-
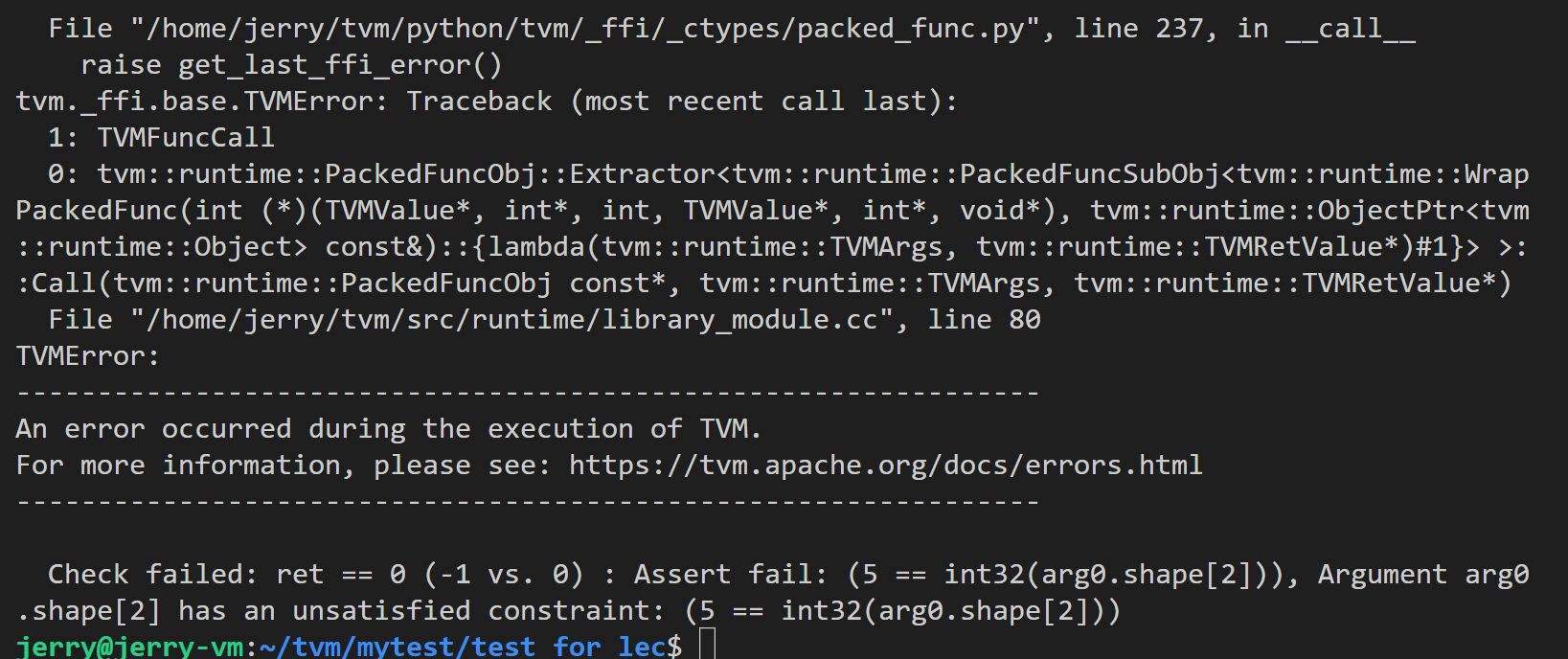
程序错误求解——关于课程中用prim_func的方式实现卷积的个人拓展尝试1. 目的说明观看了前几期的课程,于是本人尝试希望实现并查看:将一个较大的卷积算子(例如输入为 data1x1x8x8, weight 2x1x3x3,输出为 1x2x6x6)分解为多个较小的卷积算子(例如输入为 data1x1x5x5, weight 2x1x3x3,输出为 1x2x3x3)分别进行运算,类似分治法的思想,最后将多个输出汇总到一起成为1x2x6x6 的总输出。 通过上面两种实现方式,比较是否会有优化效果。但是现在遇到了问题,希望能够给我一些建议。 2. 过程说明通过python将1x1x8x8的data切分为4个1x1x5x5的小data,通过验证,两种方式得到的结果是一致的。并且用单个小data可以通过prim_func的方式正确得到对应的部分输出。 3. 错误说明其实有两个错误
4.程序报错截图
5. 程序split4Conv2d.py 用for4循环实现的prim_func: N, CI, H, W, CO, K = 1, 1, 8, 8, 2, 3
OUT_H, OUT_W = H-K+1, W-K+1
# r_d=0
# c_d=0
@tvm.script.ir_module
class MySplit4Conv:
@T.prim_func
def conv(A: T.Buffer[ (1, 1, 8, 8), "int64"],
B: T.Buffer[ (2, 1, 3, 3), "int64"],
C: T.Buffer[ (1, 2, 6, 6), "int64"]):
T.func_attr({"global_symbol":"conv", "tir.noalias":True})
# tmp
Y = T.alloc_buffer(( 1, 1, 5, 5), dtype="int64")
# r_d = T.var("int32")
# c_d = T.var("int32")
r_d = T.alloc_buffer((1,2), dtype="int32")
r_d[0,0] = T.int32(0)
r_d[0,1] = T.int32(0)
for num in T.grid(4):
for tt, ttt, row, col in T.grid(1, 1, 5, 5):
with T.block("Y"):
dd = T.axis.spatial(1, tt)
ddd = T.axis.spatial(1, ttt)
rr = T.axis.spatial(5, row)
cc = T.axis.spatial(5, col)
Y[dd, ddd, rr, cc] = A[dd, ddd,rr+r_d[0,0],cc+r_d[0,1]]
# Y[dd, ddd, rr, cc] = A[dd, ddd,rr+T.int64(3)*(num/2),cc+T.int64(3)*(num%2)]
# compute Y
# store little convd Y to C
for b, k, i, j in T.grid(1, 2, 3, 3):
with T.block("C"):
vb = T.axis.spatial(1, b)
vk = T.axis.spatial(2, k)
vi = T.axis.spatial(3, i)
vj = T.axis.spatial(3, j)
for di, dj in T.grid(3,3):
with T.init():
C[vb, vk, vi, vj] = T.int64(0)
C[vb, vk, vi+r_d[0,0], vj+r_d[0,1]] += Y[vb, 0, vi+di, vj+dj]*B[vk, 0,di, dj ]
# reset r_d, c_d
if (r_d[0,0]== 0 and r_d[0,1]==0):
r_d[0,1] = 3
elif (r_d[0,0]==0 and r_d[0,1]==3):
r_d[0,0] = 3
r_d[0,1] = 0
elif (r_d[0,0]== 3 and r_d[0,1]==0):
r_d[0,1]= 3
完整代码: """
这一节就是尝试将一个大的Conv2D运算分解为多个小的Conv2D进行求解
然后最终组合得出,然后看时间
关键的一点是,应该分别尝试relay和TensorIR 这样做的效果。
"""
from pydoc import tempfilepager
from graphviz import view
import numpy as np
from torch import row_stack
import tvm
from tvm.ir.module import IRModule
from tvm.script import tir as T
# Exercise 2: 2D Convolution 2D卷积
# 二维卷积,这是图像处理中常见的操作。
# 其中,A 是输入张量,
# W 是权重张量,
# b 是批量指标,
# k 是输出通道,
# i 和 j 是图像高度和宽度的指标,
# di 和 dj 是权重指标,
# q 是输入通道,
# strides 是过滤窗口的步幅。
# 在这个练习中,我们选择了一个小而简单的情况,大步 = 1,填充 = 0。
N, CI, H, W, CO, K = 1, 1, 8, 8, 2, 3
OUT_H, OUT_W = H-K+1, W-K+1
data = np.arange(N*CI*H*W).reshape(N, CI, H, W)
weight = np.arange(CO*CI*K*K).reshape(CO, CI, K, K)
# 这里没有运行,但是在python 的shell中运行得出了结果
# 输入: data:1*1*8*8,四维矩阵,(默认左上到右下) 0-63
# weight: 2*1*3*3, 四维矩阵, 两个3*3, 分别是0-8和9-17,
# 这个其实就是可以看作是两个卷积核,对应最后得到的两个输出结果
# 输出: 1*2*6*6, 两个6*6,
# 1. 474-2094, 同行相邻间隔为36,同列相邻间隔为288
# 2. 1203-6468, 同行相邻间隔为117,同列相邻间隔为936
# 尝试TensorIR实现,这是一个完整的conv的实现:1*1*8*8
@tvm.script.ir_module
class MyConv:
@T.prim_func
def conv(A: T.Buffer[ (1, 1, 8, 8), "int64"],
B: T.Buffer[ (2, 1, 3, 3), "int64"],
C: T.Buffer[ (1, 2, 6, 6), "int64"]):
T.func_attr({"global_symbol":"conv", "tir.noalias":True})
for b, k, i, j in T.grid(1, 2, 6, 6):
with T.block("C"):
vb = T.axis.spatial(1, b)
vk = T.axis.spatial(2, k)
vi = T.axis.spatial(6, i)
vj = T.axis.spatial(6, j)
for di, dj in T.grid(3,3):
with T.init():
C[vb, vk, vi, vj] = T.int64(0)
C[vb, vk, vi, vj] += A[vb, 0, vi+di, vj+dj]*B[vk, 0,di, dj ]
# C[vb, vk, vi, vj] += T.int64(1)
rt_lib = tvm.build(MyConv, target="llvm")
data_tvm = tvm.nd.array(data)
weight_tvm = tvm.nd.array(weight)
conv_tvm = tvm.nd.array(np.empty((N, CO, OUT_H, OUT_W), dtype=np.int64))
rt_lib["conv"](data_tvm, weight_tvm, conv_tvm)
# print("data_tvm:\n", data_tvm)
# print("weight_tvm:\n", weight_tvm)
# print("conv_tvm:\n",conv_tvm)
# np.testing.assert_allclose(conv_tvm.numpy(), conv_torch, rtol=1e-5)
f_timer_conv = rt_lib.time_evaluator("conv", tvm.cpu())
# print("Time cost of MyConv %g sec" % f_timer_conv(data_tvm, weight_tvm, conv_tvm).mean)
print("Time cost of MyConv %f ms" % (f_timer_conv(data_tvm, weight_tvm, conv_tvm).mean*1e3))
# 开始分割,也就是比如说把原始的1*1*8*8的四维矩阵
# 先分成4(变量n)个1*1*4*4 的矩阵,
# 不对这里应该考虑卷积的实际运算过程
# 如果只是单纯这样分的话,
# 那么实际运算到的只有前两个元素,
# 后面两个元素无法计算。
# 所以不能这样单纯的划分。
len = 8 # 矩阵的高和宽
row_begin = 0
col_begin = 0
dist = 5
row_end = row_begin + dist
col_end = col_begin + dist
mat1 = data[0:,0:,row_begin:row_end, col_begin:col_end]
# print("mat1:\n", mat1)
# mat1 = data[0,0,row_begin:row_end, col_begin:col_end]
col_step = dist - 2
row_step = dist - 2
col_begin += col_step
col_end = col_begin + dist
mat2 = data[0:,0:,row_begin:row_end,col_begin:col_end]
# print("mat2:\n", mat2)
row_begin += row_step
row_end = row_begin + dist
col_begin = 0
col_end = col_begin + dist
mat3 = data[0:,0:,row_begin:row_end,col_begin:col_end]
# print("mat3:\n", mat3)
col_begin += col_step
col_end = col_begin + dist
mat4 = data[0:,0:,row_begin:row_end,col_begin:col_end]
# print("mat4:\n", mat4)
# 如上面,将大矩阵切分成 4个小矩阵
# 然后就是比较这种方式是否加快了运行速度。
# 这里的话,看针对这些原本的简单四维如果前面都是1*1,
# 那么是不是直接转变为二维的矩阵运算会更加简单
# 分成5*5其实很好,因为可以算3个,最终结果是6*6,
# 这一步的本质其实是分成了4个1*1*5*5的小矩阵,
# 然后分别和weight初始矩阵进行计算:这里的做法并没有将weight切分。
# 分成4*4也行,正好等会儿比较看看。
# 这里先拿 mat1 和weight进行运算看一下。
import torch
data_torch = torch.Tensor(mat4)
weight_torch = torch.Tensor(weight)
mat1_torch = torch.nn.functional.conv2d(data_torch, weight_torch)
mat1_torch = mat1_torch.numpy().astype(np.int64)
# print("mat1_torch:\n", mat1_torch)
# 尝试TensorIR实现,这是分割后小矩阵1*1*5*5的实现
N, CI, H, W, CO, K = 1, 1, 5, 5, 2, 3
OUT_H, OUT_W = H-K+1, W-K+1
@tvm.script.ir_module
class MyLittleConv:
@T.prim_func
def conv(A: T.Buffer[ (1, 1, 5, 5), "int64"],
B: T.Buffer[ (2, 1, 3, 3), "int64"],
C: T.Buffer[ (1, 2, 3, 3), "int64"]):
T.func_attr({"global_symbol":"conv", "tir.noalias":True})
for b, k, i, j in T.grid(1, 2, 3, 3):
with T.block("C"):
vb = T.axis.spatial(1, b)
vk = T.axis.spatial(2, k)
vi = T.axis.spatial(3, i)
vj = T.axis.spatial(3, j)
for di, dj in T.grid(3,3):
with T.init():
C[vb, vk, vi, vj] = T.int64(0)
C[vb, vk, vi, vj] += A[vb, 0, vi+di, vj+dj]*B[vk, 0,di, dj ]
mat_lib = tvm.build(MyLittleConv, target="llvm")
data_tvm = tvm.nd.array(mat1)
weight_tvm = tvm.nd.array(weight)
mat_tvm = tvm.nd.array(np.empty((N, CO, OUT_H, OUT_W), dtype=np.int64))
mat_lib["conv"](data_tvm, weight_tvm, mat_tvm)
print("mat_tvm:\n", mat_tvm)
f_timer_little_conv = mat_lib.time_evaluator("conv", tvm.cpu())
print("Time cost of MyLittleConv %f ms" % (f_timer_little_conv(data_tvm, weight_tvm, mat_tvm).mean*1e3))
# 然后尝试在TensorIR中直接分割计算Conv
# 希望能够使用python的多线程和协程
N, CI, H, W, CO, K = 1, 1, 8, 8, 2, 3
OUT_H, OUT_W = H-K+1, W-K+1
# r_d=0
# c_d=0
@tvm.script.ir_module
class MySplit4Conv:
@T.prim_func
def conv(A: T.Buffer[ (1, 1, 8, 8), "int64"],
B: T.Buffer[ (2, 1, 3, 3), "int64"],
C: T.Buffer[ (1, 2, 6, 6), "int64"]):
T.func_attr({"global_symbol":"conv", "tir.noalias":True})
# tmp
Y = T.alloc_buffer(( 1, 1, 5, 5), dtype="int64")
# r_d = T.var("int32")
# c_d = T.var("int32")
r_d = T.alloc_buffer((1,2), dtype="int32")
r_d[0,0] = T.int32(0)
r_d[0,1] = T.int32(0)
for num in T.grid(4):
for tt, ttt, row, col in T.grid(1, 1, 5, 5):
with T.block("Y"):
dd = T.axis.spatial(1, tt)
ddd = T.axis.spatial(1, ttt)
rr = T.axis.spatial(5, row)
cc = T.axis.spatial(5, col)
Y[dd, ddd, rr, cc] = A[dd, ddd,rr+r_d[0,0],cc+r_d[0,1]]
# Y[dd, ddd, rr, cc] = A[dd, ddd,rr+T.int64(3)*(num/2),cc+T.int64(3)*(num%2)]
# compute Y
# store little convd Y to C
for b, k, i, j in T.grid(1, 2, 3, 3):
with T.block("C"):
vb = T.axis.spatial(1, b)
vk = T.axis.spatial(2, k)
vi = T.axis.spatial(3, i)
vj = T.axis.spatial(3, j)
for di, dj in T.grid(3,3):
with T.init():
C[vb, vk, vi, vj] = T.int64(0)
C[vb, vk, vi+r_d[0,0], vj+r_d[0,1]] += Y[vb, 0, vi+di, vj+dj]*B[vk, 0,di, dj ]
# reset r_d, c_d
if (r_d[0,0]== 0 and r_d[0,1]==0):
r_d[0,1] = 3
elif (r_d[0,0]==0 and r_d[0,1]==3):
r_d[0,0] = 3
r_d[0,1] = 0
elif (r_d[0,0]== 3 and r_d[0,1]==0):
r_d[0,1]= 3
# @tvm.script.ir_module
# class MySplit4Conv:
# @T.prim_func
# def conv(A: T.Buffer[ (1, 1, 8, 8), "int64"],
# B: T.Buffer[ (2, 1, 3, 3), "int64"],
# C: T.Buffer[ (1, 2, 6, 6), "int64"]):
# T.func_attr({"global_symbol":"conv", "tir.noalias":True})
# # tmp
# Y = T.alloc_buffer((1, 1, 5, 5), dtype="int64")
# # r_d = T.Var(0)
# # c_d = T.int64(0)
# # r_d = T.alloc_buffer((1,2), dtype="int64")
# # r_d[0,0] = T.int32(0)
# # r_d[0,1] = T.int32(0)
# # 1.
# for tt, ttt, row, col in T.grid(1, 1, 5, 5):
# with T.block("Y"):
# dd = T.axis.spatial(1, tt)
# ddd = T.axis.spatial(1, ttt)
# rr = T.axis.spatial(5, row)
# cc = T.axis.spatial(5, col)
# Y[dd, ddd, rr, cc] = A[dd, ddd,rr,cc]
# # Y[dd, ddd, rr, cc] = A[dd, ddd,rr+T.int64(3)*(num/2),cc+T.int64(3)*(num%2)]
# # compute Y
# # store little convd Y to C
# for b, k, i, j in T.grid(1, 2, 3, 3):
# with T.block("C"):
# vb = T.axis.spatial(1, b)
# vk = T.axis.spatial(2, k)
# vi = T.axis.spatial(3, i)
# vj = T.axis.spatial(3, j)
# for di, dj in T.grid(3,3):
# with T.init():
# C[vb, vk, vi, vj] = T.int64(0)
# C[vb, vk, vi, vj] += Y[vb, 0, vi+di, vj+dj]*B[vk, 0,di, dj ]
# # 2.
# for tt, ttt, row, col in T.grid(1, 1, 5, 5):
# with T.block("Y"):
# dd = T.axis.spatial(1, tt)
# ddd = T.axis.spatial(1, ttt)
# rr = T.axis.spatial(5, row)
# cc = T.axis.spatial(5, col)
# # with T.init():
# Y[dd, ddd, rr, cc] = A[dd, ddd,rr,cc+T.int32(3)]
# # Y[dd, ddd, rr, cc] = A[dd, ddd,rr+T.int64(3)*(num/2),cc+T.int64(3)*(num%2)]
# # compute Y
# # store little convd Y to C
# for b, k, i, j in T.grid(1, 2, 3, 3):
# with T.block("C"):
# vb = T.axis.spatial(1, b)
# vk = T.axis.spatial(2, k)
# vi = T.axis.spatial(3, i)
# vj = T.axis.spatial(3, j)
# for di, dj in T.grid(3,3):
# with T.init():
# C[vb, vk, vi, vj] = T.int64(0)
# C[vb, vk, vi, vj+T.int32(3)] += Y[vb, 0, vi+di, vj+dj]*B[vk, 0,di, dj ]
# # 3.
# for tt, ttt, row, col in T.grid(1, 1, 5, 5):
# with T.block("Y"):
# dd = T.axis.spatial(1, tt)
# ddd = T.axis.spatial(1, ttt)
# rr = T.axis.spatial(5, row)
# cc = T.axis.spatial(5, col)
# # with T.init():
# Y[dd, ddd, rr, cc] = A[dd, ddd,rr+T.int32(3),cc]
# # Y[dd, ddd, rr, cc] = A[dd, ddd,rr+T.int64(3)*(num/2),cc+T.int64(3)*(num%2)]
# # compute Y
# # store little convd Y to C
# for b, k, i, j in T.grid(1, 2, 3, 3):
# with T.block("C"):
# vb = T.axis.spatial(1, b)
# vk = T.axis.spatial(2, k)
# vi = T.axis.spatial(3, i)
# vj = T.axis.spatial(3, j)
# for di, dj in T.grid(3,3):
# with T.init():
# C[vb, vk, vi, vj] = T.int64(0)
# C[vb, vk, vi+T.int32(3), vj] += Y[vb, 0, vi+di, vj+dj]*B[vk, 0,di, dj ]
# # 4.
# for tt, ttt, row, col in T.grid(1, 1, 5, 5):
# with T.block("Y"):
# dd = T.axis.spatial(1, tt)
# ddd = T.axis.spatial(1, ttt)
# rr = T.axis.spatial(5, row)
# cc = T.axis.spatial(5, col)
# # with T.init():
# Y[dd, ddd, rr, cc] = A[dd, ddd,rr+T.int32(3),cc+T.int32(3)]
# # Y[dd, ddd, rr, cc] = A[dd, ddd,rr+T.int64(3)*(num/2),cc+T.int64(3)*(num%2)]
# # compute Y
# # store little convd Y to C
# for b, k, i, j in T.grid(1, 2, 3, 3):
# with T.block("C"):
# vb = T.axis.spatial(1, b)
# vk = T.axis.spatial(2, k)
# vi = T.axis.spatial(3, i)
# vj = T.axis.spatial(3, j)
# for di, dj in T.grid(3,3):
# with T.init():
# C[vb, vk, vi, vj] = T.int64(0)
# C[vb, vk, vi+T.int32(3), vj+T.int32(3)] += Y[vb, 0, vi+di, vj+dj]*B[vk, 0,di, dj ]
# N, CI, H, W, CO, K = 1, 1, 8, 8, 2, 3
# OUT_H, OUT_W = H-K+1, W-K+1
# data = np.arange(N*CI*H*W).reshape(N, CI, H, W)
# weight = np.arange(CO*CI*K*K).reshape(CO, CI, K, K)
split4conv_lib = tvm.build(MySplit4Conv, target="llvm")
data_tvm = tvm.nd.array(data)
weight_tvm = tvm.nd.array(weight)
split4conv_tvm = tvm.nd.array(np.empty((N, CO, OUT_H, OUT_W), dtype=np.int64))
mat_lib["conv"](data_tvm, weight_tvm, split4conv_tvm)
print("split4conv_tvm:\n", split4conv_tvm)
# import threading
# import time
|
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 1 reply
-
表示给定的input数据( |
Beta Was this translation helpful? Give feedback.
-
|
谢谢提醒,我想我找到了。最后调用的时候出错,这里的“mat_lib["conv"](data_tvm, weight_tvm, split4conv_tvm)”应该被替换为“split4conv_lib["conv"](data_tvm, weight_tvm, split4conv_tvm)”。 |
Beta Was this translation helpful? Give feedback.
表示给定的input数据(
data_tvm.shape)和函数本身定义的Buffer shape不一致