超长序列的训练一直在大模型训练中是一个重要的方向。在实际推理过程中,尤其是Agent链路中,模型对长序列、复杂场景的泛化性代表着模型在实际应用时的可信度。长序列的场景,对于大模型训练也提出了更高的需求。由于Attention计算的O(N^2^ )复杂度特性,使实际输入序列在增长时,显存使用会呈现指数型爆炸。这对于显存不宽裕的卡型,在长序列训练练场景中的可用性,提出了巨大的挑战。
序列并行(Sequence Parrallel, SP)技术,可以用来在多卡或多机条件下降低长序列训练对于大显存的依赖。简单而言,序列并行可以用如下概念定义:
序列并行是在训练过程中,将一个输入序列在不同卡上切分为若干个并行计算的子序列,从而降低训练对于显存的需求。
常用的序列并行方式有下面几种:
-
Ulysses
-
Ring-Attention
-
Megatron-SP/CP
这其中Ulysses和Ring-Attention都是基于Transformers生态的序列并行解决方案,我们在这里主要介绍这两种方案的技术原理和实现。而Megatron-CP[1]和Ring-Attention可以类比为同类技术,Megatron-SP则针对激活值进行了切分,一般配合Megatron-TP使用。我们在这里都不做具体的展开。
首先,我们看下在融合Ulysses和Ring-Attention两种训练技术后,在Qwen2.5-3B模型上的长序列训练过程中,能达到的降低显存的效果:
| SP size | SP Strategy | GPU memory | training time |
|---|---|---|---|
| 8 | w/ ulysses=2 ring=4 | 17.92GiB | 1:07:20 |
| 4 | w/ ulysses=2 ring=2 | 27.78GiB | 37:48 |
| 2 | w/ ulysses=2 | 48.5GiB | 24:16 |
| 1 | w/o SP | 75.35GiB | 19:41 |
注意,由于序列切分带来的通讯量增加和显卡负载的不同,训练时间会有相应的延长。
其中切分为2个子序列的时候使用了Ulysses,切分为4/8个子序列时使用了Ulysses(切分2)+Ring-Attention(切分2或4)。下面我们展开阐述一下这两种技术的原理和实现方案。
Ulysses是DeepSpeed团队开发的序列并行算法[2]。Ulysses的思路可以用一句话来概括:
在序列被切分为子序列后,在每个layer中Attention计算之前进行激活值交换,使每张卡上组合成完整的序列。而Attention Head会被拆分到不同卡上去,从而达到减少显存的目的。计算完成后再交换回来。
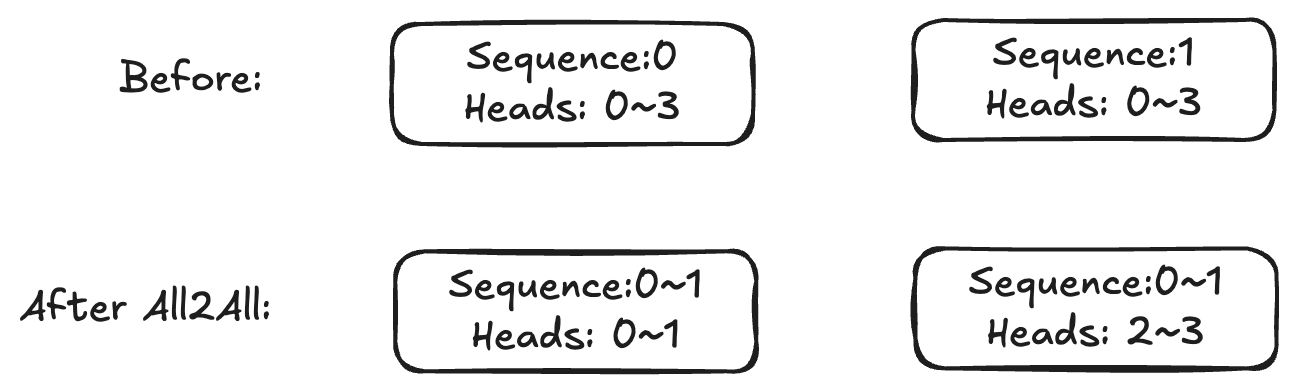
通过这样的方式,虽然QKV计算时仍然是O(N^2^) 的激活值,但由于每张卡上Attention Head减少了,因此显存占用仍然会降低。下图是一个简单的例子,假设切分为两个序列,每个序列有两个attention heads:
我们放一下论文中给的图:
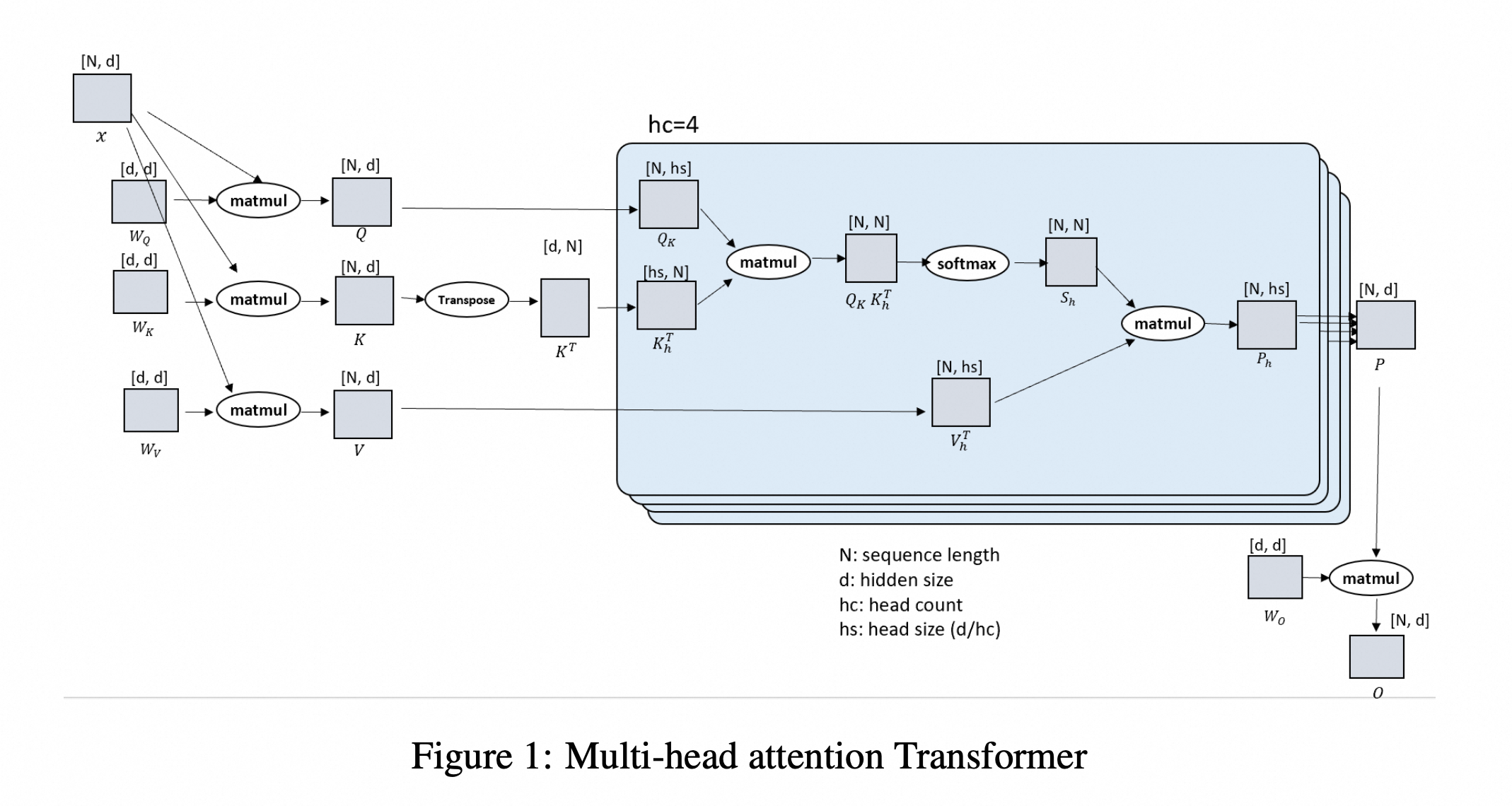
其中,N代表序列长度,d代表hidden_size,也可以具体理解为Attension Head数量*实际的hidden_size。
Ulysses切分后的状态:
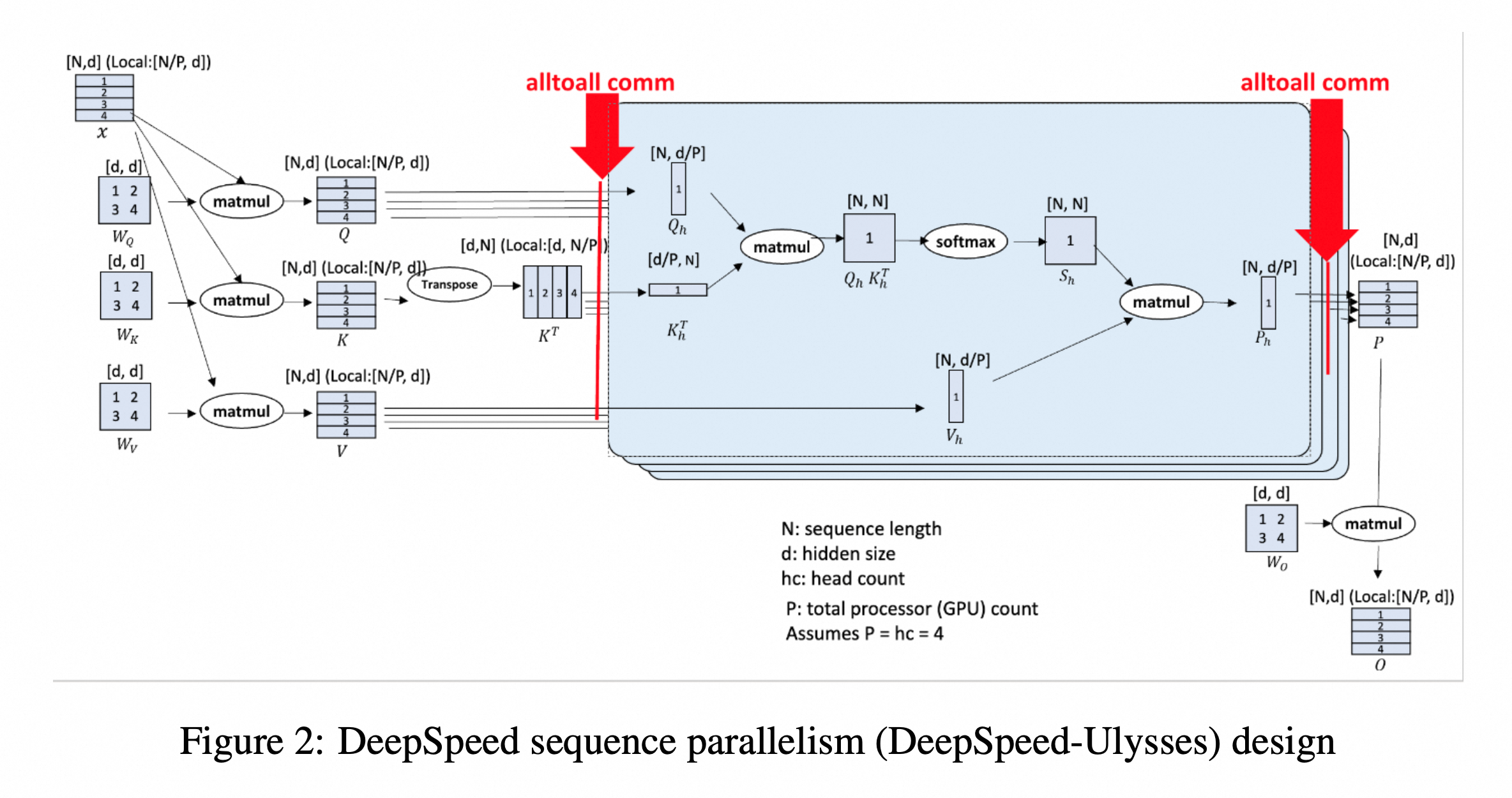
Ulysses的技术原理非常清晰,关键点是N/P到d/P的all-to-all通讯。由于QKV在Attention计算时是完整的,而不同的Attention-Head分摊在不同的卡上,因此在GQA、MHA等场景下都是通用的,并且完全兼容flash-attn、SDPA、padding_free等各种技术。当然,由于存在跨卡通讯,因此backward过程需要额外处理。 但Ulysses的限制也比较明显,即受限于Attension Head的数目。尤其是在KV头数远小于Q头数的GQA中,Ulysses可能无法拆分到更多卡上。
在谈Ring-Attention之前,需要先简单聊一下Flash-Attention。Flash-Attention的原理也可以用一句话解释:
QKV、softmax可以进行分块并行计算和更新,在最大化利用SRAM的能力的同时,降低显存使用。
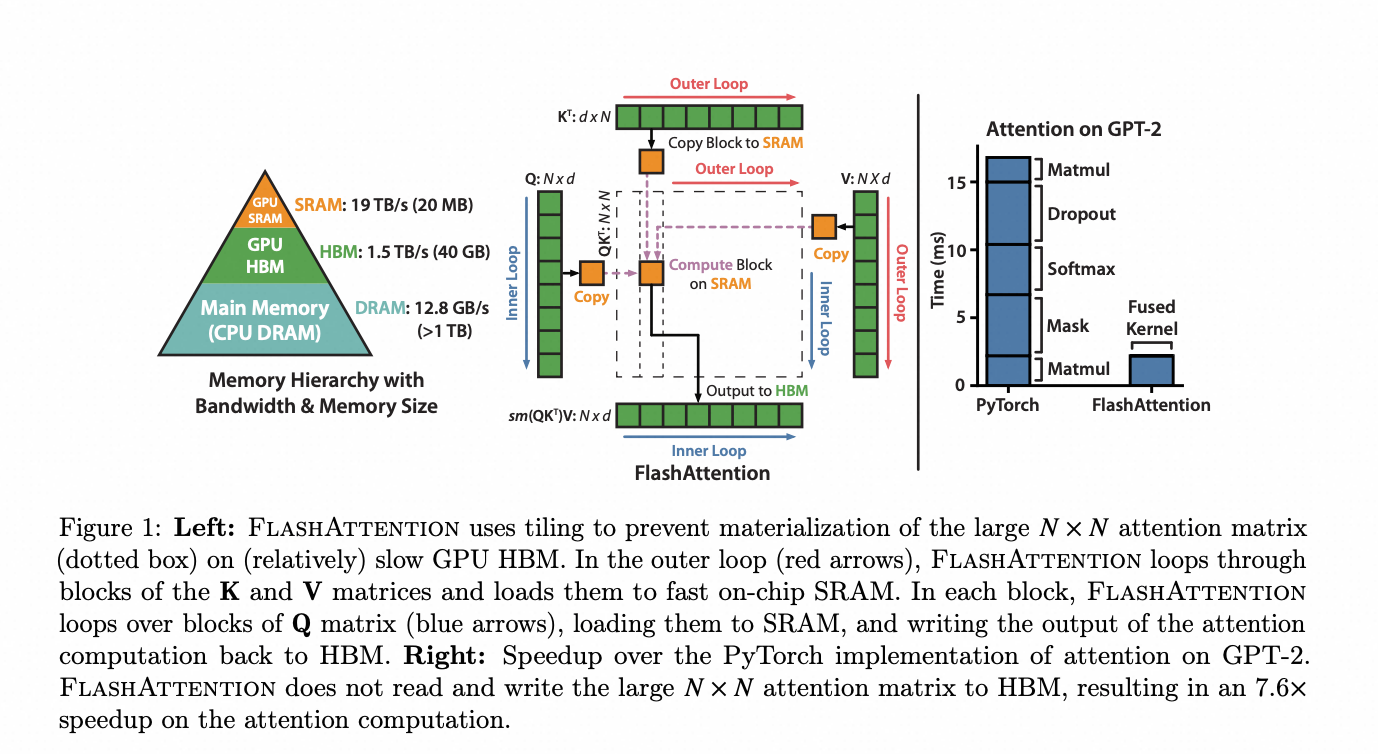
flash-attention的forward流程伪代码:

注意上面Algorithm1中第10~12行的伪代码,该部分对分块的_LSE(log-sum-exp)_:
其中:$$m_i^{new} = \max(m_i, \tilde m_{ij})$$
和Attention-Out进行了合并更新,即在计算完新的块之后,将新的块的结果和老块的结果进行合并,得到完整的结果。
那么,如果每张卡承载一部分序列长度,计算结果跨卡传递,是不是可以使flash-attention跨卡生效呢?这就是Ring-Attention的基本思想了。
Ring-Attention:利用Attention计算可以分块进行的原理,将序列块切分到多张卡上分别计算,再将计算结果合并起来得到最终结果。
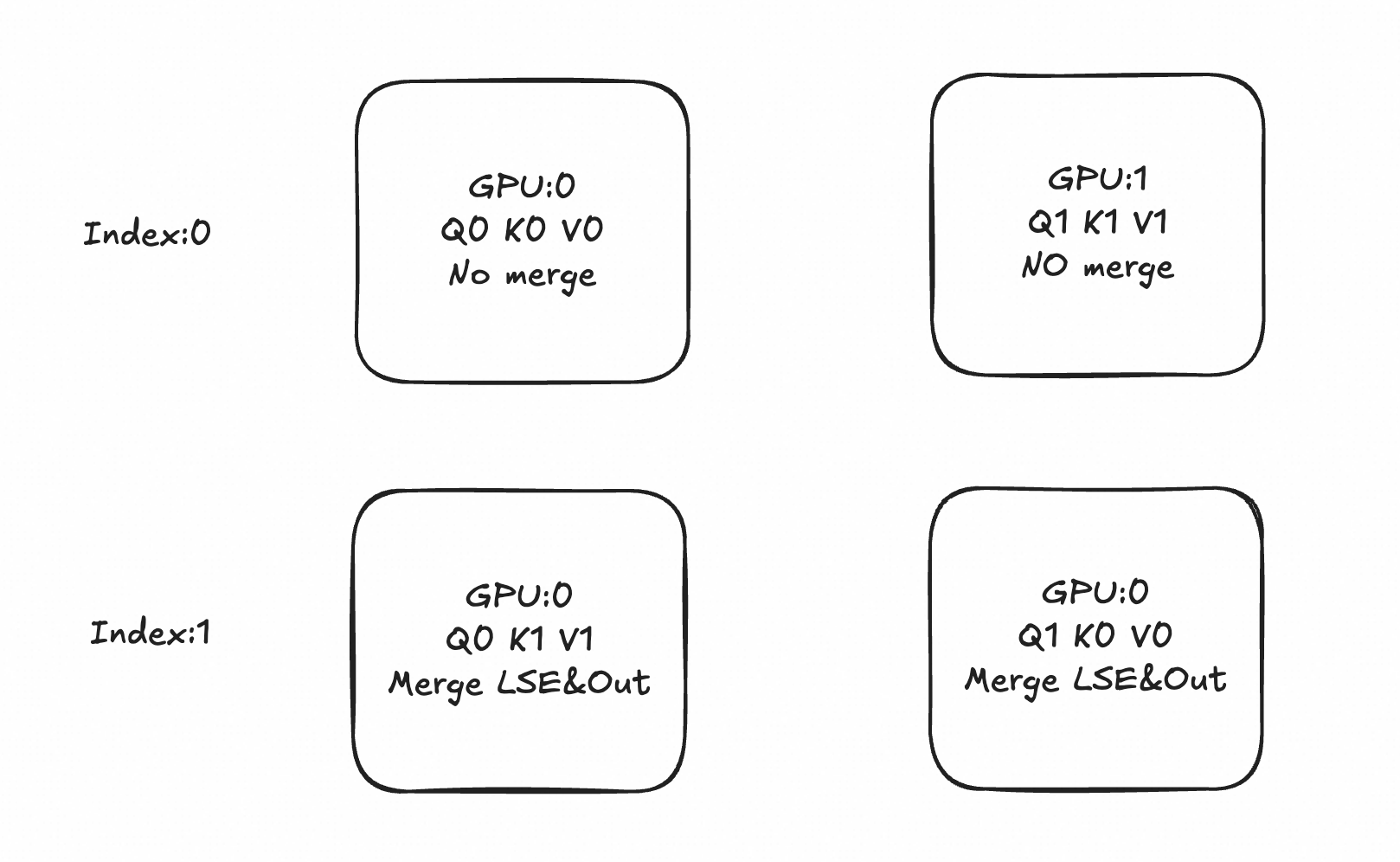
假设有N个块,考虑同一个Qi 以及可以在不同块间通讯流转的K0n-1~ V0n-1~ ,先考虑Softmax部分:
其中:$$Z_i = \sum_{j=1}^N e^{x_{ij}}$$
一般来说,为了数值稳定不会直接计算指数,而是使用数值稳定的计算方式:
可以看到使用指数公式展开后,该方式和上面的原始公式是等价的。
下面我们需要递推LSE和Attention-Out的更新,先来看LSE,考虑已经有前置的累加结果和当前块结果,那么新的LSE应该是:
那么:
其中i代表旧的累积值,ij代表当前块的值。针对右侧log进行展开:
同理为了数值稳定,不在这里计算指数,而将右侧合并为logsigmoid的形式。在PyTorch中,logsigmoid的softplus算子会负责数值稳定的计算:
这就是Ring-Attention的LSE更新公式。
下面考虑Attention-Out。我们目前有块LSE、前序累积LSE、块Attention-Out、前序累积Attention-Out四个值,需要用这几个信息递推更新后的整体Attention-Out。
根据Attention计算公式和分块定义,假设之前块的计算结果:
当前块的计算结果:
于是:
使用LSE来表示上面的公式:
根据Attention公式:
代入上面:
注意到上面的公式分子左右拆分后,可以变为两个独立的式子相加,并且这两个式子分别是sigmoid的形式,因此得到:
这两个更新公式和flash-attention论文中给的递归公式是等价的,同样是分块更新和online-softmax的思路。
上面的推导给出了迭代更新的前向计算公式,代码位置在update_out_and_lse中:
既然有前向,那就必然有反向。在反向时,需要从最终的i-1逐步还原到第0步,由于篇幅关系,反向公式的推导不在这里展开,代码位置在lse_grad中:
https://github.com/modelscope/ms-swift/blob/main/swift/trainers/sequence_parallel/zigzag_ring_attn.py#L263: https://github.com/modelscope/ms-swift/blob/main/swift/trainers/sequence_parallel/zigzag_ring_attn.py#L263 https://github.com/modelscope/ms-swift/blob/main/swift/trainers/sequence_parallel/zigzag_ring_attn.py#L458: https://github.com/modelscope/ms-swift/blob/main/swift/trainers/sequence_parallel/zigzag_ring_attn.py#L458
好的,上面我们已经准备好了理论,可以开始实现代码了。
注意,Ring-Attention有多个变种实现,例如strip-ring-attention[3]。在这些实现中,在负载均衡上最优秀的是zigzag(z字型,或者成为之字形)的实现方式。为了理解原始Ring-Attention的问题,我们看下下面的图:
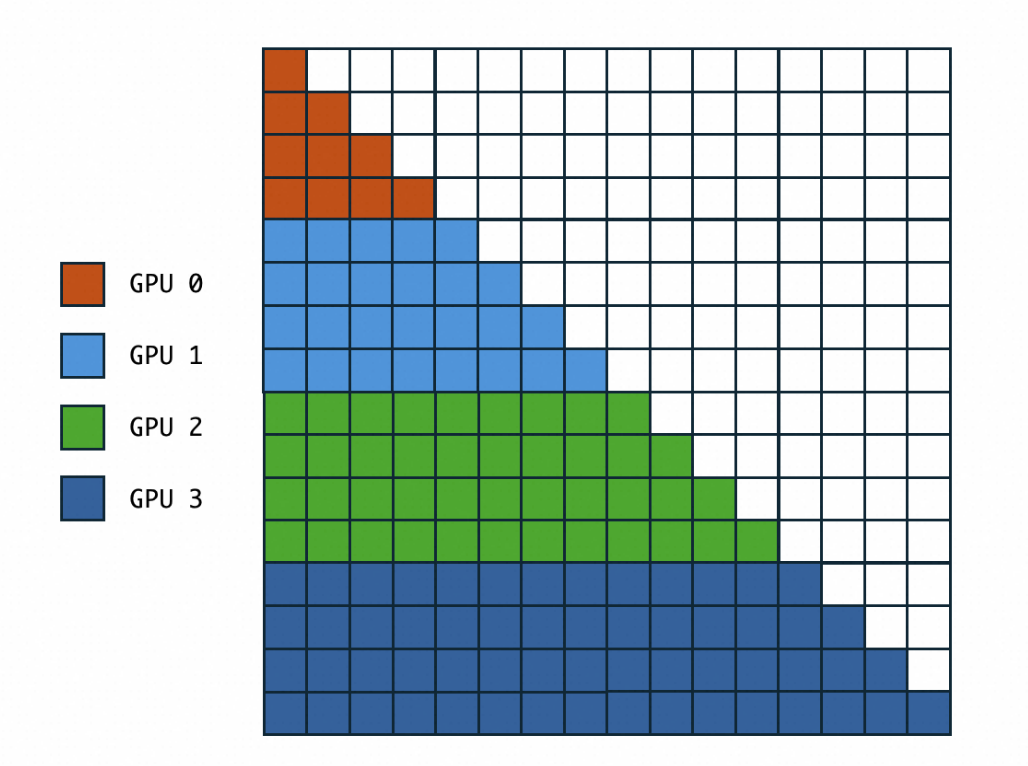
由于GPU 0处理句子的最前部分,因此其他卡的KV流转到GPU 0的时候,GPU由于causal=True的原因根本无法参与计算句子后面的部分,而GPU3可以计算0~2的全部序列,因此每张卡的计算负载并不一致。在这个前提下,Megatron-CP和一些优秀的实现采用了Z字型切分:
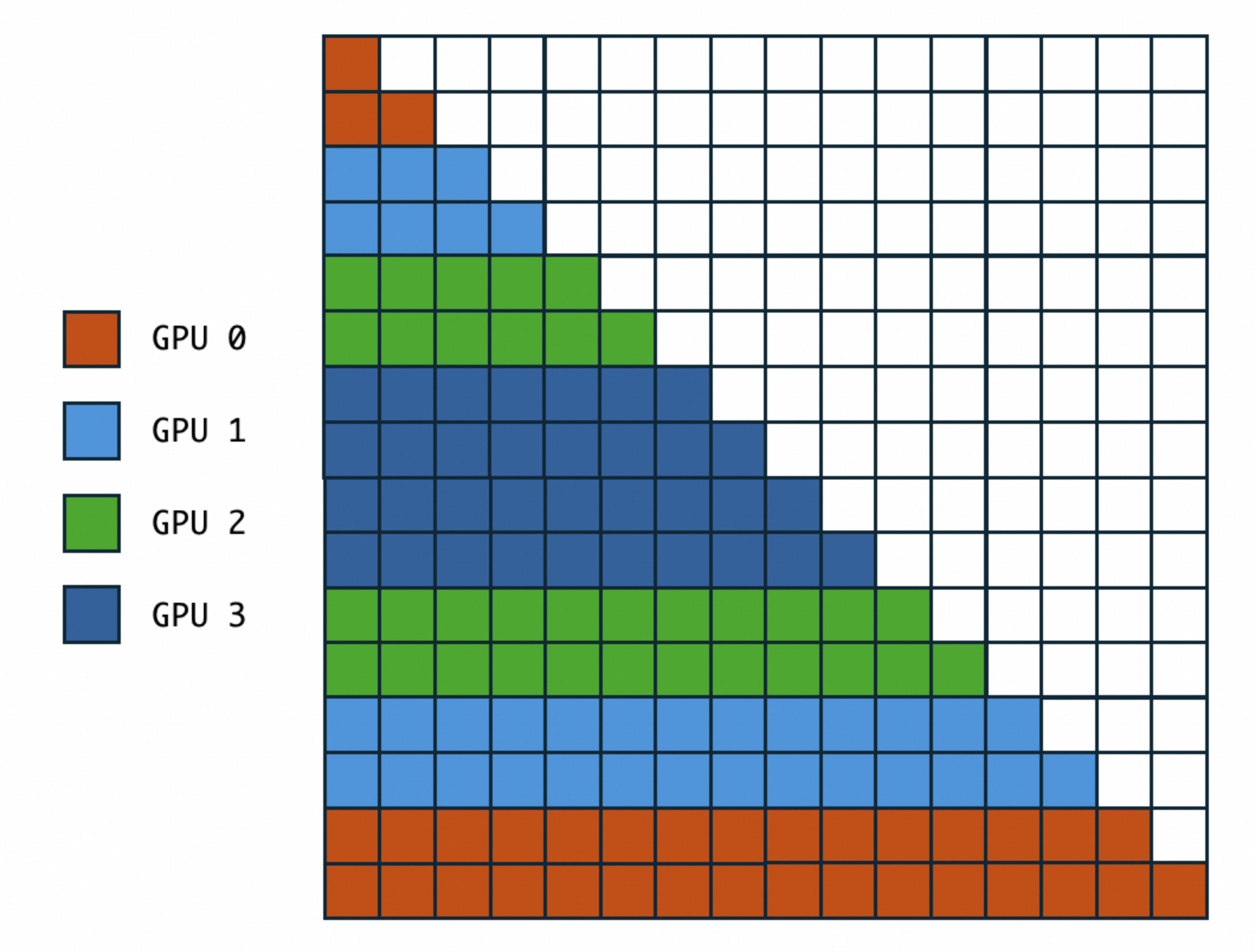
假设需要切分到4张卡上,那么在保证序列可以被均分为8片的情况下,将0/7组合到一起,1/6组合到一起,2/5、3/4也分别组合到一起,这样可以保证计算的均衡。并且,这种计算还有一个特性:
-
在本地计算QKV(序号为0)的时候,causal=True直接计算
-
在流转序号小于等于当前rank时,只需要计算KV的前半部分
-
在流转序号大于当前rank时,只需要计算Q的后半部分
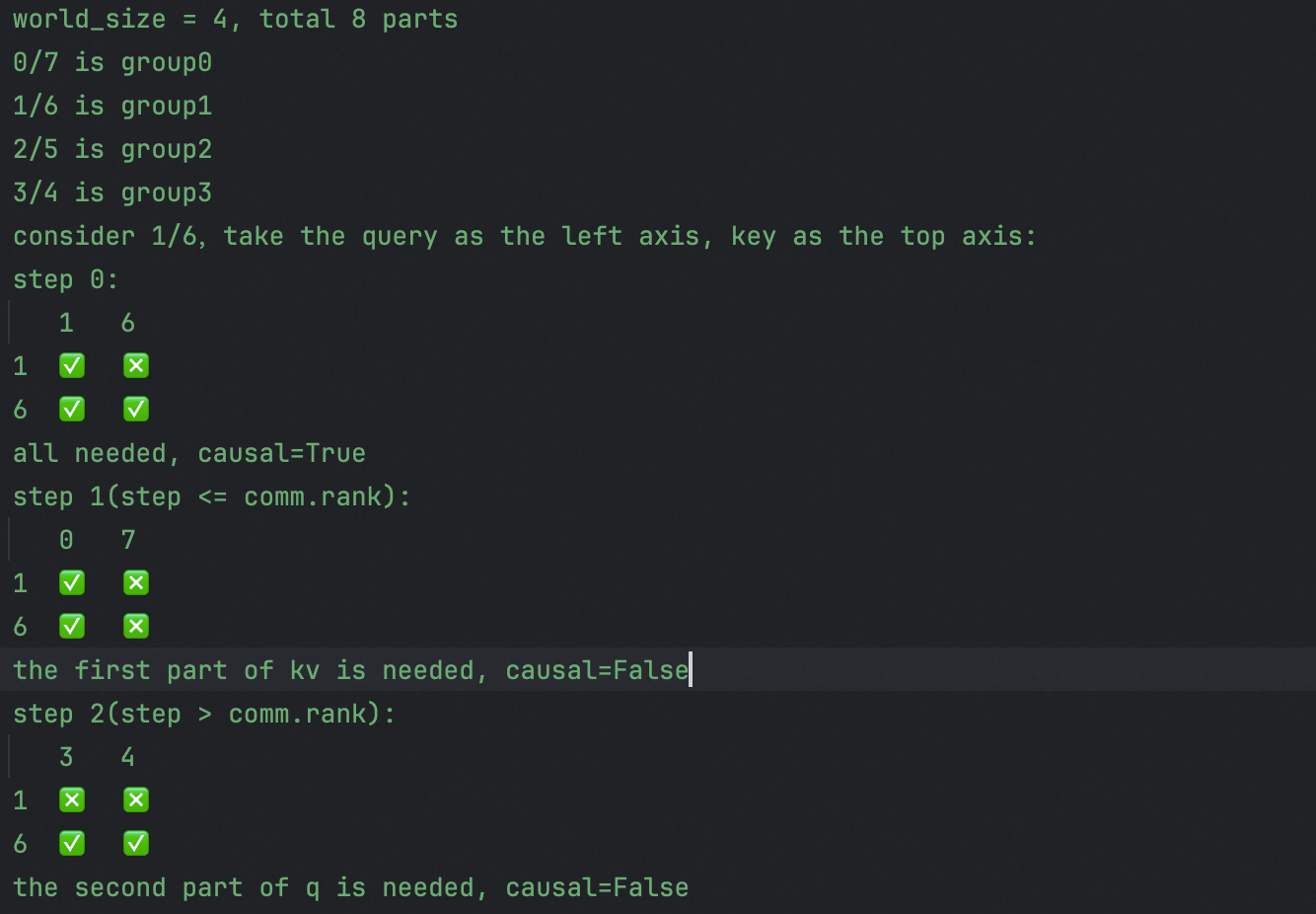
这进一步减小了计算量。代码实现参见:
不难看出,这两个序列并行方案各有特点。
- Ulysses通讯比较低,但受限于Attention Head数量,而且all-to-all通讯对延迟比较敏感,对网络拓扑也有一定要求。
- Ring-Attention的P2P环通讯要求比较低,但通讯量更高一些,也不受限于Attention Head数量。
从上面的原理可以看到,Ulysses和Ring-Attention两个技术实际上是可以融合使用的。可以先使用通讯量较低的Ulysses进行切分,如果Attention Head数量不足(GQA),或切分序列数量过大,则补充以Ring-Attention。
SWIFT中实现了这样一个融合计算的技术,并且适用于纯文本、多模态、SFT、DPO、GRPO等各类场景中。在基础代码实现中,我们采用了一些优异的社区开源工作[4][5], 并重写了部分代码。
https://github.com/modelscope/ms-swift: https://github.com/modelscope/ms-swift
使用方式也非常简单,在命令行中额外增加一个参数:
--sequence_parallel_size N框架会自行计算切分方式,甚至当显卡数量不是偶数时(3,5,7等)也可以支持。
最自然的方式是先用Ulysses做局部gather,整体使用Ring-Attention计算全局LSE和Attention-Out,假设切分为4个子序列(Ulysses world_size=2, Ring-Attention world_size=2),模型head=4,那么:
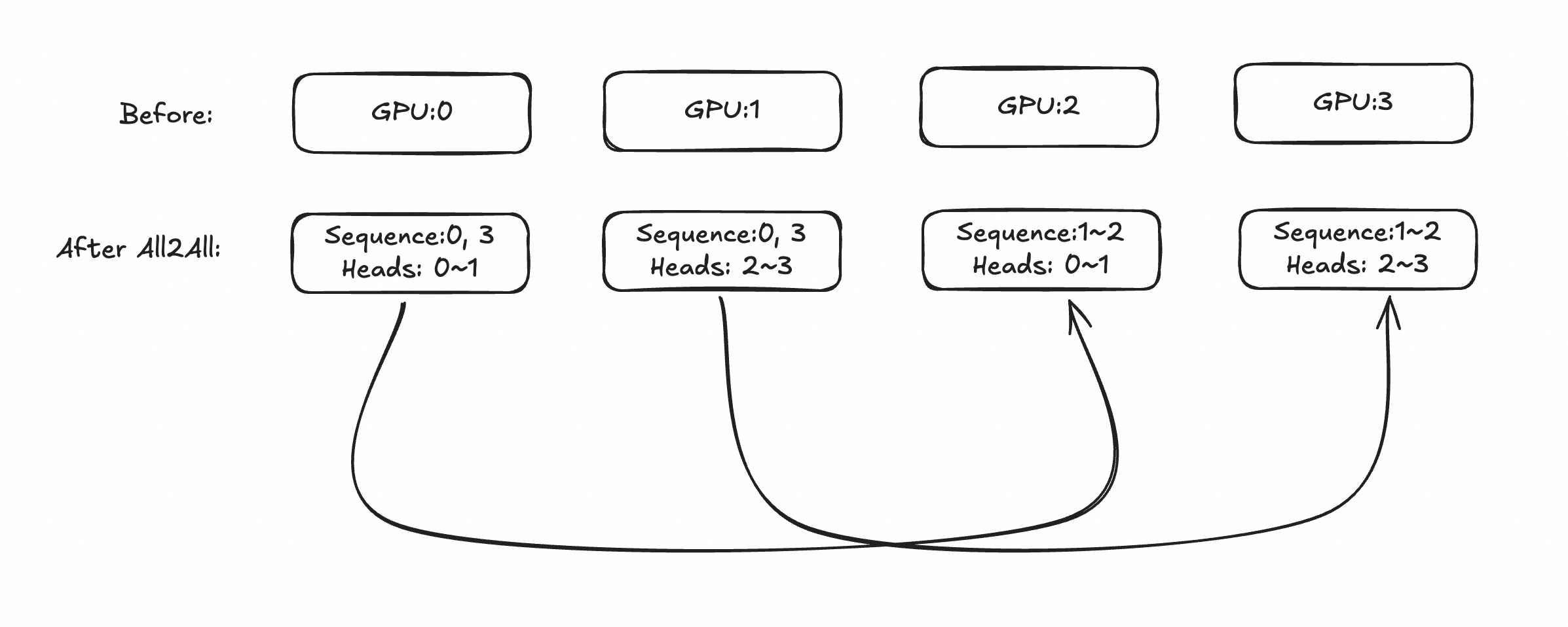
在Ulysses all-to-all 通讯后,GPU0,1作为同一个Ulysses组均持有序列0/3,但head不同(前半和后半)。GPU2,3同理。在Ring-Attention计算时,GPU0,2作为Ring-Attention组进行环状通讯,GPU1,3同理。
在切分之前,需要对序列进行padding,使其可以被world_size*2整除(乘以2是因为zigzag需要对子块重新组合)。
多模态模型的序列切分适配比较困难,主要原因有:
-
多模态模型的序列长度在实际forward之前无法确定。部分模型仅使用一个
<image> token来代表多模态部分,在ViT对图像编码后,将该token替换为一个非常长的序列。 -
部分模型的输入序列包含了闭合性标签,例如
<image></image>,在替换为实际图像编码前不能切分,否则会直接抛错。
一般多模态LLM均包含内外两层模型,外层模型包含了ViT处理过程和lm_head计算逻辑,内层模型计算decode_layers,我们称其为backbone。
为了适配多模态切分,SWIFT在实现过程中,采用了一个工程上的trick:切分不发生在数据准备过程(data_collator)中,而发生在backbone的forward hook中。因为在进入backbone时,ViT部分的多模态编码已经和纯文本部分融合完成,此时拿到的embedding是准确长度的。并且,在backbone的hook中进行切分对纯文本模型也是适配的。同时这种方式使得框架不需要保存额外的模型代码,避免了原始模型代码更新时造成的维护成本增大问题。
padding_free可以理解输入格式为flash-attention的形式:多个sequence拼接为一个超长序列。
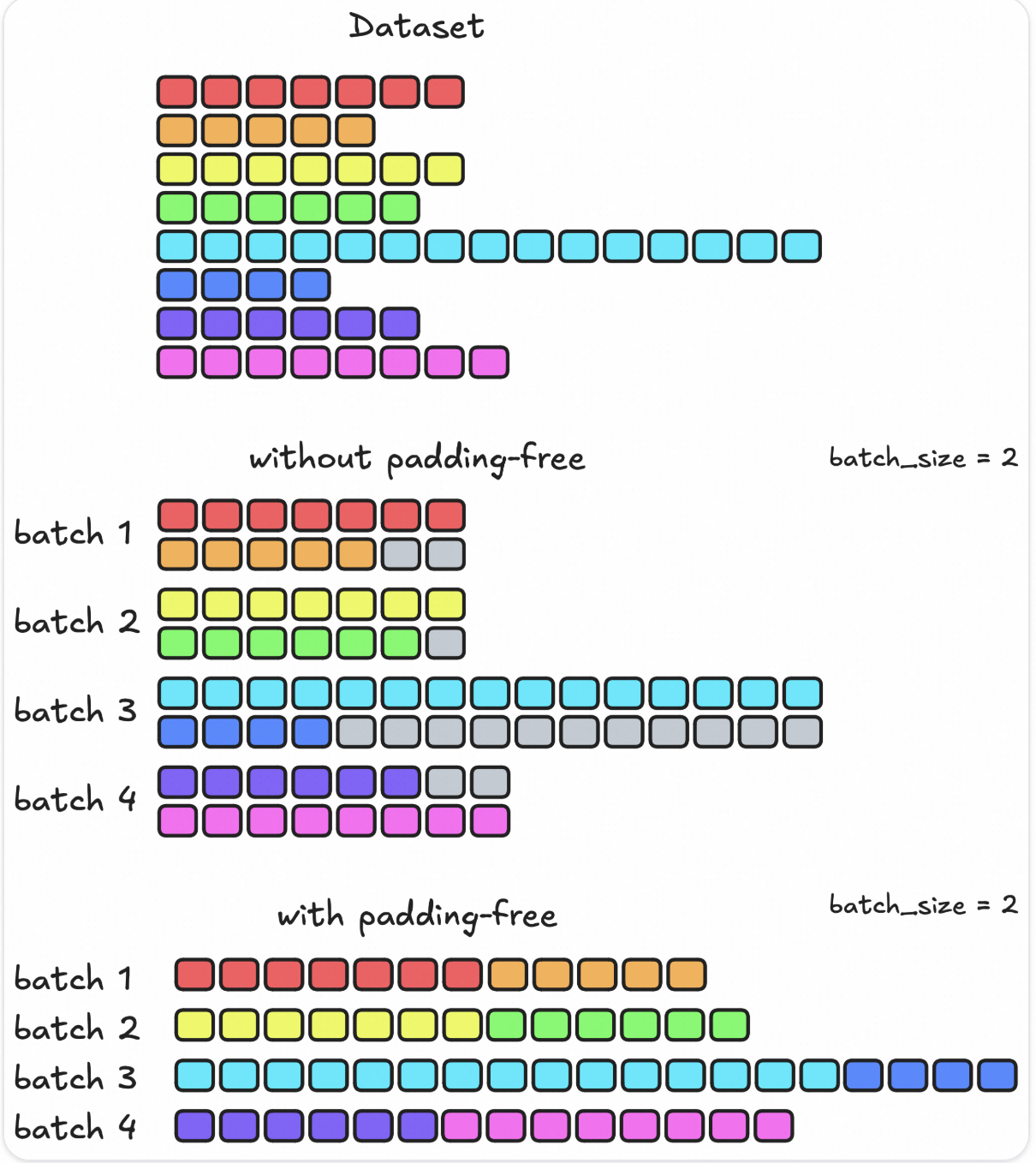
这种方式给实际的工程实现带来了麻烦。因此在实现中,SWIFT采用了如下的工程方案:
-
针对原始padding_free输入进行拆解,对每个sequence再单独进行padding(被world_size*2整除)和单独拆分。
-
在计算attention之前,根据padding位置,将QV的padding置为0,对K的padding置为极小值,防止padding对attention计算产生不良影响。
-
由于GRPO、DPO最终的loss计算需要完整序列,因此在padding_free中,如果先进行logits进行gather会增大通讯量,后进行gather会导致loss计算异常,因此需要完全重写各个训练的loss计算逻辑。
-
由于通讯序号大于rank时Q只有一半,因此在反向梯度更新时需要还原为完整长度,因此需要针对每个sequence的grad单独padding,并且LSE需要padding为极小值。
根据上面的公式推导,LSE和Attention-Out进行块状更新的反向传播需要依次进行,并且需要一些前向的信息,如块LSE、块Attention-Out等,这些信息在前向的flash_attn_forward中虽然可以拿到,但保存在ctx中可能占用额外显存,因此选择了在后向时重新计算一次flash_attn_forward的方案,再根据中间结果计算lse_grad,以及后续对QKV进行实际的backward。
我们使用了一个3B模型,在8*A100显卡上测试显存优化效果:
NPROC_PER_NODE=8 \
swift sft \
--model Qwen/Qwen2.5-3B-Instruct \
--dataset 'test.jsonl' \ # 9000 tokens per sequence
--train_type lora \
--torch_dtype bfloat16 \
--per_device_train_batch_size 4 \
--target_modules all-linear \
--gradient_accumulation_steps 8 \
--save_total_limit 2 \
--save_only_model true \
--save_steps 50 \
--max_length 65536 \
--warmup_ratio 0.05 \
--attn_impl flash_attn \
--sequence_parallel_size 8 \
--logging_steps 1 \
--use_logits_to_keep false \
--padding_free true
如文章开头所示,在切分为8片时,训练显存占用从将近80GiB下降到不到20GiB,达到了普通商业级显卡即可训练的效果。
本篇讲解了在SWIFT框架中,实现Ulysses + Ring-Attention的融合训练能力。目前我们对于这方面的进一步优化,也还在继续探索中,例如:
-
在backward中,重新计算flash_attention_forward,是否是能达到最佳速度的实现?
-
P2P的通讯量和异步执行方向,仍然有继续优化的可能。
对此有兴趣的开发者可以提出宝贵的意见,帮助SWIFT共同改进长序列场景下的大模型训练能力。
引用: