add PyTorch's DistributedDataParallel training. #3940
Conversation
|
Sure, will do. Maybe later today or tomorrow. |
|
Here are the results for DDP (DistributedDataParallel) training WITHOUT wer/cer
Training time
I will enable |
|
Fantastic!
…On Wed, Feb 19, 2020 at 5:30 PM Fangjun Kuang ***@***.***> wrote:
Here are the results for DDP (DistributedDataParallel) training *WITHOUT*
constrain_orthonormal()
wer/cer
DDP training (no constrain_orthonormal) previous pullrequest (#3925
<#3925>)
test cer 8.23 7.91
test wer 16.98 16.49
dev cer 6.74 6.48
dev wer 14.77 14.48 Training time
DDP (2 GPUs) previous pullrequest (#3925
<#3925>) with single GPU
6 epochs in total 2 hours 10 minutes 49 seconds 3 hours, 54 seconds
------------------------------
I will enable constrain_orthornormal() via forward hooks.
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
<#3940?email_source=notifications&email_token=AAZFLO5ICMRWQMVS7UVOPETRDT32RA5CNFSM4KXSLYMKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEMHANBQ#issuecomment-588121734>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAZFLO3HKWVGUUE6Q2HEXGTRDT32RANCNFSM4KXSLYMA>
.
|
|
cool! I will try later. |
|
this is my result based on this pr
|
|
thank you very much. Did you use the commit with |
|
Yes, |
|
Your results show that the training time is indeed decreased, although it is not decreased linearly. There is a slight degradation in wer/cer; I guess this is caused by setting According to this paper
When 4 gpus are used, it actually increases the batch size by 4x, so the |
|
Regarding |
|
yes, I have changed lr from 1e-3 to 4e-3 already, look at the last line of my result. |
dropout was copied dropout |
|
@fanlu So the result shows dropout can improve the cer/wer a little bit and |
|
By the way, your way to insert a hyperlink using markdown is not correct. |
|
You could reduce the weight decay. Please always report the final train
and valid objective function values.
…On Thu, Feb 20, 2020 at 5:07 PM Fangjun Kuang ***@***.***> wrote:
@fanlu <https://github.com/fanlu>
thanks.
So the result shows dropout can improve the cer/wer a little bit and
increasing the number of epochs from 6 to 18 does not really have
a big effect. I guess the final learning rate is really small because of
the learning rate decay.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#3940?email_source=notifications&email_token=AAZFLOYIO6HYXNL6USR6MKLRDZB55A5CNFSM4KXSLYMKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEMMIWAI#issuecomment-588811009>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAZFLOZCE5ZPZD3NQ5JOMXTRDZB55ANCNFSM4KXSLYMA>
.
|
|
add global objf and validation objf in above result
|
|
update result by reducing the weight decay
|
|
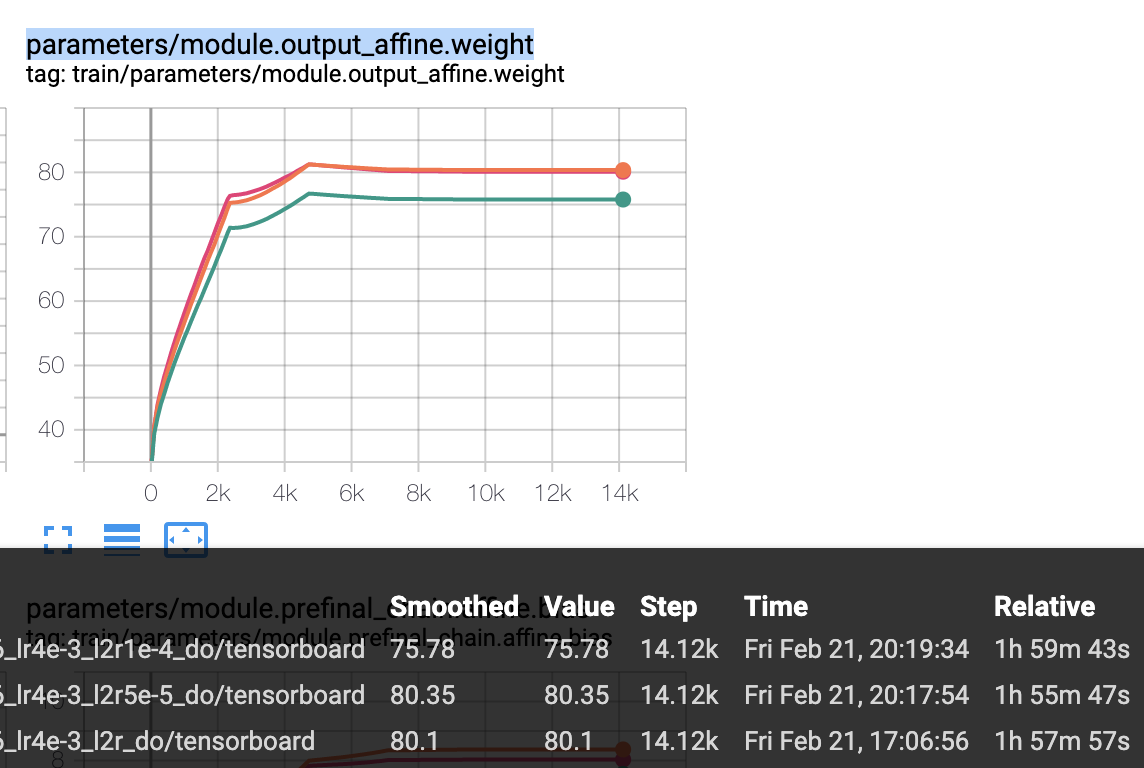
Show what happens to the norm of output.affine. It's odd there are not bigger differences in WER or objf.. I suspect either a bug, or it was too small. |
|
|
OK, I think you should be increasing the l2, not decreasing it.
It's formulated a bit differently from Kaldi, you can't compare the numbers
exactly.
…On Fri, Feb 21, 2020 at 10:38 PM fanlu ***@***.***> wrote:
base lr=4e-3 parameters/module.output_affine.weight
weight_decay=5e-4 80.1
weight_decay=1e-4 75.78
weight_decay=5e-5 80.35
[image: image]
<https://user-images.githubusercontent.com/1620875/75043324-d7f5f880-54fa-11ea-990a-4d8059d977cb.png>
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#3940?email_source=notifications&email_token=AAZFLO2WYOPXWQNMALTZ5H3RD7RN3A5CNFSM4KXSLYMKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEMS46XY#issuecomment-589680479>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAZFLO54IXIVRTNVAMOZBSTRD7RN3ANCNFSM4KXSLYMA>
.
|
|
Here is the result with multiple machines:
It takes about 45 minutes for 6 epochs with 8 GPUs on different machines. I queue jobs with Kaldi's INIT_FILE=$dir/ddp_init
rm -f $INIT_FILE # delete old one before starting
init_method=file://$(readlink -f $INIT_FILE)
echo "$init_method"
queue.pl -q v100.q --gpu $num_gpus JOB=1:$num_gpus $dir/logs/task.JOB.log \
python3 ./chain/ddp_train_copy.py \
--train.init-method $init_method \
......
# use SGE_TASK_ID as rank
local_rank = int(os.environ['SGE_TASK_ID']) - 1
dist.init_process_group('nccl',
init_method=args.init_method,
rank=local_rank,
world_size=args.world_size)
Note |
|
Wow, well done!
…On Fri, Feb 21, 2020 at 11:27 PM Haowen Qiu ***@***.***> wrote:
Here is the result with multiple machines:
WER/CER
dev_cer 6.75
dev_wer 14.82
test_cer 8.21
test_wer 16.94
It takes about 45 minutes for 6 epochs with 8 GPUs on different machines.
2020-02-21 21:14:23,462 INFO [ddp_train_copy.py:338] epoch 0, learning rate 0.007
2020-02-21 21:14:24,798 INFO [ddp_train_copy.py:178] Device (0) processing 0/1181(0.000000%) global average objf: -1.187857 over 6400.0 frames, current batch average objf: -1.187857 over 6400 frames, epoch 0
......
2020-02-21 22:02:40,117 INFO [ddp_train_copy.py:178] Device (0) processing 1100/1181(93.141406%) global average objf: -0.045180 over 6252288.0 frames, current batch average objf: -0.047351 over 3840 frames, epoch 5
2020-02-21 22:03:08,614 INFO [common.py:76] Save checkpoint to exp/chain_cleaned_pybind/tdnn1c_sp/best_model.pt: epoch=5, learning_rate=7.168000000000002e-05, objf=-0.04506898490268912
I queue jobs with Kaldi's queue.pl on SGE clusters, see this pr
<mobvoi#2> for details. Jobs communicate
with each other by a shared file (so certainly your cluster should support
share file system).
INIT_FILE=$dir/ddp_init
rm -f $INIT_FILE # delete old one before starting
*init_method=file://$(readlink -f $INIT_FILE)*
echo "$init_method"
queue.pl -q v100.q --gpu $num_gpus JOB=1:$num_gpus $dir/logs/task.JOB.log \
python3 ./chain/ddp_train_copy.py \
--train.init-method $init_method \
......
# use SGE_TASK_ID as rank
local_rank = int(os.environ['SGE_TASK_ID']) - 1
dist.init_process_group('nccl',
*init_method=args.init_method, *
rank=local_rank,
world_size=args.world_size)
Note learning_rate=7*1e-3 instead 8*1e-3 ( 8*1e-3 it will make the result
a little worse)
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#3940?email_source=notifications&email_token=AAZFLOZF5HLF3A5KB2KJNZLRD7XFHA5CNFSM4KXSLYMKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEMTCCII#issuecomment-589701409>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAZFLO7H2H6OJXNH36OVNKLRD7XFHANCNFSM4KXSLYMA>
.
|
|
update result by increasing the weight decay
|
|
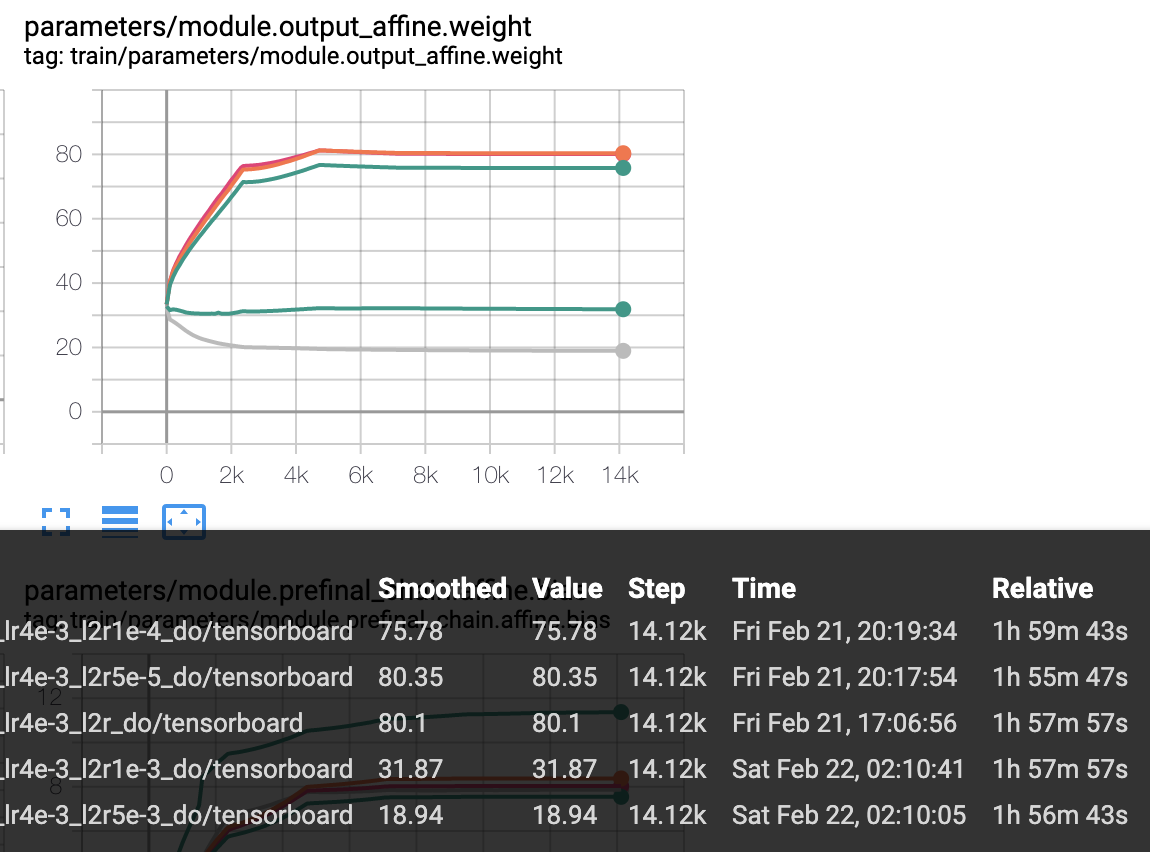
Is that consistent with the plot you showed before? Looked like the output-affine.weight param's norm wasn't ever smaller than about 70 or 80. But I couldn't see the legend of the plot so I'm not sure. |
|
Maybe there are some problems when I change the code below from to I'll make the weight_decay different from opts.l2_regularize and rerun this exp.
|
|
@fanlu
You'll normally want the opts.l2_regularize in the chain options to be
zero; we don't rely on that any more,
instead we rely on weight decay.
…On Sat, Feb 22, 2020 at 2:04 PM fanlu ***@***.***> wrote:
Maybe there are some problems when I change the code below from
opts = chain.ChainTrainingOptions()
opts.l2_regularize = args.l2_regularize
optimizer = optim.Adam(model.parameters(),
lr=learning_rate,
weight_decay=5e-4)
to
opts = chain.ChainTrainingOptions()
opts.l2_regularize = args.l2_regularize
optimizer = optim.Adam(model.parameters(),
lr=learning_rate,
weight_decay=args.l2_regularize)
I'll make the weight_decay different from opts.l2_regularize and rerun
this exp.
[image: image]
<https://user-images.githubusercontent.com/1620875/75087449-5db98880-557b-11ea-92aa-d4fa1efc0f00.png>
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#3940?email_source=notifications&email_token=AAZFLO6BIKZN5V4S3QA42W3REC56ZA5CNFSM4KXSLYMKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEMUYECI#issuecomment-589922825>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAZFLOYK4YDBVGPHY6GQ5EDREC56ZANCNFSM4KXSLYMA>
.
|
|
@qindazhu I have converged problem about SGD optimizer with
|
|
Hm. Probably implementing the max-change would fix that. sorry, I was
supposed to do that.
I am trying to get a good coding and experimentation environment set up and
I'll be more productive after that.
…On Wed, Feb 26, 2020 at 10:44 AM fanlu ***@***.***> wrote:
@qindazhu <https://github.com/qindazhu> I have converged problem about
SGD optimizer with momentum=0.9, But it seems that it will not appear
when this configuration is not used. Do you have the similar phenomenon?
This is the log below:
2020-02-26 10:22:10,397 INFO [ddp_train.py:344] epoch 0, learning rate 0.003999350705525672
2020-02-26 10:22:12,160 INFO [ddp_train.py:179] Device (1) processing 0/2364(0.000000%) global average objf: -1.277822 over 3840.0 frames, current batch average objf: -1.277822 over 3840 frames, epoch 0, scheduler lr is 0.0039987015164471736
WARNING ([5.5.791~1-be084]:DenominatorComputation():chain-denominator.cc:64) Nnet outputs -7.77028e+09, 3.26698e+09 outside the range [-30,30], derivs may be inaccurate.
WARNING ([5.5.791~1-be084]:DenominatorComputation():chain-denominator.cc:64) Nnet outputs -6.8477e+09, 2.8795e+09 outside the range [-30,30], derivs may be inaccurate.
2020-02-26 10:22:20,200 INFO [ddp_train.py:194] Validation average objf: -737218620.269293 over 17869.0 frames
2020-02-26 10:23:42,259 INFO [ddp_train.py:179] Device (1) processing 100/2364(4.230118%) global average objf: -7.088334 over 558336.0 frames, current batch average objf: -4.976176 over 6400 frames, epoch 0, scheduler lr is 0.003934311931812134
2020-02-26 10:25:00,463 INFO [ddp_train.py:179] Device (1) processing 200/2364(8.460237%) global average objf: -7.405582 over 1115520.0 frames, current batch average objf: -7.530059 over 6400 frames, epoch 0, scheduler lr is 0.003870959188409785
2020-02-26 10:26:20,953 INFO [ddp_train.py:179] Device (1) processing 300/2364(12.690355%) global average objf: -7.439822 over 1671168.0 frames, current batch average objf: -9.668958 over 6400 frames, epoch 0, scheduler lr is 0.003808626590376223
WARNING ([5.5.791~1-be084]:DenominatorComputation():chain-denominator.cc:64) Nnet outputs -46.543, 61.0312 outside the range [-30,30], derivs may be inaccurate.
WARNING ([5.5.791~1-be084]:DenominatorComputation():chain-denominator.cc:64) Nnet outputs -42.9122, 55.318 outside the range [-30,30], derivs may be inaccurate.
WARNING ([5.5.791~1-be084]:DenominatorComputation():chain-denominator.cc:64) Nnet outputs -51.7164, 74.0772 outside the range [-30,30], derivs may be inaccurate.
2020-02-26 10:27:41,098 INFO [ddp_train.py:179] Device (1) processing 400/2364(16.920474%) global average objf: -7.498366 over 2221696.0 frames, current batch average objf: -10.663645 over 3840 frames, epoch 0, scheduler lr is 0.0037472977106947553
WARNING ([5.5.791~1-be084]:DenominatorComputation():chain-denominator.cc:64) Nnet outputs -52.6615, 59.2798 outside the range [-30,30], derivs may be inaccurate.
2020-02-26 10:28:59,904 INFO [ddp_train.py:179] Device (1) processing 500/2364(21.150592%) global average objf: -7.657387 over 2778752.0 frames, current batch average objf: -8.657759 over 6400 frames, epoch 0, scheduler lr is 0.0036869563868667512
WARNING ([5.5.791~1-be084]:DenominatorComputation():chain-denominator.cc:64) Nnet outputs -47.5137, 49.1453 outside the range [-30,30], derivs may be inaccurate.
2020-02-26 10:30:17,675 INFO [ddp_train.py:179] Device (1) processing 600/2364(25.380711%) global average objf: -7.948807 over 3345280.0 frames, current batch average objf: -10.879383 over 4736 frames, epoch 0, scheduler lr is 0.0036275867166522097
And maybe we should focus on SGD now, as your result is nearly same with
Kaldi's.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#3940?email_source=notifications&email_token=AAZFLOY3PP2TUQMIUUE2INTREXJPBA5CNFSM4KXSLYMKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEM6SFCA#issuecomment-591209096>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAZFLO7D3JRFNWGNBTWKIXLREXJPBANCNFSM4KXSLYMA>
.
|
|
Thanks, Dan |
|
@fanlu, I suppose you are using a small L2, try a larger one, say, 1e-3~1e-4 |
|
@csukuangfj, wondering when this pr is ready to merge? I'll make another pr based on yours. |
|
ok, then we can merge it for now. @danpovey, can you help to do this? |
|
I have the permission to merge. |
|
merged. |
|
Hi, @danpovey , I want to compare each layer's calculation in kaldi and pytorch. So I have loaded kaldi tdnn_1c model to pytorch model. we can see the parameter of the two model are same. |
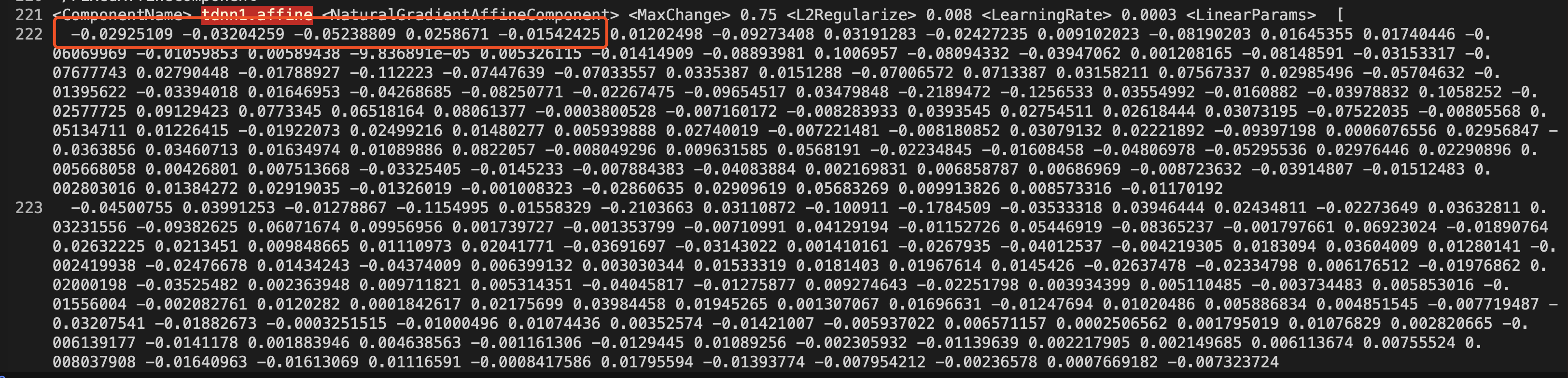

|
I can only assume you interpreted tdnn1_affine wrong. The matrix should be
interpreted as 3 blocks, for positions/offsets -1, 0 and 1, so it should be
reshaped as appropriate and then used as the parameters for Conv1d in
PyTorch. Check the Pytorch and Kaldi documentation to see what the
respective layouts are.
…On Sun, Mar 1, 2020 at 12:17 AM fanlu ***@***.***> wrote:
Hi, @danpovey <https://github.com/danpovey> , I want to compare each
layer's calculation in kaldi and pytorch. So I have loaded kaldi tdnn_1c
model to pytorch model. we can see the parameter of the two model are same.
[image: image]
<https://user-images.githubusercontent.com/1620875/75610797-7f080f00-5b4f-11ea-86b4-6ada5a8ac9bb.png>
[image: image]
<https://user-images.githubusercontent.com/1620875/75610802-8b8c6780-5b4f-11ea-8b69-ed6a51ddbd7a.png>
the kaldi's calculation was given by"nnet3-copy --nnet-config='echo
output-node name=output input=$output_name |' $model -|", pytorch is used
forward after model.eval().
And we can see that the lda layer of kaldi and pytorch give the same
result on same feat data.
[image: image]
<https://user-images.githubusercontent.com/1620875/75610901-78c66280-5b50-11ea-904b-37e2c397dde2.png>
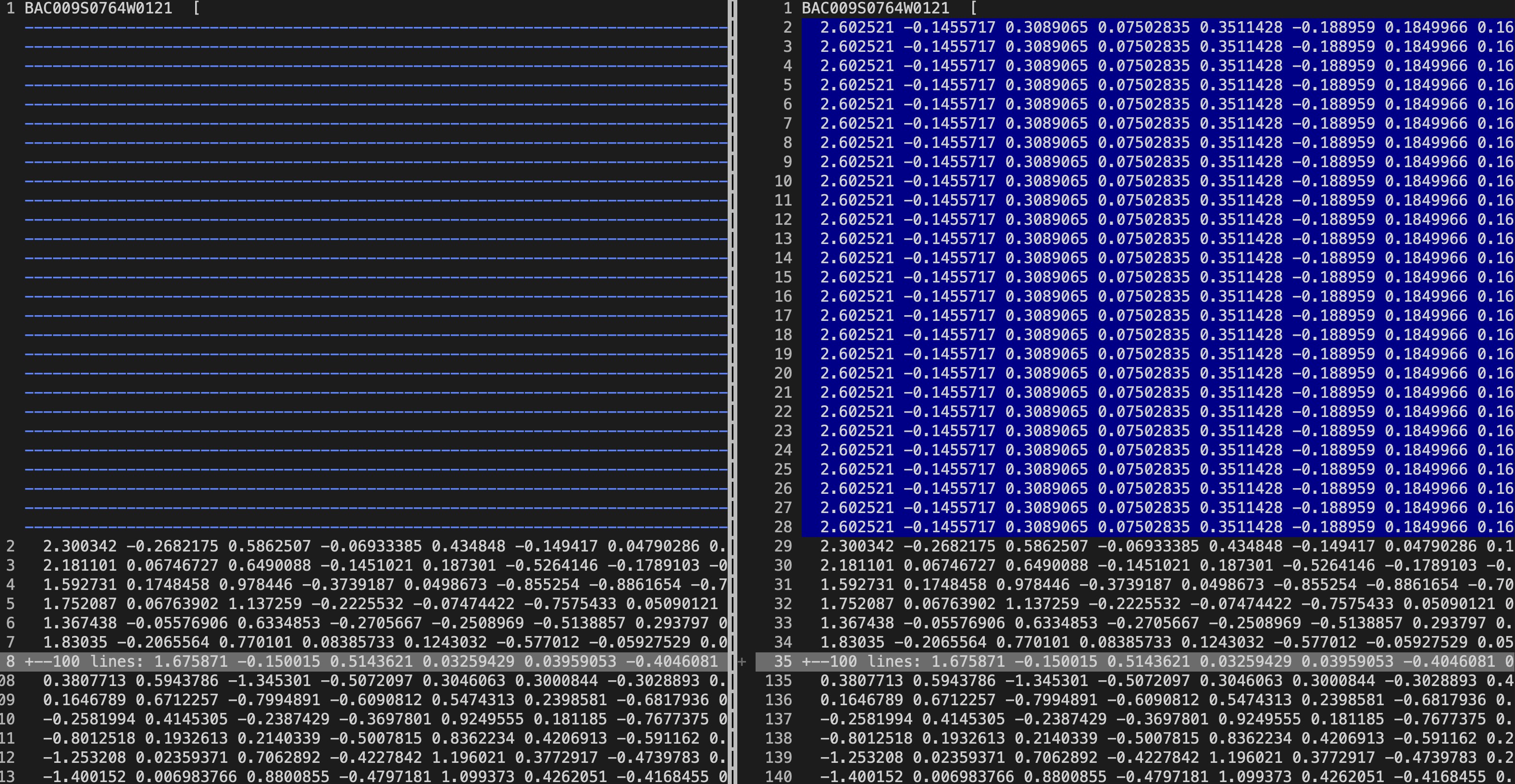
we can assume that the kaldi's tdnn1.affine and pytorch's tdnn1_affine
layer have the same input. but after tdnn1_affine layer in pytorch, I have
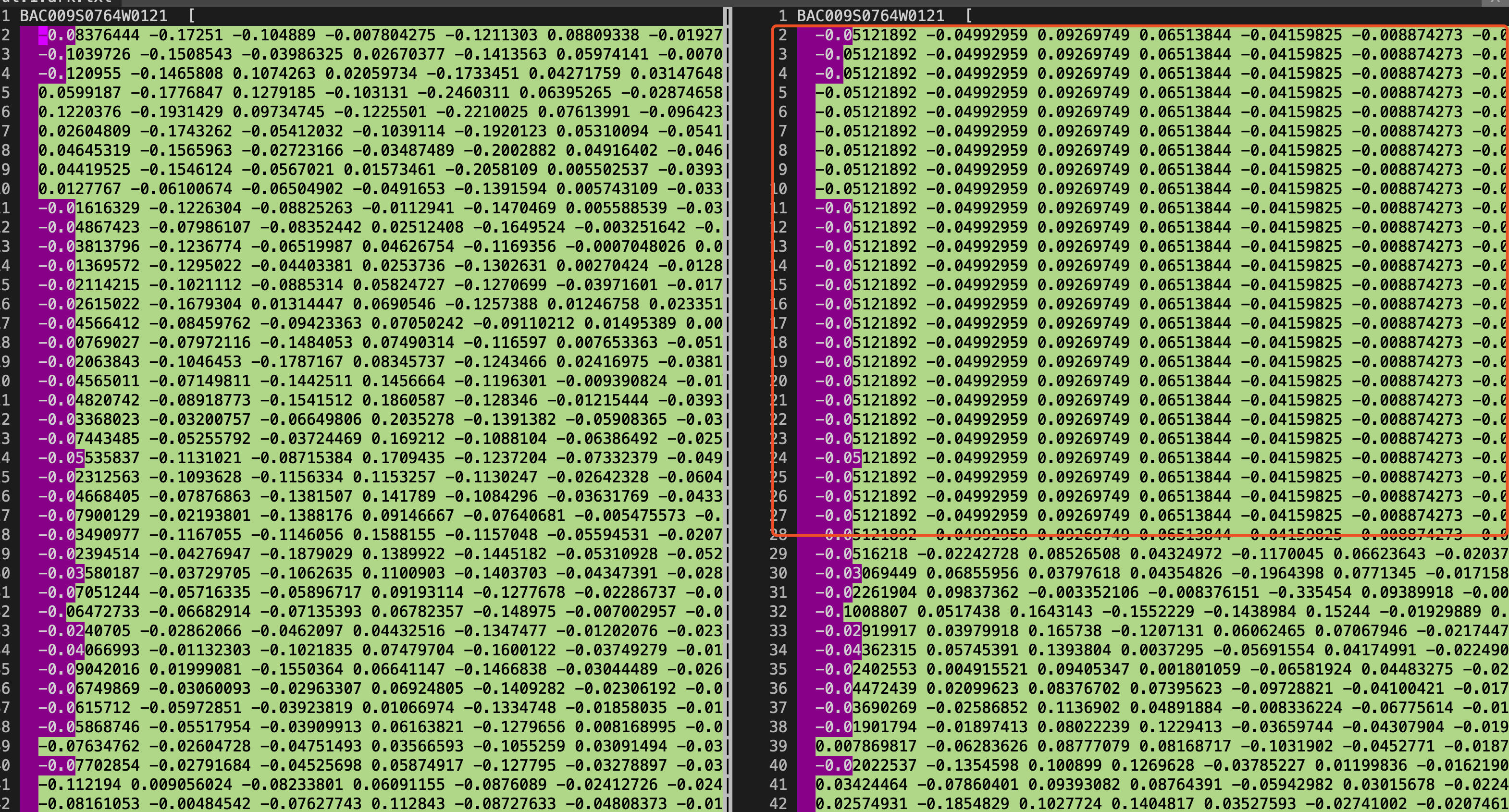
different result with kaldi's output.(the line 2~28 on right side of
picture is pytorch's first frame padding, so we can ignore it)
[image: image]
<https://user-images.githubusercontent.com/1620875/75610966-0c982e80-5b51-11ea-99b6-42154bf65769.png>
I am not sure what's the problem. Any help will be appreciated. Thanks.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#3940?email_source=notifications&email_token=AAZFLO7EQDDX2O3P7G6ISFLRFE2JRA5CNFSM4KXSLYMKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOENL6ALI#issuecomment-592961581>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAZFLO33BJDA66QG6QHQDRTRFE2JRANCNFSM4KXSLYMA>
.
|
|
Is the code below use -1 0 1 position to calculate? kaldi maybe used this code to Propagate And I have used three method in pytorch. they give me the same result, but different with kaldi's |
|
The How did you load the kaldi's affine weight into PyTorch? Please show the code here. |
|
You can refer to the code of loading |
|
|
How did you define |
|
The kernel (2,2) version that I have pull request to your git repo. |
torch.matmul(x, self.tdnn1_affine.weight.permute(1,0))+self.tdnn1_affine.bias)
torch.nn.functional.linear(x, self.tdnn1_affine.weight, self.tdnn1_affine.bias)should produce the same output as
are identical. There must be something wrong somewhere. |
|
Yes. I think so.the lda layer give the same result that I have showed above.So we can assume that we have the same input of tdnn1 affine.And the parameter looks similar either.I have no idea about this |
|
You can create some faked data to debug the program. For example, create a |
|
The all data below was calculated by kaldi. I have no problem of pytorch's operation, but kaldi's. And let me show you what kaldi does. this is the first line of tdnn_1c's component tdnn1.affine parameter the first number of bias is but the same position of kaldi's tdnn1.affine result is |
|
No, it's really just affine; I suspect the issue may be to do with the
input to that operation being different.
…On Sun, Mar 1, 2020 at 7:24 PM fanlu ***@***.***> wrote:
The all data below was calculated by kaldi. I have no problem of pytorch's
operation, but kaldi's. And let me show you what kaldi's does.
this is the first line of result after lda layer
In [19]: a = "2.300342 -0.2682175 0.5862507 -0.06933385 0.434848 -0.149417 0.04790286 0.1030131 -0.01732294 -0.09611828 0.136682 0.1814303 -0.05899795 -0.201803
...: 8 0.1067935 -0.02466351 0.08162478 -0.02118591 0.124744 0.01374727 -0.06972296 -0.005960235 -0.03282106 0.04361587 0.002798802 0.05377146 -0.0349902 0.
...: 01767303 -0.0250284 0.01511859 -0.01311266 0.04825886 -0.0002267546 -0.09969836 -0.002055793 0.02966474 0.02634935 -0.02635059 0.03734357 0.02878513 -0
...: .01532372 -0.04639435 0.02087254 0.008594703 -0.003571067 0.01858955 -0.03278194 -0.01541399 0.005724381 -0.02329349 -0.0201427 -0.001844179 -0.0260285
...: 2 0.0314902 0.03338297 0.0105119 -0.004434433 0.06942096 -0.03313885 -0.05314681 -0.01254019 -0.0003705059 0.08503703 0.02103205 -0.0002556719 0.003088
...: 835 -0.004352001 -0.008468844 0.003002871 0.0007132483 -0.01116457 0.02239098 0.0113832 0.06207408 -0.05190803 0.007352485 0.023138 0.03291445 -0.04150
...: 248 0.002104727 -0.02316702 -0.005105506 -0.001692873 0.002865741 0.05086495 0.004914522 0.000904361 0.008471237 0.008629705 -0.01996578 0.05934002 0.0
...: 1623728 -0.007537241 0.03523977 -0.01370161 -0.009647677 -0.01505581 0.003700913 -0.02384711 0.01867253 -0.01007206 0.01386262 0.02045397 -0.03400788 0
...: .01091084 0.02664956 0.0385044 -0.05636362 0.03181829 0.05379674 0.03861693 -0.004055074 -0.02378738 0.02643323 -0.01879072 -0.03662547 0.01476509 -0.0
...: 2003892 -0.0251219 0.02554548"
this is the first line of tdnn_1c's component tdnn1.affine parameter
In [21]: b = "-0.02925109 -0.03204259 -0.05238809 0.0258671 -0.01542425 0.01202498 -0.09273408 0.03191283 -0.02427235 0.009102023 -0.08190203 0.01645355 0.01740
...: 446 -0.06069969 -0.01059853 0.00589438 -9.836891e-05 0.005326115 -0.01414909 -0.08893981 0.1006957 -0.08094332 -0.03947062 0.001208165 -0.08148591 -0.0
...: 3153317 -0.07677743 0.02790448 -0.01788927 -0.112223 -0.07447639 -0.07033557 0.0335387 0.0151288 -0.07006572 0.0713387 0.03158211 0.07567337 0.02985496
...: -0.05704632 -0.01395622 -0.03394018 0.01646953 -0.04268685 -0.08250771 -0.02267475 -0.09654517 0.03479848 -0.2189472 -0.1256533 0.03554992 -0.0160882
...: -0.03978832 0.1058252 -0.02577725 0.09129423 0.0773345 0.06518164 0.08061377 -0.0003800528 -0.007160172 -0.008283933 0.0393545 0.02754511 0.02618444 0.
...: 03073195 -0.07522035 -0.00805568 0.05134711 0.01226415 -0.01922073 0.02499216 0.01480277 0.005939888 0.02740019 -0.007221481 -0.008180852 0.03079132 0.
...: 02221892 -0.09397198 0.0006076556 0.02956847 -0.0363856 0.03460713 0.01634974 0.01089886 0.0822057 -0.008049296 0.009631585 0.0568191 -0.02234845 -0.01
...: 608458 -0.04806978 -0.05295536 0.02976446 0.02290896 0.005668058 0.00426801 0.007513668 -0.03325405 -0.0145233 -0.007884383 -0.04083884 0.002169831 0.0
...: 06858787 0.00686969 -0.008723632 -0.03914807 -0.01512483 0.002803016 0.01384272 0.02919035 -0.01326019 -0.001008323 -0.02860635 0.02909619 0.05683269 0
...: .009913826 0.008573316 -0.01170192"
the first number of bias is 0.04767551
so the first col of first row of tdnn1.affine value must be
In [24]: sum([float(c)*float(d) for c,d in zip(a.split(), b.split())])+0.04767551
Out[24]: -0.05162175507930113
but the same position of kaldi's tdnn1.affine result is -0.08376444
So I suspect that there must be some other operation than only affine.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#3940?email_source=notifications&email_token=AAZFLO6UKK6EOFGFBGV4H6LRFJAVVA5CNFSM4KXSLYMKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOENM4LWI#issuecomment-593085913>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAZFLO22VVWS6HJOOSS4R2DRFJAVVANCNFSM4KXSLYMA>
.
|
|
So I must debug kaldi to find some hint. let me try it. |
|
Use high verbose level, like 4 or 5.
…On Sun, Mar 1, 2020 at 7:58 PM fanlu ***@***.***> wrote:
So I must debug kaldi to find some hint. let me try it.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#3940?email_source=notifications&email_token=AAZFLO3X57NZTWVDOPTVPX3RFJEUXA5CNFSM4KXSLYMKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOENM5CFY#issuecomment-593088791>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAZFLO24CBPO2M2ZKQJREK3RFJEUXANCNFSM4KXSLYMA>
.
|
|
Hi,Dan. Is there a convenient way to print one row data in kaldi c++ code? |
|
High verbose level is easiest way. Else mat.Row(10).Write(std::cerr,
false);
…On Sun, Mar 1, 2020 at 8:04 PM fanlu ***@***.***> wrote:
Hi,Dan. Is there a convenient way to print one row data in kaldi c++ code?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#3940?email_source=notifications&email_token=AAZFLO6YRSOB23PS27BVLMLRFJFMNA5CNFSM4KXSLYMKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOENM5G3I#issuecomment-593089389>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAZFLO76LDNSKB5EBZS6DWLRFJFMNANCNFSM4KXSLYMA>
.
|
|
OK. Thanks. |
support distributed training across multiple GPUs.
TODOs:
Part of the training log
The training seems working.