-
Notifications
You must be signed in to change notification settings - Fork 25
Expand file tree
/
Copy path06-week.Rmd
More file actions
984 lines (699 loc) · 43.7 KB
/
06-week.Rmd
File metadata and controls
984 lines (699 loc) · 43.7 KB
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
900
901
902
903
904
905
906
907
908
909
910
911
912
913
914
915
916
917
918
919
920
921
922
923
924
925
926
927
928
929
930
931
932
933
934
935
936
937
938
939
940
941
942
943
944
945
946
947
948
949
950
951
952
953
954
955
956
957
958
959
960
961
962
963
964
965
966
967
968
969
970
971
972
973
974
975
976
977
978
979
980
981
982
983
984
---
pagetitle: "Week 6 - Getting data"
---
# Week 6
## Week 6 Learning objectives
:::keyidea
At the end of this lesson you will be able to:
* Define a tidy data set
* Name the parts of a shareable data set
* Download data from multiple sources
* Import data from multiple sources
:::
*This lecture includes material from Stephanie Hicks [lecture](https://jhu-advdatasci.github.io/2019/lectures/04-gettingdata-api.html) on getting data*
## What you wish data looked like
The first step in almost every data practical data science project is to collect the data that you will need to perform your analysis, clean the data, and explore the key characteristics of the data set. It has been said in many different ways that 80% of data science is data cleaning - and the other 20% is spent complaining about it...
<blockquote class="twitter-tweet"><p lang="en" dir="ltr">In Data Science, 80% of time spent prepare data, 20% of time spent complain about need for prepare data.</p>— Big Data Borat (@BigDataBorat) <a href="https://twitter.com/BigDataBorat/status/306596352991830016?ref_src=twsrc%5Etfw">February 27, 2013</a></blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
This is unfortunately a truism that hasn't changed too much despite the best efforts to develop a set of tools that make it easier than ever to collect, manipulate, clean, and explore data.
One important reason is that data collection is often done without data analysis in mind. For example, electronic health record data may be initially collected for the purpose of billing, rather than research. Social media data may be collected to allow communication, but will not be structured for analysis.
This means that a fair amount of work will be transforming data from whatever format you find it in the wild into data that you can use to do analysis. Depending on the type of software you use, you will ultimately need to format the data in different ways.
However, there has been a major effort to standardize a lot of statistical analysis software - particularly in the R programming language - around the idea of "tidy data". [Tidy data](https://vita.had.co.nz/papers/tidy-data.pdf) was originally defined by Hadley Wickham in a now classic paper. According to Wickham, data is "tidy" if it has the following properties:
1. Each variable forms a column.
2. Each observation forms a row.
3. Each type of observational unit forms a table.
If you have multiple tables, an additional assumption of tidy data that we often use is that:
4. Each table contains a set of unique ids that allow observations to be linked
This formalism is extremely useful for a wide range of data types and thanks to significant investment by Rstudio and their extended network, there are now a large number of tools - called the [tidyverse](https://www.tidyverse.org/) - that either facilitate the creation of tidy data or accept tidy data as a default input format.
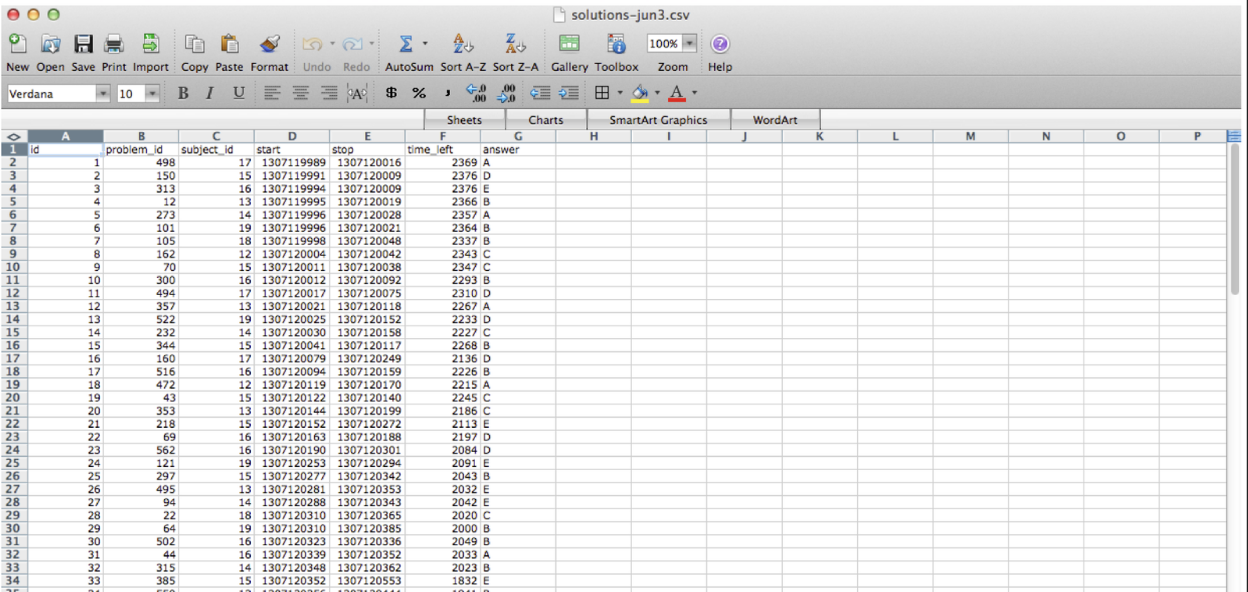
This is often how you wish data would be formatted. But not always! For example, genomic data is often best analyzed using the [Bioconductor](https://www.bioconductor.org/) suite of software that [often assumes](https://www.nature.com/articles/nmeth.3252) three (not-tidy by the above definition) data sets:
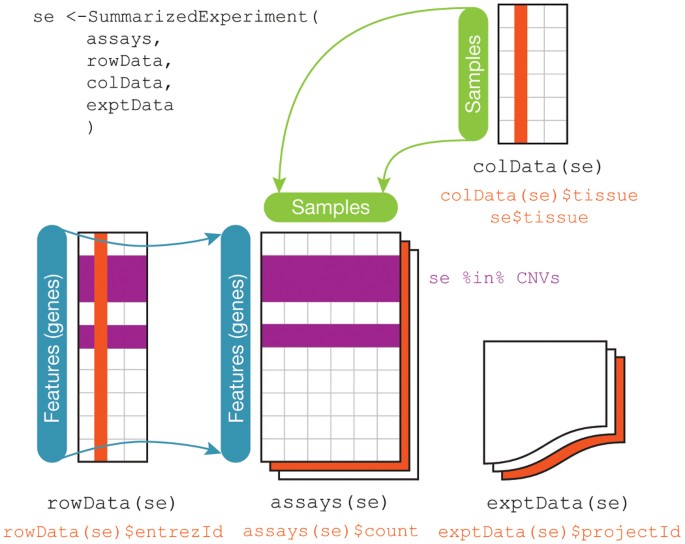
Regardless, the first steps in any data science project after the question and audience have been settled are usually around collecting, reformatting, and exploring data. These steps are hyper critical to the success of a data analysis and - much to the chagrin of statisticians - are often [very influential on the ultimate results of a data analysis](https://www.nature.com/articles/s41598-020-59516-z). So it usually makes sense to consider several alternative processing approaches particularly when dealing with complicated or sensitive data collection technolgoies.
## What it actually looks like
So what does data actually look like? As Wickham points out in his Tidy Data paper:
> tidy datasets are all alike but every messy dataset is messy in its own way.
It would take entire courses to cover all the ways messy data exists in the wild and the massive number of tools that have been developed to manipulate these data. Here we will simply give an overview of some of the most widely used/common denominator tools. However, your mileage will vary considerably depending on the field you work in.
The most common type of "messy" data that you will encounter, nearly independent of which field you choose to work in, are data in spreadsheets. These are nearly infinite in how ugly they can get.
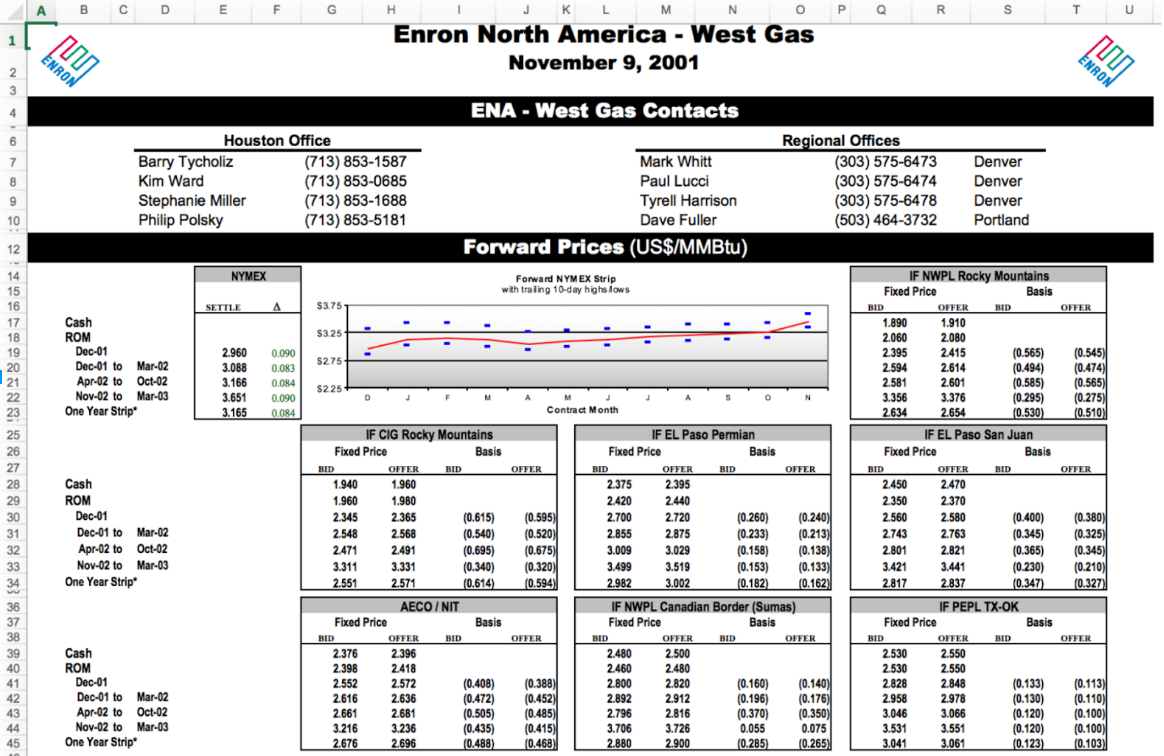
You may also encounter free text files, sometimes called "flat" files, in a variety of formats. For example a health record may be stored as a plain text file (or in one of several proprietary formats):
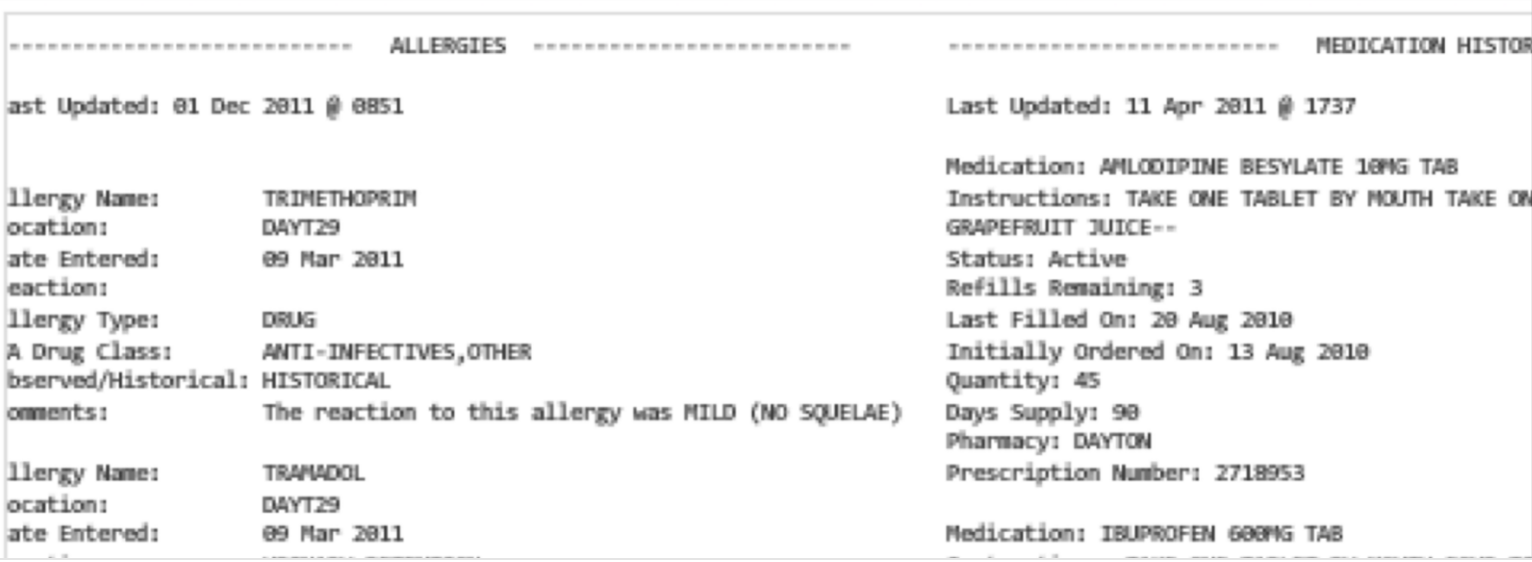
Increasingly, data from the web is stored in [JSON](https://en.wikipedia.org/wiki/JSON) format. If you collect data directly from application programming interfaces, this is almost certainly how your data will arrive.
Finally, if you work in a subfield with specialized measurement tools you will encounter raw data in a variety of very specific formats. For example, much of the data from high-throughput short-read sequencing appears in the FASTQ format, which may be a 3 gigabyte or more flat or zipped file formatted in a very specific way to report short "reads" and their quality from the genome.

Unfortunately, unless you have your own experimental research lab, start your own company, or lead the data team for your organization, you will be stuck with the raw data that arrives. This can be *extremely* frustrating, but it is important to get good at managing data that is realistically complex if you want to be a practicing data scientist. If you need to vent, you can always check out the hashtag [#otherpeoplesdata](https://twitter.com/search?q=%23otherpeoplesdata&src=typed_query) on Twitter for commiseration and humor.
<blockquote class="twitter-tweet"><p lang="en" dir="ltr">*squints at the files I was sent* <a href="https://twitter.com/hashtag/otherpeoplesdata?src=hash&ref_src=twsrc%5Etfw">#otherpeoplesdata</a> <a href="https://t.co/cB3PC6Y0Yk">pic.twitter.com/cB3PC6Y0Yk</a></p>— Dave Hemprich-Bennett (@hammerheadbat) <a href="https://twitter.com/hammerheadbat/status/929348291229253634?ref_src=twsrc%5Etfw">November 11, 2017</a></blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
## Background on getting data
Regardless of how the data is formatted, the first step in your data analysis will be to collect the data, organize it, read it into R and format it so that you can perform your analysis. We are going to cover some of the most common ways of getting data here, and this will necessarily be pretty R specific, but this is the step that is most likely to be field specific so you may need to follow tutorials within your field. A good place to start is always "file format extension rstats package" on Google.
### Where do data live?
Data lives anywhere and everywhere. Data
might be stored simply in a `.csv` or `.txt`
file. Data might be stored in an Excel or
Google Spreadsheet. Data might be stored in
large databases that require users to write
special functions to interact with to extract
the data they are interested in.
For example, you may have heard of the terms
`mySQL` or `MongoDB`.
From [Wikipedia, MySQL](https://en.wikipedia.org/wiki/MySQL)
is defined as _an open-source relational database management system (RDBMS). Its name is a combination of "My", the name of co-founder Michael Widenius's daughter,[7] and "SQL", the abbreviation for Structured Query Language._.
From [Wikipeda, MongoDB](https://en.wikipedia.org/wiki/MongoDB)
is defined as _"a free and open-source cross-platform document-oriented database program. Classified as a NoSQL database program, MongoDB uses JSON-like documents with schemata."_
So after reading that, we get the sense that there
are multiple ways large databases can be structured,
data can be formatted and interacted with.
In addition, we see that database programs
(e.g. MySQL and MongoDB) can also interact
with each other.
```{r, echo=FALSE}
knitr::include_graphics("https://github.com/jtleek/advdatasci/raw/master/imgs/databases.png")
```
We will learn more about `SQL` and `JSON` in a bit.
### Best practices on sharing data
When you are getting data, you should be thinking about how you will organize it, both for your self and for sharing with others. We wrote a paper called: [_How to share data for collaboration_](https://peerj.com/preprints/3139v5.pdf) where we provide some guidelines for sharing data:
> We highlight the need to provide raw data to the statistician, the importance of consistent formatting, and the necessity of including all essential experimental information and pre-processing steps carried out to the statistician. With these guidelines we hope to avoid errors and delays in data analysis. the importance of consistent formatting, and the necessity of including all essential experimental information and pre-processing steps carried out to the statistician.
```{r, echo=FALSE}
knitr::include_graphics("https://github.com/jtleek/advdatasci/raw/master/imgs/ellis-datashare.png")
```
The easiest data analyses start with data shared in this format and you will make a lot of friends among your collaborators if you organize data collect in this way. Specifically:
1. The raw data (or the rawest form of the data to which you have access)
* Should not have modified, removed or summarized any data; Ran no software on data
* e.g. strange binary file your measurement machine spits out
* e.g. complicated JSON file you scrapped from Twitter Application Programming Interfaces (API)
* e.g. hand-entered numbers you collected looking through a microscope
2. A clean data set
* This may or may not be transforming data into a `tidy` dataset, but possibly yes
3. A code book describing each variable and its values in the clean or tidy data set.
* More detailed information about the measurements in the data set (e.g. units, experimental design, summary choices made)
* Doesn't quite fit into the column names in the spreadsheet
* Often reported in a `.md`, `.txt` or Word file.
```{r, echo=FALSE}
knitr::include_graphics("https://github.com/jtleek/advdatasci/raw/master/imgs/code-book.png")
```
4. An explicit and exact recipe you used to go from 1 -> 2,3
```{r, echo=FALSE}
knitr::include_graphics("https://github.com/jtleek/advdatasci/raw/master/imgs/recipe-best.png")
```
## Relative versus absolute paths
When you are starting a data analysis, you have
already learned about the use of `.Rproj` files.
When you open up a `.Rproj` file, RStudio changes
the path (location on your computer) to the `.Rproj`
location.
After opening up a `.Rproj` file, you can test this
by
```{r, eval=FALSE}
getwd()
```
When you open up someone else's R code or analysis,
you might also see the `setwd()` function being used
which explicitly tells R to change the absolute path
or absolute location of which directory to move into.
For example, say I want to clone a GitHub repo from
Roger, which has 100 R script files, and in every
one of those files at the top is:
```{r, eval=FALSE}
setwd("C:\Users\Roger\path\only\that\Roger\has")
```
The problem is, if I want to use his code, I will
need to go and hand-edit every single one of those
paths (`C:\Users\Roger\path\only\that\Roger\has`)
to the path that I want to use on my computer
or wherever I saved the folder on my computer (e.g.
`/Users/Stephanie/Documents/path/only/I/have`).
1. This is an unsustainable practice.
2. I can go in and manually edit the path, but this
assumes I know how to set a working directory. Not
everyone does.
So instead of absolute paths:
```{r, eval=FALSE}
setwd("/Users/jtleek/data")
setwd("~/Desktop/files/data")
setwd("C:\\Users\\Andrew\\Downloads")
```
A better idea is to use relative paths:
```{r, eval=FALSE}
setwd("../data")
setwd("../files")
setwd("..\tmp")
```
Within R, an even better idea is to use the
[here](https://github.com/r-lib/here)
R package will recognize the top-level directory
of a Git repo and supports building all paths
relative to that. For more on project-oriented
workflow suggestions, read
[this post](https://www.tidyverse.org/articles/2017/12/workflow-vs-script/)
from Jenny Bryan.
### The `here` package
In her post, she writes
> "I suggest organizing each data analysis into a project: a folder on your computer that holds all the files relevant to that particular piece of work."
Instead of using `setwd()` at the top your `.R` or `.Rmd` file, she suggests:
* Organize each logical project into a folder on your computer.
* Make sure the top-level folder advertises itself as such. This can be as simple as having an empty file named `.here`. Or, if you use RStudio and/or Git, those both leave characteristic files behind that will get the job done.
* Use the `here()` function from the `here` package to build the path when you read or write a file. Create paths relative to the top-level directory.
* Whenever you work on this project, launch the R process from the project’s top-level directory. If you launch R from the shell, `cd` to the correct folder first.
Let's test this out. We can use `getwd()` to see our current
working directory path and the files available using `list.file()`
```{r}
getwd()
list.files()
```
OK so our current location is in the `/cloud/project` directory. Using the here package we can see that here points to this base directory.
```{r}
library(here)
here()
list.files(here::here())
```
We can now create a `data` folder if it doesn't already exist and see how to create a link to the data directory using the here package:
```{r}
if(!file.exists("data")){dir.create("data")}
list.files(here("data"))
```
Now we see that using the `here::here()` function is a
_relative_ path (relative to the `.Rproj` file in our home directory. We also see there is a `cameras.csv` file in
the `data` folder. Let's read it into R with the `readr` package.
```{r}
df <- readr::read_csv(here("data", "cameras.csv"))
df
```
We can also ask for the full paths for specific files
```{r}
here("data", "cameras.csv")
```
The nice thing about the `here` package is that the above code creates the "correct" path relative to the home directory, regardless of whether the folder is on your computer or not.
### Finding and creating files locally
If you want to download a file, one way to use the
`file.exists()`, `dir.create()` and `list.files()`
functions.
* `file.exists(here("my", "relative", "path"))` = logical test if the file exists
* `dir.create(here("my", "relative", "path"))` = create a folder
* `list.files(here("my", "relative", "path"))` = list contents of folder
```{r, eval=FALSE}
if(!file.exists(here("my", "relative", "path"))){
dir.create(here("my", "relative", "path"))
}
list.files(here("my", "relative", "path"))
```
### Downloading files
Let's say we wanted to find out where are
all the Fixed Speed Cameras in Baltimore?
To do this, we can use the
[Open Baltimore](https://data.baltimorecity.gov)
API which has information on
[the locations](https://data.baltimorecity.gov/Transportation/Baltimore-Fixed-Speed-Cameras/dz54-2aru) of fixed speed cameras
in Baltimore.
In case you aren't familiar with
fixed speed cameras, the website states:
> Motorists who drive aggressively and exceed the posted speed limit by at least 12 miles per hour will receive $40 citations in the mail. These citations are not reported to insurance companies and no license points are assigned. Notification signs will be placed at all speed enforcement locations so that motorists will be aware that they are approaching a speed check zone. The goal of the program is to make the streets of Baltimore safer for everyone by changing aggressive driving behavior. In addition to the eight portable speed enforcement units, the city has retrofitted 50 red light camera locations with the automated speed enforcement technology.
When we go to the website, we see that
the data can be provided to us as a
`.csv` file. To download in this data,
we can do the following:
```{r, eval=FALSE}
file_url <- paste0("https://data.baltimorecity.gov/api/",
"views/dz54-2aru/rows.csv?accessType=DOWNLOAD")
download.file(file_url,
destfile=here("data", "cameras.csv"))
list.files(here("data"))
```
Alternatively, if we want to only download
the file once each time we knit our reproducible
report or homework or project, we can us wrap
the code above into a `!file.exists()` function.
```{r}
filename = paste0(Sys.Date(),"-cameras.csv")
if(!file.exists(here("data", filename))){
file_url <- paste0("https://data.baltimorecity.gov/api/",
"views/dz54-2aru/rows.csv?accessType=DOWNLOAD")
todays_date = Sys.Date()
download.file(file_url,
destfile=here("data",filename))
}
date_downloaded = Sys.Date()
date_downloaded
list.files(here("data"))
```
Here you will notice I also named the file with the date and/or saved another variable with the downloaded date. The reason is that if you are downloading data directly from the internet, it is likely to update and your results may change. It is a good idea to keep track of the data each time you download.
:::keyidea
Always remember to save the date when you download a file from the internet - usually by naming the file with the date. This can prevent reproducibility errors later if the data are updated between when you collect the data and when you
:::
## Reading files
Once you have downloaded a file from the internet the next step is reading the data in so you can explore it. In R there are a number of packages that have been developed for most common data types. We will go over a few of them here.
### Reading in CSV files
The easiest type of files to read in R are delimited files (for example comma separated values, csv; or tab separated values, tsv). The cameras file we downloaded is an example of a comma separated file.
We can read `cameras.csv`
like we have already learned how to do using the
`readr::read_csv()` function:
```{r}
cameras <- readr::read_csv(here("data", "cameras.csv"))
cameras
```
A couple of important things to check for with these type of "flat" files are:
1. What are the indicators of NA - is it NA? NULL? a space? 99999 (gasp!)?
2. Are there any ill-formatted fields, where a whole row accidentally gets read into one cell?
3. For text fields, are there any strings that should be factors (or vice-versa)?
### Reading in Excel files
In an ideal world everyone would read the outstanding paper on [Data Organization in Spreadsheets](https://www.tandfonline.com/doi/full/10.1080/00031305.2017.1375989) by Broman and Woo - or at the least their abstract where they lay out the most important formatting rules!
> The basic principles are: be consistent, write dates like YYYY-MM-DD, do not leave any cells empty, put just one thing in a cell, organize the data as a single rectangle (with subjects as rows and variables as columns, and with a single header row), create a data dictionary, do not include calculations in the raw data files, do not use font color or highlighting as data, choose good names for things, make backups, use data validation to avoid data entry errors, and save the data in plain text files.
Unfortunately this is rarely the case and spreadsheets are deceptively difficult to import into R when they have formulae, colored fields, hidden sheets and other things. We can download the cameras data in Excel format and read it with the `readxl` package:
```{r}
library(readxl)
sheets = readxl::excel_sheets(here::here("data","2020-10-05-cameras.xlsx"))
sheets
cameras <- readxl::read_excel(here::here("data","2020-10-05-cameras.xlsx"),sheet=sheets[1])
cameras
```
However, in practice you might need to look out for:
1. Values that are colored - you may need to use something like [tidyxl](https://cran.r-project.org/web/packages/tidyxl/vignettes/tidyxl.html)
2. Values that appear in only a subset of the spreadsheet - you will need to set sell ranges
3. Hidden sheets - you will want to use the [excel_sheets](https://readxl.tidyverse.org/reference/excel_sheets.html) function to check for sheet names before you read.
4. Formulae - you may need to use tidyxl to discover what they are
5. Hidden/calculated values - you may again need to use tidyxl
In practice, I have seen the code to tidy a single Excel file run into thousands of lines of R code.
### Reading in JSON Files
JSON (or JavaScript Object Notation) is a file
format that stores information in human-readable,
organized, logical, easy-to-access manner.
For example, here is what a JSON file looks
like:
```{javascript, eval=FALSE}
var stephanie = {
"age" : "33",
"hometown" : "Baltimore, MD",
"gender" : "female",
"cars" : {
"car1" : "Hyundai Elantra",
"car2" : "Toyota Rav4",
"car3" : "Honda CR-V"
}
}
```
Some features about `JSON` object:
* JSON objects are surrounded by curly braces `{}`
* JSON objects are written in key/value pairs
* Keys must be strings, and values must be a valid JSON data type (string, number, object, array, boolean)
* Keys and values are separated by a colon
* Each key/value pair is separated by a comma
### Using GitHub API
Let's say we want to use the
[GitHub API](https://developer.github.com/v3/?)
to find out how many of my GitHub repositories
have open issues? (we will learn more about using APIs in a minute)
We will use the
[jsonlite](https://cran.r-project.org/web/packages/jsonlite/index.html)
R package and the `fromJSON()` function
to convert from a JSON object to a data frame.
We will read in a JSON file located at
[https://api.github.com/users/jtleek/repos](https://api.github.com/users/jtleek/repos)
```{r,eval=FALSE}
github_url = "https://api.github.com/users/jtleek/repos"
library(jsonlite)
jsonData <- fromJSON(github_url)
```
```{r,echo=FALSE}
library(jsonlite)
jsonData = fromJSON(readLines(here::here("data","repos.json")))
```
The function `fromJSON()` has now converted
the JSON file into a data frame with the names:
```{r}
names(jsonData)
```
How many are private repos? How many have forks?
```{r}
table(jsonData$private)
table(jsonData$forks)
```
What's the most popular language?
```{r}
table(jsonData$language)
```
To find out how many repos that I have
with open issues, we can just create
a table:
```{r}
# how many repos have open issues?
table(jsonData$open_issues_count)
```
Whew! Not as many as I thought.
How many do you have?
One important thing to note about data read in JSON format is that it is often "nested". The way that R handles this is by forcing an entire data frame into a column!
```{r}
class(jsonData$owner)
jsonData$owner
```
Finally, I will leave you with a few
other examples of using GitHub API:
* [How long does it take to close a GitHub Issue in the `dplyr` package?](https://blog.exploratory.io/analyzing-issue-data-with-github-rest-api-63945017dedc)
* [How to retrieve all commits for a branch](https://stackoverflow.com/questions/9179828/github-api-retrieve-all-commits-for-all-branches-for-a-repo)
* [Getting my GitHub Activity](https://masalmon.eu/2017/12/21/wherehaveyoubeen/)
## Google Sheets
Google Sheets is increasingly used to create and store data. It is one of the [most useful distributed data collection services](https://simplystatistics.org/2016/08/26/googlesheets/). Not surprisingly, there are a number of tools that have been developed for reading data from Google Sheets. If the data are not protected, then you can make them public on the web and read them without authentication:

```{r}
library(googlesheets4)
gs4_deauth()
cameras = googlesheets4::read_sheet("https://docs.google.com/spreadsheets/d/16gHHSHCIg7r4NRu_8dbCaZzjkEChh799nyujXbiDVPg/edit?usp=sharing")
cameras
```
You can also read private Google Sheets if you have permission. You will first need to authenticate with your Google account:
```{r, eval=FALSE}
library(googlesheets4)
gs4_auth()
cameras = googlesheets4::read_sheet("https://docs.google.com/spreadsheets/d/16gHHSHCIg7r4NRu_8dbCaZzjkEChh799nyujXbiDVPg/edit?usp=sharing")
cameras
```
There is a lot more you can do with the [googlesheets4](https://googlesheets4.tidyverse.org/) package including navigating the sheets you have access to, identifying them by id, and much more. All of the same caveats apply as with an Excel spreadsheet. These sheets can be just as complicated and hard to manage.
## Databases
If you plan to do data science in industry, one of the most useful things you can learn about is how to acces, manipulate, and use data that is stored in databases. We don't have time to cover all of the varieties of databases in this course. So we will focus on [relational databases](https://en.wikipedia.org/wiki/Relational_database). These databases include tables that have pre-defined relationships.
There are several ways to
[query databases in R](https://db.rstudio.com/getting-started/database-queries/). Here we will use sqllite as an example of the type of database you can access in R.
First, we will download a `.sqlite` database. This is a
portable version of a `SQL` database. For our
purposes, we will use the
[chinook sqlite database here](https://github.com/lerocha/chinook-database/blob/master/ChinookDatabase/DataSources/Chinook_Sqlite.sqlite). The database represents a
"digital media store, including tables for artists,
albums, media tracks, invoices and customers".
From the [Readme.md](https://github.com/lerocha/chinook-database) file:
> Sample Data
>
> Media related data was created using real data from an iTunes Library. It is possible for you to use your own iTunes Library to generate the SQL scripts, see instructions below. Customer and employee information was manually created using fictitious names, addresses that can be located on Google maps, and other well formatted data (phone, fax, email, etc.). Sales information is auto generated using random data for a four year period.
```{r}
if(!file.exists(here("data", "Chinook.sqlite"))){
file_url <- paste0("https://github.com/lerocha/chinook-database/raw/master/ChinookDatabase/DataSources/Chinook_Sqlite.sqlite")
download.file(file_url,
destfile=here("data", "Chinook.sqlite"))
}
list.files(here("data"))
```
The main workhorse packages that we will use are
the `DBI` and `dplyr` packages. Let's look at the
`DBI::dbConnect()` help file
```{r, eval=FALSE}
?DBI::dbConnect
```
So we need a driver and one example is `RSQLite::SQLite()`.
Let's look at the help file
```{r, eval=FALSE}
?RSQLite::SQLite
```
Ok so with `RSQLite::SQLite()` and `DBI::dbConnect()`
we can connect to a `SQLite` database. Let's try that
with our `Chinook.sqlite` file that we downloaded. Chinook.sqlite
```{r}
library(DBI)
conn <- DBI::dbConnect(RSQLite::SQLite(),
here("data", "Chinook.sqlite"))
conn
```
So we have opened up a connection with the SQLite database. You can use a similar process with most common database backends, both locally on your computer and by connecting to databases on the cloud like [BigQuery](https://db.rstudio.com/databases/big-query/) or [RedShift](https://db.rstudio.com/databases/redshift/).
Next, we can see what tables are available in the database
using the `dbListTables()` function:
```{r}
dbListTables(conn)
```
From RStudio's website, there are several ways to interact with
SQL Databases. One of the simplest ways that we will use here is
to leverage the `dplyr` framework.
> "The `dplyr` package now has a generalized SQL backend for talking to databases, and the new `dbplyr` package translates R code into database-specific variants. As of this writing, SQL variants are supported for the following databases: Oracle, Microsoft SQL Server, PostgreSQL, Amazon Redshift, Apache Hive, and Apache Impala. More will follow over time.
So if we want to query a SQL databse with `dplyr, the
benefit of using `dbplyr` is:
> "You can write your code in `dplyr` syntax, and `dplyr` will translate your code into SQL. There are several benefits to writing queries in `dplyr` syntax: you can keep the same consistent language both for R objects and database tables, no knowledge of SQL or the specific SQL variant is required, and you can take advantage of the fact that `dplyr` uses lazy evaluation.
Let's take a closer look at the `conn` database
that we just connected to:
```{r}
library(dplyr)
library(dbplyr)
src_dbi(conn)
```
You can think of the multiple tables similar to having
multiple worksheets in a spreadsheet.
Let's try interacting with one.
### Querying with `dplyr` syntax
First, let's look at the first ten rows in the
`Album` table.
```{r}
tbl(conn, "Album") %>%
head(n=10)
```
The output looks just like a `data.frame` that we are familiar
with. But it's important to know that it's not really
a dataframe. For example, what about if we use
the `dim()` function?
```{r}
tbl(conn, "Album") %>%
dim()
```
Interesting! We see that the number of rows returned is `NA`.
This is because these functions are different than operating
on datasets in memory (e.g. loading data into memory using
`read_csv()`). Instead, `dplyr` communicates differently
with a SQLite database.
Let's consider our example. If we were to use straight SQL,
the following SQL query returns the first 10 rows
from the `Album` table:
```{r, eval=FALSE}
SELECT *
FROM `Album`
LIMIT 10
```
In the background, `dplyr` does the following:
* translates your R code into SQL
* submits it to the database
* translates the database's response into an R data frame
To better understand the `dplyr` code, we can use the
`show_query()` function:
```{r}
Album <- tbl(conn, "Album")
show_query(head(Album, n = 10))
```
This is nice because instead of having to write the
SQL query ourself, we can just use the `dplyr` and R
syntax that we are used to.
However, the downside is that `dplyr` never gets to see the
full `Album` table. It only sends our query to the database,
waits for a response and returns the query. However, in this
way we can interact with large datasets!
Many of the usual `dplyr` functions are available too:
* `select()`
* `filter()`
* `summarize()`
and many join functions.
Ok let's try some of the functions out.
First, let's count how many albums each
artist has made.
```{r}
tbl(conn, "Album") %>%
group_by(ArtistId) %>%
summarize(n = count(ArtistId)) %>%
head(n=10)
```
Next, let's plot it.
```{r}
library(ggplot2)
tbl(conn, "Album") %>%
group_by(ArtistId) %>%
summarize(n = count(ArtistId)) %>%
arrange(desc(n)) %>%
ggplot(aes(x = ArtistId, y = n)) +
geom_bar(stat = "identity")
```
Let's also extract the first letter from each
album and plot the frequency of each letter.
```{r}
tbl(conn, "Album") %>%
mutate(first_letter = str_sub(Title, end = 1)) %>%
ggplot(aes(first_letter)) +
geom_bar()
```
### Delayed execution
One important feature of `dbplyr` for large data sets is delayed execution. From the dbplyr documentation:
> * It never pulls data into R unless you explicitly ask for it.
> * It delays doing any work until the last possible moment: it collects together everything you want to do and then sends it to the database in one step.
This means that when you perform a command like this
```{r}
test = tbl(conn, "Album")
```
Then the database hasn't been touched! It won't be until you run the command. Even then it will only pull the first 10 rows of the result once you ask to see the data
```{r}
test
```
If you want to pull all of the data into R, a good idea is to first check and see how many rows it has. You can do this with the `count` function
```{r}
test %>% count()
```
In this case it is a small number, so we can pull all of the data into memory in R using the `collect` function - the resulting data frame has the same number of rows as we discovered using the count function.
```{r}
test %>% collect()
```
When working with databases it is a good idea to think about ways you can make the data smaller before pulling it into memory. One is through grouping and aggregating as we showed above
```{r}
test %>%
group_by(ArtistId) %>%
summarize(n = count(ArtistId)) %>%
collect()
```
Thinking cleverly about how to make data small in database takes a certain way of thinking, but with practice can make your data analysis much easier. Some packages have been developed that automatically push certain comptuations to the database for you including:
* [dbplot](https://db.rstudio.com/dbplot/) for making plots in database
* [modeldb](https://github.com/tidymodels/modeldb) for running certain types of models (like regression) in database
Some important things to consider when dealing with data in databases are:
1. Making sure you count your data before you pull it down into a local environment.
2. Listing and looking through each table. Sometimes called database spelunking this is an important step before using any database
3. Understanding whether it costs more computationally to do an analysis mostly in the database or mostly on your computer. This will involve tradeoffs depending on the size of the data and your local computing power.
4. Ensuring you have proper authentication to access the databases and tables that you care about.
## APIs
Application Programming Interfaces (or APIs) are a way to access data through a structured URL over the web. Most social media companies provide their data to the public through this format. But there are a wide range of other government entities, companies, and non-profits that make their data available via an API.
The reason companies distribute data this way is because they can control what and how much data you download. Most have rate limits - the number of calls or amount of data you can pull per unit time. You need to respect these limits or your data collection will be blocked.
When you want to collect data from an API, the first thing you should check and see is if someone built a package for that API. For most common APIs a package will exist (for example [rtweet](https://github.com/ropensci/rtweet) or [Rfacebook](https://github.com/pablobarbera/Rfacebook)). If they don't exist, you can use the [httr](https://cran.r-project.org/web/packages/httr/vignettes/quickstart.html) R package to build your own access to an API.
Regardless of whether you are using an R package or building your own, you should:
1. Read the developer docs - look for rate limits, licenses, and other information about how to use the API appropriately.
2. Look at the worked examples, to figure out how to use the API. Each one is different, but all have a similar, structured URL approach.
Let's dissect an example of an API url. If you go to this url:
https://api.github.com/search/repositories?q=created:2014-08-13+language:r+-user:cran&type you will get a bunch of JSON - this is data from the Github API. Let's break down each part of this url:
1. https://api.github.com/search/repositories
- This is the base url that tells us we will be asking for repository data
2. ?q=
- This defines the "query", or the search, we will be doing
3. created:2014-08-13
- This tells us we will search for repos created on 2014-08-13
4. +
- This is like an "and" for the search
5. language:r
- This tells us we are searching for only R repos
6. -user:cran&type
- This tells us we don't want any repos created by cran (to avoid explosion of repos - cran has a lot!)
Using the `httr` package we can access these data directly using the `GET` command:
```{r}
library(httr)
query_url = "https://api.github.com/search/repositories?q=created:2014-08-13+language:r+-user:cran"
req = GET(query_url)
req
```
The resulting request will give us the status, the date, and information about the content. We can use the `content` function to extract the data- in this case a nested list:
```{r}
names(content(req))
```
Not all APIs are open like this Github API. You may have to create a developer account and authenticate before accessing the data. You can usually figure this out by following the developer docs on each individual site.
Some things to keep in mind when you are downloading data from APIs are the following:
1. Pay attention to the terms of service and developer docs
2. Respect rate limits so you won't be blocked
3. Think *carefully* about what data you pull and share, it is very easy to collect data people wouldn't want shared
4. Remember the data are constantly updating since they are from the web, so you might want to save versions of the data
5. Remember that the data are only the version that the company/government/entity wants to expose, so may have errors or issues due to translation.
## Webscraping
Do we want to purchase a book on Amazon?
Next we are going to learn about what to do if
your data is on a website (XML or HTML) formatted
to be read by humans instead of R.
We will use the (really powerful)
[rvest](https://cran.r-project.org/web/packages/rvest/rvest.pdf)
R package to do what is often called
"scraping data from the web".
Before we do that, we need to set up a
few things:
* [SelectorGadget tool](http://selectorgadget.com/)
* [rvest and SelectorGadget guide](https://cran.r-project.org/web/packages/rvest/vignettes/selectorgadget.html)
* [Awesome tutorial for CSS Selectors](http://flukeout.github.io/#)
* [Introduction to stringr](https://cran.r-project.org/web/packages/stringr/vignettes/stringr.html)
* [Regular Expressions/stringr tutorial](https://stat545-ubc.github.io/block022_regular-expression.html)
* [Regular Expression online tester](https://regex101.com/#python)- explains a regular expression as it is built, and confirms live whether and how it matches particular text.
We're going to be scraping [this page](http://www.amazon.com/ggplot2-Elegant-Graphics-Data-Analysis/product-reviews/0387981403/ref=cm_cr_dp_qt_see_all_top?ie=UTF8&showViewpoints=1&sortBy=helpful): it just contains the (first page of) reviews of the
ggplot2 book by Hadley Wickham.
```{r}
url <- "http://www.amazon.com/ggplot2-Elegant-Graphics-Data-Analysis/product-reviews/0387981403/ref=cm_cr_dp_qt_see_all_top?ie=UTF8&showViewpoints=1&sortBy=helpful"
```
We use the `rvest` package to download this page.
```{r}
library(rvest)
h <- read_html(url)
```
Now `h` is an `xml_document` that contains the contents of the page:
```{r}
h
```
How can you actually pull the interesting
information out? That's where CSS selectors come in.
### CSS Selectors
CSS selectors are a way to specify a subset of
nodes (that is, units of content) on a web page
(e.g., just getting the titles of reviews).
CSS selectors are very powerful and not too
challenging to master- here's
[a great tutorial](http://flukeout.github.io/#)
But honestly you can get a lot done even with
very little understanding, by using a tool
called SelectorGadget.
Install the [SelectorGadget](http://selectorgadget.com/)
on your web browser. (If you use Chrome you can
use the Chrome extension, otherwise drag the
provided link into your bookmarks bar).
[Here's a guide for how to use it with rvest to "point-and-click" your way to a working selector](http://selectorgadget.com/).
For example, if you just wanted the titles,
you'll end up with a selector that looks
something like `.a-text-bold span`. You can pipe
your HTML object along with that selector
into the `html_nodes` function, to select
just those nodes:
```{r}
h %>%
html_nodes(".a-text-bold span")
```
But you need the text from each of these, not the full tags. Pipe to the `html_text` function to pull these out:
```{r}
review_titles <- h %>%
html_nodes(".a-text-bold span") %>%
html_text()
review_titles
```
Now we've extracted something useful! Similarly,
let's grab the format (hardcover or paperback).
Some experimentation with SelectorGadget
shows it's:
```{r}
h %>%
html_nodes(".a-size-mini.a-color-secondary") %>%
html_text()
```
Now, we may be annoyed that it always
starts with `Format: `. Let's introduce
the `stringr` package.
```{r}
formats <- h %>%
html_nodes(".a-size-mini.a-color-secondary") %>%
html_text() %>%
stringr::str_replace("Format: ", "")
formats
```
We could do similar exercise for extracting
the number of stars and whether or not someone
found a review useful. This would help us decide
if we were interested in purchasing the book!
Webscraping is the opposite of APIs in some sense. Anything that is public on a website can technically be webscraped using things like the `rvest` package. However, that doesn't mean it is always ethical or a good idea to do so. One [extreme example](http://motherboard.vice.com/read/70000-okcupid-users-just-had-their-data-published
) is a student who published the private OkCupid data of 70,000 people he had scraped from the web. This included private information, including sexual preferences, pictures, and intimate details from the profiles. At the time the way he scraped the data did not violate the terms of service of the website, but the way the data were collected and shared were ethically disasterous. So when scraping data think very carefully about the ethics and purpose of your data collection.
Some other things to be aware of with data scraping are
1.Most websites have a file called `robots.txt`. You can see the one for Google [here](https://www.google.com/robots.txt) this file tells you what it is ok to scrape and not.
2. Some companies will block you if you try to scrape their website. In [one case](https://www.theguardian.com/science/2012/may/23/text-mining-research-tool-forbidden) a student got his whole university blocked from accessing certain journals by webscraping!
3. The data will certainly update frequently if you scrape it from a website.
4. Some companies consider data on their websites proprietary and you can find yourself in legal battles if you collect and use them for commercial purposes.
## Google-ing
It seems silly to talk about using Google in an "advanced" course. But for things like getting data you will be spending a lot of time Googling. As packages evolve super rapidly, you will often want to check your workflows and make sure they haven't gone out of date. For example, since the last time I taught this course, the `googlesheets` package has been replaced by `googlesheets4`, among other changes!
A good default move when embarking on a new data collection exercise is to Google for workflows for the thing you want. I generally use variations on:
* "rstats reading data type x"
* "rstats tutorial on data type x"
* "stack overflow data type x"
As a place to get started, but I also use Google by copying and pasting exact error messages I run into with any new package. I point this out primarily to make sure you know that it is not only acceptable, but encouraged to use the internet and Google as a resource when figuring out how to handle new data sets.
## Additional Resources
:::resources
* An outstanding JSM tutorial on [webscraping](https://github.com/simonmunzert/rscraping-jsm-2016)
* The databases using Rstudio [website](https://db.rstudio.com/)
* Relational data section of [R for Data Science](https://r4ds.had.co.nz/relational-data.html)
* Some of my [lecture slides on webscraping and APIs](https://docs.google.com/presentation/d/1K-TxNcPg1qugUABMH5LATh2AqBPLVTplLfQ8aBUasD0/edit#slide=id.g5d42ac9146_0_532)
* Some of my [lecture slides on databases](https://docs.google.com/presentation/d/11vCz5KrS2uKhr1rOlmeVzXGslkz5IKoEjgMTgpaK5ds/edit)
:::
## Homework
:::homework
* __Template Repo__: https://github.com/advdatasci/homework6
* __Repo Name__: homework6-ind-yourgithubusername
* __Pull Date__: 2020/10/12 9:00AM Baltimore Time
:::