Replies: 3 comments 7 replies
-
|
Hi @keithrse Before we dive into a way to circumvent the XML changes, is using a There are a couple of ways in which you could circumvent this huge XML generation. Have you measured the parsing and scene loading? Is this also worth improving or is the JIT-compilation the main pain point for your use case? |
Beta Was this translation helpful? Give feedback.
-
|
Hi @njroussel Yes we do need to be able to use other variants specifically we want to run cuda_variants but we're also testing with llvm as well, for several reasons 1) we run on heterogeneous clusters and 2) we will likely need to run these large renders millions of times. So in essence yes, the render is too slow using a scalar variant. Now as for timing, our results look like this this was with 10^6 spot type emitters, the xml file is about 200mb, we were running with the llvm_mono variant on a single thread (as a test) and as you can see its the drjit compilation thats taking the time Thanks Keith |
Beta Was this translation helpful? Give feedback.
-
|
This ☝️ is the in-depth answer as to what is currently happening in your setup. Depending on what you're doing, writing everything yourself from scratch by using some Mitsuba "primitives" like |
Beta Was this translation helpful? Give feedback.
-
|
We've change most emitter & sensors to use |
Beta Was this translation helpful? Give feedback.
-
|
Thanks Nicolas, yes this modification has drastically reduced the drjit compilation time and seems to have reduced the xml parsing time as well. we're still in the minutes for compilation and seconds for rendering, however, this is a significant step forward Ill include the output so you can see the progress! |
Beta Was this translation helpful? Give feedback.
-
|
Fantastic! Is there a specific reason why you are rendering with just one thread? ( A compilation time of 8 minutes is still quite a lot. Could you tell me more about your scene's contents? Other than their position, do the spot lights differ in any other way? Are there other plugins which are used more than once? |
Beta Was this translation helpful? Give feedback.
-
|
Hi Nicolas, I was just running on one thread to get comparable results to previous tests, obviously for production runs we'd use the max number of threads possible. As far as I know, the spots only differ in position and direction, in reality they would also differ in wavelength as well, however, we're currently using mono variants Thanks Keith |
Beta Was this translation helpful? Give feedback.
-
|
Hi Nicolas, I've been using the most recent updates you've applied and as I said it now allows us to run 10^6 emitter renders at least using llvm which is great. However, I'm struggling to run the same renders using cuda variants which Im trying to understand. I think the issue is due to the large amount of memory the kernel seems to require (during compilation). I've attached a 10^6 emitter output from a llvm variant. The JIT compiler reports a table size of 27Gb, if this would be the same for a cuda variant and held on the device it would easily exceed our GPUs global memory. I've profiled a 10^6 emitter cuda variant render (which did not complete) and it certainly saturates the GPUs memory but does not crash. I think the JIT compiler is (maybe) overflowing into system memory and trying to transfer data from HtoD and back which would explain the slowness, but thats just a guess. If I'm vaguely correct about the cause of the issue, how would I go about reducing the memory usage?
|
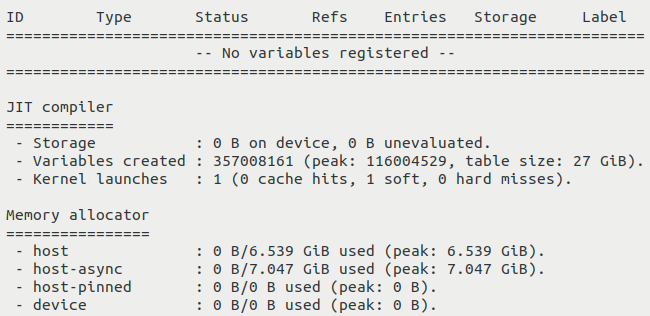
Beta Was this translation helpful? Give feedback.
-
|
Hi @keithrse The 27GiB is the JIT's memory, which is used to track variables and their types. This is host memory. When running the CUDA variant, do you not get any logs at all? If it were to overflow as you describe, I believe you should see this warning message. Also, if you run your setup through a debugger, could you tell me where exactly it is "hanging"? There are a few different steps in the JIT-compilation process. I would recommend that you implement your own custom |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
Hi,
We;re trying to use mitsuba to simulate photon propagation and we need to be able put 10^6 and about photons into each render (all with different positions, directions, wavelengths etc). at the moment we're doing this in an inefficient manor which involves xml files with 10^6 defined emitters. These scenes are taking hours to compile with drjit (for cuda/llvm variants). We've been led to understandn that we can replace 10^6 emitters with 1 emitter which has 10^6 positions passed to it in vector format. I've checked though the documentation and its not entirely clear how to use this vectorised format.
so we currently have something like this :
but 10^6 times in a single file
how would we go about making this emitter, emit from two different positions?
like this prehaps?
Thank You
Beta Was this translation helpful? Give feedback.
All reactions