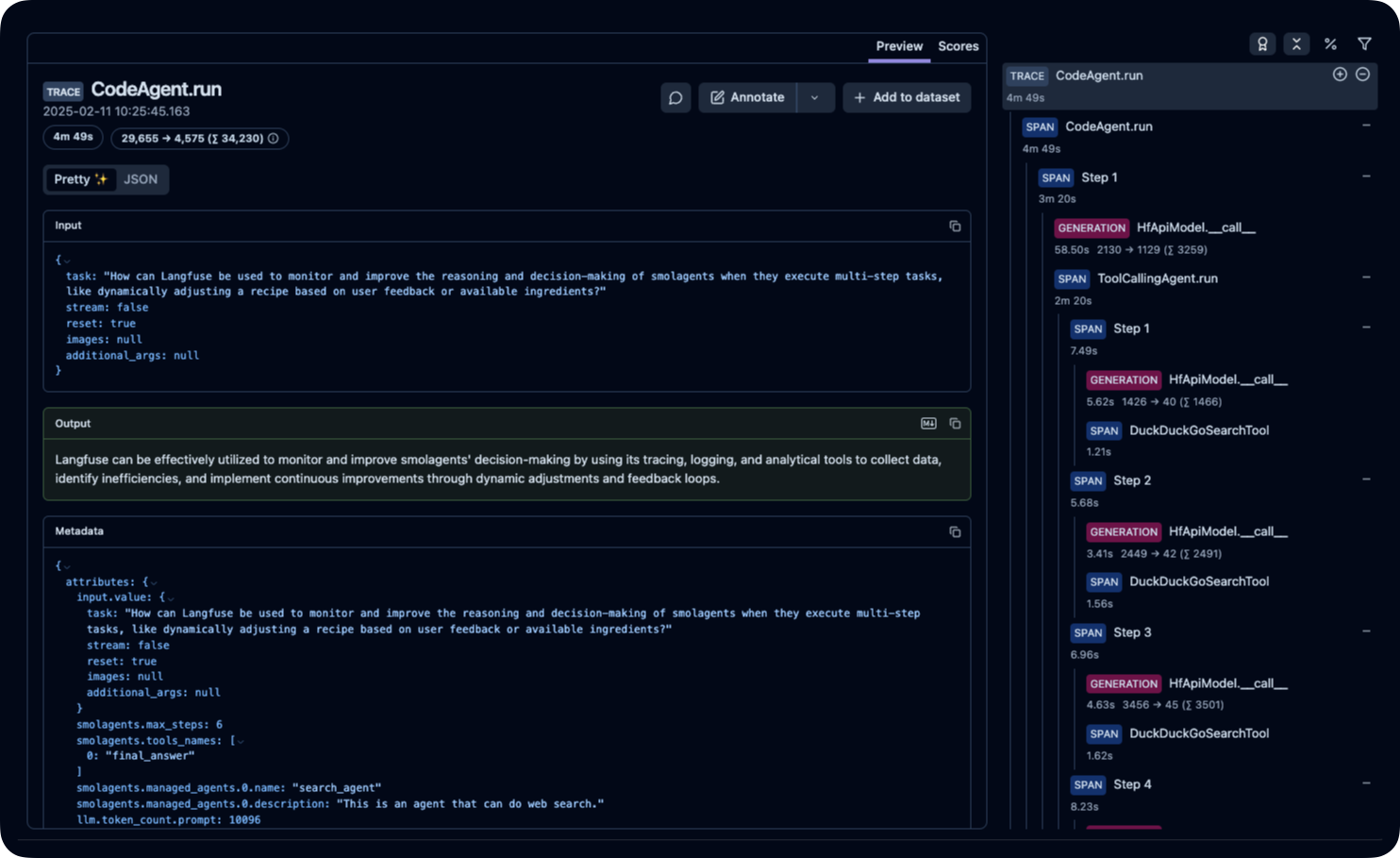
+After running the agent, you can view the traces generated by your smolagents application in [Langfuse](https://cloud.langfuse.com). You should see detailed steps of the LLM interactions, which can help you debug and optimize your AI agent.
+
+
+
+_[Public example trace in Langfuse](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/ce5160f9bfd5a6cd63b07d2bfcec6f54?timestamp=2025-02-11T09%3A25%3A45.163Z&display=details)_
diff --git a/docs/source/en/tutorials/memory.mdx b/docs/source/en/tutorials/memory.mdx
new file mode 100644
index 000000000..0732d9596
--- /dev/null
+++ b/docs/source/en/tutorials/memory.mdx
@@ -0,0 +1,148 @@
+
+# 📚 Manage your agent's memory
+
+[[open-in-colab]]
+
+In the end, an agent can be defined by simple components: it has tools, prompts.
+And most importantly, it has a memory of past steps, drawing a history of planning, execution, and errors.
+
+### Replay your agent's memory
+
+We propose several features to inspect a past agent run.
+
+You can instrument the agent's run to display it in a great UI that lets you zoom in/out on specific steps, as highlighted in the [instrumentation guide](./inspect_runs).
+
+You can also use `agent.replay()`, as follows:
+
+After the agent has run:
+```py
+from smolagents import HfApiModel, CodeAgent
+
+agent = CodeAgent(tools=[], model=HfApiModel(), verbosity_level=0)
+
+result = agent.run("What's the 20th Fibonacci number?")
+```
+
+If you want to replay this last run, just use:
+```py
+agent.replay()
+```
+
+### Dynamically change the agent's memory
+
+Many advanced use cases require dynamic modification of the agent's memory.
+
+You can access the agent's memory using:
+
+```py
+from smolagents import ActionStep
+
+system_prompt_step = agent.memory.system_prompt
+print("The system prompt given to the agent was:")
+print(system_prompt_step.system_prompt)
+
+task_step = agent.memory.steps[0]
+print("\n\nThe first task step was:")
+print(task_step.task)
+
+for step in agent.memory.steps:
+ if isinstance(step, ActionStep):
+ if step.error is not None:
+ print(f"\nStep {step.step_number} got this error:\n{step.error}\n")
+ else:
+ print(f"\nStep {step.step_number} got these observations:\n{step.observations}\n")
+```
+
+Use `agent.memory.get_full_steps()` to get full steps as dictionaries.
+
+You can also use step callbacks to dynamically change the agent's memory.
+
+Step callbacks can access the `agent` itself in their arguments, so they can access any memory step as highlighted above, and change it if needed. For instance, let's say you are observing screenshots of each step performed by a web browser agent. You want to log the newest screenshot, and remove the images from ancient steps to save on token costs.
+
+You culd run something like the following.
+_Note: this code is incomplete, some imports and object definitions have been removed for the sake of concision, visit [the original script](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py) to get the full working code._
+
+```py
+import helium
+from PIL import Image
+from io import BytesIO
+from time import sleep
+
+def update_screenshot(memory_step: ActionStep, agent: CodeAgent) -> None:
+ sleep(1.0) # Let JavaScript animations happen before taking the screenshot
+ driver = helium.get_driver()
+ latest_step = memory_step.step_number
+ for previous_memory_step in agent.memory.steps: # Remove previous screenshots from logs for lean processing
+ if isinstance(previous_memory_step, ActionStep) and previous_memory_step.step_number <= latest_step - 2:
+ previous_memory_step.observations_images = None
+ png_bytes = driver.get_screenshot_as_png()
+ image = Image.open(BytesIO(png_bytes))
+ memory_step.observations_images = [image.copy()]
+```
+
+Then you should pass this function in the `step_callbacks` argument upon initialization of your agent:
+
+```py
+CodeAgent(
+ tools=[DuckDuckGoSearchTool(), go_back, close_popups, search_item_ctrl_f],
+ model=model,
+ additional_authorized_imports=["helium"],
+ step_callbacks=[update_screenshot],
+ max_steps=20,
+ verbosity_level=2,
+)
+```
+
+Head to our [vision web browser code](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py) to see the full working example.
+
+### Run agents one step at a time
+
+This can be useful in case you have tool calls that take days: you can just run your agents step by step.
+This will also let you update the memory on each step.
+
+```py
+from smolagents import HfApiModel, CodeAgent, ActionStep, TaskStep
+
+agent = CodeAgent(tools=[], model=HfApiModel(), verbosity_level=1)
+print(agent.memory.system_prompt)
+
+task = "What is the 20th Fibonacci number?"
+
+# You could modify the memory as needed here by inputting the memory of another agent.
+# agent.memory.steps = previous_agent.memory.steps
+
+# Let's start a new task!
+agent.memory.steps.append(TaskStep(task=task, task_images=[]))
+
+final_answer = None
+step_number = 1
+while final_answer is None and step_number <= 10:
+ memory_step = ActionStep(
+ step_number=step_number,
+ observations_images=[],
+ )
+ # Run one step.
+ final_answer = agent.step(memory_step)
+ agent.memory.steps.append(memory_step)
+ step_number += 1
+
+ # Change the memory as you please!
+ # For instance to update the latest step:
+ # agent.memory.steps[-1] = ...
+
+print("The final answer is:", final_answer)
+```
\ No newline at end of file
diff --git a/docs/source/en/tutorials/secure_code_execution.md b/docs/source/en/tutorials/secure_code_execution.mdx
similarity index 100%
rename from docs/source/en/tutorials/secure_code_execution.md
rename to docs/source/en/tutorials/secure_code_execution.mdx
diff --git a/docs/source/en/tutorials/tools.md b/docs/source/en/tutorials/tools.mdx
similarity index 100%
rename from docs/source/en/tutorials/tools.md
rename to docs/source/en/tutorials/tools.mdx
diff --git a/docs/source/hi/conceptual_guides/intro_agents.md b/docs/source/hi/conceptual_guides/intro_agents.mdx
similarity index 100%
rename from docs/source/hi/conceptual_guides/intro_agents.md
rename to docs/source/hi/conceptual_guides/intro_agents.mdx
diff --git a/docs/source/hi/conceptual_guides/react.md b/docs/source/hi/conceptual_guides/react.mdx
similarity index 91%
rename from docs/source/hi/conceptual_guides/react.md
rename to docs/source/hi/conceptual_guides/react.mdx
index c36f17cfe..0f17901e8 100644
--- a/docs/source/hi/conceptual_guides/react.md
+++ b/docs/source/hi/conceptual_guides/react.mdx
@@ -42,6 +42,3 @@ ReAct प्रक्रिया में पिछले चरणों क
हम दो प्रकार के ToolCallingAgent को लागू करते हैं:
- [`ToolCallingAgent`] अपने आउटपुट में टूल कॉल को JSON के रूप में जनरेट करता है।
- [`CodeAgent`] ToolCallingAgent का एक नया प्रकार है जो अपने टूल कॉल को कोड के ब्लॉब्स के रूप में जनरेट करता है, जो उन LLM के लिए वास्तव में अच्छी तरह काम करता है जिनका कोडिंग प्रदर्शन मजबूत है।
-
-> [!TIP]
-> हम एजेंट्स को वन-शॉट में चलाने का विकल्प भी प्रदान करते हैं: बस एजेंट को लॉन्च करते समय `single_step=True` पास करें, जैसे `agent.run(your_task, single_step=True)`
\ No newline at end of file
diff --git a/docs/source/hi/examples/multiagents.md b/docs/source/hi/examples/multiagents.mdx
similarity index 99%
rename from docs/source/hi/examples/multiagents.md
rename to docs/source/hi/examples/multiagents.mdx
index 33056c8ba..1e9fcc745 100644
--- a/docs/source/hi/examples/multiagents.md
+++ b/docs/source/hi/examples/multiagents.mdx
@@ -119,7 +119,7 @@ print(visit_webpage("https://en.wikipedia.org/wiki/Hugging_Face")[:500])
अब जब हमारे पास सभी टूल्स `search` और `visit_webpage` हैं, हम उनका उपयोग वेब एजेंट बनाने के लिए कर सकते हैं।
इस एजेंट के लिए कौन सा कॉन्फ़िगरेशन चुनें?
-- वेब ब्राउज़िंग एक सिंगल-टाइमलाइन टास्क है जिसे समानांतर टूल कॉल की आवश्यकता नहीं है, इसलिए JSON टूल कॉलिंग इसके लिए अच्छी तरह काम करती है। इसलिए हम `JsonAgent` चुनते हैं।
+- वेब ब्राउज़िंग एक सिंगल-टाइमलाइन टास्क है जिसे समानांतर टूल कॉल की आवश्यकता नहीं है, इसलिए JSON टूल कॉलिंग इसके लिए अच्छी तरह काम करती है। इसलिए हम `ToolCallingAgent` चुनते हैं।
- साथ ही, चूंकि कभी-कभी वेब सर्च में सही उत्तर खोजने से पहले कई पेजों की सर्च करने की आवश्यकता होती है, हम `max_steps` को बढ़ाकर 10 करना पसंद करते हैं।
```py
diff --git a/docs/source/hi/examples/rag.md b/docs/source/hi/examples/rag.mdx
similarity index 100%
rename from docs/source/hi/examples/rag.md
rename to docs/source/hi/examples/rag.mdx
diff --git a/docs/source/hi/examples/text_to_sql.md b/docs/source/hi/examples/text_to_sql.mdx
similarity index 100%
rename from docs/source/hi/examples/text_to_sql.md
rename to docs/source/hi/examples/text_to_sql.mdx
diff --git a/docs/source/hi/guided_tour.md b/docs/source/hi/guided_tour.mdx
similarity index 96%
rename from docs/source/hi/guided_tour.md
rename to docs/source/hi/guided_tour.mdx
index 24cb71d03..745b6643a 100644
--- a/docs/source/hi/guided_tour.md
+++ b/docs/source/hi/guided_tour.mdx
@@ -142,7 +142,7 @@ agent.run("Could you get me the title of the page at url 'https://huggingface.co
रन के बाद क्या हुआ यह जांचने के लिए यहाँ कुछ उपयोगी एट्रिब्यूट्स हैं:
- `agent.logs` एजेंट के फाइन-ग्रेन्ड लॉग्स को स्टोर करता है। एजेंट के रन के हर स्टेप पर, सब कुछ एक डिक्शनरी में स्टोर किया जाता है जो फिर `agent.logs` में जोड़ा जाता है।
-- `agent.write_inner_memory_from_logs()` चलाने से LLM के लिए एजेंट के लॉग्स की एक इनर मेमोरी बनती है, चैट मैसेज की लिस्ट के रूप में। यह मेथड लॉग के प्रत्येक स्टेप पर जाता है और केवल वही स्टोर करता है जिसमें यह एक मैसेज के रूप में रुचि रखता है: उदाहरण के लिए, यह सिस्टम प्रॉम्प्ट और टास्क को अलग-अलग मैसेज के रूप में सेव करेगा, फिर प्रत्येक स्टेप के लिए यह LLM आउटपुट को एक मैसेज के रूप में और टूल कॉल आउटपुट को दूसरे मैसेज के रूप में स्टोर करेगा।
+- `agent.write_memory_to_messages()` चलाने से LLM के लिए एजेंट के लॉग्स की एक इनर मेमोरी बनती है, चैट मैसेज की लिस्ट के रूप में। यह मेथड लॉग के प्रत्येक स्टेप पर जाता है और केवल वही स्टोर करता है जिसमें यह एक मैसेज के रूप में रुचि रखता है: उदाहरण के लिए, यह सिस्टम प्रॉम्प्ट और टास्क को अलग-अलग मैसेज के रूप में सेव करेगा, फिर प्रत्येक स्टेप के लिए यह LLM आउटपुट को एक मैसेज के रूप में और टूल कॉल आउटपुट को दूसरे मैसेज के रूप में स्टोर करेगा।
## टूल्स
@@ -158,7 +158,7 @@ agent.run("Could you get me the title of the page at url 'https://huggingface.co
### डिफ़ॉल्ट टूलबॉक्स
-Transformers एजेंट्स को सशक्त बनाने के लिए एक डिफ़ॉल्ट टूलबॉक्स के साथ आता है, जिसे आप आर्ग्यूमेंट `add_base_tools = True` के साथ अपने एजेंट में इनिशियलाइजेशन पर जोड़ सकते हैं:
+`smolagents` एजेंट्स को सशक्त बनाने के लिए एक डिफ़ॉल्ट टूलबॉक्स के साथ आता है, जिसे आप आर्ग्यूमेंट `add_base_tools = True` के साथ अपने एजेंट में इनिशियलाइजेशन पर जोड़ सकते हैं:
- **DuckDuckGo वेब सर्च**: DuckDuckGo ब्राउज़र का उपयोग करके वेब सर्च करता है।
- **पायथन कोड इंटरप्रेटर**: आपका LLM जनरेटेड पायथन कोड एक सुरक्षित एनवायरनमेंट में चलाता है। यह टूल [`ToolCallingAgent`] में केवल तभी जोड़ा जाएगा जब आप इसे `add_base_tools=True` के साथ इनिशियलाइज़ करते हैं, क्योंकि कोड-बेस्ड एजेंट पहले से ही नेटिव रूप से पायथन कोड एक्जीक्यूट कर सकता है
diff --git a/docs/source/hi/index.md b/docs/source/hi/index.mdx
similarity index 100%
rename from docs/source/hi/index.md
rename to docs/source/hi/index.mdx
diff --git a/docs/source/hi/reference/agents.md b/docs/source/hi/reference/agents.mdx
similarity index 95%
rename from docs/source/hi/reference/agents.md
rename to docs/source/hi/reference/agents.mdx
index 11b461e79..2e070cf03 100644
--- a/docs/source/hi/reference/agents.md
+++ b/docs/source/hi/reference/agents.mdx
@@ -42,10 +42,9 @@ Agents और tools के बारे में अधिक जानने
[[autodoc]] ToolCallingAgent
-
### ManagedAgent
-[[autodoc]] ManagedAgent
+_This class is deprecated since 1.8.0: now you just need to pass name and description attributes to an agent to directly use it as previously done with a ManagedAgent._
### stream_to_gradio
@@ -146,6 +145,7 @@ print(model(messages))
यह क्लास आपको किसी भी OpenAIServer कम्पैटिबल मॉडल को कॉल करने देती है।
यहाँ बताया गया है कि आप इसे कैसे सेट कर सकते हैं (आप दूसरे सर्वर को पॉइंट करने के लिए `api_base` url को कस्टमाइज़ कर सकते हैं):
```py
+import os
from smolagents import OpenAIServerModel
model = OpenAIServerModel(
@@ -153,4 +153,14 @@ model = OpenAIServerModel(
api_base="https://api.openai.com/v1",
api_key=os.environ["OPENAI_API_KEY"],
)
-```
\ No newline at end of file
+```
+
+## Prompts
+
+[[autodoc]] smolagents.agents.PromptTemplates
+
+[[autodoc]] smolagents.agents.PlanningPromptTemplate
+
+[[autodoc]] smolagents.agents.ManagedAgentPromptTemplate
+
+[[autodoc]] smolagents.agents.FinalAnswerPromptTemplate
diff --git a/docs/source/hi/reference/tools.md b/docs/source/hi/reference/tools.mdx
similarity index 97%
rename from docs/source/hi/reference/tools.md
rename to docs/source/hi/reference/tools.mdx
index ddb24d1ab..6c270321e 100644
--- a/docs/source/hi/reference/tools.md
+++ b/docs/source/hi/reference/tools.mdx
@@ -80,12 +80,12 @@ Smolagents एक experimental API है जो किसी भी समय
### AgentText
-[[autodoc]] smolagents.types.AgentText
+[[autodoc]] smolagents.agent_types.AgentText
### AgentImage
-[[autodoc]] smolagents.types.AgentImage
+[[autodoc]] smolagents.agent_types.AgentImage
### AgentAudio
-[[autodoc]] smolagents.types.AgentAudio
+[[autodoc]] smolagents.agent_types.AgentAudio
diff --git a/docs/source/hi/tutorials/building_good_agents.md b/docs/source/hi/tutorials/building_good_agents.mdx
similarity index 99%
rename from docs/source/hi/tutorials/building_good_agents.md
rename to docs/source/hi/tutorials/building_good_agents.mdx
index 86eee273c..92587ef35 100644
--- a/docs/source/hi/tutorials/building_good_agents.md
+++ b/docs/source/hi/tutorials/building_good_agents.mdx
@@ -195,7 +195,7 @@ Final answer:
आइए देखें कि यह कैसे काम करता है। उदाहरण के लिए, आइए [`CodeAgent`] के लिए डिफ़ॉल्ट सिस्टम प्रॉम्प्ट की जाँच करें (नीचे दिया गया वर्जन जीरो-शॉट उदाहरणों को छोड़कर छोटा किया गया है)।
```python
-print(agent.system_prompt_template)
+print(agent.prompt_templates["system_prompt"])
```
Here is what you get:
```text
@@ -244,15 +244,7 @@ Now Begin! If you solve the task correctly, you will receive a reward of $1,000,
फिर आप सिस्टम प्रॉम्प्ट को निम्नानुसार बदल सकते हैं:
```py
-from smolagents.prompts import CODE_SYSTEM_PROMPT
-
-modified_system_prompt = CODE_SYSTEM_PROMPT + "\nHere you go!" # Change the system prompt here
-
-agent = CodeAgent(
- tools=[],
- model=HfApiModel(),
- system_prompt=modified_system_prompt
-)
+agent.prompt_templates["system_prompt"] = agent.prompt_templates["system_prompt"] + "\nHere you go!"
```
This also works with the [`ToolCallingAgent`].
diff --git a/docs/source/hi/tutorials/inspect_runs.md b/docs/source/hi/tutorials/inspect_runs.mdx
similarity index 98%
rename from docs/source/hi/tutorials/inspect_runs.md
rename to docs/source/hi/tutorials/inspect_runs.mdx
index db85fc755..0669c4dcc 100644
--- a/docs/source/hi/tutorials/inspect_runs.md
+++ b/docs/source/hi/tutorials/inspect_runs.mdx
@@ -71,7 +71,6 @@ SmolagentsInstrumentor().instrument(tracer_provider=trace_provider)
from smolagents import (
CodeAgent,
ToolCallingAgent,
- ManagedAgent,
DuckDuckGoSearchTool,
VisitWebpageTool,
HfApiModel,
@@ -79,15 +78,13 @@ from smolagents import (
model = HfApiModel()
-agent = ToolCallingAgent(
+managed_agent = ToolCallingAgent(
tools=[DuckDuckGoSearchTool(), VisitWebpageTool()],
model=model,
-)
-managed_agent = ManagedAgent(
- agent=agent,
name="managed_agent",
description="This is an agent that can do web search.",
)
+
manager_agent = CodeAgent(
tools=[],
model=model,
diff --git a/docs/source/hi/tutorials/secure_code_execution.md b/docs/source/hi/tutorials/secure_code_execution.mdx
similarity index 100%
rename from docs/source/hi/tutorials/secure_code_execution.md
rename to docs/source/hi/tutorials/secure_code_execution.mdx
diff --git a/docs/source/hi/tutorials/tools.md b/docs/source/hi/tutorials/tools.mdx
similarity index 100%
rename from docs/source/hi/tutorials/tools.md
rename to docs/source/hi/tutorials/tools.mdx
diff --git a/docs/source/zh/conceptual_guides/intro_agents.md b/docs/source/zh/conceptual_guides/intro_agents.mdx
similarity index 100%
rename from docs/source/zh/conceptual_guides/intro_agents.md
rename to docs/source/zh/conceptual_guides/intro_agents.mdx
diff --git a/docs/source/zh/conceptual_guides/react.md b/docs/source/zh/conceptual_guides/react.mdx
similarity index 93%
rename from docs/source/zh/conceptual_guides/react.md
rename to docs/source/zh/conceptual_guides/react.mdx
index 24428e03f..cdb970728 100644
--- a/docs/source/zh/conceptual_guides/react.md
+++ b/docs/source/zh/conceptual_guides/react.mdx
@@ -42,6 +42,3 @@ ReAct 过程涉及保留过去步骤的记忆。
我们实现了两个版本的 ToolCallingAgent:
- [`ToolCallingAgent`] 在其输出中生成 JSON 格式的工具调用。
- [`CodeAgent`] 是一种新型的 ToolCallingAgent,它生成代码块形式的工具调用,这对于具有强大编码性能的 LLM 非常有效。
-
-> [!TIP]
-> 我们还提供了一个选项来以单步模式运行 agent:只需在启动 agent 时传递 `single_step=True`,例如 `agent.run(your_task, single_step=True)`
\ No newline at end of file
diff --git a/docs/source/zh/examples/multiagents.md b/docs/source/zh/examples/multiagents.mdx
similarity index 90%
rename from docs/source/zh/examples/multiagents.md
rename to docs/source/zh/examples/multiagents.mdx
index 67eed890e..3b177d133 100644
--- a/docs/source/zh/examples/multiagents.md
+++ b/docs/source/zh/examples/multiagents.mdx
@@ -120,7 +120,7 @@ print(visit_webpage("https://en.wikipedia.org/wiki/Hugging_Face")[:500])
现在我们有了所有工具`search`和`visit_webpage`,我们可以使用它们来创建web agent。
我们该选取什么样的配置来构建这个agent呢?
-- 网页浏览是一个单线程任务,不需要并行工具调用,因此JSON工具调用对于这个任务非常有效。因此我们选择`JsonAgent`。
+- 网页浏览是一个单线程任务,不需要并行工具调用,因此JSON工具调用对于这个任务非常有效。因此我们选择`ToolCallingAgent`。
- 有时候网页搜索需要探索许多页面才能找到正确答案,所以我们更喜欢将 `max_steps` 增加到10。
```py
@@ -139,26 +139,24 @@ web_agent = ToolCallingAgent(
tools=[DuckDuckGoSearchTool(), visit_webpage],
model=model,
max_steps=10,
-)
-```
-
-然后我们将这个agent封装到一个`ManagedAgent`中,使其可以被其管理的agent调用。
-
-```py
-managed_web_agent = ManagedAgent(
- agent=web_agent,
name="search",
description="Runs web searches for you. Give it your query as an argument.",
)
```
-最后,我们创建一个manager agent,在初始化时将我们的managed agent传递给它的`managed_agents`参数。因为这个agent负责计划和思考,所以高级推理将是有益的,因此`CodeAgent`将是最佳选择。此外,我们想要问一个涉及当前年份的问题,并进行额外的数据计算:因此让我们添加`additional_authorized_imports=["time", "numpy", "pandas"]`,以防agent需要这些包。
+请注意,我们为这个代理赋予了 name(名称)和 description(描述)属性,这些是必需属性,以便让管理代理能够调用此代理。
+
+然后,我们创建一个管理代理,在初始化时,将受管代理作为 managed_agents 参数传递给它。
+
+由于这个代理的任务是进行规划和思考,高级推理能力会很有帮助,因此 CodeAgent(代码代理)将是最佳选择。
+
+此外,我们要提出一个涉及当前年份并需要进行额外数据计算的问题:所以让我们添加 additional_authorized_imports=["time", "numpy", "pandas"],以防代理需要用到这些包。
```py
manager_agent = CodeAgent(
tools=[],
model=model,
- managed_agents=[managed_web_agent],
+ managed_agents=[web_agent],
additional_authorized_imports=["time", "numpy", "pandas"],
)
```
diff --git a/docs/source/zh/examples/rag.mdx b/docs/source/zh/examples/rag.mdx
new file mode 100644
index 000000000..23efa9e0e
--- /dev/null
+++ b/docs/source/zh/examples/rag.mdx
@@ -0,0 +1,143 @@
+
+# Agentic RAG
+
+[[open-in-colab]]
+
+Retrieval-Augmented-Generation (RAG) 是“使用大语言模型(LLM)来回答用户查询,但基于从知识库中检索的信息”。它比使用普通或微调的 LLM 具有许多优势:举几个例子,它允许将答案基于真实事实并减少虚构;它允许提供 LLM 领域特定的知识;并允许对知识库中的信息访问进行精细控制。
+
+但是,普通的 RAG 存在一些局限性,以下两点尤为突出:
+
+- 它只执行一次检索步骤:如果结果不好,生成的内容也会不好。
+- 语义相似性是以用户查询为参考计算的,这可能不是最优的:例如,用户查询通常是一个问题,而包含真实答案的文档通常是肯定语态,因此其相似性得分会比其他以疑问形式呈现的源文档低,从而导致错失相关信息的风险。
+
+我们可以通过制作一个 RAG agent来缓解这些问题:非常简单,一个配备了检索工具的agent!这个 agent 将
+会:✅ 自己构建查询和检索,✅ 如果需要的话会重新检索。
+
+因此,它将比普通 RAG 更智能,因为它可以自己构建查询,而不是直接使用用户查询作为参考。这样,它可以更
+接近目标文档,从而提高检索的准确性, [HyDE](https://huggingface.co/papers/2212.10496)。此 agent 可以
+使用生成的片段,并在需要时重新检索,就像 [Self-Query](https://docs.llamaindex.ai/en/stable/examples/evaluation/RetryQuery/)。
+
+我们现在开始构建这个系统. 🛠️
+
+运行以下代码以安装所需的依赖包:
+```bash
+!pip install smolagents pandas langchain langchain-community sentence-transformers rank_bm25 --upgrade -q
+```
+
+你需要一个有效的 token 作为环境变量 `HF_TOKEN` 来调用 HF Inference API。我们使用 python-dotenv 来加载它。
+```py
+from dotenv import load_dotenv
+load_dotenv()
+```
+
+我们首先加载一个知识库以在其上执行 RAG:此数据集是许多 Hugging Face 库的文档页面的汇编,存储为 markdown 格式。我们将仅保留 `transformers` 库的文档。然后通过处理数据集并将其存储到向量数据库中,为检索器准备知识库。我们将使用 [LangChain](https://python.langchain.com/docs/introduction/) 来利用其出色的向量数据库工具。
+```py
+import datasets
+from langchain.docstore.document import Document
+from langchain.text_splitter import RecursiveCharacterTextSplitter
+from langchain_community.retrievers import BM25Retriever
+
+knowledge_base = datasets.load_dataset("m-ric/huggingface_doc", split="train")
+knowledge_base = knowledge_base.filter(lambda row: row["source"].startswith("huggingface/transformers"))
+
+source_docs = [
+ Document(page_content=doc["text"], metadata={"source": doc["source"].split("/")[1]})
+ for doc in knowledge_base
+]
+
+text_splitter = RecursiveCharacterTextSplitter(
+ chunk_size=500,
+ chunk_overlap=50,
+ add_start_index=True,
+ strip_whitespace=True,
+ separators=["\n\n", "\n", ".", " ", ""],
+)
+docs_processed = text_splitter.split_documents(source_docs)
+```
+
+现在文档已准备好。我们来一起构建我们的 agent RAG 系统!
+👉 我们只需要一个 RetrieverTool,我们的 agent 可以利用它从知识库中检索信息。
+
+由于我们需要将 vectordb 添加为工具的属性,我们不能简单地使用带有 `@tool` 装饰器的简单工具构造函数:因此我们将遵循 [tools 教程](../tutorials/tools) 中突出显示的高级设置。
+
+```py
+from smolagents import Tool
+
+class RetrieverTool(Tool):
+ name = "retriever"
+ description = "Uses semantic search to retrieve the parts of transformers documentation that could be most relevant to answer your query."
+ inputs = {
+ "query": {
+ "type": "string",
+ "description": "The query to perform. This should be semantically close to your target documents. Use the affirmative form rather than a question.",
+ }
+ }
+ output_type = "string"
+
+ def __init__(self, docs, **kwargs):
+ super().__init__(**kwargs)
+ self.retriever = BM25Retriever.from_documents(
+ docs, k=10
+ )
+
+ def forward(self, query: str) -> str:
+ assert isinstance(query, str), "Your search query must be a string"
+
+ docs = self.retriever.invoke(
+ query,
+ )
+ return "\nRetrieved documents:\n" + "".join(
+ [
+ f"\n\n===== Document {str(i)} =====\n" + doc.page_content
+ for i, doc in enumerate(docs)
+ ]
+ )
+
+retriever_tool = RetrieverTool(docs_processed)
+```
+BM25 检索方法是一个经典的检索方法,因为它的设置速度非常快。为了提高检索准确性,你可以使用语义搜索,使用文档的向量表示替换 BM25:因此你可以前往 [MTEB Leaderboard](https://huggingface.co/spaces/mteb/leaderboard) 选择一个好的嵌入模型。
+
+现在我们已经创建了一个可以从知识库中检索信息的工具,现在我们可以很容易地创建一个利用这个
+`retriever_tool` 的 agent!此 agent 将使用如下参数初始化:
+- `tools`:代理将能够调用的工具列表。
+- `model`:为代理提供动力的 LLM。
+
+我们的 `model` 必须是一个可调用对象,它接受一个消息的 list 作为输入,并返回文本。它还需要接受一个 stop_sequences 参数,指示何时停止生成。为了方便起见,我们直接使用包中提供的 `HfEngine` 类来获取调用 Hugging Face 的 Inference API 的 LLM 引擎。
+
+接着,我们将使用 [meta-llama/Llama-3.3-70B-Instruct](meta-llama/Llama-3.3-70B-Instruct) 作为 llm 引
+擎,因为:
+- 它有一个长 128k 上下文,这对处理长源文档很有用。
+- 它在 HF 的 Inference API 上始终免费提供!
+
+_Note:_ 此 Inference API 托管基于各种标准的模型,部署的模型可能会在没有事先通知的情况下进行更新或替换。了解更多信息,请点击[这里](https://huggingface.co/docs/api-inference/supported-models)。
+
+```py
+from smolagents import HfApiModel, CodeAgent
+
+agent = CodeAgent(
+ tools=[retriever_tool], model=HfApiModel("meta-llama/Llama-3.3-70B-Instruct"), max_steps=4, verbose=True
+)
+```
+
+当我们初始化 CodeAgent 时,它已经自动获得了一个默认的系统提示,告诉 LLM 引擎按步骤处理并生成工具调用作为代码片段,但你可以根据需要替换此提示模板。接着,当其 `.run()` 方法被调用时,代理将负责调用 LLM 引擎,并在循环中执行工具调用,直到工具 `final_answer` 被调用,而其参数为最终答案。
+
+```py
+agent_output = agent.run("For a transformers model training, which is slower, the forward or the backward pass?")
+
+print("Final output:")
+print(agent_output)
+```
diff --git a/docs/source/zh/examples/text_to_sql.md b/docs/source/zh/examples/text_to_sql.mdx
similarity index 64%
rename from docs/source/zh/examples/text_to_sql.md
rename to docs/source/zh/examples/text_to_sql.mdx
index 12d0c5e47..419c45159 100644
--- a/docs/source/zh/examples/text_to_sql.md
+++ b/docs/source/zh/examples/text_to_sql.mdx
@@ -17,17 +17,17 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-In this tutorial, we’ll see how to implement an agent that leverages SQL using `smolagents`.
+在此教程中,我们将看到如何使用 `smolagents` 实现一个利用 SQL 的 agent。
-> Let's start with the golden question: why not keep it simple and use a standard text-to-SQL pipeline?
+> 让我们从经典问题开始:为什么不简单地使用标准的 text-to-SQL pipeline 呢?
-A standard text-to-sql pipeline is brittle, since the generated SQL query can be incorrect. Even worse, the query could be incorrect, but not raise an error, instead giving some incorrect/useless outputs without raising an alarm.
+标准的 text-to-SQL pipeline 很脆弱,因为生成的 SQL 查询可能会出错。更糟糕的是,查询可能出错却不引发错误警报,从而返回一些不正确或无用的结果。
-👉 Instead, an agent system is able to critically inspect outputs and decide if the query needs to be changed or not, thus giving it a huge performance boost.
+👉 相反,agent 系统则可以检视输出结果并决定查询是否需要被更改,因此带来巨大的性能提升。
-Let’s build this agent! 💪
+让我们来一起构建这个 agent! 💪
-First, we setup the SQL environment:
+首先,我们构建一个 SQL 的环境:
```py
from sqlalchemy import (
create_engine,
@@ -69,11 +69,9 @@ for row in rows:
cursor = connection.execute(stmt)
```
-### Build our agent
+### 构建 agent
-Now let’s make our SQL table retrievable by a tool.
-
-The tool’s description attribute will be embedded in the LLM’s prompt by the agent system: it gives the LLM information about how to use the tool. This is where we want to describe the SQL table.
+现在,我们构建一个 agent,它将使用 SQL 查询来回答问题。工具的 description 属性将被 agent 系统嵌入到 LLM 的提示中:它为 LLM 提供有关如何使用该工具的信息。这正是我们描述 SQL 表的地方。
```py
inspector = inspect(engine)
@@ -91,9 +89,10 @@ Columns:
- tip: FLOAT
```
-Now let’s build our tool. It needs the following: (read [the tool doc](../tutorials/tools) for more detail)
-- A docstring with an `Args:` part listing arguments.
-- Type hints on both inputs and output.
+现在让我们构建我们的工具。它需要以下内容:(更多细节请参阅[工具文档](../tutorials/tools))
+
+- 一个带有 `Args:` 部分列出参数的 docstring。
+- 输入和输出的type hints。
```py
from smolagents import tool
@@ -120,11 +119,9 @@ def sql_engine(query: str) -> str:
return output
```
-Now let us create an agent that leverages this tool.
+我们现在使用这个工具来创建一个 agent。我们使用 `CodeAgent`,这是 smolagent 的主要 agent 类:一个在代码中编写操作并根据 ReAct 框架迭代先前输出的 agent。
-We use the `CodeAgent`, which is smolagents’ main agent class: an agent that writes actions in code and can iterate on previous output according to the ReAct framework.
-
-The model is the LLM that powers the agent system. HfApiModel allows you to call LLMs using HF’s Inference API, either via Serverless or Dedicated endpoint, but you could also use any proprietary API.
+这个模型是驱动 agent 系统的 LLM。`HfApiModel` 允许你使用 HF Inference API 调用 LLM,无论是通过 Serverless 还是 Dedicated endpoint,但你也可以使用任何专有 API。
```py
from smolagents import CodeAgent, HfApiModel
@@ -136,11 +133,9 @@ agent = CodeAgent(
agent.run("Can you give me the name of the client who got the most expensive receipt?")
```
-### Level 2: Table joins
-
-Now let’s make it more challenging! We want our agent to handle joins across multiple tables.
+### Level 2: 表连接
-So let’s make a second table recording the names of waiters for each receipt_id!
+现在让我们增加一些挑战!我们希望我们的 agent 能够处理跨多个表的连接。因此,我们创建一个新表,记录每个 receipt_id 的服务员名字!
```py
table_name = "waiters"
@@ -163,7 +158,8 @@ for row in rows:
with engine.begin() as connection:
cursor = connection.execute(stmt)
```
-Since we changed the table, we update the `SQLExecutorTool` with this table’s description to let the LLM properly leverage information from this table.
+
+因为我们改变了表,我们需要更新 `SQLExecutorTool`,让 LLM 能够正确利用这个表的信息。
```py
updated_description = """Allows you to perform SQL queries on the table. Beware that this tool's output is a string representation of the execution output.
@@ -180,7 +176,8 @@ for table in ["receipts", "waiters"]:
print(updated_description)
```
-Since this request is a bit harder than the previous one, we’ll switch the LLM engine to use the more powerful [Qwen/Qwen2.5-Coder-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct)!
+
+因为这个request 比之前的要难一些,我们将 LLM 引擎切换到更强大的 [Qwen/Qwen2.5-Coder-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct)!
```py
sql_engine.description = updated_description
@@ -192,11 +189,13 @@ agent = CodeAgent(
agent.run("Which waiter got more total money from tips?")
```
-It directly works! The setup was surprisingly simple, wasn’t it?
-This example is done! We've touched upon these concepts:
-- Building new tools.
-- Updating a tool's description.
-- Switching to a stronger LLM helps agent reasoning.
+它直接就能工作!设置过程非常简单,难道不是吗?
+
+这个例子到此结束!我们涵盖了这些概念:
+
+- 构建新工具。
+- 更新工具的描述。
+- 切换到更强大的 LLM 有助于 agent 推理。
-✅ Now you can go build this text-to-SQL system you’ve always dreamt of! ✨
\ No newline at end of file
+✅ 现在你可以构建你一直梦寐以求的 text-to-SQL 系统了!✨
diff --git a/docs/source/zh/guided_tour.md b/docs/source/zh/guided_tour.mdx
similarity index 97%
rename from docs/source/zh/guided_tour.md
rename to docs/source/zh/guided_tour.mdx
index 537e5948e..54ae10419 100644
--- a/docs/source/zh/guided_tour.md
+++ b/docs/source/zh/guided_tour.mdx
@@ -152,7 +152,7 @@ agent.run("Could you get me the title of the page at url 'https://huggingface.co
以下是一些有用的属性,用于检查运行后发生了什么:
- `agent.logs` 存储 agent 的细粒度日志。在 agent 运行的每一步,所有内容都会存储在一个字典中,然后附加到 `agent.logs` 中。
-- 运行 `agent.write_inner_memory_from_logs()` 会为 LLM 创建一个 agent 日志的内部内存,作为聊天消息列表。此方法会遍历日志的每一步,并仅存储它感兴趣的内容作为消息:例如,它会将系统提示和任务存储为单独的消息,然后对于每一步,它会将 LLM 输出存储为一条消息,工具调用输出存储为另一条消息。如果您想要更高级别的视图 - 但不是每个日志都会被此方法转录。
+- 运行 `agent.write_memory_to_messages()` 会为 LLM 创建一个 agent 日志的内部内存,作为聊天消息列表。此方法会遍历日志的每一步,并仅存储它感兴趣的内容作为消息:例如,它会将系统提示和任务存储为单独的消息,然后对于每一步,它会将 LLM 输出存储为一条消息,工具调用输出存储为另一条消息。如果您想要更高级别的视图 - 但不是每个日志都会被此方法转录。
## 工具
@@ -168,7 +168,7 @@ agent.run("Could you get me the title of the page at url 'https://huggingface.co
### 默认工具箱
-Transformers 附带了一个用于增强 agent 的默认工具箱,您可以在初始化时通过参数 `add_base_tools = True` 将其添加到您的 agent 中:
+`smolagents` 附带了一个用于增强 agent 的默认工具箱,您可以在初始化时通过参数 `add_base_tools = True` 将其添加到您的 agent 中:
- **DuckDuckGo 网页搜索**:使用 DuckDuckGo 浏览器执行网页搜索。
- **Python 代码解释器**:在安全环境中运行 LLM 生成的 Python 代码。只有在使用 `add_base_tools=True` 初始化 [`ToolCallingAgent`] 时才会添加此工具,因为基于代码的 agent 已经可以原生执行 Python 代码
diff --git a/docs/source/zh/index.md b/docs/source/zh/index.mdx
similarity index 100%
rename from docs/source/zh/index.md
rename to docs/source/zh/index.mdx
diff --git a/docs/source/zh/reference/agents.md b/docs/source/zh/reference/agents.md
deleted file mode 100644
index 3b05a6d28..000000000
--- a/docs/source/zh/reference/agents.md
+++ /dev/null
@@ -1,149 +0,0 @@
-
-# Agents
-
-
-
-You can see that the CodeAgent called its managed ToolCallingAgent (by the way, the managed agent could be have been a CodeAgent as well) to ask it to run the web search for the U.S. 2024 growth rate. Then the managed agent returned its report and the manager agent acted upon it to calculate the economy doubling time! Sweet, isn't it?
\ No newline at end of file
diff --git a/docs/source/en/tutorials/inspect_runs.mdx b/docs/source/en/tutorials/inspect_runs.mdx
new file mode 100644
index 000000000..4ade8427b
--- /dev/null
+++ b/docs/source/en/tutorials/inspect_runs.mdx
@@ -0,0 +1,193 @@
+
+# Inspecting runs with OpenTelemetry
+
+[[open-in-colab]]
+
+> [!TIP]
+> If you're new to building agents, make sure to first read the [intro to agents](../conceptual_guides/intro_agents) and the [guided tour of smolagents](../guided_tour).
+
+## Why log your agent runs?
+
+Agent runs are complicated to debug.
+
+Validating that a run went properly is hard, since agent workflows are [unpredictable by design](../conceptual_guides/intro_agents) (if they were predictable, you'd just be using good old code).
+
+And inspecting a run is hard as well: multi-step agents tend to quickly fill a console with logs, and most of the errors are just "LLM dumb" kind of errors, from which the LLM auto-corrects in the next step by writing better code or tool calls.
+
+So using instrumentation to record agent runs is necessary in production for later inspection and monitoring!
+
+We've adopted the [OpenTelemetry](https://opentelemetry.io/) standard for instrumenting agent runs.
+
+This means that you can just run some instrumentation code, then run your agents normally, and everything gets logged into your platform. Below are some examples of how to do this with different OpenTelemetry backends.
+
+Here's how it then looks like on the platform:
+
+
+
+
+You can see that the CodeAgent called its managed ToolCallingAgent (by the way, the managed agent could have been a CodeAgent as well) to ask it to run the web search for the U.S. 2024 growth rate. Then the managed agent returned its report and the manager agent acted upon it to calculate the economy doubling time! Sweet, isn't it?
+
+## Setting up telemetry with Langfuse
+
+This part shows how to monitor and debug your Hugging Face **smolagents** with **Langfuse** using the `SmolagentsInstrumentor`.
+
+> **What is Langfuse?** [Langfuse](https://langfuse.com) is an open-source platform for LLM engineering. It provides tracing and monitoring capabilities for AI agents, helping developers debug, analyze, and optimize their products. Langfuse integrates with various tools and frameworks via native integrations, OpenTelemetry, and SDKs.
+
+### Step 1: Install Dependencies
+
+```python
+%pip install smolagents
+%pip install opentelemetry-sdk opentelemetry-exporter-otlp openinference-instrumentation-smolagents
+```
+
+### Step 2: Set Up Environment Variables
+
+Set your Langfuse API keys and configure the OpenTelemetry endpoint to send traces to Langfuse. Get your Langfuse API keys by signing up for [Langfuse Cloud](https://cloud.langfuse.com) or [self-hosting Langfuse](https://langfuse.com/self-hosting).
+
+Also, add your [Hugging Face token](https://huggingface.co/settings/tokens) (`HF_TOKEN`) as an environment variable.
+
+```python
+import os
+import base64
+
+LANGFUSE_PUBLIC_KEY="pk-lf-..."
+LANGFUSE_SECRET_KEY="sk-lf-..."
+LANGFUSE_AUTH=base64.b64encode(f"{LANGFUSE_PUBLIC_KEY}:{LANGFUSE_SECRET_KEY}".encode()).decode()
+
+os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://cloud.langfuse.com/api/public/otel" # EU data region
+# os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://us.cloud.langfuse.com/api/public/otel" # US data region
+os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"Authorization=Basic {LANGFUSE_AUTH}"
+
+# your Hugging Face token
+os.environ["HF_TOKEN"] = "hf_..."
+```
+
+### Step 3: Initialize the `SmolagentsInstrumentor`
+
+Initialize the `SmolagentsInstrumentor` before your application code. Configure `tracer_provider` and add a span processor to export traces to Langfuse. `OTLPSpanExporter()` uses the endpoint and headers from the environment variables.
+
+
+```python
+from opentelemetry.sdk.trace import TracerProvider
+
+from openinference.instrumentation.smolagents import SmolagentsInstrumentor
+from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
+from opentelemetry.sdk.trace.export import SimpleSpanProcessor
+
+trace_provider = TracerProvider()
+trace_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter()))
+
+SmolagentsInstrumentor().instrument(tracer_provider=trace_provider)
+```
+
+### Step 4: Run your smolagent
+
+```python
+from smolagents import (
+ CodeAgent,
+ ToolCallingAgent,
+ DuckDuckGoSearchTool,
+ VisitWebpageTool,
+ HfApiModel,
+)
+
+model = HfApiModel(
+ model_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"
+)
+
+search_agent = ToolCallingAgent(
+ tools=[DuckDuckGoSearchTool(), VisitWebpageTool()],
+ model=model,
+ name="search_agent",
+ description="This is an agent that can do web search.",
+)
+
+manager_agent = CodeAgent(
+ tools=[],
+ model=model,
+ managed_agents=[search_agent],
+)
+manager_agent.run(
+ "How can Langfuse be used to monitor and improve the reasoning and decision-making of smolagents when they execute multi-step tasks, like dynamically adjusting a recipe based on user feedback or available ingredients?"
+)
+```
+
+### Step 5: View Traces in Langfuse
+
+After running the agent, you can view the traces generated by your smolagents application in [Langfuse](https://cloud.langfuse.com). You should see detailed steps of the LLM interactions, which can help you debug and optimize your AI agent.
+
+
+
+_[Public example trace in Langfuse](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/ce5160f9bfd5a6cd63b07d2bfcec6f54?timestamp=2025-02-11T09%3A25%3A45.163Z&display=details)_
diff --git a/docs/source/en/tutorials/memory.mdx b/docs/source/en/tutorials/memory.mdx
new file mode 100644
index 000000000..0732d9596
--- /dev/null
+++ b/docs/source/en/tutorials/memory.mdx
@@ -0,0 +1,148 @@
+
+# 📚 Manage your agent's memory
+
+[[open-in-colab]]
+
+In the end, an agent can be defined by simple components: it has tools, prompts.
+And most importantly, it has a memory of past steps, drawing a history of planning, execution, and errors.
+
+### Replay your agent's memory
+
+We propose several features to inspect a past agent run.
+
+You can instrument the agent's run to display it in a great UI that lets you zoom in/out on specific steps, as highlighted in the [instrumentation guide](./inspect_runs).
+
+You can also use `agent.replay()`, as follows:
+
+After the agent has run:
+```py
+from smolagents import HfApiModel, CodeAgent
+
+agent = CodeAgent(tools=[], model=HfApiModel(), verbosity_level=0)
+
+result = agent.run("What's the 20th Fibonacci number?")
+```
+
+If you want to replay this last run, just use:
+```py
+agent.replay()
+```
+
+### Dynamically change the agent's memory
+
+Many advanced use cases require dynamic modification of the agent's memory.
+
+You can access the agent's memory using:
+
+```py
+from smolagents import ActionStep
+
+system_prompt_step = agent.memory.system_prompt
+print("The system prompt given to the agent was:")
+print(system_prompt_step.system_prompt)
+
+task_step = agent.memory.steps[0]
+print("\n\nThe first task step was:")
+print(task_step.task)
+
+for step in agent.memory.steps:
+ if isinstance(step, ActionStep):
+ if step.error is not None:
+ print(f"\nStep {step.step_number} got this error:\n{step.error}\n")
+ else:
+ print(f"\nStep {step.step_number} got these observations:\n{step.observations}\n")
+```
+
+Use `agent.memory.get_full_steps()` to get full steps as dictionaries.
+
+You can also use step callbacks to dynamically change the agent's memory.
+
+Step callbacks can access the `agent` itself in their arguments, so they can access any memory step as highlighted above, and change it if needed. For instance, let's say you are observing screenshots of each step performed by a web browser agent. You want to log the newest screenshot, and remove the images from ancient steps to save on token costs.
+
+You culd run something like the following.
+_Note: this code is incomplete, some imports and object definitions have been removed for the sake of concision, visit [the original script](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py) to get the full working code._
+
+```py
+import helium
+from PIL import Image
+from io import BytesIO
+from time import sleep
+
+def update_screenshot(memory_step: ActionStep, agent: CodeAgent) -> None:
+ sleep(1.0) # Let JavaScript animations happen before taking the screenshot
+ driver = helium.get_driver()
+ latest_step = memory_step.step_number
+ for previous_memory_step in agent.memory.steps: # Remove previous screenshots from logs for lean processing
+ if isinstance(previous_memory_step, ActionStep) and previous_memory_step.step_number <= latest_step - 2:
+ previous_memory_step.observations_images = None
+ png_bytes = driver.get_screenshot_as_png()
+ image = Image.open(BytesIO(png_bytes))
+ memory_step.observations_images = [image.copy()]
+```
+
+Then you should pass this function in the `step_callbacks` argument upon initialization of your agent:
+
+```py
+CodeAgent(
+ tools=[DuckDuckGoSearchTool(), go_back, close_popups, search_item_ctrl_f],
+ model=model,
+ additional_authorized_imports=["helium"],
+ step_callbacks=[update_screenshot],
+ max_steps=20,
+ verbosity_level=2,
+)
+```
+
+Head to our [vision web browser code](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py) to see the full working example.
+
+### Run agents one step at a time
+
+This can be useful in case you have tool calls that take days: you can just run your agents step by step.
+This will also let you update the memory on each step.
+
+```py
+from smolagents import HfApiModel, CodeAgent, ActionStep, TaskStep
+
+agent = CodeAgent(tools=[], model=HfApiModel(), verbosity_level=1)
+print(agent.memory.system_prompt)
+
+task = "What is the 20th Fibonacci number?"
+
+# You could modify the memory as needed here by inputting the memory of another agent.
+# agent.memory.steps = previous_agent.memory.steps
+
+# Let's start a new task!
+agent.memory.steps.append(TaskStep(task=task, task_images=[]))
+
+final_answer = None
+step_number = 1
+while final_answer is None and step_number <= 10:
+ memory_step = ActionStep(
+ step_number=step_number,
+ observations_images=[],
+ )
+ # Run one step.
+ final_answer = agent.step(memory_step)
+ agent.memory.steps.append(memory_step)
+ step_number += 1
+
+ # Change the memory as you please!
+ # For instance to update the latest step:
+ # agent.memory.steps[-1] = ...
+
+print("The final answer is:", final_answer)
+```
\ No newline at end of file
diff --git a/docs/source/en/tutorials/secure_code_execution.md b/docs/source/en/tutorials/secure_code_execution.mdx
similarity index 100%
rename from docs/source/en/tutorials/secure_code_execution.md
rename to docs/source/en/tutorials/secure_code_execution.mdx
diff --git a/docs/source/en/tutorials/tools.md b/docs/source/en/tutorials/tools.mdx
similarity index 100%
rename from docs/source/en/tutorials/tools.md
rename to docs/source/en/tutorials/tools.mdx
diff --git a/docs/source/hi/conceptual_guides/intro_agents.md b/docs/source/hi/conceptual_guides/intro_agents.mdx
similarity index 100%
rename from docs/source/hi/conceptual_guides/intro_agents.md
rename to docs/source/hi/conceptual_guides/intro_agents.mdx
diff --git a/docs/source/hi/conceptual_guides/react.md b/docs/source/hi/conceptual_guides/react.mdx
similarity index 91%
rename from docs/source/hi/conceptual_guides/react.md
rename to docs/source/hi/conceptual_guides/react.mdx
index c36f17cfe..0f17901e8 100644
--- a/docs/source/hi/conceptual_guides/react.md
+++ b/docs/source/hi/conceptual_guides/react.mdx
@@ -42,6 +42,3 @@ ReAct प्रक्रिया में पिछले चरणों क
हम दो प्रकार के ToolCallingAgent को लागू करते हैं:
- [`ToolCallingAgent`] अपने आउटपुट में टूल कॉल को JSON के रूप में जनरेट करता है।
- [`CodeAgent`] ToolCallingAgent का एक नया प्रकार है जो अपने टूल कॉल को कोड के ब्लॉब्स के रूप में जनरेट करता है, जो उन LLM के लिए वास्तव में अच्छी तरह काम करता है जिनका कोडिंग प्रदर्शन मजबूत है।
-
-> [!TIP]
-> हम एजेंट्स को वन-शॉट में चलाने का विकल्प भी प्रदान करते हैं: बस एजेंट को लॉन्च करते समय `single_step=True` पास करें, जैसे `agent.run(your_task, single_step=True)`
\ No newline at end of file
diff --git a/docs/source/hi/examples/multiagents.md b/docs/source/hi/examples/multiagents.mdx
similarity index 99%
rename from docs/source/hi/examples/multiagents.md
rename to docs/source/hi/examples/multiagents.mdx
index 33056c8ba..1e9fcc745 100644
--- a/docs/source/hi/examples/multiagents.md
+++ b/docs/source/hi/examples/multiagents.mdx
@@ -119,7 +119,7 @@ print(visit_webpage("https://en.wikipedia.org/wiki/Hugging_Face")[:500])
अब जब हमारे पास सभी टूल्स `search` और `visit_webpage` हैं, हम उनका उपयोग वेब एजेंट बनाने के लिए कर सकते हैं।
इस एजेंट के लिए कौन सा कॉन्फ़िगरेशन चुनें?
-- वेब ब्राउज़िंग एक सिंगल-टाइमलाइन टास्क है जिसे समानांतर टूल कॉल की आवश्यकता नहीं है, इसलिए JSON टूल कॉलिंग इसके लिए अच्छी तरह काम करती है। इसलिए हम `JsonAgent` चुनते हैं।
+- वेब ब्राउज़िंग एक सिंगल-टाइमलाइन टास्क है जिसे समानांतर टूल कॉल की आवश्यकता नहीं है, इसलिए JSON टूल कॉलिंग इसके लिए अच्छी तरह काम करती है। इसलिए हम `ToolCallingAgent` चुनते हैं।
- साथ ही, चूंकि कभी-कभी वेब सर्च में सही उत्तर खोजने से पहले कई पेजों की सर्च करने की आवश्यकता होती है, हम `max_steps` को बढ़ाकर 10 करना पसंद करते हैं।
```py
diff --git a/docs/source/hi/examples/rag.md b/docs/source/hi/examples/rag.mdx
similarity index 100%
rename from docs/source/hi/examples/rag.md
rename to docs/source/hi/examples/rag.mdx
diff --git a/docs/source/hi/examples/text_to_sql.md b/docs/source/hi/examples/text_to_sql.mdx
similarity index 100%
rename from docs/source/hi/examples/text_to_sql.md
rename to docs/source/hi/examples/text_to_sql.mdx
diff --git a/docs/source/hi/guided_tour.md b/docs/source/hi/guided_tour.mdx
similarity index 96%
rename from docs/source/hi/guided_tour.md
rename to docs/source/hi/guided_tour.mdx
index 24cb71d03..745b6643a 100644
--- a/docs/source/hi/guided_tour.md
+++ b/docs/source/hi/guided_tour.mdx
@@ -142,7 +142,7 @@ agent.run("Could you get me the title of the page at url 'https://huggingface.co
रन के बाद क्या हुआ यह जांचने के लिए यहाँ कुछ उपयोगी एट्रिब्यूट्स हैं:
- `agent.logs` एजेंट के फाइन-ग्रेन्ड लॉग्स को स्टोर करता है। एजेंट के रन के हर स्टेप पर, सब कुछ एक डिक्शनरी में स्टोर किया जाता है जो फिर `agent.logs` में जोड़ा जाता है।
-- `agent.write_inner_memory_from_logs()` चलाने से LLM के लिए एजेंट के लॉग्स की एक इनर मेमोरी बनती है, चैट मैसेज की लिस्ट के रूप में। यह मेथड लॉग के प्रत्येक स्टेप पर जाता है और केवल वही स्टोर करता है जिसमें यह एक मैसेज के रूप में रुचि रखता है: उदाहरण के लिए, यह सिस्टम प्रॉम्प्ट और टास्क को अलग-अलग मैसेज के रूप में सेव करेगा, फिर प्रत्येक स्टेप के लिए यह LLM आउटपुट को एक मैसेज के रूप में और टूल कॉल आउटपुट को दूसरे मैसेज के रूप में स्टोर करेगा।
+- `agent.write_memory_to_messages()` चलाने से LLM के लिए एजेंट के लॉग्स की एक इनर मेमोरी बनती है, चैट मैसेज की लिस्ट के रूप में। यह मेथड लॉग के प्रत्येक स्टेप पर जाता है और केवल वही स्टोर करता है जिसमें यह एक मैसेज के रूप में रुचि रखता है: उदाहरण के लिए, यह सिस्टम प्रॉम्प्ट और टास्क को अलग-अलग मैसेज के रूप में सेव करेगा, फिर प्रत्येक स्टेप के लिए यह LLM आउटपुट को एक मैसेज के रूप में और टूल कॉल आउटपुट को दूसरे मैसेज के रूप में स्टोर करेगा।
## टूल्स
@@ -158,7 +158,7 @@ agent.run("Could you get me the title of the page at url 'https://huggingface.co
### डिफ़ॉल्ट टूलबॉक्स
-Transformers एजेंट्स को सशक्त बनाने के लिए एक डिफ़ॉल्ट टूलबॉक्स के साथ आता है, जिसे आप आर्ग्यूमेंट `add_base_tools = True` के साथ अपने एजेंट में इनिशियलाइजेशन पर जोड़ सकते हैं:
+`smolagents` एजेंट्स को सशक्त बनाने के लिए एक डिफ़ॉल्ट टूलबॉक्स के साथ आता है, जिसे आप आर्ग्यूमेंट `add_base_tools = True` के साथ अपने एजेंट में इनिशियलाइजेशन पर जोड़ सकते हैं:
- **DuckDuckGo वेब सर्च**: DuckDuckGo ब्राउज़र का उपयोग करके वेब सर्च करता है।
- **पायथन कोड इंटरप्रेटर**: आपका LLM जनरेटेड पायथन कोड एक सुरक्षित एनवायरनमेंट में चलाता है। यह टूल [`ToolCallingAgent`] में केवल तभी जोड़ा जाएगा जब आप इसे `add_base_tools=True` के साथ इनिशियलाइज़ करते हैं, क्योंकि कोड-बेस्ड एजेंट पहले से ही नेटिव रूप से पायथन कोड एक्जीक्यूट कर सकता है
diff --git a/docs/source/hi/index.md b/docs/source/hi/index.mdx
similarity index 100%
rename from docs/source/hi/index.md
rename to docs/source/hi/index.mdx
diff --git a/docs/source/hi/reference/agents.md b/docs/source/hi/reference/agents.mdx
similarity index 95%
rename from docs/source/hi/reference/agents.md
rename to docs/source/hi/reference/agents.mdx
index 11b461e79..2e070cf03 100644
--- a/docs/source/hi/reference/agents.md
+++ b/docs/source/hi/reference/agents.mdx
@@ -42,10 +42,9 @@ Agents और tools के बारे में अधिक जानने
[[autodoc]] ToolCallingAgent
-
### ManagedAgent
-[[autodoc]] ManagedAgent
+_This class is deprecated since 1.8.0: now you just need to pass name and description attributes to an agent to directly use it as previously done with a ManagedAgent._
### stream_to_gradio
@@ -146,6 +145,7 @@ print(model(messages))
यह क्लास आपको किसी भी OpenAIServer कम्पैटिबल मॉडल को कॉल करने देती है।
यहाँ बताया गया है कि आप इसे कैसे सेट कर सकते हैं (आप दूसरे सर्वर को पॉइंट करने के लिए `api_base` url को कस्टमाइज़ कर सकते हैं):
```py
+import os
from smolagents import OpenAIServerModel
model = OpenAIServerModel(
@@ -153,4 +153,14 @@ model = OpenAIServerModel(
api_base="https://api.openai.com/v1",
api_key=os.environ["OPENAI_API_KEY"],
)
-```
\ No newline at end of file
+```
+
+## Prompts
+
+[[autodoc]] smolagents.agents.PromptTemplates
+
+[[autodoc]] smolagents.agents.PlanningPromptTemplate
+
+[[autodoc]] smolagents.agents.ManagedAgentPromptTemplate
+
+[[autodoc]] smolagents.agents.FinalAnswerPromptTemplate
diff --git a/docs/source/hi/reference/tools.md b/docs/source/hi/reference/tools.mdx
similarity index 97%
rename from docs/source/hi/reference/tools.md
rename to docs/source/hi/reference/tools.mdx
index ddb24d1ab..6c270321e 100644
--- a/docs/source/hi/reference/tools.md
+++ b/docs/source/hi/reference/tools.mdx
@@ -80,12 +80,12 @@ Smolagents एक experimental API है जो किसी भी समय
### AgentText
-[[autodoc]] smolagents.types.AgentText
+[[autodoc]] smolagents.agent_types.AgentText
### AgentImage
-[[autodoc]] smolagents.types.AgentImage
+[[autodoc]] smolagents.agent_types.AgentImage
### AgentAudio
-[[autodoc]] smolagents.types.AgentAudio
+[[autodoc]] smolagents.agent_types.AgentAudio
diff --git a/docs/source/hi/tutorials/building_good_agents.md b/docs/source/hi/tutorials/building_good_agents.mdx
similarity index 99%
rename from docs/source/hi/tutorials/building_good_agents.md
rename to docs/source/hi/tutorials/building_good_agents.mdx
index 86eee273c..92587ef35 100644
--- a/docs/source/hi/tutorials/building_good_agents.md
+++ b/docs/source/hi/tutorials/building_good_agents.mdx
@@ -195,7 +195,7 @@ Final answer:
आइए देखें कि यह कैसे काम करता है। उदाहरण के लिए, आइए [`CodeAgent`] के लिए डिफ़ॉल्ट सिस्टम प्रॉम्प्ट की जाँच करें (नीचे दिया गया वर्जन जीरो-शॉट उदाहरणों को छोड़कर छोटा किया गया है)।
```python
-print(agent.system_prompt_template)
+print(agent.prompt_templates["system_prompt"])
```
Here is what you get:
```text
@@ -244,15 +244,7 @@ Now Begin! If you solve the task correctly, you will receive a reward of $1,000,
फिर आप सिस्टम प्रॉम्प्ट को निम्नानुसार बदल सकते हैं:
```py
-from smolagents.prompts import CODE_SYSTEM_PROMPT
-
-modified_system_prompt = CODE_SYSTEM_PROMPT + "\nHere you go!" # Change the system prompt here
-
-agent = CodeAgent(
- tools=[],
- model=HfApiModel(),
- system_prompt=modified_system_prompt
-)
+agent.prompt_templates["system_prompt"] = agent.prompt_templates["system_prompt"] + "\nHere you go!"
```
This also works with the [`ToolCallingAgent`].
diff --git a/docs/source/hi/tutorials/inspect_runs.md b/docs/source/hi/tutorials/inspect_runs.mdx
similarity index 98%
rename from docs/source/hi/tutorials/inspect_runs.md
rename to docs/source/hi/tutorials/inspect_runs.mdx
index db85fc755..0669c4dcc 100644
--- a/docs/source/hi/tutorials/inspect_runs.md
+++ b/docs/source/hi/tutorials/inspect_runs.mdx
@@ -71,7 +71,6 @@ SmolagentsInstrumentor().instrument(tracer_provider=trace_provider)
from smolagents import (
CodeAgent,
ToolCallingAgent,
- ManagedAgent,
DuckDuckGoSearchTool,
VisitWebpageTool,
HfApiModel,
@@ -79,15 +78,13 @@ from smolagents import (
model = HfApiModel()
-agent = ToolCallingAgent(
+managed_agent = ToolCallingAgent(
tools=[DuckDuckGoSearchTool(), VisitWebpageTool()],
model=model,
-)
-managed_agent = ManagedAgent(
- agent=agent,
name="managed_agent",
description="This is an agent that can do web search.",
)
+
manager_agent = CodeAgent(
tools=[],
model=model,
diff --git a/docs/source/hi/tutorials/secure_code_execution.md b/docs/source/hi/tutorials/secure_code_execution.mdx
similarity index 100%
rename from docs/source/hi/tutorials/secure_code_execution.md
rename to docs/source/hi/tutorials/secure_code_execution.mdx
diff --git a/docs/source/hi/tutorials/tools.md b/docs/source/hi/tutorials/tools.mdx
similarity index 100%
rename from docs/source/hi/tutorials/tools.md
rename to docs/source/hi/tutorials/tools.mdx
diff --git a/docs/source/zh/conceptual_guides/intro_agents.md b/docs/source/zh/conceptual_guides/intro_agents.mdx
similarity index 100%
rename from docs/source/zh/conceptual_guides/intro_agents.md
rename to docs/source/zh/conceptual_guides/intro_agents.mdx
diff --git a/docs/source/zh/conceptual_guides/react.md b/docs/source/zh/conceptual_guides/react.mdx
similarity index 93%
rename from docs/source/zh/conceptual_guides/react.md
rename to docs/source/zh/conceptual_guides/react.mdx
index 24428e03f..cdb970728 100644
--- a/docs/source/zh/conceptual_guides/react.md
+++ b/docs/source/zh/conceptual_guides/react.mdx
@@ -42,6 +42,3 @@ ReAct 过程涉及保留过去步骤的记忆。
我们实现了两个版本的 ToolCallingAgent:
- [`ToolCallingAgent`] 在其输出中生成 JSON 格式的工具调用。
- [`CodeAgent`] 是一种新型的 ToolCallingAgent,它生成代码块形式的工具调用,这对于具有强大编码性能的 LLM 非常有效。
-
-> [!TIP]
-> 我们还提供了一个选项来以单步模式运行 agent:只需在启动 agent 时传递 `single_step=True`,例如 `agent.run(your_task, single_step=True)`
\ No newline at end of file
diff --git a/docs/source/zh/examples/multiagents.md b/docs/source/zh/examples/multiagents.mdx
similarity index 90%
rename from docs/source/zh/examples/multiagents.md
rename to docs/source/zh/examples/multiagents.mdx
index 67eed890e..3b177d133 100644
--- a/docs/source/zh/examples/multiagents.md
+++ b/docs/source/zh/examples/multiagents.mdx
@@ -120,7 +120,7 @@ print(visit_webpage("https://en.wikipedia.org/wiki/Hugging_Face")[:500])
现在我们有了所有工具`search`和`visit_webpage`,我们可以使用它们来创建web agent。
我们该选取什么样的配置来构建这个agent呢?
-- 网页浏览是一个单线程任务,不需要并行工具调用,因此JSON工具调用对于这个任务非常有效。因此我们选择`JsonAgent`。
+- 网页浏览是一个单线程任务,不需要并行工具调用,因此JSON工具调用对于这个任务非常有效。因此我们选择`ToolCallingAgent`。
- 有时候网页搜索需要探索许多页面才能找到正确答案,所以我们更喜欢将 `max_steps` 增加到10。
```py
@@ -139,26 +139,24 @@ web_agent = ToolCallingAgent(
tools=[DuckDuckGoSearchTool(), visit_webpage],
model=model,
max_steps=10,
-)
-```
-
-然后我们将这个agent封装到一个`ManagedAgent`中,使其可以被其管理的agent调用。
-
-```py
-managed_web_agent = ManagedAgent(
- agent=web_agent,
name="search",
description="Runs web searches for you. Give it your query as an argument.",
)
```
-最后,我们创建一个manager agent,在初始化时将我们的managed agent传递给它的`managed_agents`参数。因为这个agent负责计划和思考,所以高级推理将是有益的,因此`CodeAgent`将是最佳选择。此外,我们想要问一个涉及当前年份的问题,并进行额外的数据计算:因此让我们添加`additional_authorized_imports=["time", "numpy", "pandas"]`,以防agent需要这些包。
+请注意,我们为这个代理赋予了 name(名称)和 description(描述)属性,这些是必需属性,以便让管理代理能够调用此代理。
+
+然后,我们创建一个管理代理,在初始化时,将受管代理作为 managed_agents 参数传递给它。
+
+由于这个代理的任务是进行规划和思考,高级推理能力会很有帮助,因此 CodeAgent(代码代理)将是最佳选择。
+
+此外,我们要提出一个涉及当前年份并需要进行额外数据计算的问题:所以让我们添加 additional_authorized_imports=["time", "numpy", "pandas"],以防代理需要用到这些包。
```py
manager_agent = CodeAgent(
tools=[],
model=model,
- managed_agents=[managed_web_agent],
+ managed_agents=[web_agent],
additional_authorized_imports=["time", "numpy", "pandas"],
)
```
diff --git a/docs/source/zh/examples/rag.mdx b/docs/source/zh/examples/rag.mdx
new file mode 100644
index 000000000..23efa9e0e
--- /dev/null
+++ b/docs/source/zh/examples/rag.mdx
@@ -0,0 +1,143 @@
+
+# Agentic RAG
+
+[[open-in-colab]]
+
+Retrieval-Augmented-Generation (RAG) 是“使用大语言模型(LLM)来回答用户查询,但基于从知识库中检索的信息”。它比使用普通或微调的 LLM 具有许多优势:举几个例子,它允许将答案基于真实事实并减少虚构;它允许提供 LLM 领域特定的知识;并允许对知识库中的信息访问进行精细控制。
+
+但是,普通的 RAG 存在一些局限性,以下两点尤为突出:
+
+- 它只执行一次检索步骤:如果结果不好,生成的内容也会不好。
+- 语义相似性是以用户查询为参考计算的,这可能不是最优的:例如,用户查询通常是一个问题,而包含真实答案的文档通常是肯定语态,因此其相似性得分会比其他以疑问形式呈现的源文档低,从而导致错失相关信息的风险。
+
+我们可以通过制作一个 RAG agent来缓解这些问题:非常简单,一个配备了检索工具的agent!这个 agent 将
+会:✅ 自己构建查询和检索,✅ 如果需要的话会重新检索。
+
+因此,它将比普通 RAG 更智能,因为它可以自己构建查询,而不是直接使用用户查询作为参考。这样,它可以更
+接近目标文档,从而提高检索的准确性, [HyDE](https://huggingface.co/papers/2212.10496)。此 agent 可以
+使用生成的片段,并在需要时重新检索,就像 [Self-Query](https://docs.llamaindex.ai/en/stable/examples/evaluation/RetryQuery/)。
+
+我们现在开始构建这个系统. 🛠️
+
+运行以下代码以安装所需的依赖包:
+```bash
+!pip install smolagents pandas langchain langchain-community sentence-transformers rank_bm25 --upgrade -q
+```
+
+你需要一个有效的 token 作为环境变量 `HF_TOKEN` 来调用 HF Inference API。我们使用 python-dotenv 来加载它。
+```py
+from dotenv import load_dotenv
+load_dotenv()
+```
+
+我们首先加载一个知识库以在其上执行 RAG:此数据集是许多 Hugging Face 库的文档页面的汇编,存储为 markdown 格式。我们将仅保留 `transformers` 库的文档。然后通过处理数据集并将其存储到向量数据库中,为检索器准备知识库。我们将使用 [LangChain](https://python.langchain.com/docs/introduction/) 来利用其出色的向量数据库工具。
+```py
+import datasets
+from langchain.docstore.document import Document
+from langchain.text_splitter import RecursiveCharacterTextSplitter
+from langchain_community.retrievers import BM25Retriever
+
+knowledge_base = datasets.load_dataset("m-ric/huggingface_doc", split="train")
+knowledge_base = knowledge_base.filter(lambda row: row["source"].startswith("huggingface/transformers"))
+
+source_docs = [
+ Document(page_content=doc["text"], metadata={"source": doc["source"].split("/")[1]})
+ for doc in knowledge_base
+]
+
+text_splitter = RecursiveCharacterTextSplitter(
+ chunk_size=500,
+ chunk_overlap=50,
+ add_start_index=True,
+ strip_whitespace=True,
+ separators=["\n\n", "\n", ".", " ", ""],
+)
+docs_processed = text_splitter.split_documents(source_docs)
+```
+
+现在文档已准备好。我们来一起构建我们的 agent RAG 系统!
+👉 我们只需要一个 RetrieverTool,我们的 agent 可以利用它从知识库中检索信息。
+
+由于我们需要将 vectordb 添加为工具的属性,我们不能简单地使用带有 `@tool` 装饰器的简单工具构造函数:因此我们将遵循 [tools 教程](../tutorials/tools) 中突出显示的高级设置。
+
+```py
+from smolagents import Tool
+
+class RetrieverTool(Tool):
+ name = "retriever"
+ description = "Uses semantic search to retrieve the parts of transformers documentation that could be most relevant to answer your query."
+ inputs = {
+ "query": {
+ "type": "string",
+ "description": "The query to perform. This should be semantically close to your target documents. Use the affirmative form rather than a question.",
+ }
+ }
+ output_type = "string"
+
+ def __init__(self, docs, **kwargs):
+ super().__init__(**kwargs)
+ self.retriever = BM25Retriever.from_documents(
+ docs, k=10
+ )
+
+ def forward(self, query: str) -> str:
+ assert isinstance(query, str), "Your search query must be a string"
+
+ docs = self.retriever.invoke(
+ query,
+ )
+ return "\nRetrieved documents:\n" + "".join(
+ [
+ f"\n\n===== Document {str(i)} =====\n" + doc.page_content
+ for i, doc in enumerate(docs)
+ ]
+ )
+
+retriever_tool = RetrieverTool(docs_processed)
+```
+BM25 检索方法是一个经典的检索方法,因为它的设置速度非常快。为了提高检索准确性,你可以使用语义搜索,使用文档的向量表示替换 BM25:因此你可以前往 [MTEB Leaderboard](https://huggingface.co/spaces/mteb/leaderboard) 选择一个好的嵌入模型。
+
+现在我们已经创建了一个可以从知识库中检索信息的工具,现在我们可以很容易地创建一个利用这个
+`retriever_tool` 的 agent!此 agent 将使用如下参数初始化:
+- `tools`:代理将能够调用的工具列表。
+- `model`:为代理提供动力的 LLM。
+
+我们的 `model` 必须是一个可调用对象,它接受一个消息的 list 作为输入,并返回文本。它还需要接受一个 stop_sequences 参数,指示何时停止生成。为了方便起见,我们直接使用包中提供的 `HfEngine` 类来获取调用 Hugging Face 的 Inference API 的 LLM 引擎。
+
+接着,我们将使用 [meta-llama/Llama-3.3-70B-Instruct](meta-llama/Llama-3.3-70B-Instruct) 作为 llm 引
+擎,因为:
+- 它有一个长 128k 上下文,这对处理长源文档很有用。
+- 它在 HF 的 Inference API 上始终免费提供!
+
+_Note:_ 此 Inference API 托管基于各种标准的模型,部署的模型可能会在没有事先通知的情况下进行更新或替换。了解更多信息,请点击[这里](https://huggingface.co/docs/api-inference/supported-models)。
+
+```py
+from smolagents import HfApiModel, CodeAgent
+
+agent = CodeAgent(
+ tools=[retriever_tool], model=HfApiModel("meta-llama/Llama-3.3-70B-Instruct"), max_steps=4, verbose=True
+)
+```
+
+当我们初始化 CodeAgent 时,它已经自动获得了一个默认的系统提示,告诉 LLM 引擎按步骤处理并生成工具调用作为代码片段,但你可以根据需要替换此提示模板。接着,当其 `.run()` 方法被调用时,代理将负责调用 LLM 引擎,并在循环中执行工具调用,直到工具 `final_answer` 被调用,而其参数为最终答案。
+
+```py
+agent_output = agent.run("For a transformers model training, which is slower, the forward or the backward pass?")
+
+print("Final output:")
+print(agent_output)
+```
diff --git a/docs/source/zh/examples/text_to_sql.md b/docs/source/zh/examples/text_to_sql.mdx
similarity index 64%
rename from docs/source/zh/examples/text_to_sql.md
rename to docs/source/zh/examples/text_to_sql.mdx
index 12d0c5e47..419c45159 100644
--- a/docs/source/zh/examples/text_to_sql.md
+++ b/docs/source/zh/examples/text_to_sql.mdx
@@ -17,17 +17,17 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-In this tutorial, we’ll see how to implement an agent that leverages SQL using `smolagents`.
+在此教程中,我们将看到如何使用 `smolagents` 实现一个利用 SQL 的 agent。
-> Let's start with the golden question: why not keep it simple and use a standard text-to-SQL pipeline?
+> 让我们从经典问题开始:为什么不简单地使用标准的 text-to-SQL pipeline 呢?
-A standard text-to-sql pipeline is brittle, since the generated SQL query can be incorrect. Even worse, the query could be incorrect, but not raise an error, instead giving some incorrect/useless outputs without raising an alarm.
+标准的 text-to-SQL pipeline 很脆弱,因为生成的 SQL 查询可能会出错。更糟糕的是,查询可能出错却不引发错误警报,从而返回一些不正确或无用的结果。
-👉 Instead, an agent system is able to critically inspect outputs and decide if the query needs to be changed or not, thus giving it a huge performance boost.
+👉 相反,agent 系统则可以检视输出结果并决定查询是否需要被更改,因此带来巨大的性能提升。
-Let’s build this agent! 💪
+让我们来一起构建这个 agent! 💪
-First, we setup the SQL environment:
+首先,我们构建一个 SQL 的环境:
```py
from sqlalchemy import (
create_engine,
@@ -69,11 +69,9 @@ for row in rows:
cursor = connection.execute(stmt)
```
-### Build our agent
+### 构建 agent
-Now let’s make our SQL table retrievable by a tool.
-
-The tool’s description attribute will be embedded in the LLM’s prompt by the agent system: it gives the LLM information about how to use the tool. This is where we want to describe the SQL table.
+现在,我们构建一个 agent,它将使用 SQL 查询来回答问题。工具的 description 属性将被 agent 系统嵌入到 LLM 的提示中:它为 LLM 提供有关如何使用该工具的信息。这正是我们描述 SQL 表的地方。
```py
inspector = inspect(engine)
@@ -91,9 +89,10 @@ Columns:
- tip: FLOAT
```
-Now let’s build our tool. It needs the following: (read [the tool doc](../tutorials/tools) for more detail)
-- A docstring with an `Args:` part listing arguments.
-- Type hints on both inputs and output.
+现在让我们构建我们的工具。它需要以下内容:(更多细节请参阅[工具文档](../tutorials/tools))
+
+- 一个带有 `Args:` 部分列出参数的 docstring。
+- 输入和输出的type hints。
```py
from smolagents import tool
@@ -120,11 +119,9 @@ def sql_engine(query: str) -> str:
return output
```
-Now let us create an agent that leverages this tool.
+我们现在使用这个工具来创建一个 agent。我们使用 `CodeAgent`,这是 smolagent 的主要 agent 类:一个在代码中编写操作并根据 ReAct 框架迭代先前输出的 agent。
-We use the `CodeAgent`, which is smolagents’ main agent class: an agent that writes actions in code and can iterate on previous output according to the ReAct framework.
-
-The model is the LLM that powers the agent system. HfApiModel allows you to call LLMs using HF’s Inference API, either via Serverless or Dedicated endpoint, but you could also use any proprietary API.
+这个模型是驱动 agent 系统的 LLM。`HfApiModel` 允许你使用 HF Inference API 调用 LLM,无论是通过 Serverless 还是 Dedicated endpoint,但你也可以使用任何专有 API。
```py
from smolagents import CodeAgent, HfApiModel
@@ -136,11 +133,9 @@ agent = CodeAgent(
agent.run("Can you give me the name of the client who got the most expensive receipt?")
```
-### Level 2: Table joins
-
-Now let’s make it more challenging! We want our agent to handle joins across multiple tables.
+### Level 2: 表连接
-So let’s make a second table recording the names of waiters for each receipt_id!
+现在让我们增加一些挑战!我们希望我们的 agent 能够处理跨多个表的连接。因此,我们创建一个新表,记录每个 receipt_id 的服务员名字!
```py
table_name = "waiters"
@@ -163,7 +158,8 @@ for row in rows:
with engine.begin() as connection:
cursor = connection.execute(stmt)
```
-Since we changed the table, we update the `SQLExecutorTool` with this table’s description to let the LLM properly leverage information from this table.
+
+因为我们改变了表,我们需要更新 `SQLExecutorTool`,让 LLM 能够正确利用这个表的信息。
```py
updated_description = """Allows you to perform SQL queries on the table. Beware that this tool's output is a string representation of the execution output.
@@ -180,7 +176,8 @@ for table in ["receipts", "waiters"]:
print(updated_description)
```
-Since this request is a bit harder than the previous one, we’ll switch the LLM engine to use the more powerful [Qwen/Qwen2.5-Coder-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct)!
+
+因为这个request 比之前的要难一些,我们将 LLM 引擎切换到更强大的 [Qwen/Qwen2.5-Coder-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct)!
```py
sql_engine.description = updated_description
@@ -192,11 +189,13 @@ agent = CodeAgent(
agent.run("Which waiter got more total money from tips?")
```
-It directly works! The setup was surprisingly simple, wasn’t it?
-This example is done! We've touched upon these concepts:
-- Building new tools.
-- Updating a tool's description.
-- Switching to a stronger LLM helps agent reasoning.
+它直接就能工作!设置过程非常简单,难道不是吗?
+
+这个例子到此结束!我们涵盖了这些概念:
+
+- 构建新工具。
+- 更新工具的描述。
+- 切换到更强大的 LLM 有助于 agent 推理。
-✅ Now you can go build this text-to-SQL system you’ve always dreamt of! ✨
\ No newline at end of file
+✅ 现在你可以构建你一直梦寐以求的 text-to-SQL 系统了!✨
diff --git a/docs/source/zh/guided_tour.md b/docs/source/zh/guided_tour.mdx
similarity index 97%
rename from docs/source/zh/guided_tour.md
rename to docs/source/zh/guided_tour.mdx
index 537e5948e..54ae10419 100644
--- a/docs/source/zh/guided_tour.md
+++ b/docs/source/zh/guided_tour.mdx
@@ -152,7 +152,7 @@ agent.run("Could you get me the title of the page at url 'https://huggingface.co
以下是一些有用的属性,用于检查运行后发生了什么:
- `agent.logs` 存储 agent 的细粒度日志。在 agent 运行的每一步,所有内容都会存储在一个字典中,然后附加到 `agent.logs` 中。
-- 运行 `agent.write_inner_memory_from_logs()` 会为 LLM 创建一个 agent 日志的内部内存,作为聊天消息列表。此方法会遍历日志的每一步,并仅存储它感兴趣的内容作为消息:例如,它会将系统提示和任务存储为单独的消息,然后对于每一步,它会将 LLM 输出存储为一条消息,工具调用输出存储为另一条消息。如果您想要更高级别的视图 - 但不是每个日志都会被此方法转录。
+- 运行 `agent.write_memory_to_messages()` 会为 LLM 创建一个 agent 日志的内部内存,作为聊天消息列表。此方法会遍历日志的每一步,并仅存储它感兴趣的内容作为消息:例如,它会将系统提示和任务存储为单独的消息,然后对于每一步,它会将 LLM 输出存储为一条消息,工具调用输出存储为另一条消息。如果您想要更高级别的视图 - 但不是每个日志都会被此方法转录。
## 工具
@@ -168,7 +168,7 @@ agent.run("Could you get me the title of the page at url 'https://huggingface.co
### 默认工具箱
-Transformers 附带了一个用于增强 agent 的默认工具箱,您可以在初始化时通过参数 `add_base_tools = True` 将其添加到您的 agent 中:
+`smolagents` 附带了一个用于增强 agent 的默认工具箱,您可以在初始化时通过参数 `add_base_tools = True` 将其添加到您的 agent 中:
- **DuckDuckGo 网页搜索**:使用 DuckDuckGo 浏览器执行网页搜索。
- **Python 代码解释器**:在安全环境中运行 LLM 生成的 Python 代码。只有在使用 `add_base_tools=True` 初始化 [`ToolCallingAgent`] 时才会添加此工具,因为基于代码的 agent 已经可以原生执行 Python 代码
diff --git a/docs/source/zh/index.md b/docs/source/zh/index.mdx
similarity index 100%
rename from docs/source/zh/index.md
rename to docs/source/zh/index.mdx
diff --git a/docs/source/zh/reference/agents.md b/docs/source/zh/reference/agents.md
deleted file mode 100644
index 3b05a6d28..000000000
--- a/docs/source/zh/reference/agents.md
+++ /dev/null
@@ -1,149 +0,0 @@
-
-# Agents
-
-| \n", - " | question | \n", - "source | \n", - "true_answer | \n", - "true_reasoning | \n", - "
|---|---|---|---|---|
| 0 | \n", - "If Eliud Kipchoge could maintain his record-ma... | \n", - "GAIA | \n", - "17 | \n", - "None | \n", - "
| 1 | \n", - "How many studio albums were published by Merce... | \n", - "GAIA | \n", - "3 | \n", - "None | \n", - "
| 2 | \n", - "Here's a fun riddle that I think you'll enjoy.... | \n", - "GAIA | \n", - "3 | \n", - "None | \n", - "
| 3 | \n", - "My family reunion is this week, and I was assi... | \n", - "GAIA | \n", - "2 | \n", - "None | \n", - "
| 4 | \n", - "In Emily Midkiff's June 2014 article in a jour... | \n", - "GAIA | \n", - "fluffy | \n", - "None | \n", - "
| ... | \n", - "... | \n", - "... | \n", - "... | \n", - "... | \n", - "
| 127 | \n", - "What year was the municipality of San Carlos, ... | \n", - "SimpleQA | \n", - "1786 | \n", - "['https://en.wikipedia.org/wiki/San_Carlos,_An... | \n", - "
| 128 | \n", - "In which year was Maria Elena Walsh named Illu... | \n", - "SimpleQA | \n", - "1985 | \n", - "['https://en.wikipedia.org/wiki/Mar%C3%ADa_Ele... | \n", - "
| 129 | \n", - "What is the durability of the Istarelle spear ... | \n", - "SimpleQA | \n", - "800 | \n", - "['http://demonssouls.wikidot.com/spear', 'http... | \n", - "
| 130 | \n", - "What is the number of the executive order that... | \n", - "SimpleQA | \n", - "7034 | \n", - "['https://www.loc.gov/collections/federal-thea... | \n", - "
| 131 | \n", - "Within plus or minus one minute, when was Marq... | \n", - "SimpleQA | \n", - "77 | \n", - "['https://www.fifa.com/fifaplus/en/match-centr... | \n", - "
132 rows × 4 columns
\n", - "| \n", + " | question | \n", + "source | \n", + "true_answer | \n", + "true_reasoning | \n", + "
|---|---|---|---|---|
| 0 | \n", + "What year was the municipality of Ramiriquí, B... | \n", + "SimpleQA | \n", + "1541 | \n", + "['https://en.wikipedia.org/wiki/Ramiriqu%C3%AD... | \n", + "
| 1 | \n", + "In what year did Hjalmar Hvam invent a mechani... | \n", + "SimpleQA | \n", + "1937 | \n", + "['https://www.kgw.com/article/features/portlan... | \n", + "
| 2 | \n", + "In which year did Fayaz A. Malik (an Indian ph... | \n", + "SimpleQA | \n", + "2009 | \n", + "['https://en.wikipedia.org/wiki/Fayaz_A._Malik... | \n", + "
| 3 | \n", + "In which year was John B. Goodenough elected a... | \n", + "SimpleQA | \n", + "2010 | \n", + "['https://en.wikipedia.org/wiki/John_B._Gooden... | \n", + "
| 4 | \n", + "In which year did Atul Gawande earn an M.A. in... | \n", + "SimpleQA | \n", + "1989 | \n", + "['https://en.wikipedia.org/wiki/Atul_Gawande',... | \n", + "
| \n", + " | model_id | \n", + "agent_action_type | \n", + "source | \n", + "acc | \n", + "
|---|---|---|---|---|
| 0 | \n", + "Qwen/Qwen2.5-72B-Instruct | \n", + "code | \n", + "GAIA | \n", + "28.12 | \n", + "
| 1 | \n", + "Qwen/Qwen2.5-72B-Instruct | \n", + "code | \n", + "MATH | \n", + "76.00 | \n", + "
| 2 | \n", + "Qwen/Qwen2.5-72B-Instruct | \n", + "code | \n", + "SimpleQA | \n", + "88.00 | \n", + "
| 3 | \n", + "Qwen/Qwen2.5-72B-Instruct | \n", + "vanilla | \n", + "GAIA | \n", + "6.25 | \n", + "
| 4 | \n", + "Qwen/Qwen2.5-72B-Instruct | \n", + "vanilla | \n", + "MATH | \n", + "30.00 | \n", + "
| \n", + " | is_correct | \n", + "
|---|---|
| agent_name | \n", + "\n", + " |
| code_gpt4o_03_february_goodoldtext-unbroken | \n", + "0.384 | \n", + "
| code_gpt4o_03_february_magenticbrowser | \n", + "0.352 | \n", + "
| code_gpt4o_03_february_magenticbrowser2 | \n", + "0.365 | \n", + "
| code_gpt4o_03_february_text | \n", + "0.376 | \n", + "
| code_llama-3 | \n", + "0.078 | \n", + "
| code_o1_01_february_text | \n", + "0.491 | \n", + "
| code_o1_03_february_ablation-toolcalling-manager | \n", + "0.327 | \n", + "
| code_o1_03_february_fix-print-outputs | \n", + "0.518 | \n", + "
| code_o1_03_february_fix-print-outputs2 | \n", + "0.558 | \n", + "
| code_o1_03_february_goodoldtext-unbroken | \n", + "0.534 | \n", + "
| code_o1_03_february_remove-navigational | \n", + "0.537 | \n", + "
| code_o1_03_february_text_high-reasoning-effort | \n", + "0.485 | \n", + "
| code_o1_04_february_submission | \n", + "0.494 | \n", + "
| code_o1_04_february_submission-medium | \n", + "0.488 | \n", + "
| code_o1_04_february_submission3 | \n", + "0.490 | \n", + "
| code_o1_04_february_submission4 | \n", + "0.500 | \n", + "
| code_o1_04_february_submission5 | \n", + "0.552 | \n", + "
| code_o1_22-01_managedagent-summary_planning | \n", + "0.418 | \n", + "
| code_o1_25-01_visioon | \n", + "0.340 | \n", + "
| code_o1_29-01_text | \n", + "0.390 | \n", + "
| code_o3-mini_03_february_remove-navigational | \n", + "0.291 | \n", + "
| code_qwen-coder-32B_03_february_text | \n", + "0.209 | \n", + "
| \n", + " | \n", + " | is_correct | \n", + "is_near_correct | \n", + "count_steps | \n", + "count | \n", + "
|---|---|---|---|---|---|
| agent_name | \n", + "task | \n", + "\n", + " | \n", + " | \n", + " | \n", + " |
| code_gpt4o_03_february_goodoldtext-unbroken | \n", + "1 | \n", + "0.452830 | \n", + "0.452830 | \n", + "7.000000 | \n", + "53 | \n", + "
| 2 | \n", + "0.380952 | \n", + "0.392857 | \n", + "8.511905 | \n", + "84 | \n", + "|
| 3 | \n", + "0.227273 | \n", + "0.227273 | \n", + "10.409091 | \n", + "22 | \n", + "|
| code_gpt4o_03_february_magenticbrowser | \n", + "1 | \n", + "0.480769 | \n", + "0.480769 | \n", + "7.153846 | \n", + "52 | \n", + "
| 2 | \n", + "0.349398 | \n", + "0.361446 | \n", + "8.168675 | \n", + "83 | \n", + "|
| ... | \n", + "... | \n", + "... | \n", + "... | \n", + "... | \n", + "... | \n", + "
| code_o3-mini_03_february_remove-navigational | \n", + "2 | \n", + "0.232558 | \n", + "0.244186 | \n", + "4.976744 | \n", + "86 | \n", + "
| 3 | \n", + "0.153846 | \n", + "0.153846 | \n", + "6.615385 | \n", + "26 | \n", + "|
| code_qwen-coder-32B_03_february_text | \n", + "1 | \n", + "0.357143 | \n", + "0.357143 | \n", + "5.428571 | \n", + "14 | \n", + "
| 2 | \n", + "0.136364 | \n", + "0.136364 | \n", + "6.409091 | \n", + "22 | \n", + "|
| 3 | \n", + "0.142857 | \n", + "0.142857 | \n", + "6.571429 | \n", + "7 | \n", + "
65 rows × 4 columns
\n", + "| \n", + " | is_correct | \n", + "count_steps | \n", + "question | \n", + "
|---|---|---|---|
| attachment_type | \n", + "\n", + " | \n", + " | \n", + " |
| None | \n", + "0.423799 | \n", + "4.959725 | \n", + "2185 | \n", + "
| csv | \n", + "0.000000 | \n", + "7.750000 | \n", + "16 | \n", + "
| docx | \n", + "0.571429 | \n", + "4.904762 | \n", + "21 | \n", + "
| jpg | \n", + "0.142857 | \n", + "5.750000 | \n", + "28 | \n", + "
| jsonld | \n", + "0.000000 | \n", + "6.600000 | \n", + "15 | \n", + "
| mp3 | \n", + "0.480000 | \n", + "4.500000 | \n", + "50 | \n", + "
| pdb | \n", + "0.000000 | \n", + "4.444444 | \n", + "18 | \n", + "
| 0.588235 | \n", + "4.137255 | \n", + "51 | \n", + "|
| png | \n", + "0.216783 | \n", + "4.412587 | \n", + "143 | \n", + "
| pptx | \n", + "0.882353 | \n", + "4.058824 | \n", + "17 | \n", + "
| py | \n", + "1.000000 | \n", + "4.266667 | \n", + "15 | \n", + "
| txt | \n", + "0.705882 | \n", + "4.764706 | \n", + "17 | \n", + "
| xlsx | \n", + "0.612745 | \n", + "4.823529 | \n", + "204 | \n", + "
| zip | \n", + "0.448276 | \n", + "5.344828 | \n", + "29 | \n", + "
| " + html.escape(cell.text) + " | " + else: + html_table += "" + html.escape(cell.text) + " | " + html_table += "
|---|