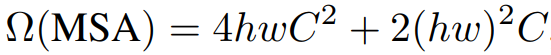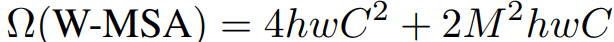Description Reference
Brief
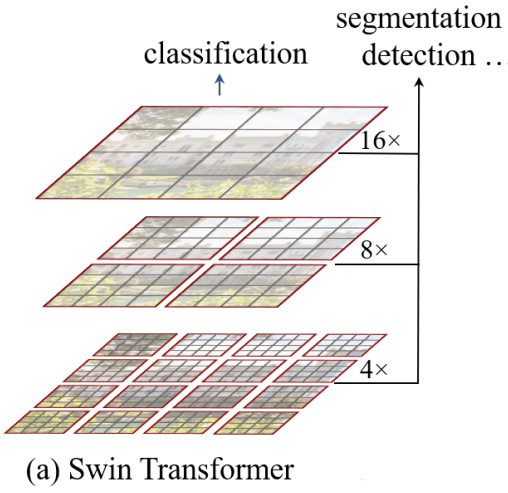
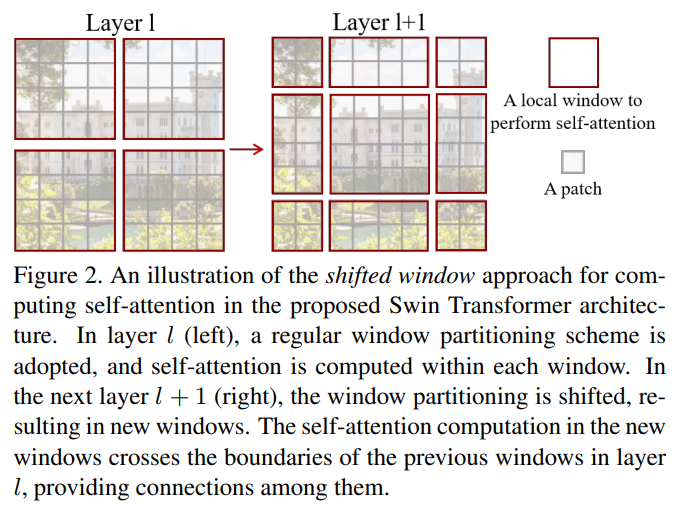
Swin - Shifted window
只计算窗口之内patch 相互的注意力, 减少计算量,引入局部信息
移动窗口, 增加 windows 信息交互
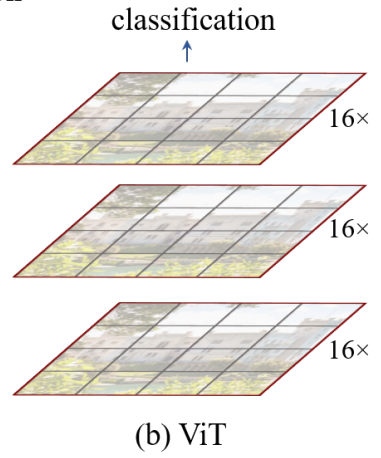
Tasks: Classification/Detection/Semantic Segmentation
Motivation
背景/存在的问题
做了什么尝试/分别有什么效果
应用领域
Model
ViT/MSA
Swin Transformer/W-MSA
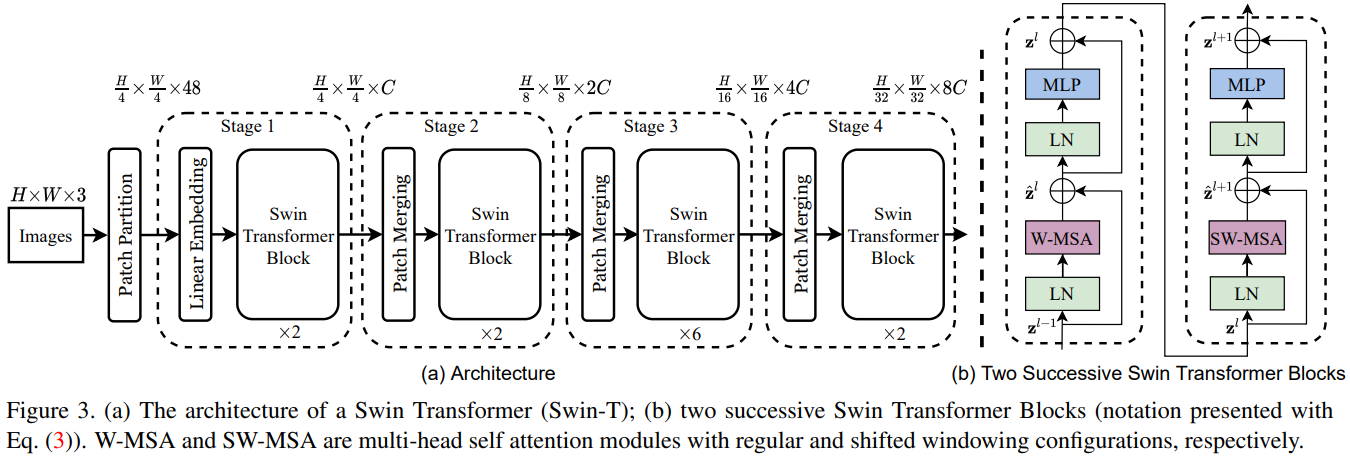
Arch
复杂度
Arch
Split Patch HxWx3 ==> 4x4x3 x H/4 x W/4
Linear Embedding (default C=96) ==> B x Token Vector(H/4 x W/4) x C
Swin Transformer blocks
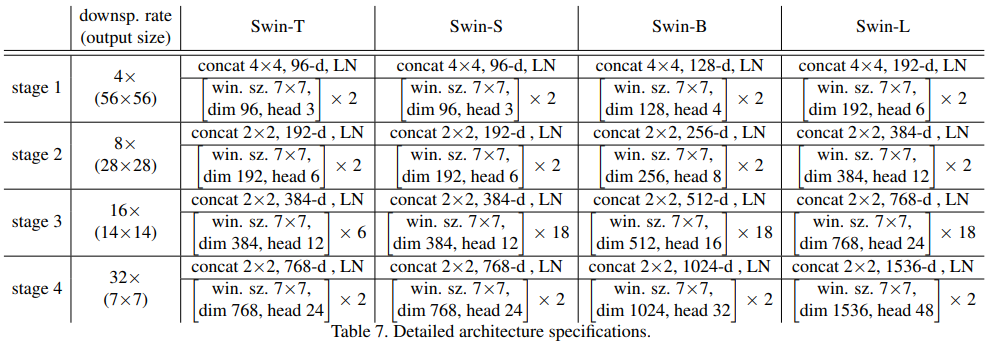
depths = [2, 2, 6, 2]
num_heads=[3, 6, 12, 24]
Patch Merging 2x2 patches
Swin Transformer Blocks
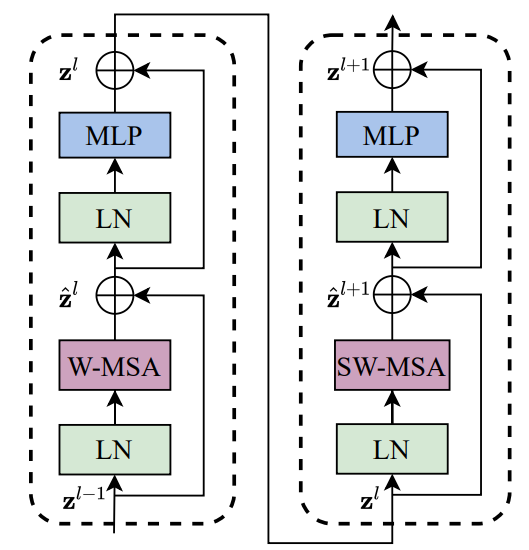
Stage1/2/3/4 分别包含 2/2/6/2 个 Transformer Blocks每两个 Transformer Blocks 作为一组
第一个 TB 使用 W-MSA
第二个 TB 使用 SW-MSA
W-MSA & SW-MSA
MSA ==> W-MSA ==> SW-MSAMSA
image size = 224x224/ patch size = 4x4 / window size = 7x7/shift size = 0window = 8x8
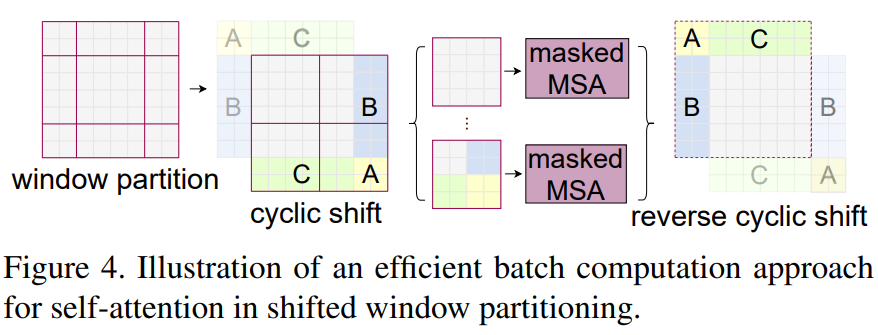
SW-MSA
shift size = window_size//2 = 3x3window = (8+1)x(8+1)
cyclic shift
通过设置 mask 计算 shift window attention
mask 设置为 -100, softmax 后就会忽略掉
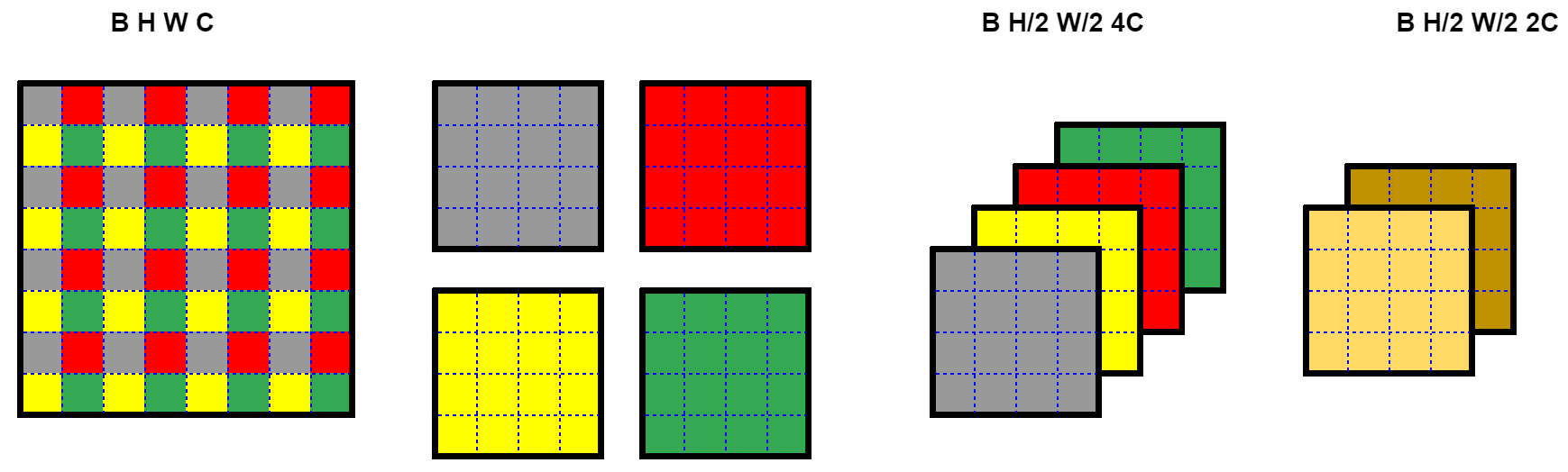
Patch Merging
B H W C ==> B H/2 W/2 4*C
x0 - B H/2 H/2 C - H 偶数部分 W 偶数部分
x1 - B H/2 H/2 C - H 奇数部分 W 偶数部分
x2 - B H/2 H/2 C - H 偶数部分 W 奇数部分
x3 - B H/2 H/2 C - H 奇数部分 W 奇数部分
concat [x0, x1, x2, x3]
B H/2 W/2 4*C ==> B H/2 W/2 2*C
nn.Linear(4 * dim, 2 * dim)
Evaluation
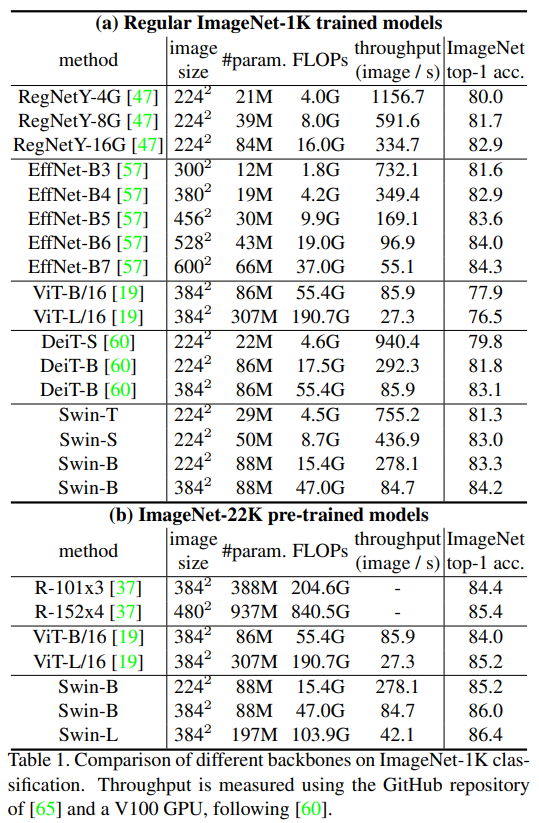
速度没有提高??? 相同量级的速度没提高,但是低量级的能够达到更高的精度
比较 ViT-B 384 & Swin-B 384 [Param/FLOPS/Throughput] 都差不多
比较 ViT-B 384 & Swin-T 224 更高的精度,更小的image size 更快的速度
精度些微提升
Num
Evaluation
1 Classification
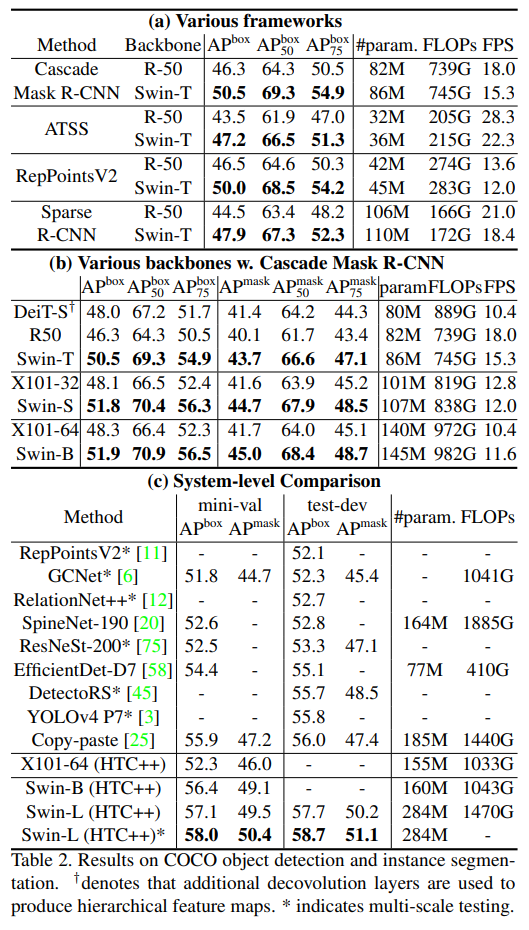
2 Detection
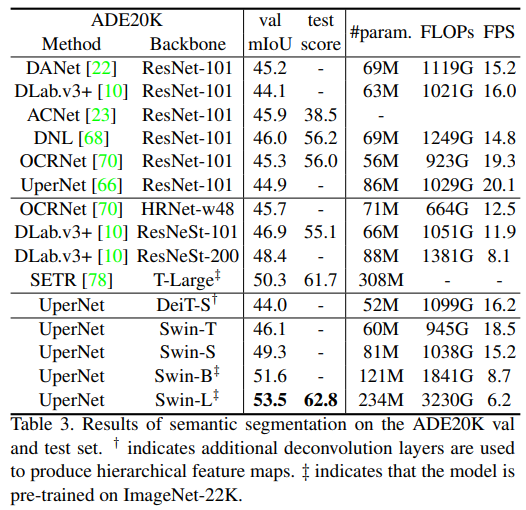
3 Segmentation
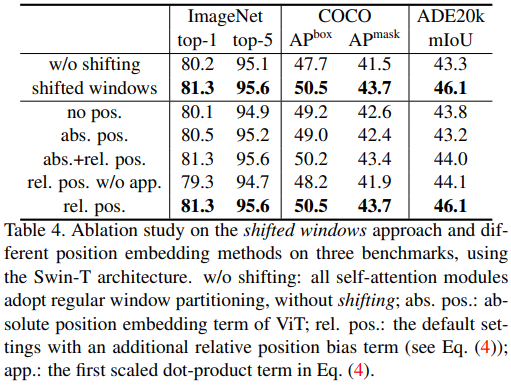
4 Ablation
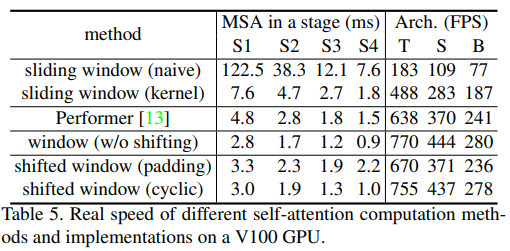
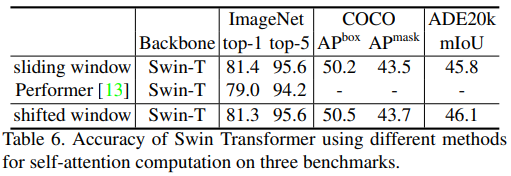
5 Speed
6
Tricks Reactions are currently unavailable
You can’t perform that action at this time.