| description | How we reduce suffering using a decentralized autonomous organization as a vehicle to use the oceans of real-world evidence to discover new cures. |
|---|---|
| emoji | 🎯 |
| title | Personalized Precision Medicine Framework |
| tags | precision-medicine, insilico-models, machine-learning, genomics, transcriptomics, proteomics, metabolomics, microbiomics, phenotype |
| published | true |
| editor | markdown |
| date | 2025-02-11T14:02:49.420Z |
| dateCreated | 2025-02-11T14:02:49.420Z |
Out of an existing pool of big health data, an insilico model of human biology can be developed to discover new interventions and their personalized dosages and combinations.
One way to achieve this is to view the human body as a black box with inputs and outputs. We can apply predictive machine learning models to stratified groups of similar people based on the following aspects:
- Genomic
- Transcriptomic
- Proteomic
- Metabolomic
- Microbiomic
- Phenotype
- Diseasomic
- Pharmacomicrobiomic
- Pharmacogenomic
- Foodomic
- Exposome
This will enable the discovery of the full personalized range of positive and negative relationships for all factors without a profit incentive for traditional trials.

- Diagnostics - Data mining and analysis to identify causes of illness
- Preventative medicine - Predictive analytics and data analysis of genetic, lifestyle, and social circumstances to prevent disease
- Precision medicine - Leveraging aggregate data to drive hyper-personalized care
- Medical research - Data-driven medical and pharmacological research to cure disease and discover new treatments and medicines
- Reduction of adverse medication events - Harnessing of big data to spot medication errors and flag potential adverse reactions
- Cost reduction - Identification of value that drives better patient outcomes for long-term savings
- Population health - Monitor big data to identify disease trends and health strategies based on demographics, geography, and socioeconomic
Failed drug applications are expensive. A global database of treatments and outcomes could provide information that could avoid massive waste on failed trials.
- A 10% improvement in predicting failure before clinical trials could save $100 million in development costs.
- Shifting 5% of clinical failures from Phase III to Phase I reduces out-of-pocket costs by $15 to $20 million.
- Shifting failures from Phase II to Phase I would reduce out-of-pocket costs by $12 to $21 million.
- In phase II studies, the typical decentralized clinical trial (DCT) deployment produced a 400% return on investment in terms of trial cost reductions.
- In phase III studies, decentralization produced a 1300% return on investment.
When people think of observational research, they typically think of correlational association studies.
Why It Seems Like Diet Advice Flip-Flops All the Time
In 1977, the USDA and Time Magazine warned Americans against the perils of dietary cholesterol. Yet, in 1999, TIME released a very different cover, suggesting that dietary cholesterol is fine.

There are two primary ways of undertaking studies to find out what affects our health:
- observational studies - the easier of the two options. They only require handing out questionnaires to people about their diet and lifestyle habits, and then again a few years later to find out which patterns are associated with different health outcomes.
- randomized trials - the far more expensive option. Two groups of randomly selected people are each assigned a different intervention.
The most significant benefit of randomized trials is the "control group". The control group consists of the people who don't receive the intervention or medication in a randomly-controlled trial. It helps to overcome the confounding variable problem that plagues observational studies.
A common source of confounding variables in correlational association studies is the "healthy person bias". For instance, say an observational study finds "People Who Brush Teeth Less Frequently Are at Higher Risk for Heart Disease". It may just be a coincidence caused by a third confounding variable. People that brush their teeth more are more likely to be generally concerned about their health. So, the third confounding factor could be that people without heart disease could also exercise more or eat better.
However, the massive amount of automatically collected, high-frequency longitudinal data we have today makes it possible to overcome the flaws with traditional observational research.
The primary flaw with observational research is that they lack the control group. However, a single person can act as their own control group with high-frequency longitudinal data. This is done by using an A/B experiment design.

For instance, if one is suffering from arthritis and they want to know if a Turmeric Curcumin supplement helps, the experimental sequence would look like this:
- Month 1: Baseline (Control Group) - No Curcumin
- Month 2: Treatment (Experimental Group) - 2000mg Curcumin/day
- Month 3: Baseline (Control Group) - No Curcumin
- Month 4: Treatment (Experimental Group) - 2000mg Curcumin/day
The more this is done, the stronger the statistical significance of the observed change from the baseline. However, there are also effects from other variables. These can be addressed using a diffusion-regression state-space model that predicts the counter-factual response. This involves the creation of a synthetic control group. This artificial control illustrates what would have occurred had no intervention taken place. In contrast to classical difference-in-differences schemes, state-space models make it possible to:
- infer the temporal evolution of attributable impact
- incorporate empirical priors on the parameters in a fully Bayesian treatment
- flexibly accommodate multiple sources of variation, including:
- local trends
- seasonality
- the time-varying influence of contemporaneous covariates
At this time, we apply coefficients representative of each of Hill's criteria for causation to quantify the likelihood of a causal relationship between two measures as:
- Strength Coefficient: A relationship is more likely to be causal if the correlation coefficient is large and statistically significant. This is determined through the use of a two-tailed t-test for significance.
- Consistency Coefficient: A relationship is more likely to be causal if it can be replicated. This value is related to the variation of the average change from baseline for other participants with the same treatment outcome variables in conjunction with the variation in average change from multiple experiments in the same individual.
- Specificity Coefficient: A relationship is more likely to be causal if there is no other plausible explanation. Relationships are calculated based on different potential predictor variables available for the individual over the same period. The value of the Specificity Coefficient starting at one is decreased by the strength of the most robust relationship of all other factors.
- Temporality Coefficient: A relationship is more likely to be causal if the effect always occurs after the cause.
- Gradient Coefficient: The relationship is more likely to be causal if more significant exposure to the suspected cause leads to a greater effect. This is represented by the k-means squared difference between the normalized pharmacokinetic time-lagged treatment outcome curves.
- Plausibility Coefficient: A relationship is more likely to be causal if a plausible mechanism exists between the cause and the effect. This is derived from the sum of the crowd-sourced plausibility votes on the study.
- Coherence: A relationship is more likely to be causal if compatible with related facts and theories. This is also derived from the sum of the crowd-sourced plausibility votes on the study.
- Experiment Coefficient: A relationship is more likely to be causal if it can be verified experimentally. This coefficient is proportional to the number of times an A/B experiment is run.
- Analogy: A relationship is more likely to be causal if there are proven relationships between similar causes and effects. This coefficient is proportional to the consistency of the result for a particular individual with the number of other individuals who also observed a similar effect.

Observational real-world evidence-based studies have several advantages over randomized, controlled trials, including lower cost, increased speed of research, and a broader range of patients. However, concern about inherent bias in these studies has limited their use in comparing treatments. Observational studies have been primarily used when randomized, controlled trials would be impossible or unethical.
However, meta-analyses found that:
when applying modern statistical methodologies to observational studies, the results are generally not quantitatively or qualitatively different from those obtained in randomized, controlled trials.


There is compelling historical evidence suggesting that large scale efficacy-trials based on real-world evidence have ultimately led to better health outcomes than current pharmaceutical industry-driven randomized controlled trials.
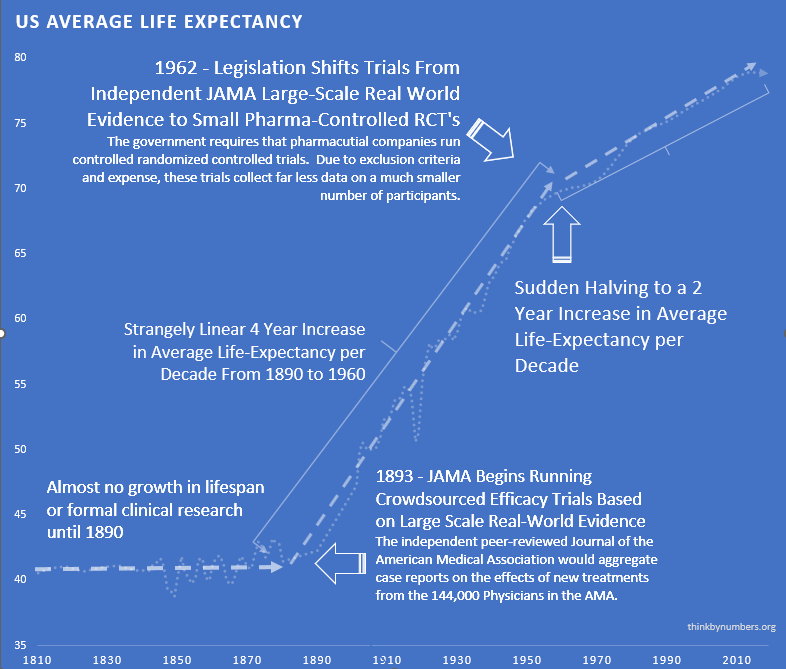
For over 99% of recorded human history, the average human life expectancy has been around 30 years.
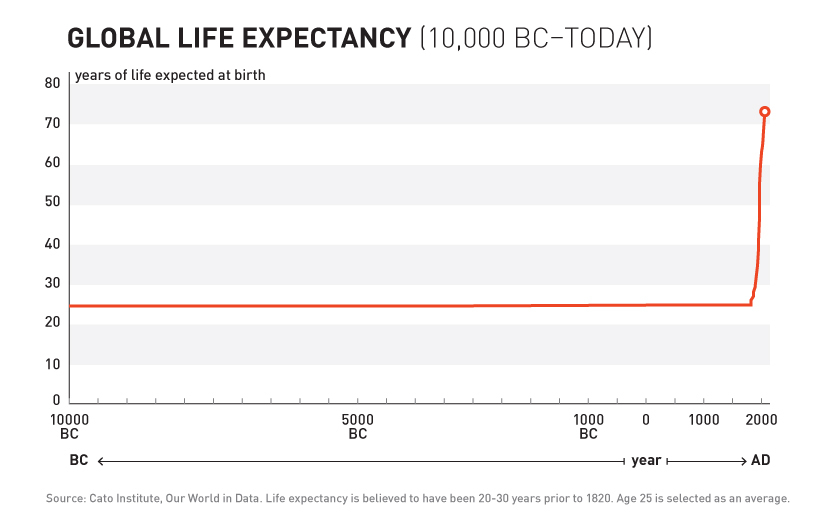
In the late nineteenth and early twentieth century, clinical objectivity grew. The independent peer-reviewed Journal of the American Medical Association (JAMA) was founded in 1893. It would gather case reports from the 144,000 physicians members of the AMA on the safety and effectiveness of drugs. The leading experts in the area of a specific medicine would review all of the data and compile them into a study listing side effects and the conditions for which a drug was or was not effective. If a medicine were found to be safe, JAMA would give its seal of approval for the conditions where it was found to be effective.
The adoption of this system of crowd-sourced, observational, objective, and peer-reviewed clinical research was followed by a sudden shift in the growth of human life expectancy. After over 10,000 years of almost no improvement, we suddenly saw a strangely linear 4-year increase in life expectancy every single year.
A drug called Elixir sulfanilamide caused over 100 deaths in the United States in 1937.
Congress reacted to the tragedy by requiring all new drugs to include:
"adequate tests by all methods reasonably applicable to show whether or not such drug is safe for use under the conditions prescribed, recommended, or suggested in the proposed labeling thereof."
These requirements evolved to what is now called the Phase 1 Safety Trial.
This consistent four-year/year increase in life expectancy remained unchanged before and after the new safety regulations.
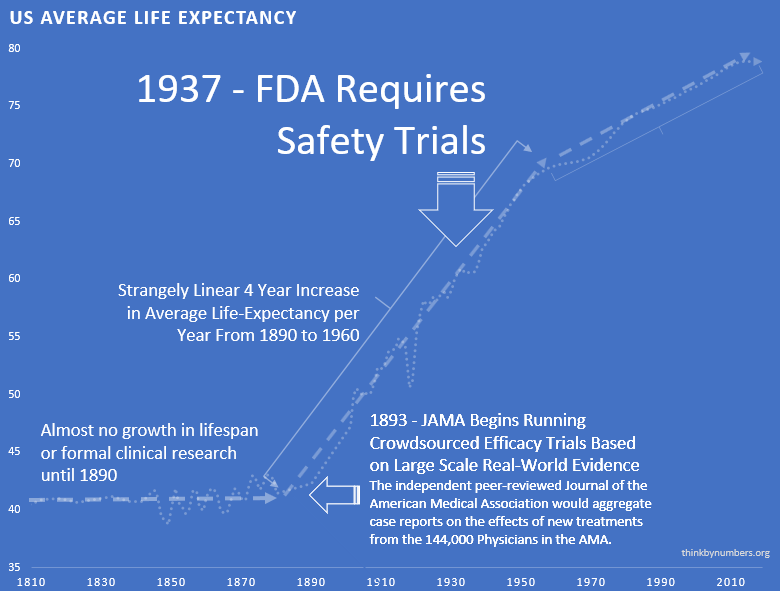
This suggests that the regulations did not have a large-scale positive or negative impact on the development of life-saving interventions.
Thalidomide was first marketed in Europe in 1957 for morning sickness. While it was initially thought to be safe in pregnancy, it resulted in thousands of horrific congenital disabilities.
Fortunately, the existing FDA safety regulations prevented any birth defects in the US. Despite the effectiveness of the existing US regulatory framework in protecting Americans, newspaper stories such as the one below created a strong public outcry for increased regulation.

As effective safety regulations were already in place, the government instead responded to the Thalidomide disaster by regulating efficacy testing via the 1962 Kefauver Harris Amendment. Before the 1962 regulations, it cost a drug manufacturer an average of $74 million (2020 inflation-adjusted) to develop and test a new drug for safety before bringing it to market. Once the FDA had approved it as safe, efficacy testing was performed by the third-party American Medical Association. Following the regulation, trials were instead to be conducted in small, highly-controlled trials by the pharmaceutical industry.
Reduction in Efficacy Data
The 1962 regulations made these large real-world efficacy trials illegal. Ironically, even though the new regulations were primarily focused on ensuring that drugs were effective through controlled FDA efficacy trials, they massively reduced the quantity and quality of the efficacy data that was collected for several reasons:
- New Trials Were Much Smaller
- Participants Were Less Representative of Actual Patients
- They Were Run by Drug Companies with Conflicts of Interest Instead of the 3rd Party AMA
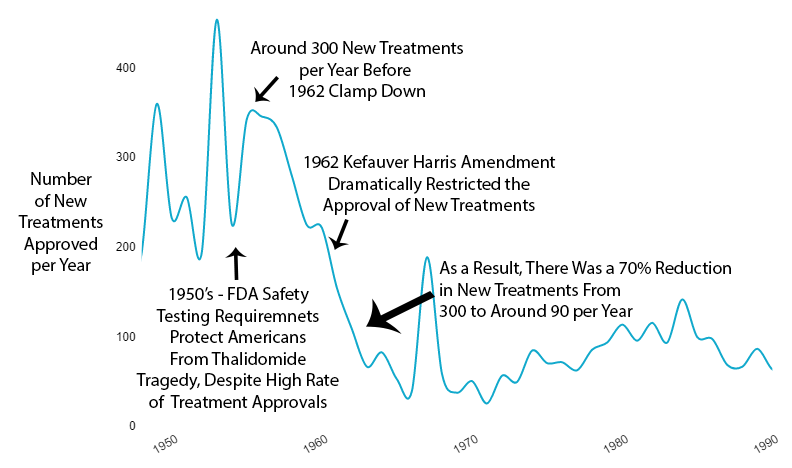
Reduction in New Treatments
The new regulatory clampdown on approvals immediately reduced the production of new treatments by 70%.
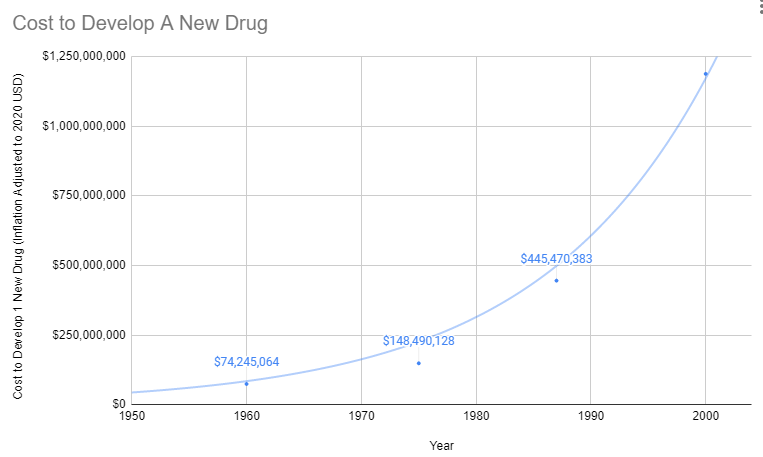
Explosion in Costs
Since the abandonment of the former efficacy trial model, costs have exploded. Since 1962, the cost of bringing a new treatment to market has gone from $74 million to over $1 billion US dollars (2020 inflation-adjusted).
High Cost of Development Favors Monopoly and Punishes Innovation
There's another problem with the increasing costs of treatment development. In the past, a genius scientist could come up with a treatment, raise a few million dollars, and do safety testing. Now that it costs a billion dollars to get a drug to market, the scientist has to persuade one of a few giant drug companies that can afford it to buy his patent.
Then the drug company has two options:
Option 1: Risk $1 billion on clinical trials
Possibility A: Drug turns out to be one of the 90% the FDA rejects. GIVE BANKER A BILLION DOLLARS. DO NOT PASS GO.
Possibility B: Drug turns out to be one of the 10%, the FDA approves. Now it's time to try to recover that billion dollars. However, very few drug companies have enough money to survive this game. So, this company almost certainly already has an existing inferior drug on the market to treat the same condition. Hence, any profit they make from this drug will likely be subtracted from revenue from other drugs they've already spent a billion dollars on.
Option 2: Put the patent on the shelf
Do not take a 90% chance of wasting a billion dollars on failed trials. Do not risk making your already approved cash-cow drugs obsolete.
What's the benefit of bringing better treatment to market if you're just going to lose a billion dollars? Either way, the profit incentive is entirely in favor of just buying better treatments and shelving them.
Cures Are Far Less Profitable Than Lifetime Treatments
If the new treatment is a permanent cure for the disease, replacing a lifetime of refills with a one-time purchase would be economically disastrous for the drug developer. With a lifetime prescription, a company can recover its costs over time. Depending on the number of people with the disease, one-time cures would require a massive upfront payment to recover development costs.
How is there any financial incentive for medical progress at all?
Fortunately, there isn't a complete monopoly on treatment development. However, the more expensive it is to get a drug to market, the fewer companies can afford the upfront R&D investment. So the drug industry inevitably becomes more monopolistic. Thus there are more situations where the cost of trials for a superior treatment exceeds the profits from existing treatments.
Slowed Growth in Life Expectancy
From 1890 to 1960, there was a linear 4-year increase in human lifespan every year. This amazingly linear growth rate had followed millennia with a flat human lifespan of around 28 years. Following this new 70% reduction in the pace of medical progress, the growth in human lifespan was immediately cut in half to an increase of 2 years per year.
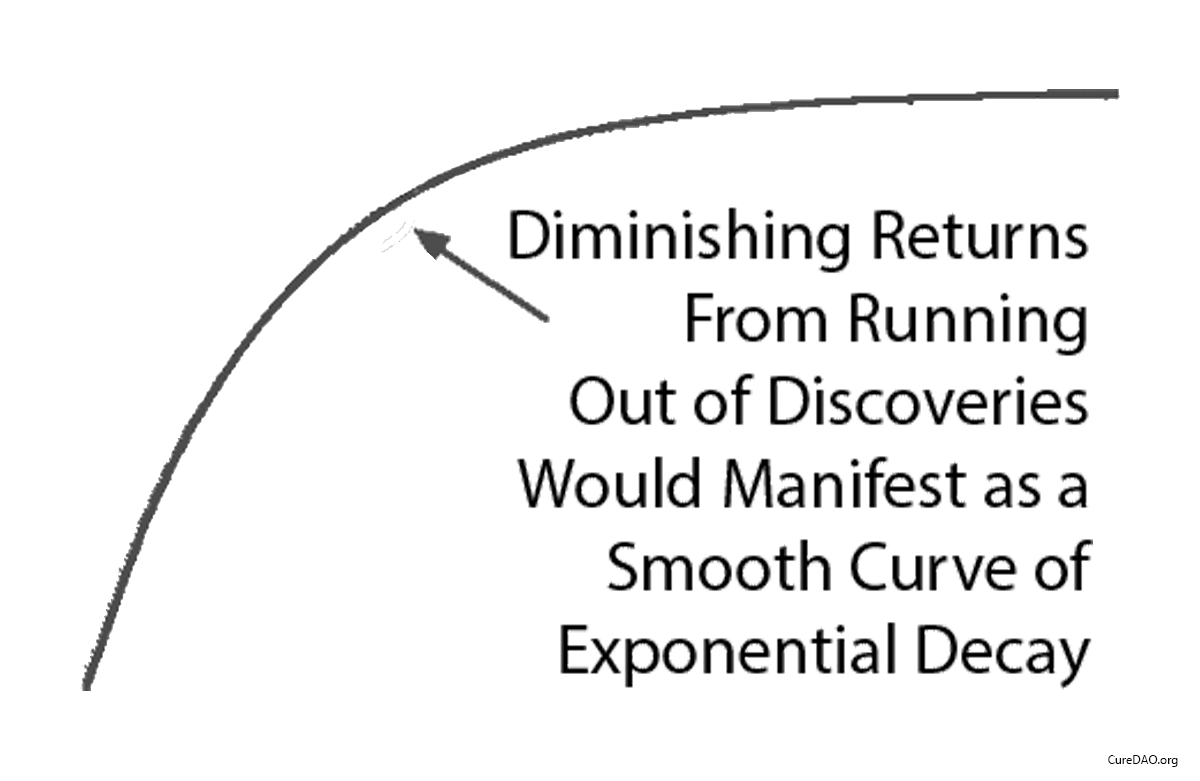
Diminishing Returns?
One might say “It seems more likely — or as likely — to me that drug development provides diminishing returns to life expectancy.” However, diminishing returns produce a slope of exponential decay. It may be partially responsible, but it’s not going to produce a sudden change in the linear slope of a curve a linear as life expectancy was before and after the 1962 regulations.
Correlation is Not Causation
You might say "I don't know how much the efficacy regulations contribute to or hampers public health. I do know that correlation does not necessarily imply causation." However, a correlation plus a logical mechanism of action is the least bad method we have for inferring the most likely significant causal factor for an outcome (i.e. life expectancy). Assuming most likely causality based on temporal correlation is the entire basis of a clinical research study and the scientific method generally.
Impact of Innovative Medicines on Life Expectancy
A three-way fixed-effects analysis of 66 diseases in 27 countries, suggests that if no new drugs had been launched after 1981, the number of years of life lost would have been 2.16 times higher it actually was. It estimates that pharmaceutical expenditure per life-year saved was $2837.

More people survive as more treatments are developed. There's a strong correlation between the development of new cancer treatments and cancer survival over 30 years.
