Ok, finally we'll actually train a machine learning system!!
The goal is to separata data like this
def generate_data(N):
s1 = np.random.multivariate_normal([1,1],[[1,0],[0,1]], size = N)
s2 = np.random.multivariate_normal([-1.5,-1.5],[[1,0.2],[0.2,1.0]], size = N)
X = np.concatenate([s1,s2])
z = np.concatenate([np.ones(N),np.zeros(N)])
return X,z
X,z = generate_data(200)
plt.scatter(X[:,0],X[:,1],c = z)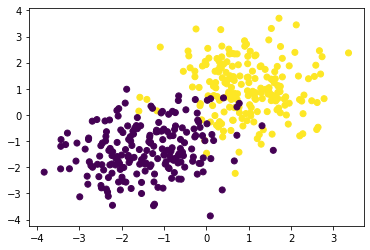
We assume the data is produced from a conditional model
Following the "amortized variational inference" approach, we assume that we can approximate
The plan is to train a "soft" percepton as discussed in the lecture
such that
We will break this down into three function and combine all parameters into a single parameter vector
-
First the linear mapping:
$h(x) = \vec{w} x + b$ mapping$h: \mathbb{R}^2 \to \mathbb{R}$ def linear(x,parameters): out = x @ parameters[:2].T + parameters[2] return out
-
Second, the squashing function
$\sigma: \mathbb{R} \to [0,1]$ def sigmoid(x): out = 1/(1+np.exp(-x)) return out
-
Third, the loss function
$l(z,\theta) = -\log q(z_i|\theta)$ def loss(z, theta): out = np.where(z==1,-np.log(theta),-np.log(1-theta)) return out
In order to estimate the loss for the full dataset, we need to compute the empirical risk
def empirical_risk(X,z,pars):
mapped = linear(X,pars)
theta = sigmoid(mapped)
loss_val = loss(z,theta)
return loss_val.mean(axis=0)We can can plot the decision function
def plot(X,z,pars):
grid = np.mgrid[-5:5:101j,-5:5:101j]
Xi = np.swapaxes(grid,0,-1).reshape(-1,2)
p = sigmoid(linear(X,pars))
zi = sigmoid(linear(Xi,pars))
zi = zi.reshape(101,101).T
plt.contour(grid[0],grid[1],zi)
plt.scatter(X[:,0],X[:,1],c = z)
plt.xlim(-5,5)
plt.ylim(-5,5)Use the above functions to plot the percepton and the data for a fixed parameter vector
In order to train the perceptron we need to have the empirical risk value and its derivative
Using the definitions we get
That is, if we just need to find an expression for
Derive an expression for the the derivative
Show that the derivative of
Derive the derivative of
Adapt the functions linear(..), sigmoid(...), loss(...) such that they return
- The function value
- The gradient value at the point at which the function was evaluated
def function(...)
out = ...
grad = ...
return out,grad
Hint: as we will evluate the function on many inputs at the same time make sure to return a "column" vector of shape (N,1) for the sigmoid and loss functions
Using the chain rule and the individual gradient computations, adapt empirical_risk similarly to return
$\hat{L}$ $\frac{\partial \hat{L}}{\partial \phi}$
Write a Training Loop!
- Initialize the parameters with
$\phi = (1.0,0.0,0.0)$ - Allow 2000 iterations of improving the parameters
- For each iteration update the parameters with Gradient Descent and a Learning Rate of
$\lambda=0.01$
- After every 500 steps, plot the current configuration using
plot(...)(Note: now that the functions return multiple return values, theplotfunction needs to be adapted a bit
Congratulations, you wrote your first full ML loop!. You can now play with the details of generate_data to try out a few data configurations and
convince yourself that your algorithm will find a good decision boundary every time.