diff --git a/docs/user_manual/operation_and_maintenance/en-US/about_this_manual/01_overview.md b/docs/user_manual/operation_and_maintenance/en-US/about_this_manual/01_overview.md
new file mode 100644
index 000000000..b2ae75822
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/about_this_manual/01_overview.md
@@ -0,0 +1,49 @@
+---
+title: Overview
+weight: 1
+---
+
+In the first half of 2024, we provided a [getting-started tutorial](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_01_overview_of_the_oceanbase_database/introduction) for beginners of OceanBase Database Community Edition. The tutorial covers topics such as the installation and deployment of OceanBase clusters, data migration, and database testing.
+
+As users become more familiar with OceanBase Database, we will release a tutorial for those who are conducting proof of concept (POC) tests and have deployed OceanBase Database for their business. This tutorial, titled *OceanBase Advanced Tutorial for DBAs*, will cover the following sections:
+
++ Best practices for different scenarios
++ Troubleshooting manuals for the platform tools and database kernel
++ Application development specifications
+
+> Note: At present, *OceanBase Advanced Tutorial for DBAs* applies only to OceanBase Database Community Edition. Therefore, the arbitration replica feature of OceanBase Database Enterprise Edition is not included in the tutorial outline provided in this topic. For more information about the differences between the two editions, see [Differences between Enterprise Edition and Community Edition](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714481).
+## Tutorial Outline
+The following figure shows the outline of this tutorial.
+
+(The outline will be continuously adjusted based on user feedback and actual circumstances during the process of tutorial writing. The outline shown in the figure below is not the final version.)
+
+
+
+*OceanBase Advanced Tutorial for DBAs* (V4.x)
+
++ Best practices
+ - O&M management
+ - Data migration and synchronization
+ - Parameter templates
+ - OLAP scenario
+ - High-concurrency scenario
+ - SaaS multitenancy scenario
+ - History/Archive database scenario
+ - Read/Write splitting scenario
++ Troubleshooting
+ - Troubleshooting manual for OceanBase Deployer (obd)
+ - Troubleshooting manual for OceanBase Migration Service (OMS)
+ - Troubleshooting manual for OceanBase Database Proxy (ODP)
+ - Troubleshooting manual for OBServer
+ - User manual for automatic diagnostics
++ Database development specifications
+ - Tenant usage specifications
+ - Database object design
+ - SQL development specifications
+ - Usage limitations
+ - Others
++ Methods and examples for GitBook collaborative building
+
+Additionally, we'd love to hear your suggestions on the framework and content of this tutorial. Please feel free to share any topics you urgently need based on your experience with OceanBase Database Community Edition.
+
+We will improve this tutorial based on your feedback. We are expecting your comments on our post in the [OceanBase community](https://ask.oceanbase.com/t/topic/35610431/).
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/about_this_manual/_index.md b/docs/user_manual/operation_and_maintenance/en-US/about_this_manual/_index.md
new file mode 100644
index 000000000..b12a5a3b9
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/about_this_manual/_index.md
@@ -0,0 +1,4 @@
+---
+title: About OceanBase Advanced Tutorial for DBAs
+weight: 1
+---
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/development_specification/01_object_specification.md b/docs/user_manual/operation_and_maintenance/en-US/development_specification/01_object_specification.md
new file mode 100644
index 000000000..b582721c4
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/development_specification/01_object_specification.md
@@ -0,0 +1,188 @@
+---
+title: Database Object Design and Usage Specifications
+weight: 1
+---
+> Note:
+>
+> **You must follow the specifications highlighted in red in this topic. **
+>
+> The specifications that are not highlighted in red are optional but recommended. You can determine whether to follow these specifications based on your business requirements.
+
+
+## Object Naming Specifications
+
+This section will not discuss object naming specifications in detail because they have been frequently mentioned. Essentially, the name of an object cannot be excessively long and must reflect the object type and corresponding business meaning, such as `tbl_student_id`. You may have your own naming styles. I think there is no right or wrong, and unified specifications are unnecessary.
+
+We recommend that **you do not use special characters or keywords in object names unless you have special requirements**. This is because such names are awkward to read and use.
+
+For example, a user once used the reserved keyword `table` as a table name and the escape character backtick (`) as a column name. The names look as if they have been encrypted. This not only makes internal users uncomfortable but also creates a headache for the technical support team when they troubleshoot issues.
+```
+obclient [test]> create table `table` (```` int);
+Query OK, 0 rows affected (0.050 sec)
+
+obclient [test]> insert into `table` values(123);
+Query OK, 1 row affected (0.007 sec)
+
+obclient [test]> select ```` from `table`;
++------+
+| ` |
++------+
+| 123 |
++------+
+1 row in set (0.000 sec)
+```
+This section does not describe how to rename an object because it is a simple operation.
+
+## Tenant Usage Specifications
+
+In OceanBase Database, each tenant is similar to a MySQL instance. For more information, see [Tenants](https://oceanbase.github.io/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/background_knowledge).
+
+**You are not allowed to store data in the sys tenant. To store data, you must create a user tenant.**
+
+**The sys tenant is designed to store the metadata of user tenants and does not provide database services. Misuse of the sys tenant may cause serious impact.**
+
+## Database Usage Specifications
+**You are not allowed to store user data in built-in metadatabases such as `information_schema` and `oceanbase`. Misuse of the metadatabases may cause serious impact.**
+```
+obclient [test]> show databases;
++--------------------+
+| Database |
++--------------------+
+| information_schema |
+| mysql |
+| obproxy |
+| oceanbase |
+| test |
++--------------------+
+5 rows in set (0.007 sec)
+```
+
+## Table Design Specifications
+
+To build a table with smaller redundancy and a more reasonable schema, you must follow specific rules when you design a database. In a relational database, these rules are called paradigms. You need to understand three paradigms for database design.
+
+
+* Consider business performance in table schema design based on the aforementioned three paradigms. Design data redundancy in storage to reduce table associations and improve business performance. A redundant column cannot be:
+
+ * A column subject to frequent modifications
+
+ * An excessively long column of the string type
+
+* Specify a primary key when you create a table.
+
+ * We recommend that you use a business column rather than an auto-increment column as the primary key or federated primary key.
+
+ * Tables in OceanBase Database are index-organized tables (IOTs). If you do not specify a primary key for a table, the system automatically generates a hidden primary key for the table.
+
+* We recommend that you specify the `COMMENT` attribute for tables and columns.
+
+* To ensure that columns do not contain null values, we recommend that you explicitly specify the `NOT NULL` attribute for the columns.
+
+* We recommend that you specify default values for columns in a table by using the `DEFAULT` clause as needed.
+
+* Try to ensure that the same column in different tables has the same definition. This prevents implicit data type conversions during computation.
+
+* The columns to be joined must be of the same data type. This prevents implicit data type conversions during computation. **Attention should also be given to auxiliary attributes of the data type, such as collation, precision, and scale. Differences in these attributes may cause issues such as invalid indexes and non-optimal execution plans.**
+
+## Column Design Specifications
+
+- We recommend that you create an auto-increment column of the BIGINT type. If the column is of the INT type, the maximum value of the column can be easily reached.
+
+- We recommend that you specify a proper length for strings and a suitable precision and scale for numbers based on your business requirements. This saves storage space and improves query performance.
+
+- When comparing columns of different types, the system performs implicit data type conversions. Based on the general implicit conversion order defined in SQL, a string is first converted to a number and then to a time. To clarify the requirements for data type conversions and use indexes for accelerating queries, we recommend that you use the CAST or CONVERT function to explicitly convert data types before column comparison.
+
+
+## Partition Design Specifications
+
+**The advantage of a distributed database is that large tables can be split and stored on multiple nodes so that requests can be distributed to multiple nodes for processing. Access requests to a partition are processed by the node on which the partition resides**. As high-concurrency SQL requests access different partitions, the requests are processed by different nodes, and the total queries per second (QPS) of all nodes can be quite tremendous. In this case, you can add more nodes to improve the QPS for processing SQL requests. This is the best case in using a distributed database.
+
+**The goal of partitioning is to evenly distribute large amounts of data and access requests to multiple nodes. This way, you can make full use of resources for parallel computing and eliminate overloads caused by frequent queries on hotspot data. You can also use the partition pruning feature to improve query efficiency.** Theoretically, if each node processes data and requests evenly, 10 nodes can process 10 times the amount of a single node. However, if the table is unevenly partitioned, some nodes will process more data or requests than others, resulting in data skew, which may lead to uneven resource utilization and load among nodes. Intensively skewed data is also known as hotspot data. The straightforward method for preventing hotspot data is to randomly distribute data to different nodes. A problem is that all partitions must be scanned to find the desired data. Therefore, this method is infeasible. In practice, partitioning strategies are often defined based on specific rules.
+
+**You must plan partitions based on clear business query conditions and actual business scenarios. Do not partition a table arbitrarily. ** When you plan partitions, try to make sure that the data distributed to each partition is relatively equal in amount.
+
+The three most common partitioning methods are as follows:
+
+- `HASH` partitioning: This method is suitable when the partitioning column has a large number of distinct values (NDV) and it is difficult to clearly define ranges for partitioning. This method can evenly distribute data without specific rules to different partitions. However, this method does not support partition pruning for range queries.
+
+- `RANGE` partitioning: This method is suitable when ranges can be clearly defined based on the partitioning key. For example, you can use the `RANGE` partitioning method to partition a large table that records bank statements based on the column that represents time.
+
+- `LIST` partitioning: This method is suitable when you want to explicitly distribute data to specific partitions. It can precisely distribute unordered or irrelevant data to specific partitions. However, it does not support partition pruning for range queries.
+
+To support parallel computing and partition pruning, OceanBase Database supports subpartitioning. OceanBase Database in MySQL mode supports the ``HASH``, ``RANGE``, ``LIST``, ``KEY``, ``RANGE COLUMNS``, and ``LIST COLUMNS`` partitioning methods, and a combination of any two partitioning methods as the subpartitioning method.
+
+For example, the database needs to partition a bill table based on the `user_id` column by using the `HASH` partitioning method, and then subpartition each partition based on the bill creation time by using the `RANGE` partitioning method.
+
+
+
+OceanBase Database supports `RANGE-HASH` and `HASH-RANGE` composite partitioning. However, ADD and DROP operations can be performed on a `RANGE` partition only when the table is first partitioned by using the `RANGE` partitioning method. Therefore, for large tables, we recommend that you use `RANGE-HASH` partitioning to facilitate maintenance such as partition addition and dropping.
+
+### References
+
+- For more information about partitions, see [Create and manage partitions](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001717055).
+
+- If data is not evenly distributed to partitions in a partitioned table, query performance may be compromised due to data skew. We recommend that you use the SQL plan monitor tool of OceanBase Database to check whether query performance is compromised due to data skew. For more information about how to use the tool, see the "Collect sql_plan_monitor" section in [Use obdiag to Collect Information and Diagnose Issues](https://open.oceanbase.com/blog/8810787744).
+
+## Index Design Specifications
+
+### Index creation rules
+For more information about the index creation rules, see the "Index tuning" section in [Common SQL tuning methods](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_07_diagnosis_and_tuning/sql_tuning).
+
+### Global indexes and their application scenarios
+
+In MySQL tenants of OceanBase Database, indexes are divided into two types: local indexes and global indexes.
+
+The difference between the two is that a local index uses the same partitioning method as the primary table, whereas a global index can use a partitioning method different from that of the primary table. If the index type is not explicitly specified within a MySQL tenant, a local index is created by default.
+
+A global index can be recognized as an extended feature of MySQL. For more information, see the "Global index" section in [Extended features of a MySQL tenant of OceanBase Database](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_06_using_ob_for_business_development/extended_functionality).
+
+
+### Index design suggestions
+- Read the preceding "Index creation rules" and "Global indexes and their application scenarios" sections before you continue.
+
+- Do not use global indexes unless necessary. To use global indexes, you must understand the application scenarios of global indexes.
+ - The cost of table access by index primary key for a global index-based query is high, approximately ten times that for a local index-based query.
+ - The costs of creating, dropping, and modifying global indexes are high, which compromises DML performance.
+ - When you create a global index, we recommend that you specify a partitioning method. Otherwise, the global index is not partitioned by default. Select a column with a larger NDV as the partitioning key for the global partitioned index.
+
+- When you perform multi-table join queries, the joined columns must be indexed. This can improve join performance. Try to ensure that the data types of the joined columns are the same. This prevents implicit data type conversions, allowing indexes to be used.
+
+- You can create a covering index to avoid table access by index primary key. Try to ensure that redundant columns covered by an index are not of large object (LOB) data types.
+
+- If an index contains multiple columns, we recommend that you place the column with a larger NDV before others. For example, if the NDV of column `b` is larger than that of column `a` and the filter condition is ``WHERE a= ? AND b= ?``, you can create the `idx(b,a)` index.
+
+- For the filter condition ``WHERE a= ? AND b= ?``, we recommend that you use the composite index `idx_ab(a,b)` instead of creating indexes `idx_a(a)` on column `a` and `idx_b(b)` on column `b`. This is because the indexes created respectively on columns `a` and `b` cannot be used at the same time.
+
+### Index usage suggestions
+
+**To modify an index, create a new one, ensure that the new index has taken effect, and drop the old index once it is confirmed that it is no longer needed. **
+
+By the way, this suggestion is somewhat like advising students to bring their exam admission tickets when taking the exam. Simple as it may seem, the suggestion is necessary. In Ant Group, there are always a few database administrators (DBAs) who drop old indexes before new ones take effect every year. As a result, certain services of Alipay become unavailable, leading to significant losses. Finally, we have to penalize the DBAs to calm public anger.
+
+We hope that you strictly follow this suggestion. Otherwise, a great impact may be caused.
+
+
+
+## Auto-increment Column Design Specifications
+
+For more information, see the "Sequences" section in [Extended features of a MySQL tenant of OceanBase Database](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_06_using_ob_for_business_development/extended_functionality).
+
+
+- Read the aforementioned "Sequences" section before you continue.
+- To be compatible with MySQL databases, an auto-increment column is created in ORDER mode by default.
+ - If the sequence values do not need to be incremental but must be unique, we recommend that you set the increment mode to NOORDER. This improves performance.
+ - To avoid value hopping in NOORDER mode while applying for auto-increment values from different nodes in distributed scenarios, set the increment mode of the auto-increment column to ORDER.
+
+
+## Recycle Bin Design Specifications
+
+For more information, see the "Recycle bin" section in [Extended features of a MySQL tenant of OceanBase Database](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_06_using_ob_for_business_development/extended_functionality).
+
+- Read the aforementioned "Recycle bin" section before you continue.
+- While it seems easy to perform FLASHBACK or PURGE operations on tables in the recycle bin by their original names specified by the `ORIGINAL_NAME` parameter, we recommend that you use their unique new names specified by the `OBJECT_NAME` parameter to avoid losses due to your misremembering of the operation rules.
+
+## Table Group Design Specifications
+
+This section describes the table group feature because it is an extended feature that is not supported by MySQL.
+
+For more information, see the "Table groups" section in [Extended features of a MySQL tenant of OceanBase Database](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_06_using_ob_for_business_development/extended_functionality).
diff --git a/docs/user_manual/operation_and_maintenance/en-US/development_specification/02_charset_specification.md b/docs/user_manual/operation_and_maintenance/en-US/development_specification/02_charset_specification.md
new file mode 100644
index 000000000..b3930f5f0
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/development_specification/02_charset_specification.md
@@ -0,0 +1,199 @@
+---
+title: Character Set Usage Specifications
+weight: 1
+---
+> Note:
+>
+> At present, *OceanBase Advanced Tutorial for DBAs* applies only to MySQL tenants of OceanBase Database Community Edition. Features of Oracle tenants of OceanBase Database Enterprise Edition are not described in this topic. For more information about the differences between the two editions, see [Differences between Enterprise Edition and Community Edition](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714481).
+
+
+## Basic Knowledge
+This section describes two terms: character set and collation. If you have understood the terms, you can ignore the section.
+
+### Character set
+To put it simply, character sets define how characters are encoded and stored. Here are some examples:
+- If the character set is `utf8`, the uppercase letter "A" is encoded as the byte 0100 0001, which is represented as 0x41 in hexadecimal.
+- If the character set is `utf16`, the uppercase letter "A" is encoded as two bytes 0000 0100 0000 0001, which is represented as 0x0041 in hexadecimal.
+
+Different character sets support storage of different types and ranges of characters. For example, the `utf8` character set can store all Unicode characters, whereas the `latin1` character set supports storage of only characters from Western European languages.
+
+
+### Collation
+A collation is an attribute of character sets. It defines a set of rules for comparing and sorting characters. For example, the `utf8mb4` character set supports collations such as `utf8mb4_general_ci`, `utf8mb4_bin`, and `utf8mb4_unicode_ci`.
+
+- `utf8mb4_general_ci`: the case-insensitive general collation of `utf8mb4`.
+- `utf8mb4_bin`: the case-sensitive binary collation of `utf8mb4`.
+- `utf8mb4_unicode_ci`: the Unicode-based case-insensitive collation of `utf8mb4`.
+- `utf8mb4` also supports collations for different languages, such as `utf8mb4_zh_pinyin_ci`, which sorts data by Pinyin.
+
+A character set can have multiple collations. However, a collation belongs to only one character set. For example, if you define a column as `c3 varchar(200) COLLATE utf8mb4_bin`, the character set of the column is automatically set to `utf8mb4`.
+
+
+## Set Character Sets for Database Objects
+
+This section describes the specifications for setting character sets in OceanBase Database.
+
+You can set character sets at the tenant, database, table, column, or session level. OceanBase Database supports character sets such as `utf8mb4`, `gbk`, `gb18030`, `binary`, `utf16`, and `latin1`.
+
+```
+obclient [test]> show charset;
++--------------+-----------------------+-------------------------+--------+
+| Charset | Description | Default collation | Maxlen |
++--------------+-----------------------+-------------------------+--------+
+| binary | Binary pseudo charset | binary | 1 |
+| utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 |
+| gbk | GBK charset | gbk_chinese_ci | 2 |
+| utf16 | UTF-16 Unicode | utf16_general_ci | 2 |
+| gb18030 | GB18030 charset | gb18030_chinese_ci | 4 |
+| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
+| gb18030_2022 | GB18030-2022 charset | gb18030_2022_chinese_ci | 4 |
++--------------+-----------------------+-------------------------+--------+
+7 rows in set (0.008 sec)
+
+obclient [test]> show collation;;
++-------------------------+--------------+-----+---------+----------+---------+
+| Collation | Charset | Id | Default | Compiled | Sortlen |
++-------------------------+--------------+-----+---------+----------+---------+
+| utf8mb4_general_ci | utf8mb4 | 45 | Yes | Yes | 1 |
+| utf8mb4_bin | utf8mb4 | 46 | | Yes | 1 |
+| binary | binary | 63 | Yes | Yes | 1 |
+| gbk_chinese_ci | gbk | 28 | Yes | Yes | 1 |
+| gbk_bin | gbk | 87 | | Yes | 1 |
+| utf16_general_ci | utf16 | 54 | Yes | Yes | 1 |
+| utf16_bin | utf16 | 55 | | Yes | 1 |
+| gb18030_chinese_ci | gb18030 | 248 | Yes | Yes | 1 |
+| gb18030_bin | gb18030 | 249 | | Yes | 1 |
+| latin1_swedish_ci | latin1 | 8 | Yes | Yes | 1 |
+| latin1_bin | latin1 | 47 | | Yes | 1 |
+| gb18030_2022_bin | gb18030_2022 | 216 | | Yes | 1 |
+| gb18030_2022_chinese_ci | gb18030_2022 | 217 | Yes | Yes | 1 |
+| gb18030_2022_chinese_cs | gb18030_2022 | 218 | | Yes | 1 |
+| gb18030_2022_radical_ci | gb18030_2022 | 219 | | Yes | 1 |
+| gb18030_2022_radical_cs | gb18030_2022 | 220 | | Yes | 1 |
+| gb18030_2022_stroke_ci | gb18030_2022 | 221 | | Yes | 1 |
+| gb18030_2022_stroke_cs | gb18030_2022 | 222 | | Yes | 1 |
++-------------------------+--------------+-----+---------+----------+---------+
+18 rows in set (0.007 sec)
+```
+
+
+> Note:
+>
+> To support seamless migration, OceanBase Database recognizes UTF8 as a synonym of UTF8MB4.
+>
+> You cannot modify the database character set.
+
+
+In the following examples, the `gbk` character set is used:
+
+* Set the character set when you create a tenant
+
+ * Select **gbk** as the character set when you create a tenant in OceanBase Cloud Platform (OCP).
+
+ 
+
+ * Add `"charset=gbk"` in the `create tenant` statement to set the character set.
+
+ ```shell
+ create tenant zlatan replica_num = 1,
+ resource_pool_list =('pool1'),
+ charset = gbk
+ set
+ ob_tcp_invited_nodes = '%',
+ ob_compatibility_mode = 'mysql',
+ parallel_servers_target = 10,
+ ob_sql_work_area_percentage = 20,
+ secure_file_priv = "";
+ ```
+
+**You can also specify a character set and collation when you create a database, table, or column. If not specified, the character set and collation of the higher-level database object are used. The object levels, from highest to lowest, are tenant, database, table, and column.**
+
+The syntax for creating these database objects will not be described in this section.
+
+
+
+## Set the Client (Link) Character Set
+
+The client (link) character set is used for the interaction between the client and the server.
+
+The client sends SQL statements to the server for execution. The server then returns the execution results to the client.
+
+In this process, the server must recognize the character set used by the client to correctly parse and execute the SQL statements and return the execution results.
+
+In different environments, the client can be OceanBase Command-Line Client (OBClient), Java Database Connectivity (JDBC), or Oracle Call Interface (OCI). The client character set is also called the link character set.
+
+* The tenant character set and the client character set are independent of each other.
+
+ A tenant with the `gbk` character set can be accessed by a client with the `gbk` or `utf8` character set.
+
+ * If the client character set is `gbk`, the server parses and executes the received SQL statements based on `gbk`.
+
+ * If the client character set is `utf8`, the server parses and executes the received SQL statements based on `utf8`.
+
+* Configuration methods
+
+ * Permanent configuration
+
+ ```shell
+ set global character_set_client = gbk;
+ set global character_set_connection = gbk;
+ set global character_set_results = gbk;
+ ```
+
+ * `character_set_client`: the client character set.
+ * `character_set_connection`: the connection character set.
+ * `character_set_results`: the character set of the results returned by the server to the client.
+
+ In most cases, the strings sent by the client to the server and those returned by the server to the client use the same character set. In MySQL mode, these three variables are provided for flexible configuration. **In general scenarios, you can set the three variables to the client character set**.
+
+ * Temporary configuration (valid only for the current session)
+
+ * Method 1:
+
+ ```shell
+ set character_set_client = gbk;
+ set character_set_connection = gbk;
+ set character_set_results = gbk;
+ ```
+
+ * Method 2:
+
+ ```shell
+ set names gbk;
+ ```
+
+## Set the Client Character Set
+
+ * When you use the JDBC driver to connect to an OceanBase database, add `characterEncoding=gbk` to the URL to create a GBK link.
+
+ ```shell
+ String url = "jdbc:oceanbase://xxx.xxx.xxx.xxx:xxxx?useSSL=false&useUnicode=true&characterEncoding=gbk&connectTimeout=30000&rewriteBatchedStatements=true";
+ ```
+
+ * When you use OBClient to connect to an OceanBase database, we recommend that you use the `zh_CN.GB18030` superset of `zh_CN.GBK` for the bash environment variables of the GBK link.
+
+ * Modify the bash environment variables.
+
+ ```shell
+ export LANG=zh_CN.GB18030
+ export LC_ALL=zh_CN.GB18030
+ ```
+
+ * Modify the character set configuration of the terminal to set the character set of the current window to `gbk`. Follow the instructions on the terminal.
+
+
+
+> Notice
+>
+> You must set the client and driver accordingly. Otherwise, garbled characters may occur.
+
+
+## Indexes Do Not Work When Columns with Different Collations Are Joined
+
+As reported by many users in the community, indexes cannot be used for joining two columns with the same data type (such as `varchar`) and the same character set.
+
+This issue usually occurs when different database administrators (DBAs) create the table and columns and set different collations for them. For more information about how to analyze and troubleshoot the issue, see [SQL Tuning Practices - Analyze the Inability to Use Indexes When Joining Columns with Different Collations](https://open.oceanbase.com/blog/14870818145).
+
+**Note that if tables in the production environment are created by different DBAs, you must check the collations set for these tables when using them. Otherwise, query performance may be compromised due to non-optimal plans. **
+
+**If you have no special requirements, we recommend that you set the same collation for columns to be joined when creating them. **
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/development_specification/03_sql_specification.md b/docs/user_manual/operation_and_maintenance/en-US/development_specification/03_sql_specification.md
new file mode 100644
index 000000000..0958c4146
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/development_specification/03_sql_specification.md
@@ -0,0 +1,68 @@
+---
+title: SQL Development Specifications
+weight: 3
+---
+
+> Note:
+>
+> The specifications in this topic are only recommended. You can determine whether to follow these specifications based on your business requirements.
+
+## Specifications for the SELECT Statement
+
+- For an SQL statement that uses a partitioned table, we recommend that you include the partitioning key in the predicate to avoid unnecessary full table scans.
+
+- We recommend that the columns specified in the `ORDER BY` clause be unique or unique in combination.
+ - Unlike a standalone database, a distributed database may produce unstable sorting results when sorting data by a non-unique column, as it implements sorting in a fundamentally different way. For example, the result of `ORDER BY c1` may be as follows in a distributed database:
+
+ |c1|c2|
+ |:---:|:---:|
+ | 1 | a |
+ |1|b|
+ |2|c|
+ |2|d|
+
+ The result may also be as follows:
+ |c1|c2|
+ |:---:|:---:|
+ | 1 | b |
+ |1|a|
+ |2|d|
+ |2|c|
+
+- We recommend that you do not use an `IN` operator. Instead, try to rewrite a subquery with an `IN` operator by using a `JOIN` operator. If an `IN` operator is required, do not specify more than 100 collection elements after the operator.
+
+- If data deduplication is not required, we recommend that you use the ``UNION ALL`` operator instead of the ``UNION`` operator. The ``UNION ALL`` operator can reduce unnecessary resource consumption for sorting.
+
+- COUNT(*) counts the rows with a NULL value, whereas COUNT(column name) does not count rows with a NULL value. Select a proper aggregation method based on your business requirements.
+
+- We recommend that you do not compare or join columns of different data types. Otherwise, implicit data type conversions may be performed and indexes cannot be used. If you must compare or join columns of different data types, you can use the `CAST` or `CONVERT` function to implement explicit data type conversions.
+
+- We do not recommend the `WHERE (c1, c2) = ('abc', 'def')` syntax. First, it is not standard SQL syntax and is applicable only to specific databases, which can cause compatibility issues. Second, although the syntax is supported by specific databases, it cannot utilize indexes or be optimized, compromising query performance. We recommend that you rewrite the preceding filter condition as `WHERE c1 = 'abc' AND c2 = 'def'`.
+
+- When you set the degree of parallelism (DOP) for a query, the query shows the best performance if the DOP equals the number of table shards, and shows the second-best performance if the DOP generated by the auto DOP feature is used.
+
+- We recommend that you do not add a read lock by using `SELECT ... FOR UPDATE (WITH CS)`. Otherwise, it can cause a lock wait and impact the business in the case of highly concurrent large transactions.
+
+- We recommend that you specify column names in the `SELECT` statement as needed. Try to avoid using the ``SELECT * `` syntax, as it may lead to the following issues:
+ - The parsing cost of the query analyzer is increased and additional I/O costs are generated.
+ - Table access by index primary key may occur and compromise query performance.
+ - Adding or removing columns may cause inconsistencies with the upstream and downstream `resultMap` configurations.
+
+## Specifications for DML Statements
+
+- We recommend that you specify column names in an `INSERT` statement instead of using the `INSERT INTO TBL VALUES(......)` syntax. Otherwise, unexpected issues may occur when you add or remove columns in a table.
+
+- A change made by a DML statement is persisted only when the transaction is committed. A single DML statement can be a transaction. You can configure the [autocommit](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001715675) system variable to specify whether to enable automatic commit of transactions. The default value of the system variable is `1`, indicating that a DML statement is taken as a transaction and automatically committed.
+
+- When you execute an `UPDATE` statement that involves a large number of data records without using the `WHERE` clause, a large transaction is generated. If the transaction times out, the `UPDATE` statement may fail to be executed.
+ - We recommend that you use a `WHERE` clause to control the number of rows to be updated in an `UPDATE` statement. This ensures that the transaction is in a proper size.
+ - We recommend that you specify a `WHERE` clause in a `DELETE` statement to delete data in batches. Alternatively, you can use the `TRUNCATE TABLE` statement to delete all data from the table. This can improve data deletion performance. However, the `TRUNCATE` statement is a DDL statement and cannot be executed in another transaction.
+ - You can set greater values for the [ob_query_timeout](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001715719) and [ob_trx_timeout](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001715749) variables to ensure that large transactions can be executed.
+
+- **If you frequently insert, delete, or update data in a table, the buffer table issue may occur. You can enable the adaptive major compaction feature or set the `table_mode` parameter to troubleshoot the issue. For more information, see [Adaptive major compactions](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001719947). **
+
+## Specifications for DDL statements
+
+- **For more information about the online and offline DDL operations supported by OceanBase Database, see [Online and offline DDL operations](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001784252). When offline DDL operations are performed on a table, the table is locked and you cannot perform DML operations on the table. **
+
+- We recommend that you perform DDL operations during off-peak hours to reduce the impact on the system.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/development_specification/04_some_limits.md b/docs/user_manual/operation_and_maintenance/en-US/development_specification/04_some_limits.md
new file mode 100644
index 000000000..f960a87c7
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/development_specification/04_some_limits.md
@@ -0,0 +1,100 @@
+---
+title: Limitations
+weight: 4
+---
+> Note:
+>
+> At present, *OceanBase Advanced Tutorial for DBAs* applies only to MySQL tenants of OceanBase Database Community Edition. Features of Oracle tenants of OceanBase Database Enterprise Edition are not described in this topic. For more information about the differences between the two editions, see [Differences between Enterprise Edition and Community Edition](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714481).
+
+
+## Cluster Name Length
+
+| **Item** | **Maximum length** |
+|------------------------|----------------------|
+| Cluster name | 128 bytes |
+
+## Identifier Length
+
+ | **Item** | **Maximum length** |
+ |------------|-----------------|
+ | Username | 64 bytes |
+ | Tenant name | 63 bytes |
+ | Database name | 128 bytes |
+ | Table name | 64 characters |
+ | Column name | 128 bytes |
+ | Index name | 64 bytes |
+ | View name | 64 bytes |
+ | Alias | 255 bytes |
+ | Table group name | 127 bytes |
+ | User-defined variable | 64 characters |
+
+
+## ODP Connections
+
+### Connections to databases
+
+When you connect to OceanBase Database V4.x by using OceanBase Database Proxy (ODP), free routing between primary and standby databases is not supported.
+
+### Maximum number of connections
+
+| Item | Upper limit |
+|-----------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| Number of connections per ODP | It is specified by the `client_max_connections` parameter of ODP. The default value is `8192`. Note
You can increase the number of ODP nodes or the value of the client_max_connections parameter to increase the maximum number of connections for a cluster.
|
+
+## Number of Partition Replicas
+
+| Item | Upper limit |
+|:---:|:---:|
+| Number of partition replicas per OBServer node | Unlimited.
You can estimate the number of partition replicas of each OBServer node based on the memory size of the tenant. 1 GB of memory supports about 20,000 tablets. |
+
+## Single Table
+
+| Item | Upper limit |
+|:---:|:---:|
+| Row length | 1.5 MB |
+| Number of columns | 4,096 |
+| Number of indexes | 128 |
+| Total number of index columns | 512 |
+| Index length | 16 KB |
+| Total number of primary key columns | 64 |
+| Primary key length | 16 KB |
+| Number of partitions | 8,192 to 65,536.
The maximum number of partitions in a single table in MySQL mode is specified by the tenant-level parameter max_partition_num. The default value is `8192`. |
+
+## Single Column
+
+| Item | Upper limit |
+|:---:|:---:|
+| Length of an index column | 16 KB |
+
+## String Type
+
+ | **Item** | **Maximum length** |
+ |:---:|:---:|
+ | `CHAR` | 256 characters |
+ | `VARCHAR` | 262,144 characters |
+ | `BINARY` | 256 bytes |
+ | `VARBINARY` | 1,048,576 bytes |
+ | `TINYBLOB` | 255 bytes |
+ | `BLOB` | 65,535 bytes |
+ | `MEDIUMBLOB` | 16,777,215 bytes |
+ | `LONGBLOB` | 536,870,910 bytes |
+ | `TINYTEXT` | 255 bytes |
+ | `TEXT` | 65,535 bytes |
+ | `MEDIUMTEXT` | 16,777,215 bytes |
+ | `LONGTEXT` | 536,870,910 bytes |
+
+## Feature Usage
+
+The following table describes the limitations for using the Physical Standby Database feature.
+
+| Item | Description |
+|:---:|:---:|
+| Maximum number of standby tenants supported by one primary tenant | Unlimited. |
+| Whether homogeneous resources are required for the primary and standby tenants | Resources of the primary and standby tenants do not need to be homogeneous. We recommend that you use the same resource specifications for the primary and standby tenants. |
+| Parameters | The parameters of the primary tenant are independent of those of a standby tenant, and parameter modifications are not physically synchronized. After you modify a parameter of the primary tenant, you must assess whether to modify the corresponding parameter of the standby tenants. |
+| System variables | System variables of the primary and standby tenants are physically synchronized. If you modify a system variable of the primary tenant, the system synchronously modifies the corresponding system variable of the standby tenants. |
+| Users and passwords | You can create users and change user passwords only in the primary tenant. The updated information is synchronized to the standby tenants. |
+| Read/write operations | A standby tenant supports only read operations. |
+| Minor and major compactions | Minor compactions in the primary tenant are independent of those in the standby tenants.
Major compactions are not performed in a standby tenant. Instead, the major compaction information is synchronized from the primary tenant to the standby tenants. |
+| Switchover | All replicas of log streams of the standby tenants must be online. |
+| Failover | All replicas of log streams of the standby tenants must be online. |
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/development_specification/_category_.yml b/docs/user_manual/operation_and_maintenance/en-US/development_specification/_category_.yml
new file mode 100644
index 000000000..f5c1a0951
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/development_specification/_category_.yml
@@ -0,0 +1 @@
+label: Database Development Specifications
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/01_high_availability_architecture_overview.md b/docs/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/01_high_availability_architecture_overview.md
new file mode 100644
index 000000000..da516ac46
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/01_high_availability_architecture_overview.md
@@ -0,0 +1,56 @@
+---
+title: Disaster Recovery Architecture Overview
+weight: 1
+---
+
+The database system supports data storage and queries in the application architecture. It is crucial for data security and business continuity of enterprises. High availability is the primary consideration in the architecture design of the database system. High availability includes high availability of services and high reliability of data. This topic describes the technologies for ensuring the high availability of services in OceanBase Database.
+
+OceanBase Database provides a variety of technologies for ensuring high availability of services, including intra-cluster multi-replica disaster recovery and inter-cluster disaster recovery with the Physical Standby Database solution.
+
+> Note: At present, *OceanBase Advanced Tutorial for DBAs* applies only to OceanBase Database Community Edition. Therefore, the arbitration replica feature of OceanBase Database Enterprise Edition is not described in this topic. For more information about the differences between the two editions, see [Differences between Enterprise Edition and Community Edition](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714481).
+
+## Multi-replica Disaster Recovery
+
+
+
+As shown in the preceding figure, the data service layer is an OceanBase cluster. This cluster contains three sub-clusters (zones). Each zone comprises multiple physical servers, and each physical server is called a data node, or an OBServer node. OceanBase Database adopts the shared-nothing distributed architecture, and OBServer nodes are equivalent to each other.
+
+The data stored in OceanBase Database is distributed on multiple OBServer nodes in a zone, and other zones store multiple data replicas. In the preceding figure, the data in the OceanBase cluster has three replicas. Each replica is stored in a separate zone. The three zones comprise a complete database cluster to provide services for users.
+
+OceanBase Database can implement disaster recovery at different levels based on different deployment modes.
+
+* Server-level lossless disaster recovery: The unavailability of a single OBServer node is acceptable, and a lossless switchover can be automatically performed.
+
+* Zone-level lossless disaster recovery: The unavailability of a single Internet data center (IDC) (zone) is acceptable, and a lossless switchover can be automatically performed.
+
+* Region-level lossless disaster recovery: The unavailability in a city (region) is acceptable, and a lossless switchover can be automatically performed.
+
+If your cluster is deployed on multiple OBServer nodes in an IDC, server-level disaster recovery can be achieved. If your OBServer nodes are deployed in multiple IDCs of a region, IDC-level disaster recovery can be achieved. If your OBServer nodes are deployed in multiple IDCs across different regions, region-level disaster recovery can be achieved.
+
+OceanBase Database supports multi-replica disaster recovery based on the Paxos protocol. This solution provides high availability with a recovery point objective (RPO) of 0 and a recovery time objective (RTO) of less than 8 seconds when a minority of replicas fail, meeting the level 6 high availability standard in GB/T 20988-2007.
+
+Multiple OBServer nodes in an OceanBase distributed cluster concurrently provide database services to ensure the high availability of database services. In the preceding figure, the application layer sends a request to OceanBase Database Proxy (ODP), also known as OBProxy, and ODP routes the request to the OBServer node where the requested service data is located. The request result is then returned to the application layer along the same path in the opposite direction. During the entire process, different components contribute to high availability in different ways.
+
+In a cluster consisting of OBServer nodes, all data is stored based on partitions. Each partition has multiple replicas to ensure the high availability. The multiple replicas of a partition are distributed across different zones. Among the replicas, only one replica supports modifications and is called the leader, and other replicas are called followers. Data consistency is ensured between the leader and followers based on the Multi-Paxos protocol. If the OBServer node where the leader is located fails, a follower is elected as the new leader to continue to provide services.
+
+The election service is the basis of high availability. Unlike earlier versions, OceanBase Database V4.x changes the granularity of the election service from partitions to log streams, with partitions mounted to log streams. Among multiple replicas of a log stream, one is elected as the leader based on the election protocol. This type of election is carried out when the cluster restarts or when the previously elected leader becomes faulty.
+
+In OceanBase Database V4.x, the election service no longer depends on clock synchronization services such as Network Time Protocol (NTP) to ensure clock consistency across OBServer nodes in the cluster. Instead, the election service uses local clocks and an enhanced lease mechanism to ensure consistency. The election service adopts a priority mechanism to ensure that the optimal replica is elected as the leader. The priority mechanism also takes the specified primary zone and the status of OBServer nodes into consideration.
+
+After the leader starts to provide services, user operations produce data modifications. All modifications are logged and synchronized to the followers. OceanBase Database uses the Multi-Paxos protocol for log synchronization. Based on the Multi-Paxos protocol, if the persistence of log data is completed on the majority of followers, the log data is retained even if the minority of replicas become faulty. Based on the multiple synchronous replicas, the Multi-Paxos protocol ensures no data loss or service interruption when the minority of OBServer nodes fail. The downtime of the minority of OBServer nodes is acceptable to the data written by users. When an OBServer node fails, the system can select a new replica as the leader to continue to provide database services.
+
+Global Timestamp Service (GTS) is activated for each OceanBase Database tenant. GTS provides a read snapshot version and a commit version for all transactions executed within a tenant to ensure that transactions are committed in order. When GTS is abnormal, transaction-related operations within the tenant are affected. OceanBase Database ensures the reliability and availability of GTS in the same way as that for partition replicas. The GTS location for a tenant is determined by a special partition, which also has multiple replicas. For this special partition, a leader is selected by using the election service, and the OBServer node where the leader is located also hosts GTS. If this OBServer node fails, another replica is selected as the leader for the special partition to provide services. In addition, GTS automatically switches over to the OBServer node where the new leader is located and continues to provide services.
+
+The preceding content describes the key components that help ensure the high availability of OBServer nodes. ODP also requires high availability to maintain its service performance. User requests are first forwarded to ODP. If ODP is abnormal, user requests cannot be properly processed. ODP also needs to handle OBServer node failures and perform fault tolerance operations.
+
+Unlike a database cluster, ODP has no persistent state. ODP obtains the required data by accessing the relevant database. Therefore, ODP failures do not cause data loss. ODP is also a cluster service consisting of multiple nodes. The specific ODP node used to execute user requests is subject to a load balancing component such as F5. If an ODP node fails, the corresponding load balancing component automatically removes the node to ensure that new requests are not forwarded to the node.
+
+ODP monitors the database cluster status in real time. It obtains the cluster system table in real time to check the health status of each server and the real-time location of each partition. ODP also monitors the service status of OBServer nodes based on network connections. If ODP detects an exception, it marks the corresponding OBServer node as faulty and switches over the services.
+
+## Disaster Recovery with the Physical Standby Database Solution
+
+The Physical Standby Database solution is an important part of the high availability capability of OceanBase Database.
+
+This solution is applicable to multi-cluster deployment mode. Transaction logs are transmitted between multiple clusters to provide log-based physical hot backup services. In OceanBase Database V4.2.0 and later, the Physical Standby Database solution adopts an independent primary/standby architecture. Primary and standby tenants can be created. Only logs are transmitted between primary and standby tenants by using a direct network connection or a transmission channel established by using a third-party log service. Unlike the centralized architecture in earlier versions, clusters in the independent primary/standby architecture are separated from each other. You can manage the clusters more flexibly.
+
+Logs are asynchronously transmitted from the primary tenant to standby tenants, and only the Maximum Performance mode is supported. Therefore, if you want to ensure strong data consistency during disaster recovery, use the multi-replica or arbitration-based disaster recovery solution.
diff --git a/docs/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/02_multi_replica_solution.md b/docs/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/02_multi_replica_solution.md
new file mode 100644
index 000000000..e892b437d
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/02_multi_replica_solution.md
@@ -0,0 +1,70 @@
+---
+title: Multi-replica High Availability Solution
+weight: 2
+---
+
+## Multi-replica High Availability Solution Based on Paxos
+
+ This solution is implemented based on the Paxos protocol. Generally, multiple replicas, such as three or five replicas, constitute a cluster and provide disaster recovery capabilities.
+
+ If a minority of replicas, such as one out of three or two out of five, are unavailable, the database can automatically execute a failover and recover services with a recovery point objective (RPO) of 0 and a recovery time objective (RTO) of less than 8 seconds.
+
+You can flexibly adjust the distribution of Internet data centers (IDCs) in different zones and regions of a cluster, as well as the distribution of replicas for tenants in the zones, to adjust the deployment mode of tenants and achieve different levels of disaster recovery.
+
+The following table describes the disaster recovery levels supported in OceanBase Database.
+
+| Deployment mode | Optimal number of replicas | Disaster recovery scenario | Disaster recovery capability |
+|-------------|------------|-----------------------|-------------------|
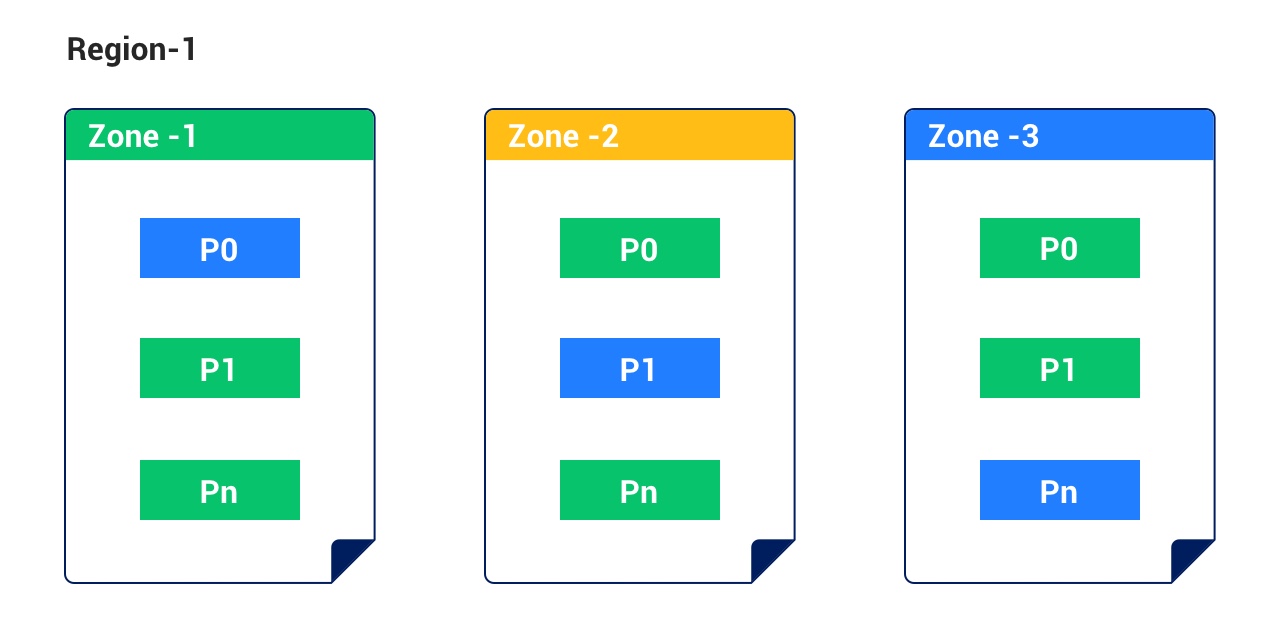
+| Single IDC | 3 | This deployment mode is applicable to scenarios with only a single IDC. Three replicas in the same IDC form a cluster. We recommend that you deploy the replicas of the same copy of data on a group of servers with the same disaster recovery capability, such as the same rack or the same power supply. | - Able to cope with failures of a minority of nodes.
- Unable to cope with IDC-level failures or city-wide failures. IDC-level failures include network disconnection and power outage of the IDC. City-wide failures include natural disasters such as earthquakes, tsunamis, and hurricanes.
|
+| Three IDCs in the same region | 3 | This deployment mode is applicable to scenarios with three IDCs in a city. Three IDCs in the same city form a cluster. Each IDC is a zone. The network latency between the IDCs generally ranges from 0.5 ms to 2 ms. | - Able to cope with failures of a minority of nodes.
- Able to cope with single-IDC failures.
- Unable to cope with city-wide failures.
|
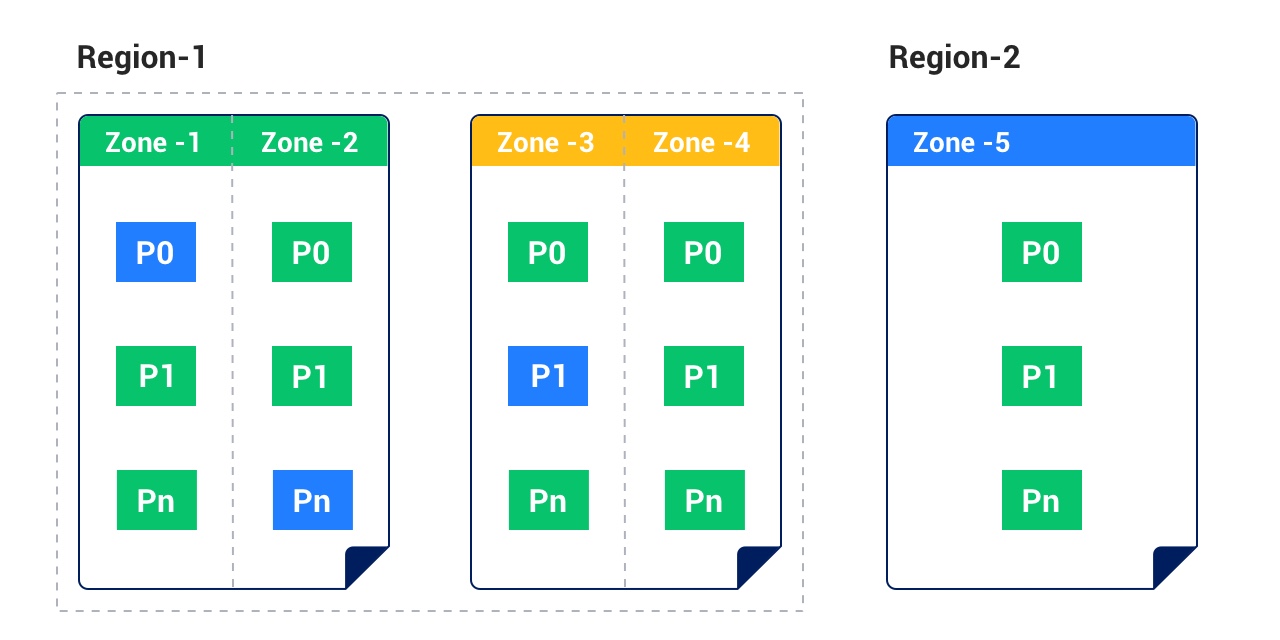
+| Three IDCs across two regions | 5 | This deployment mode is applicable to scenarios with two IDCs in a city. The primary city and the standby city form a cluster with five replicas. The primary city has four replicas distributed in two IDCs and the standby city has one replica. When an IDC fails, at most two replicas are lost, and the remaining three replicas are still available. | - Able to cope with failures of a minority of nodes.
- Able to cope with single-IDC failures.
- Unable to cope with failures in the primary city.
|
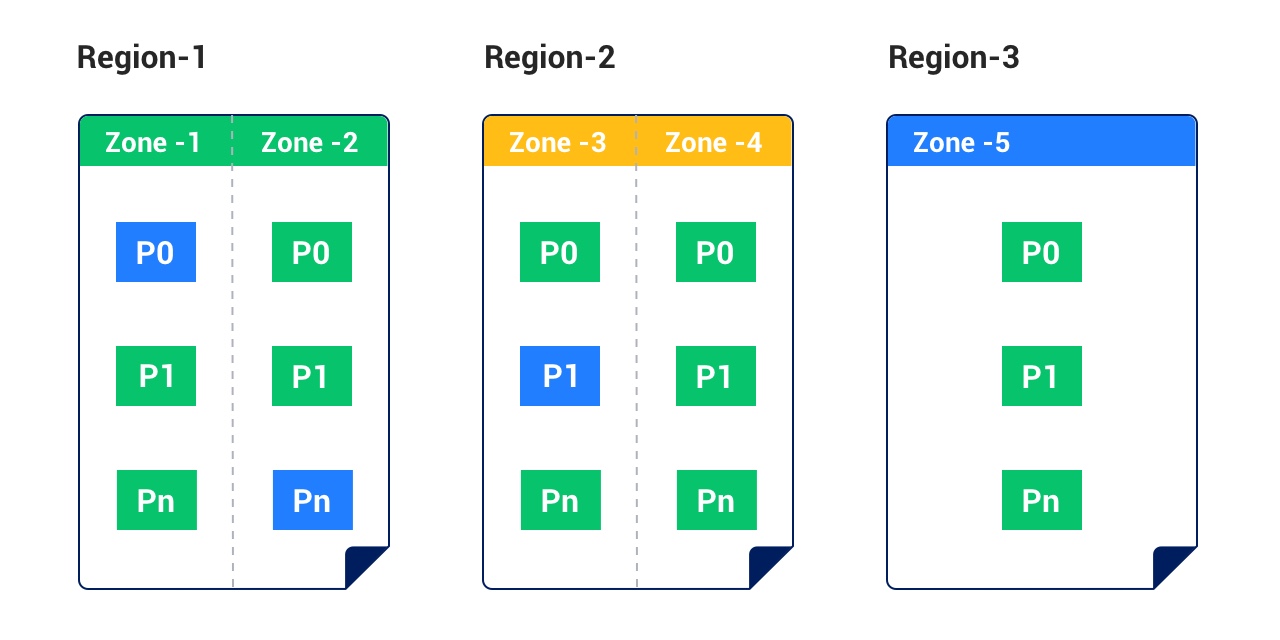
+| Five IDCs across three regions | 5 | This deployment mode is applicable to scenarios where city-level disaster recovery is required. Five replicas in three cities form a cluster. Two cities each have two replicas, and a third city has one replica. In the case of an IDC-level or city-wide failure, the remaining replicas are still available and can guarantee an RPO of 0. | - Able to cope with failures of a minority of nodes.
- Able to cope with failures of a minority of IDCs.
- Able to cope with failures of a minority of cities.
|
+
+
+The following figures show the three deployment modes.
+
+* Three IDCs in the same region
+
+ 
+
+* Three IDCs across two regions
+
+ 
+
+* Five IDCs across three regions
+
+ 
+
+The deployment mode of OceanBase Database is described by the locality of tenants. For more information about the locality settings in the three deployment modes, see "Manage replicas." You can adjust the locality of tenants to flexibly adjust the deployment mode and achieve different levels of disaster recovery. For more information, see [Locality](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714976).
+
+The core logic of multi-replica disaster recovery is to ensure that transaction logs are committed in the majority of replicas based on the Paxos protocol. If a minority of replicas fail, the election protocol guarantees automatic recovery with an RPO of 0. If a majority of replicas fail, manual intervention is required. You can pull up the service based on a single replica. The minority of replicas may not contain the latest data. Therefore, the last part of data may be lost.
+> **Notice**
+>
+> Pulling up the service based on a single replica is not a regular O&M operation, but the last resort taken when a cluster cannot be recovered. It may cause data loss and dual leaders. If you want to perform this operation, contact OceanBase Technical Support for instructions. This topic does not provide operation details.
+
+
+In the financial industry, a conventional relational database is usually deployed in the architecture of three IDCs across two regions. Two IDCs in the same city are deployed in primary/standby mode, and one IDC in the other city is deployed in cold standby mode. The native semi-synchronization mechanism of the database ensures that business updates are also synchronized to the standby database. However, it is not a strong consistency mechanism. When the primary database fails, the latest updates may have not been synchronized to the standby database, and forcibly switching the standby database to a primary database may cause data loss. Therefore, for conventional relational databases in the architecture of three IDCs across two regions, only one of the high availability and strong consistency features can be implemented, and the consistency, availability, partition tolerance (CAP) theorem applies. However, Paxos-based multi-replica disaster recovery of OceanBase Database achieves lossless city-level disaster recovery and geo-disaster recovery, with an RPO of 0 and an RTO of less than 8 seconds.
+
+In the multi-replica disaster recovery architecture of OceanBase Database, applications are aware of only one data source and are unaware of details of internal replication in the database. In addition, this architecture provides lossless single-server, IDC-level, and even city-level disaster recovery with an RTO of less than 8 seconds.
+
+### Single-server disaster recovery
+
+The heartbeat mechanism of OceanBase Database can automatically monitor OBServer node failures. OceanBase Database Proxy (ODP) can also detect OBServer node failures to avoid impact on applications. If an OBServer node is connected but abnormal, you must immediately isolate the OBServer node to avoid transient impact on applications due to the ping-pong effect. For more information, see [Isolate a node](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714999). If the leader automatically elected after you isolate the OBServer node is not the optimal choice, you can manually switch the primary zone to a specific zone. For more information, see [Database-level high availability](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001715084).
+
+Follow-up operations vary based on the following scenarios:
+
+* If the failed OBServer node can be restarted:
+
+ After you restart the OBServer node, it can resume services when the heartbeat connection to RootService is restored, regardless of the previous heartbeat status of the OBServer node. For more information, see [Restart a node](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714995).
+
+* If the failed OBServer node is damaged and cannot be restarted:
+
+ Remove the failed OBServer node and put a new OBServer node online. For more information, see [Replace a node](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001715006).
+
+### IDC-level disaster recovery
+
+IDC-level disaster recovery requires that the cluster be deployed in multiple IDCs, such as three IDCs in the same region or three IDCs across two regions. In this deployment mode, if a minority of replicas are unavailable due to IDC failures, the remaining majority of replicas can still provide services, ensuring zero data loss. If an IDC failure affects only a single zone, you can run the STOP ZONE command to isolate the failed replica. For more information, see [Isolate a zone](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714999). If an IDC failure affects multiple zones, you can manually switch the leader to a specific zone. For more information, see [Database-level high availability](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001715084).
+
+### City-level disaster recovery
+
+City-level disaster recovery requires that the cluster be deployed in multiple cities, such as five IDCs across three regions. In this deployment mode, at most two replicas are lost in the case of a city-wide failure, and the remaining majority of replicas can still provide services, ensuring zero data loss. If the leader automatically elected is not the optimal choice or if you want to avoid the intermittent impact of city-wide failures, you can manually switch the leader to the optimal zone. For more information, see [Database-level high availability](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001715084).
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/03_primary_standby_database_solution.md b/docs/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/03_primary_standby_database_solution.md
new file mode 100644
index 000000000..e16e00304
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/03_primary_standby_database_solution.md
@@ -0,0 +1,55 @@
+---
+title: Physical Standby Database Solution Based on Asynchronous Log Replication
+weight: 3
+---
+
+ This solution is similar to the primary/standby replication solution of traditional databases. Redo logs are replicated among tenants in two or more clusters to form a tenant-level primary/standby relationship. This provides two types of disaster recovery capabilities: switchover and failover.
+
+ This solution is mainly designed for disaster recovery purposes in dual-IDC or dual-region scenarios. The primary tenant provides read and write capabilities, whereas the standby tenants provide read-only and disaster recovery capabilities. When a switchover is performed, the roles of the primary and standby tenants are switched without data loss (RPO = 0) within seconds (RTO within seconds).
+
+ If the cluster of the primary tenant fails, you can perform a failover to make a standby tenant the new primary tenant. In this case, data loss may occur (RPO > 0), and the failover occurs within seconds (RTO within seconds).
+
+
+## Disaster Recovery with the Physical Standby Database Solution
+
+The Physical Standby Database solution allows you to deploy one primary tenant and one or more standby tenants. The primary tenant provides read and write services for your business. The standby tenants synchronize business data written in the primary tenant from redo logs in real time.
+
+You can deploy a primary tenant and its standby tenants in multiple OceanBase clusters that are close to each other or far apart, or in the same OceanBase cluster. In other words, an OceanBase cluster can contain only primary tenants or standby tenants, or both. Tenant names, resource specifications, configurations, and locality of the primary and standby tenants can be different.
+
+In addition, the primary and standby tenants can be single-replica tenants, multi-replica tenants, or tenants with arbitration-based high availability. Different deployment modes provide different levels of replica-based disaster recovery for tenants.
+
+The tenant-level Physical Standby Database solution is highly flexible. You can deploy the solution in the following typical modes:
+
+### A cluster contains only primary or standby tenants
+
+In this deployment mode, you deploy multiple OceanBase clusters, and each OceanBase cluster contains primary or standby tenants.
+
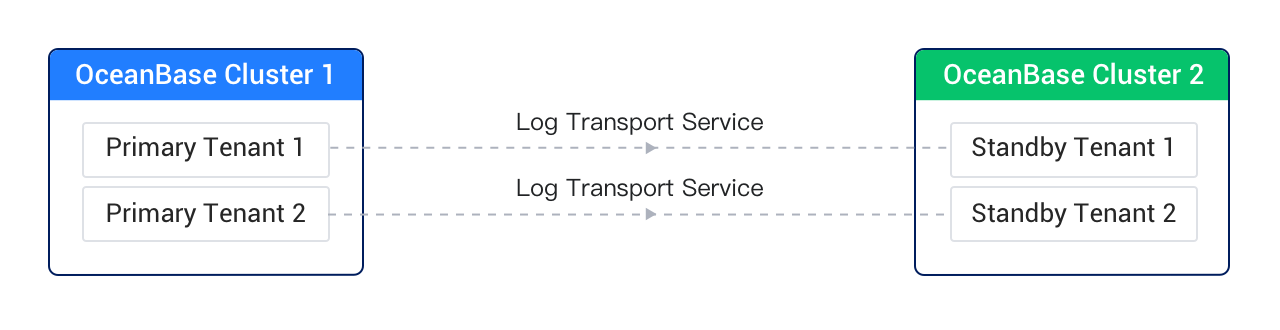
+This deployment mode allows you to use the Physical Standby Database solution for remote disaster recovery.
+
+The following figure shows the architecture of this deployment mode.
+
+
+
+### A cluster contains both primary and standby tenants
+
+In this deployment mode, you deploy multiple OceanBase clusters, and each cluster contains both primary and standby tenants or only primary tenants.
+
+You can use this deployment mode in the following typical scenario:
+
+Your business requires read/write and geo-disaster recovery in two different regions. Therefore, you must deploy both primary and standby databases in each region. In a database using other primary/standby solutions, you must deploy two or more clusters in each of the two regions, and clusters across regions work in primary/standby mode.
+
+If you use OceanBase Database, you need to only deploy one cluster in each of the two regions, and deploy primary and standby tenants in the two clusters to meet your business requirements. This greatly simplifies management of database clusters. The following figure shows the architecture of this deployment mode.
+
+
+
+### Primary and standby tenants belong to one cluster
+
+In this deployment mode, you deploy only one OceanBase cluster, and the primary tenant and one or more standby tenants belong to the same OceanBase cluster.
+
+You can use this deployment mode in the following scenario:
+
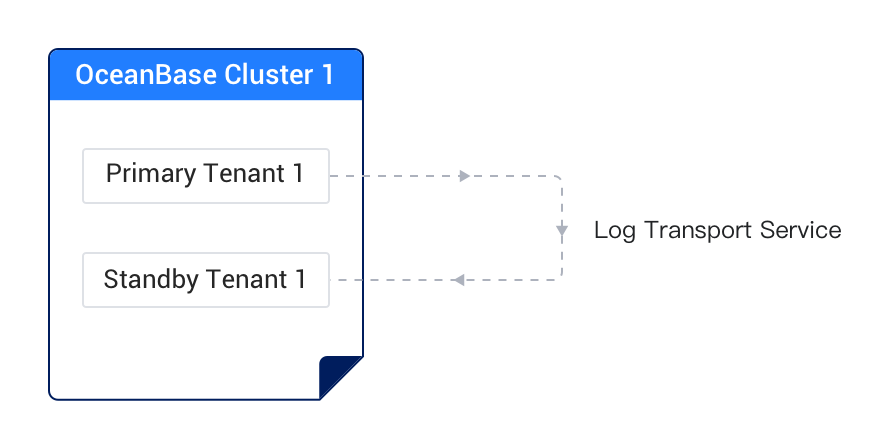
+You need to retain a database snapshot in a business tenant before a business upgrade. You can create a standby tenant for real-time synchronization in the same cluster of the business tenant and suspend the synchronization to the standby tenant before the business upgrade. Then, you can perform any read/write operations, such as starting a business upgrade, in the primary tenant, without affecting the standby tenant. If the business upgrade fails, you can delete the primary tenant and set the standby tenant to a new primary tenant. You can change the name of the new primary tenant to that of the original primary tenant so that access to the proxy remains unchanged.
+
+The following figure shows the architecture of this deployment mode.
+
+
diff --git a/docs/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04_common_disaster_recovery_deployment_models.md b/docs/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04_common_disaster_recovery_deployment_models.md
new file mode 100644
index 000000000..a5c28c643
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04_common_disaster_recovery_deployment_models.md
@@ -0,0 +1,96 @@
+---
+title: Common Deployment Solutions for Disaster Recovery
+weight: 4
+---
+
+## Common Deployment Solutions for Disaster Recovery
+You can use different high-availability solutions in combination. The following table lists the deployment solutions that we recommend for OceanBase Database. You can flexibly choose a deployment solution based on the Internet data center (IDC) configuration and your performance and availability requirements.
+
+| Deployment solution | Disaster recovery capability | RTO | RPO |
+|-------------------|-----------------------------------------------|-------|------|
+| Three replicas in an IDC | Lossless disaster recovery at the server or rack level (when a minority of replicas fail) | < 8 seconds | 0 |
+| Physical standby databases for two IDCs in the same region | Lossy disaster recovery at the IDC level (when the primary IDC fails) | Within seconds | > 0 |
+| Three replicas across three IDCs in the same region | Lossless disaster recovery at the IDC level (when a minority of replicas fail) | < 8 seconds | 0 |
+| Physical standby databases for two IDCs across two regions | Lossy disaster recovery (when a region fails) | Within seconds | > 0 |
+| Physical standby databases for three IDCs across two regions | Lossless disaster recovery (when an IDC fails) or lossy disaster recovery (when a region fails) | Within seconds | When an IDC fails, the RPO is 0. When a region fails, the RPO is greater than 0. |
+| Five replicas in three IDCs across three regions | Lossless disaster recovery (when a region fails) | < 8 seconds | 0 |
+| Five replicas in five IDCs across three regions | Lossless disaster recovery (when a region fails) | < 8 seconds | 0 |
+
+
+### Three replicas in an IDC
+
+If you use only one IDC, you can deploy three or more replicas to achieve lossless disaster recovery at the OBServer node level. If an OBServer node or a minority of OBServer nodes fails, services remain available without data loss. If the IDC contains multiple racks, you can deploy a zone for each rack to achieve lossless disaster recovery at the rack level.
+
+### Physical standby databases for two IDCs in the same region
+
+To achieve disaster recovery at the IDC level with two IDCs in the same region, you can use a physical standby database and deploy a cluster in each IDC. If one of the IDCs is unavailable, another IDC can take over the services. If the standby IDC is unavailable, business data is not affected and services remain available. If the primary IDC is unavailable, the standby database takes over business services. In the second case, data loss may occur because data in the primary database may not be fully synchronized to the standby database.
+
+
+**Characteristics**
+
+* An OceanBase cluster is deployed in each IDC. One serves as the primary database and the other serves as the standby database. Each cluster has a separate Paxos group to maintain data consistency across multiple replicas.
+* Data is synchronized between clusters by using redo logs, which is similar to the leader-follower replication of conventional databases. Data can be synchronized in asynchronous mode, which is similar to Maximum Performance mode of Oracle Data Guard.
+
+**Solution diagram**
+
+.png)
+
+
+### Three replicas across three IDCs in the same region
+
+If three IDCs are available in the same region, you can deploy a zone in each IDC to achieve lossless disaster recovery at the IDC level. If one of the IDCs is unavailable, the other two IDCs can continue to provide services without data loss. This deployment architecture does not rely on physical standby databases, but cannot provide disaster recovery capabilities at the region level.
+
+**Characteristics**
+
+* Three IDCs in the same region form a cluster. Each IDC is a zone, with network latency ranging from 0.5 ms to 2 ms.
+* If an IDC fails, the remaining two replicas are still in the majority. They can enable redo log synchronization and guarantee a recovery point objective (RPO) of 0.
+* This deployment solution cannot cope with city-wide disasters.
+
+**Solution diagram**
+
+.png)
+
+### Physical standby databases for two IDCs across two regions
+
+If you want to achieve region-level disaster recovery but have only one IDC in each region, you can use the physical standby database architecture. Specifically, you can specify one region as the primary region to deploy the primary database, and specify the other region as the standby region to deploy the standby database. When the standby region is unavailable, business services in the primary region are not affected. When the primary region is unavailable, the standby database becomes the new primary database to continue to provide services. In this case, business data loss may occur.
+
+Furthermore, you can use two IDCs in two regions to implement the dual-active architecture and deploy two sets of physical standby databases. In this case, the two regions are in primary/standby mode. This allows you to manage resources in an efficient manner and achieve higher disaster recovery performance.
+
+### Physical standby databases for three IDCs across two regions
+
+If you have three IDCs in two regions, you can use the "physical standby databases for three IDCs across two regions" solution to provide disaster recovery at the region level.
+
+The region with two IDCs serves as the primary region. Each IDC in the primary region is deployed with one or two full-featured replicas. The primary region provides the database read and write services. The arbitration service and physical standby database are deployed in the IDC in the standby region to provide disaster recovery services.
+
+If a fault occurs in an IDC in the primary region, the arbitration service performs automatic downgrade to restore services within seconds without data loss. If both IDCs in the primary region fail at the same time, the physical standby database takes over the services of the primary database. In this case, the RPO is greater than 0 with data loss.
+
+**Characteristics**
+
+* Five replicas in the primary and standby regions form a cluster. When an IDC in the primary region fails, at most two replicas become unavailable, and the remaining three replicas are still in the majority.
+* An independent three-replica cluster is deployed in the standby region and serves as a standby database. Data is asynchronously synchronized from the primary database to the standby database.
+* When the primary region encounters a disaster, the standby region can take over its services.
+
+**Solution diagram**
+
+.png)
+
+
+
+### Five replicas in three IDCs across three regions
+
+To support lossless disaster recovery at the region level, you need to use at least three regions based on the Paxos protocol. This solution involves three regions, each with one IDC. The IDCs in the first two regions have two replicas each, whereas the third IDC has only one replica. Compared with the "three IDCs across two regions" solution, this solution requires each transaction to be synchronized to at least two regions. Business applications must be tolerant of the latency introduced by cross-region replication.
+
+### Five replicas in five IDCs across three regions
+
+This deployment solution is similar to the "five replicas in three IDCs across three regions" solution. The difference is that with five replicas in five IDCs across three regions, each replica is deployed in a different IDC to further enhance the disaster recovery capabilities at the IDC level.
+
+
+**Characteristics**
+
+* Five IDCs across three regions form a cluster with five replicas.
+* In the case of an IDC-level or city-wide failure, the remaining replicas are still in the majority and can guarantee an RPO of 0.
+* The majority must contain at least three replicas. However, each region has at most two replicas. To reduce the latency for synchronizing redo logs, Region 1 and Region 2 must be close to each other.
+
+**Solution diagram**
+
+.png)
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/_index.md b/docs/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/_index.md
new file mode 100644
index 000000000..6e2b12d3b
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/_index.md
@@ -0,0 +1,4 @@
+---
+title: Disaster Recovery Architecture Design
+weight: 2
+---
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/01_emergency_overview.md b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/01_emergency_overview.md
new file mode 100644
index 000000000..9c545da05
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/01_emergency_overview.md
@@ -0,0 +1,81 @@
+---
+title: Overview
+weight: 1
+---
+
+We have been updating *OceanBase Advanced Tutorial for DBAs* for some time, and now it's time to talk about troubleshooting.
+
+Some relevant documents are already available for your reference, such as the blog [Quick Fixes for OceanBase Issues](https://open.oceanbase.com/blog/13250502949) written by an OceanBase engineer and the [Emergency response](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714619) chapter in the official documentation of OceanBase Database.
+
+However, the scenarios and solutions provided in these documents are not systematic or intuitive enough for users of OceanBase Database Community Edition.
+
+Additionally, considering suggestions from community users such as @oceanvoice and @Zhang Yuqi, we will provide a more systematic and comprehensive troubleshooting manual in this advanced tutorial.
+
+The manual will summarize issues that may occur when you use OceanBase Database and provide corresponding solutions. **While these issues may not be common, they can have a serious impact and require database administrators (DBAs) to conduct preliminary analysis and take immediate corrective measures.** The contents are likely to be as follows:
+
+* Overview
+
+* Slow response
+
+* High CPU load
+
+* Node failures
+
+* Hardware and infrastructure exceptions
+
+ * Network jitter
+
+ * Disk issues
+
+* Exceptions caused by load changes
+
+ * Full log/data disk
+
+* ...
+
+
+
+The following figure shows the troubleshooting mind map of OceanBase Database.
+
+
+
+
+## What's More
+
+This topic provides only an overview of the troubleshooting manual and does not contain much in-depth content, for which we apologize. To make up for this, we provide the following **common method for quick recovery in the event of serious OceanBase faults, especially when services are interrupted**. Briefly speaking, you can take the following steps:
+
+- If only one tenant is faulty in a cluster, execute the `ALTER TENANT [SET] PRIMARY_ZONE` statement to change the primary zone of the tenant for leader switchover.
+
+- If only one node is faulty in a cluster, stop or isolate the node.
+
+- If all nodes are faulty in a cluster, restart the nodes one by one.
+
+- If issues persist after all nodes are restarted in the cluster, perform a failover to switch the standby cluster to the primary role.
+
+- Always analyze faults only after they have been handled and the service has been recovered.
+
+
+## Coming Soon
+
+If you encounter cluster issues that are not covered in this manual, you need to contact engineers on duty in the OceanBase community forum to obtain technical support in most cases. As O&M staff, you do not need to further understand the issues. Therefore, these issues are assigned lower priorities. After the advanced tutorial is completed, we will add relevant content in the "Official Selection" module of the OceanBase community forum.
+
+ * sys tenant or RootService exceptions
+
+ * Memory leak
+
+ * Disk space leak
+
+ * Long-running transaction
+
+ * Suspended transaction
+
+ * Core dump
+
+ * ...
+
+
+## References
+
+- [Quick Fixes for OceanBase Issues](https://open.oceanbase.com/blog/13250502949)
+
+- [Emergency response](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714619)
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response.md b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response.md
new file mode 100644
index 000000000..008ca08af
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response.md
@@ -0,0 +1,207 @@
+---
+title: Slow Response
+weight: 2
+---
+
+## Business and Database Symptoms
+
+Business symptom: Business responses slow down or even time out.
+
+Database symptom: SQL execution time increases, and the response time (RT) for SQL requests becomes longer.
+
+## Troubleshooting Approach and Procedure
+
+
+
+
+### Troubleshoot hardware issues
+
+Check whether slow SQL responses are caused by hardware issues such as issues related to networks and disk I/O.
+
+
+
+### Troubleshoot slow queries
+
+Check whether suspicious SQL queries exist in OceanBase Cloud Platform (OCP).
+
+
+If the system responds to short requests with high latency because most resources are occupied by slow queries, you can troubleshoot as follows:
+
+- Enable throttling for slow queries that occupy excessive resources in OCP.
+
+
+- Set the [large_query_worker_percentage](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001715377) parameter to specify the percentage of worker threads reserved for slow queries. The default value of the parameter is 30%.
+
+- Set the [large_query_threshold](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001715457) parameter to specify the threshold for determining a slow query. The default value of the parameter is 5 seconds. Modifying this parameter will significantly affect the system. We recommend that you do not modify the parameter unless you understand it.
+
+- Add hosts in OCP and scale up the OceanBase Database tenant after more nodes are added to zones. For more information, see [Scale out an OceanBase cluster and scale up an OceanBase Database tenant](https://en.oceanbase.com/docs/common-ocp-10000000001703629).
+
+
+
+### Troubleshoot tenant request queue backlogs
+
+#### Troubleshooting methods
+
+In addition to slow queries that occupy excessive resources, you need to troubleshoot tenant request queue backlogs by using the following methods:
+
+- Check if the average queuing time of a slow query as a percentage of the response time is as expected. If the average queuing time is too long, the tenant request queue may be backlogged.
+
+
+
+- Query the information about a slow query in the `GV$OB_SQL_AUDIT` view. For more information, see [Perform analysis based on SQL monitoring views](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_07_diagnosis_and_tuning/analyze_sql_monitoring_view). The following figure shows the intervals between important events.
+
+
+
+ ```
+ -- In this example, an SQL request that is executed by the tenant with ID 1002 after 2024-11-20 12:00:00,
+ -- with an execution time exceeding 100 ms, is queried.
+
+ select
+ tenant_id,
+ request_id,
+ usec_to_time(request_time),
+ elapsed_time,
+ queue_time,
+ execute_time,
+ query_sql
+ from
+ oceanbase.GV$OB_SQL_AUDIT
+ where
+ tenant_id = 1002
+ and elapsed_time > 100000
+ and request_time > time_to_usec('2024-11-20 12:00:00')
+ order by
+ elapsed_time desc
+ limit 1 \G
+
+ *************************** 1. row ***************************
+ tenant_id: 1002
+ request_id: 13329994
+ usec_to_time(request_time): 2024-11-20 15:14:58.765564
+ elapsed_time: 153118
+ queue_time: 34
+ execute_time: 139873
+ query_sql: select * from xxxx where xxxx;
+ 1 row in set (0.11 sec)
+ ```
+
+- **To observe the request queue backlogs of a specific tenant, you can search the logs by using the "dump tenant info" keyword, which is the most common method**.
+ ```
+ grep 'dump tenant info' observer.log*
+ ```
+ 
+
+You can refer to the following keywords in the logs:
+
+1. **req_queue**: the regular request queue.
+
+ - total_size=n: n indicates the total number of requests in the queue.
+
+ - queue[x]=y: y indicates the number of requests at a specific priority in the queue. A smaller value of x indicates a higher priority.
+
+2. **multi_level_queue**: the nested request queue.
+
+ - total_size=n: n indicates the total number of requests in the queue.
+
+ - queue[x]=y: y indicates the number of requests at a specific nesting level in the queue. x indicates the nesting level.
+
+ - queue[0]: non-nested requests. This parameter is left empty in most cases because non-nested requests are queued in the regular request queue.
+
+ - queue[1]: requests at nesting level 1, such as a remote procedure call (RPC) request triggered by an SQL query.
+
+ - queue[2]: requests at nesting level 2, such as an RPC request triggered by another RPC request that was initiated by an SQL query.
+
+ - …
+
+3. **group_id = x, queue_size = y**: y indicates the number of requests in a grouped request queue.
+ - A group is used to process RPC requests of a specific type. Each group ID corresponds to a request type. For more information, see [ob_group_list.h](https://github.com/oceanbase/oceanbase/blob/develop/src/share/resource_manager/ob_group_list.h).
+
+This method allows you to view historical information about both tenant request queues and threads. However, the logs are printed periodically, which means the information is less timely.
+
+- Log in to the sys tenant and execute the following SQL statement to observe request queue backlogs of a tenant:
+ ```
+ obclient [oceanbase]> select * from oceanbase.__all_virtual_dump_tenant_info where tenant_id = 1002\G
+ *************************** 1. row ***************************
+ svr_ip: 11.158.31.20
+ svr_port: 22602
+ tenant_id: 1002
+ compat_mode: 0
+ unit_min_cpu: 2
+ unit_max_cpu: 2
+ slice: 0
+ remain_slice: 0
+ token_cnt: 10
+ ass_token_cnt: 10
+ lq_tokens: 0
+ used_lq_tokens: 0
+ stopped: 0
+ idle_us: 0
+ recv_hp_rpc_cnt: 99
+ recv_np_rpc_cnt: 2226
+ recv_lp_rpc_cnt: 0
+ recv_mysql_cnt: 5459
+ recv_task_cnt: 5
+ recv_large_req_cnt: 0
+ recv_large_queries: 3661
+ actives: 10
+ workers: 10
+ lq_waiting_workers: 0
+ req_queue_total_size: 0
+ queue_0: 0
+ queue_1: 0
+ queue_2: 0
+ queue_3: 0
+ queue_4: 0
+ queue_5: 0
+ large_queued: 0
+ 1 row in set (0.001 sec)
+ ```
+You can view the real-time queue information in the virtual table. However, the virtual table does not record the historical queue information.
+
+#### Solutions
+
+The thread model of OceanBase Database is a typical producer-consumer model. If the request production speed is faster than the request consumption speed for a long period of time, requests are accumulated in queues and the maximum queue size is reached. In this case, error code -4019 is returned.
+
+Even if the maximum queue size is not reached, requests may still wait in the queue for a long period of time in scenarios such as when a large number of auto-increment columns exist. For more information about auto-increment columns, see the "Sequences" section in [Extended features of a MySQL tenant of OceanBase Database](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_06_using_ob_for_business_development/extended_functionality).
+
+To solve this issue, perform the following operations:
+
+- **If the maximum request queue size is reached, you can recover the service only through restart. Rejecting new requests will not help.** We recommend that you submit your question in the [OceanBase community forum](https://ask.oceanbase.com/) and contact engineers on duty to obtain technical support. The engineers will help you obtain stack traces by using obstack or pstack to identify the cause.
+
+- **In most cases, the maximum request queue size will not be reached. Request queue backlogs are the more common issue. **
+ - If the request queue is backlogged, check whether auto-increment columns with the ORDER property exist.
+
+ - If the issue is not caused by bulk data writes to auto-increment columns, contact engineers on duty in the OceanBase community forum to obtain technical support. The engineers will help you analyze stack traces by using obstack or pstack.
+
+ - If the request queue backlog is not caused by deadlocks, you can upgrade tenant specifications to address the issue in special scenarios. The "special scenarios" here refer to situations involving high overhead from threads waiting for locks due to bulk data writes or those involving operations that are extremely CPU-intensive. You can use the top or tsar tool to identify such operations.
+
+
+
+### Troubleshoot plan issues
+
+If slow responses are not caused by resource issues, they may be due to plans.
+
+
+
+If SQL execution is "slowing down", you can troubleshoot the following common issues:
+
+- Bad case of the plan cache (cardinality). For more information about the issue description, troubleshooting method, and solution, see [Bad case of the plan cache](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_07_diagnosis_and_tuning/sql_tuning). This issue may occur in the following scenarios:
+ - If SQL statements are identical except for the constants they contain, the database reuses the same plan from the plan cache for them. This scenario has been introduced in the getting-started tutorial.
+ > To avoid this scenario, later versions of OceanBase Database will cache different plans for SQL statements with the same structure but different constants in certain scenarios.
+ - Statistics on the table accessed by an SQL query have significantly changed, but the database still uses the previously cached plan from the plan cache.
+ > This scenario will also be eliminated in later versions.
+
+
+- Buffer tables. For more information, see [Buffer table issues](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_07_diagnosis_and_tuning/troubleshooting_sql_performance_issues). No details will be provided here.
+ > The getting-started tutorial provides an approach to solving this issue, which is to improve the major compaction frequency of specific tables. In addition to the manual compaction feature, OceanBase Database V4.2.0 and later support the adaptive major compaction feature. You can set the `table_mode` parameter to `queue` to resolve the issue. For more information, see [Adaptive major compactions](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001719947).
+
+- Change of optimal plans to non-optimal plans after version upgrade.
+ - In most cases, plans become more optimal after version upgrade. This issue occurs rarely, and is not described in the getting-started tutorial. You can view the historical trends and plan changes of an SQL statement in OCP to check for the issue.
+
+ - For more information about the solution, see the "Use hints to generate a plan" and "Use an outline to bind a plan" sections in [Read and manage SQL execution plans in OceanBase Database](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_07_diagnosis_and_tuning/management_execution_plan#syntax-of-the-explain-statement).
+
+
+- Hard parsing. You can view the historical trends in the generation time of an SQL execution plan in OCP to check for the issue. For more information about the solution, see the "Hard parsing" section in [Typical scenarios and troubleshooting logic for SQL performance issues](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_07_diagnosis_and_tuning/troubleshooting_sql_performance_issues#tools-for-analyzing-sql-performance-issues).
+
+
+If SQL execution does not change from fast to slow but "remains consistently slow", refer to [SQL performance diagnostics and tuning](https://oceanbase.github.io/docs/user_manual/operation_and_maintenance/scenario_best_practices/chapter_03_htap/performance_tuning).
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high.md b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high.md
new file mode 100644
index 000000000..60f24e456
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high.md
@@ -0,0 +1,89 @@
+---
+title: High CPU Load
+weight: 3
+---
+
+## Business and Database Symptoms
+
+Business symptom: Business delays occasionally occur, and the operation call failure rate increases.
+
+Database symptom: The database receives alerts for high CPU utilization, the response time of SQL queries increases, and the monitored CPU utilization spikes.
+
+## Troubleshooting Approach and Procedure
+
+
+
+
+### Troubleshoot processes with high CPU utilization on an OBServer node
+
+Run the `ps` or `top` command to check whether only the observer process on an OBServer node consumes high CPU utilization.
+```
+ps -eo pid,user,%cpu,cmd --sort=-%cpu
+PID USER %CPU CMD
+124648 user_a 99.9 other_process
+1332 user_b 50.5 observer
+```
+If another process also consumes high CPU utilization on the node, you need to contact the user who runs the process for adjustment.
+
+
+### Troubleshoot suspicious threads on an OBServer node
+
+If only the observer process consumes high CPU utilization, run the `top -H` command to check whether the high CPU consumption is caused by tenant worker threads or background threads.
+
+```
+top -p `pidof observer` -H
+```
+
+#### If high CPU consumption is caused by worker threads
+
+**In 99% of scenarios, we need to only focus on regular threads, which are tenant worker threads instead of background threads, such as TNT_L0_G0_1001 in OceanBase Database V3.1 and T1001_L0_G0 in OceanBase Database V4.x. **
+
+> By the way, worker threads are renamed in OceanBase Database V4.x because the `grep` command often returns unwanted results in OceanBase Database V3.1 when you query worker threads by name. For example, when you run the `grep TNT_L0_G0_1` command, the TNT_L0_G0_1001 thread may also be returned.
+
+If a tenant executes SQL queries that consume a large amount of CPU resources and affect other tenants, you can run the `top -H` command to identify the tenant.
+
+
+
+The preceding results indicate that tenant `1002` causes high CPU utilization.
+
+
+Then, you can go to OceanBase Cloud Platform (OCP) to check which SQL query executed by tenant `1002` is consuming so many CPU resources.
+
+Then, you need to analyze why the SQL query is special based on the knowledge in the previous topic.
+
+
+
+
+
+#### If high CPU consumption is caused by background threads
+
+If you find that high CPU utilization is caused by unfamiliar threads, such as T1_HBService, RootBalance, and IO_GETEVENT0, after you run the `top -H` command, we recommend that you submit your question in the OceanBase community forum and contact the engineers on duty to obtain technical support. The engineers will help you record stack traces by using obstack or pstack to identify the cause.
+
+
+## What's More
+
+> The above is all the content of this topic in the initial release version. The following content was added when we updated the topic.
+
+After finishing writing this topic, I suddenly remembered that my superior once suggested that we could introduce the GUI-based monitoring feature of OCP to users, if possible.
+
+I haven't written such content, as this feature is easy to learn and use. In most cases, you even do not need to read the official documentation.
+
+I conducted a test to see whether I could analyze the cause of high CPU load by using OCP without referring to the official documentation, as shown in the following procedure. My attempt shows that you can easily use the GUI-based monitoring feature of OCP.
+
+- First, I increased the load on the database at 20:37 on November 21, 2024.
+
+- Then, I logged in to the OCP console, clicked **Performance Monitoring** in the left-side navigation pane, and clicked the OBServer node performance tab on the page that appeared. Since the load was increased, I found that the CPU utilization of the target cluster suddenly spiked and almost reached full capacity.
+
+
+- Next, I switched to the database performance tab and found that the SQL response time of the cluster also significantly increased.
+
+
+- Afterward, I switched to the tenant tab to view the monitoring metrics of each tenant in the cluster. I found that the `mysql` tenant has high CPU utilization.
+
+
+- Then, I clicked **SQL Diagnostics**. The diagnostic results showed that the `mysql` tenant is repeatedly executing an extremely complex SQL query.
+
+
+- The cause was therefore identified.
+
+Although the test was conducted on the premise that I already knew the cause of the fault, it still proves that you can use the GUI-based monitoring feature of OCP to troubleshoot high CPU utilization without the need to read the official documentation. Feel confident using this feature.
diff --git a/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/04_node_breakdown.md b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/04_node_breakdown.md
new file mode 100644
index 000000000..7465e1f66
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/04_node_breakdown.md
@@ -0,0 +1,165 @@
+---
+title: Node Failures
+weight: 4
+---
+
+## Business and Database Symptoms
+
+Business symptom: Business fails.
+
+Database symptom: Database services held by a certain OBServer node are unavailable.
+
+## Troubleshooting Approach and Procedure
+
+
+
+### Troubleshoot node failures
+
+Check the availability of the host. If you can log in to the node, run the `ps` command to check whether the observer process is running on the node.
+
+```
+$ps -ef | grep observer
+03:55:52 /home/xiaofeng.lby/obn.obs0/bin/observer
+00:00:00 grep --color=auto observer
+```
+
+If the observer process is running on the node, test the network connectivity of the host on which the node resides. This aims to identify misreported alerts due to network isolation between nodes and network jitter.
+
+For more information, see [Troubleshoot NTP clock synchronization issues](https://www.oceanbase.com/knowledge-base/oceanbase-database-1000000000207684).
+
+
+### If healthy nodes cannot form the majority
+
+If the host or network issue cannot be fixed in time, try the following measures in order:
+
+- Initiate a **failover** to switch the physical standby tenant or cluster to the primary role in OceanBase Cloud Platform (OCP).
+
+- Use the **physical backup and restore** feature in OCP.
+
+- If no physical standby database or data backup is available, restart the observer process on each node in the cluster, one by one.
+
+- If the issue persists after the restart, contact the engineers on duty in the OceanBase community forum for troubleshooting.
+
+- Contact the engineers on duty in the OceanBase community forum to identify the cause.
+
+
+**We recommend that you back up important data and key tenants in the production environment to prevent losses caused by unexpected faults.** You can use the [physical backup and restore](https://en.oceanbase.com/docs/common-ocp-10000000001703571) feature and [create standby tenants or clusters](https://en.oceanbase.com/docs/common-ocp-10000000001703770) in the OCP console.
+
+
+### If healthy nodes can form the majority
+
+- If healthy nodes in the cluster can form the majority, the cluster can elect a new leader within eight seconds by using its high-availability capability and continue to provide services. You need to only restart or replace the abnormal nodes. In most cases, the issue is fixed after you perform the preceding operations. **You can record the following statements. **
+
+ ```
+ -- Before a fault occurs
+ SELECT SVR_IP, ROLE, SCN_TO_TIMESTAMP(END_SCN)
+ FROM oceanbase.GV$OB_LOG_STAT
+ WHERE TENANT_ID = 1 order by LS_ID, ROLE;
+ +---------------+----------+----------------------------+
+ | SVR_IP | ROLE | SCN_TO_TIMESTAMP(END_SCN) |
+ +---------------+----------+----------------------------+
+ | xx.xxx.xxx.1 | FOLLOWER | 2024-11-27 19:44:27.881516 |
+ | xx.xxx.xxx.2 | FOLLOWER | 2024-11-27 19:44:27.881516 |
+ | xx.xxx.xxx.3 | LEADER | 2024-11-27 19:44:27.881516 |
+ +---------------+----------+----------------------------+
+
+ -- After the system elects the leader
+ SELECT SVR_IP, ROLE, SCN_TO_TIMESTAMP(END_SCN)
+ FROM oceanbase.GV$OB_LOG_STAT
+ WHERE TENANT_ID = 1 order by LS_ID, ROLE;
+ +---------------+----------+----------------------------+
+ | SVR_IP | ROLE | SCN_TO_TIMESTAMP(END_SCN) |
+ +---------------+----------+----------------------------+
+ | xx.xxx.xxx.1 | FOLLOWER | 2024-11-27 19:44:38.737837 |
+ | xx.xxx.xxx.2 | LEADER | 2024-11-27 19:44:38.737837 |
+ +---------------+----------+----------------------------+
+ ```
+ > The `SCN_TO_TIMESTAMP(END_SCN)` function obtains the latest system change numbers (SCNs) of replicas of a specific log stream and converts them into timestamps. If the difference between the latest SCN of followers and that of the leader is within five seconds, the logs have been synchronized.
+
+- If the cluster cannot provide services, isolate the abnormal nodes first. Then, determine whether to specify a greater value for the [server_permanent_offline_time](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001715463) parameter. By default, this parameter is set to one hour.
+ ```
+ -- Check the status of nodes in the cluster.
+ select SVR_IP, SVR_PORT, ZONE, WITH_ROOTSERVER, STATUS from oceanbase.DBA_OB_SERVERS;
+ +---------------+----------+-------+-----------------+----------+
+ | SVR_IP | SVR_PORT | ZONE | WITH_ROOTSERVER | STATUS |
+ +---------------+----------+-------+-----------------+----------+
+ | xx.xxx.xxx.3 | 2882 | zone3 | NO | INACTIVE |
+ | xx.xxx.xxx.2 | 2882 | zone2 | YES | ACTIVE |
+ | xx.xxx.xxx.1 | 2882 | zone1 | NO | ACTIVE |
+ +---------------+----------+-------+-----------------+----------+
+
+ -- Check the value of the server_permanent_offline_time parameter.
+ show parameters like "%server_permanent_offline_time%";
+
+ -- Stop the abnormal node to isolate it.
+ alter system stop server 'xx.xxx.xxx.3:2882';
+ ```
+
+ > `STOP SERVER` is the most secure statement for node isolation. The `STOP SERVER` statement can switch the business traffic from an abnormal node to isolate the node from the business traffic. The statement can also ensure that other nodes are still the majority in the Paxos group. This way, you can securely perform all actions on the isolated node. For example, you can run the `pstack` or `obstack` command, adjust the log level, or even stop the observer process. When you need to isolate a fault or stop a node for maintenance, you can use the `STOP SERVER` statement, which is the best choice in this case.
+
+
+- If the cluster remains faulty two minutes after you execute the previous step, manually specify a zone with no faulty nodes as the primary zone for the leader switchover.
+ ```
+ ALTER TENANT tenant_name primary_zone='zone1';
+
+ -- Check the ROLE column in the GV$OB_LOG_STAT view to determine whether the leader switchover is successful.
+ SELECT SVR_IP, ROLE, SCN_TO_TIMESTAMP(END_SCN)
+ FROM oceanbase.GV$OB_LOG_STAT
+ WHERE TENANT_ID = 1 order by LS_ID, ROLE;
+ ```
+
+- If the cluster still cannot provide services three minutes after the leader switchover, refer to the "If healthy nodes cannot form the majority" section of this topic.
+
+- Contact the engineers on duty in the OceanBase community forum to identify the cause.
+
+
+## References
+
+- [Quick Fixes for OceanBase Issues](https://open.oceanbase.com/blog/13250502949)
+- [Troubleshoot common problems](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001715007)
+- [Isolate a node](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714999)
+
+
+
+## Updates Released on December 4, 2024
+
+I want to provide more suggestions for you.
+- If the host of the node can be restored, you can restart the node in OCP.
+
+ 
+
+
+
+ If the node cannot be immediately restarted in OCP, you can go to the installation directory of the node and manually start its observer process.
+
+ ```
+ [xiaofeng.lby@sqaobnoxdn011161204091.sa128 /home/xiaofeng.lby/oceanbase]
+ $sudo su admin
+
+ [admin@sqaobnoxdn011161204091.sa128 /home/xiaofeng.lby/oceanbase]
+ $export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/xiaofeng.lby/oceanbase/lib
+
+ [admin@sqaobnoxdn011161204091.sa128 /home/xiaofeng.lby/oceanbase]
+ $./bin/observer
+ ./bin/observer
+ ```
+ Note that you must run the ``./bin/observer`` command in the `/oceanbase` directory. This may be because specific configuration files in the `etc` directory are required.
+ ```
+ [admin@sqaobnoxdn011161204091.sa128 /home/xiaofeng.lby/oceanbase]
+ $find . -name observer.config.bin
+ ./etc/observer.config.bin
+ ```
+
+- After you restart the node, you can switch back to the original leader during off-peak hours. This prevents the session from accessing the leader through cross-IDC communication for a long period of time.
+ ```
+ ALTER TENANT tenant_name primary_zone='zone1';
+
+ -- Check the ROLE column in the GV$OB_LOG_STAT view to determine whether the leader switchover is successful.
+ SELECT SVR_IP, ROLE, SCN_TO_TIMESTAMP(END_SCN)
+ FROM oceanbase.GV$OB_LOG_STAT
+ WHERE TENANT_ID = 1 order by LS_ID, ROLE;
+ ```
+
+- If the host of the node cannot be restored, add a new node to replace the abnormal node in OCP. After the new node is added, the system automatically adds replicas.
+
+- If no new host is available, you can temporarily use two replicas to provide services. However, this method does not ensure high availability and may cause risks. You must put new hosts online at the earliest opportunity.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem.md b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem.md
new file mode 100644
index 000000000..44c994677
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem.md
@@ -0,0 +1,106 @@
+---
+title: Network Jitter
+weight: 5
+---
+
+> The previous topic describes how to troubleshoot OBServer node failures. The following topics will introduce troubleshooting approaches for certain hardware and environment faults.
+>
+> If you are not interested in topics relevant to faults, you do not need to read such topics in advance. You can bookmark the topics and refer to them when you encounter such faults. In short, you may choose not to read such content, but we must provide it.
+
+> **After a network exception occurs, we recommend that you isolate the exception before you analyze it. **
+
+
+## Business and Database Symptoms
+If a network failure or network jitter occurs, an election without leader is repeatedly initiated among the log streams in the cluster. This results in fluctuations in the response time of application requests.
+
+- Minor network jitters may affect business SQL performance.
+
+- Severe network jitters may cause unstable communication with OceanBase databases, which further causes frequent leader switchovers. The database may even report the [OB_NOT_MASTER (-4038)](https://open.oceanbase.com/quicksearch?q=OB_NOT_MASTER&scope=knowledge) error. In 99.9% of cases, this error occurs because no leader is available due to leader switchover at the bottom layer.
+
+- When the network is disconnected and the network-isolated node hosts the leader, the cluster performs a leader switchover, after which the business recovers. If the sessions on the OBServer node are terminated due to network disconnection, specific business systems may be affected.
+
+## Troubleshooting Approach
+- If network packets are lost, OceanBase Cloud Platform (OCP) reports alerts.
+
+ 
+
+- If a network failure occurs or network packets are lost for a long period of time, OCP may report the [ob_cluster_exists_inactive_server](https://en.oceanbase.com/docs/common-ocp-10000000001899714) alert.
+
+ 
+
+- For more information about how to troubleshoot network failures, see [Network troubleshooting](https://en.oceanbase.com/docs/common-ocp-10000000001899741).
+
+## Troubleshooting Procedure
+
+Check the network of all nodes in the cluster to determine the impact scope.
+
+The following troubleshooting procedure is similar to that for node failures.
+
+### Single-server network failures
+
+- View network monitoring metrics to check whether packet loss and timeout retransmission occur.
+
+- **Isolate the affected server to prevent frequent leader switchovers**.
+ ```
+ -- Stop the abnormal node to isolate it.
+ alter system stop server 'xx.xxx.xxx.x:2882';
+ ```
+- Identify the cause and fix the issue, and then cancel the isolation.
+ ```
+ alter system start server 'xx.xxx.xxx.x:2882';
+ ```
+
+
+### IDC-level network failures
+
+
+- Determine the affected replicas.
+
+- **Specify a new primary zone for leader switchover in the tenant. Isolate the zone where the faulty Internet data center (IDC) resides. For more information, see [Isolate a zone](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714991)**.
+ ```
+ -- Specify a new primary zone for leader switchover in the tenant.
+ ALTER TENANT tenant_name primary_zone='zone2';
+
+ -- Isolate the zone where the faulty IDC resides.
+ ALTER SYSTEM STOP ZONE 'zone1';
+
+ SELECT zone, status FROM oceanbase.DBA_OB_ZONES;
+ +-------+----------+
+ | zone | status |
+ +-------+----------+
+ | zone1 | INACTIVE |
+ | zone2 | ACTIVE |
+ | zone3 | ACTIVE |
+ +-------+----------+
+ ```
+
+- Identify the cause and fix the issue, and then cancel the isolation.
+ ```
+ ALTER SYSTEM START ZONE zone_name;
+
+ SELECT zone, status FROM oceanbase.DBA_OB_ZONES;
+ +-------+--------+
+ | zone | status |
+ +-------+--------+
+ | zone1 | ACTIVE |
+ | zone2 | ACTIVE |
+ | zone3 | ACTIVE |
+ +-------+--------+
+ ```
+
+### Cluster-level network failures
+
+If network failures occur in all IDCs of the cluster and cannot be fixed within a short period of time, you need to switch to the standby cluster. For more information, see [Primary/Standby cluster switchover for disaster recovery](https://en.oceanbase.com/docs/common-ocp-10000000001899404).
+
+
+## Troubleshoot NIC Overload (Update Released on December 5, 2024)
+
+For more information, see [Node network card overload](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001717374).
+
+In my opinion, the backup tasks and data import/export tasks mentioned in the reference topic have a smaller impact on the network than on the disks. In most cases, these factors do not cause NIC overloads.
+
+However, when a special SQL query is executed, network shuffles generated by a distributed plan may cause network overload.
+
+In this case, you can use the SQL diagnostics feature of OCP to optimize the SQL query or throttle the SQL query in OCP.
+
+
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/06_disk_problem.md b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/06_disk_problem.md
new file mode 100644
index 000000000..a9e11e418
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/06_disk_problem.md
@@ -0,0 +1,56 @@
+---
+title: Disk Issues
+weight: 6
+---
+
+## Business and Database Symptoms
+
+The database is not putting pressure on disk I/O, but the io_await value remains high.
+
+> io_await indicates the average amount of time an I/O request waits in a queue to be processed, which reflects the I/O processing efficiency. If the io_await value is small, the I/O queue is not congested.
+>
+> When the io_await value approaches the svctm value, waiting in the I/O queue is almost not required. The svctm metric reflects disk performance, which is usually lower than 20 ms.
+
+## Troubleshooting Approach
+
+OceanBase Cloud Platform (OCP) provides two io_await monitoring metrics: [os_tsar_nvme_ioawait](https://en.oceanbase.com/docs/common-ocp-10000000001899727) and [os_tsar_sda_ioawait](https://en.oceanbase.com/docs/common-ocp-10000000001899731). If the value of any metric is abnormal, OCP reports an alert by default.
+
+
+
+- If the amount of business traffic is small and no other processes consume the disk I/O, the issue is due to data migration, replication, and major compaction. The common solution to this issue is to downgrade some tasks with high I/O load.
+
+- If no such tasks exist, check whether the disk itself is faulty. In most cases, if an exception such as a disk recognition failure occurs, OCP reports an alert indicating that the OBServer node is unavailable, rather than an alert relevant to io_await.
+
+## Troubleshoot Disk Faults
+
+The troubleshooting procedure for disk faults is similar to that for node failures or network jitter.
+
+To put it simply, if faulty disks are the minority, you can troubleshoot the issue as follows:
+
+- Rely on the high-availability mechanism of OceanBase Database to implement self-healing.
+
+- General disk faults cannot be fixed in a short period of time. You need to put new hosts online for the cluster.
+
+- Switch back to the original primary zone during off-peak hours for the tenant.
+
+It is rare for disk faults to occur on all the nodes where the majority of replicas reside. If you encounter this issue, switch to the standby cluster.
+
+
+## Troubleshoot High Disk I/O
+
+High disk I/O usually occurs due to major compactions, also known as daily compactions. You can check in OCP to see if the system is running a major compaction.
+
+
+
+If so, you can suspend the major compaction and then resume it during off-peak hours.
+```
+-- Suspend the running major compaction.
+ALTER SYSTEM SUSPEND MERGE [ZONE [=] 'zone'];
+
+-- Resume the major compaction.
+ALTER SYSTEM RESUME MERGE [ZONE [=] 'zone'];
+```
+
+Other causes, such as data import/export and backup, are rarely seen. For more information, see [Node disk I/O high](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001717376). However, the descriptions of parameter definitions and modifications in the reference topic may contain errors. We recommend that you visit the official website to learn about a parameter before you modify it.
+
+We recommend that you do not manually modify parameters to limit the resources for major and minor compactions, as these parameters do not have recommended values, and your modifications may not have a positive effect. You can adjust the daily compaction time to avoid overlapping business peak hours, which may be an optimal method.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/07_disk_capacity_problem.md b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/07_disk_capacity_problem.md
new file mode 100644
index 000000000..b3935bf9c
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/07_disk_capacity_problem.md
@@ -0,0 +1,244 @@
+---
+title: Full Log/Data Disk
+weight: 6
+---
+
+## Business and Database Symptoms
+
+
+### Full data disk
+
+OceanBase Cloud Platform (OCP) reports a data disk alert, such as the alert for [ob_host_data_path_disk_percent](https://en.oceanbase.com/docs/common-ocp-10000000001899685).
+
+The business application reports an error. OBServer nodes may fail to perform minor compactions, major compactions, or memory release, resulting in a failure to write data to the cluster.
+
+### Full log disk
+
+OCP reports a log disk alert, such as [ob_host_log_disk_percent_over_threshold](https://en.oceanbase.com/docs/common-ocp-10000000001899703).
+
+The business application reports an error. OBServer nodes may not function properly, affecting the election process.
+
+> The methods described in the preceding topics are applicable when other programs generate a large amount of data in the log disk or data disk of an OBServer node. Do not manually delete log files or data files on OBServer nodes. Otherwise, the system may fail to be restored.
+
+## Troubleshooting Approach
+
+### Full data disk
+
+Connect to the `oceanbase` database through the sys tenant and query information about the data disk usage of each node in the cluster, including the total allocated size, occupied size, and remaining size.
+
+```
+SELECT b.zone, a.svr_ip, a.svr_port,
+ ROUND(a.total_size/1024/1024/1024,3) total_size_GB,
+ ROUND((a.total_size-a.free_size)/1024/1024/1024,3) used_size_GB,
+ ROUND(a.free_size/1024/1024/1024,3) free_size_GB,
+ ROUND((a.total_size-a.free_size)/total_size,2)*100 disk_used_percentage
+FROM oceanbase.__all_virtual_disk_stat a
+INNER JOIN oceanbase.__all_server b
+ ON a.svr_ip=b.svr_ip AND a.svr_port=b.svr_port
+ORDER BY zone
+
+*************************** 1. row ***************************
+ zone: zone1
+ svr_ip: 1.2.3.4
+ svr_port: 22602
+ total_size_GB: 8.000
+ used_size_GB: 0.307
+ free_size_GB: 7.693
+disk_used_percentage: 4.00
+```
+
+If the `disk_used_percentage` value exceeds the default alert threshold, which is 97%, the alert reported by OCP is valid.
+
+
+### Full log disk
+
+> The issue of a full log disk rarely occurs because expired logs are recycled.
+
+Check whether the alert reported by OCP is valid on the affected node. The cluster and host information for the node can be found in the alert.
+
+Log in to the sys tenant and connect to the `oceanbase` database. Run the following command to check whether the log disk usage in a tenant exceeds the threshold.
+
+```
+select a.svr_ip,a.svr_port,a.tenant_id,b.tenant_name,
+ CAST(a.data_disk_in_use/1024/1024/1024 as DECIMAL(15,2)) data_disk_use_G,
+ CAST(a.log_disk_size/1024/1024/1024 as DECIMAL(15,2)) log_disk_size,
+ CAST(a.log_disk_in_use/1024/1024/1024 as DECIMAL(15,2)) log_disk_use_G,
+ log_disk_in_use/log_disk_size 'usage%'
+from oceanbase.__all_virtual_unit a,dba_ob_tenants b
+where a.tenant_id=b.tenant_id\G
+
+*************************** 1. row ***************************
+ svr_ip: 1.2.3.4
+ svr_port: 22602
+ tenant_id: 1
+ tenant_name: sys
+data_disk_use_G: 0.10
+ log_disk_size: 2.00
+ log_disk_use_G: 1.54
+ usage%: 0.7693
+*************************** 2. row ***************************
+ svr_ip: 1.2.3.4
+ svr_port: 22602
+ tenant_id: 1001
+ tenant_name: META$1002
+data_disk_use_G: 0.07
+ log_disk_size: 0.60
+ log_disk_use_G: 0.43
+ usage%: 0.7174
+*************************** 3. row ***************************
+ svr_ip: 1.2.3.4
+ svr_port: 22602
+ tenant_id: 1002
+ tenant_name: mysql
+data_disk_use_G: 0.05
+ log_disk_size: 5.40
+ log_disk_use_G: 3.13
+ usage%: 0.5789
+```
+
+
+## Troubleshooting Procedure
+
+### Full data disk
+
+#### Check whether the operating system disk that stores data files has enough remaining capacity for allocation.
+
+If so, modify the cluster-level parameter [datafile_size](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001715485) or [datafile_disk_percentage](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001715434) to increase the available capacity of the data disk for the database.
+
+Run the following commands to check the values of the `datafile_size` and `datafile_disk_percentage` parameters:
+
+```
+show parameters like 'datafile_size'\G
+*************************** 1. row ***************************
+ zone: zone1
+ svr_type: observer
+ svr_ip: 1.2.3.4
+ svr_port: 22602
+ name: datafile_size
+ data_type: CAPACITY
+ value: 2G
+ info: size of the data file. Range: [0, +∞)
+ section: SSTABLE
+ scope: CLUSTER
+ source: DEFAULT
+ edit_level: DYNAMIC_EFFECTIVE
+default_value: 0M
+ isdefault: 0
+1 row in set (0.006 sec)
+```
+
+The default value of the `datafile_size` parameter is `0M`. If the default value is used, the available capacity of the data disk is controlled by the `datafile_disk_percentage` parameter.
+
+```
+show parameters like 'datafile_disk_percentage'\G
+*************************** 1. row ***************************
+ zone: zone1
+ svr_type: observer
+ svr_ip: 11.158.31.20
+ svr_port: 22602
+ name: datafile_disk_percentage
+ data_type: INT
+ value: 0
+ info: the percentage of disk space used by the data files. Range: [0,99] in integer
+ section: SSTABLE
+ scope: CLUSTER
+ source: DEFAULT
+ edit_level: DYNAMIC_EFFECTIVE
+default_value: 0
+ isdefault: 1
+1 row in set (0.006 sec)
+```
+The default value of the `datafile_disk_percentage` parameter is `0`. If the default value is used, the system automatically calculates the percentage of the total disk space occupied by the data file in Shared-Nothing (SN) mode or local cache in Shared-Storage (SS) mode based on whether the logs and data share the same disk.
+- If the same disk is shared, the percentage of the total disk space occupied by data files or local cache is 60%.
+- If the disk is not shared, the percentage of the total disk space occupied by data files or local cache is 90%.
+If this parameter and the `datafile_size` parameter are both specified, the value of the `datafile_size` parameter prevails.
+
+Run the following commands to set the parameters to greater values:
+
+```
+-- Set the size of the data file to 80 GB.
+obclient> ALTER SYSTEM SET datafile_size = '80G';
+
+-- Alternatively, set the percentage of the total disk space occupied by the data file to 95%.
+obclient> ALTER SYSTEM SET datafile_disk_percentage = 90;
+```
+
+**OceanBase Database supports auto scale-out of disk space available for data files based on the actual situation. We recommend that you set the `datafile_next` and `datafile_maxsize` parameters for auto scale-out when you deploy a cluster. For more information, see [Configure automatic scale-out of disk space for data files](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714935). **
+
+**In a production environment, we recommend that the size of the log disk be at least three times the memory size of the host. To avoid I/O performance issues, we recommend that you mount the data directory and the log directory to different disks. **
+
+
+#### If the system disk has no remaining capacity for allocation, add nodes to the zone and migrate resource units to evenly distribute data across nodes.
+
+You can perform GUI-based operations in OCP to add nodes to the zone and migrate resource units. For more information, see [Migrate a resource unit from an OceanBase Database tenant](https://en.oceanbase.com/docs/common-ocp-10000000001899145).
+
+If an OBServer node hosts resource units of multiple tenants, migrate the resource units to evenly distribute data across nodes.
+
+If an OBServer node hosts only one user tenant, purge the recycle bin to delete redundant data.
+
+
+### Full log disk
+
+Check whether the log disk of the cluster has remaining capacity for allocation. If the value of the `log_disk_free` parameter is 0, the log disk has no remaining capacity for allocation.
+```
+select zone,concat(SVR_IP,':',SVR_PORT) observer,
+ cpu_capacity_max cpu_total,cpu_assigned_max cpu_assigned,
+ cpu_capacity-cpu_assigned_max as cpu_free,
+ round(memory_limit/1024/1024/1024,2) as memory_total,
+ round((memory_limit-mem_capacity)/1024/1024/1024,2) as system_memory,
+ round(mem_assigned/1024/1024/1024,2) as mem_assigned,
+ round((mem_capacity-mem_assigned)/1024/1024/1024,2) as memory_free,
+ round(log_disk_capacity/1024/1024/1024,2) as log_disk_capacity,
+ round(log_disk_assigned/1024/1024/1024,2) as log_disk_assigned,
+ round((log_disk_capacity-log_disk_assigned)/1024/1024/1024,2) as log_disk_free,
+ round((data_disk_capacity/1024/1024/1024),2) as data_disk,
+ round((data_disk_in_use/1024/1024/1024),2) as data_disk_used,
+ round((data_disk_capacity-data_disk_in_use)/1024/1024/1024,2) as data_disk_free
+from gv$ob_servers\G
+*************************** 1. row ***************************
+ zone: zone1
+ observer: 11.158.31.20:22602
+ cpu_total: 8
+ cpu_assigned: 4
+ cpu_free: 4
+ memory_total: 8.00
+ system_memory: 1.00
+ mem_assigned: 3.00
+ memory_free: 4.00
+log_disk_capacity: 21.00
+log_disk_assigned: 8.00
+ log_disk_free: 13.00
+ data_disk: 8.00
+ data_disk_used: 0.27
+ data_disk_free: 7.73
+1 row in set (0.006 sec)
+```
+
+If the value of the `log_disk_free` parameter is not 0, the log disk has remaining capacity for allocation. In this case, you can set the log disk size to a greater value for the resource unit of the tenant.
+```
+ALTER RESOURCE UNIT unit_name LOG_DISK_SIZE = '10G';
+```
+
+If the value of the `log_disk_free` parameter is 0, the log disk space allocated to the cluster is used up. You can run the ``df -h`` command to check whether all the capacity of the disk to which the log directory of the node is mounted is allocated to the log directory.
+
+If the disk has remaining capacity for allocation, you can modify the cluster-level parameter [log_disk_size](log_disk_https://en.oceanbase.com/docs/common-oceanbase-database-10000000001715277) or [log_disk_percentage](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001715452) to increase the log disk size available for the cluster. Then, run the ``ALTER RESOURCE UNIT`` command to increase the log disk size available for the tenant.
+
+```
+ALTER system SET log_disk_size = '40G';
+
+ALTER system SET log_disk_percentage = 90;
+```
+
+If the operating system disk has no remaining capacity for allocation, stop the write operations to the abnormal tenant. Otherwise, the space temporarily released from the clog disk can be quickly used up again. At the same time, modify the [log_disk_utilization_limit_threshold](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001715555) parameter to increase the threshold of the clog disk usage from 95% to 98%.
+```
+ALTER system SET log_disk_utilization_limit_threshold = 98;
+```
+
+Wait a period of time until clogs have been synchronized. The capacity is then automatically recycled by the database system and the cluster can be automatically restored.
+
+
+## References
+
+- [Quick Fixes for OceanBase Issues](https://open.oceanbase.com/blog/13250502949)
+
+- [Emergency response](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714619)
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/08_how_to_ask.md b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/08_how_to_ask.md
new file mode 100644
index 000000000..38d874c48
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/08_how_to_ask.md
@@ -0,0 +1,140 @@
+---
+title: Unexpected Errors
+weight: 6
+---
+## Background Information
+
+Many of you may submit questions to the OceanBase community forum when you encounter unexpected errors.
+
+However, it is often observed that only the error code is included in the questions, which is insufficient. You need to include more relevant information, such as the OceanBase Database version, the SQL statement involved, and logs. This helps engineers on duty reproduce the error and identify its cause.
+
+In the following example, only an error code that indicates an internal error is provided, which does not help identify the error cause. The user must also provide relevant logs.
+
+
+
+
+**This topic describes the information that you need to provide to the engineers on duty in the community forum when you encounter unexpected errors, as well as how to retrieve logs. **
+
+## Required Information
+
+The information that you provide will be used by OceanBase Technical Support engineers to reproduce the error and identify its cause. In most cases, the following information is required:
+- The table schema involved in the error
+- The SQL statement that triggered the error
+- The logs that correspond to the error
+
+
+## Retrieve Logs
+
+
+For example, an error is reported when I create a database named `zlatan_db` in a special version of OceanBase Database.
+```
+obclient> create database zlatan_db;
+ERROR 4016 (HY000): Internal error
+```
+
+I can use one of the following methods to retrieve corresponding logs.
+
+### Method 1: select last_trace_id()
+
+In the same session, execute the ``select last_trace_id()`` statement after the SQL statement that triggered the error.
+```
+obclient> create database zlatan_db;
+ERROR 4016 (HY000): Internal error
+
+obclient> select last_trace_id();
++------------------------------------+
+| last_trace_id() |
++------------------------------------+
+| Y584A0B9E1F14-0006299CA6E2263B-0-0 |
++------------------------------------+
+1 row in set (0.00 sec)
+```
+Then, run a `grep` command in a log directory similar to ``/home/user_name/oceanbase/log`` to search for the occurrences of the trace ID in log files.
+
+If the directory contains a small number of log files, run the `grep trace_id *` command in the directory.
+```
+grep Y584A0B9E1F14-0006299CA6E2263B-0-0 * > zlatan.log
+```
+Otherwise, run a `grep` command to search for the occurrences of the trace ID in log files generated within a specific period of time.
+```
+grep Y584A0B9E1F14-0006299CA6E2263B-0-0 observer.log.2024121918* rootservice.log.2024121918* > zlatan.log
+```
+Upload the `zlatan.log` file as an attachment to the question and then post the question in the forum.
+
+You can also highlight ``ret=-4016`` in the `zlatan.log` file, as the reported error code is 4016. The direct cause of the error is found next to the first occurrence of ``ret=-4016`` in the logs.
+
+
+
+```
+rootservice.log.20241219182047574:[2024-12-19 18:12:51.807165] WDIAG [RS]
+create_database (ob_root_service.cpp:3039) [44788][DDLQueueTh0][T0]
+[Y584A0B9E1F14-0006299CA6E2263B-0-0] [lt=18][errcode=-4016]
+create database failed, because db_name is forbidden by zlatan. just for test.(ret=-4016)
+
+rootservice.log.20241219182047574:[2024-12-19 18:12:51.807177] WDIAG [RS] process_
+(ob_rs_rpc_processor.h:206) [44788][DDLQueueTh0][T0]
+[Y584A0B9E1F14-0006299CA6E2263B-0-0] [lt=10][errcode=-4016] process failed(ret=-4016)
+
+rootservice.log.20241219182047574:[2024-12-19 18:12:51.807187] INFO [RS]
+process_ (ob_rs_rpc_processor.h:226) [44788][DDLQueueTh0][T0]
+[Y584A0B9E1F14-0006299CA6E2263B-0-0] [lt=8] [DDL]
+execute ddl like stmt(
+ ret=-4016, cost=117618, ddl_arg=ddl_stmt_str:"create database zlatan_db",
+ exec_tenant_id:1002, ddl_id_str:"", sync_from_primary:false,
+ based_schema_object_infos:[], parallelism:0, task_id:0, consumer_group_id:0)
+```
+
+The preceding results show that the direct cause of error 4016 is ``create database failed, because db_name is forbidden by zlatan. just for test.``
+
+This is because I modified the code in this special version of OceanBase Database to prevent users from naming a database `zlatan_db`. You will never encounter the error. Don't worry.
+```
+int ObRootService::create_database(
+ const ObCreateDatabaseArg &arg,
+ UInt64 &db_id)
+{
+ int ret = OB_SUCCESS;
+
+ // other codes, we ignore
+ // ...
+
+ // add by zlatan, just for debug
+ ObString forbidden_db_name = "zlatan_db";
+ if (arg.database_schema_.get_database_name_str() == forbidden_db_name) {
+ ret = OB_ERR_UNEXPECTED;
+ LOG_WARN("create database failed, because db_name is forbidden by zlatan. just for test.", K(ret));
+ }
+
+ return ret;
+}
+```
+
+### Method 2: grep "ret=-errno"
+
+Method 1 is limited, as **you must execute the ``select last_trace_id()`` statement immediately after the SQL statement that triggered the error, within the same session.**
+
+If another SQL statement has been executed after the SQL statement that triggered the error or the session is exited, you can run the ``grep "ret=-errno"`` command to obtain the trace ID.
+
+```
+$grep "ret=-4016" *
+observer.log.20241219181453955:[2024-12-19 18:12:51.807313]
+WDIAG [RPC] send (ob_poc_rpc_proxy.h:176) [46486][T1002_L0_G0][T1002]
+[Y584A0B9E1F14-0006299CA6E2263B-0-0] [lt=10][errcode=-4016]
+execute rpc fail(addr="11.158.31.20:22602", pcode=520, ret=-4016, timeout=999999400)
+...
+```
+
+Then, retrieve complete logs by running a `grep` command with the trace ID, which is ``Y584A0B9E1F14-0006299CA6E2263B-0-0`` in this example.
+
+```
+grep Y584A0B9E1F14-0006299CA6E2263B-0-0 * > zlatan.log
+```
+
+### Method 3: logs from OCP
+
+If you do not want to run a `grep` command to retrieve logs, you can perform GUI-based operations to obtain logs from OCP. You can use the keyword `ret=-errno` to obtain the logs within the specified time range.
+
+
+
+## What to Do Next
+
+Submit your question in the community forum, with the logs attached.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/_category_.yml b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/_category_.yml
new file mode 100644
index 000000000..fc150b157
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/emergency_handbook/_category_.yml
@@ -0,0 +1 @@
+label: OceanBase Database Troubleshooting Manual
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path.md b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path.md
new file mode 100644
index 000000000..4a07f9364
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path.md
@@ -0,0 +1,92 @@
+---
+title: Version Upgrade Path
+weight: 1
+---
+## Background Information
+This topic is provided based on a suggestion from the user Huangfu Hou on the OceanBase community forum. The user hopes that we can introduce the version upgrade path of OceanBase Database. In this topic, we will summarize and share the basic knowledge of OceanBase Database version upgrades, hoping it will be helpful to you.
+
+
+
+If you have other requirements for the O&M of OceanBase Database, leave a comment on our post in the [OceanBase community](https://ask.oceanbase.com/t/topic/35610431). We will continue to improve this tutorial based on your opinions and suggestions.
+
+
+## Product Version Number
+Before we talk about the upgrade path, we will briefly introduce the product version numbers of OceanBase Database. A product version number represents the version of OBServer nodes, and it is incremented with each release.
+
++ The first digit of a version number represents the architecture level and is incremented only when the architecture is modified. As of September 5, 2024, the first digit of the latest version number is 4.
++ The second and third digits of a version number are incremented when major features of different levels are added.
++ The fourth digit of a version number represents the version of the bundle patch (BP), which is regularly released after a batch of bugfixes are bundled and packaged in each branch version.
+
+Note that when the first three digits of two version numbers are the same, a larger fourth digit indicates a later version. However, this rule does not take effect when the first three digits of the two version numbers are different. To check whether specific bugfixes exist, you must view the product topology.
+
+Some product version numbers may have one of the following suffixes:
+
++ CE: indicates Community Edition.
++ LTS: indicates Long-Term Support Edition. This edition provides long-term support to fix bugs that affect service stability.
++ HF: indicates HotFix Edition. This edition provides key bugfixes to resolve specific intractable issues.
++ GA: indicates General Availability Edition. This edition is secure and reliable, and therefore can be used for extensive deployment and daily operations in the production environment. For example, OceanBase Database V4.3.1 is of General Availability Edition. For more information, see [Official website](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001783557).
+
+In the following figure, 4.2.1_BP8(LTS) indicates OceanBase Database V4.2.1 of Long-Term Support Edition in which eight BPs are released.
+
+
+
+## Barrier Version
+What is a barrier version? Let me start with my personal experience. I once downloaded OceanBase Database V4.2.3.1 and wanted to upgrade a test cluster from OceanBase Database V4.1.0.1 to this version by using OceanBase Cloud Platform (OCP). The test cluster supports only downtime upgrade because it is a single-replica cluster deployed on a single machine.
+
+
+
+I thought the upgrade process would be simple, but OCP prompted me to upload an additional barrier version. That is, I must download the binary files of both OceanBase Database V4.2.1.2 and V4.2.3.1, and provide the files to OCP.
+
+OCP directly upgraded the cluster to V4.2.3.1 after I followed the prompt, without requiring any additional manual operations.
+
+
+
+The following content introduces the concept and purpose of a barrier version.
+
+OceanBase Database supports rolling upgrade between many versions. During the rolling upgrade of a cluster, OBServer nodes of the source version are replaced with those of the target version in sequence. In this case, the database can provide services without downtime as long as the available OBServer nodes form the majority. OBServer nodes that have been upgraded still need to run as nodes of the source version until all the nodes in the cluster are upgraded. Therefore, the code of the source version must be retained in the target version, even if features of the source version are deprecated. This ensures that the cluster can be upgraded without downtime.
+
+To reduce the cost of maintaining code compatibility between source and target versions, we recommend that you do not directly upgrade OceanBase Database from a much earlier version to the latest version. OceanBase Database uses barrier versions to resolve this issue. A barrier version must be passed through when you upgrade from a specific earlier version to a later version. Versions prior to a barrier version must first be upgraded to the barrier version, and only then can they be upgraded to a version later than the barrier version. This way, you do not need to worry about the issue of code compatibility between the latest version and versions prior to the closest barrier version.
+
+If you find the explanation above difficult to understand, that's okay. Let me further introduce this concept based on the two figures below.
+
+As shown in the first figure, there are five versions: A, B, C, D, and E, with C being the barrier version. You can directly upgrade OceanBase Database from A or B to C, or from C to D or E. However, you cannot directly upgrade OceanBase Database from A or B to D or E. To do this, you must upgrade it to C first.
+
+
+
+Note that a version may be the barrier version for some versions but not for others.
+
+The second figure shows four versions: A, B, C, and D, with C being the barrier version for A but not for B. To upgrade OceanBase Database from A to D, you must first upgrade it to C. However, you can directly upgrade OceanBase Database from B to D because C is not the barrier version for B.
+
+
+
+Passing through the barrier version during the upgrade does not require node shutdown, but simply means that the cluster must first be upgraded to the barrier version and then to the target version.
+
+## Upgrade Topology
+This section describes the upgrade topology. The upgrade topology is defined by using the [oceanbase_upgrade_dep.yml](https://github.com/oceanbase/oceanbase/blob/develop/tools/upgrade/oceanbase_upgrade_dep.yml) file.
+
+This file is stored in the installation directory, and its content may vary based on the version. Since the file path for compilation-based installation is different from that for installation using OCP, you need to find the path in the target version package by yourself.
+
+
+
+
+
+The upgrade topology consists of the following parameters:
+
++ `version`: the source version or a transition version during the upgrade.
++ `can_be_upgraded_to`: the target version to which the current version can be directly upgraded.
++ `deprecated`: indicates whether the current version is deprecated. Default value: `False`. The value `True` indicates that the current version has been deprecated and can serve as the source version or a transition version of the upgrade. We recommend that you do not specify a deprecated version as the target version of the upgrade.
++ `require_from_binary`: indicates whether the current version is a barrier version. Default value: `False`.
++ `when_come_from`: the list of source versions for which the current version serves as the barrier version. This parameter is used together with the `require_from_binary` parameter.
+
+
+
+The preceding figure provides an example of upgrade topology, which is simplified and only for reference. The actual upgrade topology in the `oceanbase_upgrade_dep.yml` file is usually more complex.
+
+In this example, the following four versions are available: V4.0.0.0, V4.0.0.1, V4.1.0.0, and V4.2.0.0. The setting `when_come_from: [4.0.0.0]` indicates that V4.1.0.0 is the barrier version for V4.0.0.0.
+
+However, the value of the `when_come_from` parameter does not contain `4.0.0.1`, which indicates that you can directly upgrade from V4.0.0.1 to V4.2.0.0. V4.1.0.0 does not serve as the barrier version for V4.0.0.1.
+
+In summary, you can regard the upgrade topology as a directed acyclic graph that displays the entire upgrade process. Unless a barrier version is specified for the source version, you can directly upgrade from the source version to the target version.
+
+## What's More
+Some users have commented on our post in the [OceanBase community forum](https://ask.oceanbase.com/t/topic/35611595/15), requesting a tool that can directly provide the upgrade path once the source and target versions are specified. This feature may be available in [obdiag](https://github.com/oceanbase/obdiag/issues/428). Stay tuned.
diff --git a/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/_index.md b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/_index.md
new file mode 100644
index 000000000..03d309d4b
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/_index.md
@@ -0,0 +1,4 @@
+---
+title: O&M Management
+weight: 3
+---
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/01_introduction.md b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/01_introduction.md
new file mode 100644
index 000000000..1cc8b5078
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/01_introduction.md
@@ -0,0 +1,22 @@
+---
+title: Introduction
+weight: 1
+---
+
+## Background Information
+This chapter is provided based on a suggestion from the user Xuebei in the OceanBase community forum. Xuebei hopes that we can add some SQL statements or commands commonly used for O&M to this tutorial so that users can maintain OceanBase Database in CLI mode without the need to use specific features of OceanBase Cloud Platform (OCP).
+
+
+
+In this chapter, we will summarize and share the SQL statements commonly used by OceanBase Technical Support for O&M over a long period of time. We hope it is helpful to users who are accustomed to using CLI to maintain OceanBase Database.
+
+You can directly copy and use most of the SQL statements provided in each topic of this chapter. Other SQL statements may require you to modify parameters based on your business requirements before use.
+
+If you have other requirements for the O&M of OceanBase Database, leave a comment on our post in the [OceanBase community](https://ask.oceanbase.com/t/topic/35610431). We will continue to improve this tutorial based on your opinions and suggestions.
+
+## Considerations for View Queries in OceanBase Database V4.x
+We recommend that you query metadata by using views in OceanBase Database V4.x. However, the performance of view queries may be poor. In this case, you can specify more query conditions to improve query performance, such as `tenant_id = 1001`.
+
+In the sys tenant, you can query CDB views or DBA views in the `oceanbase` database. In a user tenant, you can query only DBA views in the `oceanbase` database as the root user in MySQL mode.
+
+For more information about the changes of views, see [Changes in views in OceanBase Database V3.x and V4.x](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001785344).
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/02_cluster_operations.md b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/02_cluster_operations.md
new file mode 100644
index 000000000..52e75e6e3
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/02_cluster_operations.md
@@ -0,0 +1,157 @@
+---
+title: Cluster O&M
+weight: 2
+---
+
+## Query the Version of OceanBase Database
+
+Execute the following SQL statement to query the version of the OceanBase Database installation package as any user, whether in MySQL or Oracle mode:
+
+```
+SHOW VARIABLES LIKE '%version_comment%';
+```
+
+## Query the Name and ID of a Cluster
+
+```
+SELECT
+ *
+FROM
+ gv$ob_parameters
+WHERE
+ name IN ('cluster', 'cluster_id');
+```
+
+## Query the Character Sets Supported by a Cluster
+
+```
+SELECT
+ `collation_name` AS collation,
+ `character_set_name` AS charset,
+ `id`,
+ `is_default`
+FROM
+ information_schema.collations;
+```
+
+
+
+## Query Information about All Zones
+
+```
+SELECT
+ *
+FROM
+ dba_ob_zones;
+```
+
+## Query the Server Status
+
+Execute the following SQL statement to query the information as the `root@sys` user:
+
+```
+SELECT
+ /*+READ_CONSISTENCY(WEAK), QUERY_TIMEOUT(100000000)*/
+ zone,
+ svr_ip,
+ with_rootserver,
+ start_service_time,
+ stop_time,
+ status,
+ substr(
+ build_version,
+ 1,
+ instr(build_version, '-') - 1
+ ) build_version
+FROM
+ dba_ob_servers
+ORDER BY
+ zone,
+ svr_ip;
+```
+
+## Query the Resource Configurations of Servers
+
+Execute the following SQL statement to query the information as the `root@sys` user:
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ svr_ip,
+ svr_port,
+ cpu_capacity_max AS cpu_total,
+ cpu_assigned_max AS cpu_assigned,
+ round(mem_capacity / 1024 / 1024 / 1024) mem_total_gb,
+ round(mem_assigned / 1024 / 1024 / 1024) mem_assigned_gb,
+ round((cpu_assigned_max / cpu_capacity_max), 2) AS cpu_assigned_percent,
+ round((mem_assigned / mem_capacity), 2) AS mem_assigned_percent,
+ round(data_disk_capacity / 1024 / 1024 / 1024) data_disk_capacity_gb,
+ round(data_disk_in_use / 1024 / 1024 / 1024) data_disk_in_use_gb,
+ round(
+ (data_disk_capacity - data_disk_in_use) / 1024 / 1024 / 1024
+ ) data_disk_free_gb,
+ round(log_disk_capacity / 1024 / 1024 / 1024) log_disk_capacity_gb,
+ round(log_disk_assigned / 1024 / 1024 / 1024) log_disk_assigned_gb,
+ round(log_disk_in_use / 1024 / 1024 / 1024) log_disk_in_use_gb
+FROM
+ gv$ob_servers
+ORDER BY
+ svr_ip,
+ svr_port;
+```
+
+## Query Degraded Log Streams of Tenants
+
+```
+SELECT
+ a.tenant_id,
+ ls_id,
+ svr_ip,
+ svr_port,
+ role,
+ arbitration_member,
+ degraded_list
+FROM
+ gv$ob_log_stat a,
+ dba_ob_tenants b
+WHERE
+ degraded_list <> ''
+ AND a.tenant_id = b.tenant_id
+ AND tenant_type != 'META'
+ORDER BY
+ a.tenant_id,
+ svr_ip,
+ svr_port;
+```
+
+## Query the Arbitration Service Information of a Cluster
+
+```
+SELECT
+ arbitration_service_key,
+ arbitration_service,
+ previous_arbitration_service,
+ type
+FROM
+ dba_ob_arbitration_service;
+```
+
+## Query the Major Compaction Progress of Tenants
+
+```
+SELECT
+ tenant_id,
+ compaction_scn,
+ 100 * (
+ 1 - SUM(unfinished_tablet_count) / SUM(total_tablet_count)
+ ) progress_pct
+FROM
+ gv$ob_compaction_progress
+GROUP BY
+ tenant_id,
+ compaction_scn
+ORDER BY
+ compaction_scn
+LIMIT
+ 20;
+```
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/03_tenant_management.md b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/03_tenant_management.md
new file mode 100644
index 000000000..9ccaac8c3
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/03_tenant_management.md
@@ -0,0 +1,522 @@
+---
+title: Tenant Management
+weight: 3
+---
+
+## View the Basic Information of Tenants
+
+```
+SELECT
+ tenant_id,
+ tenant_name,
+ tenant_type,
+ primary_zone,
+ locality,
+ compatibility_mode,
+ status,
+ 0 AS locked,
+ in_recyclebin,
+ timestampdiff(
+ second,
+ create_time,
+ now()
+ ) AS exist_seconds
+FROM
+ dba_ob_tenants
+WHERE
+ tenant_type IN ('SYS', 'USER');
+```
+
+## Query Unit Configs
+
+```
+SELECT
+ unit_config_id,
+ name,
+ max_cpu,
+ min_cpu,
+ round(memory_size / 1024 / 1024 / 1024) max_memory_size_gb,
+ round(memory_size / 1024 / 1024 / 1024) min_memory_size_gb,
+ round(log_disk_size / 1024 / 1024 / 1024) log_disk_size_gb,
+ max_iops,
+ min_iops,
+ iops_weight
+FROM
+ dba_ob_unit_configs
+ORDER BY
+ unit_config_id;
+```
+
+## Query Resource Pools
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ p.tenant_id,
+ u.svr_ip,
+ uc.name,
+ uc.max_cpu,
+ uc.min_cpu,
+ round(uc.memory_size / 1024 / 1024 / 1024) AS max_memory_gb,
+ round(uc.log_disk_size / 1024 / 1024 / 1024) AS log_disk_size_gb,
+ uc.max_iops,
+ uc.min_iops
+FROM
+ dba_ob_resource_pools p,
+ dba_ob_unit_configs uc,
+ dba_ob_units u
+WHERE
+ p.unit_config_id = uc.unit_config_id
+ AND u.resource_pool_id = p.resource_pool_id
+ORDER BY
+ p.tenant_id,
+ u.svr_ip,
+ uc.name;
+```
+
+## Query Units
+
+Execute the following SQL statement to query the information as the `root@sys` user:
+
+```
+SELECT
+ tenant_id,
+ svr_ip,
+ svr_port,
+ unit_id,
+ status,
+ create_time,
+ modify_time,
+ zone,
+ unit_config_id,
+ max_cpu,
+ min_cpu,
+ round(memory_size / 1024 / 1024 / 1024) memory_size_gb,
+ round(log_disk_size / 1024 / 1024 / 1024) log_disk_size_gb,
+ max_iops,
+ min_iops
+FROM
+ dba_ob_units
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ unit_id;
+```
+
+## Query the Disk Usage Information of Tenants
+
+```
+SELECT
+ t1.unit_id,
+ t1.svr_ip,
+ t1.svr_port,
+ t3.tenant_id,
+ t3.tenant_name,
+ round(t1.log_disk_size / 1024 / 1024 / 1024) AS log_disk_size_gb,
+ round(t1.log_disk_in_use / 1024 / 1024 / 1024) AS log_disk_in_use_gb,
+ round(t1.data_disk_in_use / 1024 / 1024 / 1024) AS data_disk_in_use_gb
+FROM
+ (
+ SELECT
+ unit_id,
+ svr_ip,
+ svr_port,
+ SUM(log_disk_size) AS log_disk_size,
+ SUM(log_disk_in_use) AS log_disk_in_use,
+ SUM(data_disk_in_use) AS data_disk_in_use
+ FROM
+ gv$ob_units
+ GROUP BY
+ unit_id,
+ svr_ip,
+ svr_port
+ ) t1
+ JOIN dba_ob_units t2 ON t1.unit_id = t2.unit_id
+ AND t1.svr_ip = t2.svr_ip
+ AND t1.svr_port = t2.svr_port
+ JOIN (
+ SELECT
+ tenant_id,
+ tenant_name
+ FROM
+ dba_ob_tenants
+ WHERE
+ tenant_type IN ('SYS', 'USER')
+ ) t3 ON t2.tenant_id = t3.tenant_id
+ORDER BY
+ t3.tenant_id,
+ t1.svr_ip,
+ t1.svr_port,
+ t1.unit_id;
+```
+
+## Query the Data Amount of a Tenant
+
+Execute the following SQL statement to query the information as the `root@sys` user:
+
+```
+SELECT
+ tenant_id,
+ svr_ip,
+ svr_port,
+ round(SUM(data_size) / 1024 / 1024) data_size_mb,
+ round(SUM(required_size) / 1024 / 1024) required_size_mb
+FROM
+ cdb_ob_tablet_replicas
+WHERE
+ tenant_id = 1002
+GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port;
+```
+
+Execute the following SQL statement in a user tenant:
+
+```
+SELECT
+ svr_ip,
+ svr_port,
+ round(SUM(data_size) / 1024 / 1024) data_size_mb,
+ round(SUM(required_size) / 1024 / 1024) required_size_mb
+FROM
+ dba_ob_tablet_replicas
+GROUP BY
+ svr_ip,
+ svr_port
+ORDER BY
+ svr_ip,
+ svr_port;
+```
+
+## Query the Table Size Statistics of a Tenant
+
+Execute the following SQL statement to query the information as the `root@sys` user.
+
+We recommend that you specify the tenant ID and other parameters to improve query performance.
+
+```
+SELECT
+ /*+ READ_CONSISTENCY(WEAK) QUERY_TIMEOUT(50000000) */
+ a.tenant_id,
+ a.svr_ip,
+ a.svr_port,
+ c.object_type,
+ round(SUM(data_size) / 1024 / 1024) AS data_size_mb,
+ round(SUM(required_size) / 1024 / 1024) AS required_size_mb
+FROM
+ cdb_ob_table_locations a
+ JOIN (
+ SELECT
+ tenant_id,
+ tablet_id,
+ svr_ip,
+ svr_port,
+ data_size,
+ required_size
+ FROM
+ cdb_ob_tablet_replicas
+ ) b ON a.tenant_id = b.tenant_id
+ AND a.tenant_id = 1002
+-- AND a.database_name = 'ALVIN'
+ AND a.tablet_id = b.tablet_id
+ AND a.svr_ip = b.svr_ip
+ AND a.svr_port = b.svr_port
+ JOIN cdb_objects c ON a.tenant_id = c.con_id
+ AND a.table_id = c.object_id
+ AND c.object_type = 'TABLE'
+-- AND c.object_name = 'test'
+GROUP BY
+ a.tenant_id,
+ a.svr_ip,
+ a.svr_port,
+ c.object_type
+ORDER BY
+ a.tenant_id,
+ a.svr_ip,
+ a.svr_port;
+```
+
+If the performance of the preceding query is poor, execute the following SQL statement with the specified tenant ID to query the statistics. The performance of this query is more than 10 times faster.
+
+```
+SELECT
+ /*+ READ_CONSISTENCY(WEAK) QUERY_TIMEOUT(50000000) */
+ a.tenant_id,
+ a.svr_ip,
+ a.svr_port,
+ round(SUM(data_size) / 1024 / 1024) AS data_size_mb,
+ round(SUM(required_size) / 1024 / 1024) AS required_size_mb
+FROM
+ cdb_ob_table_locations a
+ JOIN (
+ SELECT
+ tenant_id,
+ tablet_id,
+ svr_ip,
+ svr_port,
+ data_size,
+ required_size
+ FROM
+ __all_virtual_tablet_meta_table
+ ) b ON a.tenant_id = b.tenant_id
+ AND a.tenant_id = 1002
+ AND a.tablet_id = b.tablet_id
+ AND a.svr_ip = b.svr_ip
+ AND a.svr_port = b.svr_port
+ JOIN __all_virtual_table c ON a.tenant_id = c.tenant_id
+ AND a.table_id = c.table_id
+GROUP BY
+ a.tenant_id,
+ a.svr_ip,
+ a.svr_port
+ORDER BY
+ a.tenant_id,
+ a.svr_ip,
+ a.svr_port;
+```
+
+Execute the following statement with the specified tenant ID and database name to query the statistics sorted by table size:
+
+```
+SELECT
+ /*+ READ_CONSISTENCY(WEAK) QUERY_TIMEOUT(50000000) */
+ a.tenant_id,
+ a.svr_ip,
+ a.svr_port,
+ c.object_type,
+ c.object_name,
+ round(SUM(data_size) / 1024 / 1024) AS data_size_mb,
+ round(SUM(required_size) / 1024 / 1024) AS required_size_mb
+FROM
+ cdb_ob_table_locations a
+ JOIN (
+ SELECT
+ tenant_id,
+ tablet_id,
+ svr_ip,
+ svr_port,
+ data_size,
+ required_size
+ FROM
+ cdb_ob_tablet_replicas
+ ) b ON a.tenant_id = b.tenant_id
+ AND a.tenant_id = 1012
+ AND a.database_name = 'ALVIN'
+ AND a.tablet_id = b.tablet_id
+ AND a.svr_ip = b.svr_ip
+ AND a.svr_port = b.svr_port
+ JOIN cdb_objects c ON a.tenant_id = c.con_id
+ AND a.table_id = c.object_id
+ AND c.object_type = 'TABLE'
+-- AND c.object_name = 'test'
+GROUP BY
+ a.tenant_id,
+ a.svr_ip,
+ a.svr_port,
+ c.object_type,
+ c.object_name
+ORDER BY
+ required_size_mb DESC
+LIMIT
+ 100;
+```
+
+Execute the following SQL statement in a user tenant:
+
+```
+SELECT
+ /*+ READ_CONSISTENCY(WEAK) QUERY_TIMEOUT(50000000) */
+ a.svr_ip,
+ a.svr_port,
+ a.database_name,
+ c.object_type,
+ c.object_name,
+ round(SUM(data_size) / 1024 / 1024) AS data_size_mb,
+ round(SUM(required_size) / 1024 / 1024) AS required_size_mb
+FROM
+ dba_ob_table_locations a
+ JOIN (
+ SELECT
+ tablet_id,
+ svr_ip,
+ svr_port,
+ data_size,
+ required_size
+ FROM
+ dba_ob_tablet_replicas
+ ) b ON a.tablet_id = b.tablet_id
+ AND a.database_name = 'SYS'
+ AND a.svr_ip = b.svr_ip
+ AND a.svr_port = b.svr_port
+ JOIN dba_objects c ON a.table_id = c.object_id
+ AND c.object_type = 'TABLE'
+ AND c.object_name = 'TEST'
+GROUP BY
+ a.svr_ip,
+ a.svr_port,
+ a.database_name,
+ c.object_type,
+ c.object_name
+ORDER BY
+ required_size_mb DESC;
+```
+
+## Query the Distribution of Partitions or Leaders in a Tenant
+
+Execute the following SQL statement to query the information as the `root@sys` user:
+
+```
+SELECT
+ zone,
+ svr_ip,
+ role,
+ COUNT(1) cnt
+FROM
+ cdb_ob_table_locations
+WHERE
+ tenant_id = 1012
+GROUP BY
+ svr_ip,
+ role
+ORDER BY
+ 1,
+ 3 DESC;
+```
+
+Execute the following SQL statement with the specified tenant ID, database name, and object name to query leaders:
+
+```
+SELECT
+ *
+FROM
+ cdb_ob_table_locations a
+WHERE
+ a.tenant_id = 1012
+ AND a.database_name = 'ALVIN'
+ AND (a.tenant_id, a.table_id) IN (
+ SELECT
+ c.con_id,
+ c.object_id
+ FROM
+ cdb_objects c
+ WHERE
+ c.con_id = a.tenant_id
+ AND c.object_type = 'TABLE'
+ AND c.object_name = 'test'
+ )
+LIMIT
+ 100;
+```
+
+Execute the following SQL statement with the specified tenant ID, database name, and object name to query tablet replicas:
+
+```
+SELECT
+ *
+FROM
+ cdb_ob_tablet_replicas r
+WHERE
+ (r.tenant_id, r.tablet_id) IN (
+ SELECT
+ a.tenant_id,
+ a.tablet_id
+ FROM
+ cdb_ob_table_locations a
+ WHERE
+ a.tenant_id = 1012
+ AND a.database_name = 'ALVIN'
+ AND (a.tenant_id, a.table_id) IN (
+ SELECT
+ c.con_id,
+ c.object_id
+ FROM
+ cdb_objects c
+ WHERE
+ c.con_id = a.tenant_id
+ AND c.object_type = 'TABLE'
+ AND c.object_name = 'test'
+ )
+ )
+LIMIT
+ 100;
+```
+
+## Query Databases in MySQL Mode
+
+```
+SELECT
+ o.created AS gmt_create,
+ o.object_id AS database_id,
+ d.database_name,
+ c.id AS collation_type,
+ c.character_set_name,
+ c.collation_name,
+ NULL AS primary_zone,
+ 0 AS read_only
+FROM
+ dba_ob_databases d
+ JOIN dba_objects o ON o.object_type = 'DATABASE'
+ JOIN information_schema.collations c ON d.database_name = o.object_name
+ AND d.collation = c.collation_name;
+```
+
+## Query the Total Number of Tables in Tenants
+
+Execute the following statement to query the total number of tables, except those in the `oceanbase` and `mysql` databases, in non-meta tenants:
+
+```
+SELECT
+ /*+ MONITOR_AGENT QUERY_TIMEOUT(100000000) */
+ t.tenant_id,
+ c.owner,
+ COUNT(*) AS cnt
+FROM
+ cdb_tables c
+ JOIN dba_ob_tenants t ON c.con_id = t.tenant_id
+ AND tenant_type IN ('SYS', 'USER')
+ AND c.owner NOT IN ('oceanbase', 'mysql')
+GROUP BY
+ t.tenant_id,
+ c.owner
+ORDER BY
+ t.tenant_id,
+ c.owner;
+```
+
+Execute the following statement to query the total number of tables in non-meta tenants:
+
+```
+SELECT
+ /*+ MONITOR_AGENT QUERY_TIMEOUT(100000000) */
+ t.tenant_id,
+ COUNT(*) AS cnt
+FROM
+ cdb_tables c
+ JOIN dba_ob_tenants t ON c.con_id = t.tenant_id
+ AND tenant_type IN ('SYS', 'USER')
+GROUP BY
+ t.tenant_id
+ORDER BY
+ t.tenant_id;
+```
+
+Execute the following statement to query the total number of tables in all tenants:
+
+```
+SELECT
+ /*+ MONITOR_AGENT QUERY_TIMEOUT(100000000) */
+ con_id tenant_id,
+ COUNT(*) AS cnt
+FROM
+ cdb_tables
+GROUP BY
+ con_id
+ORDER BY
+ con_id;
+```
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/04_user_and_privilege_management.md b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/04_user_and_privilege_management.md
new file mode 100644
index 000000000..f6376ca68
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/04_user_and_privilege_management.md
@@ -0,0 +1,163 @@
+---
+title: User and Privilege Management
+weight: 4
+---
+
+## Query Objects
+
+```
+SELECT
+ object_type,
+ object_name,
+ owner AS schema_name
+FROM
+ dba_objects
+WHERE
+ object_type IN ('TABLE', 'VIEW', 'PROCEDURE')
+ AND owner NOT IN ('SYS', 'oceanbase');
+```
+
+## Query Users and the Authorization of Global Privileges in MySQL Mode
+
+```
+SELECT
+ `user`,
+ `account_locked`,
+ `select_priv`,
+ `insert_priv`,
+ `update_priv`,
+ `delete_priv`,
+ `create_priv`,
+ `drop_priv`,
+ `process_priv`,
+ `grant_priv`,
+ `index_priv`,
+ `alter_priv`,
+ `show_db_priv`,
+ `super_priv`,
+ `create_view_priv`,
+ `show_view_priv`,
+ `create_user_priv`,
+ `password`
+FROM
+ `mysql`.`user`;
+```
+
+## Query the Authorization of Database Privileges in MySQL Mode
+
+```
+SELECT
+ `db`,
+ `user`,
+ `select_priv`,
+ `insert_priv`,
+ `update_priv`,
+ `delete_priv`,
+ `create_priv`,
+ `drop_priv`,
+ `index_priv`,
+ `alter_priv`,
+ `create_view_priv`,
+ `show_view_priv`
+FROM
+ `mysql`.`db`;
+```
+
+## Query the Authorization of Roles in Oracle Mode
+
+```
+SELECT
+ *
+FROM
+ dba_role_privs
+WHERE
+ grantee = 'SYS'
+ORDER BY
+ grantee,
+ granted_role;
+```
+
+```
+SELECT
+ *
+FROM
+ dba_role_privs
+WHERE
+ granted_role = 'SYS'
+ AND grantee IN (
+ SELECT
+ username
+ FROM
+ dba_users
+ )
+ORDER BY
+ grantee,
+ granted_role;
+```
+
+```
+SELECT
+ *
+FROM
+ dba_role_privs
+WHERE
+ granted_role = 'SYS'
+ AND grantee IN (
+ SELECT
+ role
+ FROM
+ dba_roles
+ )
+ORDER BY
+ grantee,
+ granted_role;
+```
+
+## Query Roles in Oracle Mode
+
+```
+SELECT
+ *
+FROM
+ dba_roles
+ORDER BY
+ role;
+```
+
+
+## Query the Authorization of System Privileges in Oracle Mode
+
+```
+SELECT
+ *
+FROM
+ dba_sys_privs
+WHERE
+ grantee = 'SYS'
+ORDER BY
+ grantee,
+ privilege;
+```
+
+## Query the Authorization of Object Privileges in Oracle Mode
+
+```
+SELECT
+ p.grantee,
+ p.owner,
+ o.object_type,
+ o.object_name,
+ p.privilege
+FROM
+ dba_tab_privs p
+ JOIN dba_objects o ON p.owner = o.owner
+ AND p.table_name = o.object_name
+WHERE
+ p.grantee = 'SYS'
+ORDER BY
+ p.grantee,
+ p.owner,
+ o.object_type,
+ o.object_name,
+ p.privilege;
+```
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/05_backup_and_restore.md b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/05_backup_and_restore.md
new file mode 100644
index 000000000..16213b999
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/05_backup_and_restore.md
@@ -0,0 +1,113 @@
+---
+title: Backup and Restore
+weight: 5
+---
+
+## Query the Status of Log Backup
+
+Execute the following SQL statement to query the information as the `root@sys` user:
+
+```
+SELECT
+ *
+FROM
+ (
+ SELECT
+ incarnation,
+ round_id AS log_archive_round,
+ tenant_id,
+ path AS backup_dest,
+ if(start_scn_display != '', start_scn_display, NULL) AS min_first_time,
+ if(
+ checkpoint_scn_display != '',
+ checkpoint_scn_display,
+ NULL
+ ) AS max_next_time,
+ status,
+ if(
+ checkpoint_scn != '',
+ truncate(
+ (time_to_usec(now()) - checkpoint_scn / 1000) / 1000000,
+ 4
+ ),
+ NULL
+ ) AS delay,
+ now(6) AS check_time
+ FROM
+ cdb_ob_archivelog_summary
+ right JOIN (
+ SELECT
+ tenant_id AS _tenant_id,
+ MAX(round_id) AS _round_id
+ FROM
+ cdb_ob_archivelog_summary
+ GROUP BY
+ _tenant_id
+ ) AS t ON tenant_id = t._tenant_id
+ AND round_id = t._round_id
+ )
+limit
+ 0, 100;
+```
+
+## Query the Status of Full Backup
+
+Execute the following SQL statement to query the information as the `root@sys` user:
+
+```
+SELECT
+ *
+FROM
+ (
+ SELECT
+ job_id,
+ incarnation,
+ tenant_id,
+ backup_set_id,
+ backup_type,
+ path AS backup_dest,
+ start_timestamp AS start_time,
+ end_timestamp AS end_time,
+ now(6) AS check_time,
+ status,
+ comment,
+ description,
+ 'TENANT' AS backup_level
+ FROM
+ (
+ SELECT
+ job_id,
+ incarnation,
+ tenant_id,
+ backup_set_id,
+ backup_type,
+ path,
+ start_timestamp,
+ NULL AS end_timestamp,
+ status,
+ comment,
+ description
+ FROM
+ cdb_ob_backup_jobs
+ UNION
+ SELECT
+ job_id,
+ incarnation,
+ tenant_id,
+ backup_set_id,
+ backup_type,
+ path,
+ start_timestamp,
+ end_timestamp,
+ status,
+ comment,
+ description
+ FROM
+ cdb_ob_backup_job_history
+ )
+ WHERE
+ tenant_id != 1
+ ORDER BY
+ start_time DESC
+ );
+```
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/06_merge_management.md b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/06_merge_management.md
new file mode 100644
index 000000000..8e2775ed3
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/06_merge_management.md
@@ -0,0 +1,200 @@
+---
+title: Compaction Management
+weight: 6
+---
+
+
+## Query the Major Compaction Status of All Tenants in the sys Tenant
+
+Execute the following SQL statements as the `root@sys` user:
+
+```
+SELECT
+ tenant_id,
+ global_broadcast_scn AS broadcast_scn,
+ is_error AS error,
+ status,
+ frozen_scn,
+ last_scn,
+ is_suspended AS suspend,
+ info,
+ start_time,
+ last_finish_time,
+ timestampdiff(second, start_time, last_finish_time) merge_time_second
+FROM
+ cdb_ob_major_compaction
+ORDER BY
+ start_time DESC
+LIMIT
+ 50;
+```
+
+```
+SELECT
+ *
+FROM
+ cdb_ob_zone_major_compaction;
+```
+
+## Query the Major Compaction Status of the Current User Tenant
+
+```
+SELECT
+ global_broadcast_scn AS broadcast_scn,
+ is_error AS error,
+ status,
+ frozen_scn,
+ last_scn,
+ is_suspended AS suspend,
+ info,
+ start_time,
+ last_finish_time,
+ timestampdiff(second, start_time, last_finish_time) merge_time_second
+FROM
+ dba_ob_major_compaction
+ORDER BY
+ start_time DESC
+LIMIT
+ 50;
+```
+
+## Query the Minor Compaction History of Tablets in All Tenants
+
+```
+SELECT
+ *
+FROM
+ gv$ob_tablet_compaction_history
+WHERE
+ type = 'MINI_MERGE'
+ AND finish_time >= date_sub(now(), INTERVAL 2 HOUR)
+ORDER BY
+ start_time DESC
+LIMIT
+ 50;
+```
+
+```
+SELECT
+ tenant_id,
+ MIN(start_time) AS min_start_time,
+ MAX(finish_time) AS max_finish_time,
+ SUM(occupy_size) AS occupy_size,
+ SUM(total_row_count) AS total_row_count,
+ COUNT(1) AS tablet_count
+FROM
+ gv$ob_tablet_compaction_history
+WHERE
+ type = 'MINI_MERGE'
+-- AND finish_time >= date_sub(now(), INTERVAL 600 SECOND)
+-- AND finish_time >= date_sub(now(), INTERVAL 3 HOUR)
+ AND finish_time >= date_sub(now(), INTERVAL 1 DAY)
+GROUP BY
+ tenant_id
+LIMIT
+ 50;
+```
+
+## Query the MemStore Information of All Tenants
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ round(active_span / 1024 / 1024) active_mb,
+ round(memstore_used / 1024 / 1024) memstore_used_mb,
+ round(freeze_trigger / 1024 / 1024) freeze_trigger_mb,
+ round(memstore_limit / 1024 / 1024) mem_limit_mb,
+ freeze_cnt,
+ round(memstore_used / memstore_limit, 2) mem_usage
+FROM
+ gv$ob_memstore
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port;
+```
+
+## Query the MemStore Information of Specified Tenants
+
+```
+SELECT
+ /*+ READ_CONSISTENCY(WEAK),query_timeout(100000000) */
+ t.tenant_id,
+ t.tenant_name,
+ MAX(m.freeze_cnt) AS freeze_cnt,
+ s.value AS minor_freeze_times,
+ round(100 * MAX(m.freeze_cnt) / s.value, 2) AS compact_trigger_ratio
+FROM
+ gv$ob_memstore m
+ JOIN dba_ob_tenants t ON m.tenant_id = t.tenant_id
+ JOIN gv$ob_parameters s ON s.name = 'major_compact_trigger'
+ AND s.tenant_id = t.tenant_id
+WHERE
+ t.tenant_id > 1000
+ AND t.tenant_type <> 'meta'
+GROUP BY
+ m.tenant_id;
+```
+
+## Query the Minor Compaction Information
+
+Execute the following SQL statement to query the information as the `root@sys` user:
+
+```
+SELECT
+ *
+FROM
+ dba_ob_rootservice_event_history
+WHERE
+ event = 'root_minor_freeze'
+ORDER BY
+ timestamp DESC
+LIMIT
+ 30;
+```
+
+## Query the Duration of Major Compactions
+
+Execute the following SQL statement to query the information as the `root@sys` user:
+
+```
+SELECT
+ t.tenant_id,
+ t.global_boradcast_scn,
+ t.merge_begin_time,
+ u.merge_end_time,
+ timestampdiff(second, t.merge_begin_time, u.merge_end_time) merge_time_second
+FROM
+ (
+ SELECT
+ value1 tenant_id,
+ value2 global_boradcast_scn,
+ timestamp merge_begin_time
+ FROM
+ dba_ob_rootservice_event_history
+ WHERE
+ module = 'daily_merge'
+ AND event = 'merging'
+ ) t,
+ (
+ SELECT
+ value1 tenant_id,
+ value2 global_boradcast_scn,
+ timestamp merge_end_time
+ FROM
+ dba_ob_rootservice_event_history
+ WHERE
+ module = 'daily_merge'
+ AND event = 'global_merged'
+ ) u
+WHERE
+ t.tenant_id = u.tenant_id
+ AND t.global_boradcast_scn = u.global_boradcast_scn
+ORDER BY
+ 3 DESC
+LIMIT
+ 10;
+```
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/07_monitoring_metrics.md b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/07_monitoring_metrics.md
new file mode 100644
index 000000000..b3b211bd7
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/07_monitoring_metrics.md
@@ -0,0 +1,549 @@
+---
+title: Monitoring Metrics
+weight: 7
+---
+
+## Query Cache Size Statistics
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ tenant_id,
+ cache_name,
+ round(cache_size / 1024 / 1024) cache_size_mb
+FROM
+ gv$ob_kvcache
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ cache_name;
+```
+
+## Query the Connection Information
+
+```
+SELECT
+ t2.svr_ip,
+ t2.svr_port,
+ t1.tenant_name,
+ coalesce(t2.active_cnt, 0) AS active_cnt,
+ coalesce(t2.all_cnt, 0) AS all_cnt
+FROM
+ (
+ SELECT
+ tenant_name
+ FROM
+ dba_ob_tenants
+ WHERE
+ tenant_type <> 'META'
+ ) t1
+ LEFT JOIN (
+ SELECT
+ count(
+ `state` = 'ACTIVE'
+ OR NULL
+ ) AS active_cnt,
+ COUNT(1) AS all_cnt,
+ tenant AS tenant_name,
+ svr_ip,
+ svr_port
+ FROM
+ gv$ob_processlist
+ GROUP BY
+ tenant,
+ svr_ip,
+ svr_port
+ ) t2 ON t1.tenant_name = t2.tenant_name
+ORDER BY
+ all_cnt DESC,
+ active_cnt DESC,
+ t2.svr_ip,
+ t2.svr_port,
+ t1.tenant_name;
+```
+
+## Query the Delay of Log Stream Synchronization
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ leader.tenant_id,
+ '0' AS replica_type,
+ abs(
+ MAX(
+ CAST(leader_ts AS signed) - CAST(follower_ts AS signed)
+ )
+ ) / 1000000000 max_clog_sync_delay_seconds
+FROM
+ (
+ SELECT
+ MAX(end_scn) leader_ts,
+ tenant_id,
+ role
+ FROM
+ gv$ob_log_stat
+ WHERE
+ role = 'LEADER'
+ GROUP BY
+ tenant_id
+ ) leader
+ INNER JOIN (
+ SELECT
+ MIN(end_scn) follower_ts,
+ tenant_id,
+ role
+ FROM
+ gv$ob_log_stat
+ WHERE
+ role = 'FOLLOWER'
+ GROUP BY
+ tenant_id
+ ) follower ON leader.tenant_id = follower.tenant_id
+GROUP BY
+ leader.tenant_id
+ORDER BY
+ leader.tenant_id;
+```
+
+## Query the Number of Index Errors
+
+```
+SELECT
+ /*+ MONITOR_AGENT QUERY_TIMEOUT(100000000) */
+ COUNT(*) AS cnt
+FROM
+ cdb_indexes
+WHERE
+ status IN ('ERROR', 'UNUSABLE');
+```
+
+## Query the Status of Indexes
+
+```
+SELECT
+ con_id tenant_id,
+ table_type,
+ table_owner,
+ table_name,
+ owner index_owner,
+ index_name,
+ status,
+ index_type,
+ uniqueness,
+ compression
+FROM
+ cdb_indexes
+WHERE
+ con_id = 1012
+ AND table_owner = 'ALVIN'
+-- AND table_name = 'TEST'
+ORDER BY
+ tenant_id,
+ table_owner,
+ table_name,
+ index_name;
+```
+
+## Query Abnormal Indexes
+
+```
+SELECT
+ con_id tenant_id,
+ table_type,
+ table_owner,
+ table_name,
+ owner index_owner,
+ index_name,
+ status,
+ index_type,
+ uniqueness,
+ compression
+FROM
+ cdb_indexes
+WHERE
+ status IN ('ERROR', 'UNUSABLE')
+ AND con_id = 1012
+ AND table_owner = 'ALVIN';
+```
+
+## Query Plan Cache Statistics
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ tenant_id,
+ mem_used,
+ access_count,
+ hit_count
+FROM
+ v$ob_plan_cache_stat;
+```
+
+## Query the Duration of MemTable Snapshots
+
+```
+SELECT
+ /*+ PARALLEL(2), ENABLE_PARALLEL_DML, MONITOR_AGENT */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ MAX(unix_timestamp(now()) - end_log_scn / 1000000000) max_snapshot_duration_seconds
+FROM
+ gv$ob_sstables
+WHERE
+ table_type = 'MEMTABLE'
+ AND is_active = 'NO'
+ AND end_log_scn / 1000000000 > 1
+GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port;
+```
+
+## Query Memory Usage of the Tenant sys500
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ round(SUM(hold) / 1024 / 1024) AS hold_mb,
+ round(SUM(used) / 1024 / 1024) AS used_mb
+FROM
+ gv$ob_memory
+WHERE
+ tenant_id = 500
+ AND mod_name <> 'KvstorCacheMb'
+GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port;
+```
+
+## Query Memory Usage Statistics Grouped by Tenant
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ round(SUM(hold) / 1024 / 1024) AS hold_mb,
+ round(SUM(used) / 1024 / 1024) AS used_mb
+FROM
+ gv$ob_memory
+WHERE
+ mod_name <> 'KvstorCacheMb'
+GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port;
+```
+
+## Query Memory Usage Statistics Grouped by Module
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ mod_name,
+ round(SUM(hold) / 1024 / 1024) AS hold_mb,
+ round(SUM(used) / 1024 / 1024) AS used_mb
+FROM
+ gv$ob_memory
+WHERE
+ mod_name <> 'KvstorCacheMb'
+GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ mod_name
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ mod_name;
+```
+
+## Query Latch Information
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ con_id tenant_id,
+ name,
+ svr_ip,
+ svr_port,
+ gets,
+ misses,
+ sleeps,
+ immediate_gets,
+ immediate_misses,
+ spin_gets,
+ wait_time / 1000000 AS wait_time
+FROM
+ gv$latch
+WHERE
+ (
+ con_id = 1
+ OR con_id > 1000
+ )
+ AND (
+ gets > 0
+ OR misses > 0
+ OR sleeps > 0
+ OR immediate_gets > 0
+ OR immediate_misses > 0
+ )
+ORDER BY
+ tenant_id,
+ name,
+ svr_ip,
+ svr_port;
+```
+
+## Query the Time Spent for Ongoing System Jobs
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ tenant_id,
+ job_type AS task_type,
+ timestampdiff(second, start_time, current_timestamp) AS max_sys_task_duration_seconds,
+ rs_svr_ip AS svr_ip,
+ rs_svr_port AS svr_port
+FROM
+ dba_ob_tenant_jobs
+WHERE
+ job_status = 'INPROGRESS'
+UNION
+SELECT
+ tenant_id,
+ job_type AS task_type,
+ timestampdiff(second, start_time, current_timestamp) AS max_sys_task_duration_seconds,
+ rs_svr_ip AS svr_ip,
+ rs_svr_port AS svr_port
+FROM
+ dba_ob_unit_jobs
+WHERE
+ tenant_id IS NOT NULL
+ AND job_status = 'INPROGRESS'
+ORDER BY
+ tenant_id,
+ task_type,
+ svr_ip,
+ svr_port;
+```
+
+## Query the Time Spent for All System Jobs
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ tenant_id,
+ rs_svr_ip AS svr_ip,
+ rs_svr_port svr_port,
+ job_status,
+ job_type AS task_type,
+ timestampdiff(second, start_time, current_timestamp) AS max_sys_task_duration_seconds
+FROM
+ dba_ob_tenant_jobs
+UNION
+SELECT
+ tenant_id,
+ rs_svr_ip AS svr_ip,
+ rs_svr_port svr_port,
+ job_status,
+ job_type AS task_type,
+ timestampdiff(second, start_time, current_timestamp) AS max_sys_task_duration_seconds
+FROM
+ dba_ob_unit_jobs
+WHERE
+ tenant_id IS NOT NULL
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ job_status,
+ task_type;
+```
+
+## Query the Time Spent for Server Jobs
+
+Execute the following SQL statement to query the time spent for ongoing server jobs:
+
+```
+SELECT
+ job_type AS task_type,
+ timestampdiff(second, start_time, current_timestamp) AS max_sys_task_duration_seconds,
+ svr_ip
+FROM
+ dba_ob_server_jobs
+WHERE
+ job_status = 'INPROGRESS'
+ORDER BY
+ start_time DESC,
+ task_type,
+ job_status;
+```
+
+Execute the following SQL statement to query the time spent for all server jobs:
+
+```
+SELECT
+ job_type AS task_type,
+ job_status,
+ timestampdiff(second, start_time, current_timestamp) AS max_sys_task_duration_seconds,
+ svr_ip
+FROM
+ dba_ob_server_jobs
+ORDER BY
+ start_time DESC,
+ task_type,
+ job_status;
+```
+
+## Query System Event Statistics Grouped by Tenant
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ con_id tenant_id,
+ SUM(total_waits) AS total_waits,
+ SUM(time_waited_micro) / 1000000 AS time_waited
+FROM
+ v$system_event
+WHERE
+ v$system_event.wait_class <> 'IDLE'
+ AND (
+ con_id > 1000
+ OR con_id = 1
+ )
+GROUP BY
+ tenant_id;
+```
+
+## Query System Event Statistics Grouped by Event
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ con_id tenant_id,
+ CASE
+ WHEN event_id = 10000 THEN 'INTERNAL'
+ WHEN event_id = 13000 THEN 'SYNC_RPC'
+ WHEN event_id = 14003 THEN 'ROW_LOCK_WAIT'
+ WHEN (
+ event_id >= 10001
+ AND event_id <= 11006
+ )
+ OR (
+ event_id >= 11008
+ AND event_id <= 11011
+ ) THEN 'IO'
+ WHEN event LIKE 'latch:%' THEN 'LATCH'
+ ELSE 'OTHER'
+END
+ event_group,
+ SUM(total_waits) AS total_waits,
+ SUM(time_waited_micro / 1000000) AS time_waited
+FROM
+ v$system_event
+WHERE
+ v$system_event.wait_class <> 'IDLE'
+ AND (
+ con_id > 1000
+ OR con_id = 1
+ )
+GROUP BY
+ tenant_id,
+ event_group
+ORDER BY
+ tenant_id,
+ event_group;
+```
+
+
+
+## Query System Statistics
+
+```
+SELECT /* MONITOR_AGENT */
+ con_id tenant_id,
+ stat_id,
+ value
+FROM
+ v$sysstat
+WHERE
+ stat_id IN ( 10000, 10001, 10002, 10003, 10004,
+ 10005, 10006, 140002, 140003, 140005,
+ 140006, 140012, 140013, 40030, 80040,
+ 80041, 130000, 130001, 130002, 130004,
+ 20000, 20001, 20002, 30000, 30001,
+ 30002, 30005, 30006, 30007, 30008,
+ 30009, 30010, 30011, 30012, 30013,
+ 30080, 30081, 30082, 30083, 30084,
+ 30085, 30086, 40000, 40001, 40002,
+ 40003, 40004, 40005, 40006, 40007,
+ 40008, 40009, 40010, 40011, 40012,
+ 40018, 40019, 40116, 40117, 40118,
+ 50000, 50001, 60087, 50004, 50005,
+ 50008, 50009, 50010, 50011, 50037,
+ 50038, 60000, 60001, 60002, 60003,
+ 60004, 60005, 60019, 60020, 60021,
+ 60022, 60023, 60024, 80001, 80002,
+ 80003, 80007, 80008, 80009, 80057,
+ 120000, 120001, 120009, 120008 )
+ AND ( con_id > 1000
+ OR con_id = 1 )
+ AND class < 1000;
+```
+
+Execute the following SQL statement to exclude the statistics of meta tenants:
+
+```
+SELECT /* MONITOR_AGENT */
+ tenant_id,
+ stat_id,
+ value
+FROM
+ v$sysstat,
+ dba_ob_tenants
+WHERE
+ stat_id IN ( 30066, 50003, 50021, 50022, 50030,
+ 50039, 50040, 60031, 60057, 60083,
+ 80023, 80025, 80026, 120002, 120005,
+ 120006, 200001, 200002 )
+ AND ( con_id > 1000
+ OR con_id = 1 )
+ AND dba_ob_tenants.tenant_id = v$sysstat.con_id
+ AND dba_ob_tenants.tenant_type <> 'META'
+UNION ALL
+SELECT
+ con_id AS tenant_id,
+ stat_id,
+ value
+FROM
+ v$sysstat
+WHERE
+ stat_id IN ( 80025, 80026, 80023 )
+ AND con_id > 1
+ AND con_id < 1001
+ AND value > 0;
+```
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/08_sql_audit.md b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/08_sql_audit.md
new file mode 100644
index 000000000..d1fb20db2
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/08_sql_audit.md
@@ -0,0 +1,160 @@
+---
+title: SQL Audit
+weight: 8
+---
+
+## Query the Top N SQL Statements with the Highest Elapsed Time That Were Executed in the Last M Minutes
+
+Execute the following SQL statement to query the information as the `root@sys` user:
+
+
+```
+SELECT
+ /*+READ_CONSISTENCY(WEAK), QUERY_TIMEOUT(100000000)*/
+ tenant_id,
+ tenant_name,
+ user_name,
+ db_name,
+ svr_ip,
+ plan_id,
+ plan_type,
+ affected_rows,
+ return_rows,
+ elapsed_time,
+ execute_time,
+ sql_id,
+ usec_to_time(request_time),
+ substr(
+ replace(query_sql, '\n', ' '),
+ 1,
+ 100
+ )
+FROM
+ gv$ob_sql_audit
+WHERE
+ 1 = 1
+ AND request_time > (time_to_usec(now()) - 10 * 60 * 1000000)
+ AND is_inner_sql = 0
+-- AND tenant_id = 1001
+ORDER BY
+ elapsed_time DESC
+LIMIT
+ 10;
+```
+
+## Query the Top N SQL Statements with the Highest QPS That Were Executed in User Tenants in the Last M Minutes
+
+Execute the following SQL statement to query the information as the `root@sys` user:
+
+```
+SELECT
+ /*+READ_CONSISTENCY(WEAK), QUERY_TIMEOUT(100000000)*/
+ tenant_id,
+ sql_id,
+ COUNT(1) / 60 qps,
+ AVG(elapsed_time),
+ AVG(execute_time),
+ AVG(queue_time),
+ AVG(return_rows),
+ AVG(affected_rows),
+ substr(
+ replace(query_sql, '\n', ' '),
+ 1,
+ 100
+ ) query_sql,
+ ret_code
+FROM
+ gv$ob_sql_audit
+WHERE
+ 1 = 1
+ AND request_time > (time_to_usec(now()) - 10 * 60 * 1000000)
+ AND is_inner_sql = 0
+ AND tenant_id > 1000
+GROUP BY
+ tenant_id,
+ sql_id,
+ query_sql,
+ ret_code
+ORDER BY
+ qps DESC
+LIMIT
+ 10;
+```
+
+## Query Details of the Last N SQL Statements Executed Based on SQL Statement IDs
+
+Execute the following SQL statement to query the information as the `root@sys` user:
+
+```
+SELECT
+ /*+READ_CONSISTENCY(WEAK), QUERY_TIMEOUT(100000000)*/
+ *
+FROM
+ gv$ob_sql_audit
+WHERE
+ 1 = 1
+-- AND sql_id = 'xxx'
+ORDER BY
+ request_time DESC
+LIMIT
+ 10;
+```
+
+## Query the QPS of a Tenant on Each Server in the Last M Minutes
+
+Execute the following SQL statement to query the information as the `root@sys` user:
+
+```
+SELECT
+ t2.zone,
+ t1.tenant_id,
+ t1.svr_ip,
+ COUNT(*) / 10 / 60 AS qps,
+ AVG(t1.elapsed_time),
+ AVG(t1.queue_time),
+ AVG(get_plan_time),
+ AVG(execute_time)
+FROM
+ gv$ob_sql_audit t1,
+ dba_ob_servers t2
+WHERE
+ t1.svr_ip = t2.svr_ip
+ -- AND t1.tenant_id = 1001
+ AND is_executor_rpc = 0
+ AND request_time > (time_to_usec(now()) - 10 * 60 * 1000000)
+GROUP BY
+ t1.tenant_id,
+ t1.svr_ip
+ORDER BY
+ qps;
+```
+
+## Query the IDs of the Top N SQL Statements with the Highest CPU Utilization in a Tenant
+
+Execute the following SQL statement to query the information as the `root@sys` user:
+
+```
+SELECT
+ sql_id,
+ SUM(elapsed_time - queue_time) sum_t,
+ COUNT(*) cnt,
+ AVG(get_plan_time),
+ AVG(execute_time),
+ substr(
+ replace(query_sql, '\n', ' '),
+ 1,
+ 100
+ ) query_sql
+FROM
+ gv$ob_sql_audit
+WHERE
+ tenant_id = tenant_id
+ AND is_executor_rpc = 0
+ AND request_time > (time_to_usec(now()) - 10 * 60 * 1000000)
+GROUP BY
+ sql_id
+ORDER BY
+ sum_t DESC
+LIMIT
+ 10;
+```
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/09_ocp_monitor_ob.md b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/09_ocp_monitor_ob.md
new file mode 100644
index 000000000..505c72ee1
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/09_ocp_monitor_ob.md
@@ -0,0 +1,2463 @@
+---
+title: O&M SQL Statements Used in OCP
+weight: 9
+---
+
+Some users hope that we can add some SQL statements or commands commonly used for O&M to this tutorial so that they can maintain OceanBase Database in CLI mode without the need to use specific features of OceanBase Cloud Platform (OCP).
+
+This topic describes SQL statements commonly used in OCP for the O&M of OceanBase Database V3.x and V4.x, for your reference.
+
+## ob_role
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ with_rootserver,
+ *
+FROM
+ __all_server;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ with_rootserver,
+ *
+FROM
+ dba_ob_servers;
+```
+
+## ob_server
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ status,
+ (
+ CASE
+ WHEN stop_time = 0 THEN 0
+ ELSE (time_to_usec(now()) - stop_time) / 1000000
+ END
+ ) AS stopped_duration_seconds
+FROM
+ __all_server;
+```
+
+
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ ifnull(group_concat(svr_ip SEPARATOR ','), '') AS servers,
+ 'active' status,
+ COUNT(1) AS cnt
+FROM
+ __all_server
+WHERE
+ status = 'active'
+UNION ALL
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ ifnull(group_concat(svr_ip SEPARATOR ','), '') AS servers,
+ 'inactive' status,
+ COUNT(1) AS cnt
+FROM
+ __all_server
+WHERE
+ status = 'inactive';
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ status,
+ (
+ CASE
+ WHEN stop_time IS NULL THEN 0
+ ELSE timestampdiff(second, stop_time, current_timestamp)
+ END
+ ) AS stopped_duration_seconds
+FROM
+ dba_ob_servers;
+```
+
+
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ ifnull(group_concat(svr_ip SEPARATOR ','), '') AS servers,
+ 'active' status,
+ COUNT(1) AS cnt
+FROM
+ dba_ob_servers
+WHERE
+ status = 'active'
+UNION ALL
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ ifnull(group_concat(svr_ip SEPARATOR ','), '') AS servers,
+ 'inactive' status,
+ COUNT(1) AS cnt
+FROM
+ dba_ob_servers
+WHERE
+ status = 'inactive';
+```
+
+## ob_cache
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ cache_name,
+ round(cache_size / 1024 / 1024) cache_size_mb
+FROM
+ __all_virtual_kvcache_info
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ cache_name;
+```
+
+
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ round(SUM(cache_size) / 1024 / 1024) cache_size_mb
+FROM
+ __all_virtual_kvcache_info
+GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ cache_name,
+ round(cache_size / 1024 / 1024) cache_size_mb
+FROM
+ gv$ob_kvcache
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ cache_name;
+```
+
+
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ round(SUM(cache_size) / 1024 / 1024) cache_size_mb
+FROM
+ gv$ob_kvcache
+GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port;
+```
+
+## ob_sysstat
+
+### OceanBase Database V3.x
+
+```
+SELECT /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ con_id tenant_id,
+ stat_id,
+ value
+FROM
+ v$sysstat
+WHERE
+ stat_id IN ( 10000, 10001, 10002, 10003, 10004,
+ 10005, 10006, 140002, 140003, 140005,
+ 140006, 140012, 140013, 40030, 80040,
+ 80041, 130000, 130001, 130002, 130004,
+ 20000, 20001, 20002, 30000, 30001,
+ 30002, 30005, 30006, 30007, 30008,
+ 30009, 30010, 30011, 30012, 30013,
+ 30080, 30081, 40000, 40001, 40002,
+ 40003, 40004, 40005, 40006, 40007,
+ 40008, 40009, 40010, 40011, 40012,
+ 40018, 40019, 40116, 40117, 40118,
+ 50000, 50001, 50002, 50004, 50005,
+ 50008, 50009, 50010, 50011, 50037,
+ 50038, 60000, 60001, 60002, 60003,
+ 60004, 60005, 60019, 60020, 60021,
+ 60022, 60023, 60024, 80057, 120000,
+ 120001, 120009, 120008 )
+ AND ( con_id > 1000
+ OR con_id = 1 )
+ AND class < 1000;
+```
+
+
+
+```
+SELECT /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ con_id AS tenant_id,
+ stat_id,
+ value
+FROM
+ v$sysstat
+WHERE
+ stat_id IN ( 30066, 50003, 50021, 50022, 50030,
+ 50039, 50040, 60031, 60057, 80023,
+ 80025, 80026, 120002, 120005, 120006,
+ 200001, 200002 )
+ AND ( con_id > 1000
+ OR con_id = 1 )
+UNION ALL
+SELECT
+ con_id,
+ stat_id,
+ value
+FROM
+ v$sysstat
+WHERE
+ stat_id IN ( 80025, 80026, 80023 )
+ AND con_id > 1
+ AND con_id < 1001
+ AND value > 0
+UNION ALL
+SELECT
+ con_id AS tenant_id,
+ stat_id,
+ value
+FROM
+ v$sysstat
+WHERE
+ name = "memstore write lock wait timeout count"
+ AND ( con_id > 1000
+ OR con_id = 1 );
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT /* MONITOR_AGENT */
+ con_id tenant_id,
+ stat_id,
+ value
+FROM
+ v$sysstat
+WHERE
+ stat_id IN ( 10000, 10001, 10002, 10003, 10004,
+ 10005, 10006, 140002, 140003, 140005,
+ 140006, 140012, 140013, 40030, 80040,
+ 80041, 130000, 130001, 130002, 130004,
+ 20000, 20001, 20002, 30000, 30001,
+ 30002, 30005, 30006, 30007, 30008,
+ 30009, 30010, 30011, 30012, 30013,
+ 30080, 30081, 30082, 30083, 30084,
+ 30085, 30086, 40000, 40001, 40002,
+ 40003, 40004, 40005, 40006, 40007,
+ 40008, 40009, 40010, 40011, 40012,
+ 40018, 40019, 40116, 40117, 40118,
+ 50000, 50001, 60087, 50004, 50005,
+ 50008, 50009, 50010, 50011, 50037,
+ 50038, 60000, 60001, 60002, 60003,
+ 60004, 60005, 60019, 60020, 60021,
+ 60022, 60023, 60024, 80001, 80002,
+ 80003, 80007, 80008, 80009, 80057,
+ 120000, 120001, 120009, 120008 )
+ AND ( con_id > 1000
+ OR con_id = 1 )
+ AND class < 1000;
+```
+
+Execute the following SQL statement to exclude the statistics of meta tenants:
+
+```
+SELECT /* MONITOR_AGENT */
+ tenant_id,
+ stat_id,
+ value
+FROM
+ v$sysstat,
+ dba_ob_tenants
+WHERE
+ stat_id IN ( 30066, 50003, 50021, 50022, 50030,
+ 50039, 50040, 60031, 60057, 60083,
+ 80023, 80025, 80026, 120002, 120005,
+ 120006, 200001, 200002 )
+ AND ( con_id > 1000
+ OR con_id = 1 )
+ AND dba_ob_tenants.tenant_id = v$sysstat.con_id
+ AND dba_ob_tenants.tenant_type <> 'META'
+UNION ALL
+SELECT
+ con_id AS tenant_id,
+ stat_id,
+ value
+FROM
+ v$sysstat
+WHERE
+ stat_id IN ( 80025, 80026, 80023 )
+ AND con_id > 1
+ AND con_id < 1001
+ AND value > 0;
+```
+
+## ob_disk
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ svr_ip,
+ svr_port,
+ round(total_size / 1024 / 1024 / 1024) total_size_gb,
+ round(free_size / 1024 / 1024 / 1024) free_size_gb
+FROM
+ __all_virtual_disk_stat
+ORDER BY
+ svr_ip,
+ svr_port;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ svr_ip,
+ svr_port,
+ round(data_disk_capacity / 1024 / 1024 / 1024) data_disk_capacity_gb,
+ round((data_disk_capacity - data_disk_in_use) / 1024 / 1024 / 1024) data_disk_free_gb,
+ round(log_disk_capacity / 1024 / 1024 / 1024) log_disk_capacity_gb,
+ round(log_disk_assigned / 1024 / 1024 / 1024) log_disk_assigned_gb,
+ round(log_disk_in_use / 1024 / 1024 / 1024) log_disk_in_use_gb
+FROM
+ gv$ob_servers
+ORDER BY
+ svr_ip,
+ svr_port;
+```
+
+## ob_server_resource
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ svr_ip,
+ svr_port,
+ cpu_total,
+ cpu_max_assigned AS cpu_assigned,
+ round(mem_total / 1024 / 1024 / 1024) mem_total_gb,
+ round(mem_max_assigned / 1024 / 1024 / 1024) mem_assigned_gb,
+ round(disk_total / 1024 / 1024 / 1024) disk_total_gb,
+ cpu_assigned_percent,
+ mem_assigned_percent
+FROM
+ __all_virtual_server_stat
+ORDER BY
+ svr_ip,
+ svr_port;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ svr_ip,
+ svr_port,
+ cpu_capacity_max AS cpu_total,
+ cpu_assigned_max AS cpu_assigned,
+ round(mem_capacity / 1024 / 1024 / 1024) mem_total_gb,
+ round(mem_assigned / 1024 / 1024 / 1024) mem_assigned_gb,
+ round(data_disk_capacity / 1024 / 1024 / 1024) data_disk_capacity_gb,
+ (cpu_assigned_max / cpu_capacity_max) AS cpu_assigned_percent,
+ (mem_assigned / mem_capacity) AS mem_assigned_percent
+FROM
+ gv$ob_servers
+ORDER BY
+ svr_ip,
+ svr_port;
+```
+
+## ob_table
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) QUERY_TIMEOUT(100000000) */
+ tenant_name,
+ tenant_id,
+ COUNT(*) AS cnt
+FROM
+ gv$table
+GROUP BY
+ tenant_id;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT QUERY_TIMEOUT(100000000) */
+ con_id tenant_id,
+ COUNT(*) AS cnt
+FROM
+ cdb_tables
+GROUP BY
+ con_id;
+```
+
+## ob_session
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ t2.svr_ip,
+ t2.svr_port,
+ t1.tenant_name,
+ coalesce(t2.active_cnt, 0) AS active_cnt,
+ coalesce(t2.all_cnt, 0) AS all_cnt
+FROM
+ (
+ SELECT
+ tenant_name
+ FROM
+ v$unit
+ ) t1
+ LEFT JOIN (
+ SELECT
+ count(
+ `state` = 'ACTIVE'
+ OR NULL
+ ) AS active_cnt,
+ COUNT(1) AS all_cnt,
+ tenant AS tenant_name,
+ svr_ip,
+ svr_port
+ FROM
+ __all_virtual_processlist
+ GROUP BY
+ tenant,
+ svr_ip,
+ svr_port
+ ) t2 ON t1.tenant_name = t2.tenant_name;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ t2.svr_ip,
+ t2.svr_port,
+ t1.tenant_name,
+ coalesce(t2.active_cnt, 0) AS active_cnt,
+ coalesce(t2.all_cnt, 0) AS all_cnt
+FROM
+ (
+ SELECT
+ tenant_name
+ FROM
+ dba_ob_tenants
+ WHERE
+ tenant_type <> 'META'
+ ) t1
+ LEFT JOIN (
+ SELECT
+ count(
+ `state` = 'ACTIVE'
+ OR NULL
+ ) AS active_cnt,
+ COUNT(1) AS all_cnt,
+ tenant AS tenant_name,
+ svr_ip,
+ svr_port
+ FROM
+ v$ob_processlist
+ GROUP BY
+ tenant,
+ svr_ip,
+ svr_port
+ ) t2 ON t1.tenant_name = t2.tenant_name;
+```
+
+## ob_plan_cache
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ tenant_id,
+ mem_used,
+ access_count,
+ hit_count
+FROM
+ v$plan_cache_stat;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ tenant_id,
+ mem_used,
+ access_count,
+ hit_count
+FROM
+ v$ob_plan_cache_stat;
+```
+
+## ob_waitevent
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ con_id tenant_id,
+ SUM(total_waits) AS total_waits,
+ SUM(time_waited_micro) / 1000000 AS time_waited
+FROM
+ v$system_event
+WHERE
+ v$system_event.wait_class <> 'IDLE'
+ AND (
+ con_id > 1000
+ OR con_id = 1
+ )
+GROUP BY
+ tenant_id;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ con_id tenant_id,
+ SUM(total_waits) AS total_waits,
+ SUM(time_waited_micro) / 1000000 AS time_waited
+FROM
+ v$system_event
+WHERE
+ v$system_event.wait_class <> 'IDLE'
+ AND (
+ con_id > 1000
+ OR con_id = 1
+ )
+GROUP BY
+ tenant_id;
+```
+
+## ob_system_event
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ con_id tenant_id,
+ CASE
+ WHEN event_id = 10000 THEN 'INTERNAL'
+ WHEN event_id = 13000 THEN 'SYNC_RPC'
+ WHEN event_id = 14003 THEN 'ROW_LOCK_WAIT'
+ WHEN (
+ event_id >= 10001
+ AND event_id <= 11006
+ )
+ OR (
+ event_id >= 11008
+ AND event_id <= 11011
+ ) THEN 'IO'
+ WHEN event LIKE 'latch:%' THEN 'LATCH'
+ ELSE 'OTHER'
+END
+ event_group,
+ SUM(total_waits) AS total_waits,
+ SUM(time_waited_micro / 1000000) AS time_waited
+FROM
+ v$system_event
+WHERE
+ v$system_event.wait_class <> 'IDLE'
+ AND (
+ con_id > 1000
+ OR con_id = 1
+ )
+GROUP BY
+ tenant_id,
+ event_group;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ con_id tenant_id,
+ CASE
+ WHEN event_id = 10000 THEN 'INTERNAL'
+ WHEN event_id = 13000 THEN 'SYNC_RPC'
+ WHEN event_id = 14003 THEN 'ROW_LOCK_WAIT'
+ WHEN (
+ event_id >= 10001
+ AND event_id <= 11006
+ )
+ OR (
+ event_id >= 11008
+ AND event_id <= 11011
+ ) THEN 'IO'
+ WHEN event LIKE 'latch:%' THEN 'LATCH'
+ ELSE 'OTHER'
+END
+ event_group,
+ SUM(total_waits) AS total_waits,
+ SUM(time_waited_micro / 1000000) AS time_waited
+FROM
+ v$system_event
+WHERE
+ v$system_event.wait_class <> 'IDLE'
+ AND (
+ con_id > 1000
+ OR con_id = 1
+ )
+GROUP BY
+ tenant_id,
+ event_group;
+```
+
+## ob_tenant_memstore
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ READ_CONSISTENCY(WEAK),query_timeout(100000000) */
+ t.tenant_id,
+ t.tenant_name,
+ MAX(m.freeze_cnt) AS freeze_cnt,
+ s.value AS minor_freeze_times,
+ round(100 * MAX(m.freeze_cnt) / s.value, 2) AS compact_trigger_ratio
+FROM
+ gv$memstore m
+ JOIN __all_tenant t ON m.tenant_id = t.tenant_id
+ JOIN __all_virtual_sys_parameter_stat s ON s.name = 'minor_freeze_times'
+WHERE
+ t.tenant_id > 1000
+GROUP BY
+ m.tenant_id;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /*+ READ_CONSISTENCY(WEAK),query_timeout(100000000) */
+ t.tenant_id,
+ t.tenant_name,
+ MAX(m.freeze_cnt) AS freeze_cnt,
+ s.value AS minor_freeze_times,
+ round(100 * MAX(m.freeze_cnt) / s.value, 2) AS compact_trigger_ratio
+FROM
+ gv$ob_memstore m
+ JOIN dba_ob_tenants t ON m.tenant_id = t.tenant_id
+ JOIN gv$ob_parameters s ON s.name = 'major_compact_trigger'
+ AND s.tenant_id = t.tenant_id
+WHERE
+ t.tenant_id > 1000
+ AND t.tenant_type <> 'meta'
+GROUP BY
+ m.tenant_id;
+```
+
+## ob_unit
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ unit_id,
+ unit_config_id,
+ unit_config_name,
+ resource_pool_id,
+ resource_pool_name,
+ zone,
+ tenant_id,
+ tenant_name,
+ svr_ip,
+ svr_port,
+ migrate_from_svr_ip,
+ migrate_from_svr_port,
+ max_cpu,
+ min_cpu,
+ round(max_memory / 1024 / 1024 / 1024) max_memory_gb,
+ round(min_memory / 1024 / 1024 / 1024) min_memory_gb,
+ max_iops,
+ min_iops,
+ round(max_disk_size / 1024 / 1024 / 1024) max_disk_size_gb,
+ max_session_num
+FROM
+ v$unit
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ unit_id;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ svr_ip,
+ svr_port,
+ unit_id,
+ tenant_id,
+ zone,
+ zone_type,
+ region,
+ max_cpu,
+ min_cpu,
+ round(memory_size / 1024 / 1024 / 1024) memory_size_gb,
+ max_iops,
+ min_iops,
+ iops_weight,
+ round(log_disk_size / 1024 / 1024 / 1024) log_disk_size_gb,
+ round(log_disk_in_use / 1024 / 1024 / 1024) log_disk_in_use_gb,
+ round(data_disk_in_use / 1024 / 1024 / 1024) data_disk_in_use_gb,
+ status,
+ create_time
+FROM
+ gv$ob_units
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ unit_id;
+```
+
+
+
+```
+SELECT
+ unit_id,
+ tenant_id,
+ status,
+ resource_pool_id,
+ unit_group_id,
+ create_time,
+ modify_time,
+ zone,
+ svr_ip,
+ svr_port,
+ migrate_from_svr_ip,
+ migrate_from_svr_port,
+ manual_migrate,
+ unit_config_id,
+ max_cpu,
+ min_cpu,
+ round(memory_size / 1024 / 1024 / 1024) memory_size_gb,
+ round(log_disk_size / 1024 / 1024 / 1024) log_disk_size_gb,
+ max_iops,
+ min_iops,
+ iops_weight
+FROM
+ dba_ob_units
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ unit_id;
+```
+
+## ob_tenant_resource
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+read_consistency(weak) */
+ coalesce(tenant_id, - 1) AS tenant_id,
+ tenant_name,
+ SUM(max_cpu) AS max_cpu,
+ SUM(min_cpu) AS min_cpu,
+ round(SUM(max_memory) / 1024 / 1024 / 1024) max_memory_gb,
+ round(SUM(min_memory) / 1024 / 1024 / 1024) min_memory_gb
+FROM
+ v$unit
+GROUP BY
+ tenant_id;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ coalesce(t1.tenant_id, - 1) AS tenant_id,
+ tenant_name,
+ svr_ip,
+ svr_port,
+ SUM(max_cpu) AS max_cpu,
+ SUM(min_cpu) AS min_cpu,
+ round(SUM(max_memory) / 1024 / 1024 / 1024) max_memory_gb,
+ round(SUM(min_memory) / 1024 / 1024 / 1024) min_memory_gb
+FROM
+ (
+ SELECT
+ t1.unit_id,
+ t1.svr_ip,
+ t1.svr_port,
+ t2.tenant_id,
+ t1.min_cpu,
+ t1.max_cpu,
+ t1.min_memory,
+ t1.max_memory
+ FROM
+ (
+ SELECT
+ unit_id,
+ svr_ip,
+ svr_port,
+ SUM(min_cpu) AS min_cpu,
+ SUM(max_cpu) AS max_cpu,
+ SUM(memory_size) AS min_memory,
+ SUM(memory_size) AS max_memory
+ FROM
+ gv$ob_units
+ GROUP BY
+ unit_id,
+ svr_ip,
+ svr_port
+ ) t1
+ JOIN dba_ob_units t2 ON t1.unit_id = t2.unit_id
+ ) t1
+ JOIN dba_ob_tenants t2 ON t1.tenant_id = t2.tenant_id
+WHERE
+ tenant_type <> 'meta'
+GROUP BY
+ tenant_id
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port;
+```
+
+## ob_tenant_assigned
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ t2.tenant_id,
+ t2.tenant_name,
+ t1.svr_ip,
+ t1.svr_port,
+ t1.cpu_total,
+ t1.cpu_max_assigned AS cpu_assigned,
+ round(t1.mem_total / 1024 / 1024 / 1024) mem_total_gb,
+ round(t1.mem_max_assigned / 1024 / 1024 / 1024) mem_assigned_gb
+FROM
+ __all_virtual_server_stat t1
+ JOIN (
+ SELECT
+ tenant_id,
+ tenant_name,
+ svr_ip,
+ svr_port
+ FROM
+ v$unit
+ ) t2 ON t1.svr_ip = t2.svr_ip
+ AND t1.svr_port = t2.svr_port
+ORDER BY
+ t2.tenant_id,
+ t1.svr_ip,
+ t1.svr_port;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ t4.tenant_id,
+ t4.tenant_name,
+ t4.svr_ip,
+ t4.svr_port,
+ cpu_capacity AS cpu_total,
+ cpu_assigned,
+ round(mem_capacity / 1024 / 1024 / 1024) mem_total_gb,
+ round(mem_assigned / 1024 / 1024 / 1024) mem_assigned_gb
+FROM
+ gv$ob_servers t1
+ JOIN (
+ SELECT
+ t2.tenant_id,
+ t3.tenant_name,
+ t2.svr_ip,
+ t2.svr_port
+ FROM
+ gv$ob_units t2
+ LEFT JOIN dba_ob_tenants t3 ON t2.tenant_id = t3.tenant_id
+ WHERE
+ t3.tenant_type <> 'META'
+ ) t4 ON t1.svr_ip = t4.svr_ip
+ AND t1.svr_port = t4.svr_port
+ORDER BY
+ t4.tenant_id,
+ t1.svr_ip,
+ t1.svr_port;
+```
+
+## ob_tenant_disk
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ t2.tenant_id,
+ t2.tenant_name,
+ t1.svr_ip,
+ t1.svr_port,
+ round(t1.total_size / 1024 / 1024 / 1024) total_size_gb
+FROM
+ __all_virtual_disk_stat t1
+ JOIN (
+ SELECT
+ tenant_id,
+ tenant_name,
+ svr_ip,
+ svr_port
+ FROM
+ gv$unit
+ ) t2 ON t1.svr_ip = t2.svr_ip
+ AND t1.svr_port = t2.svr_port
+ORDER BY
+ t2.tenant_id,
+ t1.svr_ip,
+ t1.svr_port;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ t4.tenant_id AS tenant_id,
+ t4.tenant_name,
+ t4.svr_ip,
+ t4.svr_port,
+ round(t1.data_disk_capacity / 1024 / 1024 / 1024) total_size_gb
+FROM
+ gv$ob_servers t1
+ JOIN (
+ SELECT
+ t2.tenant_id,
+ t3.tenant_name,
+ t2.svr_ip,
+ t2.svr_port
+ FROM
+ gv$ob_units t2
+ LEFT JOIN dba_ob_tenants t3 ON t2.tenant_id = t3.tenant_id
+ WHERE
+ t3.tenant_type <> 'META'
+ ) t4 ON t1.svr_ip = t4.svr_ip
+ AND t1.svr_port = t4.svr_port
+ORDER BY
+ t4.tenant_id,
+ t1.svr_ip,
+ t1.svr_port;
+```
+
+## ob_tenant_task
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ task_type,
+ MAX(
+ timestampdiff(
+ second,
+ sys_task_status.start_time,
+ current_timestamp
+ )
+ ) max_sys_task_duration_seconds
+FROM
+ __all_virtual_sys_task_status sys_task_status
+GROUP BY
+ tenant_id,
+ task_type
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ task_type;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ tenant_id,
+ rs_svr_ip AS svr_ip,
+ rs_svr_port svr_port,
+ job_status,
+ job_type AS task_type,
+ timestampdiff(second, start_time, current_timestamp) AS max_sys_task_duration_seconds
+FROM
+ dba_ob_tenant_jobs
+UNION
+SELECT
+ tenant_id,
+ rs_svr_ip AS svr_ip,
+ rs_svr_port svr_port,
+ job_status,
+ job_type AS task_type,
+ timestampdiff(second, start_time, current_timestamp) AS max_sys_task_duration_seconds
+FROM
+ dba_ob_unit_jobs
+WHERE
+ tenant_id IS NOT NULL
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ job_status,
+ task_type;
+```
+
+## ob_server_task
+
+### OceanBase Database V3.x
+
+None.
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ job_type AS task_type,
+ job_status,
+ timestampdiff(second, start_time, current_timestamp) AS max_sys_task_duration_seconds,
+ svr_ip
+FROM
+ dba_ob_server_jobs
+ORDER BY
+ start_time DESC,
+ task_type,
+ job_status;
+```
+
+## ob_memtable
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ PARALLEL(2), ENABLE_PARALLEL_DML, MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ MAX(
+ unix_timestamp(now()) - snapshot_version / 1000000
+ ) max_snapshot_duration_seconds
+FROM
+ __all_virtual_table_mgr
+WHERE
+ snapshot_version / 1000000 > 1
+ AND table_type = 0
+ AND is_active = 0
+GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /*+ PARALLEL(2), ENABLE_PARALLEL_DML, MONITOR_AGENT */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ MAX(unix_timestamp(now()) - end_log_scn / 1000000000) max_snapshot_duration_seconds
+FROM
+ v$ob_sstables
+WHERE
+ table_type = 'MEMTABLE'
+ AND is_active = 'NO'
+ AND end_log_scn / 1000000000 > 1
+GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port;
+```
+
+## ob_clog
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ stat.svr_ip,
+ stat.svr_port,
+ stat.table_id >> 40 tenant_id,
+ stat.replica_type,
+ MAX(stat.next_replay_ts_delta) / 1000000 AS max_clog_sync_delay_seconds
+FROM
+ __all_virtual_clog_stat stat
+ LEFT JOIN (
+ SELECT
+ meta.svr_ip,
+ meta.svr_port,
+ meta.table_id,
+ meta.partition_id
+ FROM
+ __all_virtual_meta_table meta
+ WHERE
+ meta.status = 'REPLICA_STATUS_NORMAL'
+ AND meta.table_id NOT IN (
+ SELECT
+ table_id
+ FROM
+ __all_virtual_partition_migration_status mig
+ WHERE
+ mig.action <> 'END'
+ )
+ ) meta ON stat.table_id = meta.table_id
+ AND stat.partition_idx = meta.partition_id
+ AND stat.svr_ip = meta.svr_ip
+ AND stat.svr_port = meta.svr_port
+GROUP BY
+ svr_ip,
+ svr_port,
+ tenant_id,
+ replica_type
+HAVING
+ max_clog_sync_delay_seconds < 18446744073709
+ORDER BY
+ svr_ip,
+ svr_port,
+ tenant_id,
+ replica_type;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ leader.tenant_id,
+ '0' AS replica_type,
+ abs(
+ MAX(
+ CAST(leader_ts AS signed) - CAST(follower_ts AS signed)
+ )
+ ) / 1000000000 max_clog_sync_delay_seconds
+FROM
+ (
+ SELECT
+ MAX(end_scn) leader_ts,
+ tenant_id,
+ role
+ FROM
+ gv$ob_log_stat
+ WHERE
+ role = 'LEADER'
+ GROUP BY
+ tenant_id
+ ) leader
+ INNER JOIN (
+ SELECT
+ MIN(end_scn) follower_ts,
+ tenant_id,
+ role
+ FROM
+ gv$ob_log_stat
+ WHERE
+ role = 'FOLLOWER'
+ GROUP BY
+ tenant_id
+ ) follower ON leader.tenant_id = follower.tenant_id
+GROUP BY
+ leader.tenant_id
+ORDER BY
+ leader.tenant_id;
+```
+
+## ob_index
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) QUERY_TIMEOUT(100000000) */
+ COUNT(*) AS cnt
+FROM
+ gv$table
+WHERE
+ table_type IN (5)
+ AND index_status IN (5, 6, 7);
+```
+
+
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) QUERY_TIMEOUT(100000000) */
+ index_status,
+ tenant_id,
+ tenant_name,
+ table_id,
+ table_name,
+ database_id,
+ database_name,
+ table_type,
+ comment,
+ index_type
+FROM
+ gv$table
+WHERE
+ table_type IN ( 5 )
+ AND tenant_name = 'oboracle'
+ AND database_name = 'ALVIN';
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT QUERY_TIMEOUT(100000000) */
+ COUNT(*) AS cnt
+FROM
+ cdb_indexes
+WHERE
+ status IN ('ERROR', 'UNUSABLE');
+```
+
+
+
+```
+SELECT
+ status,
+ con_id,
+ owner,
+ index_name,
+ index_type,
+ table_owner,
+ table_name,
+ table_type,
+ uniqueness,
+ compression
+FROM
+ cdb_indexes
+WHERE
+ table_owner = 'ALVIN'
+ AND table_name = 'TEST';
+```
+
+## ob_memstore
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ ip,
+ port,
+ tenant_id,
+ round(active / 1024 / 1024) active_mb,
+ round(total / 1024 / 1024) memstore_used_mb,
+ round(freeze_trigger / 1024 / 1024) freeze_trigger_mb,
+ round(mem_limit / 1024 / 1024) mem_limit_mb,
+ freeze_cnt,
+ round(total / mem_limit, 2) mem_usage
+FROM
+ gv$memstore
+ORDER BY
+ ip,
+ port;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ round(active_span / 1024 / 1024) active_mb,
+ round(memstore_used / 1024 / 1024) memstore_used_mb,
+ round(freeze_trigger / 1024 / 1024) freeze_trigger_mb,
+ round(memstore_limit / 1024 / 1024) mem_limit_mb,
+ freeze_cnt,
+ round(memstore_used / memstore_limit, 2) mem_usage
+FROM
+ gv$ob_memstore
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port;
+```
+
+## ob_compaction
+
+### OceanBase Database V3.x
+
+None.
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ tenant_id,
+ frozen_scn AS frozen_version,
+ last_scn AS last_version,
+ CASE is_error
+ WHEN 'YES' THEN 1
+ ELSE 0
+END
+ AS is_error,
+ CASE is_suspended
+ WHEN 'YES' THEN 1
+ ELSE 0
+END
+ AS is_suspended,
+ start_time AS start_time,
+ frozen_time AS frozen_time,
+ now() AS current
+FROM
+ cdb_ob_major_compaction;
+```
+
+## ob_tenant500_memory
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ round(SUM(hold) / 1024 / 1024) AS hold_mb,
+ round(SUM(used) / 1024 / 1024) AS used_mb
+FROM
+ __all_virtual_memory_info
+WHERE
+ tenant_id = 500
+ AND mod_name <> 'OB_KVSTORE_CACHE_MB'
+GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ round(SUM(hold) / 1024 / 1024) AS hold_mb,
+ round(SUM(used) / 1024 / 1024) AS used_mb
+FROM
+ gv$ob_memory
+WHERE
+ tenant_id = 500
+ AND mod_name <> 'KvstorCacheMb'
+GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port;
+```
+
+## ob_tenant_memory
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ round(SUM(hold) / 1024 / 1024) AS hold_mb,
+ round(SUM(used) / 1024 / 1024) AS used_mb
+FROM
+ __all_virtual_memory_info
+WHERE
+ mod_name <> 'OB_KVSTORE_CACHE_MB'
+GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ round(SUM(hold) / 1024 / 1024) AS hold_mb,
+ round(SUM(used) / 1024 / 1024) AS used_mb
+FROM
+ gv$ob_memory
+WHERE
+ mod_name <> 'KvstorCacheMb'
+GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port;
+```
+
+## ob_unit_config
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ tenant_id,
+ __all_unit.svr_ip,
+ __all_unit_config.name,
+ max_cpu,
+ min_cpu,
+ round(max_memory / 1024 / 1024 / 1024) AS max_memory_gb,
+ round(min_memory / 1024 / 1024 / 1024) AS min_memory_gb,
+ max_iops,
+ min_iops
+FROM
+ __all_resource_pool,
+ __all_unit_config,
+ __all_unit
+WHERE
+ __all_resource_pool.unit_config_id = __all_unit_config.unit_config_id
+ AND __all_unit.resource_pool_id = __all_resource_pool.resource_pool_id
+ORDER BY
+ tenant_id,
+ __all_unit.svr_ip,
+ __all_unit_config.name;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ p.tenant_id,
+ u.svr_ip,
+ uc.name,
+ uc.max_cpu,
+ uc.min_cpu,
+ round(uc.memory_size / 1024 / 1024 / 1024) AS max_memory_gb,
+ round(uc.log_disk_size / 1024 / 1024 / 1024) AS log_disk_size_gb,
+ uc.max_iops,
+ uc.min_iops
+FROM
+ dba_ob_resource_pools p,
+ dba_ob_unit_configs uc,
+ dba_ob_units u
+WHERE
+ p.unit_config_id = uc.unit_config_id
+ AND u.resource_pool_id = p.resource_pool_id
+ORDER BY
+ p.tenant_id,
+ u.svr_ip,
+ uc.name;
+```
+
+## ob_tenant_log_disk
+
+### OceanBase Database V3.x
+
+None.
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ t1.unit_id,
+ t1.svr_ip,
+ t1.svr_port,
+ t3.tenant_id,
+ t3.tenant_name,
+ round(t1.log_disk_size / 1024 / 1024 / 1024) AS log_disk_size_gb,
+ round(t1.log_disk_in_use / 1024 / 1024 / 1024) AS log_disk_in_use_gb
+FROM
+ (
+ SELECT
+ unit_id,
+ svr_ip,
+ svr_port,
+ SUM(log_disk_size) AS log_disk_size,
+ SUM(log_disk_in_use) AS log_disk_in_use
+ FROM
+ gv$ob_units
+ GROUP BY
+ unit_id,
+ svr_ip,
+ svr_port
+ ) t1
+ JOIN dba_ob_units t2 ON t1.unit_id = t2.unit_id
+ AND t1.svr_ip = t2.svr_ip
+ AND t1.svr_port = t2.svr_port
+ JOIN (
+ SELECT
+ tenant_id,
+ tenant_name
+ FROM
+ dba_ob_tenants
+ WHERE
+ tenant_type IN ('SYS', 'USER')
+ ) t3 ON t2.tenant_id = t3.tenant_id
+ORDER BY
+ t3.tenant_id,
+ t1.svr_ip,
+ t1.svr_port,
+ t1.unit_id;
+```
+
+## ob_system_event_detail
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ con_id AS tenant_id,
+ event_id,
+ event AS event_name,
+ wait_class,
+ total_waits,
+ total_timeouts,
+ time_waited * 10000 AS time_waited_us
+FROM
+ v$system_event
+WHERE
+ wait_class <> 'IDLE'
+ AND (
+ con_id > 1000
+ OR con_id = 1
+ )
+ AND total_waits > 0;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ con_id AS tenant_id,
+ event_id,
+ event AS event_name,
+ wait_class,
+ total_waits,
+ total_timeouts,
+ time_waited * 10000 AS time_waited_us
+FROM
+ v$system_event
+WHERE
+ wait_class <> 'IDLE'
+ AND (
+ con_id > 1000
+ OR con_id = 1
+ )
+ AND total_waits > 0;
+```
+
+## ob_latch
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ con_id tenant_id,
+ name,
+ svr_ip,
+ svr_port,
+ gets,
+ misses,
+ sleeps,
+ immediate_gets,
+ immediate_misses,
+ spin_gets,
+ wait_time / 1000000 AS wait_time
+FROM
+ gv$latch
+WHERE
+ (
+ con_id = 1
+ OR con_id > 1000
+ )
+ AND (
+ gets > 0
+ OR misses > 0
+ OR sleeps > 0
+ OR immediate_gets > 0
+ OR immediate_misses > 0
+ )
+ORDER BY
+ tenant_id,
+ name,
+ svr_ip,
+ svr_port;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ con_id tenant_id,
+ name,
+ svr_ip,
+ svr_port,
+ gets,
+ misses,
+ sleeps,
+ immediate_gets,
+ immediate_misses,
+ spin_gets,
+ wait_time / 1000000 AS wait_time
+FROM
+ gv$latch
+WHERE
+ (
+ con_id = 1
+ OR con_id > 1000
+ )
+ AND (
+ gets > 0
+ OR misses > 0
+ OR sleeps > 0
+ OR immediate_gets > 0
+ OR immediate_misses > 0
+ )
+ORDER BY
+ tenant_id,
+ name,
+ svr_ip,
+ svr_port;
+```
+
+## ob_tenant_server
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ READ_CONSISTENCY(WEAK) QUERY_TIMEOUT(50000000) */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ round(SUM(data_size) / 1024 / 1024) AS data_size_mb,
+ round(SUM(required_size) / 1024 / 1024) AS required_size_mb,
+ sum(row_count) row_count
+from
+ (
+ SELECT
+ tenant_id,
+ svr_ip,
+ svr_port,
+ table_id,
+ partition_id,
+ data_size,
+ required_size,
+ row_count
+ FROM
+ __all_virtual_meta_table
+ union
+ SELECT
+ tenant_id,
+ svr_ip,
+ svr_port,
+ table_id,
+ partition_id,
+ data_size,
+ required_size,
+ row_count
+ FROM
+ __all_root_table
+ )
+group by
+ tenant_id,
+ svr_ip,
+ svr_port;
+```
+
+The following SQL statement is no longer used due to performance issues:
+
+```
+SELECT
+ tenant_id,
+ svr_ip,
+ svr_port,
+ table_type,
+ SUM(replica_count) AS partition_replica_count,
+ SUM(row_count) AS row_count,
+ round(SUM(data_size) / 1024 / 1024) AS data_size_mb,
+ round(SUM(required_size) / 1024 / 1024) AS required_size_mb
+FROM
+ (
+ SELECT
+ c.tenant_id,
+ COUNT(*) AS replica_count,
+ (
+ CASE b.table_type
+ WHEN 5 THEN 'index_table'
+ ELSE 'data_table'
+ END
+ ) AS table_type,
+ c.svr_ip,
+ c.svr_port,
+ SUM(c.row_count) AS row_count,
+ SUM(c.occupy_size) AS data_size,
+ COUNT(DISTINCT(c.macro_idx_in_data_file)) * 2 * 1024 * 1024 AS required_size
+ FROM
+ (
+ SELECT
+ svr_ip,
+ svr_port,
+ tenant_id,
+ row_count,
+ table_id,
+ partition_id,
+ occupy_size,
+ macro_idx_in_data_file
+ FROM
+ __all_virtual_partition_sstable_macro_info
+ GROUP BY
+ svr_ip,
+ svr_port,
+ tenant_id,
+ table_id,
+ partition_id,
+ macro_idx_in_data_file
+ ) c
+ LEFT JOIN __all_virtual_table b ON b.tenant_id = c.tenant_id
+ AND b.table_id = c.table_id
+ GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ partition_id,
+ b.table_type
+ )
+GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ table_type;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /*+ READ_CONSISTENCY(WEAK) QUERY_TIMEOUT(50000000) */
+ a.tenant_id,
+ a.svr_ip,
+ a.svr_port,
+ round(SUM(data_size) / 1024 / 1024) AS data_size_mb,
+ round(SUM(required_size) / 1024 / 1024) AS required_size_mb
+FROM
+ cdb_ob_table_locations a
+ JOIN (
+ SELECT
+ tenant_id,
+ tablet_id,
+ svr_ip,
+ svr_port,
+ data_size,
+ required_size
+ FROM
+ __all_virtual_tablet_meta_table
+ ) b ON a.tenant_id = b.tenant_id
+ AND a.tablet_id = b.tablet_id
+ AND a.svr_ip = b.svr_ip
+ AND a.svr_port = b.svr_port
+ JOIN __all_virtual_table c ON a.tenant_id = c.tenant_id
+ AND a.table_id = c.table_id
+GROUP BY
+ a.tenant_id,
+ a.svr_ip,
+ a.svr_port
+ORDER BY
+ a.tenant_id,
+ a.svr_ip,
+ a.svr_port;
+```
+
+
+```
+SELECT
+ a.tenant_id,
+ a.svr_ip,
+ a.svr_port,
+ a.row_count,
+ round(a.data_size / 1024 / 1024) AS data_size_mb,
+ round(b.required_size / 1024 / 1024) AS required_size_mb
+FROM
+ (
+ SELECT
+ tenant_id,
+ svr_ip,
+ svr_port,
+ SUM(occupy_size) AS data_size,
+ SUM(row_count) AS row_count
+ FROM
+ (
+ SELECT
+ tenant_id,
+ svr_ip,
+ svr_port,
+ tablet_id,
+ row_count,
+ occupy_size
+ FROM
+ __all_virtual_tablet_sstable_macro_info
+ GROUP BY
+ tenant_id,
+ tablet_id,
+ svr_ip,
+ svr_port,
+ macro_block_idx
+ )
+ GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port
+ ) a
+ INNER JOIN (
+ SELECT
+ tenant_id,
+ svr_ip,
+ svr_port,
+ SUM(required_size) AS required_size
+ FROM
+ (
+ SELECT
+ tenant_id,
+ svr_ip,
+ svr_port,
+ COUNT(DISTINCT(macro_block_idx)) * 2 * 1024 * 1024 AS required_size
+ FROM
+ __all_virtual_tablet_sstable_macro_info
+ GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ macro_block_idx
+ )
+ GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port
+ ) b ON a.tenant_id = b.tenant_id
+ AND a.svr_ip = b.svr_ip
+ AND a.svr_port = b.svr_port
+ORDER BY
+ a.tenant_id,
+ a.svr_ip,
+ a.svr_port;
+```
+
+## ob_tenant_server_data_index
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ READ_CONSISTENCY(WEAK) QUERY_TIMEOUT(50000000) */
+ a.tenant_id,
+ b.svr_ip,
+ b.svr_port,
+ round(SUM(size) / 1024 / 1024) AS data_size_mb
+FROM
+ __all_virtual_table_mgr b
+ LEFT JOIN __all_virtual_table a ON a.tenant_id = b.tenant_id
+ AND a.table_id = b.index_id
+WHERE
+ a.table_type = 5
+GROUP BY
+ 1,
+ 2,
+ 3;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /*+ READ_CONSISTENCY(WEAK) QUERY_TIMEOUT(50000000) */
+ a.tenant_id,
+ a.svr_ip,
+ a.svr_port,
+ SUM(data_size) AS data_size
+FROM
+ cdb_ob_table_locations a
+ JOIN (
+ SELECT
+ tenant_id,
+ tablet_id,
+ svr_ip,
+ svr_port,
+ data_size,
+ required_size
+ FROM
+ __all_virtual_tablet_meta_table
+ ) b ON a.tenant_id = b.tenant_id
+ AND a.tablet_id = b.tablet_id
+ AND a.svr_ip = b.svr_ip
+ AND a.svr_port = b.svr_port
+ JOIN __all_virtual_table c ON a.tenant_id = c.tenant_id
+ AND c.table_type = 5
+ AND a.table_id = c.table_id
+GROUP BY
+ a.tenant_id,
+ a.svr_ip,
+ a.svr_port;
+```
+
+The following SQL statement is no longer used:
+
+```
+SELECT
+ tenant_id,
+ svr_ip,
+ svr_port,
+ SUM(row_count) AS row_count,
+ round(SUM(data_size) / 1024 / 1024) AS data_size_mb,
+ table_type
+FROM
+ (
+ SELECT
+ a.tenant_id,
+ a.svr_ip,
+ a.svr_port,
+ SUM(row_count) AS row_count,
+ SUM(occupy_size) AS data_size,
+ (
+ CASE table_type
+ WHEN 'INDEX' THEN 'index_table'
+ ELSE 'data_table'
+ END
+ ) AS table_type
+ FROM
+ (
+ SELECT
+ tenant_id,
+ svr_ip,
+ svr_port,
+ tablet_id,
+ row_count,
+ occupy_size
+ FROM
+ __all_virtual_tablet_sstable_macro_info
+ GROUP BY
+ tenant_id,
+ tablet_id,
+ svr_ip,
+ svr_port,
+ macro_block_idx
+ ) a
+ LEFT JOIN cdb_ob_table_locations b ON a.tenant_id = b.tenant_id
+ AND a.tablet_id = b.tablet_id
+ GROUP BY
+ a.tenant_id,
+ svr_ip,
+ svr_port,
+ table_type
+ )
+GROUP BY
+ tenant_id,
+ svr_port,
+ svr_ip,
+ table_type
+ORDER BY
+ tenant_id,
+ svr_port,
+ svr_ip,
+ table_type;
+```
+
+## ob_tenant_unit
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ READ_CONSISTENCY(WEAK) */
+ coalesce(tenant_id, - 1) AS tenant_id,
+ tenant_name,
+ svr_ip,
+ svr_port,
+ unit_id,
+ zone,
+ max_cpu,
+ min_cpu,
+ round(max_memory / 1024 / 1024 / 1024) AS max_memory_gb,
+ round(min_memory / 1024 / 1024 / 1024) AS min_memory_gb,
+ 1 AS unit_count
+FROM
+ gv$unit
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ unit_id;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ t2.tenant_id,
+ t1.svr_ip,
+ t1.svr_port,
+ t1.unit_id,
+ t1.zone,
+ t1.min_cpu,
+ t1.max_cpu,
+ round(t1.max_memory / 1024 / 1024 / 1024) AS max_memory_gb,
+ round(t1.min_memory / 1024 / 1024 / 1024) AS min_memory_gb
+FROM
+ (
+ SELECT
+ unit_id,
+ svr_ip,
+ svr_port,
+ zone,
+ SUM(min_cpu) AS min_cpu,
+ SUM(max_cpu) AS max_cpu,
+ SUM(memory_size) AS min_memory,
+ SUM(memory_size) AS max_memory
+ FROM
+ gv$ob_units
+ GROUP BY
+ unit_id,
+ svr_ip,
+ svr_port
+ ) t1
+ JOIN dba_ob_units t2 ON t1.unit_id = t2.unit_id
+ AND t1.svr_ip = t2.svr_ip
+ AND t1.svr_port = t2.svr_port
+ORDER BY
+ t2.tenant_id,
+ t1.svr_ip,
+ t1.svr_port,
+ t1.unit_id;
+```
+
+## ob_server_partition_replica
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ READ_CONSISTENCY(WEAK) */
+ t1.svr_ip,
+ t1.svr_port,
+ t2.zone,
+ t1.`count` AS count
+FROM
+ (
+ SELECT
+ svr_ip,
+ svr_port,
+ COUNT(*) AS `count`
+ FROM
+ __all_virtual_partition_info
+ GROUP BY
+ svr_ip,
+ svr_port
+ ) t1
+ JOIN __all_server t2 ON t1.svr_ip = t2.svr_ip
+ AND t1.svr_port = t2.svr_port
+ORDER BY
+ t1.svr_ip,
+ t1.svr_port,
+ t2.zone;
+```
+
+
+
+```
+SELECT
+ /*+ READ_CONSISTENCY(WEAK) */
+ t1.tenant_id,
+ t1.svr_ip,
+ t1.svr_port,
+ t2.zone,
+ t1.`count` AS count
+FROM
+ (
+ SELECT
+ tenant_id,
+ svr_ip,
+ svr_port,
+ COUNT(*) AS `count`
+ FROM
+ __all_virtual_partition_info
+ GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port
+ ) t1
+ JOIN __all_server t2 ON t1.svr_ip = t2.svr_ip
+ AND t1.svr_port = t2.svr_port
+ORDER BY
+ t1.tenant_id,
+ t1.svr_ip,
+ t1.svr_port,
+ t2.zone;
+```
+
+### OceanBase Database V4.x
+
+None.
+
+## ob_server_partition
+
+### OceanBase Database V3.x
+
+
+```
+SELECT
+ /*+ READ_CONSISTENCY(WEAK) */
+ t.svr_ip,
+ t.svr_port,
+ t.zone,
+ coalesce(_max_partition_cnt_per_server, 30000) AS replica_limit
+FROM
+ (
+ SELECT
+ svr_ip,
+ svr_port,
+ MAX(zone) AS zone,
+ MAX(
+ CASE `name`
+ WHEN '_max_partition_cnt_per_server' THEN `value`
+ ELSE NULL
+ END
+ ) AS _max_partition_cnt_per_server
+ FROM
+ __all_virtual_sys_parameter_stat
+ GROUP BY
+ `svr_ip`,
+ `svr_port`
+ ) t;
+```
+
+
+
+```
+SELECT
+ /*+ READ_CONSISTENCY(WEAK) */
+ svr_ip,
+ svr_port,
+ zone,
+ `value`
+FROM
+ __all_virtual_sys_parameter_stat
+WHERE
+ `name` = '_max_partition_cnt_per_server'
+ORDER BY
+ svr_ip,
+ svr_port;
+```
+
+### OceanBase Database V4.x
+
+None.
+
+## ob_tenant_context_memory
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ mod_name,
+ round(SUM(hold) / 1024 / 1024) AS hold_mb,
+ round(SUM(used) / 1024 / 1024) AS used_mb
+FROM
+ __all_virtual_memory_info
+WHERE
+ mod_name <> 'OB_KVSTORE_CACHE_MB'
+GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ mod_name
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ mod_name;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ /* MONITOR_AGENT */
+ tenant_id,
+ svr_ip,
+ svr_port,
+ mod_name,
+ round(SUM(hold) / 1024 / 1024) AS hold_mb,
+ round(SUM(used) / 1024 / 1024) AS used_mb
+FROM
+ gv$ob_memory
+WHERE
+ mod_name <> 'KvstorCacheMb'
+GROUP BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ mod_name
+ORDER BY
+ tenant_id,
+ svr_ip,
+ svr_port,
+ mod_name;
+```
+
+## log_stream
+
+### OceanBase Database V3.x
+
+None.
+
+### OceanBase Database V4.x
+
+OceanBase Database V4.1+:
+
+```
+SELECT
+ /*+ MONITOR_AGENT */
+ t2.tenant_id,
+ t1.svr_ip,
+ t1.svr_port,
+ sum(t1.degraded_list <> '') AS degraded_count
+FROM
+ gv$ob_log_stat t1
+ INNER JOIN dba_ob_tenants t2 ON t1.tenant_id = t2.tenant_id
+ AND t2.tenant_type != 'META'
+GROUP BY
+ t2.tenant_id,
+ t1.svr_ip,
+ t1.svr_port
+ORDER BY
+ t2.tenant_id,
+ t1.svr_ip,
+ t1.svr_port;
+```
+
+## ob_database_disk
+
+### OceanBase Database V3.x
+
+```
+SELECT
+ t1.tenant_id,
+ t2.database_id,
+ t3.database_name,
+ round(SUM(t1.data_size) / 1024 / 1024) AS data_size_mb,
+ round(SUM(t1.required_size) / 1024 / 1024) AS required_size_mb
+FROM
+ (
+ SELECT
+ tenant_id,
+ table_id,
+ SUM(data_size) AS data_size,
+ SUM(required_size) AS required_size
+ FROM
+ __all_virtual_tenant_partition_meta_table
+ GROUP BY
+ table_id
+ ) t1
+ LEFT JOIN (
+ SELECT
+ tenant_id,
+ table_id,
+ database_id
+ FROM
+ __all_virtual_table
+ ) t2 ON t1.tenant_id = t2.tenant_id
+ AND t1.table_id = t2.table_id
+ LEFT JOIN (
+ SELECT
+ tenant_id,
+ database_id,
+ database_name
+ FROM
+ gv$database
+ ) t3 ON t2.tenant_id = t3.tenant_id
+ AND t2.database_id = t3.database_id
+GROUP BY
+ t2.database_id
+ORDER BY
+ data_size_mb DESC;
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT
+ t1.tenant_id,
+ t1.database_name,
+ t3.object_id AS database_id,
+ round(SUM(t2.data_size) / 1024 / 1024) AS data_size_mb,
+ round(SUM(t2.required_size) / 1024 / 1024) AS required_size_mb
+FROM
+ (
+ SELECT
+ tenant_id,
+ database_name,
+ table_id,
+ tablet_id
+ FROM
+ cdb_ob_table_locations
+ ) t1
+ LEFT JOIN (
+ SELECT
+ tenant_id,
+ tablet_id,
+ svr_ip,
+ svr_port,
+ data_size,
+ required_size
+ FROM
+ cdb_ob_tablet_replicas
+ ) t2 ON t1.tenant_id = t2.tenant_id
+ AND t1.tablet_id = t2.tablet_id
+ LEFT JOIN (
+ SELECT
+ con_id,
+ object_name,
+ object_id
+ FROM
+ cdb_objects
+ WHERE
+ object_type = 'DATABASE'
+ ) t3 ON t1.tenant_id = t3.con_id
+ AND t1.database_name = t3.object_name
+GROUP BY
+ t1.database_name
+ORDER BY
+ data_size_mb DESC;
+```
+
+## tenant
+
+### OceanBase Database V3.x
+
+```
+SELECT tenant_id ob_tenant_id, tenant_name FROM __all_tenant
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT tenant_id ob_tenant_id, tenant_name FROM DBA_OB_TENANTS WHERE tenant_type<>'META'
+```
+
+## unit
+
+### OceanBase Database V3.x
+
+```
+SELECT tenant_id ob_tenant_id, tenant_name FROM v$unit
+```
+
+### OceanBase Database V4.x
+
+```
+SELECT a.tenant_id as ob_tenant_id, a.tenant_name FROM DBA_OB_TENANTS a join v$ob_units b on a.tenant_id = b.tenant_id WHERE a.tenant_type<>'META'
+```
diff --git a/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/_category_.yml b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/_category_.yml
new file mode 100644
index 000000000..e8f7e9951
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/commonly_used_sql/_category_.yml
@@ -0,0 +1 @@
+label: Common SQL Statements for O&M
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/optimizer_statistics/01_operations_and_maintenance.md b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/optimizer_statistics/01_operations_and_maintenance.md
new file mode 100644
index 000000000..6645857ca
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/optimizer_statistics/01_operations_and_maintenance.md
@@ -0,0 +1,379 @@
+---
+title: Statistics O&M Manual
+weight: 1
+---
+
+> **This statistics O&M manual is used for OceanBase Database Community Edition V4.2.0 or later. By default, if you collect statistics on a table, execution plans involving access to the table are refreshed in the plan cache. We recommend that you do not collect statistics during peak hours unless necessary.**
+
+## Basic Knowledge of Statistics
+
+Before you read this topic, we recommend that you learn about the basic knowledge of statistics. For more information, see the "Statistics" section in [Common SQL tuning methods](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_07_diagnosis_and_tuning/sql_tuning).
+
+> If you already have a basic understanding of OceanBase Database statistics, you can directly read the following sections.
+
+
+
+
+## Troubleshoot Collection Job Execution Failures {#troubleshoot-collection-job-execution-failures}
+### Working principles of automatic statistics collection
+Automatic statistics collection jobs are implemented based on the `DBMS_SCHEDULER` system package. The following table describes the seven windows defined to schedule statistics collection jobs during each week.
+
+| **Maintenance window** | **Start time/Frequency** | **Maximum collection duration** |
+| :---: | :---: | :---: |
+| **MONDAY_WINDOW** | 22:00/Per week | 4 hours |
+| **TUESDAY_WINDOW** | 22:00/Per week | 4 hours |
+| **WEDNESDAY_WINDOW** | 22:00/Per week | 4 hours |
+| **THURSDAY_WINDOW** | 22:00/Per week | 4 hours |
+| **FRIDAY_WINDOW** | 22:00/Per week | 4 hours |
+| **SATURDAY_WINDOW** | 06:00/Per week | 20 hours |
+| **SUNDAY_WINDOW** | 06:00/Per week | 20 hours |
+
+Automatic statistics collection involves only tables whose statistics are missing or outdated and is performed in an incremental manner. That is, the system collects statistics only on partitions in which data has changed, instead of on the entire table. By default, if the total amount of data that is added, deleted, and modified since the last collection in a partition exceeds 10% of the current table data amount, the statistics of the partition are outdated.
+
+
+### Troubleshooting procedure {#troubleshooting-procedure}
+To check whether automatic statistics collection is successful, perform the following steps:
+
++ **Step 1: Execute the following SQL statements based on the types of tenants to check whether automatic collection jobs are normally scheduled for all tenants within the previous day. If so, perform the operation in Step 2. If not, refer to [Troubleshoot Collection Job Scheduling Failures](#troubleshoot-collection-job-scheduling-failures).**
+
+ ```sql
+
+ -- Execute the following SQL statement in the sys tenant. If the return result is not empty, the automatic statistics collection jobs of specific tenants are not scheduled as expected. This method is recommended.
+
+ SELECT tenant_id AS failed_scheduler_tenant_id
+ FROM oceanbase.__all_tenant t
+ WHERE NOT EXISTS(SELECT 1
+ FROM oceanbase.__all_virtual_task_opt_stat_gather_history h
+ WHERE TYPE = 1
+ AND start_time > date_sub(now(), interval 1 day)
+ AND h.tenant_id = t.tenant_id);
+
+
+ -- Execute the following SQL statement in a MySQL tenant. If the return result is empty, the automatic statistics collection jobs of the tenant are not scheduled as expected.
+
+ SELECT *
+ FROM oceanbase.dba_ob_task_opt_stat_gather_history
+ WHERE start_time > date_sub(now(), interval 1 day)
+ AND TYPE = 'AUTO GATHER';
+ ```
+
++ **Step 2: Execute the following SQL statements based on the types of tenants to obtain the list of failed collection jobs within the previous day. If the return result is empty, the statistics are collected as expected. If not, perform the operations in Step 3 to troubleshoot the issue.**
+
+ ```sql
+
+ -- Execute the following SQL statement in the sys tenant to query this information of specific or all user tenants. We recommend that you query the information about specific tenants.
+
+ SELECT t_opt.tenant_id,
+ t_opt.task_id,
+ task_opt.start_time AS task_start_time,
+ task_opt.end_time AS task_end_time,
+ d.database_name,
+ t.table_name,
+ t_opt.table_id,
+ t_opt.ret_code,
+ t_opt.start_time,
+ t_opt.end_time,
+ t_opt.memory_used,
+ t_opt.stat_refresh_failed_list,
+ t_opt.properties
+ FROM (
+ SELECT tenant_id,
+ task_id,
+ start_time,
+ end_time,
+ table_count
+ FROM oceanbase.__all_virtual_task_opt_stat_gather_history
+ WHERE type = 1
+ -- AND tenant_id = {tenant_id} -- Specify the IDs of tenants whose information you want to query.
+ AND start_time > date_sub(Now(), interval 1 day)) task_opt
+ JOIN oceanbase.__all_virtual_table_opt_stat_gather_history t_opt
+ JOIN oceanbase.__all_virtual_table t
+ JOIN oceanbase.__all_virtual_database d
+ WHERE t_opt.ret_code != 0
+ AND task_opt.task_id = t_opt.task_id
+ AND task_opt.tenant_id = t_opt.tenant_id
+ AND t_opt.tenant_id = t.tenant_id
+ AND t_opt.table_id = t.table_id
+ AND t.tenant_id = d.tenant_id
+ AND t.database_id = d.database_id
+ AND t_opt.table_id > 200000;
+
+
+ -- Execute the following SQL statement in a MySQL tenant to query this information of the tenant:
+
+ SELECT task_opt.task_id,
+ task_opt.start_time AS task_start_time,
+ task_opt.end_time AS task_end_time,
+ t_opt.owner,
+ t_opt.table_name,
+ t_opt.start_time,
+ t_opt.end_time,
+ t_opt.memory_used,
+ t_opt.stat_refresh_failed_list,
+ t_opt.properties
+ FROM (SELECT task_id,
+ start_time,
+ end_time
+ FROM oceanbase.dba_ob_task_opt_stat_gather_history
+ WHERE start_time > Date_sub(Now(), interval 1 day)
+ AND TYPE = 'AUTO GATHER') task_opt
+ join oceanbase.dba_ob_table_opt_stat_gather_history t_opt
+ ON task_opt.task_id = t_opt.task_id
+ AND t_opt.status != 'SUCCESS'
+ AND owner != 'oceanbase';
+ ```
+
++ **Step 3: Troubleshoot and resolve the collection failure as follows:**
+
+1. **(Most common)** If the collection times out and error ret=-4012 is reported because the target table contains more than 100 million rows, refer to [Troubleshoot Stuck Collection Caused by an Ultra-large Table](#troubleshoot-stuck-collection-caused-by-an-ultra-large-table).
+
+2. If the collection fails because a tenant has too many tables requiring statistics collection but the collection window has a limited duration, you need to manually collect the statistics of the tenant during **off-peak hours**. For more information about collection strategies, see [Statements for Manual Statistics Collection](https://oceanbase.github.io/docs/user_manual/operation_and_maintenance/operations_and_maintenance/optimizer_statistics/command).
+
+3. If an error other than the timeout error is reported, manually collect the statistics of the target table during **off-peak hours**. For more information, see [Statements for Manual Statistics Collection](https://oceanbase.github.io/docs/user_manual/operation_and_maintenance/operations_and_maintenance/optimizer_statistics/command). Then, follow up the collection and report the error to the on-duty engineers of the OceanBase community forum.
+
+## Troubleshoot Collection Job Scheduling Failures {#troubleshoot-collection-job-scheduling-failures}
+You can execute the following SQL statements to check whether the automatic collection jobs are normally scheduled based on tenant types:
+
++ **sys tenant (with specified user tenant ID):**
+
+ ```sql
+ -- Check whether the jobs in all windows of the target user tenant are normally scheduled and run in order.
+
+ SELECT tenant_id,
+ job_name,
+ what,
+ start_date,
+ this_date,
+ last_date,
+ next_date,
+ enabled
+ FROM oceanbase.__all_virtual_tenant_scheduler_job
+ WHERE tenant_id = {tenant_id}
+ AND job_name IN ( 'MONDAY_WINDOW', 'TUESDAY_WINDOW', 'WEDNESDAY_WINDOW',
+ 'THURSDAY_WINDOW',
+ 'FRIDAY_WINDOW', 'SATURDAY_WINDOW', 'SUNDAY_WINDOW' )
+ AND job != 0;
+
+
+ -- Check whether the last job of the target user tenant is successful. The result code 0 indicates success.
+
+ SELECT *
+ FROM OCEANBASE.__ALL_VIRTUAL_TENANT_SCHEDULER_JOB_RUN_DETAIL
+ WHERE tenant_id = {tenant_id}
+ ORDER BY time;
+ ```
+
++ **MySQL tenant:**
+
+ ```sql
+ -- Check whether the jobs in all windows of the tenant are normally scheduled and run in order.
+
+ SELECT job_name,
+ job_action,
+ start_date,
+ last_start_date,
+ next_run_date,
+ enabled
+ FROM oceanbase.dba_scheduler_jobs
+ WHERE job_name IN ( 'MONDAY_WINDOW', 'TUESDAY_WINDOW', 'WEDNESDAY_WINDOW',
+ 'THURSDAY_WINDOW',
+ 'FRIDAY_WINDOW', 'SATURDAY_WINDOW', 'SUNDAY_WINDOW' );
+
+ -- Check whether the last job of the tenant is successful. The result code 0 indicates success.
+
+ SELECT *
+ FROM OCEANBASE.__ALL_TENANT_SCHEDULER_JOB_RUN_DETAIL
+ ORDER BY time;
+ ```
+
+If the scheduling is abnormal, report the issue to the on-duty engineers of the OceanBase community forum.
+
+## Troubleshoot Stuck Collection Caused by an Ultra-large Table {#troubleshoot-stuck-collection-caused-by-an-ultra-large-table}
+The automatic statistics collection for many tenants fails due to slow collection on an ultra-large table. This issue can be troubleshot by using the method described in [Troubleshoot collection job execution failures](#troubleshoot-collection-job-execution-failures). If an ultra-large table causes the failure, use the following strategy to fix the issue:
+
++ **Step 1: Execute the following SQL statements to query the collection status of the ultra-large table within the previous period of time and check whether each collection on the ultra-large table is time-consuming. For the query in the sys tenant, a non-zero value of the `ret_code` parameter indicates a collection failure. For the query in a user tenant, a NULL value or a value other than 'SUCCESS' of the `status` parameter indicates a collection failure.**
+
+ ```sql
+ -- sys tenant
+
+ SELECT *
+ FROM oceanbase.__all_virtual_table_opt_stat_gather_history
+ WHERE table_id = {table_id}
+ ORDER BY start_time;
+ -- MySQL tenant
+
+ SELECT *
+ FROM oceanbase.dba_ob_table_opt_stat_gather_history
+ WHERE table_name = '{table_name}'
+ ORDER BY start_time;
+ ```
+
++ **Step 2: Modify the statistics collection strategies of ultra-large tables. For more information, see** [Modify the statistics collection strategies of ultra-large tables](#modify-the-statistics-collection-strategies-of-ultra-large-tables).
+
++ **Step 3: After the collection strategies are modified, determine whether to manually collect statistics of the large table again based on the actual situation. When most statistics of the table are outdated and the plans generated for queries that require accessing the table are not optimal, increase the degree of parallelism (DOP) for statistics collection if the system resources are sufficient. In other cases, you can execute the following SQL statement to check whether the automatic statistics collection can be successfully performed based on the modified strategies:**
+
+ ```plsql
+ -- MySQL tenant
+ -- To ensure stability, this collection does not refresh relevant plans in the plan cache.
+ call dbms_stats.gather_table_stats('database_name','table_name', no_invalidate=>true);
+ ```
+
++ **Step 4: If the issue of stuck collection has frequently occurred for the tenant, you can check whether the statistics on most tables in the tenant are missing or outdated. If so, manually collect the statistics on the tables during off-peak hours. For more information, see [Quickly query tables with outdated or missing statistics in the current tenant](#quickly-query-tables-with-outdated-or-missing-statistics-in-the-current-tenant) and [Statements for Manual Statistics Collection](https://oceanbase.github.io/docs/user_manual/operation_and_maintenance/operations_and_maintenance/optimizer_statistics/command).**
+
++ **Step 5: Modify the start time of automatic statistics collection jobs. We recommend that the collection is performed after the daily compaction during off-peak hours. For more information, see [Modify the Scheduling Time of Automatic Statistics Collection Jobs](#modify-the-scheduling-time-of-automatic-statistics-collection-jobs).**
+
+If you have any questions about the preceding steps or encounter any issues during actual operations, contact the on-duty engineers of the OceanBase community forum.
+
+## Common O&M Methods of Statistics
+### Disable and enable automatic statistics collection
+You can execute the following statements to disable or enable automatic statistics collection. Note that you need to re-configure the collection jobs as needed after automatic statistics collection is enabled.
+
+```sql
+-- MySQL tenant:
+-- Disable automatic statistics collection:
+call dbms_scheduler.disable('MONDAY_WINDOW');
+call dbms_scheduler.disable('TUESDAY_WINDOW');
+call dbms_scheduler.disable('WEDNESDAY_WINDOW');
+call dbms_scheduler.disable('THURSDAY_WINDOW');
+call dbms_scheduler.disable('FRIDAY_WINDOW');
+call dbms_scheduler.disable('SATURDAY_WINDOW');
+call dbms_scheduler.disable('SUNDAY_WINDOW');
+
+-- Enable automatic statistics collection:
+call dbms_scheduler.enable('MONDAY_WINDOW');
+call dbms_scheduler.enable('TUESDAY_WINDOW');
+call dbms_scheduler.enable('WEDNESDAY_WINDOW');
+call dbms_scheduler.enable('THURSDAY_WINDOW');
+call dbms_scheduler.enable('FRIDAY_WINDOW');
+call dbms_scheduler.enable('SATURDAY_WINDOW');
+call dbms_scheduler.enable('SUNDAY_WINDOW');
+```
+
+### Quickly query tables with outdated or missing statistics in the current tenant {#quickly-query-tables-with-outdated-or-missing-statistics-in-the-current-tenant}
+You can execute the following statement to query tables whose statistics are missing or outdated in a user tenant and sort the tables by their data amount:
+
+```sql
+-- MySQL tenant
+
+SELECT v2.database_name,
+ v2.table_name,
+ Sum(inserts - deletes) row_cnt
+FROM oceanbase.dba_tab_modifications v1,
+ (SELECT DISTINCT database_name AS DATABASE_NAME,
+ table_name AS table_name
+ FROM oceanbase.dba_ob_table_stat_stale_info
+ WHERE is_stale = 'YES'
+ AND database_name != 'oceanbase') v2
+WHERE v1.table_name = v2.table_name
+GROUP BY v2.database_name,
+ v2.table_name
+ORDER BY row_cnt;
+```
+
+### Modify the statistics collection strategies of ultra-large tables {#modify-the-statistics-collection-strategies-of-ultra-large-tables}
+The statistics collection on ultra-large tables is time-consuming due to the following reasons:
+
+1. **The tables contain a large amount of data. Therefore, full table scans take a long time during statistics collection.**
+
+2. **The histogram collection involves complex computations, which causes extra costs.**
+
+3. **By default, statistics and histograms are collected from subpartitions, partitions, and whole tables of large partitioned tables. The cost is equal to 3 × (full table scan cost + histogram collection cost). This issue is optimized only for OceanBase V4.2.2 and later**.
+
+In view of the preceding reasons, you can optimize statistics collection configurations based on your business requirements and the actual situation of tables by using the following methods:
+
++ Set an appropriate default DOP for statistics collection. Note that you must schedule the automatic statistics collection job to run during off-peak hours to prevent your business from being affected. For more information, see [Modify the Scheduling Time of Automatic Statistics Collection Jobs](#modify-the-scheduling-time-of-automatic-statistics-collection-jobs). **We recommend that you set the DOP to 8 or a smaller value.** Here is an example:
+
+ ```sql
+ -- MySQL tenant:
+ call dbms_stats.set_table_prefs('database_name', 'table_name', 'degree', '8');
+ ```
+
++ Set the default histogram collection method for columns. We recommend that you do not collect histograms on columns in which data is evenly distributed.
+
+ ```sql
+ -- MySQL tenant
+
+ -- 1. If data is evenly distributed in all columns of the table, you can skip histogram collection on all columns. Here is an example:
+
+ call dbms_stats.set_table_prefs('database_name', 'table_name', 'method_opt', 'for all columns size 1');
+
+ -- 2. If data is unevenly distributed in a few columns of the table, you can collect histograms on these columns and skip histogram collection on other columns. The following sample statement shows how to collect histograms on the `c1` and `c2` columns and skip histogram collection on the `c3`, `c4`, and `c5` columns:
+
+ call dbms_stats.set_table_prefs('database_name', 'table_name', 'method_opt', 'for columns c1 size 254, c2 size 254, c3 size 1, c4 size 1, c5 size 1');
+ ```
+
++ Set the default statistics collection granularity for partitioned tables. For HASH-partitioned tables and KEY-partitioned tables, you can collect only global statistics or deduce global statistics based on partition-level statistics. Here is an example:
+
+ ```sql
+ -- MySQL tenant
+
+ -- 1. Collect only global statistics:
+ call dbms_stats.set_table_prefs('database_name', 'table_name', 'granularity', 'GLOBAL');
+
+ -- 2. Deduce global statistics based on partition-level statistics:
+ call dbms_stats.set_table_prefs('database_name', 'table_name', 'granularity', 'APPROX_GLOBAL AND PARTITION');
+ ```
+
++ **Use large-table sampling with caution. When you use large-table sampling to collect statistics, the number of histogram samples becomes very large, which lowers collection efficiency. Large-table sampling is suitable for the collection of basic statistics instead of histograms.** Here is an example:
+
+ ```sql
+ -- MySQL tenant
+
+ -- 1. Skip histogram collection on all columns:
+ call dbms_stats.set_table_prefs('database_name', 'table_name', 'method_opt', 'for all columns size 1');
+
+ -- 2. Set the sampling ratio to 10%:
+ call dbms_stats.set_table_prefs('database_name', 'table_name', 'estimate_percent', '10');
+ ```
+
+If you want to clear or delete a default statistics collection strategy that you specified, specify only the attribute to be deleted. Here is an example:
+
+```sql
+-- Delete the "granularity" attribute in a MySQL tenant:
+
+call dbms_stats.delete_table_prefs('database_name', 'table_name', 'granularity');
+```
+
+After you set a statistics collection strategy, you can query whether it has taken effect. Here is an example:
+
+```sql
+-- Query the specified "degree" attribute in a MySQL tenant:
+
+select dbms_stats.get_prefs('degree', 'database_name','table_name') from dual;
+```
+You can also lock statistics after you manually collect the statistics on ultra-large tables. For more information, see [Lock statistics to prevent statistics updates](#lock-statistics-to-prevent-statistics-updates).
+
+### Lock statistics to prevent statistics updates {#lock-statistics-to-prevent-statistics-updates}
+If the overall data distribution of a table does not significantly change and you want to maintain stability of query plans that require accessing the table, you can execute the following statements to lock and unlock the table statistics:
+
+```sql
+-- Lock the statistics on a table in a MySQL tenant:
+call dbms_stats.lock_table_stats('database_name', 'table_name');
+
+-- Unlock the statistics on a table in a MySQL tenant:
+call dbms_stats.unlock_table_stats('database_name', 'table_name');
+```
+
+**Note that the locked statistics are not automatically updated. This is suitable for scenarios with slight data changes and insensitive to data values.** If you want to recollect the locked statistics, you must unlock the statistics first.
+
+### Modify the strategies for slow statistics collection
+If the statistics collection of a table is very slow, you can perform the following operations to modify the collection strategies:
+
+1. **Disable histogram collection**. Histogram collection is the most time-consuming operation and histograms are not very necessary in many scenarios. You can execute the following statement to skip histogram collection for all columns in the specified table by setting the `method_opt` option to `for all columns size 1`:
+
+ ```sql
+ call dbms_stats.set_table_prefs('database_name',
+ 'table_name',
+ 'method_opt',
+ 'for all columns size 1');
+ ```
+
+2. **Increase the DOP by specifying the `degree` option**. You can increase the DOP of statistics collection during off-peak hours to accelerate the collection.
+3. Specify to deduce global statistics based on partition-level statistics.
+
+In addition, **we recommend that you do not modify the `estimate_percent` option**. By default, histograms are collected based on the calculation result of a small amount of sample data. If you modify this option, a large amount of data may be sampled. This significantly slows down histogram collection and decreases the accuracy of collected basic statistics.
+
+## References
+- [Statistical information and row estimation](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001718186)
+
+- [OceanBase community forum](https://ask.oceanbase.com/)
diff --git a/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/optimizer_statistics/02_best_practices.md b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/optimizer_statistics/02_best_practices.md
new file mode 100644
index 000000000..edd4632dd
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/optimizer_statistics/02_best_practices.md
@@ -0,0 +1,156 @@
+---
+title: Best Practices for Statistics Collection
+weight: 2
+---
+
+> Note: At present, *OceanBase Advanced Tutorial for DBAs* applies only to OceanBase Database Community Edition V4.x. Features of Oracle tenants of OceanBase Database Enterprise Edition are not described in this topic. For more information about the differences between the two editions, see [Differences between Enterprise Edition and Community Edition](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714481).
+
+## Purpose of Statistics Collection
+Before the optimizer generates and selects the optimal execution plan, it evaluates and compares the execution cost of each available plan. Therefore, it is crucial to increase the accuracy of cost evaluation.
+
+The optimizer evaluates the costs of execution plans based on the cost model and the number of rows estimated for each operator. In this process, statistics play a key role. Accurate statistics improve row estimation for operators, which allows the optimizer to estimate costs of execution plans and select the optimal plan in a more efficient manner.
+
+Therefore, the accuracy of statistics must be guaranteed.
+
+## Default Statistics Collection Strategies
+
+By default, the system starts to collect statistics from 22:00 on each workday and from 06:00 on weekends. The collection lasts at most 4 hours on workdays and 20 hours on weekends. Each collection duration is called a statistics maintenance window.
+
+In each statistics maintenance window, the optimizer re-collects all outdated statistics on tables or partitions. By default, the statistics on a table or partition are outdated if no statistics on the table or partition are collected or more than **10%** of rows in the table or partition have been added, deleted, or modified since the last collection. The following table describes the default statistics collection strategies.
+
+| **Preference name** | **Description** | **Default value** |
+| --- | --- | --- |
+| degree | The degree of parallelism (DOP). | 1, which indicates single-thread scanning. | |
+| method_opt | The strategy used to collect column-level statistics. | Collect the statistics on all columns and the histograms of columns with data skew used in WHERE conditions. |
+| granularity | The granularity of the collection. | Collect partition-level statistics and deduce global statistics based on the collected partition-level statistics. For non-partitioned tables, global statistics are directly collected. |
+| estimate_percent | The sampling ratio. | Collect statistics through a full table scan without sampling. | |
+| block_sample | Specifies whether to perform block sampling. | Perform row sampling instead of block sampling. | |
+
+
+## Configure Statistics Collection Strategies
+The default statistics collection strategies are applicable to most tables. In certain scenarios, you may need to modify the collection strategies based on your business characteristics. This section describes some common scenarios and corresponding collection strategies.
+
+### Business peak hours overlap statistics maintenance windows
+
+
+
+**The default settings of statistics maintenance windows in OceanBase Database follow those in Oracle. However, many domestic business applications still run after 22:00 on working days. If statistics collection starts at 22:00, the SQL statements for statistics collection may preempt resources with business SQL statements, affecting business performance. In this case, you can modify the start time of a statistics maintenance window to avoid overlap with business peak hours. **
+
+```sql
+-- For example, it is 11:00 on Thursday, March 7, 2024.
+-- You can execute the following statements to start statistics collection at 02:00 every day from Friday:
+
+call dbms_scheduler.set_attribute(
+ 'FRIDAY_WINDOW', 'NEXT_DATE', '2024-03-08 02:00:00');
+
+call dbms_scheduler.set_attribute(
+ 'SATURDAY_WINDOW', 'NEXT_DATE', '2024-03-09 02:00:00');
+
+call dbms_scheduler.set_attribute(
+ 'SUNDAY_WINDOW', 'NEXT_DATE', '2024-03-10 02:00:00');
+
+call dbms_scheduler.set_attribute(
+ 'MONDAY_WINDOW', 'NEXT_DATE', '2024-03-11 02:00:00');
+
+call dbms_scheduler.set_attribute(
+ 'TUESDAY_WINDOW', 'NEXT_DATE', '2024-03-12 02:00:00');
+
+call dbms_scheduler.set_attribute(
+ 'WEDNESDAY_WINDOW', 'NEXT_DATE', '2024-03-13 02:00:00');
+
+call dbms_scheduler.set_attribute(
+ 'THURSDAY_WINDOW', 'NEXT_DATE', '2024-03-14 02:00:00');
+
+```
+> Note: The preceding statements apply only to OceanBase Database tenants in MySQL mode.
+
+### Statistics collection fails to complete due to ultra-large tables
+When the default statistics collection strategies are used, the system performs a full table scan on tables or partitions whose statistics are to be collected by using a single thread. If a table or partition contains a large amount of data or occupies much disk space, the statistics collection of the table or partition takes a long period of time, which affects that of other tables or even incurs a timeout error.
+
+If a table in your business contains more than 100 million rows or occupies more than 20 GB of disk space, we recommend that you configure the statistics collection strategies by using the following methods:
+
+1. Skip large objects.
+
+ In MySQL mode, statistics on LONGTEXT columns are collected by default. If the LONGTEXT columns store large objects (LOBs), the statistics are collected at a slow speed.
+
+ In the following example, the fourth parameter specifies the columns whose statistics are to be collected. You need to specify all columns except LOB columns.
+
+ ```sql
+ call dbms_stats.set_table_prefs(
+ 'databse_name',
+ 'table_name',
+ 'method_opt',
+ 'for columns col1,col2,col3,... size auto');
+ ```
+
+2. Increase the DOP or configure block sampling.
+
+ If you increase the DOP, more concurrent threads are used to collect statistics. This way, you can achieve quick collection by consuming more resources.
+
+ Alternatively, you can configure block sampling to reduce the amount of data to be processed during statistics collection.
+
+ Both methods improve the statistics collection efficiency. The first method trades off resources for statistics accuracy, whereas the second method trades off statistics accuracy for resource availability.
+
+ You can select a method based on your business requirements.
+
+ ```sql
+ -- Configure the DOP of statistics collection.
+ call dbms_stats.set_table_prefs(
+ 'databse_name',
+ 'table_name',
+ 'degree',
+ '4');
+ ```
+
+ ```sql
+ -- Enable block sampling.
+ call dbms_stats.set_table_prefs(
+ 'databse_name',
+ 'table_name',
+ 'block_sample',
+ 'True');
+
+ -- Configure a sampling ratio based on the data size of the table. In most cases, you can know the data characteristics of a table after you collect statistics of tens of millions of rows from the table.
+ call dbms_stats.set_table_prefs(
+ 'databse_name',
+ 'table_name',
+ 'estimate_percent',
+ '0.1');
+ ```
+
+3. Do not collect global statistics on partitioned tables. In the following example, the fourth parameter specifies the level of statistics to be collected. For a partitioned table, you can configure to collect statistics of only partitions. For a subpartitioned table, you can configure to collect statistics of only subpartitions. Note that if you use this strategy, you must delete global statistics for partitioned tables, and delete global and partition-level statistics for subpartitioned tables.
+
+ ```sql
+ -- Partitioned tables
+ call dbms_stats.set_table_prefs(
+ 'databse_name',
+ 'table_name',
+ 'granularity',
+ 'PARTITION');
+
+ -- Subpartitioned tables
+ call dbms_stats.set_table_prefs(
+ 'databse_name',
+ 'table_name',
+ 'granularity',
+ 'SUBPARTITION');
+ ```
+
+### Table statistics are missing for queries initiated immediately after batch data import into a table
+By default, statistics are updated only after automatic statistics collection, which is scheduled periodically.
+
+> OceanBase Database V4.2.4 and versions later than V4.2.5 provide the asynchronous statistics collection capability to address this issue.
+
+If a large amount of data is imported into an empty table or small table, as often happens in batch processing scenarios, and the table is then immediately queried, the optimizer may generate a poor plan due to missing or severely outdated statistics.
+
+**In this case, we recommend that you manually collect the statistics and then perform queries after the data import. If an excessively large amount of data is imported, you can modify the manual collection strategies. For more information, see the "Statistics collection fails to complete due to ultra-large tables" section of this topic. **
+
+### Partition statistics are missing for queries initiated on the same day as the data import into a partition pre-created by date
+
+For a table in which partitions are pre-created by date, the optimizer may fail to collect statistics on some pre-created partitions because the partitions contain no data.
+
+If data is imported into such a partition and the imported data is queried on the same day, the optimizer may generate a poor plan due to severely outdated statistics.
+
+In this case, we recommend that you manually collect statistics on the partition on the same day after the data import.
+
+> OceanBase Database V4.2.4 and versions later than V4.2.5 provide the asynchronous statistics collection capability to address this issue.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/optimizer_statistics/03_command.md b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/optimizer_statistics/03_command.md
new file mode 100644
index 000000000..71950c7ce
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/optimizer_statistics/03_command.md
@@ -0,0 +1,220 @@
+---
+title: Statements for Manual Statistics Collection
+weight: 3
+---
+
+> Note: At present, *OceanBase Advanced Tutorial for DBAs* applies only to OceanBase Database Community Edition V4.x. Features of Oracle tenants of OceanBase Database Enterprise Edition are not described in this topic. For more information about the differences between the two editions, see [Differences between Enterprise Edition and Community Edition](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714481).
+
+Optimizer statistics are a collection of data that describes the tables and columns in a database, which are the key to selecting the optimal execution plan.
+
+In OceanBase Database of a version earlier than V4.x, statistics are mainly collected during daily compactions. However, statistics are not always accurate because of the incremental data involved in daily compactions. In addition, histogram information cannot be collected during daily compactions.
+
+Therefore, the statistics feature is upgraded in OceanBase Database V4.x and later, so that statistics are no longer collected during daily compactions. When you use OceanBase Database V4.x, pay special attention to the collection of statistics.
+
+This topic recommends some statements for manual statistics collection in actual scenarios.
+
+## Collect Table-level Statistics
+To explicitly collect statistics on a table, you can use the following methods: **DBMS_STATS system package and ANALYZE statement**. Pay attention to the table type.
+
+### Collect statistics on a non-partitioned table
+**If the product of the number of rows and the number of columns in a table is no greater than 10 million**, we recommend that you run the following statements to collect statistics on the table. In the following example, the `t1` table owned by the `test` user contains 10 columns and one million rows:
+
+```sql
+create table test.t1(
+ c1 int, c2 int, c3 int, c4 int, c5 int,
+ c6 int, c7 int, c8 int, c9 int, c10 int);
+
+insert /*+append*/ into t1
+ select level,level,level,level,level,
+ level,level,level,level,level
+ from dual
+ connect by level <= 1000000;
+```
+
+```sql
+-- re1. Histograms are not collected.
+
+call dbms_stats.gather_table_stats(
+ 'test',
+ 't1',
+ method_opt=>'for all columns size 1');
+
+
+-- re2. Histograms are collected by using the default strategy.
+
+call dbms_stats.gather_table_stats('test', 't1');
+
+-- The collection takes about 2 seconds.
+```
+
+**If the product of the number of rows and the number of columns in a table exceeds 10 million**, we recommend that you specify an appropriate degree of parallelism (DOP) based on your business requirements and system resources to accelerate the statistics collection. In the following example, the DOP is set to 8 when the data amount in the `t1` table is increased to 10 million rows:
+
+```sql
+create table test.t1(
+ c1 int, c2 int, c3 int, c4 int, c5 int,
+ c6 int, c7 int, c8 int, c9 int, c10 int);
+
+insert /*+append*/ into t1
+ select level,level,level,level,level,
+ level,level,level,level,level
+ from dual
+ connect by level <= 10000000;
+```
+
+```sql
+-- re1. Histograms are not collected.
+
+call dbms_stats.gather_table_stats(
+ 'test',
+ 't1',
+ degree=>8,
+ method_opt=>'for all columns size 1');
+
+-- re2. Histograms are collected by using the default strategy.
+
+call dbms_stats.gather_table_stats(
+ 'test',
+ 't1',
+ degree=>8);
+
+-- The collection takes about 4 seconds.
+```
+
+
+### Collect statistics on a partitioned table
+Different from statistics collection strategies for non-partitioned tables, the strategies for partitioned tables must cover the collection of partition statistics.
+
+**If system resources are sufficient, we recommend that you double the DOP for statistics collection on partitioned tables.** For example, the `t_part` table of the `test` user contains 128 partitions, 10 columns, and one million rows of data. In this case, you can set the DOP to 2 to collect the basic statistics and partition statistics:
+
+```sql
+create table t_part(
+ c1 int, c2 int, c3 int, c4 int, c5 int,
+ c6 int, c7 int, c8 int, c9 int, c10 int
+)partition by hash(c1) partitions 128;
+
+insert /*+append*/ into t_part
+ select level,level,level,level,level,
+ level,level,level,level,level
+ from dual
+ connect by level <= 1000000;
+```
+
+```sql
+-- Specify an appropriate DOP:
+
+-- re1. Histograms are not collected.
+
+call dbms_stats.gather_table_stats(
+ 'test',
+ 't_part',
+ degree=>2,
+ method_opt=>'for all columns size 1');
+
+-- re2. Histograms are collected by using the default strategy.
+
+call dbms_stats.gather_table_stats(
+ 'test',
+ 't_part',
+ degree=>2);
+
+-- The collection takes about 4 seconds.
+```
+
+
+For partitioned tables, **you can also deduce global statistics from partition-level statistics to accelerate statistics collection**. That is, you can modify the collection granularity to `APPROX_GLOBAL AND PARTITION` instead of increasing the DOP for statistics collection on the `t_part` table.
+
+```sql
+-- re1. Histograms are not collected.
+
+call dbms_stats.gather_table_stats(
+ 'test',
+ 't_part',
+ granularity=>'APPROX_GLOBAL AND PARTITION',
+ method_opt=>'for all columns size 1');
+
+-- re2. Histograms are collected by using the default strategy.
+
+call dbms_stats.gather_table_stats(
+ 'test',
+ 't_part',
+ granularity=>'APPROX_GLOBAL AND PARTITION');
+
+-- The collection takes about 4 seconds.
+```
+
+**In summary, you can specify an appropriate DOP or deduce global statistics from partition-level statistics to accelerate statistics collection on partitioned tables.**
+
+
+
+## Collect Schema-level Statistics
+
+In addition to manual statistics collection on a single table, you can use the `DBMS_STATS` system package to collect statistics on all tables of a user.
+
+This process is time-consuming. Therefore, we recommend that you use this feature during off-peak hours.
+
++ If **each table of the user contains no more than one million rows**, you can run the statements in the following example to collect statistics:
+
+ ```sql
+
+ -- re1. Histograms are not collected.
+
+ call dbms_stats.gather_schema_stats('TEST', method_opt=>'for all columns size 1');
+
+
+ -- re2. Histograms are collected by using the default strategy.
+
+ call dbms_stats.gather_schema_stats('TEST');
+
+ ```
+
++ If **the user has large tables and each large table contains tens of millions of rows**, you can increase the DOP and collect statistics during off-peak hours.
+
+ ```sql
+
+ -- re1. Histograms are not collected.
+
+ call dbms_stats.gather_schema_stats(
+ 'TEST',
+ degree=>'16',
+ method_opt=>'for all columns size 1');
+
+ -- re2. Histograms are collected by using the default strategy.
+
+ call dbms_stats.gather_schema_stats('TEST', degree=>'16');
+ ```
+
++ If **the user has ultra-large tables and each ultra-large table contains more than 100 million rows, you can collect statistics on the ultra-large tables separately at a high DOP**. Then, you can lock the statistics on the ultra-large tables and execute the preceding statements to collect statistics on all tables of the user. After the statistics are collected, you can unlock the statistics on the ultra-large tables and then collect the subsequent statistics in incremental mode. Here is an example:
+
+ ```sql
+ call dbms_stats.gather_table_stats(
+ 'test',
+ 'big_table',
+ degree=>128,
+ method_opt=>'for all columns size 1');
+
+ call dbms_stats.lock_table_stats('test','big_table');
+
+ call dbms_stats.gather_schema_stats(
+ 'TEST',
+ degree=>'16',
+ method_opt=>'for all columns size 1');
+
+ call dbms_stats.unlock_table_stats('test','big_table');
+ ```
+
+## Query Whether Statistics Are Outdated
+
+The following SQL statements apply only to OceanBase Database V4.2 and later:
+```sql
+select distinct DATABASE_NAME, TABLE_NAME
+ from oceanbase.DBA_OB_TABLE_STAT_STALE_INFO
+ where DATABASE_NAME not in('oceanbase','mysql', '__recyclebin')
+ and (IS_STALE = 'YES' or LAST_ANALYZED_TIME is null);
+```
+
+```cpp
+select distinct OWNER, TABLE_NAME
+ from sys.DBA_OB_TABLE_STAT_STALE_INFO
+ where OWNER != 'oceanbase'
+ and OWNER != '__recyclebin' and (IS_STALE = 'YES' or LAST_ANALYZED_TIME is null);
+```
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/optimizer_statistics/_category_.yml b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/optimizer_statistics/_category_.yml
new file mode 100644
index 000000000..6f6f56dec
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/optimizer_statistics/_category_.yml
@@ -0,0 +1 @@
+label: Statistics User Guide
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates.md
new file mode 100644
index 000000000..7ec054549
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates.md
@@ -0,0 +1,612 @@
+---
+title: Parameter Templates
+weight: 1
+---
+
+> Parameter templates are required by microservice customers. These customers run their business on a software as a service (SaaS) platform. Tenants in the same cluster may run the same business. However, tenant parameters must be configured each time a tenant is created. In a SaaS-based business scenario with a large number of tenants, the workload in configuring tenant parameters is heavy.
+>
+> Other users also raise similar requirements. They hope that templates of recommended parameter settings can be provided for different business scenarios. After a business scenario is specified for a cluster or tenant, the system automatically tunes various parameters to adapt to the scenario.
+>
+> To meet these requirements, OceanBase Database provides the parameter template feature. For a cluster or tenant created by using OceanBase Cloud Platform (OCP) or OceanBase Deployer (obd), parameters and their default settings are tuned to cater to business needs in different scenarios.
+
+
+## Background Information
+I have recently come into contact with some users of OceanBase Database Community Edition and found that their application scenarios are diverse. However, the default parameter/variable settings provided by OceanBase Database do not apply to all scenarios. The recommended parameter/variable settings vary based on the application scenario. For example, the default value of the `ob_query_timeout` variable is `10s`, which is acceptable for simple online transaction processing (OLTP) scenarios but may not be suitable for online analytical processing (OLAP) business, especially for time-consuming complex queries.
+
+To provide more suitable default parameter settings for clusters and tenants in different application scenarios, OceanBase Database provides the parameter template feature. I have tried this feature for a few days and here are my usage records for your reference.
+
+I used OceanBase Database Community Edition V4.3.2.1 and OCP Community Edition V4.3.1 for testing. **We recommend that you use OCP Community Edition V4.3.2 or later, which fixes some known bugs and provides comprehensive parameter template functionality.**
+
+## Check the Configuration File for Parameter Templates
+In the OBServer source code of OceanBase Database, parameters and their default settings for various scenarios are maintained and output as an RPM package. When you upload the software package of OceanBase Database V4.3.0 or later to OCP, the configuration file in the software package is automatically parsed in the background of OCP and saved as a parameter template of the cluster or tenant.
+
+
+
+It takes about 1 minute to parse the configuration file and save it to a certain meta table. If you cannot see the options of the parameter template on the OCP GUI after waiting for a long time, confirm whether OCP has finished parsing the parameter template configuration file. The procedure is as follows:
+
+1. Log in to the OCP console, choose **Tenants** > **User Management**, and copy the login connection string of the `ocp_meta` tenant.
+
+
+
+2. Log in to the `ocp_meta` tenant on the corresponding OBServer node by using the copied connection string.
+
+```sql
+[xiaofeng.lby@obvos-dev-d3 /home/xiaofeng.lby]
+$mysql -h1.2.3.4 -P2881 -u root@ocp_meta -p YourPassword
+
+Welcome to the MariaDB monitor. Commands end with ; or \g.
+Your MySQL connection id is 3221740061
+Server version: 5.7.25 OceanBase_CE 4.2.1.2
+Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
+Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
+```
+
+3. A scenario-based parameter template is saved in the background. You cannot directly see it on the parameter template page but you can confirm in the MetaDB whether it exists.
+
+```sql
+MySQL [(none)]> use meta_database;
+Reading table information for completion of table and column names
+You can turn off this feature to get a quicker startup with -A
+Database changed
+
+-- View cluster-level parameter template types. Here is an example. You can delete limit 1 and then execute the statement.
+MySQL [meta_database]> select * from meta_database.ob_cluster_parameter_template where `group` = 'scenario' limit 1 \G
+*************************** 1. row ***************************
+ id: 1001
+ create_time: 2024-09-20 14:28:09
+ update_time: 2024-09-20 14:28:09
+ name: cluster parameter template for scenario HTAP, version 4.3.2.1-100000102024081217
+ creator_id: 200
+ modifier_id: 200
+ description: cluster parameter template for scenario HTAP, version 4.3.2.1-100000102024081217
+ built_in: 0
+extra_data_json: {"fullVersion":"4.3.2.1-100000102024081217","scenario":"HTAP"}
+ group: scenario
+1 row in set (0.04 sec)
+
+-- View tenant-level parameter template types. Here is an example. You can delete limit 1 and then execute the statement.
+MySQL [meta_database]> select * from meta_database.ob_tenant_parameter_template where `group` = 'scenario' limit 1 \G
+*************************** 1. row ***************************
+ id: 1001
+ create_time: 2024-09-20 14:28:09
+ update_time: 2024-09-20 14:28:09
+ name: tenant parameter template for scenario HTAP, version 4.3.2.1-100000102024081217
+ creator_id: 200
+ modifier_id: 200
+ description: tenant parameter template for scenario HTAP, version 4.3.2.1-100000102024081217
+compatible_type: ALL
+ built_in: 0
+extra_data_json: {"fullVersion":"4.3.2.1-100000102024081217","scenario":"HTAP"}
+ group: scenario
+1 row in set (0.04 sec)
+```
+
+
+
+## Set a Cluster-level Parameter Template
+When you create a cluster of OceanBase Database V4.3.0 or later, you can select a parameter template based on the application scenario.
+
+
+
+The procedure is simple. On the **Create Cluster** page of the OCP console, you can either use the default parameter settings or enable **Parameter Settings** to modify cluster parameters.
+
++ You can add and configure startup parameters one by one.
++ You can also click **Parameter Template** and select a parameter template. The system will automatically populate the parameters and their values from the template on the cluster parameter configuration page.
+
+OceanBase Database V4.3.2.1 used for testing provides five built-in parameter templates, which are described in the following table.
+
+| Template | Description |
+| --- | --- |
+| Default Parameter Template for HTAP | Suitable for hybrid transactional and analytical processing (HTAP) workloads. You can use it to quickly get insights from campaign operation data, fraud detection, and scenario-specific recommendations. This template applies to OceanBase Database V4.3.0 and later. |
+| Default Parameter Template for OLAP | Suitable for real-time data warehouse analytics. This template applies to OceanBase Database V4.3.0 and later. |
+| Default Parameter Template for COMPLEX_OLTP | Suitable for workloads such as banking and insurance systems. These workloads often involve complex join operations, complex subqueries, batch processing jobs compiled in PL, long-running transactions, and large transactions. Short-running queries are sometimes executed in parallel. This template applies to OceanBase Database V4.3.0 and later. |
+| Default Parameter Template for KV | Suitable for workloads involving a high throughput and are sensitive to latency, such as key-value workloads and wide-column workloads of an HBase database. This template applies to OceanBase Database V4.3.0 and later. |
+| Default Parameter Template for OceanBase Database V2.2.77 | The template recommended for a production cluster of OceanBase Database V2.2.77. |
+
+
+## Set a Tenant-level Parameter Template
+
+
+Log in to the OCP console and choose **Tenants** > **Create Tenant**. On the page that appears, enable **Parameter Settings** and configure the tenant parameters.
+
++ You can add and configure startup parameters one by one.
++ You can also click **Parameter Template** and select a parameter template. The system will automatically populate the parameters and their values from the template on the tenant parameter configuration page.
+
+
+
+## Solution to a Known Bug (Fixed in OCP Community Edition V4.3.2)
+When a user creates a tenant in OCP by using the Default Parameter Template for OLAP, OCP misjudges the types of some parameters because part of the metadata recorded by OCP is incorrect. As a result, the tenant fails to be created. This bug does not occur in cluster creation or when a tenant is created by using other parameter templates.
+
+
+This bug has been fixed in OCP Community Edition V4.3.2. If you use the Default Parameter Template for OLAP to create a tenant in OCP of a version earlier than V4.3.2, you can temporarily delete the parameters without a value type, namely, `parallel_degree_policy`, `_io_read_batch_size`, and `_io_read_redundant_limit_percentage`.
+
+
+After the tenant is created, choose **Tenants** > **Parameter Management** and manually configure these three parameters.
+
+
+
+
+
+
+## Performance Tests with Different Parameter Templates
+### Typical production environments
+Our team member Junye has tested the parameter templates in different benchmarks. Currently, OceanBase Database Community Edition provides five typical production environments:
+
++ EXPRESS_OLTP: for Internet applications featuring simple CRUD statements, a large number of point queries, and high concurrency
++ COMPLEX_OLTP: for traditional industry applications featuring complex queries, a large number of PL queries, and batch processing jobs
++ OLAP: online analytical processing and data warehousing.
+ - Typical load: import -> conversion -> query -> report generation
+ * Lightweight:
+ + Extract, load, transform (ELT) rather than extract, transform, load (ETL)
+ + SQL used for data conversion and real-time queries, and materialized views used for real-time acceleration
+ + Simple and lightweight dependencies, namely, no or a few external dependencies
+ - Performance metric: response time, ranging from seconds to hours
+ - Data size: 100 TB
+ - Data model: star schema for multi-table joins and multidimensional ad-hoc queries on wide tables
+ - Read/Write mode: more reads than writes, batch writes with a few updates, a few query types with a low query concurrency, and queries featuring wide-range scan
+ - Typical benchmarks: TPC-DS, TPC-H, ClickBench, and Star Schema Benchmark (SSB)
+ - Application scenarios: real-time warehousing, marketing analysis, aggregation analysis, and ad-hoc queries
++ HTAP: hybrid load processing with enhanced transaction processing (TP) capabilities
+ - Real-time lightweight reports
+ * Typical load: online transaction write -> batch processing job -> real-time report
+ * Typical benchmarks: TPC-C + TPC-H, and Hybench
+ * Data size: 10 TB
+ * Performance metric: subsecond-level response time of an analytical query
+ * Data model: basically designed in accordance with the relational model paradigm
+ * Read/Write mode: heavy reads and writes with high read and write concurrency. Data is written in real time, including high-concurrency writes of transactions involving small amounts of data and batch writes of large transactions. Data reads include transactional short queries and analytical large queries.
+ * Application scenarios: (a) BI reports, (b) substitute for the "database/table sharding + aggregated database" dual-database instance architecture, (c) ad-hoc queries, and (d) real-time risk control
+ - Quasi-real-time decision analysis
+ * Typical load: online transactions with a high concurrency and large-scale real-time data analysis
+ * Data size: 100 TB
+ * Performance metric: response time of an analytical query, ranging from subseconds to hours
+ * Data model: basically designed in accordance with the relational model paradigm
+ * Read/Write mode: heavy reads and writes with high read and write concurrency. Data is written in real time, including high-concurrency writes of transactions involving small amounts of data and batch writes of large transactions. Data reads include transactional short queries and analytical large queries, which can be separated on the application side. Analytical queries support old data.
+ * Typical benchmarks: TPC-C + TPC-DS, and TPC-C + ClickBench
+ * Application scenarios: (a) BI reports, (b) substitute for the "database/table sharding + aggregated database" dual-database instance architecture, and (c) ad-hoc queries
++ KV: applicable to OBKV HBase-compatible access and key-value table access, single-partition access, and no-SQL layer.
+
+### Default values for parameters in templates
++ System variables: For more information, see [GitHub](https://github.com/oceanbase/oceanbase/blob/4.3.3/src/share/system_variable/default_system_variable.json).
++ Parameters: For more information, see [GitHub](https://github.com/oceanbase/oceanbase/blob/4.3.3/src/share/parameter/default_parameter.json).
+
+### Test environment
+#### Test versions
++ OceanBase Database Community Edition: V4.3.2
++ OceanBase Database Proxy (ODP) Community Edition: V4.2.3
+
+##### Hardware environment
++ Three OBServer nodes are deployed on [ecs.r7.8xlarge servers](https://www.alibabacloud.com/help/en/ecs/user-guide/instance-specification-naming-and-classification?spm=a2c63.p38356.help-menu-25365.d_4_1_2_0.30363520na3b5u), each with 32 CPU cores and 256 GB of memory. The system disk is used as the system log disk, while two PL1 ESSDs are mounted to store clogs and data, respectively.
++ ODP is deployed on a separate [ecs.c7.16xlarge server](https://www.alibabacloud.com/help/en/ecs/user-guide/overview-of-instance-families?spm=a2c63.m28257.0.i3) with 64 CPU cores and 128 GB of memory.
+
+##### Operating system
+The operating system is CentOS 7.9 64-bit.
+
+```shell
+echo "vm.max_map_count=655360" >> /etc/sysctl.conf; sysctl -p (obd startup check items)
+sudo sysctl -w kernel.sched_migration_cost_ns=0 (optimization based on kernel parameters of ApsaraDB for OceanBase)
+```
+
+##### Tenant specifications
+28 CPU cores, 180 GB of memory, three full-featured replicas, and `primary_zone` set to `RANDOM`
+
+```shell
+## Valid values of scenario in the command are express_oltp, complex_oltp, olap, htap, and kv.
+obd cluster tenant create perf --max-cpu=28 --memory-size=180G -n mysql_tenant -o ${scenario}
+```
+
+##### Deployment configuration file
+```sql
+oceanbase-ce:
+ version: 4.3.2.0
+ servers:
+ - name: server1
+ ip: omitted
+ - name: server2
+ ip: omitted
+ - name: server3
+ ip: omitted
+ global:
+ scenario: ${scenario}
+ home_path: /root/observer
+ data_dir: /data/1/storage
+ redo_dir: /data/2/redo
+ devname: eth0
+ memory_limit: 240G
+ log_disk_size: 700G
+ datafile_disk_percentage: 93
+ root_password: 123456
+ mysql_port: 2881
+ rpc_port: 2882
+ server1:
+ zone: zone1
+ server2:
+ zone: zone2
+ server3:
+ zone: zone3
+obproxy-ce:
+ version: 4.2.3.0
+ depends:
+ - oceanbase-ce
+ servers:
+ - omitted
+ global:
+ listen_port: 2886 ## External port. The default value is 2883.
+ home_path: /root/obproxy
+ enable_cluster_checkout: false
+ skip_proxy_sys_private_check: true
+ enable_strict_kernel_release: false
+```
+
+### Tune parameters
+In this section, performance data is tested based on the tuned basic workload parameters and default parameter settings for different types of tenants.
+
+#### Tune basic workload parameters
+Sysbench
+
+```sql
+ALTER system SET enable_sql_audit=false;
+ALTER system SET enable_perf_event=false;
+ALTER system SET syslog_level='PERF';
+alter system set enable_record_trace_log=false;
+```
+
+TPC-C
+
+```sql
+#proxy
+ALTER proxyconfig SET proxy_mem_limited='4G';
+ALTER proxyconfig set enable_compression_protocol=false;
+
+#sys
+ALTER system SET enable_sql_audit=false;
+select sleep(5);
+ALTER system SET enable_perf_event=false;
+ALTER system SET syslog_level='PERF';
+alter system set enable_record_trace_log=false;
+```
+
+TPC-H
+
+```sql
+#sys
+ALTER SYSTEM flush plan cache GLOBAL;
+ALTER system SET enable_sql_audit=false;
+select sleep(5);
+ALTER system SET enable_perf_event=false;
+ALTER system SET syslog_level='PERF';
+alter system set enable_record_trace_log=false;
+
+#Test tenant
+SET GLOBAL ob_sql_work_area_percentage = 80;
+SET GLOBAL ob_query_timeout = 36000000000;
+SET GLOBAL ob_trx_timeout = 36000000000;
+SET GLOBAL max_allowed_packet = 67108864;
+## parallel_servers_target = max_cpu * server_num * 8
+SET GLOBAL parallel_servers_target = 624;
+```
+
+TPC-DS
+
+```sql
+#sys
+ALTER SYSTEM flush plan cache GLOBAL;
+ALTER system SET enable_sql_audit=false;
+select sleep(5);
+ALTER system SET enable_perf_event=false;
+ALTER system SET syslog_level='PERF';
+alter system set enable_record_trace_log=false;
+
+#Test tenant
+SET GLOBAL ob_sql_work_area_percentage = 80;
+SET GLOBAL ob_query_timeout = 36000000000;
+SET GLOBAL ob_trx_timeout = 36000000000;
+SET GLOBAL max_allowed_packet = 67108864;
+## parallel_servers_target = max_cpu * server_num * 8
+SET GLOBAL parallel_servers_target = 624;
+```
+
+### Test data
+#### Sysbench
+**Parameter tuning**
+
+```yaml
+ALTER system SET enable_sql_audit=false;
+ALTER system SET enable_perf_event=false;
+ALTER system SET syslog_level='PERF';
+alter system set enable_record_trace_log=false;
+```
+
+**Test command**
+
+The native Sysbench benchmark process encapsulated by obd is used. The ob-sysbench used by obd depends on LibOBClient. You need to run `export ENABLE_PROTOCOL_OB20=0` to disable the OceanBase 2.0 protocol to keep consistent with the native Sysbench benchmark.
+
+```sql
+obd test sysbench rn --tenant=perf --script-name=xxx.lua --table-size=1000000 --threads=xx --report-interval=1 --rand-type=uniform --time=30 --db-ps-mode=disable
+```
+
+
+
+**Test data (QPS/95% RT)**
+
+**POINT_SELECT performance**
+
+| Threads | EXPRESS_OLTP | COMPLEX_OLTP | OLAP | HTAP | KV |
+| :---: | :---: | :---: | :---: | :---: | :---: |
+| 32 | 163457.60/0.22 | 162747.70/0.22 | 161428.80/0.23 | 162948.95/0.20 | 163204.29/0.20 |
+| 64 | 296206.41/0.25 | 291823.36/0.26 | 291583.48/0.26 | 293622.63/0.25 | 295541.97/0.25 |
+| 128 | 505203.80/0.30 | 493859.95/0.31 | 492135.78/0.31 | 498132.19/0.31 | 505266.56/0.30 |
+| 256 | 798005.94/0.45 | 794547.97/0.47 | 803165.10/0.49 | 797304.31/0.45 | 794627.82/0.45 |
+| 512 | 1039286.05/0.90 | 1023822.11/1.14 | 1022666.33/1.12 | 1032713.76/0.90 | 1016045.20/0.92 |
+| 1024 | 1013992.61/2.39 | 1011295.14/2.39 | 997362.00/2.57 | 1004848.34/2.48 | 990136.68/2.52 |
+
+
+**READ_ONLY performance**
+
+| Threads | EXPRESS_OLTP | COMPLEX_OLTP | OLAP | HTAP | KV |
+| :---: | :---: | :---: | :---: | :---: | :---: |
+| 32 | 134791.19/4.10 | 136145.15/3.97 | 137486.55/3.96 | 137327.53/3.95 | 137750.08/3.96 |
+| 64 | 244754.37/4.49 | 244093.17/4.57 | 244641.01/4.57 | 244586.46/4.57 | 247914.45/4.49 |
+| 128 | 416929.45/5.37 | 420143.73/5.47 | 419772.35/5.28 | 420445.05/5.28 | 421381.09/5.28 |
+| 256 | 613453.13/7.56 | 611436.43/8.28 | 603989.96/8.28 | 610998.14/7.43 | 607015.73/8.13 |
+| 512 | 725364.76/16.12 | 738362.91/17.65 | 736059.64/15.83 | 720899.31/16.12 | 693449.90/26.20 |
+| 1024 | 715777.22/41.10 | 707831.35/42.61 | 697077.19/44.17 | 706809.11/42.61 | 699619.03/44.83 |
+
+
+**WRITE_ONLY performance**
+
+| Threads | EXPRESS_OLTP | COMPLEX_OLTP | OLAP | HTAP | KV |
+| :---: | :---: | :---: | :---: | :---: | :---: |
+| 32 | 50914.06/5.00 | 52894.62/4.91 | 50589.47/5.67 | 52088.46/4.74 | 54033.87/4.41 |
+| 64 | 90119.99/5.47 | 93447.67/5.37 | 90202.65/5.37 | 90264.56/5.57 | 94874.07/5.00 |
+| 128 | 164488.33/5.77 | 166099.69/5.57 | 159493.96/5.99 | 159005.24/6.09 | 162650.65/5.57 |
+| 256 | 242240.38/8.13 | 241749.01/8.43 | 232320.85/8.43 | 230522.31/8.74 | 238971.17/7.84 |
+| 512 | 304060.67/13.70 | 306416.65/13.70 | 299155.86/13.70 | 289147.63/13.95 | 301695.38/13.22 |
+| 1024 | 345068.37/23.52 | 348929.05/26.20 | 306096.92/29.72 | 327905.15/27.17 | 313276.26/30.81 |
+
+
+**READ_WRITE performance**
+
+| Threads | EXPRESS_OLTP | COMPLEX_OLTP | OLAP | HTAP | KV |
+| :---: | :---: | :---: | :---: | :---: | :---: |
+| 32 | 90881.38/7.84 | 88141.94/8.28 | 88216.59/8.58 | 89948.44/7.98 | 90592.37/7.98 |
+| 64 | 159748.46/8.90 | 160695.31/9.06 | 157714.41/10.09 | 157230.31/9.39 | 161391.32/8.90 |
+| 128 | 273142.95/10.46 | 275431.02/10.27 | 272648.28/10.27 | 269700.79/11.24 | 275952.12/10.46 |
+| 256 | 391348.85/15.27 | 402154.83/15.00 | 382679.53/16.71 | 383447.47/15.27 | 405787.34/14.46 |
+| 512 | 465031.62/28.67 | 462574.18/33.72 | 466465.96/26.20 | 461249.29/27.66 | 464724.24/27.66 |
+| 1024 | 525924.96/52.89 | 535977.26/48.34 | 510540.58/58.92 | 522066.61/51.02 | 521969.84/51.94 |
+
+
+#### TPC-C
+**Parameter tuning**
+
+```yaml
+#proxy
+ALTER proxyconfig SET proxy_mem_limited='4G';
+ALTER proxyconfig set enable_compression_protocol=false;
+
+#sys
+ALTER system SET enable_sql_audit=false;
+select sleep(5);
+ALTER system SET enable_perf_event=false;
+ALTER system SET syslog_level='PERF';
+alter system set enable_record_trace_log=false;
+```
+
+****
+
+**Test command**
+
+The TPC-C benchmark process encapsulated by obd is used. For more information, see [Run the TPC-C benchmark on OceanBase Database](https://en.oceanbase.com/docs/common-oceanbase-database-10000000000919959).
+
+```sql
+obd test tpcc rn --tenant=perf --tmp-dir=/data/2/tpcc --warehouses=1000 --load-workers=40 --terminals=800 --run-mins=5 -v -O 2
+```
+
+****
+
+**Test data**
+
+| | express_oltp | complex_oltp | olap | htap | kv |
+| :---: | :---: | :---: | :---: | :---: | :---: |
+| tpmC (NewOrders) | 292204.95 | 302608.69 | 264422.69 | 294316.6 | 286362.9 |
+| tpmTOTAL | 648918.9 | 672866.36 | 587580.74 | 654271.82 | 636369.93 |
+| Transaction Count | 3246324 | 3366013 | 2939166 | 3272514 | 3183132 |
+
+
+#### TPC-H
+**Parameter tuning**
+
+```yaml
+#sys
+ALTER SYSTEM flush plan cache GLOBAL;
+ALTER system SET enable_sql_audit=false;
+select sleep(5);
+ALTER system SET enable_perf_event=false;
+ALTER system SET syslog_level='PERF';
+alter system set enable_record_trace_log=false;
+
+#Test tenant
+SET GLOBAL ob_sql_work_area_percentage = 80;
+SET GLOBAL ob_query_timeout = 36000000000;
+SET GLOBAL ob_trx_timeout = 36000000000;
+SET GLOBAL max_allowed_packet = 67108864;
+## parallel_servers_target = max_cpu * server_num * 8
+SET GLOBAL parallel_servers_target = 624;
+```
+
+****
+
+**Test command**
+
+The TPC-H benchmark process encapsulated by obd is used. For more information, see [Run the TPC-H benchmark on OceanBase Database](https://en.oceanbase.com/docs/common-oceanbase-database-10000000000919955).
+
+```sql
+obd test tpch rn --user=root --test-server=server1 --tmp-dir=/data/2/ob --tenant=perf --remote-tbl-dir=/home/admin -s 100
+```
+
+**Test data (columnstore tables used)**
+
+| | express_oltp | complex_oltp | olap | htap | kv |
+| :---: | :---: | :---: | :---: | :---: | :---: |
+| Q1 | 32.33s | 9.86s | 1.83s | 3.03s | 1.90s |
+| Q2 | 1.42s | 0.52s | 0.22s | 0.26s | 0.22s |
+| Q3 | 7.79s | 2.58s | 0.52s | 0.91s | 0.54s |
+| Q4 | 9.55s | 3.01s | 0.27s | 0.66s | 0.27s |
+| Q5 | 15.77s | 4.59s | 0.73s | 1.29s | 0.70s |
+| Q6 | 0.25s | 0.11s | 0.06s | 0.06s | 0.05s |
+| Q7 | 9.76s | 3.65s | 1.19s | 1.76s | 1.18s |
+| Q8 | 5.72s | 1.85s | 0.39s | 0.61s | 0.38s |
+| Q9 | 25.26s | 8.93s | 1.88s | 3.28s | 1.88s |
+| Q10 | 3.96s | 1.74s | 0.46s | 0.75s | 0.46s |
+| Q11 | 2.01s | 0.61s | 0.14s | 0.21s | 0.13s |
+| Q12 | 6.00s | 1.89s | 0.33s | 0.66s | 0.39s |
+| Q13 | 8.40s | 3.43s | 1.64s | 1.94s | 1.64s |
+| Q14 | 0.99s | 0.45s | 0.19s | 0.25s | 0.19s |
+| Q15 | 1.29s | 0.64s | 0.31s | 0.34s | 0.31s |
+| Q16 | 2.69s | 1.07s | 0.53s | 0.61s | 0.51s |
+| Q17 | 3.85s | 1.15s | 0.21s | 0.31s | 0.20s |
+| Q18 | 17.53s | 5.51s | 1.33s | 1.96s | 1.27s |
+| Q19 | 1.49s | 0.60s | 0.24s | 0.31s | 0.23s |
+| Q20 | 6.02s | 2.38s | 1.33s | 1.33s | 1.30s |
+| Q21 | 26.01s | 9.11s | 2.70s | 3.60s | 2.74s |
+| Q22 | 6.01s | 2.23s | 0.79s | 1.00s | 0.78s |
+| Total | 194.10s | 65.91s | 17.26s | 25.13s | 17.28s |
+
+
+#### TPC-DS
+**Parameter tuning**
+
+```yaml
+#sys
+ALTER SYSTEM flush plan cache GLOBAL;
+ALTER system SET enable_sql_audit=false;
+select sleep(5);
+ALTER system SET enable_perf_event=false;
+ALTER system SET syslog_level='PERF';
+alter system set enable_record_trace_log=false;
+
+#Test tenant
+SET GLOBAL ob_sql_work_area_percentage = 80;
+SET GLOBAL ob_query_timeout = 36000000000;
+SET GLOBAL ob_trx_timeout = 36000000000;
+SET GLOBAL max_allowed_packet = 67108864;
+## parallel_servers_target = max_cpu * server_num * 8
+SET GLOBAL parallel_servers_target = 624;
+```
+
+****
+
+**Test command**
+
+The test data volume is 100 GB. For the test process, see [Run the TPC-DS benchmark on OceanBase Database](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000931730).
+
+
+
+**Test data (columnstore tables used)**
+
+| Query | express_oltp | complex_oltp | olap | htap | kv |
+| :---: | :---: | :---: | :---: | :---: | :---: |
+| Q1 | 0.62 | 0.33 | 0.21 | 0.21 | 0.20 |
+| Q2 | 10.19 | 3.29 | 0.99 | 1.26 | 0.99 |
+| Q3 | 0.20 | 0.13 | 0.11 | 0.11 | 0.11 |
+| Q4 | 36.42 | 17.89 | 11.29 | 11.90 | 11.39 |
+| Q5 | 3.95 | 1.79 | 0.98 | 1.11 | 1.00 |
+| Q6 | 0.55 | 0.31 | 0.22 | 0.23 | 0.32 |
+| Q7 | 0.81 | 0.38 | 0.19 | 0.21 | 0.29 |
+| Q8 | 0.55 | 0.32 | 0.24 | 0.24 | 0.22 |
+| Q9 | 2.15 | 0.95 | 0.47 | 0.51 | 0.48 |
+| Q10 | 1.81 | 0.85 | 0.52 | 0.54 | 0.50 |
+| Q11 | 22.09 | 10.94 | 7.09 | 7.35 | 7.13 |
+| Q12 | 0.47 | 0.29 | 0.22 | 0.24 | 0.23 |
+| Q13 | 0.53 | 0.27 | 0.18 | 0.19 | 0.19 |
+| Q14 | 81.19 | 26.90 | 7.86 | 10.40 | 8.01 |
+| Q15 | 0.71 | 0.43 | 0.38 | 0.39 | 0.39 |
+| Q16 | 5.18 | 1.74 | 0.57 | 0.73 | 0.57 |
+| Q17 | 1.26 | 0.64 | 0.39 | 0.44 | 0.41 |
+| Q18 | 0.71 | 0.39 | 0.26 | 0.28 | 0.37 |
+| Q19 | 0.30 | 0.20 | 0.15 | 0.16 | 0.16 |
+| Q20 | 0.39 | 0.26 | 0.19 | 0.21 | 0.20 |
+| Q21 | 0.99 | 0.39 | 0.16 | 0.20 | 0.17 |
+| Q22 | 4.93 | 2.14 | 1.12 | 1.26 | 1.14 |
+| Q23 | 92.37 | 34.42 | 13.27 | 16.41 | 13.41 |
+| Q24 | 3.47 | 1.55 | 0.84 | 0.93 | 0.85 |
+| Q25 | 1.14 | 0.59 | 0.41 | 0.43 | 0.40 |
+| Q26 | 0.49 | 0.26 | 0.16 | 0.19 | 0.16 |
+| Q27 | 1.14 | 0.54 | 0.31 | 0.33 | 0.31 |
+| Q28 | 1.37 | 0.95 | 0.83 | 0.84 | 0.86 |
+| Q29 | 3.94 | 1.34 | 0.46 | 0.56 | 0.45 |
+| Q30 | 0.40 | 0.27 | 0.22 | 0.22 | 0.22 |
+| Q31 | 2.37 | 1.08 | 0.60 | 0.67 | 0.59 |
+| Q32 | 0.12 | 0.11 | 0.10 | 0.10 | 0.10 |
+| Q33 | 1.21 | 0.87 | 0.63 | 0.66 | 0.62 |
+| Q34 | 2.22 | 0.77 | 0.22 | 0.29 | 0.20 |
+| Q35 | 3.57 | 1.51 | 0.76 | 0.85 | 0.72 |
+| Q36 | 1.98 | 0.85 | 0.29 | 0.40 | 0.29 |
+| Q37 | 0.52 | 0.32 | 0.23 | 0.24 | 0.23 |
+| Q38 | 7.00 | 2.99 | 1.50 | 1.70 | 1.52 |
+| Q39 | 2.98 | 1.31 | 0.72 | 0.81 | 0.71 |
+| Q40 | 0.29 | 0.18 | 0.15 | 0.15 | 0.14 |
+| Q41 | 0.04 | 0.04 | 0.04 | 0.03 | 0.04 |
+| Q42 | 0.18 | 0.12 | 0.10 | 0.10 | 0.10 |
+| Q43 | 3.89 | 1.43 | 0.47 | 0.60 | 0.47 |
+| Q44 | 0.50 | 0.45 | 0.44 | 0.46 | 0.45 |
+| Q45 | 0.47 | 0.37 | 0.35 | 0.36 | 0.35 |
+| Q46 | 0.97 | 0.46 | 0.28 | 0.30 | 0.27 |
+| Q47 | 5.12 | 2.11 | 0.99 | 1.11 | 0.98 |
+| Q48 | 0.54 | 0.29 | 0.17 | 0.18 | 0.16 |
+| Q49 | 1.25 | 0.96 | 0.84 | 0.85 | 0.82 |
+| Q50 | 8.07 | 2.36 | 0.44 | 0.65 | 0.44 |
+| Q51 | 22.35 | 7.02 | 2.81 | 3.04 | 2.83 |
+| Q52 | 0.17 | 0.13 | 0.10 | 0.10 | 0.10 |
+| Q53 | 1.56 | 0.52 | 0.17 | 0.20 | 0.16 |
+| Q54 | 2.24 | 0.97 | 0.54 | 0.57 | 0.52 |
+| Q55 | 0.14 | 0.11 | 0.10 | 0.10 | 0.10 |
+| Q56 | 0.67 | 0.61 | 0.60 | 0.59 | 0.57 |
+| Q57 | 2.88 | 1.29 | 0.66 | 0.74 | 0.67 |
+| Q58 | 1.15 | 0.85 | 0.69 | 0.69 | 0.68 |
+| Q59 | 18.73 | 6.56 | 2.10 | 2.64 | 2.04 |
+| Q60 | 1.16 | 0.85 | 0.67 | 0.69 | 0.66 |
+| Q61 | 0.41 | 0.33 | 0.29 | 0.29 | 0.29 |
+| Q62 | 3.00 | 1.15 | 0.37 | 0.47 | 0.36 |
+| Q63 | 1.57 | 0.52 | 0.16 | 0.20 | 0.16 |
+| Q64 | 6.74 | 3.01 | 1.45 | 1.71 | 1.42 |
+| Q65 | 4.18 | 1.66 | 0.73 | 0.86 | 0.70 |
+| Q66 | 1.00 | 0.61 | 0.38 | 0.40 | 0.37 |
+| Q67 | 21.56 | 13.49 | 10.43 | 10.28 | 10.44 |
+| Q68 | 0.37 | 0.26 | 0.22 | 0.23 | 0.22 |
+| Q69 | 1.23 | 0.66 | 0.48 | 0.50 | 0.47 |
+| Q70 | 5.39 | 2.26 | 1.15 | 1.28 | 1.16 |
+| Q71 | 1.20 | 0.67 | 0.42 | 0.45 | 0.40 |
+| Q72 | 22.39 | 14.68 | 10.40 | 11.09 | 10.44 |
+| Q73 | 0.63 | 0.32 | 0.17 | 0.20 | 0.17 |
+| Q74 | 14.22 | 6.83 | 3.68 | 3.93 | 3.59 |
+| Q75 | 6.72 | 2.80 | 1.42 | 1.55 | 1.39 |
+| Q76 | 0.39 | 0.38 | 0.39 | 0.38 | 0.38 |
+| Q77 | 1.39 | 0.88 | 0.73 | 0.72 | 0.70 |
+| Q78 | 14.46 | 5.91 | 2.57 | 3.00 | 2.56 |
+| Q79 | 2.66 | 1.17 | 0.48 | 0.56 | 0.48 |
+| Q80 | 2.94 | 1.50 | 0.97 | 1.00 | 0.95 |
+| Q81 | 0.63 | 0.29 | 0.16 | 0.18 | 0.16 |
+| Q82 | 0.78 | 0.45 | 0.32 | 0.33 | 0.37 |
+| Q83 | 1.14 | 0.75 | 0.58 | 0.59 | 0.58 |
+| Q84 | 0.58 | 0.28 | 0.18 | 0.18 | 0.18 |
+| Q85 | 0.71 | 0.45 | 0.36 | 0.36 | 0.36 |
+| Q86 | 1.14 | 0.56 | 0.34 | 0.39 | 0.35 |
+| Q87 | 7.29 | 3.04 | 1.59 | 1.72 | 1.57 |
+| Q88 | 1.83 | 0.78 | 0.29 | 0.36 | 0.29 |
+| Q89 | 1.78 | 0.72 | 0.23 | 0.32 | 0.24 |
+| Q90 | 0.44 | 0.22 | 0.14 | 0.15 | 0.14 |
+| Q91 | 0.14 | 0.11 | 0.10 | 0.10 | 0.10 |
+| Q92 | 0.11 | 0.10 | 0.10 | 0.10 | 0.10 |
+| Q93 | 7.68 | 2.24 | 0.47 | 0.64 | 0.47 |
+| Q94 | 2.74 | 1.08 | 0.49 | 0.56 | 0.49 |
+| Q95 | 39.75 | 18.00 | 6.97 | 8.23 | 6.72 |
+| Q96 | 2.43 | 0.78 | 0.20 | 0.26 | 0.20 |
+| Q97 | 7.34 | 2.64 | 1.01 | 1.22 | 1.04 |
+| Q98 | 0.64 | 0.42 | 0.31 | 0.33 | 0.31 |
+| Q99 | 6.00 | 2.16 | 0.68 | 0.80 | 0.65 |
+| Total | 570.64s | 242.76s | 119.88s | 134.26s | 119.98s |
+
+
+### Summary
+After a tenant is created by using a parameter template, the benchmark results for the corresponding business scenario show that the performance is significantly improved. The parameter template feature will be gradually popularized among OceanBase Database users. We recommend that you have a try.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/_index.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/_index.md
new file mode 100644
index 000000000..395db83bf
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/_index.md
@@ -0,0 +1,4 @@
+---
+title: Best Practices for Different Scenarios
+weight: 4
+---
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/01_introduction.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/01_introduction.md
new file mode 100644
index 000000000..e38c5e441
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/01_introduction.md
@@ -0,0 +1,92 @@
+---
+title: Introduction
+weight: 1
+---
+
+> Keywords: resource pooling | manageability | cost reduction
+>
+> OceanBase Database adopts a native multitenancy architecture, which supports multiple tenants in one cluster. Each tenant can be considered a database service. Data and resources of a tenant are isolated from those of other tenants, and tenant resources are uniformly scheduled within the cluster. Users can create MySQL tenants or Oracle tenants and configure the number, type, and storage location of data replicas as well as computing resources for each tenant.
+
+## SaaS Resource Consolidation
+
+### Microservice architecture
+As the business system of an enterprise becomes more complex, a monolithic service architecture will cause overwhelming workload in engineering and management. If a microservice architecture is used, the enterprise can add and adjust services only by adding new microservice nodes. However, as each microservice needs a separate database, more services require more databases, leading to challenges for database reliability and O&M management.
+
+With the multitenancy architecture of OceanBase Database, the administrator needs to maintain only a small number of clusters, with guaranteed isolation of tenant data and resources and improved database stability.
+
+### Multi-tenant SaaS
+Generally, software-as-a-service (SaaS) cloud vendors provide multi-tenant services. If the spaces of multiple business tenants are logically isolated by tenant name in a single database, operations of different tenants can affect each other. If each business tenant uses a separate database, the large number of scattered databases can be a real headache for O&M engineers. The scalability is limited, let alone the high costs.
+
+The native multitenancy architecture of OceanBase Database provides a better balance between resource isolation and costs, and tenants of any specification can be scaled in and out separately.
+
+
+## Current Status and Challenges of the Industry
+- Fragmented instances: Typically, a SaaS enterprise comprises multiple business applications or has to deploy many database instances to accommodate the resource isolation requirements of different customers. When the requests of a key business or customer surge, the performance and availability cannot be ensured because flexible scaling is not supported.
+
+- Resource waste: Due to fragmented deployment of database resources, a capacity margin is reserved for each instance to accommodate request growth within a short period. From the perspective of the whole business, the resource reservation is actually a great waste of resources, which increases the resource cost of the enterprise.
+
+- Complex management: The management efficiency for a large number of database instances is low. The database team cannot perform refined management on hundreds or thousands of instances. The time efficiency in recovery is low when events such as faults or jitters occur. The overall resource usage cannot be controlled globally, increasing the manual management cost.
+
+
+## Solution
+
+OceanBase Database consolidates the database instances of different businesses based on its multitenancy architecture, improves the resource utilization, and ensures high availability for each resource unit by using the Paxos-based multi-replica mechanism.
+
+OceanBase Database applies both to medium- and large-sized enterprises for resource pooling of different business links, and to SaaS vendors from different industries to provide instances of different specifications for different customers. This lowers the costs while ensuring resource isolation.
+
+
+
+## Solution Advantages
+
+- Multi-tenant resource pooling: OceanBase Database natively supports resource isolation and virtualization for multiple tenants in the same cluster. This means that hundreds of database instances can be deployed in one OceanBase cluster. Data and resources are isolated for each tenant. Computing resources can be upgraded within seconds.
+- Multidimensional scalability: The multi-node distributed architecture of OceanBase Database allows you to upgrade the specifications of an individual node, add more nodes to a cluster, and distribute the traffic across multiple nodes with higher specifications. The scaling is transparent to upper-layer applications. No manual intervention is required during the scaling for data migration. OceanBase Database automatically completes the data migration and multidimensional data verification.
+- Unified management: After the scattered instances are deployed in OceanBase Database in a unified manner, the complexity in O&M management is significantly reduced. Before the optimization, the database administrator (DBA) needs to manage hundreds of scattered instances. After the optimization, the DBA needs to manage only a couple of OceanBase clusters. Loads, alerts, and tuning are all consolidated to the cluster level. Common faults can be automatically troubleshot, significantly improving the business support efficiency and emergency response capability.
+- Cost reduction and efficiency improvement: Computing resources are pooled based on the multitenancy architecture, improving the overall resource utilization. The advanced compression feature of OceanBase Database reduces the storage cost by 2/3 compared to a conventional database. According to extensive feedback from customers and statistics of cases, the resource consolidation solution of OceanBase Database can help medium- and large-sized enterprises reduce the total cost of ownership (TCO) by about 30% to 50%.
+
+## Cases
+
+### Dmall
+#### Business challenges
+Dmall markets its services across borders. In China, its customers include large supermarkets, such as Wumart and Zhongbai, as well as multinational retailers, such as METRO AG and 7-Eleven. Dmall also serves many Chinese and international brands. It links brand owners, suppliers, and retailers with smooth data and information flows so that they can better support and serve consumers. The long service chain, from manufacturers, brand owners, and suppliers, to retailers in various shopping malls and stores, and finally to consumers, generates massive data volumes. The system complexity increases exponentially with the data volume. As a result, the retail SaaS system of Dmall faces three major challenges:
+
+- Complex O&M: Dmall uses a microservice architecture that involves many business links in the overall process and a large system application scale. Dmall already has more than 500 databases. Moreover, as its system continues to iterate, the data scale continues to increase, and O&M management is becoming more and more difficult.
+- Rapid business growth and more horizontal scaling requirements: Dmall formulated a global expansion strategy to cope with its business growth. According to the requirements of regional data security laws, it needs to deploy a new system to undertake business traffic outside China. It is hard to predict future business scale and data growth in the initial deployment phase. Therefore, database resource allocation in the initial deployment phase is quite difficult. The common practice is to deploy the system with limited resources at low costs. However, rapid business growth and exponential data increase will require quick scaling.
+- Serving a large number of merchants in the same cluster: The number of stock keeping units (SKUs) of different convenience stores and supermarket chains ranges from thousands to tens of thousands. Therefore, it is impossible for Dmall to deploy an independent system for each customer. This means that Dmall SaaS system must support hundreds of small and medium-sized business customers, and the data generated by all merchants shares database resources at the underlying layer. Moreover, Dmall has massive individual tenants in the system, such as large chain stores. It wants to isolate the resources for these tenants from those for others.
+
+#### Solution
+- OceanBase Database consolidates multiple individual instances in one OceanBase cluster for unified management and flexible scheduling, thereby effectively improving the resource utilization.
+- Resources are isolated based on tenants. The data of different business modules is isolated from each other. Specifications are transparently upgraded or downgraded as needed.
+- With the powerful intelligent management platform of OceanBase Database, typical faults are automatically detected and analyzed, significantly improving the O&M efficiency.
+- OceanBase Migration Service (OMS) is used to efficiently migrate all business data to OceanBase Database with slight or zero business reconstruction.
+- Based on the powerful leader distribution and read/write routing strategies of OceanBase Database, Ant Group's high-concurrency best practices accumulated over years are shared with customers.
+
+
+
+#### Customer benefits
+- In a multi-tenant cluster, resources can be scaled for a database instance within seconds to support business peaks without adjusting the overall resources of the cluster.
+- OceanBase Database effectively reduces the O&M cost and error probability while addressing the issue of business scalability. In terms of Internet Data Center (IDC)-level disaster recovery, OceanBase Database achieves a recovery point objective (RPO) of 0 and a recovery time objective (RTO) of less than 8s. It can support hundreds of millions of users.
+- With the advanced compression technology, OceanBase Database saves the data storage space by nearly 6 times while ensuring the performance. In other words, OceanBase Database can store more data by using the same hardware resources.
+- OceanBase Database is highly compatible with the SQL statements, stored procedures, and triggers of MySQL. Existing business data can be smoothly migrated to OceanBase Database without business interruption.
+
+### Other cases
+
++ E-surfing Pay: [https://open.oceanbase.com/blog/4446837760](https://open.oceanbase.com/blog/4446837760)
+ - Industry: government enterprises and network operators
+ - Pain points: E-surfing Pay deployed multiple databases in a database cluster, with resources shared among them. When any database was experiencing traffic surges during peak hours, the services of other databases were affected, which significantly impacted the user experience.
+ - Benefits: OceanBase Database supports multitenancy and resource isolation. E-surfing Pay needs to deploy multiple databases for some business modules, such as the online mall. To avoid resource contention among these databases, which may affect other business modules, each database is contained in an OceanBase Database tenant. Resources for each tenant are isolated, so that we can limit the amount of resources for each database. Furthermore, the amount of tenant resources can be adjusted as needed, which means E-surfing Pay can adjust resources of each database. This ensures the business stability and flexibility.
++ China Unicom: [https://open.oceanbase.com/blog/8185228352](https://open.oceanbase.com/blog/8185228352)
+ - Industry: government enterprises and network operators
+ - Pain points: A large number of scattered databases was a real headache for O&M engineers, and the scalability was limited.
+ - Benefits: OceanBase Database supports multiple tenants in one cluster. Each tenant provides services as a database. Data and resources of a tenant are isolated from those of other tenants, and tenant resources are uniformly scheduled within the cluster.
++ TAL: [https://open.oceanbase.com/blog/7832546560](https://open.oceanbase.com/blog/7832546560)
+ - Industry: education
+ - Pain points: The original database was deployed in standalone mode with multiple instances. It did not support resource isolation and generated a large number of resource fragments. The resource deployment mode did not support scaling. A large resource margin was reserved during allocation, leading to low resource utilization.
+ - Benefits: OceanBase Database implements resource isolation and scaling based on its multitenancy architecture. Furthermore, extra cost benefits are gained through data compression.
++ Sunshine Insurance: [https://open.oceanbase.com/blog/8657676560](https://open.oceanbase.com/blog/8657676560)
+ - Industry: financing
+ - Pain points: The original MySQL database hosted many small business modules, leading to complex O&M.
+ - Benefits: OceanBase Database implements resource isolation based on its multitenancy architecture. Resources are allocated based on business needs, maximizing the use of server resources.
++ KEYTOP: [https://open.oceanbase.com/blog/7521893152](https://open.oceanbase.com/blog/7521893152)
+ - Industry: logistics and mobility service
+ - Pain points: The SaaS architecture of the entire platform failed to be upgraded based on the original MySQL database. All groups ran independently without data interactions. Some groups demanded data isolation. SaaS can reduce a part of the private deployment and O&M costs.
+ - Benefits: OceanBase Database simplifies private deployment and operations. Based on the group scale, tenants of different specifications are selected to more clearly calculate the resources used by each group and estimate the expenses. After resource isolation, the data amount of each group will be smaller than that of all groups aggregated together. This way, the system can achieve higher performance, stability, and scalability.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge.md
new file mode 100644
index 000000000..e1369e84b
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge.md
@@ -0,0 +1,231 @@
+---
+title: Background Knowledge of Tenants
+weight: 2
+---
+
+> The content marked red in this topic is easily ignored when you use OceanBase Database in a test or production environment, which may lead to serious impact. Therefore, we recommend that you pay more attention to such content.
+
+## Definition
+
+Tenants are created within a cluster. OceanBase Database is built based on a multi-tenant architecture. The multi-tenant architecture applies to scenarios such as resource consolidation and software as a service (SaaS) services and simplifies O&M.
+
+A cluster is a physical concept in the deployment layer and is a collection of zones and nodes. Zones and nodes have attributes such as region. A tenant is a logical concept in the resource layer and is a resource unit defined on a physical node. You can specify the specifications for a resource unit, such as the CPU, memory, log disk space, and IOPS.
+
+**Tenants in OceanBase Database are similar to database instances of conventional databases. A tenant is associated with resources by using a resource pool and thereby exclusively occupies a resource quota. The resource quota can be dynamically adjusted. You can create database objects such as databases, tables, and users in a tenant.**
+
+The concepts of unit config, resource unit, and resource pool are the basis for understanding the concept of tenant.
+
+* Unit config
+
+ A unit config defines the amounts of general physical resources, such as the CPU, memory, disk space, and IOPS. When you create a resource pool, you must specify its unit config and then create resource units based on the unit config.
+
+* Resource unit
+
+ Resource unit is a very important concept in tenant management. OceanBase Database manages physical resources based on resource units. A resource unit is a collection of physical resources such as CPU, memory, disk space, and IOPS. A resource unit is also the basic unit for resource scheduling. It has location attributes such as node, zone, and region. A node is the abstraction of a server and a zone is the abstraction of an IDC. You can modify the deployment mode of a tenant by modifying the location attributes of its resource units.
+
+* Resource pool
+
+ Each resource unit belongs to a resource pool. A resource pool consists of multiple resource units. A resource pool is the basic unit in resource allocation. Resource units in the same resource pool have the same unit config. In other words, the sizes of physical resources are the same for all resource units in the resource pool.
+
+ 
+
+ The preceding figure shows a resource pool named `a_pool` that consists of six resource units. The resource pool has the following attributes:
+
+ * `ZONE_LIST`: the distribution of resource units in zones, which is `ZONE_LIST='zone1,zone2,zone3'` in this example.
+ * `Unit_NUM`: the number of resource units in each zone specified by `ZONE_LIST`, which is `2` in this example.
+ * `Unit_CONFIG_ID`: the ID of the unit config associated with the resource pool. The unit config defines the amounts of physical resources in each resource unit, such as the CPU, memory, log disk space, and IOPS.
+
+The physical concepts and logical concepts are associated based on resource units in OceanBase Database. Each tenant has multiple resource units distributed on multiple nodes in multiple zones. The resource units on each node belong to different tenants. To be short, a cluster consists of nodes and a node is the container of resource units. A tenant consists of resource units and a resource unit is the container of database objects.
+
+When you create a tenant, you can set `RESOURCE_POOL_LIST` to specify the resource pool associated with the tenant. The resource units in this resource pool are intended for this tenant. For example, set `RESOURCE_POOL_LIST` to `a_pool` for Tenant `a`. The following figure shows the deployment.
+
+
+
+This tenant is deployed across three zones and each zone has two resource units. You can modify the `Unit_CONFIG_ID` parameter for the `a_pool` resource pool to dynamically adjust the physical resources for this tenant.
+
+You can also modify the distribution of resource units on different nodes in the same zone, which is called resource unit migration, to achieve load balancing among the nodes. When a node fails, you can migrate the resource units on it to other nodes in the same zone to implement disaster recovery. You can modify the distribution of resource units in different zones, namely, modify the locality of the tenant, to adjust the deployment mode of the tenant, thereby achieving different disaster recovery levels. General deployment modes include three IDCs in the same city, three IDCs across two regions, and five IDCs across three regions.
+
+## Tenant Types
+
+Three types of tenants are supported in OceanBase Database V4.0 and later: sys tenant, user tenant, and meta tenant.
+
+In OceanBase Database of a version earlier than V4.x, only two types of tenants exist: sys tenant and user tenant. Data of a user tenant may be mistakenly stored in the sys tenant, resulting in a large amount of data in the sys tenant. This causes a series of issues such as too many resources occupied by the sys tenant, coarse-grained resource statistics, and insufficient resource isolation, thereby causing a great challenge to the stability of the cluster. In OceanBase Database V4.0 and later, a meta tenant is configured for each user tenant to manage the private data of this user tenant. The meta tenant uses the resources of the user tenant.
+
+RootService implements cluster management, tenant management, resource management, load balancing, daily compaction scheduling, and migration and replication in the sys tenant of OceanBase Database. The sys tenant is a database instance used to process public cluster management tasks within OceanBase Database.
+
+### Overview
+
+* sys tenant
+
+ The sys tenant is automatically created when you create an OceanBase cluster. Its lifecycle is consistent with that of the cluster. It manages the lifecycles of the cluster and all user tenants in the cluster. The sys tenant has only one log stream with the ID 1, supports only single-point writes, and does not support scaling. You can create user tables in the sys tenant. All user tables and system tables are served by the No.1 log stream. The data of the sys tenant is the private data of the cluster and does not support physical backup or restore.
+
+ Application systems access OceanBase Database from the sys tenant. The client parses the configuration file of an application system and obtains the IP address list of the sys tenant from the config server. Then, the client accesses the sys tenant to obtain the metadata and connects to the target tenant. The stability of the sys tenant is challenged by its capacity. When multiple application systems restart simultaneously, the surge in connection requests can overwhelm the worker threads of the sys tenant, leading to failures in establishing connections between the application systems and the target tenants. The sys tenant does not support horizontal scaling. You can perform vertical scaling or adjust cluster parameters for the sys tenant.
+
+ Though the multi-replica mechanism ensures that the sys tenant can tolerate failures of a minority of nodes, the sys tenant is still a single point in the cluster. If the sys tenant in an OceanBase cluster becomes abnormal due to a kernel bug, the service availability of the cluster is affected, thereby causing connection establishment failures on the client and management exceptions in the cluster. Therefore, the stability of the sys tenant is essential to the stability of the OceanBase cluster. The system provides a detection mechanism for detecting exceptions of the sys tenant. When an exception is detected, you can use O&M commands to forcibly switch the leader role to recover services. You can also use an external admin tool to forcibly switch services to the new leader and then isolate the abnormal server.
+
+ **Notice: The sys tenant is designed for managing clusters and tenants. It does not provide complete database features. Do not use the sys tenant in a production or test environment, where you need to create and use user tenants.**
+
+
+* User tenant
+
+ A user tenant is a tenant created by a user. It provides complete database features. OceanBase Database Community Edition supports only the MySQL mode. A user tenant can distribute its service capabilities on multiple servers and supports dynamic scaling. Log streams are automatically created and deleted based on user configurations. The data of a user tenant, such as the schema data, user table data, and transaction data, requires stronger data protection and higher availability. Physical synchronization and physical backup and restore of user tenant data across clusters are supported.
+
+* Meta tenant
+
+ Meta tenants are used for internal management in OceanBase Database. When you create a user tenant, a corresponding meta tenant is automatically created. The lifecycle of a meta tenant is the same as that of its user tenant. You can use a meta tenant to store and manage tenant-level private data of the corresponding user tenant. This private data, such as parameters and information about locations, replicas, log stream status, backup and restore, and major compactions, does not require cross-database physical synchronization or physical backup and restore. You cannot log in to a meta tenant. You can only query the data in a meta tenant from views in the sys tenant. A meta tenant has no independent resource units. When a meta tenant is created, resources are reserved for it by default. The resources are deducted from those of the corresponding user tenant.
+
+User tenants and meta tenants are associated. A user tenant stores the data of users, including tables created by users and some system tables. This data must be synchronized between the primary and standby clusters and is also needed during physical backup and restore. A meta tenant stores the private data of the corresponding user tenant to support the running of the user tenant. Meta tenants are separately created in the primary and standby clusters. A meta tenant will also be created for a user tenant restored based on the physical backup data. Therefore, the data stored in a meta tenant does not need to be synchronized between the primary and standby clusters or backed up. Similar to a meta tenant, the sys tenant stores the private data of the cluster to support the running of the cluster. This data also does not need to be synchronized between the primary and standby clusters or physically backed up.
+
+
+
+As shown in the preceding figure:
+
+* A tenant is an instance in OceanBase Database and exclusively occupies part of the physical resources. It is similar to a Docker container in a cloud environment.
+* The sys tenant is created by default for an OceanBase cluster and its lifecycle is consistent with that of the cluster. It manages the lifecycles of the cluster and all user tenants in the cluster.
+* A user tenant is created by a user. One user tenant corresponds to one meta tenant, and they have the same lifecycle.
+* Private data refers to the data required to support the running of a cluster or user tenant. Each cluster or tenant has its own data, which does not need to be synchronized between the primary and standby clusters or physically backed up.
+* Non-private data refers to the user data, including the tables created by users and some system tables. This part of data must be synchronized between the primary and standby clusters and physically backed up.
+* The sys tenant or meta tenant has only one log stream with the ID 1 and does not support scaling.
+* You can dynamically create and delete log streams for a user tenant to implement horizontal scaling.
+
+### Tenant information query
+
+You can log in to the sys tenant and query the `DBA_OB_TENANTS` view for information about all tenants. `TENANT_TYPE` indicates the tenant type. The value `SYS` indicates the sys tenant, `META` indicates a meta tenant, and `USER` indicates a user tenant. The ID of the sys tenant is 1. Among tenants whose IDs are greater than 1000, an even ID number indicates a user tenant, and an odd number indicates a meta tenant. The ID of a user tenant is equal to that of the corresponding meta tenant plus 1.
+
+Here is an example:
+
+```shell
+obclient [oceanbase]> SELECT * FROM DBA_OB_TENANTS;
++-----------+-------------+-------------+----------------------------+----------------------------+--------------+---------------+-------------------+--------------------+--------+---------------+--------+-------------+-------------------+------------------+---------------------+---------------------+---------------------+---------------------+--------------+----------------------------+
+| TENANT_ID | TENANT_NAME | TENANT_TYPE | CREATE_TIME | MODIFY_TIME | PRIMARY_ZONE | LOCALITY | PREVIOUS_LOCALITY | COMPATIBILITY_MODE | STATUS | IN_RECYCLEBIN | LOCKED | TENANT_ROLE | SWITCHOVER_STATUS | SWITCHOVER_EPOCH | SYNC_SCN | REPLAYABLE_SCN | READABLE_SCN | RECOVERY_UNTIL_SCN | LOG_MODE | ARBITRATION_SERVICE_STATUS |
++-----------+-------------+-------------+----------------------------+----------------------------+--------------+---------------+-------------------+--------------------+--------+---------------+--------+-------------+-------------------+------------------+---------------------+---------------------+---------------------+---------------------+--------------+----------------------------+
+| 1 | sys | SYS | 2023-05-17 18:10:19.940353 | 2023-05-17 18:10:19.940353 | RANDOM | FULL{1}@zone1 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | NULL | NULL | NULL | NULL | NOARCHIVELOG | DISABLED |
+| 1001 | META$1002 | META | 2023-05-17 18:15:21.455549 | 2023-05-17 18:15:36.639479 | zone1 | FULL{1}@zone1 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | NULL | NULL | NULL | NULL | NOARCHIVELOG | DISABLED |
+| 1002 | mysql001 | USER | 2023-05-17 18:15:21.461276 | 2023-05-17 18:15:36.669988 | zone1 | FULL{1}@zone1 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | 1684395321137516636 | 1684395321137516636 | 1684395321052204807 | 4611686018427387903 | NOARCHIVELOG | DISABLED |
+| 1003 | META$1004 | META | 2023-05-17 18:18:19.927859 | 2023-05-17 18:18:36.443233 | zone1 | FULL{1}@zone1 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | NULL | NULL | NULL | NULL | NOARCHIVELOG | DISABLED |
+| 1004 | oracle001 | USER | 2023-05-17 18:18:19.928914 | 2023-05-17 18:18:36.471606 | zone1 | FULL{1}@zone1 | NULL | ORACLE | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | 1684395321137558760 | 1684395321137558760 | 1684395320951813345 | 4611686018427387903 | NOARCHIVELOG | DISABLED |
++-----------+-------------+-------------+----------------------------+----------------------------+--------------+---------------+-------------------+--------------------+--------+---------------+--------+-------------+-------------------+------------------+---------------------+---------------------+---------------------+---------------------+--------------+----------------------------+
+5 rows in set
+```
+
+### Differences among different types of tenants
+
+The following table compares the key characteristics of the three types of tenants from the user perspective.
+
+| Comparison item | sys tenant | User tenant | Meta tenant |
+|------|---------|---------|-----------|
+| Tenant ID | Fixed value: 1 | Minimum value: 1002 | Minimum value: 1001
Relationship with the user tenant ID: meta tenant ID + 1 = user tenant ID |
+| Tenant type | SYS | USER | META |
+| Tenant naming rule | sys | The name consists of letters, digits, and underscores (_). | The format is `META${user_tenant_id}`. For example, if the user tenant ID is 1002, the meta tenant name is META$1002. |
+| Data attribute | Private cluster data | Non-private tenant data | Private tenant data |
+| Scalability | Horizontal scaling is not supported. Only one log stream is available. | Dynamic scale-out and scale-in are supported. | Horizontal scaling is not supported. Only one log stream is available. |
+| O&M operations | - Create: not supported
- Drop: not supported
- Rename: not supported
- User login: supported
- Modify the locality: supported
- Modify the primary zone setting: supported
| - Create: supported
- Drop: supported
- Rename: supported
- User login: supported
- Modify the locality: supported
- Modify the primary zone setting: supported
| - Create: not supported
- Drop: not supported
- Rename: not supported
- User login: not supported
- Modify the locality: not supported
- Modify the primary zone setting: not supported
|
+| External data access interface | Views in the sys tenant | - In the sys tenant:
- The `CDB_xxx` views and dynamic performance views display the data of all user tenants.
- The `DBA_OB_TENANTS` view displays information about all user tenants.
- In a user tenant, the data of the current tenant is displayed.
| You cannot log in to a meta tenant. However, you can access its data from a user tenant or the sys tenant. - In the sys tenant:
- The `CDB_xxx` views and dynamic performance views display the data of all meta tenants.
- The `DBA_OB_TENANTS` view displays information about all meta tenants.
- The data managed by a meta tenant is displayed in the views of the corresponding user tenant. For example, the `DBA_OB_LS_LOCATIONS` view displays the routing information and the `GV$OB_PARAMETERS` view displays the parameter information.
|
+
+## User Tenant
+
+A user tenant is similar to a general database management system. It is equivalent to a database instance. User tenants are created in the sys tenant based on business needs and provide complete database features. You cannot use the sys tenant or meta tenants in a production or test environment. Instead, you need to create and use user tenants.
+
+The characteristics of a user tenant are the same as that of a database instance. Major characteristics are as follows:
+
+* Users can be created in a user tenant.
+* All objects such as databases (supported only in MySQL mode) and tables can be created in a user tenant.
+* A user tenant has a separate set of system tables and system views.
+* A user tenant has a separate set of system variables.
+* A user tenant has other characteristics of a database instance.
+
+The metadata of all user data is stored in user tenants. Each tenant is assigned a unique namespace that is isolated from other namespaces.
+
+A cluster has only one sys tenant, through which you can create and manage user tenants in the cluster. You can create and manage database objects such as users, databases, tables, and views in a user tenant. The following figure shows the hierarchical relationship between database objects in OceanBase Database.
+
+
+
+Users that are created in a user tenant can log in only to this user tenant and are invisible to other tenants. You can query the `mysql.user` view for user information.
+
+Tables created in a user tenant are invisible to other tenants. You can query the `information_schema.tables` view for information about all user tables in the current tenant.
+
+A user tenant can modify only its own system variables. You can query the `information_schema.global_variables` and `information_schema.session_variables` views for system variables of a tenant. You can also execute the `SHOW VARIABLES` statement to query the system variables of a tenant.
+
+## System Variables and Parameters
+
+You can configure system variables and parameters to ensure that the behavior of OceanBase Database meets your business needs.
+
+Different system variables and parameters may take effect on a different scope, which can be the entire cluster, the current tenant, or the current session.
+
+### Tenant system variables
+
+**In OceanBase Database, all system variables take effect only for the current tenant. Therefore, system variables are also referred to as tenant system variables.**
+
+When you set a system variable, you can add the `Global` or `Session` keyword to specify the effective scope of the system variable within the tenant.
+* A global variable is used to implement a global modification. Users in the same database tenant share the settings of global variables. Modifications to global variables remain effective after you exit the session. In addition, modifications to global variables do not take effect on the currently open session and take effect only after a new session is established.
+* A session variable is used to implement a session-level modification. In other words, the modification takes effect only for the current session. When a new client is connected to the database, the database copies global variables to automatically generate session-level variables.
+
+### Parameters
+
+OceanBase Database provides cluster-level and tenant-level parameters.
+
+* Cluster-level parameters specify the basic information and performance and security options of an entire OceanBase cluster. Typical cluster-level parameters are those used for global tasks, such as data backup and restore, and load balancing. Usually, cluster-level parameters are specified during cluster startup and are seldom modified.
+
+* Tenant-level parameters specify feature options of one or more tenants to optimize specific configurations of the tenants. Typical tenant-level parameters are those used for the storage engine, SQL execution strategies, and access control. Usually, tenant-level parameters are specified when you create and manage a tenant, and can be modified as needed at any time.
+
+To query whether a parameter is a cluster-level or tenant-level parameter, execute the following statement:
+
+```shell
+obclient [test]> SHOW PARAMETERS; -- Queries all system parameters.
+
+obclient [test]> SHOW PARAMETERS like 'cpu_quota_concurrency'\G
+*************************** 1. row ***************************
+ zone: zone1
+ svr_type: observer
+ svr_ip: 11.158.31.20
+ svr_port: 22602
+ name: cpu_quota_concurrency
+ data_type: NULL
+ value: 4
+ info: max allowed concurrency for 1 CPU quota. Range: [1,20]
+ section: TENANT
+ scope: TENANT
+ source: DEFAULT
+edit_level: DYNAMIC_EFFECTIVE
+1 row in set (0.004 sec)
+
+obclient [test]> SHOW PARAMETERS like 'max_string_print_length'\G
+*************************** 1. row ***************************
+ zone: zone1
+ svr_type: observer
+ svr_ip: 11.158.31.20
+ svr_port: 22602
+ name: max_string_print_length
+ data_type: NULL
+ value: 500
+ info: truncate very long string when printing to log file. Range:[0,]
+ section: OBSERVER
+ scope: CLUSTER
+ source: DEFAULT
+edit_level: DYNAMIC_EFFECTIVE
+1 row in set (0.005 sec)
+```
+
+If the value in the `scope` column is `CLUSTER`, the parameter takes effect for the entire cluster. If the value is `TENANT`, the parameter takes effect for the current tenant.
+
+If the value in the `edit_level` column is `DYNAMIC_EFFECTIVE`, the modification takes effect immediately. If the value is `STATIC_EFFECTIVE`, the modification takes effect after the OBServer node is restarted.
+
+**Notice**
+
+**In the preceding query result, the `section` column can be easily confused with the `scope` column. Its valid values include `LOAD_BALANCE`, `DAILY_MERGE`, `RPC`, `TRANS`, and `LOCATION_CACHE`, and can even be `TENANT` or `OBSERVER`, as shown in the preceding example. The `section` column is just a tag that indicates the module to which the parameter is related, and does not indicate the effective scope of the parameter. Familiarize yourself with the meanings of the two columns.**
+
+**We recommend that you pay special attention to value `TENANT` or `OBSERVER` of the `section` column, which does not mean that the parameter takes effect for the current tenant or for the OBServer node of the current session. Instead, such a value may indicate that the R&D personnel cannot decide the module to categorize the corresponding parameter.**
+
+
+
+
+The following table compares parameters and system variables.
+
+| Comparison item | Parameter | System variable |
+|---------|-----------|---------|
+| Effective scope | Effective in a cluster, zone, server, or tenant. | Effective globally or at the session level in a tenant. |
+| Effective scope | - Dynamically take effect: The value of
edit_level is dynamic_effective. - Take effect upon restart: The value of
edit_level is static_effective.
| - A session-level variable takes effect only for the current session.
- A global variable does not take effect on the current session and takes effect only on new sessions established upon re-login.
|
+| Modification | - Modification can be performed by using SQL statements, for example,
Alter SYSTEM SET schema_history_expire_time='1h';. - Modification can be performed by using startup parameters, for example,
cd /home/admin/oceanbase && ./bin/observer -o "schema_history_expire_time='1h'";.
| Modification can be performed only by using SQL statements. Here is an example:- MySQL mode
SET ob_query_timeout = 20000000;
SET GLOBAL ob_query_timeout = 20000000;
|
+| Query | You can query a parameter by using the `SHOW PARAMETERS` statement, for example, `SHOW PARAMETERS LIKE 'schema_history_expire_time';`. | You can query a variable by using the `SHOW [GLOBAL] VARIABLES` statement. Here are some examples: - `SHOW VARIABLES LIKE 'ob_query_timeout';`
- `SHOW GLOBAL VARIABLES LIKE 'ob_query_timeout';`
|
+| Persistence | Parameters are persisted into internal tables and configuration files and can be queried from the observer.config.bin and observer.config.bin.history files in the /home/admin/oceanbase/etc directory. | Only global variables are persisted. |
+| Lifecycle | Long. A parameter remains effective for the entire duration of a process. | Short. A system variable takes effect only after the tenant schema is created. |
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/03_resource_isolation_between_tenants.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/03_resource_isolation_between_tenants.md
new file mode 100644
index 000000000..324361fb9
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/03_resource_isolation_between_tenants.md
@@ -0,0 +1,190 @@
+---
+title: Resource Isolation Between Tenants
+weight: 3
+---
+
+OceanBase Database is a multi-tenant database system. It isolates resources among tenants to prevent resource contention and ensure stable business operation.
+
+Resource isolation refers to the behavior of controlling resource allocation among multiple resource units on a node, and it is a local behavior of the node. Similar technologies include Docker and virtual machines (VMs), but OceanBase Database does not rely on Docker or VM technologies for resource isolation. It implements resource isolation internally within the database.
+
+In OceanBase Database, resource units are the basic units for allocating resources to tenants. A resource unit is equivalent to a Docker container. You can create multiple resource units on a node. Each resource unit created on a node occupies a part of the physical resources on the node, such as the CPU and memory resources. The allocation of resources on a node is recorded in an internal table for database administrators.
+
+You can create multiple resource units across nodes for a tenant. However, a tenant can have only one resource unit on a node. The resource units of a tenant are independent of each other. Currently, OceanBase Database does not aggregate the resource usage of multiple resource units for global resource control. Specifically, if the resources on a node fail the demand of a tenant, OceanBase Database does not allow the tenant to compete for resources of other tenants on another node.
+
+## Advantages of Multi-tenant Isolation in OceanBase Database
+
+Compared with Docker containers and VMs, OceanBase Database provides more lightweight tenant isolation and makes it easier to implement advanced features such as priority management.
+From the perspective of OceanBase Database requirements, Docker containers and VMs have the following disadvantages:
+
+* There are heavy overheads in runtime environments of both Docker containers and VMs, while OceanBase Database needs to support lightweight tenants.
+
+* The specification change and migration of Docker containers or VMs are costly, while OceanBase Database is designed to help tenants change specifications and perform the migration at a faster speed.
+
+* Tenants cannot share resources such as object pools if Docker containers or VMs are used.
+
+* Customizing resource isolation within Docker containers or VMs, such as priority support within tenants, is challenging.
+
+In addition, unified views cannot be exposed if Docker containers or VMs are used.
+
+## Isolation Effects
+
+* Memory resources are completely isolated.
+
+ * Memory resources for operators during SQL execution are isolated. When the memory of a tenant is exhausted, other tenants are not affected.
+
+ * The block cache and MemTable are isolated. When the memory of a tenant is exhausted, the read and write operations of other tenants are not affected.
+
+* CPU resources are completely isolated.
+
+ * Basic CPU resource isolation is implemented by controlling the number of active threads based on the user status. Each tenant has an independent thread pool. The specifications of a thread pool are subject to the tenant specifications and some parameters. The CPU resources available for a tenant are determined by the unit config.
+
+ * To achieve better isolation effects, OceanBase Database allows you to configure control groups (cgroups) for CPU isolation since V4.0.0. Cgroup is a mechanism provided by the Linux kernel to aggregate or divide, based on specialized behavior, a series of system tasks and their subtasks into different groups that are graded based on resources, thereby providing a unified framework for system resource management. You can precisely limit the CPU utilization of threads based on cgroups, thereby implementing CPU isolation among tenants.
+
+ 
+
+* SQL modules of different tenants do not affect each other.
+
+ * The SQL plan cache of a tenant is isolated from that of another tenant. When the plan cache of a tenant is evicted, the plan caches of other tenants are not affected.
+
+ * The SQL audit table of a tenant is isolated from that of another tenant. If the queries per second (QPS) value of a tenant is very high, the audit information about other tenants is not flushed.
+
+* Transaction modules of different tenants do not affect each other.
+
+ * If the row lock of a tenant is suspended, other tenants are not affected.
+
+ * If the transaction of a tenant is suspended, other tenants are not affected.
+
+ * If the replay for a tenant fails, other tenants are not affected.
+
+* Clog modules of different tenants do not affect each other.
+
+ The log stream directories are divided by tenant. The structure of a log stream directory on the disk is as follows:
+
+ ```
+ tenant_id
+ ├── unit_id_0
+ │ ├── log
+ │ └── meta
+ ├── unit_id_1
+ │ ├── log
+ │ └── meta
+ └── unit_id_2
+ ├── log
+ └── meta
+ ```
+
+## Resource Classification
+
+OceanBase Database supports isolation of CPU, memory, and IOPS resources for tenants in V4.0.0 and later. You can specify resource specifications such as `CPU`, `MEMORY`, `IOPS`, and `LOG_DISK_SIZE` for each resource unit.
+
+```sql
+obclient>
+ CREATE RESOURCE UNIT name
+ MAX_CPU = 1, [MIN_CPU = 1,]
+ MEMORY_SIZE = '5G',
+ [MAX_IOPS = 1024, MIN_IOPS = 1024, IOPS_WEIGHT=0,]
+ [LOG_DISK_SIZE = '2G'];
+```
+
+### Available CPU resources on an OBServer node
+
+When an OBServer node starts, the system detects the number of online CPU cores of the physical server or container. If the detected number of CPU cores is inaccurate, for example, in a containerized environment, you can use the `cpu_count` parameter to specify CPU resources.
+
+Each OBServer node reserves two CPU cores for background threads. Therefore, the total CPU cores that can be allocated to tenants are two less than the CPU cores on the OBServer node.
+
+### Available memory resources on an OBServer node
+
+When an OBServer node starts, the system detects the memory of the physical server or container. Each OBServer node reserves a part of the memory for other processes. Therefore, the size of memory available for the observer process is calculated based on the following formula: `physical memory × memory_limit_percentage`. You can also use the `memory_limit` parameter to specify the total size of memory available for the observer process.
+
+The size of memory for internal shared modules must be subtracted from the size of memory available for the observer process. The remaining memory is available for tenants. The size of memory for internal shared modules is specified by the `system_memory` parameter.
+
+### Check the available resources on each OBServer node
+
+You can query the `oceanbase.GV$OB_SERVERS` view for the available resources on each OBServer node. Here is an example:
+
+```sql
+obclient> SELECT * FROM oceanbase.GV$OB_SERVERS\G
+*************************** 1. row ***************************
+ SVR_IP: xx.xx.xx.xx
+ SVR_PORT: 57234
+ ZONE: zone1
+ SQL_PORT: 57235
+ CPU_CAPACITY: 14
+ CPU_CAPACITY_MAX: 14
+ CPU_ASSIGNED: 6.5
+ CPU_ASSIGNED_MAX: 6.5
+ MEM_CAPACITY: 10737418240
+ MEM_ASSIGNED: 6442450944
+ LOG_DISK_CAPACITY: 316955164672
+ LOG_DISK_ASSIGNED: 15569256438
+ LOG_DISK_IN_USE: 939524096
+ DATA_DISK_CAPACITY: 10737418240
+ DATA_DISK_IN_USE: 624951296
+DATA_DISK_HEALTH_STATUS: NORMAL
+DATA_DISK_ABNORMAL_TIME: NULL
+1 row in set
+```
+
+## Resource Isolation
+
+### Memory isolation
+
+OceanBase Database does not support memory overprovisioning on OBServer nodes in V4.0.0 and later, because memory overprovisioning will cause unstable tenant operation. The `MIN_MEMORY` and `MAX_MEMORY` parameters are deprecated, and the `MEMORY_SIZE` parameter is used instead.
+
+### CPU isolation
+
+Before OceanBase Database V3.1.x, you can limit the number of threads to control CPU utilization. In OceanBase Database V3.1.x and later, you can configure cgroups to control CPU utilization.
+
+**Thread classification**
+
+Many threads with different features start along with an OBServer node. In this section, threads are classified into the following two types:
+
+* Threads for processing SQL statements and transaction commits, which are collectively referred to as tenant worker threads.
+
+* Threads for processing network I/O, disk I/O, compactions, and scheduled tasks, which are referred to as background threads.
+
+In the current version of OceanBase Database, tenant worker threads and most background threads are tenant-specific, and network threads are shared.
+
+**CPU isolation for tenant worker threads based on the number of threads**
+
+CPU resources in a resource unit are isolated based on the number of active tenant worker threads for the resource unit.
+
+Because the execution of SQL statements may involve I/O waiting and lock waiting, a thread may not fully utilize a physical CPU. Therefore, under default configurations, an OBServer node starts four threads on each CPU. You can set the `cpu_quota_concurrency` parameter to control the number of threads to be started on a CPU. In this case, if the `MAX_CPU` parameter of a resource unit is set to `10`, 40 parallel active threads are allowed for the resource unit, and the maximum CPU utilization is 400%.
+
+**CPU isolation for tenant worker threads based on cgroups**
+
+After cgroups are configured, worker threads of different tenants are stored in different cgroup directories, which improves CPU isolation between tenants. The isolation results are described as follows:
+
+* If a tenant on an OBServer node has a very high load and the rest of the tenants are relatively idle, then the CPU of the high-load tenant will also be limited by `MAX_CPU`.
+
+* If the load of the idle tenants increases, physical CPU resources become insufficient. In this case, cgroups allocate time slices based on weights.
+
+**CPU isolation for background threads**
+
+* In OceanBase Database V4.0.0, threads used by a tenant are isolated from those used by another tenant, and each tenant controls a corresponding number of threads.
+
+* For better isolation, background threads are also allocated to different cgroup directories to achieve isolation between tenants and between tenants and worker threads.
+
+**Large query processing**
+
+Compared with quick responses to large queries, quick responses to small queries are of higher significance. This means that large queries have lower priorities than small queries. When large queries and small queries contend for CPU resources, the system limits the amount of CPU resources occupied by large queries.
+
+If a worker thread takes a long time to execute an SQL query, the query is identified as a large query, and the worker thread waits in a pthread condition to release its CPU resources to other tenant worker threads.
+
+To support this feature, OBServer nodes insert many checkpoints into the code, making tenant worker threads periodically check their status during the running process. When an OBServer node determines that a worker thread should be suspended, the worker thread waits in a pthread condition.
+
+If both large queries and small queries exist, the large queries can occupy at most 30% of the tenant worker threads. The percentage 30% is specified by the `large_query_worker_percentage` parameter.
+
+Take note of the following items:
+
+* If no small queries exist, large queries can occupy 100% of the tenant worker threads. The percentage 30% takes effect only when both large queries and small queries exist.
+
+* If a tenant worker thread is suspended because it executes a large query, the system may create a tenant worker thread for compensation. However, the total number of tenant worker threads cannot exceed 10 times the value of the `MAX_CPU` parameter. The multiple 10 is specified by the `workers_per_cpu_quota` parameter.
+
+**Identify large queries in advance**
+
+An OBServer node starts a new tenant worker thread after it suspends a large query thread. However, if many large queries are initiated, new threads created on the OBServer node are still used to process large queries, and the number of tenant worker threads soon reaches the upper limit. No threads are available for small queries until all the large queries are processed.
+
+To resolve this issue, an OBServer node predicts whether an SQL query is large before it is executed by estimating the execution time of the SQL query. Prediction is based on the following assumptions: If the execution plans of two SQL queries are the same, the execution time of the SQL queries is also similar. In this case, you can determine whether an SQL query is large based on the execution time of the latest SQL query with the same execution plan.
+
+Once an SQL request is identified as a large query, it is placed in a large query queue and the tenant worker thread executing the query is released. In this case, the system can continue to respond to subsequent requests.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/01_overview.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/01_overview.md
new file mode 100644
index 000000000..6d0754323
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/01_overview.md
@@ -0,0 +1,38 @@
+---
+title: Overview
+weight: 1
+---
+
+In OceanBase Database, resource units are the basic units for allocating resources to tenants during tenant creation. To some extent, resource isolation between tenants can be considered a native feature of OceanBase Database.
+
+In OceanBase Database Community Edition, each tenant is equivalent to a MySQL instance. For user-level resource isolation and more fine-grained resource isolation within a tenant, you need to configure related settings by referring to this topic.
+
+## Resource Isolation Within a Tenant
+
+In OceanBase Database, the procedural language (PL) package `DBMS_RESOURCE_MANAGER` is used to manage resource allocation in a database to implement resource isolation.
+
+You can use the `DBMS_RESOURCE_MANAGER` package to configure the following types of resource isolation in a tenant based on the granularity of resource usage:
+
+* User-level resource isolation
+
+ User-level resource isolation specifies the mapping between a user and a resource group. All SQL statements initiated by the specified user can be executed by using only the resources in the resource group mapped to the user.
+
+* SQL statement-level resource isolation
+
+ SQL statement-level resource isolation is finer-grained than user-level resource isolation. You can bind the SQL statements that meet a specified condition to a specified resource group to implement SQL statement-level resource isolation. If multiple accounts exist in the business system, when an order of an account is processed, a transaction is enabled to execute a batch of SQL statements related to this account. Generally, the account is specified in the `WHERE` clause. Different accounts may involve different amounts of data. If accounts involving a large amount of data use up the CPU resources, the orders of accounts involving a small amount of data cannot be processed. You can bind SQL statements for processing different orders with different resource groups. In this way, SQL statements for different orders can use resources in different resource groups.
+
+* Function-level resource isolation
+
+ Function-level resource isolation specifies the mapping between a background task and a resource group. In this way, resources are isolated for different types of tasks. At present, you can control the CPU resources available for the background tasks.
+
+## DBMS_RESOURCE_MANAGER Package
+
+The `DBMS_RESOURCE_MANAGER` package is used to maintain the following elements:
+
+* Resource groups: A resource group is a collection of sessions that are grouped based on resource requirements. The system allocates resources to a resource group rather than to individual sessions.
+
+* Resource management plans: A resource management plan is a container of plan directives and specifies how resources are allocated to resource groups. You can activate a specific resource management plan to control the allocation of resources.
+
+* Plan directives: A plan directive associates a resource group with a resource management plan and specifies how resources are allocated to this resource group.
+
+For more information about the `DBMS_RESOURCE_MANAGER` package, see [DBMS_RESOURCE_MANAGER](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001784731) in MySQL mode.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config.md
new file mode 100644
index 000000000..06beda549
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config.md
@@ -0,0 +1,312 @@
+---
+title: Prepare for CPU Resource Isolation
+weight: 2
+---
+
+## Configure Cgroups
+
+**Limitations**
+
+* Resource isolation considerably compromises performance. We recommend that you do not use the control group (cgroup) feature to isolate tenant resources in the following scenarios:
+
+ * Single-tenant scenarios that have only one tenant in the cluster.
+
+ * Scenarios where tenants are associated with each other. For example, multiple tenants serve different microservices, resulting in an upstream and downstream relationship among the tenants.
+
+ * Small-scale tenant scenarios where each tenant has two or four CPU cores.
+
+* If the operating system of the OBServer node is Alibaba Cloud Linux, to use the cgroup feature, the operating system version must be 4.19 or later.
+
+* **Enabling the cgroup feature compromises the performance of OceanBase Database. Therefore, weigh the isolation benefits and performance loss before you enable the cgroup feature.**
+
+### Step 1: Configure the cgroup system directory
+
+
+Notice
+
+- You must configure the cgroup system directory before you install OceanBase Database.
+- You must obtain the
root user privileges before you configure the cgroup system directory.
+
+
+
+This section describes how to configure the cgroup system directory on one OBServer node as the `usercg` user. If the OceanBase cluster consists of multiple OBServer nodes, you must configure the cgroup system directory on each OBServer node.
+
+1. Log in as the `usercg` user to the OBServer node.
+
+2. Run the following command to mount the `/sys/fs/cgroup` directory:
+
+ Note: If the /sys/fs/cgroup directory already exists, skip this step.
+
+ ```shell
+ [usercg@xxx /]$ sudo mount -t tmpfs cgroups /sys/fs/cgroup
+ ```
+
+ `cgroups` is a custom name for identification when you view the mount information.
+
+ The mounting result is as follows:
+
+ ```shell
+ $df
+ Filesystem 1K-blocks Used Available Use% Mounted on
+ / 293601280 28055472 265545808 10% /
+ /dev/v01d 2348810240 2113955876 234854364 91% /data/1
+ /dev/v02d 1300234240 1170211208 130023032 91% /data/log1
+ shm 33554432 0 33554432 0% /dev/shm
+ /dev/v04d 293601280 28055472 265545808 10% /home/usercg/logs
+ cgroups 395752136 0 395752136 0% /sys/fs/cgroup
+ ```
+
+3. Create a directory named `/sys/fs/cgroup/cpu` and change its owner. This directory is used for mounting the `cpu` subsystem later.
+
+ ```shell
+ [usercg@xxx /]$ sudo mkdir /sys/fs/cgroup/cpu
+
+ [usercg@xxx /]$ sudo chown usercg:usercg -R /sys/fs/cgroup/cpu
+ ```
+ Note: If the /sys/fs/cgroup/cpu directory already exists and is empty, skip this step.
+
+4. Mount the `cpu` subsystem.
+
+ Create a directory hierarchy named `cpu`, attach the `cpu` subsystem to this hierarchy, and mount this hierarchy to the `/sys/fs/cgroup/cpu` directory.
+
+ ```shell
+ [usercg@xxx /]$ sudo mount -t cgroup -o cpu cpu /sys/fs/cgroup/cpu
+ ```
+
+5. Create a subdirectory named `oceanbase` and change its owner to `usercg`.
+
+ ```shell
+ [usercg@xxx /]$ sudo mkdir /sys/fs/cgroup/cpu/oceanbase
+
+ [usercg@xxx /]$ sudo chown usercg:usercg -R /sys/fs/cgroup/cpu/oceanbase
+ ```
+
+6. Run the following commands to set the `oceanbase` directory to inherit the CPU and memory configurations from the upper-level directory and set the lower-level directories of the `oceanbase` directory to automatically inherit its configurations.
+
+
+ Notice
+ At present, the cpu, cpuset, and cpuacct subsystems cannot be mounted to different directories. If they are mounted to different directories on your server, clear the mounting information and then run the sudo mount -t cgroup -o cpuset,cpu,cpuacct cpu /sys/fs/cgroup/cpu command to mount them to the same directory.
+
+
+ Confirm that the `cpu`, `cpuset`, and `cpuacct` subsystems are mounted to the same directory and then run the following commands:
+
+ ```shell
+ [usercg@xxx /]$ sudo sh -c "echo `cat /sys/fs/cgroup/cpu/cpuset.cpus` > /sys/fs/cgroup/cpu/oceanbase/cpuset.cpus"
+
+ [usercg@xxx /]$ sudo sh -c "echo `cat /sys/fs/cgroup/cpu/cpuset.mems` > /sys/fs/cgroup/cpu/oceanbase/cpuset.mems"
+
+ [usercg@xxx /]$ sudo sh -c "echo 1 > /sys/fs/cgroup/cpu/oceanbase/cgroup.clone_children"
+ ```
+
+### Step 2: Deploy OceanBase Database
+
+After the `cgroup` system directory is configured, you can deploy OceanBase Database Community Edition. For more information about how to deploy OceanBase Database Community Edition, see [Deploy an OceanBase cluster through the GUI of OCP](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001717430).
+
+
+ Note
+ Only OceanBase Database Community Edition V4.0.0 and later support the complete cgroup feature.
+
+
+### Step 3: Establish a soft link to OceanBase Database
+
+After OceanBase Database is installed, establish a soft link between the installation directory of OceanBase Database and the cgroup system directory.
+
+1. Log in as the `usercg` user to the OBServer node.
+
+2. Manually establish a soft link between the installation directory of OceanBase Database and the cgroup system directory.
+
+ ```shell
+ [usercg@xxx /home/usercg]$ cd /home/usercg/oceanbase/
+
+ [usercg@xxx /home/usercg]
+ $ ln -sf /sys/fs/cgroup/cpu/oceanbase/ cgroup
+ ```
+
+ `/home/usercg/oceanbase/` is the installation directory of OceanBase Database.
+
+ The execution result is as follows:
+
+ ```shell
+ [usercg@xxx /home/usercg/oceanbase]
+ $ll cgroup
+ lrwxrwxrwx 1 usercg usercg 29 Dec 8 11:09 cgroup -> /sys/fs/cgroup/cpu/oceanbase/
+ ```
+
+3. Restart the observer process.
+
+ You must first stop the observer process and then restart it. For more information, see [Restart a node](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714995).
+
+ If the observer process detects that a soft link has been established, it will create the cgroup directory in the `/sys/fs/cgroup/cpu/oceanbase/` directory.
+
+### Step 4: Enable the cgroup feature
+
+In OceanBase Database, the cluster-level `enable_cgroup` parameter specifies whether to enable the cgroup feature for the OBServer nodes in the cluster. The default value is `True`, which specifies to enable this feature. If this feature is disabled, perform the following steps to enable it.
+
+1. Log in to the `sys` tenant of the cluster as the `root` user.
+
+2. Execute any of the following statements to enable the cgroup feature:
+
+ ```sql
+ obclient> ALTER SYSTEM SET enable_cgroup=true;
+ ```
+
+ or
+
+ ```sql
+ obclient> ALTER SYSTEM SET enable_cgroup=1;
+ ```
+
+ or
+
+ ```sql
+ obclient> ALTER SYSTEM SET enable_cgroup=ON;
+ ```
+
+### Others
+
+After you configure the cgroup system directory and enable the cgroup feature, in the case of emergencies, you can control the utilization of CPU resources in a tenant by using the `cpu.cfs_period_us`, `cpu.cfs_quota_us`, and `cpu.shares` files in the directory of the tenant. Generally, we recommend that you do not implement resource isolation in this way.
+
+We recommend that you use the files in the cgroup system directory to call the `CREATE_CONSUMER_GROUP` subprogram in the `DBMS_RESOURCE_MANAGER` package to create resource groups for resource isolation.
+
+## Clear Cgroup Configurations
+
+After OceanBase Database is upgraded, the structure of the cgroup directory may change. Therefore, before you upgrade OceanBase Database, you must delete the original cgroup system directory.
+
+To do so, make sure that you have stopped the OBServer node where the cgroup system directory is configured. For more information, see [Restart a node](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714995).
+
+1. Log in to the server where the OBServer node is located as the `admin` user.
+
+2. Delete the soft link between the installation directory of OceanBase Database and the cgroup system directory.
+
+ ```shell
+ [admin@xxx /home/admin/oceanbase]
+ $ll cgroup
+ lrwxrwxrwx 1 admin admin 29 Dec 8 11:09 cgroup -> /sys/fs/cgroup/cpu/oceanbase/
+
+ [admin@xxx /home/admin/oceanbase]
+ $ rm -rf cgroup
+ ```
+
+3. Delete the cgroup system directory `/sys/fs/cgroup/cpu/oceanbase`.
+
+ Files in the cgroup system directory must be recursively deleted from a lower-level directory to an upper-level directory. Therefore, you can create a script file named `deletecgroupdir.sh` to delete the cgroup system directory and its subdirectories.
+
+ 1. Create a script file, enter related content, and save the script file.
+
+ ```shell
+ [admin@xxx /home/admin]$ vim deletecgroupdir.sh
+ ```
+
+ You must enter the following content in the script file:
+
+ ```JavaScript
+ #! /bin/bash
+ function read_dir(){
+ for file in `ls $1`
+ do
+ if [ -d $1"/"$file ]
+ then
+ read_dir $1"/"$file
+ fi
+ done
+ string=$1
+ echo rmdir $string
+ rmdir $string
+ }
+ # Read the first parameter.
+ read_dir /sys/fs/cgroup/cpu/oceanbase
+ ```
+
+ 2. Execute the script to delete the cgroup system directory.
+
+ ```shell
+ [admin@xxx /home/admin]
+ $sudo /bin/bash deletecgroupdir.sh
+ ```
+
+## Configure Global CPU Resource Isolation for Foreground and Background Tasks
+
+OceanBase Database supports global CPU resource isolation for foreground and background tasks in all tenants.
+
+### Overview
+
+In a high-performance computing environment, reasonable resource allocation and isolation are decisive in ensuring system stability and improving efficiency. An effective resource isolation strategy can prevent resource contention and interference between tasks, thereby improving the resource utilization efficiency and overall service quality. At present, OceanBase Database allows you to configure different unit configs for tenants to implement resource isolation between the tenants, and use the `DBMS_RESOURCE_MANAGER` system package to configure resource isolation within a tenant.
+
+Before you enable global CPU resource isolation for foreground and background tasks on an OBServer node, the OBServer node supports CPU resource isolation between tenants and within a tenant, as shown in the following figure.
+
+
+
+The isolation hierarchy is shown as a tree structure. The strategies of resource isolation between tenants depend on the unit configs of the tenants. The strategies of resource isolation between tasks within a tenant are determined by the `DBMS_RESOURCE_MANAGER` system package.
+
+After you enable global CPU resource isolation for foreground and background tasks, the system creates a tenant-level sub-cgroup based on background tasks. The background sub-cgroup can be understood as a virtual tenant. The `MAX_CPU` value of the virtual tenant is the same as the value of the `global_background_cpu_quota` parameter, and the `MIN_CPU` value of the virtual tenant is `1`. The following figure shows the isolation hierarchy after global CPU resource isolation is enabled for foreground and background tasks.
+
+
+
+After you enable global CPU resource isolation for foreground and background tasks, the maximum CPU resources available to all background tasks are limited by the `global_background_cpu_quota` parameter even if you do not specify strategies of resource isolation within a tenant. This prevents background tasks from affecting foreground tasks.
+
+### Scenarios
+
+We recommend that you enable global CPU resource isolation for foreground and background tasks in the following scenarios:
+
+* You expect global resource isolation for background tasks to prevent them from affecting foreground tasks.
+
+* You want to avoid calculation or configuration of complex strategies of resource isolation between tenants and within a tenant, especially when a large number of tenants are deployed.
+
+### Prerequisites
+
+You have configured the cgroup directory and enabled the cgroup feature on the OBServer node.
+
+### Considerations
+
+* CPU resources can be isolated between tenants. After you enable global CPU resource isolation for foreground and background tasks, the maximum CPU resources available for background tasks of each tenant are limited by the `global_background_cpu_quota` parameter and are equal to `min(MAX_CPU of the tenant, global_background_cpu_quota)`.
+
+
+ Notice
+ In OceanBase Database V4.2.1 and later, CPU resources for the sys tenant are not limited, to avoid impact on requests from the sys tenant.
+
+
+* CPU resources can be isolated within a tenant. After you enable global CPU resource isolation for foreground and background tasks, you can use the `DBMS_RESOURCE_MANAGER` system package to configure resource isolation within a tenant. The maximum CPU resources available to each background task of the tenant are calculated based on the maximum CPU resources available for all background tasks of the tenant and are equal to `min(global_background_cpu_quota, MAX_CPU of the tenant) × UTILIZATION_LIMIT within the resource group`.
+
+### Enable global CPU resource isolation for foreground and background tasks
+
+In OceanBase Database, global CPU resource isolation for foreground and background tasks is controlled by the following two parameters:
+
+* `enable_global_background_resource_isolation`
+
+ This parameter specifies whether to enable global CPU resource isolation for foreground and background tasks. It is a cluster-level parameter. The default value is `False`, which specifies to disable global CPU resource isolation for foreground and background tasks. In this case, CPU resources for foreground and background tasks are isolated within a tenant. The setting takes effect only after you restart the OBServer node.
+
+ The value `True` specifies to enable global CPU resource isolation for foreground and background tasks. In this case, CPU resources for background tasks are limited independently of tenants.
+
+ For more information about the `enable_global_background_resource_isolation` parameter, see [enable_global_background_resource_isolation](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001719949).
+
+* `global_background_cpu_quota`
+
+ This parameter specifies the CPU quota available for background tasks. It is a cluster-level parameter. The default value is `-1`, which specifies that the CPU resources available for background tasks are not limited by the cgroup.
+
+ For more information about the `global_background_cpu_quota` parameter, see [global_background_cpu_quota](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001719950).
+
+To enable global CPU resource isolation for foreground and background tasks, perform the following steps:
+
+1. Log in to the `sys` tenant of the cluster as the `root` user.
+
+2. Execute the following statement to enable global CPU resource isolation for foreground and background tasks:
+
+ ```shell
+ obclient> ALTER SYSTEM SET enable_global_background_resource_isolation = True;
+ ```
+
+3. Specify the CPU quota available for background tasks based on your business needs.
+
+ The value must be less than the CPU quota available for the current OBServer node.
+
+ ```shell
+ obclient> ALTER SYSTEM SET global_background_cpu_quota = 3;
+ ```
+
+4. Restart the OBServer node for the setting to take effect.
+
+ After the setting takes effect, the system creates a `background` directory at the same level as all tenants in the original cgroup directory structure. The `background` directory acts as a cgroup directory for background tasks. The system also creates cgroup directories corresponding to all tenants in the `background` directory.
+
+### What to do next
+
+Global CPU resource isolation for foreground and background tasks limits the CPU resources for background tasks from a global perspective. If you expect finer-grained resource isolation for background tasks, you can use the `DBMS_RESOURCE_MANAGER` system package to configure resource isolation within a tenant.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/03_disk_performance_calibration.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/03_disk_performance_calibration.md
new file mode 100644
index 000000000..438855d3c
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/03_disk_performance_calibration.md
@@ -0,0 +1,300 @@
+---
+title: Prepare for IOPS Resource Isolation
+weight: 3
+---
+## Calibrate the Disk Performance
+
+Before you perform IOPS resource isolation, you must calibrate the disk performance. If IOPS resource isolation is not required, skip this step.
+
+### Calculate the baseline IOPS value
+
+Disk performance calibration is mainly about calibrating the IOPS value of the disk. The formula for calculating the baseline IOPS value is as follows:
+
+`Baseline IOPS value = Min(Maximum IOPS value supported by the disk, (Target bandwidth/Amount of data involved in I/O operations))`
+
+You must consider the following aspects when you determine the target bandwidth:
+
+* Specifications of the server, specifically, the bandwidth limit of the disk
+
+* Sensitivity requirements on the response time (RT)
+
+* Bandwidth used by the I/O manager, which must be excluded
+
+* 10 to 20 MB/s of bandwidth reserved for clogs
+
+The baseline IOPS value for 16 KB reads on the disk is calculated as follows: Assume that the bandwidth limit of the disk is 600 MB/s, the IOPS is 30,000, and your business is highly sensitive to the RT. The probability of jitters will significantly increase if the entire bandwidth is used. Therefore, 400 MB/s is taken as the target bandwidth considering other factors such as the bandwidth reserved for clogs. The maximum IOPS allowed for 16 KB reads with a bandwidth of 400 MB/s is `(400 × 1024 KB)/16 KB = 25600`. Therefore, you can calibrate the IOPS value to 25600. If the calculated IOPS value reaches or exceeds the IOPS limit of the disk, such as 10000, you can calibrate the IOPS value to 10000.
+
+### Calibration methods
+
+OceanBase Database provides the disk performance calibration feature for you to calibrate the read/write performance of the disk where an OBServer node resides. At present, OceanBase Database supports two disk performance calibration modes:
+
+* Automatic calibration: A background automatic calibration job is triggered by the `ALTER SYSTEM RUN JOB` statement.
+
+* Manual calibration: You can refresh the disk performance information for manual calibration.
+
+### Automatic calibration
+
+If the current OceanBase cluster runs with zero load and the data disk has much idle space, you can execute the `ALTER SYSTEM RUN JOB` statement to trigger a background job to automatically calibrate the disk performance. In this mode, the system automatically calibrates the data disk.
+
+1. Log in to the `sys` tenant of the cluster as the `root` user.
+
+ Note that you must specify the corresponding parameters in the following sample code based on your actual database configurations.
+
+ ```shell
+ obclient -h10.xx.xx.xx -P2883 -uroot@sys#obdemo -p***** -A
+ ```
+
+2. Trigger a disk calibration job by using an appropriate statement based on business scenarios.
+
+ * Trigger a disk calibration job for all OBServer nodes in a cluster
+
+ The syntax is as follows:
+
+ ```sql
+ ALTER SYSTEM RUN JOB "job_name";
+ ```
+
+ In the statement, `job_name` specifies the name of the background job. To trigger a background disk calibration job, specify `io_calibration`.
+
+ Here is an example:
+
+ ```sql
+ ALTER SYSTEM RUN JOB "io_calibration";
+ ```
+
+ * Trigger a disk calibration job for all OBServer nodes in a specified zone
+
+ The syntax is as follows:
+
+ ```sql
+ ALTER SYSTEM RUN JOB "job_name" ZONE [=] zone_name;
+ ```
+
+ The parameters are described as follows:
+
+ * `job_name`: the name of the background job. To trigger a background disk calibration job, specify `io_calibration`.
+ * `zone_name`: the name of the zone for which the disk calibration job is to be triggered. At present, you can specify only one zone.
+
+ Here is an example:
+
+ ```sql
+ ALTER SYSTEM RUN JOB "io_calibration" ZONE = zone1;
+ ```
+
+ * Trigger a disk calibration job for a specified OBServer node
+
+ The syntax is as follows:
+
+ ```sql
+ ALTER SYSTEM RUN JOB "job_name" SERVER [=] 'svr_ip:svr_port';
+ ```
+
+ The parameters are described as follows:
+
+ * `job_name`: the name of the background job. To trigger a background disk calibration job, specify `io_calibration`.
+ * `svr_ip`: the IP address of the OBServer node for which the disk calibration job is to be triggered. At present, you can specify only one OBServer node.
+ * `svr_port`: the remote procedure call (RPC) port of the OBServer node for which the disk calibration job is to be triggered.
+
+ Here is an example:
+
+ ```sql
+ ALTER SYSTEM RUN JOB "io_calibration" SERVER = 'xx.xx.xx.1:2882';
+ ```
+
+3. Query the disk I/O calibration status.
+
+ After you trigger a disk calibration job, you can query the `GV$OB_IO_CALIBRATION_STATUS` or `V$OB_IO_CALIBRATION_STATUS` view for the I/O calibration status.
+
+ ```sql
+ SELECT * FROM oceanbase.V$OB_IO_CALIBRATION_STATUS;
+ ```
+
+ The query result is as follows:
+
+ ```shell
+ +----------------+----------+--------------+-------------+----------------------------+-------------+
+ | SVR_IP | SVR_PORT | STORAGE_NAME | STATUS | START_TIME | FINISH_TIME |
+ +----------------+----------+--------------+-------------+----------------------------+-------------+
+ | xx.xx.xx.197 | 2882 | DATA | IN PROGRESS | 2023-06-27 14:30:38.393482 | NULL |
+ +----------------+----------+--------------+-------------+----------------------------+-------------+
+ 1 row in set
+ ```
+
+ Possible I/O calibration states include the following ones:
+
+ * `NOT AVAILABLE`: I/O calibration is not started.
+ * `IN PROGRESS`: I/O calibration is in progress.
+ * `READY`: I/O calibration is completed.
+ * `FAILED`: I/O calibration failed.
+
+ In the sample query result, the value of the `STATUS` column is `IN PROGRESS`, indicating that disk I/O calibration is in progress. After the disk I/O calibration is completed, the value of the `STATUS` column changes to `READY`, and the completion time is displayed in the `FINISH_TIME` column.
+
+ ```shell
+ +----------------+----------+--------------+--------+----------------------------+----------------------------+
+ | SVR_IP | SVR_PORT | STORAGE_NAME | STATUS | START_TIME | FINISH_TIME |
+ +----------------+----------+--------------+--------+----------------------------+----------------------------+
+ | xx.xx.xx.197 | 2882 | DATA | READY | 2023-06-27 14:25:20.202022 | 2023-06-27 14:27:00.398748 |
+ +----------------+----------+--------------+--------+----------------------------+----------------------------+
+ 1 row in set
+ ```
+
+4. Verify whether the disk I/O calibration takes effect.
+
+ After the disk I/O calibration is completed, you can query the `GV$OB_IO_BENCHMARK` or `V$OB_IO_BENCHMARK` view to check whether the calibration takes effect.
+
+ ```sql
+ SELECT * FROM oceanbase.GV$OB_IO_BENCHMARK;
+ ```
+
+ A sample query result is as follows:
+
+ ```shell
+ +----------------+----------+--------------+-------+---------+--------+------+---------+
+ | SVR_IP | SVR_PORT | STORAGE_NAME | MODE | SIZE | IOPS | MBPS | LATENCY |
+ +----------------+----------+--------------+-------+---------+--------+------+---------+
+ | xx.xx.xx.197 | 2882 | DATA | READ | 4096 | 124648 | 486 | 128 |
+ | xx.xx.xx.197 | 2882 | DATA | READ | 8192 | 118546 | 926 | 134 |
+ | xx.xx.xx.197 | 2882 | DATA | READ | 16384 | 98870 | 1544 | 161 |
+ | xx.xx.xx.197 | 2882 | DATA | READ | 32768 | 73857 | 2308 | 216 |
+ | xx.xx.xx.197 | 2882 | DATA | READ | 65536 | 48015 | 3000 | 332 |
+ | xx.xx.xx.197 | 2882 | DATA | READ | 131072 | 33780 | 4222 | 473 |
+ | xx.xx.xx.197 | 2882 | DATA | READ | 262144 | 20650 | 5162 | 774 |
+ | xx.xx.xx.197 | 2882 | DATA | READ | 524288 | 12111 | 6055 | 1321 |
+ | xx.xx.xx.197 | 2882 | DATA | READ | 1048576 | 6237 | 6237 | 2565 |
+ | xx.xx.xx.197 | 2882 | DATA | READ | 2097152 | 2762 | 5524 | 5795 |
+ | xx.xx.xx.197 | 2882 | DATA | WRITE | 4096 | 49771 | 194 | 321 |
+ | xx.xx.xx.197 | 2882 | DATA | WRITE | 8192 | 48566 | 379 | 329 |
+ | xx.xx.xx.197 | 2882 | DATA | WRITE | 16384 | 42784 | 668 | 373 |
+ | xx.xx.xx.197 | 2882 | DATA | WRITE | 32768 | 35187 | 1099 | 454 |
+ | xx.xx.xx.197 | 2882 | DATA | WRITE | 65536 | 24892 | 1555 | 642 |
+ | xx.xx.xx.197 | 2882 | DATA | WRITE | 131072 | 12720 | 1590 | 1257 |
+ | xx.xx.xx.197 | 2882 | DATA | WRITE | 262144 | 6889 | 1722 | 2322 |
+ | xx.xx.xx.197 | 2882 | DATA | WRITE | 524288 | 3452 | 1726 | 4636 |
+ | xx.xx.xx.197 | 2882 | DATA | WRITE | 1048576 | 1689 | 1689 | 9481 |
+ | xx.xx.xx.197 | 2882 | DATA | WRITE | 2097152 | 876 | 1752 | 18296 |
+ +----------------+----------+--------------+-------+---------+--------+------+---------+
+ 20 rows in set
+ ```
+
+ The columns in the query result are described as follows:
+
+ * `STORAGE_NAME`: the name of the storage disk. `DATA` indicates a data disk.
+ * `MODE`: the I/O mode, which can be read or write.
+ * `SIZE`: the size of each I/O request, in bytes.
+ * `IOPS`: the number of I/O requests completed per second.
+ * `MBPS`: the disk bandwidth, in MB/s.
+ * `LATENCY`: the RT of the disk, in microseconds.
+
+### Manual calibration
+
+If the current OceanBase cluster runs at a load, you can actively refresh the disk performance information to manually calibrate the disk performance.
+
+1. Log in to the `sys` tenant of the cluster as the `root` user.
+
+ Note that you must specify the corresponding parameters in the following sample code based on your actual database configurations.
+
+ ```shell
+ obclient -h10.xx.xx.xx -P2883 -uroot@sys#obdemo -p***** -A
+ ```
+
+2. Actively refresh the disk performance information by using an appropriate statement based on business scenarios.
+
+ * Refresh the disk performance information for all OBServer nodes in the cluster
+
+ ```sql
+ ALTER SYSTEM REFRESH IO CALIBRATION [STORAGE [=] 'storage_name'] [CALIBRATION_INFO [=] ("mode : size : latency : iops" [, "mode : size : latency : iops"])];
+ ```
+
+ * Clear the disk performance information of all OBServer nodes in the cluster
+
+ ```sql
+ ALTER SYSTEM REFRESH IO CALIBRATION [STORAGE [=] 'storage_name'] CALIBRATION_INFO = ("");
+ ```
+
+ * Refresh the disk performance information for all OBServer nodes in a specified zone
+
+ ```sql
+ ALTER SYSTEM REFRESH IO CALIBRATION [STORAGE [=] 'storage_name'] [CALIBRATION_INFO [=] ("mode : size : latency : iops "[, "mode : size : latency : iops"])] ZONE [=] zone_name;
+ ```
+
+ * Refresh the disk performance information for a specified OBServer node
+
+ ```sql
+ ALTER SYSTEM REFRESH IO CALIBRATION [STORAGE [=] 'storage_name'] [CALIBRATION_INFO [=] ("mode : size : latency : iops" [, "mode : size : latency : iops"])] SERVER [=] 'svr_ip:svr_port';
+ ```
+
+ The parameters are described as follows:
+
+ * `STORAGE`: the name of the storage disk of OceanBase Database. At present, the value can be only `DATA`, which indicates a data disk.
+
+ * `CALIBRATION_INFO`: the disk performance information to be refreshed. If you do not specify this parameter, the disk performance information is refreshed from the internal table by default. When you set `CALIBRATION_INFO`, you must specify at least one record for both the read and write modes. Otherwise, the system returns an error.
+
+
+ Note
+ When you specify disk performance information, if no stress testing data of the current disk is available, you can use the flexible I/O (FIO) tester to perform a performance stress test to obtain performance data of the current disk. For more information about the FIO tester, visit its official website.
+
+
+ * `mode`: the I/O mode. Valid values are `r`, `w`, `read`, and `write`.
+ * `size`: the size of a single I/O request. The value must be followed by a unit, such as 4K. Supported units are KB (K), MB (M), and GB (G).
+ * `latency`: the RT of the disk. If a numeric value is specified, the default unit is seconds. We recommend that you specify a unit together with a value and do not use the default unit. Supported units are us, ms, s, min, and h.
+ * `iops`: the number of I/O requests processed per second.
+
+ * `zone_name`: the zone for which the disk performance information is to be refreshed. At present, you can specify only one zone.
+ * `svr_ip`: the IP address of the OBServer node for which the disk performance information is to be refreshed.
+ * `svr_port`: the RPC port of the OBServer node for which the disk performance information is to be refreshed.
+
+ Here is an example:
+
+ * Refresh the disk performance information for the data disks of all OBServer nodes in the cluster from the internal table
+
+ ```sql
+ ALTER SYSTEM REFRESH IO CALIBRATION;
+ ```
+
+ * Clear the disk performance information of data disks of all OBServer nodes in the cluster
+
+ ```sql
+ ALTER SYSTEM REFRESH IO CALIBRATION CALIBRATION_INFO = ("");
+ ```
+
+ * Refresh the disk performance information for the data disks of all OBServer nodes in `zone1`
+
+ ```sql
+ ALTER SYSTEM REFRESH IO CALIBRATION STORAGE = 'DATA' CALIBRATION_INFO = ("read:4K:100us:200000","write:2M:5ms:1500") ZONE = zone1;
+ ```
+
+ In this example, the refreshed disk performance information is as follows: The RT of random reads of 4 KB data is 100 μs with an IOPS value of 200000. The RT of random writes of 2 MB data is 5 ms with an IOPS value of 1500.
+
+ * Refresh the disk performance information for the data disk of a specified OBServer node
+
+ ```sql
+ ALTER SYSTEM REFRESH IO CALIBRATION STORAGE = 'DATA' CALIBRATION_INFO = ("read:4K:100us:200000","write:2M:5ms:1500") SERVER = 'xx.xx.xx.1:2882';
+ ```
+
+3. Verify whether the disk I/O calibration takes effect.
+
+ After the disk performance information is refreshed, you can query the `GV$OB_IO_BENCHMARK` or `V$OB_IO_BENCHMARK` view to confirm whether the disk I/O calibration takes effect.
+
+ ```sql
+ SELECT * FROM oceanbase.GV$OB_IO_BENCHMARK;
+ ```
+
+ A sample query result is as follows:
+
+ ```shell
+ +----------------+----------+--------------+-------+---------+--------+------+---------+
+ | SVR_IP | SVR_PORT | STORAGE_NAME | MODE | SIZE | IOPS | MBPS | LATENCY |
+ +----------------+----------+--------------+-------+---------+--------+------+---------+
+ | xx.xx.xx.197 | 2882 | DATA | READ | 4096 | 200000 | 781 | 100 |
+ +----------------+----------+--------------+-------+---------+--------+------+---------+
+ 1 rows in set
+ ```
+
+ The columns in the query result are described as follows:
+
+ * `STORAGE_NAME`: the name of the storage disk. `DATA` indicates a data disk.
+ * `MODE`: the I/O mode, which can be read or write.
+ * `SIZE`: the size of each I/O request, in bytes.
+ * `IOPS`: the number of I/O requests completed per second.
+ * `MBPS`: the disk bandwidth, in MB/s.
+ * `LATENCY`: the RT of the disk, in microseconds.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/04_dbms_resource_manager.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/04_dbms_resource_manager.md
new file mode 100644
index 000000000..0206e85f2
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/04_dbms_resource_manager.md
@@ -0,0 +1,418 @@
+---
+title: Configure Resource Isolation Within a Tenant
+weight: 4
+---
+
+This topic describes how to configure resource isolation within a MySQL tenant.
+
+## Prerequisites
+
+* You have familiarized yourself with the "Overview" topic under "Resource Isolation Within a Tenant".
+* You have configured the control group (cgroup) directory and enabled the cgroup feature, if you need to implement isolation of CPU resources, which relies on cgroups. For more information, see the "Prepare for CPU Resource Isolation" topic.
+
+ When you configure user-level or function-level resource isolation, you do not need to configure cgroups if CPU resource isolation is not required. When you configure SQL statement-level resource isolation, you must configure cgroups regardless of whether CPU resource isolation is required.
+
+* You have calibrated the disk performance before you implement IOPS resource isolation. For more information, see the "Prepare for IOPS Resource Isolation" topic.
+
+ If you need to implement only CPU resource isolation, you do not need to calibrate the disk performance.
+
+* You have created a user for which resource isolation is to be implemented.
+
+* You have created the database, table, and column for which resource isolation is to be implemented, if you need to implement SQL statement-level resource isolation.
+
+## (Optional) Step 1: Specify Valid Values for the MAX_IOPS and MIN_IOPS Parameters of the Tenant
+
+Note: If you have set MAX_IOPS and MIN_IOPS to the baseline IOPS value for 16 KB reads when you create the unit config for the tenant, or if IOPS resource isolation is not required, skip this step.
+
+Before you configure a resource isolation plan after disk calibration, make sure that the MAX_IOPS and MIN_IOPS parameters in the unit config of the tenant are set to valid values that are not greater than the baseline IOPS value for 16 KB reads.
+
+1. Log in to the `sys` tenant of the cluster as the `root` user.
+
+2. Execute the following statement to query the unit config of the tenant for which resource isolation is to be implemented:
+
+ ```sql
+ obclient [oceanbase]> SELECT * FROM oceanbase.DBA_OB_UNIT_CONFIGS;
+ ```
+
+ A sample query result is as follows:
+
+ ```shell
+ +----------------+-----------------+----------------------------+----------------------------+---------+---------+-------------+---------------+---------------------+---------------------+-------------+
+ | UNIT_CONFIG_ID | NAME | CREATE_TIME | MODIFY_TIME | MAX_CPU | MIN_CPU | MEMORY_SIZE | LOG_DISK_SIZE | MAX_IOPS | MIN_IOPS | IOPS_WEIGHT |
+ +----------------+-----------------+----------------------------+----------------------------+---------+---------+-------------+---------------+---------------------+---------------------+-------------+
+ | 1 | sys_unit_config | 2023-12-19 13:55:04.463295 | 2023-12-19 13:56:08.969718 | 3 | 3 | 2147483648 | 3221225472 | 9223372036854775807 | 9223372036854775807 | 3 |
+ | 1001 | small_unit | 2023-12-19 13:56:09.851665 | 2023-12-19 13:56:09.851665 | 1 | 1 | 2147483648 | 6442450944 | 9223372036854775807 | 9223372036854775807 | 1 |
+ | 1002 | medium_unit | 2023-12-19 13:56:10.030914 | 2023-12-19 13:56:10.030914 | 8 | 4 | 8589934592 | 25769803776 | 9223372036854775807 | 9223372036854775807 | 4 |
+ | 1003 | large_unit | 2023-12-19 13:56:10.112115 | 2023-12-19 13:56:10.112115 | 16 | 8 | 21474836480 | 64424509440 | 9223372036854775807 | 9223372036854775807 | 8 |
+ +----------------+-----------------+----------------------------+----------------------------+---------+---------+-------------+---------------+---------------------+---------------------+-------------+
+ 4 rows in set
+ ```
+
+ If the default value `INT64_MAX` (which is `9223372036854775807`) is used for the `MAX_IOPS` and `MIN_IOPS` parameters of the tenant, you must replan the IOPS resources for the tenant.
+
+3. Execute the following statement to query the OBServer nodes on which the tenant is deployed:
+
+ ```sql
+ obclient [oceanbase]> SELECT DISTINCT SVR_IP, SVR_PORT FROM oceanbase.CDB_OB_LS_LOCATIONS WHERE tenant_id = xxxx;
+ ```
+
+ A sample query result is as follows:
+
+ ```shell
+ +----------------+----------+
+ | SVR_IP | SVR_PORT |
+ +----------------+----------+
+ | xx.xxx.xxx.xx1 | xxxx1 |
+ | xx.xxx.xxx.xx1 | xxxx2 |
+ | xx.xxx.xxx.xx1 | xxxx3 |
+ +----------------+----------+
+ 3 rows in set
+ ```
+
+4. Execute the following statement to query the baseline IOPS value of the disk on each OBServer node where the tenant is deployed. If the queried baseline IOPS value is less than the baseline IOPS value for 16 KB reads, set the queried baseline IOPS value as the upper IOPS limit of the node; otherwise, set the baseline IOPS value for 16 KB reads as the upper IOPS limit of the node.
+
+ ```sql
+ obclient [oceanbase]> SELECT * FROM oceanbase.GV$OB_IO_BENCHMARK WHERE MODE='READ' AND SIZE=16384;
+ ```
+
+ A sample query result is as follows:
+
+ ```shell
+ +----------------+----------+--------------+------+-------+-------+------+---------+
+ | SVR_IP | SVR_PORT | STORAGE_NAME | MODE | SIZE | IOPS | MBPS | LATENCY |
+ +----------------+----------+--------------+------+-------+-------+------+---------+
+ | xx.xxx.xxx.xx1 | xxxx1 | DATA | READ | 16384 | 48162 | 752 | 331 |
+ | xx.xxx.xxx.xx1 | xxxx2 | DATA | READ | 16384 | 47485 | 741 | 336 |
+ | xx.xxx.xxx.xx1 | xxxx3 | DATA | READ | 16384 | 48235 | 753 | 331 |
+ +----------------+----------+--------------+------+-------+-------+------+---------+
+ 3 rows in set
+ ```
+
+ Plan the IOPS resources available for the tenant by using the queried disk calibration value of each node as the upper IOPS limit. Multiple tenants in a cluster may be deployed on the same OBServer nodes. You can allocate the IOPS resources based on the actual situation.
+
+ Assume that a cluster has two tenants deployed on the same OBServer nodes, the baseline IOPS value for 16 KB reads is 20000 on each OBServer node, and the loads of the two tenants are similar. You can evenly distribute the IOPS resources to the two tenants based on the actual situation. Specifically, you can set the `MAX_IOPS` and `MIN_IOPS` parameters to 10000 for both tenants. You can also set `MIN_IOPS` to a value smaller than that of `MAX_IOPS` based on your business needs.
+
+5. Execute the following statements to modify the values of `MAX_IOPS` and `MIN_IOPS`.
+
+ We recommend that you modify the value of `MIN_IOPS` first and then that of `MAX_IOPS`.
+
+ ```sql
+ ALTER RESOURCE UNIT unit_name MIN_IOPS = xxx;
+ ```
+
+ ```sql
+ ALTER RESOURCE UNIT unit_name MAX_IOPS = xxx;
+ ```
+
+## Step 2: Configure a Resource Isolation Plan
+
+Assume that the current tenant contains two users: `tp_user` and `ap_user`.
+
+You can configure a resource isolation plan to control the CPU and IOPS resources available for different users or background tasks.
+
+1. Log in to a MySQL tenant of the cluster as the administrator of the tenant.
+
+2. Call the `CREATE_CONSUMER_GROUP` subprogram in the `DBMS_RESOURCE_MANAGER` package to create a resource group.
+
+ The syntax is as follows:
+
+ ```sql
+ CALL DBMS_RESOURCE_MANAGER.CREATE_CONSUMER_GROUP(
+ CONSUMER_GROUP => 'group_name' ,
+ COMMENT => 'comments'
+ );
+ ```
+
+ The parameters are described as follows:
+
+ * `CONSUMER_GROUP`: the name of the resource group.
+
+ * `COMMENT`: the comments on the resource group.
+
+ For example, create two resource groups respectively named `interactive_group` and `batch_group`.
+
+ ```shell
+ obclient [test]> CALL DBMS_RESOURCE_MANAGER.CREATE_CONSUMER_GROUP(
+ CONSUMER_GROUP => 'interactive_group' ,
+ COMMENT => 'TP'
+ );
+ ```
+
+ ```shell
+ obclient [test]> CALL DBMS_RESOURCE_MANAGER.CREATE_CONSUMER_GROUP(
+ CONSUMER_GROUP => 'batch_group' ,
+ COMMENT => 'AP'
+ );
+ ```
+
+ You can query the `oceanbase.DBA_RSRC_CONSUMER_GROUPS` view to verify whether the resource groups are created. For more information about the `oceanbase.DBA_RSRC_CONSUMER_GROUPS` view, see [oceanbase.DBA_RSRC_CONSUMER_GROUPS](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001785827).
+
+3. Call the `CREATE_PLAN` subprogram in the `DBMS_RESOURCE_MANAGER` package to create a resource management plan.
+
+ The syntax is as follows:
+
+ ```sql
+ CALL DBMS_RESOURCE_MANAGER.CREATE_PLAN(
+ PLAN => 'plan_name',
+ comment => 'comments');
+ ```
+
+ The parameters are described as follows:
+
+ * `PLAN`: the name of the resource management plan.
+
+ * `COMMENT`: the comments on the resource management plan.
+
+ For example, create a resource management plan named `daytime` and add comments.
+
+ ```sql
+ obclient [test]> CALL DBMS_RESOURCE_MANAGER.CREATE_PLAN(
+ PLAN => 'daytime',
+ comment => 'TPFirst');
+ ```
+
+ You can query the `oceanbase.DBA_RSRC_PLANS` view to verify whether the resource management plan is created. For more information about the `oceanbase.DBA_RSRC_PLANS` view, see [oceanbase.DBA_RSRC_PLANS](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001785831).
+
+4. Call the `CREATE_PLAN_DIRECTIVE` subprogram in the `DBMS_RESOURCE_MANAGER` package to create a plan directive, which is used to limit the CPU and IOPS resources available for the resource group when the resource management plan is enabled. The syntax is as follows:
+
+ ```sql
+ CALL DBMS_RESOURCE_MANAGER.CREATE_PLAN_DIRECTIVE (
+ PLAN => 'plan_name',
+ GROUP_OR_SUBPLAN => 'group_name' ,
+ COMMENT => 'comments',
+ MGMT_P1 => int_value,
+ UTILIZATION_LIMIT => int_value,
+ MIN_IOPS => int_value,
+ MAX_IOPS => int_value,
+ WEIGHT_IOPS => int_value);
+ ```
+
+ Call the `UPDATE_PLAN_DIRECTIVE` subprogram in the `DBMS_RESOURCE_MANAGER` package to update the plan directive. Here is an example:
+
+ ```sql
+ obclient [test]> CALL DBMS_RESOURCE_MANAGER.UPDATE_PLAN_DIRECTIVE(
+ PLAN => 'daytime',
+ GROUP_OR_SUBPLAN => 'interactive_group' ,
+ COMMENT => 'new',
+ MGMT_P1 => 40,
+ UTILIZATION_LIMIT => 60);
+ MIN_IOPS => 40,
+ MAX_IOPS => 80,
+ WEIGHT_IOPS => 70);
+ ```
+
+ The parameters are described as follows:
+
+ * `PLAN`: the name of the resource management plan.
+
+ * `GROUP_OR_SUBPLAN`: the resource group.
+
+ * `COMMENT`: the comments on the plan directive. The default value is `NULL`.
+
+ * `MGMT_P1`: the maximum percentage of CPU resources available when the system runs at full load. The default value is `100`.
+
+ * `UTILIZATION_LIMIT`: the upper limit on the CPU resources available for the resource group. The default value is `100`. The value range is (0, 100\]. The value `100` indicates that all CPU resources of the tenant are available for the resource group. The value `70` indicates that at most 70% of the CPU resources of the tenant are available for the resource group.
+
+ * `MIN_IOPS`: the IOPS resources reserved for the resource group in the case of I/O resource contention. The sum of `MIN_IOPS` values of all resource groups cannot exceed 100. The default value is `0`.
+
+ * `MAX_IOPS`: the maximum IOPS resources available for the resource group. The sum of `MAX_IOPS` values of all resource groups can exceed 100. The default value is `100`.
+
+ * `WEIGHT_IOPS`: the weight for IOPS resources. The sum of `WEIGHT_IOPS` values of all resource groups can exceed 100. The default value is `0`.
+
+ Here is an example:
+
+ * Create a plan directive as follows: Set the resource plan to `daytime`, the resource group to `interactive_group`, and the maximum CPU resources available to 80% of the total CPU resources of the tenant. Set the minimum IOPS resources available upon I/O contention to 30% of the total IOPS resources, the maximum IOPS resources available to 90% of the total IOPS resources, and the weight of IOPS resources to 80.
+
+ ```shell
+ obclient [test]> CALL DBMS_RESOURCE_MANAGER.CREATE_PLAN_DIRECTIVE(
+ PLAN => 'daytime',
+ GROUP_OR_SUBPLAN => 'interactive_group' ,
+ COMMENT => '',
+ UTILIZATION_LIMIT =>80,
+ MIN_IOPS => 30,
+ MAX_IOPS => 90,
+ WEIGHT_IOPS => 80);
+ ```
+
+ * Create a plan directive as follows: Set the resource plan to `daytime`, the resource group to `batch_group`, and the maximum CPU resources available to 40% of the total CPU resources of the tenant. Set the minimum IOPS resources available upon I/O contention to 40% of the total IOPS resources, the maximum IOPS resources available to 80% of the total IOPS resources, and the weight of IOPS resources to 70.
+
+ ```shell
+ obclient [test]> CALL DBMS_RESOURCE_MANAGER.CREATE_PLAN_DIRECTIVE(
+ PLAN => 'daytime',
+ GROUP_OR_SUBPLAN => 'batch_group' ,
+ COMMENT => '',
+ UTILIZATION_LIMIT => 40,
+ MIN_IOPS => 40,
+ MAX_IOPS => 80,
+ WEIGHT_IOPS => 70);
+ ```
+
+ You can query the `oceanbase.DBA_RSRC_PLAN_DIRECTIVES` and `oceanbase.DBA_OB_RSRC_IO_DIRECTIVES` views to verify whether the plan directives are created.
+
+ For more information about the `oceanbase.DBA_RSRC_PLAN_DIRECTIVES` view, see [oceanbase.DBA_RSRC_PLAN_DIRECTIVES](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001785829).
+
+ For more information about the `oceanbase.DBA_OB_RSRC_IO_DIRECTIVES` view, see [oceanbase.DBA_OB_RSRC_IO_DIRECTIVES](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001785796).
+
+5. Call the `SET_CONSUMER_GROUP_MAPPING` subprogram in the `DBMS_RESOURCE_MANAGER` package to create a matching rule for resource isolation based on your business scenario.
+
+ The syntax is as follows:
+
+ ```sql
+ CALL DBMS_RESOURCE_MANAGER.SET_CONSUMER_GROUP_MAPPING(
+ ATTRIBUTE => 'column | user | function',
+ VALUE => 'values',
+ CONSUMER_GROUP => 'group_name');
+ ```
+
+ The parameters are described as follows:
+
+ * `ATTRIBUTE`: the attribute type. The attribute name is case-insensitive.
+
+ * The value `column` indicates SQL statement-level resource isolation.
+
+ * The value `user` indicates user-level resource isolation.
+
+ * The value `function` indicates function-level resource isolation.
+
+ * `VALUE`: the attribute value.
+
+ * If the attribute type is `column`, specify the database name, table name, column name, constant value, and username.
+
+ Specifically:
+
+ * The database name and username are optional. The default database name is the name of the current database. If no username is specified, the settings take effect for all users, including those created later in the current tenant.
+
+ * The table name, column name, and constant value are required, and each of them can have only one value. The constant value must be a number or string.
+
+ * When you specify the table name, column name, and username, the specified table, column, and user must exist.
+
+ * If the attribute type is `user`, specify the username. At present, you can specify only one username.
+
+ * If the attribute type is `function`, specify a background task corresponding to the directed acyclic graph (DAG) thread. Eight types of background tasks are supported: `compaction_high`, `ha_high`, `compaction_mid`, `ha_mid`, `compaction_low`, `ha_low`, `ddl`, and `ddl_high`. At present, you can specify only one task.
+
+ * `CONSUMER_GROUP`: the resource group to bind. When an SQL statement hits the matching rule specified by the `VALUE` parameter, this statement is bound to the specified resource group for execution. At present, an SQL statement can be bound only to one resource group.
+
+ If no resource group is specified, the built-in resource group `OTHER_GROUPS` is bound by default. The resources of the built-in resource group `OTHER_GROUPS` are as follows:
+
+ * `MIN_IOPS` = 100 – SUM(Resources of other resource groups in the tenant)
+
+ * `MAX_IOPS` = 100
+
+ * `WEIGHT_IOPS` = 100
+
+ Here is an example:
+
+ * Create a matching rule for SQL statement-level resource isolation.
+
+ * Specify to bind an SQL statement that is initiated by the `tp_user` user and that has a `WHERE` clause containing `test.t.c3 = 3` to the `batch_group` resource group for execution by using the CPU and IOPS resources available for the resource group.
+
+
+ Notice
+ An SQL statement can be bound to the batch_group resource group provided that c3 is parsed into test.t.c3 but the statement does not necessarily need to contain test.t.. For example, the statement SELECT * FROM test.t WHERE c3 = 1; can be bound to the resource group.
+
+
+ ```shell
+ obclient [test]> CALL DBMS_RESOURCE_MANAGER.SET_CONSUMER_GROUP_MAPPING(
+ ATTRIBUTE => 'column',
+ VALUE => 'test.t.c3=3 for tp_user',
+ CONSUMER_GROUP => 'batch_group');
+ ```
+
+ * Specify to bind an SQL statement that has a `WHERE` clause containing `t.c3=5` to the `interactive_group` resource group for execution by using the CPU and IOPS resources available for the resource group.
+
+ ```shell
+ obclient [test]> CALL DBMS_RESOURCE_MANAGER.SET_CONSUMER_GROUP_MAPPING(
+ ATTRIBUTE => 'column',
+ VALUE => 't.c3=5',
+ CONSUMER_GROUP => 'interactive_group');
+ ```
+
+ You can also use a hint to bind an SQL statement to a resource group without calling the `SET_CONSUMER_GROUP_MAPPING` subprogram. For example, if you want the `SELECT * FROM T` statement to use resources available for the `batch_group` resource group during execution, you can use a hint to bind the statement to the resource group.
+
+ ```shell
+ obclient [test]> SELECT /*+resource_group('batch_group')*/ * FROM t;
+ ```
+
+
+ Note
+ If the resource group specified by the hint does not exist, the default resource group OTHER_GROUPS is used.
+
+
+ * Create a matching rule for user-level resource isolation.
+
+ * Specify to bind SQL statements initiated by the `tp_user` user to the `interactive_group` resource group for execution by using the CPU and IOPS resources available for the resource group.
+
+ ```shell
+ obclient [test]> CALL DBMS_RESOURCE_MANAGER.SET_CONSUMER_GROUP_MAPPING(
+ ATTRIBUTE => 'user',
+ VALUE => 'tp_user',
+ CONSUMER_GROUP => 'interactive_group');
+ ```
+
+ * Specify to bind SQL statements initiated by the `ap_user` user to the `batch_group` resource group for execution by using the CPU and IOPS resources available for the resource group.
+
+ ```shell
+ obclient [test]> CALL DBMS_RESOURCE_MANAGER.SET_CONSUMER_GROUP_MAPPING(
+ ATTRIBUTE => 'user',
+ VALUE => 'ap_user',
+ CONSUMER_GROUP => 'batch_group');
+ ```
+
+ * Create a matching rule for function-level resource isolation.
+
+ * Specify to bind `compaction_high` tasks to the `interactive_group` resource group for execution by using the CPU and IOPS resources available for the resource group.
+
+ ```shell
+ obclient [test]> CALL DBMS_RESOURCE_MANAGER.SET_CONSUMER_GROUP_MAPPING(
+ ATTRIBUTE => 'function',
+ VALUE => 'compaction_high',
+ CONSUMER_GROUP => 'interactive_group');
+ ```
+
+ * Specify to bind `ddl_high` tasks to the `batch_group` resource group for execution by using the CPU and IOPS resources available for the resource group.
+
+ ```shell
+ obclient [test]> CALL DBMS_RESOURCE_MANAGER.SET_CONSUMER_GROUP_MAPPING(
+ ATTRIBUTE => 'function',
+ VALUE => 'ddl_high',
+ CONSUMER_GROUP => 'batch_group');
+ ```
+
+ You can query the `oceanbase.DBA_RSRC_GROUP_MAPPINGS` view to verify whether the matching rule is created. For more information about the `oceanbase.DBA_RSRC_GROUP_MAPPINGS` view, see [oceanbase.DBA_RSRC_GROUP_MAPPINGS](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001785828).
+
+6. Enable a proper resource management plan for a resource group.
+
+ The resources available for a resource group vary based on the resource management plan. Therefore, you must enable a proper resource management plan for a resource group.
+
+ ```sql
+ obclient [test]> SET GLOBAL resource_manager_plan = 'daytime';
+ ```
+
+
+ Note
+ If resource usage does not need to be limited, you can execute the SET GLOBAL resource_manager_plan = ''; statement to disable all resource management plans.
+
+
+## Considerations
+
+* After a matching rule for user-level resource isolation is added, if you delete the user and create the user again, this matching rule still applies.
+
+* A matching rule for resource isolation does not take effect immediately after it is added, but is expected to take effect within 10 seconds. The time may vary based on the actual environment.
+
+* SQL statement-level resource isolation has a higher priority than user-level resource isolation and function-level resource isolation.
+
+* After a matching rule for resource isolation is added, it takes effect only in the `SELECT`, `INSERT`, `UPDATE`, and `DELETE` statements, and does not take effect in data definition language (DDL), data control language (DCL), or procedural language (PL) statements. It can take effect in prepared statements.
+
+## Impact on Performance
+
+* The system performance will not be affected after user-level resource isolation and function-level resource isolation are enabled. This is because the resource group used for executing an SQL statement is determined before the SQL statement is parsed.
+
+* The impact of SQL statement-level resource isolation on performance is caused by retries. In user-level and function-level resource isolation, the resource group used for executing an SQL statement is determined before the SQL statement is parsed. However, in SQL statement-level resource isolation, the resource group used for executing an SQL statement is determined when the SQL statement is parsed or hits the plan cache. If the system detects that the resource group being used is not the determined resource group, the system will perform a retry to use the resources in the resource group determined based on the matching rule to execute this SQL statement.
+
+ The impact of SQL statement-level resource isolation falls into three cases:
+
+ 1. If an SQL statement does not hit any matching rule, SQL statement-level resource isolation has no impact on the performance.
+
+ 2. If an SQL statement hits a matching rule that specifies to use the `batch_group` resource group, this SQL statement is executed by using resources in the `batch_group` resource group. The next SQL statement is also preferentially executed by using resources in this resource group. When the system detects that the matching rule hit by another SQL statement is bound to a different resource group, it will perform a retry to use resources in the new resource group to execute this statement. To continuously execute a batch of SQL statements that are bound to the same resource group, you can use this strategy so that the system needs to retry only the first SQL statement. This reduces the number of retries and causes slight impact on the performance.
+
+ 3. If the expected resource group of each SQL statement is different from that of the previous statement, the system must retry for each SQL statement. This greatly affects the performance.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation.md
new file mode 100644
index 000000000..f1cf9675b
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation.md
@@ -0,0 +1,85 @@
+---
+title: Resource Isolation Effects
+weight: 4
+---
+
+## CPU Isolation Effects
+
+We have noted that customers tend to run batch processing tasks during off-peak hours, such as midnight or early morning, when online transaction processing (OLTP) is unlikely affected by online analytical processing (OLAP), and most resources of a cluster can be allocated to OLAP with minimal resources reserved to support essential OLTP tasks. During peak hours in the daytime, the resource isolation plan can be adjusted to ensure sufficient resources for OLTP with minimal resources reserved to support essential OLAP tasks.
+
+**OceanBase Database allows you to set two plans for resource management in the daytime and at night. You can activate the plans as needed to ensure isolation and maximize resource utilization.**
+
+
+
+For example, the following syntax defines a daytime resource plan where OLTP (interactive_group) and OLAP (batch_group) are respectively allocated with 80% and 20% of the resources.
+
+```
+DBMS_RESOURCE_MANAGER.CREATE_PLAN(
+ PLAN => 'DAYTIME',
+ COMMENT => 'More resources for OLTP applications');
+
+DBMS_RESOURCE_MANAGER.CREATE_PLAN_DIRECTIVE (
+ PLAN => 'DAYTIME',
+ GROUP_OR_SUBPLAN => 'interactive_group',
+ COMMENT => 'OLTP group',
+ MGMT_P1 => 80,
+ UTILIZATION_LIMIT => 100);
+
+DBMS_RESOURCE_MANAGER.CREATE_PLAN_DIRECTIVE (
+ PLAN => 'DAYTIME',
+ GROUP_OR_SUBPLAN => 'batch_group',
+ COMMENT => 'OLAP group',
+ MGMT_P1 => 20,
+ UTILIZATION_LIMIT => 20);
+
+-- After the plan is ready, you can execute the following statement to activate it:
+ALTER SYSTEM SET RESOURCE_MANAGER_PLAN = 'DAYTIME';
+```
+Similarly, you can define a night resource plan and activate it during off-peak hours.
+
+OceanBase Database also supports user-based SQL categorization, which makes resource isolation more fine-grained, simple, and effective. You can create a user dedicated to executing analytical SQL queries, so that all SQL queries initiated by this user are processed as OLAP workloads. Furthermore, OceanBase Database identifies requests whose execution time exceeds the specified value, such as 5s, as large queries, and downgrades their priorities.
+
+We mentioned that a dedicated user can be created for OLAP. Therefore, create two test users respectively named AP and TP. Bind OLAP tasks to AP_GROUP and OLTP tasks to TP_GROUP. Assume that the test business involves heavy OLTP workloads during daytime and most OLAP workloads are handled at night. Therefore, we set two resource plans for daytime and night. The daytime plan schedules 80% of the resources for OLTP and 20% for OLAP, and the night plan schedules 50% of the resources for OLTP and 50% for OLAP.
+
+The test result in the following figure shows that the queries per second (QPS) for OLAP increases significantly while the OLTP QPS decreases after the plan switchover because a larger portion of CPU resources are allocated to OLAP in the night plan. In the following figure, you can see the turning points of OLAP and OLTP QPS curves caused by the plan switchover.
+
+
+
+It seems that the change in the OLTP QPS is not as noticeable in comparison to OLAP QPS. This is actually a result as expected. The percentage of resources for OLAP is increased from 20% to 50%, an increase of 150%, and that for OLTP is reduced from 80% to 50%, a decrease of 37.5%. In ideal conditions, the QPS fluctuation amplitude of OLTP is smaller than that of OLAP.
+
+
+
+## IOPS Isolation Effects
+We performed a simulation test to verify the IOPS isolation effects.
+- Create four tenants for the simulation test. Each tenant starts 64 threads to send I/O requests that perform 16 KB random reads.
+- The loads of tenants 1, 2, and 4 last for 20 seconds, and the load of tenant 3 begins from the 10th second and lasts for 10 seconds.
+- In this test, the maximum IOPS is about 60,000. Without limitations, any tenant can use up the disk resources.
+
+
+We first verified the disk I/O isolation between tenants. The following figures respectively show the resource configurations and test results of the tenants.
+
+
+
+
+- When the disk resources are used up, the newly joined tenant 3 still has an IOPS of 10,000, which is reserved by using the `MIN_IOPS` parameter.
+- The IOPS of tenant 4 does not exceed 5,000 because its maximum IOPS is limited by using the `MAX_IOPS` parameter.
+- Regardless of the load changes, the IOPS ratio between tenant 1 and tenant 2 is always 2:1 as defined.
+
+
+Then, we verified the disk I/O isolation between loads in a tenant. Set four types of loads in tenant 2. The following figures respectively show the resource configurations and test results of the loads.
+
+
+
+
+
+- The IOPS of Load B remains about 2,000, even if its weight is 0. This is because 97% of the minimum IOPS resources of the tenant are reserved for Load B by using the `MIN_PERCENT` parameter.
+- The IOPS of Load A remains about 1,000. This is because the `MAX_PERCENT` parameter is set to `1` for Load A. In this way, Load A can use only 1% of the maximum resources of the tenant.
+- The IOPS ratio between Load C and Load D is always 2:1, which conforms to their weight ratio of 50:25.
+
+The preceding two tests show that OceanBase Database supports disk I/O isolation between tenants and between loads in a tenant, and meets the three isolation semantics of reservation, limitation, and proportion.
+
+## References
+
+* [Why Resource Isolation Matters in Databases: Take HTAP as an Example](https://en.oceanbase.com/blog/2615023872)
+
+* [Flexible and Simple I/O Isolation Experience](https://open.oceanbase.com/blog/3105048832)
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/_category_.yml b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/_category_.yml
new file mode 100644
index 000000000..549d8ad65
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/_category_.yml
@@ -0,0 +1 @@
+label: Resource Isolation Within a Tenant
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/_category_.yml b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/_category_.yml
new file mode 100644
index 000000000..ef052597c
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/_category_.yml
@@ -0,0 +1 @@
+label: SaaS Multi-tenant Resource Consolidation
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction.md
new file mode 100644
index 000000000..6ffc29df4
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction.md
@@ -0,0 +1,109 @@
+---
+title: Introduction
+weight: 1
+---
+
+> Keywords: automatic lifecycle management | cost effectiveness | super large capacity
+>
+> The intelligent history database migration platform of OceanBase Database helps users quickly archive cold data in a secure manner and allows them to configure related settings only once for automatic lifecycle management. OceanBase Database implements a distributed storage engine featuring a high compression ratio. Thanks to the adaptive compression technologies, this LSM-tree-based storage engine balances the system performance and compression ratio in a creative manner, which is impossible in a conventional database that stores data in fixed-size blocks.
+
+## Historical Data Archiving
+
+In business scenarios such as order processing, transaction processing, and logging, the total amount of data will continue to increase. Access to such data is often highly correlated with time. Usually, data that is closer to the current time is "hotter", which means that the data may be frequently modified and used for point queries. Hot data is usually accessed by transactional loads and real-time analytical loads, and accounts for a relatively low proportion of all data in the system.
+
+Data that has existed in the system for a period of time is called "cold data", which is queried less frequently and rarely modified. In a stable IT system, cold data is a main part of the entire data volume and usually accessed by a small amount of transactional loads as well as some analytical loads such as report statistics.
+
+Due to the obvious difference between hot data and cold data, it will apparently waste system resources to equally treat the two types of data in the same environment and allow them to share one set of resource specifications. In addition, the capacity limit of a single database system may also restrict the storage of data. However, if you periodically archive cold data to more cost-effective storage media and restore data from the history database when accessing it, the data query performance will be compromised at higher system complexity.
+
+Therefore, more and more systems adopt a dual-database solution to separately store online data and historical data. This solution regularly synchronizes online data to the history database and deploys the history database in an environment with lower storage and computing costs, which reduces the overall costs and meets business needs.
+
+## Current Status and Challenges of the Industry
+
+- Rapid data growth: Online data, especially order and transaction data generated in scenarios such as new retail and payment, is growing fast in volume, and most of the data will barely be accessed or updated again some time after it is written to the disk.
+
+- Low efficiency with high costs: Cold data takes up space of solid storage intended for the databases of online businesses, resulting in a serious waste of hardware resources and high IT costs for enterprises. The clumsiness of online databases drags down the query efficiency and hinders data changes and system scaling.
+
+- High risks delivered by conventional solutions: In most conventional solutions, developers or database administrators archive data by using scripts or simple synchronization tools. The concurrency and efficiency of the archiving tasks are hard to control. It is easy to affect online databases, and even cause accidental deletion of production data.
+
+- Complex O&M management: The applicable archiving interval and restrictions vary with databases or even tables of different business modules. It takes a lot of time and effort to maintain the execution logic of a large number of scheduled tasks.
+
+## Solution
+
+- The history database platform of OceanBase Database can be built with average hardware. It allows you to configure archiving tasks on graphical pages and supports automatic archiving interval management. You can set automatic canary execution of data migration, verification, and deletion tasks with a few clicks. The platform provides features such as Out-of-Memory (OOM) prevention, intelligent throttling, and multi-granularity traffic management to ensure stability, achieving intelligent O&M of data archiving tasks in the real sense.
+
+- This solution has been verified in the core business scenarios of Ant Group. A single transaction payment history database stores more than 6 PB of data using hundreds of cost-effective large-capacity mechanical disks, with the disk usage automatically balanced. These disks have been running smoothly for years, saving huge in machine resource investment.
+
+
+
+## Solution Advantages
+
+- Visual management: You can create and run a task, check the task progress, suspend and resume a task, and perform other basic operations by using a GUI provided by OceanBase Database.
+
+- Intelligent O&M: OceanBase Database uses the token bucket algorithm for throttling, and provides features such as resumable data transmission and automatic task scheduling. In addition, it is capable of self-healing. For example, it automatically replaces failed nodes, scales resources, and prevents OOM issues. O&M tasks are executed without requiring human intervention.
+
+- Low costs: OceanBase Database is friendly to large-capacity SATA disks and compresses data at a high compression ratio for compact storage. A single node can store up to 400 TB of data, equivalent to the storage capacity of an entire conventional database.
+
+- Large storage capacity: OceanBase Database allows you to streamline your online business system and reduce the costs of data archiving. A history database cluster of OceanBase Database can serve as a large-capacity relational database to stably support tasks, such as data monitoring, logging, auditing, and verification tasks. These tasks generate a large amount of data that is barely accessed again.
+
+
+## Cases
+
+### Ctrip
+
+#### Business challenges
+
+- As the volume of orders increases, business data grows rapidly, and the storage bottlenecks and performance issues of conventional databases become increasingly apparent.
+
+- The increasing number of database shards not only made O&M more costly and complex but also resulted in endless application adaptation.
+
+#### Solution
+
+- Compared with a conventional centralized MySQL database, OceanBase Database compresses data in the storage at an ultra-high data compression ratio, which greatly reduces the hardware costs of enterprises.
+
+- OceanBase Database supports flexible resource scaling. Its capacity can be linearly scaled in response to the actual business development to support the storage and computing of massive amounts of data. This allows you to get ready for future business growth.
+
+- In addition, OceanBase Database is compatible with MySQL protocols and syntax, so that legacy data can be smoothly migrated to significantly reduce the costs of business migration and transformation. OceanBase Migration Service (OMS) ensures strong data consistency during data migration through full migration, incremental migration, and reverse migration, and supports the synchronization of data to message queue products such as Kafka.
+
+
+
+
+#### Customer benefits
+
+- More efficient O&M: Dozens of MySQL database shards are aggregated into one OceanBase cluster, making management easier with greatly reduced O&M costs. An OceanBase cluster with ultrahigh throughput can be built based on regular PC servers. The cluster does not require database or table sharding and can be quickly scaled out as needed.
+
+- Low costs: OceanBase Database stores hundreds of terabytes of data with guaranteed performance and stability. Compared with the previous solution, the storage cost of the OceanBase solution is slashed by 85%.
+
+- Higher synchronization performance: Data migration is transparent to business. OMS provides full migration and incremental synchronization to support all-in-one data migration of mainstream databases. The latency from data writing in the upstream business modules to the response of the downstream OceanBase cluster is reduced, accelerating data synchronization and reducing the synchronization latency time by 75%.
+
+- High data write performance: Efficient multi-node write is implemented thanks to the Shared-nothing architecture, partition-level leader distribution, and parallel DML provided by the parallel execution framework. With this feature, the data write performance is significantly improved to accommodate highly concurrent data write requirements of the archive database of Ctrip.
+
+#### Videos
+[Cost reduction for the history database of Ctrip](https://www.oceanbase.com/video/9001003)
+
+
+### Other cases
+
++ Alipay: [https://open.oceanbase.com/blog/5377309696](https://open.oceanbase.com/blog/5377309696)
+ - Industry: Internet
+ - Pain points: A MySQL database with a sharding architecture was used as the history database, which was poor in horizontal scalability and had many limitations on queries and transactions.
+ - Benefits: After the history database is migrated from MySQL to OceanBase Database, the disk cost per unit space is reduced to 30% of that of an online server and the overall costs are reduced by about 80%. The storage costs of some business modules are even reduced by 90%.
++ BOSS Zhipin: [https://open.oceanbase.com/blog/8983073840](https://open.oceanbase.com/blog/8983073840)
+ - Industry: Internet
+ - Pain points: A MySQL database with a sharding architecture was used as the history database, which was poor in horizontal scalability and had many limitations on queries and transactions.
+ - Benefits: OceanBase Database is a native distributed system with high scalability. It provides high availability with a recovery point objective (RPO) of 0 and a recovery time objective (RTO) of less than 8s when a minority of replicas fail, making the database more stable. In addition, more than 70% of the storage resources are saved.
++ ENERGY MONSTER: [https://open.oceanbase.com/blog/7057790512](https://open.oceanbase.com/blog/7057790512)
+ - Industry: intelligent manufacturing
+ - Pain points: The business system architecture becomes increasingly complex as the business volume rapidly grows. A MySQL database with a sharding architecture was used as the history database, which was poor in horizontal scalability and had many limitations on queries and transactions.
+ - Benefits: OceanBase Database supports both vertical and horizontal scaling in a quick, transparent, and convenient manner. The storage costs are reduced by 71%.
++ Tsinghua Tongfang: [https://open.oceanbase.com/blog/10581685536](https://open.oceanbase.com/blog/10581685536)
+ - Industry: energy science and technology
+ - Pain points: A MySQL database with a sharding architecture was used as the history database, which was poor in horizontal scalability and had many limitations on queries and transactions.
+ - Benefits: The storage costs are reduced by 75%.
++ Yoka Games: [https://open.oceanbase.com/blog/7746416928](https://open.oceanbase.com/blog/7746416928)
+ - Industry: gaming
+ - Pain points: The resource utilization of different business modules varied greatly in the original MySQL database. The resource utilization of non-blockbuster games is low.
+ - Benefits: The hardware costs are reduced by 80% based on resource isolation between tenants and a high compression ratio. Hundreds of thousands of CNY are saved for each business cluster, significantly reducing the hardware costs.
++ Zuoyebang: [https://open.oceanbase.com/blog/8811965232](https://open.oceanbase.com/blog/8811965232)
+ - Industry: education
+ - Pain points: The storage costs of a MySQL database were high.
+ Benefits: The storage costs are reduced by more than 60%, the real-time analysis performance is improved by more than four times, and the hardware costs are reduced by 77.8%.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge.md
new file mode 100644
index 000000000..73799f197
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge.md
@@ -0,0 +1,143 @@
+---
+title: Background Knowledge of the Storage Engine
+weight: 2
+---
+
+> In the process of collecting suggestions for this advanced tutorial, many users hope to learn more about the background knowledge and the implementation principles of key technologies. Therefore, this topic is added to brief the architecture of the OceanBase Database storage engine, the encoding and compression technologies adopted by the database system, as well as several ways to reduce the impact of encoding on the query performance.
+
+> The content marked red in this topic is easily ignored when you use OceanBase Database in a test or production environment, which may lead to serious impact. We recommend that you pay more attention to such content.
+
+## Architecture of the Storage Engine
+
+Generally, a history database is **write-intensive** (with more writes than reads). Based on the log-structured merge-tree (LSM-tree), the storage engine of OceanBase Database is endowed with high write performance. In a history database, direct load is leveraged to efficiently synchronize data in batches periodically, with data update and real-time data synchronization supported.
+
+The storage engine of OceanBase Database stores baseline data in baseline SSTables and incremental data in MemTables and incremental SSTables. The baseline data is read-only and cannot be modified. Incremental data supports both read and write operations.
+
+
+
+**In OceanBase Database, DML operations such as `INSERT`, `UPDATE`, and `DELETE` are first written to MemTables in memory. This means that the data write performance is equivalent to that of an in-memory database, which agrees with the write-intensive scenario of our history database.**
+
+**When the size of a MemTable reaches the specified threshold, data in the MemTable is dumped to an incremental SSTable on the disk, as shown in the preceding figure. The dumping process is performed sequentially in batches, delivering much higher performance compared with the discrete random writing of a B+ tree-based storage engine.**
+
+When the size of an incremental SSTable reaches the specified threshold, incremental data in the SSTable is merged with the existing baseline data to produce new baseline data. This process is referred to as a major compaction. Then, the new baseline data remains unchanged until the next major compaction. OceanBase Database automatically performs a major compaction during off-peak hours early in the morning on a daily basis.
+
+A downside of the LSM-tree architecture is that it causes read amplification, as shown by the right-side arrows in the preceding figure. Upon a query request, OceanBase Database queries SSTables and MemTables separately, merges the query results, and then returns the merged result to the SQL layer. To mitigate the impact of read amplification, OceanBase Database implements multiple layers of caches in memory, such as the block cache and row cache, to avoid frequent random reads of baseline data.
+
+The history database contains a small amount of incremental data and most data is stored in baseline SSTables. Therefore, for regular batch processing reports of the history database and extensive data scan in ad-hoc analytical queries, computations can be pushed down to the baseline SSTables to bypass the general issue of read amplification in the LSM-tree architecture. OceanBase Database supports pushing down operators on compressed data and uses a compression format that supports vectorized decoding. This way, it can easily process a large amount of data queries and computations.
+
+The SSTable storage format and data encoding and compression technologies enable OceanBase Database to store massive amounts of historical data. The high compression ratio and the higher query performance on equivalent hardware can significantly reduce the storage and computation costs.
+
+In addition, enterprises can choose to deploy the cluster of the history database on more cost-effective hardware, where data encoding and compression configurations hardly need to be considered during database O&M. In terms of application development, the same interface can be used to access the online database and history database, which simplifies the application code and architecture.
+
+Attracted by these characteristics, more and more enterprises begin to use an OceanBase database as their history database. In the future, OceanBase Database will continue to seek breakthroughs in storage architecture, cost reduction, and efficiency improvement.
+
+## Data Compression and Encoding Technologies
+
+OceanBase Database supports both compression and encoding. Compression does not consider data characteristics, while encoding compresses data by column based on data characteristics. The two methods are orthogonal, meaning that we can first encode a data block and then compress it to achieve a higher compression ratio.
+
+At the stage of compression, OceanBase Database uses compression algorithms to compress a microblock without considering the data format, and eliminate data redundancy if detected. OceanBase Database supports zlib, snappy, zstd, and lz4 algorithms for compression. You can use DDL statements to configure and change the compression algorithms for tables based on table application scenarios.
+
+> Note: The concept of microblock is similar to the concepts of page and block in conventional databases. In the LSM-tree architecture, microblocks in OceanBase Database are compressed and become longer after compression. When you create a table, you can set the `block_size` parameter to specify the size of microblocks before compression. (Now you know the meaning of the `block_size` parameter in the output of the `SHOW CREATE TABLE` statement.)
+
+**You can set `block_size`, which defaults to `16KB`, to a larger value to achieve a higher compression ratio. However, this may compromise the read performance because microblock is the smallest unit of read I/O operations. If you want to read a specific row of data in a microblock, only this row of data is decoded. This prevents specific decompression algorithms from decompressing the entire data block when you want to read only a part of data in the data block. If you set `block_size` to a large value, microblocks with data updates cannot be reused during a major compaction but must be rewritten, which slows down the major compaction.** **Adjusting the value of the `block_size` parameter has its pros and cons. You can modify the parameter value as needed after you understand the meaning and impact. We recommend that you use the default value.**
+
+Before data is read from a compressed microblock, the whole microblock is decompressed for scanning, which causes CPU overhead. To minimize the impact of decompression on the query performance, OceanBase Database assigns the decompression task to asynchronous I/O threads and then stores the decompressed microblocks in the block cache as needed. This, combined with query prefetching, provides a pipeline of microblocks for query processing threads and eliminates the additional overhead due to decompression.
+
+
+### Encoding technology for compression
+
+- Data is stored in columns by city, gender, product category, and other classification attributes. In this case, data in each column has a small cardinality. We can create dictionaries directly on these columns to achieve a higher compression ratio.
+
+- If data is inserted into the database in chronological order, time-related columns and auto-increment columns of the inserted rows have small value ranges, and their values increase monotonically. We can make use of these characteristics and apply encoding algorithms such as bit-packing and delta encoding quite easily.
+
+To achieve a higher compression ratio and help users slash storage costs, OceanBase Database has developed a variety of encoding algorithms that have worked well. In addition to single-column encoding algorithms, such as bit-packing, hex encoding, dictionary encoding, run-length encoding (RLE), constant encoding, delta encoding for numeric data, and delta encoding for fixed-length strings, OceanBase Database also provides innovative span-column equal encoding and column prefix encoding to compress different types of redundant data in one or several columns, respectively.
+
+#### Reduced bit width for storage: bit-packing and hex encoding
+
+Bit-packing and hex encoding are similar in that they represent the original data by encoding it with fewer bits if the cardinality of data is small. Moreover, these two encoding algorithms are not exclusive, which means that you can perform bit-packing or hex encoding on numeric data or strings generated by other encoding algorithms to further reduce data redundancy.
+
+
+
+(Bit-packing)
+
+
+
+(Hex encoding)
+
+
+#### Data deduplication for a single column: dictionary encoding and RLE
+
+We can create a dictionary for a data block to compress data with a low cardinality. If the distribution of data with a low cardinality in a microblock conforms to corresponding characteristics, you can use an encoding method such as RLE or constant encoding to further compress the data.
+
+
+
+(Dictionary encoding and RLE)
+
+> Note: In the RLE on the rightmost of the preceding figure, the values 0, 4, and 6 in the first column are the initial subscripts of 0, 1, and 2 in the right-side dictionary encoding. RLE and dictionary encoding apply to scenarios with a large amount of continuous duplicate data.
+
+
+#### Value range-based data compression: delta encoding
+
+OceanBase Database supports delta encoding for numeric data and delta encoding for fixed-length strings. Delta encoding for numeric data is suitable for compressing numeric data in a small value range. To compress date, timestamp, or other numeric data of small adjacent differences, we can keep the minimum value, and store the difference between the original data and the minimum value in each row. Delta encoding for fixed-length strings is a better choice for compressing artificially generated nominal numbers, such as order IDs and ID card numbers, as well as strings of a certain pattern, such as URLs. We can specify a pattern string for a microblock of such data and store the difference between the original string and the pattern string in each row to achieve better compression results.
+
+
+
+(Delta encoding for numeric data)
+
+
+
+(Delta encoding for fixed-length strings)
+
+
+#### Reduced redundancy across columns: span-column encoding
+
+OceanBase Database provides span-column encoding to improve the compression ratio by making use of the data similarity between different columns. Technically, a columnar storage database encodes data only within columns. In an actual business database, however, it is common that data in different columns are associated. In this case, you can use one column to represent part of the information of another column.
+
+Span-column encoding outperforms other encoding algorithms in the compression of composite columns and system-generated data, and can also reduce the data redundancy due to inappropriate table design paradigms.
+
+> Note: Span-column encoding is used only for columns with certain associations, for example, most data of two columns is equivalent or the data of one column is the prefix or substring of another column.
+
+
+### Adaptive compression
+
+Adaptive compression allows the database system to select an optimal encoding algorithm.
+
+The compression performance of data encoding algorithms is related not only to the table schema but also to data characteristics such as the distribution of data and the value range of data within a microblock. This means it is hard to achieve the best compression performance by specifying a columnar encoding algorithm when you design the table data model.
+
+To make your work easier and improve the compression performance, OceanBase Database can analyze characteristics such as the data type, value range, and number of distinct values (NDV) of a column during major compaction. It can also select an appropriate encoding algorithm based on the encoding algorithm and compression ratio of the corresponding column in the previous microblock in the compaction task. OceanBase Database supports encoding the same column in different microblocks with different algorithms while ensuring that the overhead in selecting an encoding algorithm is within an acceptable range.
+
+
+### Reduce the impact of data encoding on the query performance
+
+To better balance compression performance and query performance, we have considered the impact on the query performance when designing data encoding methods.
+
+
+#### Row-level random access
+
+In compression scenarios, the whole data block will be decompressed even if you want to access just a part of data in it. When you access a row in some analytical systems intended for scan queries rather than point queries, adjacent or all rows in the database are decoded.
+
+To better support transactional workloads, OceanBase Database needs to support more efficient point queries. Therefore, our encoding methods ensure row-level random access to encoded data. To be specific, the database accesses and decodes only the metadata of the target row in a point query, which reduces the computational amplification during random point queries. In addition, OceanBase Database stores all metadata required for decoding data in a microblock just within the microblock, so that the microblock is self-describing with better memory locality during decoding.
+
+> Note: In other words, when you perform a point query, OceanBase Database can decode a single row rather than the whole microblock.
+
+#### Computation pushdown
+
+Furthermore, since we store ordered dictionaries, null bitmaps, constants, and other metadata in a microblock to describe the distribution of the encoded data, we can use the metadata to optimize the execution of some filter and aggregate operators during a data scan, and to perform computations directly on the encoded data.
+
+OceanBase Database significantly strengthened its analytical processing capabilities. In the latest versions, aggregation and filtering are pushed down to the storage layer and the vectorized engine is used for vectorized batch decoding based on the columnar storage characteristics of encoded data.
+
+When processing a query, OceanBase Database performs computations directly on the encoded data by making full use of the encoding metadata and the locality of encoded data stored in a columnar storage architecture. This brings a significant increase in the execution efficiency of the pushed-down operators and the data decoding efficiency of the vectorized engine. Data encoding-based operator push-down and vectorized decoding are also important features that have empowered OceanBase Database to efficiently handle analytical workloads and demonstrate an extraordinary performance in TPC-H benchmark tests.
+
+> Note: In other words, for common filter conditions and simple aggregate computations, the storage layer does not need to transfer data to the SQL layer for computation. OceanBase Database can directly complete the computations in the storage layer, saving the overhead for the storage layer to return rows to the SQL layer. OceanBase Database also supports directly performing computations on encoded data, saving the overhead in decoding.
+
+### Basic test of encoding and compression
+
+We performed a simple test to see the influence of different compression methods on the compression performance of OceanBase Database.
+
+We used OceanBase Database V4.0 to test the compression ratio with a TPC-H 10 GB data model in transaction scenarios and with an IJCAI-16 Brick-and-Mortar Store Recommendation Dataset in user behavior log scenarios.
+
+- The TPC-H model simulated real-life order and transaction processing. We tested the compression ratios of two large tables in the TPC-H model: ORDERS table, which stores order information, and LINEITEM table, which stores product information. Under the default configuration where both the zstd and encoding algorithms were used, the compression ratio of the two tables reached about 4.6 in OceanBase Database, much higher than the compression ratio achieved when only the encoding or zstd algorithm was used.
+
+- The IJCAI-16 taobao user log dataset stored desensitized real behavior logs of Taobao users. The compression ratio reached 9.9 when the zstd and encoding algorithms were combined, 8.3 for the encoding algorithm alone, and 6.0 for the zstd algorithm alone.
+
+
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices.md
new file mode 100644
index 000000000..8a88a40be
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices.md
@@ -0,0 +1,203 @@
+---
+title: Best Practices for Archiving Historical Data
+weight: 3
+---
+
+> The content marked red in this topic is easily ignored when you use OceanBase Database in a test or production environment, which may lead to serious impact. We recommend that you pay more attention to such content.
+
+## Background Information
+With the explosive growth of the data volume, enterprises and organizations are facing increasingly severe challenges in database management. Database performance declines, storage costs rise, and data O&M complexity increases, making data management more difficult for database administrators (DBAs) and developers.
+
+To address these challenges, more refined management is required for data throughout the lifecycle, including four stages: online storage, nearline storage, archiving, and destruction. Among them, the nearline storage and archiving of historical data are key stages in history database management. In the archiving stage, data can be stored in a database or an offline file. For archived data that still needs to be queried from time to time, the history database solution is usually applied. The history database solution separates hot and cold data and improves the performance by reducing the load of the online database. **Cold data in the history database is barely accessed. We recommend that you use a server with large disk space and low CPU configurations for the history database to reduce costs.**
+
+> Note: The nearline storage stage is a specific stage between active data use (online storage stage) and long-term archiving or backup (archiving stage). In the nearline storage stage, the data access frequency is low but a high restore or access speed is still required to handle unexpected needs.
+
+We introduced the history database feature to meet users' eager expectations for data management solutions, which brings new challenges to our database management system. In communication with users, we found that many users urgently need a solution that can effectively process large-scale historical data and reduce costs without affecting performance and data availability. These feedbacks have profoundly influenced our understanding of history databases. Therefore, we expect a history database to have the following characteristics:
+
+- Large storage space to support the storage of large amounts of data as well as efficient and continuous data import from the online database.
+
+- High scalability to process increasing amounts of data without adjusting the storage architecture.
+
+- Lower storage costs to store more data with less disk space and more economical storage media.
+
+- Efficient query capabilities for analytical queries and a small number of transactional queries.
+
+- Same access interface for applications and the online database to reduce application complexity.
+
+OceanBase Database is the optimal choice to meet these demands. With its high integrated (standalone + distributed) scalability and hybrid transaction and analytical processing (HTAP) capabilities, OceanBase Database can efficiently support the online database and history database of the business system. More importantly, OceanBase Database can lower the storage costs by at least a half while meeting business needs. According to some customers, after they migrated their history database to OceanBase Database, the storage costs were reduced by about 80%. Lower storage cost is one of the reasons they chose OceanBase Database.
+
+We further consider the storage architecture design of the history database from the following aspects:
+
+- **Whether the architecture of the history database needs to be consistent with that of the online database: We do not think this is necessary.** The online database may adopt a sharding architecture to meet the requirements of data scale and performance, but the history database usually has low requirements for performance. The sharding architecture brings additional costs to the deployment, O&M, and backup and restore of the database. If OceanBase Database is used as the history database, a single table can easily carry tens of terabytes of data. Partitioned tables can be used when the data scale is large.
+
+- Whether the history database should support data updates: This is technically feasible. The history database can be either updatable or just read-only. **To lower the overall costs of the history database, we recommend that you set the history database to read-only.** The history database has fewer random reads and writes and can be deployed on economical storage hardware, such as Serial Advanced Technology Attachment (SATA) disks instead of SSDs. In addition, a read-only history database reduces its own backup costs, namely only one backup copy needs to be maintained.
+
+- Minimizing the impact of data archiving on the online database: This is essential. The online database is the key to the continuous and stable operation of enterprise business. In scenarios with a large data scale, the reading, computation, and deletion of large amounts of data will put pressure on the online database. Therefore, **when choosing a data archiving method, make sure that the stability of the online database can be ensured.**
+
+
+
+
+The following section describes how to build data archive links to OceanBase Database by using archiving tools and migration/synchronization tools.
+
+## Archive Data by Using ODC (Recommended)
+
+This section describes how to use OceanBase Developer Center (ODC) to archive data to and manage data in the history database. Compared with other migration/synchronization tools such as OceanBase Migration Service (OMS), ODC is adapted for data archiving scenarios and provides high usability.
+
+Pay more attention to the first three subsections, which describe the key points that are easily ignored during installation and deployment, as well as the considerations for using the data archiving feature.
+
+The data archiving feature of ODC is easy to use. The GUI-based operations described in the last two subsections are simple and therefore do not require much attention.
+
+
+### Cold data separated from hot data to improve the performance of the online database
+Generally, part of the business data is barely or never accessed after a period of time. This part of data is called cold data. Cold data is archived to the history database, and the online database stores only recent data.
+
+Conventional data archiving methods often consume large amounts of time and manpower and have risks such as misoperations and data loss. Moreover, the data management efficiency and flexibility are limited due to complex manual archiving operations.
+
+**To address these issues, ODC introduces the data archiving feature since V4.2.0 to tackle the difficulties in data management and improve the work efficiency and data security. When the amount of data in an online database increases, the query performance and business operations may be affected. ODC allows you to periodically archive table data from one database to another to address this issue.**
+
+The following figure provides an overview of the data archiving capabilities of ODC.
+
+
+### Install and deploy ODC
+
+For information about how to install and deploy ODC, see [Deploy Web ODC](https://en.oceanbase.com/docs/common-odc-10000000001670043).
+
+**Pay attention to the following points when you install and deploy ODC:**
+
+1. ODC is available in two editions: Client ODC and Web ODC. Client ODC does not support data lifecycle management (with data archiving included), project collaboration management, data desensitization, or auditing. Similar to GUI-based tools such as Navicat and DBeaver, Client ODC is more suitable for individual developers. **If you need to use the data archiving feature, install Web ODC.**
+2. The data archiving feature depends on OceanBase Database Proxy (ODP). When you start ODC, set `DATABASE_PORT` in the `docker run` command to the port number of ODP, rather than that of the OBServer node.
+```
+#!/usr/bin/env bash
+docker run -v /var/log/odc:/opt/odc/log -v /var/data/odc:/opt/odc/data \
+-d -i --net host --cpu-period 100000 --cpu-quota 400000 --memory 8G --name "obodc" \
+-e "DATABASE_HOST=xxx.xx.xx.xx" \
+-e "DATABASE_PORT=xxxxx" \
+-e "DATABASE_USERNAME=[username]@[tenant name]#[cluster name]" \
+-e "DATABASE_PASSWORD=******" \
+-e "DATABASE_NAME=odc_metadb" \
+-e "ODC_ADMIN_INITIAL_PASSWORD=******" \
+oceanbase/odc:4.2.2
+```
+3. **If a small amount of tenant resources such as 1.5 CPU cores and 5 GB of memory are allocated to ODC, it takes about 1.5 minutes for ODC to start. If you cannot log in to the web page of the ODC console,** try running the `cd /var/log/odc` command first and then the `tail -F odc.log` command to observe the initialization process. The following information is displayed during the process: `localIpAddress=xxx.xx.xx.xx, listenPort=8989`. Log in to the ODC console by using the IP address and port number (8989 by default) in this information. If a message similar to `Started OdcServer in 96.934 seconds` is displayed, the initialization is successful.
+
+
+4. We recommend that you check in the official documentation whether required features have any [limitations](https://en.oceanbase.com/docs/common-odc-10000000001670090). If so, make preparations when you create a data source.
+
+
+For example, the data archiving feature depends on ODP and you must use ODP to connect to the database when you configure a data source. The connection string is used for intelligent parsing, as shown in the following figure.
+
+
+After installation, copy the database connection string, paste it into the **Intelligent Parsing** field, and click **Intelligent Parsing** to create a new data source. The parsed information is automatically populated, as shown in the preceding figure. **You must also observe the following points:**
+- For a locally installed OceanBase cluster, select **OceanBase MySQL** and do not select other options such as **MySQL Cloud**. If you select **MySQL Coud** for a locally installed OceanBase cluster, the data source can be successfully created but may have unexpected issues. For example, the `sys` tenant may be connected by default.
+- Click **Test Connection** to verify whether the username and password are correct.
+- Select **Query Tenant Views with sys Tenant Account**. If you do not select this option, some features, such as data archiving, are unavailable.
+
+I hope the preceding tips are helpful.
+
+### [Considerations](https://en.oceanbase.com/docs/common-odc-10000000001669993)
+
+- Prerequisites:
+ - The table to be archived has a primary key.
+
+- Pay attention to the following rules:
+
+ - Make sure that the columns in the source table are compatible with those in the destination. The data archiving service does not handle column compatibility issues.
+
+ - CPU and memory exhaustion prevention is not supported for a MySQL data source.
+
+ - Schema synchronization is not supported for subpartitions of homogeneous databases. Schema synchronization and automatic table creation are not supported for heterogeneous databases.
+
+- The following archive links are supported:
+
+ - Links between MySQL tenants of OceanBase Database
+
+ - Links between Oracle tenants of OceanBase Database
+
+ - Links between MySQL databases
+
+ - Links from a MySQL database to a MySQL tenant of OceanBase Database
+
+ - Links from a MySQL tenant of OceanBase Database to a MySQL database
+
+ - Links between Oracle databases
+
+ - Links from an Oracle database to an Oracle tenant of OceanBase Database
+
+ - Links from an Oracle tenant of OceanBase Database to an Oracle database
+
+ - Links from a PostgreSQL database to a MySQL tenant of OceanBase Database
+
+- Data archiving is not supported in the following cases:
+
+ - The source table in the MySQL or OceanBase MySQL data source does not have a primary key or non-null unique index.
+
+ - The source table in the Oracle, OceanBase Oracle, or PostgreSQL data source does not have a primary key.
+
+ - The source table in the OceanBase Oracle data source contains columns of the JSON or XMLType data type.
+
+ - The source table in the PostgreSQL data source contains data of the following types: array, composite, enumeration, geometry, XML, HSTORE, and full-text retrieval.
+
+ - The archiving condition contains a `LIMIT` clause.
+
+ - The source table contains a foreign key.
+
+- The following archive links do not support schema synchronization and automatic table creation:
+
+ - Links from an Oracle database to an Oracle tenant of OceanBase Database
+ - Links from an Oracle tenant of OceanBase Database to an Oracle database
+ - Links from a MySQL database to a MySQL tenant of OceanBase Database
+ - Links from a MySQL tenant of OceanBase Database to a MySQL database
+ - Links from a PostgreSQL database to a MySQL tenant of OceanBase Database
+
+
+### Create a data archiving ticket
+
+In the ODC console, choose **Tickets** > **Create Ticket** > **Data Archiving**. On the page for creating a data archiving ticket, specify related parameters. This example creates a task to archive the `tb_order` table from the online database to the history database. Select **Purge archived data from the source**. Set the `archive_date` variable referenced in the filter condition to a value one year earlier than the current time. By doing this, you can archive data generated one year ago every time you execute an archiving task.
+
+
+
+The data archiving feature of ODC supports various execution scheduling strategies. You can specify to schedule a data archiving task immediately, at a specified point in time, or periodically. You can also configure schema synchronization, data insertion, and throttling strategies. You can specify whether to synchronize partitions and indexes during schema synchronization. The history database and online database may use different partitioning methods and they have different query requirements. Therefore, you can use fewer indexes in a history database to further lower the storage costs.
+
+
+
+Click **Create Task** to preview the archiving SQL statement. Confirm the scope of data to be archived.
+
+
+As you can see, you can simply configure a data archiving task in the ODC console to archive cold data from the online database to the history database, separating cold data from hot data in the online database. So is it enough to complete this process? What if we need to restore the data archived to the history database back to the online database due to business changes or misoperations? Creating a reverse archiving task is certainly possible, but we have to spend efforts to configure the new task and worry about issues resulting from configuration errors. To cope with such a situation, ODC provides the rollback feature. Let's take the previous task as an example. Now we need to roll back the archived data to the online database. We only need to click the rollback button in the **Action** column of the corresponding data archiving task record on the execution record page. Then, an archiving rollback task is initiated.
+
+
+
+### Clean up expired data to lower storage costs
+The data archiving feature of ODC can separate cold data from hot data in the online database by migrating the cold data to the history database, thereby lowering costs and improving efficiency. However, you may be curious to know whether extra costs are required for maintaining a history database.
+
+In fact, the cold business data in the history database does not necessarily need to be retained permanently. After a period of time, some cold data may be in the "expired" state and will not be used at all, such as log data. If the expired data can be cleaned up in a timely manner, the storage costs will be further reduced. To resolve this issue, ODC provides the data cleanup feature to regularly clean up expired data in the database and further optimize the utilization of storage resources.
+
+
+### Create a data cleanup ticket
+In the ODC console, choose **Tickets** > **Create Ticket** > **Data Cleanup**. The settings on the page for creating a data cleanup ticket are basically the same as those on the page for creating a data archiving ticket. This example creates a periodic cleanup ticket. ODC also supports data verification for the associated history database before cleanup.
+
+
+
+
+
+## Archive data by using OMS
+
+For more information, see [Use OMS for data migration and synchronization](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_04_migration_and_synchronization_oceanbase/migration_and_synchronization_through_oms) in the **OceanBase Quick Starts for DBAs**.
+
+**Pay special attention when using OMS for data archiving. We recommend that you enable only full migration and do not enable incremental synchronization. This is because if incremental synchronization is enabled, the cleanup operations performed on data in the source database will be synchronized to the target database. In this case, archive data may be mistakenly deleted.**
+
+## Archive Data by Using Other Migration Tools
+
+For more information, see the following topics in the **OceanBase Quick Starts for DBAs**:
+- [Use OBLOADER & OBDUMPER for data migration](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_04_migration_and_synchronization_oceanbase/use-obdumper_and_obloader)
+
+- [Use SQL statements for data migration](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_04_migration_and_synchronization_oceanbase/migration_and_synchronization_through_sql)
+
+- [Use other tools for data migration and synchronization](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_04_migration_and_synchronization_oceanbase/migration_and_synchronization_through_other_tools)
+
+
+**Pay attention to issues similar to those occurring during data archiving with OMS when you use these migration/synchronization tools.**
+
+## References
+
+[ODC official documentation](https://en.oceanbase.com/docs/common-odc-10000000001670005)
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/_category_.yml b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/_category_.yml
new file mode 100644
index 000000000..7a4532d45
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/_category_.yml
@@ -0,0 +1 @@
+label: Historical Data Archiving
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction.md
new file mode 100644
index 000000000..6c1978d0a
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction.md
@@ -0,0 +1,112 @@
+---
+title: Introduction
+weight: 1
+---
+
+> Keywords: T + 0 HTAP | distributed execution framework | support for multi-model scenarios
+>
+> Hybrid transaction and analytical processing (HTAP) is a highly expected database capability. With its distributed architecture, OceanBase Database can process transactions while handling analytical tasks such as data analysis and batch processing. Online analytical processing (OLAP) and online transaction processing (OLTP) are supported by the same set of engines to implement two sets of system features. Transactions and real-time analysis are provided by the same system, and one copy of data is used for different workloads. This fundamentally ensures data consistency and minimizes data redundancy, thereby significantly reducing the costs.
+
+## HTAP Scenarios
+Business scenarios of enterprise applications can be roughly classified into OLTP and OLAP.
+
+
+
+Many enterprises tend to deploy multiple database products to support OLTP and OLAP scenarios separately. In this solution, data needs to be transmitted between two systems. Data synchronization inevitably causes latency and introduces the risk of data inconsistency. Redundant data is generated in the two systems, increasing the storage costs.
+
+
+
+
+## Current Status and Challenges of the Industry
+- Poor real-time performance of offline data warehouses: Typically, an offline data warehouse can provide only T+1 data capabilities and poor data update performance. As a result, requirements such as real-time analysis and membership marketing of online business teams cannot be met in a timely manner. It is complex for small- and medium-sized enterprises to separately build a real-time data warehouse. In addition, extra manpower must be invested to maintain the data synchronization link.
+
+- Poor isolation of HTAP: The core of HTAP lies in supporting multiple types of loads by using one set of engines. If resource isolation cannot be ensured, the database intended for key transactions can be affected by analytical and batch processing business. This directly leads to decline of online transactions and business stability.
+
+- Sole capabilities of the conventional primary/standby architecture: In the read/write splitting solution based on primary/standby replication, a standby node can process only read-only queries and does not support batch processing. The real-time data performance is closely related to the synchronization latency. Real-time data consistency cannot be ensured in the case of a large number of transactions or DDL operations. The SQL optimizer has limited capabilities and is incompetent for complex multi-table analysis across shards.
+
+
+
+## Solution
+
+- OceanBase Migration Service (OMS), which supports multi-table aggregation and synchronization, is used to synchronize data from tables of a heterogeneous database to native partitioned tables of OceanBase Database.
+
+- Multiple instances are merged into one instance after being migrated to OceanBase Database. This eliminates the need for middleware maintenance and greatly improves the storage scalability.
+
+- In HTAP mode of OceanBase Database, business analysis and queries as well as real-time marketing and decision analysis can be directly performed in the online database, without the need for T+1 data.
+
+
+
+## Solution Advantages
+- High data update performance: Based on the powerful update capabilities as a relational database, OceanBase Database achieves a millisecond-level ultralow synchronization latency between replicas.
+
+- Integrated HTAP: OceanBase Database uses one set of engines to accommodate OLTP and basic OLAP scenarios, and implements reliable resource isolation between OLTP business and OLAP business based on resource groups. This way, no real-time data warehouse needs to be built.
+
+- Distributed parallel computing engine: The powerful SQL optimizer and executor support vectorized computing, as well as parallel computing and analysis of massive amounts of data.
+
+- Support for multi-model scenarios: OceanBase Database is fully compatible with the syntax of MySQL. It also supports HBase-compatible APIs and TableAPI as well as semi-structured JSON data. OceanBase Database provides powerful Change Data Capture (CDC) capabilities to support data consumption by different types of downstream systems.
+
+- Flexible dynamic scaling: A single OceanBase cluster can contain more than 1,000 nodes and store data at a level higher than PB.
+
+
+
+OceanBase Database uses Flink CDC as the streaming engine and leverages PL/SQL stored procedures in combination with job packages to handle batch processing tasks, thereby implementing data integration and data modeling in an integrated manner. It also implements collaboration between data and business and ensures time efficiency based on the vectorized engine and multi-replica architecture.
+
+
+
+## Cases
+
+### Sinopec
+
+#### Business challenges
+- The original fuel card system failed to support the Internet-based marketing service and business mode innovation. A next-gen smart gas station is expected to be built by using novel technologies to transform Sinopec into an all-around life service provider.
+
+- As more types of data are more profoundly applied and utilized in a wider range of sectors, new features are expected from a database. The original heterogeneous and dispersed database failed to meet the transformation requirements for low systemic risk, easy management and O&M, and business innovation.
+
+#### Solution
+- Based on the powerful HTAP capabilities of OceanBase Database, technologies such as read/write splitting and resource isolation are used to implement load balancing and improve OLAP performance. The OLTP performance is improved by using the log-structured merge-tree (LSM-tree) architecture of the storage engine and technologies such as early lock release (ELR) of the transaction engine.
+
+- The original fuel card system consists of 23 standalone Sybase and Oracle databases, which are operated and maintained by respective provincial branches. The solution aggregates those standalone databases into one distributed OceanBase cluster whose architecture integrates data, platform, and applications.
+
+- OceanBase Database is highly compatible with conventional centralized databases and helps Sinopec migrate its applications from original databases without data loss. A transition solution is provided to minimize business interruptions.
+
+
+
+#### Customer benefits
+
+- Transformation: Users can receive e-coupons and discounts instantly and choose a payment method from multiple options, which is a great step towards transforming Sinopec into an all-around life service provider.
+
+- Efficiency improvement: OceanBase Database empowers Sinopec to provide the fuel card service for about 30,000 gas stations around China. The time consumed for uploading transaction records is reduced from almost one day to a few seconds, meeting the need for daily job handover and reporting. The data query time is shortened from several minutes to several seconds. Up to 50,000 business transactions can be carried out per minute.
+
+- Cost reduction: As 23 separate databases are aggregated into one OceanBase cluster, the software, hardware, and O&M costs are greatly reduced. The storage cost is slashed by 8 times.
+
+- High reliability: The time consumed for failure recovery is decreased from hours to minutes, the business continuity reaches 99.99%, and security requirements in MLPS 2.0 are met.
+
+
+
+### Other cases
+
++ KUAYUE EXPRESS (KYE): [https://open.oceanbase.com/blog/27200135](https://open.oceanbase.com/blog/27200135)
+ - Industry: logistics
+ - Pain points: MySQL cannot meet the increasingly complex analysis and processing requirements. TiDB, OceanBase Database, StarRocks, and Doris are considered in terms of online scaling, load balancing, and other maintainability metrics. Either TiDB or OceanBase Database will be chosen.
+ - Benefits: Both the real-time and offline data query performance of OceanBase Database is five times that of TiDB, and the storage cost is 1/5 that of TiDB. Moreover, OceanBase Database has a few components, enabling easy maintenance.
+
++ Zuoyebang: [https://open.oceanbase.com/blog/8811965232](https://open.oceanbase.com/blog/8811965232)
+ - Industry: education
+ - Pain points: MySQL cannot support real-time data analysis requirements.
+ - Benefits: Zuoyebang tested the performance of OceanBase Database in a typical scenario, where a dataset of more than one million rows was used for 10 to 20 concurrent aggregate queries. The test results showed that OceanBase Database responded to analytical queries within milliseconds, demonstrating performance dozens of times better than MySQL Database without impacting core transaction processing (TP) performance.
+
++ ClassIn: [https://open.oceanbase.com/blog/27200134](https://open.oceanbase.com/blog/27200134)
+ - Industry: education
+ - Pain points: Bottlenecks occur in read and write performance. During the COVID-19 pandemic, the traffic of online classroom business surged. As standalone databases such as MySQL do not support smooth horizontal scaling like distributed databases, many online clusters had obvious bottlenecks in reads and writes.
+ - Benefits: The actual online traffic was introduced to test clusters. The optimizer of TiDB was unstable and had indexing errors. The CPU utilization and latency of TiDB frequently fluctuated obviously. On the contrary, the CPU utilization and latency of OceanBase Database were very stable.
+
++ Yunli Smart of China Unicom: [https://open.oceanbase.com/blog/5244321792](https://open.oceanbase.com/blog/5244321792)
+ - Industry: government enterprises and network operators
+ - Pain points: The big data processing system contains too many components. Hive depends on Hadoop, Hadoop Distributed File System (HDFS) is used for data storage, YARN is used as the resource management framework, and Tez is used to optimize directed acyclic graph (DAG) tasks of Hive, making O&M difficult.
+ - Benefits: The architecture of OceanBase Database is simple and contains only OBServer nodes and OceanBase Database Proxy (ODP). If tens or hundreds of clusters are to be deployed and maintained, OceanBase Database is a better choice in terms of configuration, deployment, and O&M. OceanBase Database improves the data governance efficiency from a minute level to a quasi-real-time level. OceanBase Database outperforms Hive in terms of latency in scenarios with small amounts of data. In TP scenarios, OceanBase Database with an HTAP engine is superior to Hive, which is based on a single AP engine.
+ - Video: [Evolution Path of the Real-time Data Warehouse for Yunli Smart of China Unicom](https://www.oceanbase.com/video/9001367)
+
++ Hwadee: [https://open.oceanbase.com/blog/6776731648](https://open.oceanbase.com/blog/6776731648)
+ - Industry: Internet
+ - Pain points: The data computing platform was built based on the Hadoop ecosystem. It comprised too many components, leading to complex building and high O&M costs. What's worse, troubleshooting was difficult in this complex environment.
+ - Benefits: The architecture is greatly simplified, enabling easy O&M and lowering the costs. The OBServer nodes are peer-to-peer, and each contains a storage engine and a computing engine. OceanBase Database boasts a small number of components, simple deployment, and easy O&M. With OceanBase Database, we no longer need to add other components to the database to achieve high availability and automatic failover.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/02_background_knowledge.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/02_background_knowledge.md
new file mode 100644
index 000000000..211f176f5
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/02_background_knowledge.md
@@ -0,0 +1,112 @@
+---
+title: Background Knowledge of the SQL Engine
+weight: 2
+---
+
+> In the process of collecting suggestions for this advanced tutorial, many users hope to learn more about the background knowledge and the implementation principles of key technologies. Therefore, this topic is added here to brief the SQL engine of OceanBase Database.
+
+## Overview of the SQL Engine
+After a query is initiated in OceanBase Database:
+
+- It first enters into the parser/resolver, a module where the kernel figures out the purpose and requirement of the query.
+
+- Then, the query enters into the optimizer, which will select the best among a variety of implementation methods for the executor.
+
+- The executor contains all details for executing the selected method. It will faithfully execute the query based on the plan recommended by the optimizer and return the result to the user.
+
+
+The following figure shows the overall framework of the SQL engine of OceanBase Database.
+
+
+
+
+The preceding figure compares the features of the optimizer and executor in a business trip. The optimizer will enumerate all plans of traveling to the destination, evaluate the costs of these plans, and select the best one. Then, the executor will execute the selected plan.
+
+As shown in the figure, the SQL engine involves a lot of content. However, you only need to delve into a few of the content.
+
+## Basic Knowledge
+
+OceanBase Database users need to know the basic knowledge about the SQL engine, which is only a very small proportion of all related knowledge.
+
+After understanding the basic knowledge, you can spend less time troubleshooting.
+
+### Optimizer
+**You need to understand the following basic knowledge about the optimizer:**
+- **Statistics and plan cache**
+- **Execution plan reading and management**
+- **Common SQL tuning methods**
+- **Typical scenarios and general troubleshooting logic for SQL performance issues**
+
+### Executor
+**You need to understand the following basic knowledge about the executor:**
+- **Parallel execution**
+- **Tools for analyzing SQL performance issues**
+
+### Others
+**You need to understand the following basic knowledge related to analytical processing (AP):**
+- **Columnar storage**
+
+## Advanced Knowledge
+
+During the communication with users, many users expressed their hope to have a deeper understanding of the key technical implementation principles of the SQL engine.
+
+Here, I'll recommend some knowledge that I personally think is very valuable for learning, but I will not review them one by one.
+
+If you can master both the basic and advanced knowledge, you will be an expert in the SQL engine.
+
+
+
+### Optimizer
+
+For advanced knowledge about the optimizer, see [Rewrite SQL Statements](https://open.oceanbase.com/blog/10900289).
+
+The content in this blog is demanding for users and is applicable to those who hope to deeply understand SQL query rewrite. Before you read this blog, we recommend that you first learn how to read and manage execution plans.
+
+
+### Executor
+
+- Vectorized execution
+
+ - Recommended blog: [Evolution Path of Database Engines: From Row Engine to Vectorized Engine](https://open.oceanbase.com/blog/12082655296)
+
+ - This blog is merely intended for popularization. All code in this article is pseudocode. We recommend this blog for all OceanBase Database users.
+
+ - By the way, to **achieve the optimal performance of vectorized execution**, we recommend you enable vectorized execution and do not change the default value of `rowset` (which can be adaptively modified).
+
+
+- Parallel execution
+
+ - Recommended blog: [Mastering Parallel Execution in OceanBase Database](https://open.oceanbase.com/blog/7083583808)
+
+ - The content in this blog is a little bit demanding and is **applicable to users who want to know about AP**. Before you read this blog, we recommend that you first learn how to read and manage execution plans.
+
+- Data access service (DAS)
+ - Recommended blog: [Practices of SQL Tuning in OceanBase Database: Execution Plan Instability Caused by Dynamic Sampling](https://open.oceanbase.com/blog/12134198082#%E7%AC%AC%E4%BA%8C%E4%B8%AA%E9%97%AE%E9%A2%98)
+
+ - With DAS, OceanBase Database does not need to use the REMOTE or EXCHANGE operator to transfer complex SQL queries or subplans among nodes, but directly interacts with the storage layer to pull remote storage-layer data through remote procedural calls (RPCs) in proper scenarios. This is to simplify remote and distributed execution plans into local plans.
+
+ - Before you read this blog, we recommend that you first learn how to read and manage execution plans.
+
+- Distributed pushdown
+ - Recommended blog: [Pushdown Techniques in OceanBase Database](https://open.oceanbase.com/blog/5382203648)
+
+ - Simply put, to better utilize parallel execution capabilities and reduce CPU and network overheads during distributed execution, the optimizer often pushes down some operators to lower-layer computing nodes when it generates execution plans. This is to make full use of the computing resources of the cluster to improve the execution efficiency.
+
+ - Before you read this blog, we recommend that you first learn how to read and manage execution plans.
+
+- Adaptive techniques of the execution engine
+ - Recommended blog: [Adaptive Techniques in the OceanBase Database Execution Engine](https://open.oceanbase.com/blog/5250647552)
+
+ - Simply put, adaptive techniques enable the execution engine to dynamically adjust the execution strategy based on actual data characteristics (for example, uneven data distribution), thereby improving the execution performance.
+
+ - Before you read this blog, we recommend that you first learn how to read and manage execution plans.
+
+
+
+### Others
+
+- Columnar storage
+ - Recommended blog: [Columnstore Engine: Your Ticket to OLAP](https://open.oceanbase.com/blog/11547010336)
+
+- References
+ - We strongly recommend that you watch the following video made by Xifeng: [Technical Mechanism and Practices of the HTAP Technology of OceanBase Database](https://www.oceanbase.com/video/9000963).
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices.md
new file mode 100644
index 000000000..8a3c6bcbc
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices.md
@@ -0,0 +1,108 @@
+---
+title: Read/Write Splitting Strategy and Architecture
+weight: 3
+---
+
+> Note: At present, *OceanBase Advanced Tutorial for DBAs* applies only to OceanBase Database Community Edition. Therefore, the arbitration replica feature of OceanBase Database Enterprise Edition is not included in the tutorial outline provided in this topic. For more information about the differences between the two editions, see [Differences between Enterprise Edition and Community Edition](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714481).
+
+## Overview
+The read/write splitting strategy separates query operations from write operations in a database, preventing mutual impact and improving resource utilization. In a hybrid transaction and analytical processing (HTAP) database, read/write splitting scenarios are common, and read-only scenarios include business intelligence (BI) queries, extract, transform, and load (ETL) in big data, and data pulling from caches.
+
+Hosting both transaction processing (TP) business and analytical processing (AP) business in the same database cluster raises high requirements for database configurations. The read/write splitting strategy is generally used to route some read requests to followers to reduce the resource usage by complex online analytical processing (OLAP) requests and shorten the response time of online business.
+
+OceanBase Database natively supports read/write splitting by using [OceanBase Database Proxy (ODP)](https://open.oceanbase.com/blog/10900290) and modifying the configurations of OBServer nodes.
+
+OceanBase Database provides two read consistency levels: strong consistency and weak consistency. Strong-consistency read requests are routed to the leader to read the latest data. [Weak-consistency read requests](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001029729) are preferentially routed to followers and may not read the latest data.
+
+OceanBase Database allows you to add an SQL hint to an SQL statement to be executed at the application side to explicitly enable weak-consistency reads, thereby implementing comment-based read-write splitting. OceanBase Database supports the following three common read/write splitting strategies and allows you to flexibly configure a read/write splitting strategy as needed.
+
+## Follower-first Read (Weak-consistency Read) Strategy
+1. Single-table SQL queries are generally routed to the node where the leader of the table resides, regardless of the ODP that you use to connect to the OceanBase cluster. This default routing strategy is called strong-consistency read.
+2. You can change the routing strategy of ODP to follower-first so that business read traffic is assigned to the ODP and read requests are preferentially routed to followers. By default, ODP routes a read request to the local follower. If the local replica is the leader, ODP preferentially routes the read request to the follower in another IDC in the same region. In one word, the follower-first read strategy means to read a nearby follower.
+3. For the configuration method, see [Best practices for read/write splitting](https://en.oceanbase.com/docs/common-best-practices-10000000001714402).
+
+**The following figure shows the routing strategy.**
+
+
+
+**Advantages**: The configuration procedure is simple. You need to modify only ODP settings but no OBServer node settings. Read traffic is evenly distributed to all followers.
+
+**Disadvantages**: If the local replica is the leader, read requests need to be routed across IDCs (zones). If leaders are not changed, the leader and followers of different replicas may coexist in the same zone or server. In other words, zone- or server-level read/write splitting cannot be fully implemented.
+
+**Scenarios: Generally, the follower-first read (weak-consistency read) strategy applies to scenarios without high requirements for read/write splitting and with a few read requests. For a scenario with many read requests, the read-only zone or read-only replica strategy is recommended to avoid affecting read and write operations of the leader. **
+
+## Read-only Zone Strategy
+
+
+1. Set `PRIMARY_ZONE` to `zone1,zone2;zone3`. Note that a comma (,) is used between `zone1` and `zone2`, while a semicolon (;) is used between `zone2` and `zone3`, which indicates that both `zone1` and `zone2` are set to primary zones. Therefore, all leaders will be migrated to `zone1` and `zone2`. By default, followers are routed to `zone3` and are configured to process only OLAP SQL statements for which the weak-consistency read strategy is specified.
+2. SQL statements that require weak-consistency read are routed to the ODP with weak-consistency read enabled. Other SQL statements are routed to a normal ODP.
+3. All SQL statements bound for the ODP with weak-consistency read enabled are automatically routed to the local follower based on the logical data center (LDC)-based strategy and follower-first read strategy.
+4. For the configuration method, see [Best practices for read/write splitting](https://en.oceanbase.com/docs/common-best-practices-10000000001714402).
+
+**The following figure shows the routing strategy.**
+
+
+
+**Advantages**: Read/Write splitting is implemented at the zone level by setting a read-only zone. The isolation performance is higher than that of the follower-first read strategy.
+
+**Disadvantages**: The primary zones must be manually specified. The write traffic will be distributed to `zone1` and `zone2`.
+
+**Scenarios: The read-only zone strategy applies to scenarios with balanced read and write requests. **
+
+## Read-only Replica Strategy
+Apart from full-featured replicas, OceanBase Database also supports read-only replicas. The name of read-only replicas is READONLY or R for short. Read-only replicas support read operations and do not support write operations. A read-only replica can serve only as a follower of a log stream, and cannot participate in election or voting. In other words, a read-only replica cannot be elected as the leader of the log stream.
+
+You can configure a dedicated zone to host a read-only replica for processing OLAP requests. When the read-only replica fails, services of the primary cluster are not affected.
+
+
+1. The primary cluster provides services normally.
+2. AP requests are routed by using an independent ODP to a read-only replica.
+3. Select the read-only replica type for the corresponding zone during tenant creation. **Note that a full-featured replica can be dynamically switched to a read-only replica.**
+
+
+
+
+**The following figure shows the routing strategy.**
+
+
+
+**Advantages**: OLAP requests can be fully isolated from online transaction processing (OLTP) requests without affecting each other.
+
+**Disadvantages**: More resources are required for the read-only replica.
+
+**Scenarios: The read-only replica strategy applies to scenarios with far more read requests than write requests, most of which do not require high real-time performance, or scenarios with a large number of AP requests. **
+
+## Read-only Standby Cluster (Standby Tenant) Strategy
+The preceding read/write splitting strategies apply to the three-replica or five-replica architecture. **For scenarios that demand cost effectiveness but not require high availability**, you can build a single-replica or three-replica standby cluster for the OceanBase cluster and route read-only requests only to the standby cluster.
+
+Notice: A standby cluster supports only reads and the reads must have weak consistency.
+
+For information about the Physical Standby Database solution, see [Physical standby database solution based on asynchronous log replication](https://oceanbase.github.io/docs/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/primary_standby_database_solution).
+
+You can create a standby tenant in OceanBase Cloud Platform (OCP) by setting the tenant type to STANDBY and specifying the primary tenant for it.
+
+## Summary
+To sum up, OceanBase Database supports the following read/write splitting strategies:
+
+- Follower-first read/Read-only zone: In the three-replica or five-replica architecture, you can specify a weak-consistency read hint or configure session settings to enable certain SQL statements to access a nearby read-only replica.
+
+- Read-only replica: In the three-replica or five-replica architecture, you can specify one or more additional read-only replicas and configure a dedicated ODP to route read-only requests to the read-only replicas.
+
+- Read-only standby cluster: You can build a standby cluster with one or three replicas. In this case, read-only requests are routed only to this standby cluster.
+
+Advantages of the read/write splitting feature:
+
+- A follower or read-only replica, which does not support write operations, will not be mistakenly written. All write operations will be routed to the leader.
+
+- When a follower or read-only replica fails, ODP will route the requests to a nearby follower.
+
+
+Finally, let me end this topic about read/write splitting with a user's fair comment: "If you are used to Oracle's ADG or MySQL's master/slave read/write splitting, you may find OceanBase Database's read/write splitting solution a little complicated. Strictly speaking, a read/write splitting solution needs to consider various abnormal situations. That's exactly what OceanBase Database has done. What's more, OceanBase Database simplifies the configuration procedure and makes O&M easier."
+
+
+## References
+
+[Read/Write Splitting](https://open.oceanbase.com/blog/5581452032)
+
+[Architecture Design for AP Scenarios: Read/Write Splitting](https://open.oceanbase.com/blog/1100238)
+
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices.md
new file mode 100644
index 000000000..2632a1c88
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices.md
@@ -0,0 +1,87 @@
+---
+title: HTAP System Architecture Design
+weight: 4
+---
+
+> Note: At present, *OceanBase Advanced Tutorial for DBAs* applies only to OceanBase Database Community Edition. Therefore, the arbitration replica feature of OceanBase Database Enterprise Edition is not included in the tutorial outline provided in this topic. For more information about the differences between the two editions, see [Differences between Enterprise Edition and Community Edition](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001714481).
+
+OceanBase Database supports read-only columnstore replicas since V4.3.3. This topic describes how to use columnar storage to further optimize the system architecture on the basis of read/write splitting.
+
+## Business Architecture for Real-time Reports and Risk Control
+ - **Scenarios: This architecture applies to scenarios that are dominated by transaction processing (TP) business but have a few analytical processing (AP) requirements. **
+
+ - Architecture design idea: Use rowstore replicas and create columnstore indexes on rowstore replicas.
+
+ - For information about how to create a columnstore index, see [Columnstore Engine: Your Ticket to OLAP](https://open.oceanbase.com/blog/11547010336).
+
+ > Note:
+ >
+ > With columnstore indexes, both a rowstore replica (for TP business) and a columnstore replica (AP business) are available for the same data.
+ >
+ > Compared with the dual-replica mode (rowstore replica + columnstore replica), the columnstore index feature allows you to create an index only on columns involved in AP. This can accelerate AP queries and minimize the storage costs.
+
+
+
+## Business Architecture for Quasi-real-time Decision Analysis
+ - **Scenarios: This architecture applies to scenarios that have more TP business needs than AP business needs and where resource isolation cannot be implemented by using control groups (cgroups). **
+
+ - Architecture design idea: Use read-only columnstore replicas to implement zone-level hard isolation.
+
+ - For the considerations on using read-only columnstore replicas, see [Columnstore replica](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001719945).
+
+ > Note:
+ >
+ > The columnstore replica feature is a new feature available since OceanBase Database V4.3.3, which was released on October 24, 2024. We recommend that you do not use it in a proof of concept (POC) environment, to avoid compromising system stability.
+
+
+
+
+
+## Business Architecture for Lightweight Data Warehouses
+
+ - **Scenarios: This architecture applies to scenarios dominated by AP business that has both large queries and many small queries. **
+
+ - Architecture design idea: Use a columnstore table and create rowstore indexes on the table.
+
+ - For information about the columnar storage syntax, see [Columnstore Engine: Your Ticket to OLAP](https://open.oceanbase.com/blog/11547010336).
+
+ > Note:
+ >
+ > The columnstore table aims to accelerate complex AP queries and rowstore indexes aim to accelerate point queries.
+ >
+ > A lightweight data warehouse is not an offline data warehouse. It has not only complex queries but also simple and lightweight point queries.
+
+
+
+
+
+## Position and Functionality of OceanBase Database in Design of Real-time Data Warehouses
+
+This section describes the position and functionality of OceanBase Database in the design of real-time data warehouses.
+
+A common hierarchical architecture of real-time data warehouses comprises the following layers: operational data store (ODS), data warehouse detail (DWD), data warehouse summary (DWS), and application data store (ADS). These layers have different features and purposes to better organize and manage data to support efficient data processing and analysis.
+
+These layers are described as follows:
+
+- ODS layer: stores quasi-real-time raw data for operation reports and monitoring.
+
+- DWD layer: stores cleansed and standardized details data without redundancy and inconsistency.
+
+- DWS layer: stores aggregated and summarized data for complex analysis and report generation.
+
+- ADS layer: stores highly aggregated and processed data for frontend applications and reports.
+
+Usually, a TP database is among the upstream systems of the data warehouse business. Business logs are written to the queue by using ecosystem tools such as Kafka and then batch written to the data warehouse.
+
+- OceanBase Database can serve as the data warehouse.
+ - Based on its materialized view capabilities, OceanBase Database cleanses data stored in the DWD layer and summarizes data in the DWS layer, thereby eliminating the extract, transform, and load (ETL) process between different layers.
+ 
+
+- OceanBase Database can serve as the storage medium of the data warehouse.
+ - Third-party ecosystem tools such as Flink are used for computations, and OceanBase Database is also used to process some complex queries, which can be seen as a hybrid computation solution.
+ 
+
+- If a third-party ecosystem tool is required for data processing when the data volume is large:
+ - OceanBase Database can serve as the ODS layer to address the pain point of poor real-time write performance.
+ - OceanBase Database can serve as the ADS layer to address the pain point of poor performance in high-concurrency scenarios.
+ 
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/05_performance_tuning.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/05_performance_tuning.md
new file mode 100644
index 000000000..d60009035
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/05_performance_tuning.md
@@ -0,0 +1,72 @@
+---
+title: SQL Performance Diagnostics and Tuning
+weight: 5
+---
+
+
+SQL performance diagnostics and tuning are the most frequently mentioned requirements when collecting user suggestions on the **OceanBase Advanced Tutorial for DBAs** ("**Advanced Tutorial**" for short).
+
+However, when we answered users' questions about SQL tuning in the Q&A section of the OceanBase community forum, we found that most issues can be easily solved by creating a suitable index and few SQL performance tuning issues cannot be solved based on Chapter 7 of the **OceanBase Quick Starts for DBAs** ("**Quick Starts**" for short).
+
+We have prepared the complete study notes of [OceanBase Quick Starts for DBAs](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_01_overview_of_the_oceanbase_database/overview). Therefore, we strongly recommend that you read through [Chapter 7](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_07_diagnosis_and_tuning/introduction) of the **Quick Starts**.
+
+The "Background Knowledge of the SQL Engine" topic has described the following knowledge about SQL performance diagnostics and tuning:
+
+- Statistics and plan cache
+
+- Execution plan reading and management
+
+- Common SQL tuning methods
+
+- Typical scenarios and general troubleshooting logic for SQL performance issues
+
+- Tools for analyzing SQL performance issues
+
+All of the above content is available in Chapter 7 of the **Quick Starts** (or you can learn only the above content). If you really do not have the patience to read through Chapter 7, we recommend that you read the three sections framed in red in the following figure.
+
+
+
+
+If you still do not have the patience to read these three sections, we recommend that you read the paragraphs framed in red of the following two sections on the right side of the following figures. This can eliminate your overhead in asking questions in the Q&A section of the OceanBase community forum during SQL performance analysis.
+
+"Common SQL tuning methods" section: Statistics, Plan cache, and Index tuning
+
+
+
+"Typical scenarios and troubleshooting logic for SQL performance issues" section
+
+
+
+
+
+## "SQL Tuning Practices" Topic (Under Planning)
+
+For the time being, we are not going to add any new tutorial-oriented content related to SQL tuning methods in the **Advanced Tutorial**.
+
+However, as I mentioned in Chapter 7 of the **Quick Starts**: "You are not likely to become an expert in SQL performance analysis simply by reading them. You must also gradually accumulate experience in extensive practices."
+
+Therefore, Xuyu, an expert in SQL tuning, and I will record and summarize some typical SQL tuning issues posted in the OceanBase community forum, and share these issues with you in the "SQL Tuning Practices" topic under the [Well-chosen](https://ask.oceanbase.com/c/well-chosen/75) section on the OceanBase community forum.
+
+Example: [SQL Tuning Practices: Index Failure Caused by Collation](https://ask.oceanbase.com/t/topic/35613940)
+
+In this "SQL Tuning Practices" topic, we will gradually introduce typical SQL tuning practices based on actual problems encountered by users, including:
+
+- Failure to make full use of indexes
+
+- Exceptions caused by poor join methods in plans
+
+- Exceptions caused by poor shuffle methods in plans
+
+- Exceptions caused by poor order methods in plans
+
+- Exceptions caused by partition data skew
+
+- Others
+
+More information is to be supplemented by Xuyu and I.
+
+## References
+
+[Well-chosen](https://ask.oceanbase.com/c/well-chosen/75) section on the OceanBase community forum
+
+Complete study notes of [OceanBase Quick Starts for DBAs](https://oceanbase.github.io/docs/user_manual/quick_starts/en-US/chapter_01_overview_of_the_oceanbase_database/overview)
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/06_others.md b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/06_others.md
new file mode 100644
index 000000000..1c5031b6b
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/06_others.md
@@ -0,0 +1,36 @@
+---
+title: Others
+weight: 5
+---
+
+In this topic, I will share with you some information related to analytical processing (AP) scenarios.
+
+## Recommended Configurations in AP Scenarios
+
+- **Simply put, we recommend that you directly use a parameter template. ** Parameter templates can free you from manual parameter configuration. For more information, see [Parameter Templates](https://oceanbase.github.io/docs/user_manual/operation_and_maintenance/scenario_best_practices/parameter_templates) in this advanced tutorial.
+
+- The detailed parameter configurations in each template are also available for your reference:
+
+ - [Recommended configurations in HTAP scenarios](https://en.oceanbase.com/docs/common-best-practices-10000000001740745)
+
+ - [Recommended configurations in OLAP scenarios](https://en.oceanbase.com/docs/common-best-practices-10000000001740746)
+
+
+## Best Practices for Parallel Execution
+
+- Recommended blog: [Mastering Parallel Execution in OceanBase Database](https://open.oceanbase.com/blog/7083583808)
+
+ - The content in this blog is a little bit demanding and is applicable to users who want to know about AP. Before you read this blog, we recommend that you first learn how to read and manage execution plans.
+
+- Recommended blog: [Auto DOP in OceanBase Database V4.2](https://open.oceanbase.com/blog/7439298336)
+
+ - With the auto degree of parallelism (DOP) feature, you do not need to manually set a DOP.
+ - **If you do not have time to read all the recommended blogs, you must know how to set an optimal DOP ** by simply performing the following two steps:
+ - Set the maximum DOP based on the server performance and the acceptable resource usage by complex queries, for example, `set parallel_degree_limit = 32;`.
+ - Specify `set parallel_degree_policy = AUTO;` to enable auto DOP.
+
+## Best Practices for Columnar Storage
+
+- Recommended blog: [Columnstore Engine: Your Ticket to OLAP](https://open.oceanbase.com/blog/11547010336)
+
+ - The columnar storage feature of OceanBase Database is being improved. Best practices for new capabilities such as columnstore replicas will be added here later.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/_category_.yml b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/_category_.yml
new file mode 100644
index 000000000..42dd41ce7
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/_category_.yml
@@ -0,0 +1 @@
+label: HTAP Scenario
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide.md b/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide.md
new file mode 100644
index 000000000..d47693fce
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide.md
@@ -0,0 +1,642 @@
+---
+title: OMS Community Edition Troubleshooting Guide
+weight: 1
+---
+
+> Why do we provide a troubleshooting manual for OMS Community Edition?
+>
+> On the one hand, most documentation on the official website of OceanBase Database is intended for the Enterprise Edition, but the Enterprise Edition and Community Edition of OceanBase Migration Service (OMS) are totally independent of each other. Therefore, a troubleshooting manual for users of the Community Edition is required.
+>
+> On the other hand, lightweight O&M tools such as OceanBase Deployer (obd) are dedicated for OceanBase Database Community Edition, and will be supported for OceanBase Database Enterprise Edition later. However, a detailed obd troubleshooting manual is absent on the official website.
+>
+> As for tools like OceanBase Cloud Platform (OCP) whose Enterprise Edition and Community Edition are built based on the same set of code, you can visit the official website for the troubleshooting information.
+
+>
+> This troubleshooting manual is written personally by Liu Che, the R&D director of OMS Community Edition, and is a valuable reference for troubleshooting OMS. Feel free to read through this manual and save it as a favorite.
+>
+> Today I chatted with Xie Yun, the R&D director of obd. He said that many users of OceanBase Database Community Edition are using obd for O&M management of clusters. A similar troubleshooting manual for obd Community Edition will be released in December 2024.
+>
+
+
+## Troubleshooting Procedure
+
+When an error occurs in OMS Community Edition, check whether the error is caused by the limitations mentioned in the official documentation.
+
+The following figure shows the overall troubleshooting procedure when an error occurs in a data migration or synchronization task in OMS Community Edition.
+
+
+
+
+## Features, Components, and Log Locations
+
+> Note:
+>
+> All log files are automatically archived and compressed. If you want to view logs, locate the log file by time.
+
+### Schema migration
+
+| Item | Description |
+|---------|-----------|
+| Component | Ghana |
+| Log directory | /home/admin/logs/ghana/Ghana |
+| Schema conversion logs | dbcat.log |
+| Common error logs | common-error.log |
+| Common output logs | common-default.log |
+| Query logs | check_query.log |
+| Task logs | oms-step.log |
+| Background scheduling logs | oms-scheduler.log |
+
+### Full migration
+
+| Item | Description |
+|---------|-----------|
+| Component | Connector |
+| Log directory | /home/ds/run/`{Component ID}`/logs |
+| Error logs | error.log |
+| Operation logs | connector.log |
+
+Perform the following steps to query the component ID:
+
+1. Log in to the console of OMS Community Edition.
+
+2. In the left-side navigation pane, click **Data Migration**.
+
+3. On the **Data Migration** page, click the name of the target data migration task to go to its details page.
+
+4. Click **View Component Monitoring** in the upper-right corner.
+
+ 
+
+5. In the **View Component Monitoring** dialog box, check the component ID of the Full-Import component.
+
+ 
+
+### Incremental synchronization
+
+#### Store
+
+| Item | Description |
+|---------|-----------|
+| Component | Store |
+| Log directory | /home/ds/store/`store{port}`/log |
+| obstore (source database: OceanBase Database V3.x) | liboblog.log |
+| obstore (source database: OceanBase Database V4.x) | libobcdc.log |
+| mysqlstore (xlog implemented by using Java) | connector/connector.log |
+
+Perform the following steps to query the port number of the Store component:
+
+1. Log in to the console of OMS Community Edition.
+
+2. In the left-side navigation pane, click **Data Migration**.
+
+3. On the **Data Migration** page, click the name of the target data migration task to go to its details page.
+
+4. Click **View Component Monitoring** in the upper-right corner.
+
+ 
+
+5. Click **View Component Monitoring** in the upper-right corner to view the component ID of the Store component.
+
+ The component ID is in the format of `{ip}-{port}:{subtopic}:{seq}`, from which you can obtain the port number of the Store component.
+
+ 
+
+
+
+#### Incr-Sync
+
+| Item | Description |
+|---------|-----------|
+| Component | Incr-Sync |
+| Log directory | /home/ds/run/`{Component ID}`/logs |
+| Error logs | error.log |
+| Operation logs | connector.log |
+| Data (which contains only the primary keys) read by Incr-Sync from the source | msg/connector_source_msg.log |
+| Data (which contains only the primary keys) written by Incr-Sync to the target | msg/connector_sink_msg.log |
+| Data filtered by Incr-Sync | msg/connector_filter_msg.log |
+
+### Full verification
+
+| Item | Description |
+|---------|-----------|
+| Component | Full-Verification |
+| Log directory | /home/ds/run/`{Component ID}`/logs |
+| Error logs | error.log |
+| Operation logs | task.log |
+| Verification result file | /home/ds/run/`{Component ID}`/verify/`{subid}`/ |
+| File of inconsistent data and inconsistency reasons | /home/ds/run/`{Component ID}`/verify/`{subid}`/`{schema}`/diff/`{table_name}.diff` |
+| Correction SQL file that can be executed in the target | /home/ds/run/`{Component ID}`/verify/`{subid}`/`{schema}`/sql/`{table_name}.sql` |
+
+The value of `{subid}` starts from 1 and increments by 1 for each reverification.
+
+### Forward switchover
+
+Forward switchover is completed in Ghana. If you have selected **Reverse Incremental Migration**, a Store component and an Incr-Sync component for reverse incremental migration will be created.
+
+| Item | Description |
+|---------|-----------|
+| Component | Ghana |
+| Log directory | /home/admin/logs/ghana/Ghana |
+| Common error logs | common-error.log |
+| Common output logs | common-default.log |
+| Task logs | oms-step.log |
+| Background scheduling logs | oms-scheduler.log |
+
+### Reverse incremental migration
+
+The content is consistent with that of the "Incremental synchronization" section, except the component ID naming format. The ID of a component for reverse incremental migration contains the **reverse** keyword.
+
+### Management components
+
+| Component | Description |
+| --- | --- |
+| oms_console | The Ghana component, whose log directory is `/home/admin/logs/ghana/Ghana`. |
+| oms_drc_cm | The CM component, whose log directory is `/home/admin/logs/cm`. |
+| oms_drc_supervisor | The Supervisor component, whose log directory is `/home/admin/logs/supervisor`. |
+
+## Issues that May Occur During OMS Installation
+
+Log in to the container of OMS Community Edition and check whether its components are normal. If any component is abnormal, check its logs.
+
+```shell
+supervisorctl status
+```
+
+The following issues often occur during installation:
+
+* The port is occupied.
+
+* You do not have required privileges on the MetaDB of OMS Community Edition.
+
+* The Docker environment of some operating systems has compatibility issues. The service cannot be started due to errors related to file permissions. In this case, install OMS Community Edition in another system.
+
+* If the user system is cgroup v2, the status of the OMS Community Edition server is abnormal. This issue is resolved in OMS of a version later than V4.2.4.
+
+## Full/Incremental Migration Performance Tuning
+
+For more information, see [Incr-Sync or Full-Import tuning](https://en.oceanbase.com/docs/community-oms-en-10000000001658042).
+
+### Issues related to concurrency, Java virtual machine (JVM) memory, and number of records per slice
+
+Most performance issues can be resolved by referring to this section.
+
+| Issue type | Solution |
+|----------|--------------|
+| Concurrency | The degree of parallelism (DOP) for the source is specified by `source.workerNum`, and that for the target is specified by `sink.workerNum`. Generally, the same DOP is specified for the source and target during full migration. You do not need to specify a DOP for the source during incremental synchronization.
The DOP is subject to the number of CPU cores on the server and the maximum DOP can be four times the number of CPU cores. You also need to check whether any other migration task is running on the server. |
+|JVM memory | The JVM memory is specified by `coordinator.connectorJvmParam`. You mainly need to adjust the `-Xms8g` (initial memory), `-Xmx8g` (maximum memory), and `-Xmn4g` (new memory) parameters, which must conform to the following rules: - Initial memory = Maximum memory
- New memory = Maximum memory - 4 GB
- 1 GB of memory is allocated to one worker thread. For example, if the DOP is set to 32, the maximum memory must be set to 32 GB.
|
+| Number of records per slice | The number of records per slice is specified by the `source.sliceBatchSize` parameter, which defaults to `600`.
You can set the parameter to `10000` for a large table. If you set a larger value, much more memory will be consumed. You can determine whether to modify the `source.sliceBatchSize` parameter based on the `slice_queue` value in the `metrics.log` file in the `logs/msg/` directory. If the value of `slice_queue` is `0`, you need to increase the value of `source.sliceBatchSize`. The source worker thread pulls slices from the slice queue. The value of `slice_queue` being `0` indicates that no slice is available. In this case, the source worker thread will keep waiting. |
+
+In full migration, post-indexing is usually required to improve the full migration efficiency. If the target is OceanBase Database, you can configure the DOP for index creation based on `ob.parallel` in the `struct.transfer.config` system parameter.
+
+### Incremental synchronization
+
+The `source.splitThreshold` parameter specifies the transaction splitting threshold. If an incremental synchronization latency is caused by batch operations in the source, you can modify the `source.splitThreshold` parameter, which defaults to `128`. For batch `INSERT` operations, you can set the parameter to a large value no greater than `512`. For batch `UPDATE` or `DELETE` operations, you can set the parameter to a small value no less than `1`.
+
+### Analyze logs in the metrics.log file
+
+#### Identify bottlenecks
+
+Identify bottlenecks throughout the following link: slicing > reading data from the source > distributing data > writing data to the target.
+
+* If the value of `slice_queue` is greater than `0`, no bottleneck exists in slicing. The value of `slice_queue` being `0` indicates that slicing is slow. In this case, you can increase the value of the `source.sliceBatchSize` parameter. In a multi-table scenario, you can also increase the value of the `source.sliceWorkerNum` parameter.
+
+* If the value of `source_worker_num` is smaller than that of `source_worker_num_all`, no bottleneck exists in reading data from the source.
+
+* If the value of `sink_worker_num` is smaller than that of `sink_worker_num_all`, no bottleneck exists in writing data to the target.
+
+* If the value of `dispatcher.ready_execute_batch_size` is `0`, no bottleneck exists in writing. If the value of `ready_execute_batch_size` is greater than `0`, writing is slow.
+
+* If the value of `dispatcher.wait_dispatch_record_size` is `0`, no bottleneck exists in data distribution. If the value of `wait_dispatch_record_size` is greater than `0`, a bottleneck exists in partition calculation in OMS. Partition calculation determines to which partition data is to be distributed and is time-consuming. Therefore, data records for which partition calculation is to be performed are often accumulated for a partitioned table. In a direct load scenario, you can set `sink.enablePartitionBucket` to `false` to disable partition calculation. As a result, hotspot data may exist. For more information, see [Suspected hotspot issues](https://www.oceanbase.com/knowledge-base/oms-ee-1000000000253328).
+
+* If the JVM memory is insufficient, full garbage collection (GC) may occur, leading to significantly compromised overall efficiency, which may be mistakenly considered as a database disconnection error. You can log in to the container of OMS Community Edition to check the GC status.
+
+* If batch operations are performed in the source, we recommend that you throttle the batch operations.
+
+ ```json
+ su - ds
+ ps -ef|grep "Component ID"
+
+ /opt/alibaba/java/bin/jstat -gcutil {pid} 1s
+ S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
+ 0.00 18.27 64.08 0.90 97.11 93.45 7 0.374 0 0.000 0.374
+ 0.00 18.27 64.08 0.90 97.11 93.45 7 0.374 0 0.000 0.374
+ ```
+
+ If full GC occurs frequently, you need to increase the JVM memory.
+
+ ```JSON
+
+ {
+ "jvm": {
+ "JVM": "{\"heapMemoryMax\":7782,\"heapMemoryInit\":8192,\"heapMemoryUsed\":1072,\"heapMemoryCommitted\":7782,\"noHeapMemoryMax\":0,\"noHeapMemoryInit\":2,\"noHeapMemoryUsed\":78,\"noHeapMemoryCommitted\":83,\"gcInfoList\":[{\"name\":\"ParNew\",\"count\":6,\"costMs\":770},{\"name\":\"ConcurrentMarkSweep\",\"count\":1,\"costMs\":362}],\"threadCount\":34}"
+ },
+ "dataflow": {
+ "slice_queue": 0
+ },
+ "os": {
+ "OS": "{\"cpu\":0.5210029306414848,\"sysCpu\":62.941847206385404}"
+ },
+ "sink": {
+ "sink_worker_num": 0,
+ "ob_watermark_detect_times": 231,
+ "sink_request_time": 198.43,
+ "source_iops": 0.0,
+ "sink_total_transaction": 2384.0,
+ "ob_exceed_mem_high_watermark_times": 0,
+ "sink_total_record": 23383.0,
+ "paused_time_ms": 0.0,
+ "sink_commit_time": 3363.16,
+ "sink_worker_num_all": 8,
+ "shardTime": 0.0,
+ "sink_total_bytes": 8739678.0,
+ "sink_delay": 1717642529661,
+ "paused_total_time_ms": 0.0,
+ "ob_free_memory": 92,
+ "rps": 41.42,
+ "tps": 3.1,
+ "ob_exceed_cpu_high_watermark_times": 0,
+ "iops": 3921.59,
+ "sinkSlowRoutes": "",
+ "sink_execute_time": 17.25,
+ "ob_free_cpu": -1
+ },
+ "source": {
+ "source_read_time": 0.0,
+ "source_rps": 0.0,
+ "source_slice_time": 0.0,
+ "source_worker_num_all": 8,
+ "source_worker_num": 0
+ },
+ "dispatcher": {
+ "wait_dispatch_record_size": 0,
+ "ready_execute_batch_size": 0
+ },
+ "frame": {
+ "SourceTaskManager.createdSourceSize": 0,
+ "queue_slot1.batchAccumulate": 0,
+ "frame.throttle.throttle_memory_remain": "2.14748365E9",
+ "queue_slot1.batchCount": 3715.0,
+ "queue_slot1.tps": 0.0
+ }
+ }
+ ```
+
+### Incremental synchronization delay caused by suspected hotspots
+
+For more information, see [Suspected hotspot issues](https://www.oceanbase.com/knowledge-base/oms-ee-1000000000253328).
+
+### Full verification
+
+* For more information, see the "Full migration" section of this topic.
+
+* Specify the `task.sourceMasterSection.excludeColumn` parameter to exclude columns of the large object (LOB) type and columns that do not require verification. For more information, see [Parameters of the Full-Verification component](https://en.oceanbase.com/docs/community-oms-en-10000000001658037).
+
+## Data Issues in Full Verification
+
+
+
+### How to dump data from a Store component
+
+```shell
+# The checkpoint is a Unix timestamp.
+# For the 17006 and p_47qaxxxu8_source-000-0 error codes, see the following figure.
+# You can locate data by table name, time, and column content.
+wget 'localhost:17006/p_47qaxxxsu8_source-000-0' --post-data 'filter.conditions=*.*.*&checkpoint=1667996779'
+```
+
+
+
+## Typical Scenarios and Features
+
+### Multi-table aggregation
+
+Here is an example of migrating data from multiple source tables to a single non-partitioned or partitioned table in the target.
+
+```SQL
+-- Source table, primary key ID, unique key ID
+CREATE TABLE test_01(id bigint not null AUTO_INCREMENT,uk_id bigint not null,...);
+
+CREATE TABLE test_02(id bigint not null AUTO_INCREMENT,uk_id bigint not null,...);
+
+-- Target table
+CREATE TABLE test(id_new bigint not null AUTO_INCREMENT,uk_id bigint not null,...,
+ PRIMARY KEY (id_new,uk_id),
+ unique key(uk_id))
+PARTITION BY HASH(uk_id)
+PARTITIONS 4;
+```
+
+Common issues are described as follows:
+
+* Source tables need to be batch renamed during the creation of a data migration task. To batch rename tables, perform the following operations:
+
+ * Select the **Match Rules** option.
+
+ * Use the `src_schema.test_*=dst_schema.test` setting.
+
+* If the auto-increment ID column is used in multiple source tables, a new column name is specified as the auto-increment primary key in the target table. In this case:
+
+ * Do not migrate the ID column in the source table to the target table, and use the `id_new` column as an auto-increment column in the target table.
+
+ * Set `sink.ignoreRedunantColumnsReplicate` to `true` to ignore the ID column during full migration.
+
+ * Set `sink.ignoreRedunantColumnsReplicate` to `true` to ignore the ID column during incremental synchronization.
+
+* In OceanBase Database, the primary key must contain the partitioning key if the target is a partitioned table. To enable support for data verification, perform the following operations:
+
+ * Set `task.sourceMasterSection.matchAllColumn` to `false` to skip the ID column during full verification. The source table must have a non-null unique key. Otherwise, verification is not supported.
+
+ * Use the `filter.verify.inmod.tables=.*;.*;.*` setting to enable the IN mode for full verification. For more information, see [Parameters of the Full-Verification component](https://en.oceanbase.com/docs/community-oms-en-10000000001658037).
+
+### Migration of a table without a primary key from OceanBase Database, with a hidden column added in the target
+
+When migrating a table without a primary key from OceanBase Database Community Edition, OMS Community Edition will use a hidden column `__pk_increment` as the primary key. During schema migration, an `OMS_PK_INCRMT` column will be added to the target table.
+
+* The `OMS_PK_INCRMT` column will be deleted after a forward switchover.
+
+* If no forward switchover is performed and the target database serves as the source database in the next task, an exception will occur. In this case, you must manually delete the `OMS_PK_INCRMT` column.
+
+### Direct load
+
+Apart from concurrency parameters, the direct load performance is also subject to the `sink.serverParallel` parameter, which defaults to `8`. This parameter will affect the number of worker threads and concurrency for direct load tasks on the OBServer node.
+
+### Reverse incremental migration
+
+If you want to roll back the database or use the source database as a standby database, we recommend that you select **Reverse Incremental Migration** when you create a data migration task. When you migrate data from a MySQL database to OceanBase Database Community Edition, you need to manually create a transaction database named `omstxndb` in the MySQL database, which will be used by OMS Community Edition. If you do not create this transaction database, an error prompting that the `omstxndb` database does not exist will be returned.
+
+### Active-active disaster recovery
+
+If double write or canary switching is required, you can use the active-active disaster recovery feature of OMS Community Edition. At present, this feature is supported when you migrate data from a MySQL database to OceanBase Database Community Edition, or migrate data within OceanBase Database Community Edition. OMS Community Edition automatically sets cyclical replication prevention parameters. In an active-active disaster recovery scenario, all tables must have a primary key or unique key.
+
+1. Two databases named A and B exist.
+
+2. An application writes data to A and B based on certain rules.
+
+ Non-double write means that data written to one database will not be written to the other database.
+
+3. Both A and B store all data of the application.
+
+
+
+### Full verification
+
+Two full verification modes are supported:
+
+* Default mode: Data is queried based on the slice scope in both the source and target databases.
+
+* IN mode: Data is queried based on the slice scope in the source database. Data is queried in the target database by using the primary key or unique key in the data queried from the source database. You can enable the IN mode by using the `filter.verify.inmod.tables` parameter.
+
+ Here are some examples:
+
+ * Enable IN mode verification for all tables of the current task: `filter.verify.inmod.tables=.*;.*;.*`
+
+ * Enable IN mode verification for the `T1` table in the `D1` database: `filter.verify.inmod.tables=D1;T1;.*`
+
+ * Enable IN mode verification for the `T1` and `T2` tables in the `D1` database: `filter.verify.inmod.tables=D1;T1;.*|D1;T2;.*`
+
+ * Enable IN mode verification for the `T1` and `T2` tables in the `D1` database and the `T3` and `T4` tables in the `D2` database: `filter.verify.inmod.tables=D1;T1;.*|D1;T2;.*|D2;T3;.*|D2;T4;.*`
+
+## System Views Used in OMS Community Edition
+
+### MySQL
+
+#### System tables and views
+
+| Table/View | Description |
+| --- | --- |
+| information_schema.SCHEMATA | Stores information about schemas. |
+| information_schema.tables | Stores information about tables. |
+| information_schema.columns | Stores information about columns. |
+| information_schema.STATISTICS | Stores information about table indexes. |
+
+#### SQL statements
+
+```SQL
+SET TIME_ZONE='%s';
+
+SET sql_mode='';
+
+SET names 'utf8mb4';
+
+SET foreign_key_checks = off;
+
+SELECT version();
+
+SELECT 1;
+
+-- Query information about all schemas.
+SELECT CATALOG_NAME, SCHEMA_NAME, DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME, SQL_PATH
+FROM `information_schema`.`SCHEMATA`
+
+-- Query information about all tables.
+SELECT NULL,TABLE_SCHEMA,TABLE_NAME,TABLE_ROWS, TABLE_COLLATION, ENGINE
+FROM information_schema.tables WHERE TABLE_TYPE='BASE TABLE' AND TABLE_SCHEMA NOT IN('mysql','information_schema','performance_schema')
+
+-- Query the database engine of a table.
+SELECT `ENGINE` FROM `information_schema`.`tables` WHERE TABLE_SCHEMA = '%s' AND TABLE_NAME = '%s'
+
+-- Query the character set of a table.
+SELECT TABLE_COLLATION FROM information_schema.tables WHERE TABLE_SCHEMA = '%s' AND TABLE_NAME = '%s'
+
+-- Query information about columns.
+SELECT `COLUMN_NAME` ,upper(`COLUMN_TYPE`) ,`CHARACTER_MAXIMUM_LENGTH` ,`NUMERIC_PRECISION`,`NUMERIC_SCALE`
+FROM information_schema.columns WHERE table_schema=? AND table_name=? ORDER BY ORDINAL_POSITION ASC
+
+-- Query all views.
+SELECT TABLE_NAME, TABLE_SCHEMA, VIEW_DEFINITION FROM information_schema.views
+WHERE TABLE_SCHEMA IN ('xx');
+
+
+-- Query only regular columns, excluding generated columns.
+SELECT `COLUMN_NAME` ,upper(`COLUMN_TYPE`) ,`CHARACTER_MAXIMUM_LENGTH` ,`NUMERIC_PRECISION`,`NUMERIC_SCALE`
+FROM information_schema.columns WHERE table_schema=? AND table_name=? AND (GENERATION_EXPRESSION='' or GENERATION_EXPRESSION is null) ORDER BY ORDINAL_POSITION ASC
+
+-- Query indexes.
+SELECT INDEX_NAME,NON_UNIQUE,SEQ_IN_INDEX,COLUMN_NAME,SUB_PART FROM information_schema.STATISTICS WHERE table_schema=? AND table_name=?
+AND concat(index_schema,'.',index_name) NOT IN (
+SELECT concat(index_schema,'.',index_name) FROM information_schema.STATISTICS
+WHERE table_schema=? AND table_name=? AND upper(nullable)='YES')
+ORDER BY INDEX_NAME ASC, SEQ_IN_INDEX ASC
+
+-- Query partitions.
+SELECT TABLE_SCHEMA, TABLE_NAME,PARTITION_NAME,SUBPARTITION_NAME,PARTITION_METHOD,PARTITION_EXPRESSION,SUBPARTITION_METHOD,SUBPARTITION_EXPRESSION
+FROM information_schema.PARTITIONS
+
+-- Query constraints.
+SELECT REFERENCED_TABLE_SCHEMA, REFERENCED_TABLE_NAME, TABLE_SCHEMA, TABLE_NAME, CONSTRAINT_NAME,REFERENCED_COLUMN_NAME, COLUMN_NAME FROM information_schema.KEY_COLUMN_USAGE
+```
+
+### MySQL tenant of OceanBase Database
+
+#### System tables and views
+
+| Table/View | Description |
+| --- | --- |
+| information_schema.SCHEMATA | Stores information about schemas. |
+| information_schema.tables | Stores information about tables. |
+| information_schema.columns | Stores information about columns. |
+| information_schema.STATISTICS | Stores information about table indexes. |
+| information_schema.PARTITIONS | Stores information about partitions. |
+| oceanbase.gv$memstore | Stores memory usage information. |
+| oceanbase.gv$sysstat | Stores CPU utilization information. |
+| oceanbase.gv$table | Stores table IDs. |
+| oceanbase.__tenant_virtual_table_index | Stores information about indexes. |
+| The following system tables are required for dividing data into macroblocks. | |
+| oceanbase.__all_tenant | Stores information about tenants. |
+| oceanbase.__all_database | Stores information about databases. |
+| oceanbase.__all_table | Stores information about tables. |
+| oceanbase.__all_part | Stores information about partitions. |
+| oceanbase.__all_meta_table | Stores table metadata. |
+| oceanbase.__all_virtual_database | Stores information about databases. |
+| oceanbase.__all_virtual_table | Stores information about tables. |
+| oceanbase.__all_virtual_proxy_partition | Stores information about partitions. |
+| oceanbase.__all_meta_table | Stores metadata. |
+| oceanbase.__all_virtual_partition_item | Stores information about subpartitions. |
+| oceanbase.__all_virtual_partition_sstable_macro_info | Stores information about macroblocks. |
+
+
+ Note
+ Macroblock information can be queried only from the sys tenant.
+
+
+#### SQL statements
+
+```SQL
+-- Query information about all schemas.
+SELECT CATALOG_NAME, SCHEMA_NAME, DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME, SQL_PATH
+FROM `information_schema`.`SCHEMATA`
+
+-- Query information about all tables.
+SELECT NULL,TABLE_SCHEMA,TABLE_NAME,TABLE_ROWS, TABLE_COLLATION, ENGINE
+FROM information_schema.tables WHERE TABLE_TYPE='BASE TABLE' AND TABLE_SCHEMA NOT IN('mysql','information_schema','performance_schema')
+
+-- Query the database engine of a table.
+SELECT `ENGINE` FROM `information_schema`.`tables` WHERE TABLE_SCHEMA = '%s' AND TABLE_NAME = '%s'
+
+-- Query the character set of a table.
+SELECT TABLE_COLLATION FROM information_schema.tables WHERE TABLE_SCHEMA = '%s' AND TABLE_NAME = '%s'
+
+-- Query column information.
+SELECT `COLUMN_NAME` ,upper(`COLUMN_TYPE`) ,`CHARACTER_MAXIMUM_LENGTH` ,`NUMERIC_PRECISION`,`NUMERIC_SCALE`
+FROM information_schema.columns WHERE table_schema=? AND table_name=? ORDER BY ORDINAL_POSITION ASC
+
+
+-- Query only regular columns, excluding generated columns.
+SELECT `COLUMN_NAME` ,upper(`COLUMN_TYPE`) ,`CHARACTER_MAXIMUM_LENGTH` ,`NUMERIC_PRECISION`,`NUMERIC_SCALE`
+FROM information_schema.columns WHERE table_schema=? AND table_name=? AND (GENERATION_EXPRESSION='' or GENERATION_EXPRESSION is null) ORDER BY ORDINAL_POSITION ASC
+
+-- Query indexes.
+SELECT INDEX_NAME,NON_UNIQUE,SEQ_IN_INDEX,COLUMN_NAME,SUB_PART FROM information_schema.STATISTICS WHERE table_schema=? AND table_name=?
+AND concat(index_schema,'.',index_name) NOT IN (
+SELECT concat(index_schema,'.',index_name) FROM information_schema.STATISTICS
+WHERE table_schema=? AND table_name=? AND upper(nullable)='YES')
+ORDER BY INDEX_NAME ASC, SEQ_IN_INDEX ASC
+
+-- Query partition information.
+SELECT PARTITION_NAME,SUBPARTITION_NAME FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA='{}' AND TABLE_NAME='{}'
+
+-- Query the partitioning key expression.
+SELECT DISTINCT PARTITION_EXPRESSION,SUBPARTITION_EXPRESSION FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=? AND TABLE_NAME=?
+
+
+-- Query tenant information.
+SELECT tenant_id FROM oceanbase.__all_tenant WHERE tenant_name = '%s'
+
+-- Query indexes in a table.
+SELECT key_name, NON_UNIQUE,SEQ_IN_INDEX,COLUMN_NAME,`null` nullable FROM oceanbase.__tenant_virtual_table_index WHERE table_id = ?
+
+-- Query the ID of a table.
+-- Versions earlier than 20200
+SELECT %s b.table_id FROM oceanbase.__all_database a, oceanbase.__all_table b WHERE a.database_id = b.database_id AND a.tenant_id = %d AND a.database_name = '%s' AND b.table_name = '%s'
+
+-- Versions later than 20200
+SELECT %s b.table_id FROM oceanbase.__all_virtual_database a, oceanbase.__all_virtual_table b WHERE a.database_id = b.database_id AND a.tenant_id = %d AND a.database_name = '%s' AND b.table_name = '%s'
+
+-- Query partition information.
+-- Versions earlier than 20200
+SELECT %s part_id,part_name FROM oceanbase.__all_part WHERE table_id = %d AND part_name IS NOT NULL AND part_name<>''
+
+-- Versions later than 20200
+SELECT %s part_id,part_name FROM oceanbase.__all_virtual_proxy_partition WHERE table_id = %d AND part_name IS NOT NULL AND part_name<>''
+
+-- Query subpartition information.
+SELECT %s partition_id,case when subpart_name is null then concat(part_name,'sp',subpart_id) ELSE subpart_name END subpart_name FROM oceanbase.__all_virtual_partition_item WHERE table_id = %d AND partition_level>1
+
+-- Query the ID of a table.
+SELECT table_id FROM oceanbase.gv$table WHERE database_name=? AND table_name=?
+
+-- Query macroblock information. store_type=1 indicates normal information, and store_type=4 indicates minor compaction information.
+-- Versions earlier than 20200
+SELECT %s partition_id OMS_PARTITION_ID,data_seq OMS_DATA_SEQ,macro_range OMS_MACRO_RANGE,row_count OMS_ROW_COUNT FROM oceanbase.__all_virtual_partition_sstable_macro_info
+WHERE tenant_id=%d AND table_id = %d AND store_type=1 AND macro_range NOT LIKE '%%]always true' AND macro_range<>'(MIN ; MAX]' AND macro_range LIKE '%%]'
+AND (svr_ip,svr_port,partition_id) IN (SELECT svr_ip, svr_port,partition_id FROM oceanbase.__all_meta_table
+WHERE tenant_id=%d AND table_id = %d AND ROLE = 1)
+ORDER BY partition_id,data_seq
+
+-- Versions later than 20200
+SELECT %s partition_id OMS_PARTITION_ID,data_seq OMS_DATA_SEQ,macro_range OMS_MACRO_RANGE,row_count OMS_ROW_COUNT FROM oceanbase.__all_virtual_partition_sstable_macro_info
+WHERE tenant_id=%d AND table_id = %d AND store_type=1 AND macro_range NOT LIKE '%%]always true' AND macro_range<>'(MIN ; MAX]' AND macro_range LIKE '%%]'
+AND (svr_ip,svr_port,partition_id) IN (SELECT svr_ip, svr_port,partition_id FROM oceanbase.__all_virtual_meta_table
+WHERE tenant_id=%d AND table_id = %d AND ROLE = 1)
+ORDER BY partition_id,data_seq
+
+-- Memory resource exhaustion prevention
+SELECT /*+query_timeout(5000000)*/ total, freeze_trigger,mem_limit FROM oceanbase.gv$memstore
+
+-- CPU resource exhaustion prevention
+SELECT min(100-round(cpu_usage.value * 100 / cpu_limit.value)) cpu_free_percent
+FROM oceanbase.gv$sysstat cpu_usage, oceanbase.gv$sysstat cpu_limit
+WHERE cpu_usage.name = 'cpu usage' AND cpu_limit.name = 'max cpus'
+AND cpu_usage.svr_ip = cpu_limit.svr_ip
+```
+
+## Others
+
+### Hot update for the CDC library
+
+OceanBase Database of each version provides a corresponding Change Data Capture (CDC) library for pulling incremental logs. The Store component of OMS Community Edition loads the CDC dynamic library to pull incremental data from OceanBase Database.
+
+The following table lists the subdirectories in the `/home/ds/lib64/reader` directory of the Store component that are corresponding to OceanBase CDC libraries of different versions.
+
+| Store component | OceanBase CDC library |
+|------------------------|-----------------------|
+| ob-ce-reader | Hot updates not supported |
+| ob-ce-4.x-reader | OceanBase Database of a version from V4.0.0 to V4.2.1 |
+| ob-ce-4.2.2-reader | OceanBase Database of a version from V4.2.2 to V4.3.0 |
+| ob-ce-4.3-reader | OceanBase Database V4.3.0 and later |
+
+The hot update procedure is as follows:
+
+1. Download the RPM package of OceanBase CDC from [OceanBase Download Center](https://en.oceanbase.com/softwarecenter).
+
+2. Run the following command to decompress the RPM package: `rpm2cpio oceanbase-ce-cdc-x.x.x.x-xxxx.el7.x86_64.rpm|cpio -idmu --quiet`.
+
+3. After the decompression, the following files appear in the `./home/admin/oceanbase/lib64` directory:
+
+ ```shell
+ libobcdc.so.x.x.x.x
+ libobcdc.so.x -> libobcdc.so.x.x.x.x
+ libobcdc.so -> libobcdc.so.x
+ ```
+
+4. Log in to the container of OMS Community Edition and run the `cd` command to go to the `/home/ds/lib64/reader` directory. Find the corresponding `ob-ce-xxx-reader` directory based on the version of OceanBase Database.
+
+5. Back up the original files in the `ob-ce-xxx-reader` directory.
+
+6. Copy the files in the `./home/admin/oceanbase/lib64` directory extracted from the RPM package to the `ob-ce-xxx-reader` directory.
+
+Then, all new Store components will use the updated CDC library. To perform a hot update for an existing Store component, perform the following steps:
+
+1. Go to the runtime directory `/home/ds/store/store{port}/lib64/reader` of the Store component. The directory structure is consistent with that of `/home/ds/lib64/reader`.
+
+2. Copy the files in the `./home/admin/oceanbase/lib64` directory extracted from the RPM package to the `/home/ds/store/store{port}/lib64/reader/ob-ce-xxx-reader` directory.
+
+3. Log in to the console of OMS Community Edition and pause the Store component. For more information, see [Start and pause a store](https://en.oceanbase.com/docs/community-oms-en-10000000001658190).
+
+4. Run the following command to check whether the Store process has been stopped. If not, run the `kill -9` command.
+
+ ```shell
+ ps -ef | grep store{port}
+ ```
+
+5. In the console of OMS Community Edition, start the Store component.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction.md b/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction.md
new file mode 100644
index 000000000..e000d236d
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction.md
@@ -0,0 +1,523 @@
+---
+title: Background Knowledge of ODP
+weight: 1
+---
+
+> If you are not familiar with OceanBase Database Proxy (ODP) of OceanBase Database, we recommend that you quickly browse this document to understand the background knowledge related to ODP, before you read the troubleshooting manual of ODP Community Edition.
+>
+> **If you are pressed for time, you can just read the "Benefits of ODP" and "Implementation logic of ODP routing" sections of this topic. **
+
+## Troubleshooting Mind Map for ODP
+If you already know about ODP and just want to troubleshoot the issues encountered during the use of ODP, you can go to the following sections based on the following figure.
+
+
+
+
+## What is ODP
+Although ODP adds a hop to the database access link, ODP serves as a proxy server that provides various features and benefits. See the following figure.
+
+
+
+As shown in the preceding figure, the application is a business application and is allocated with three ODP nodes that each run an obproxy process. In actual deployment, a load balancer such as F5, LVS, or Nginx is deployed between the ODP nodes and the application to distribute requests to the ODP nodes, to which OBServer nodes are connected. Six OBServer nodes are deployed in the sample deployment architecture.
+
+The reasons why ODP is required are as follows:
+
+- Data routing
+
+ ODP can obtain information about data distribution on OBServer nodes and forward an SQL statement of a user to the OBServer node where the required data is located. This improves execution efficiency. For example, ODP can forward the SQL statement `insert into t1 where c1 in P1` to the OBServer node that contains the leader named `P1` in Zone 2 and the SQL statement `update t1 where c1 in P2` to the OBServer node that contains the leader named `P2` in Zone 1.
+
+- Connection management
+
+ An OceanBase cluster containing a large number of OBServer nodes is highly susceptible to connection status changes caused by maintenance and OBServer node problems. If one of the preceding exceptions occurs when a client is directly connected to an OBServer node, the connection will be closed. ODP masks the complexity of distributed OBServer nodes. If a client is connected to ODP, ODP can ensure the stability of the connection and manage the status of OBServer nodes in complex business scenarios.
+
+Based on ODP, a distributed database can be used in a similar manner as a standalone database.
+
+## Benefits of ODP
+
+ODP is a key component of OceanBase Database and provides the following benefits:
+
+- High-performance forwarding
+
+ ODP is fully compatible with the MySQL protocol and supports the proprietary protocol of OceanBase. It adopts the multi-threaded asynchronous framework and transparent streaming forwarding to ensure high-performance data forwarding. In addition, it consumes minimal cluster resources.
+
+- Optimal routing
+
+ ODP fully considers the location of replicas that are included in each user request, read/write split routing strategy configured by each user, the optimal procedure for multi-region deployment of OceanBase Database, and the status and load of each OBServer node. ODP routes a user request to the optimal OBServer node and ensures the performance of OceanBase Database operations.
+
+- Connection management
+
+ For the physical connections of a client, ODP maintains its connections to multiple OBServer nodes at the backend. It also adopts the incremental synchronization solution based on version numbers to maintain the session status of connections to each OBServer node. This ensures efficient client access to each OBServer node.
+
+- Security and reliability
+
+ ODP supports data access by using SSL and is compatible with the MySQL protocol to meet the security requirements of users.
+
+- Easy O&M
+
+ ODP is stateless and supports unlimited horizontal scale-out. It allows you to access multiple OceanBase clusters at the same time. You can monitor the status of OceanBase Database in real time by using various internal commands. This allows you to perform routine O&M in an efficient manner.
+
+ODP Community Edition is fully open source under Mulan Public License, Version 2 (Mulan PubL v2). You can copy and use the source code free of charge. You must follow the requirements outlined in the license when you modify or distribute the source code.
+
+## High Performance Based on ODP Routing
+
+High performance is an important characteristic of OceanBase Database. Routing affects performance mainly in terms of network communication overheads. ODP reduces network communication overheads and improves overall performance by perceiving data distribution and geographic locations of servers. This section describes routing strategies in terms of performance.
+
+This section answers the following three questions:
+
+- What is the implementation logic of ODP routing?
+
+- What types of SQL execution plans are supported by ODP?
+
+- How can I view resource distribution information?
+
+### Implementation logic of ODP routing
+
+As an important feature of OceanBase Database, routing enables quick data access in a distributed architecture.
+
+A partition is a basic unit of data storage in OceanBase Database. After a table is created, mappings between the table and its partitions are generated. A non-partitioned table is mapped to one partition. A partitioned table is mapped to multiple partitions.
+
+Based on the routing feature, a query can be accurately routed to the OBServer node where the desired data is located. In addition, a read request without high consistency requirements can be routed to an OBServer node where a replica is located. This maximizes the usage of server resources. During the routing process, SQL statements, configuration rules, and OBServer node status are used as the input, and an available OBServer node IP address is generated as the output.
+
+The following figure shows the routing logic.
+
+
+
+1. Parse the SQL request and extract information.
+
+ The custom parser module of ODP is used to parse SQL statements. ODP needs only to parse the database names, table names, and hints in DML statements. No complex expression analysis is required.
+
+2. Obtain location information from the location cache.
+
+ ODP obtains the location of the replica involved in the SQL request. ODP attempts to obtain the routing table first from the local cache and then from the global cache. If the preceding operations fail, ODP initiates an asynchronous query task to query the routing table from the OBServer node. ODP uses the trigger mechanism to update the routing table. ODP forwards SQL requests to corresponding OBServer nodes based on the routing table. If an OBServer node finds that it cannot process an SQL request, it places the feedback in the response packet and sends the packet to ODP. ODP determines whether to forcibly update the routing table in the local cache based on the feedback. Generally, the routing table changes only when an OBServer node undergoes a major compaction or when leader switchover is caused by load balancing.
+
+3. Determine routing rules.
+
+ ODP must determine the optimal routing rule based on the actual situation. For example, DML requests for strong-consistency reads are routed to the OBServer node where the partition leader is located, whereas DML requests for weak-consistency reads and other requests are evenly distributed to the OBServer nodes where the leader and followers are located. If an OceanBase cluster is deployed across regions, ODP provides logical data center (LDC)-based routing to preferentially route requests to an OBServer node in the same IDC, then an OBServer node in the same region, and finally an OBServer node in a different region. If the OceanBase cluster adopts the read-write splitting mode, ODP provides rules such as RZ-first, RZ-only, and non-major-compaction-first. You can set these rules based on your business needs. Here, RZ refers to read-only zone. In practice, the previous rules can be combined to generate a specific routing rule.
+
+4. Select a target OBServer node.
+
+ ODP selects an OBServer node from the obtained routing table based on the determined routing rule and forwards the request to the OBServer node after the OBServer node passes the blocklist and graylist checks.
+
+### Types of SQL execution plans
+
+A partition is a basic unit for data storage. When you create a table, mappings between the table and its partitions are automatically created. A non-partitioned table is mapped to one partition, and a partitioned table can be mapped to multiple partitions. Each partition contains one leader and multiple followers. By default, data is read from and written to the leader.
+
+In OceanBase Database, an execution plan is generated before an SQL statement is executed, and the executor schedules different operators for evaluation based on the execution plan. OceanBase Database supports local, remote, and distributed plans.
+
+This section describes how to read data from a partition leader in strong-consistency mode based on the three types of execution plans.
+
+#### Local plan
+
+All partition leaders involved in an SQL statement with a local plan are stored on the OBServer node where the current session resides. The OBServer node does not need to interact with other nodes during execution of the SQL statement.
+
+
+
+You can execute the `EXPLAIN` statement to query a local plan. The output is as follows:
+
+```shell
+========================================
+|ID|OPERATOR |NAME|EST. ROWS|COST |
+----------------------------------------
+|0 |HASH JOIN | |98010000 |66774608|
+|1 | TABLE SCAN|T1 |100000 |68478 |
+|2 | TABLE SCAN|T2 |100000 |68478 |
+========================================
+```
+
+#### Remote plan
+
+All partition leaders involved in an SQL statement with a remote plan are stored on an OBServer node other than the one where the current session resides. The current OBServer node must forward the SQL statement or subplan.
+
+
+
+You can execute the `EXPLAIN` statement to query a remote plan, which contains `EXCHANGE REMOTE` operators. The output is as follows:
+
+```shell
+==================================================
+|ID|OPERATOR |NAME|EST. ROWS|COST |
+--------------------------------------------------
+|0 |EXCHANGE IN REMOTE | |98010000 |154912123|
+|1 | EXCHANGE OUT REMOTE| |98010000 |66774608 |
+|2 | HASH JOIN | |98010000 |66774608 |
+|3 | TABLE SCAN |T1 |100000 |68478 |
+|4 | TABLE SCAN |T2 |100000 |68478 |
+==================================================
+```
+
+In the preceding plan, Operator 0 `EXCHANGE IN REMOTE` and Operator 1 `EXCHANGE OUT REMOTE` execute operations on different OBServer nodes.
+
+The OBServer node where Operator 0 resides generates a remote plan for an SQL statement forwarded by ODP, and forwards the SQL statement or the subplans generated by Operators 1 to 4 to the OBServer node where the partition leader resides.
+
+The OBServer node where Operators 1 to 4 reside executes the `HASH JOIN` operation, and returns the result to the OBServer node where Operator 0 resides through Operator 1.
+
+Finally, the OBServer node where Operator 0 resides receives the result through Operator 0, and further returns the result to the upper layer.
+
+#### Distributed plan
+
+A distributed plan does not define the relationship between partition leaders involved in the SQL statement and the current session. You can create a distributed plan for an SQL statement that needs to access multiple partitions with their leaders distributed on different OBServer nodes.
+
+A distributed plan is scheduled in parallel execution mode and divided into multiple steps during scheduling. Each step is called a data flow operation (DFO).
+
+
+
+You can execute the `EXPLAIN` statement to query a distributed plan, which contains `EXCHANGE DISTR` operators. The output is as follows:
+
+```shell
+================================================================
+|ID|OPERATOR |NAME |EST. ROWS|COST |
+----------------------------------------------------------------
+|0 |PX COORDINATOR | |980100000|1546175452|
+|1 | EXCHANGE OUT DISTR |:EX10002|980100000|664800304 |
+|2 | HASH JOIN | |980100000|664800304 |
+|3 | EXCHANGE IN DISTR | |200000 |213647 |
+|4 | EXCHANGE OUT DISTR (HASH)|:EX10000|200000 |123720 |
+|5 | PX BLOCK ITERATOR | |200000 |123720 |
+|6 | TABLE SCAN |T1 |200000 |123720 |
+|7 | EXCHANGE IN DISTR | |500000 |534080 |
+|8 | EXCHANGE OUT DISTR (HASH)|:EX10001|500000 |309262 |
+|9 | PX BLOCK ITERATOR | |500000 |309262 |
+|10| TABLE SCAN |T2 |500000 |309262 |
+================================================================
+```
+
+All partition leaders involved in a local or remote plan reside on a single OBServer node. ODP is designed to use better-performing local plans instead of remote plans as much as possible.
+
+Without ODP, an OBServer node must generate a remote plan for an SQL statement and then forward the remote plan. In this case, the SQL statement must be processed by the parser and the resolver, and the optimizer must rewrite the SQL statement and select an optimal execution plan. Even so, the forwarded plan may still be a subplan with high network transmission costs.
+
+However, ODP can forward an SQL statement by simply parsing the SQL statement and obtaining partition information. For more information, see “Implementation logic of ODP routing”. The overall process is much simpler than that of the preceding method.
+
+If you have a large number of SQL statements whose table-based routing types are remote plans, the routing of the SQL statements may be abnormal. You can check the `plan_type` column in the `oceanbase.GV$OB_SQL_AUDIT` view for verification. You can query the number of execution plans by type. Here is a sample SQL statement:
+
+```sql
+MySQL [oceanbase]> select plan_type, count(1) from gv$ob_sql_audit where
+request_time > time_to_usec('2021-08-24 18:00:00') group by plan_type;
+```
+
+The output is as follows:
+
+```shell
++-----------+----------+
+| plan_type | count(1) |
++-----------+----------+
+| 1 | 17119 |
+| 0 | 9614 |
+| 3 | 4400 |
+| 2 | 23429 |
++-----------+----------+
+4 rows in set
+```
+
+The value of `plan_type` can be `1`, `2`, or `3`, indicating a local plan, remote plan, or distributed plan, respectively. Generally, `0` indicates an SQL statement without a plan, for example, `set autocommit=0/1` and `commit`.
+
+### Resource distribution information
+
+OceanBase Database uses ODP to provide SQL routing. This section first describes how to view the data locations for you to better understand the SQL routing strategies.
+
+#### View the locations of tenant resource units
+
+ODP must know the locations of tenant resources before it can accurately route SQL statements to optimal OBServer nodes. The locations are stored in the location cache. You can find the locations of tenant resources by using either of the following methods:
+
+- Query resource locations from the `sys` tenant
+
+ ```sql
+ select
+ t1.name resource_pool_name,
+ t2.`name` unit_config_name,
+ t2.max_cpu,
+ t2.min_cpu,
+ round(t2.memory_size / 1024 / 1024 / 1024) max_mem_gb,
+ round(t2.memory_size / 1024 / 1024 / 1024) min_mem_gb,
+ t3.unit_id,
+ t3.zone,
+ concat(t3.svr_ip, ':', t3.`svr_port`) observer,
+ t4.tenant_id,
+ t4.tenant_name
+ from
+ __all_resource_pool t1
+ join __all_unit_config t2 on (t1.unit_config_id = t2.unit_config_id)
+ join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`)
+ left join __all_tenant t4 on (t1.tenant_id = t4.tenant_id)
+ order by
+ t1.`resource_pool_id`,
+ t2.`unit_config_id`,
+ t3.unit_id;
+ ```
+
+ The output is as follows:
+
+ ```shell
+ +------------------------------+-----------------------------------+---------+---------+------------+------------+---------+-------+--------------------+-----------+---------------+
+ | resource_pool_name | unit_config_name | max_cpu | min_cpu | max_mem_gb | min_mem_gb | unit_id | zone | observer | tenant_id | tenant_name |
+ +------------------------------+-----------------------------------+---------+---------+------------+------------+---------+-------+--------------------+-----------+---------------+
+ | sys_pool | config_sys_zone1_xiaofeng_sys_lpj | 3 | 3 | 6 | 6 | 1 | zone1 | xx.xxx.xx.20:22602 | 1 | sys |
+ | pool_for_tenant_mysql | 2c2g | 2 | 2 | 2 | 2 | 1001 | zone1 | xx.xxx.xx.20:22602 | 1002 | mysql |
+ | pool_mysql_standby_zone1_xcl | config_mysql_standby_zone1_S1_xic | 1.5 | 1.5 | 6 | 6 | 1002 | zone1 | xx.xxx.xx.20:22602 | 1004 | mysql_standby |
+ +------------------------------+-----------------------------------+---------+---------+------------+------------+---------+-------+--------------------+-----------+---------------+
+ 3 rows in set
+ ```
+
+- Query resource locations from a user tenant
+
+ ```sql
+ select * from GV$OB_UNITS where tenant_id=1002;
+ ```
+
+ When you query resource locations from a business tenant, the `WHERE tenant_id=1002` clause can be omitted. This is because you can view only the information about the current tenant from a business tenant. The output is as follows:
+
+ ```shell
+ +--------------+----------+---------+-----------+-------+-----------+------------+---------+---------+-------------+---------------------+---------------------+-------------+---------------+-----------------+------------------+--------+----------------------------+
+ | SVR_IP | SVR_PORT | UNIT_ID | TENANT_ID | ZONE | ZONE_TYPE | REGION | MAX_CPU | MIN_CPU | MEMORY_SIZE | MAX_IOPS | MIN_IOPS | IOPS_WEIGHT | LOG_DISK_SIZE | LOG_DISK_IN_USE | DATA_DISK_IN_USE | STATUS | CREATE_TIME |
+ +--------------+----------+---------+-----------+-------+-----------+------------+---------+---------+-------------+---------------------+---------------------+-------------+---------------+-----------------+------------------+--------+----------------------------+
+ | 1.2.3.4 | 22602 | 1001 | 1002 | zone1 | ReadWrite | sys_region | 2 | 2 | 1073741824 | 9223372036854775807 | 9223372036854775807 | 2 | 5798205850 | 4607930545 | 20971520 | NORMAL | 2023-11-20 11:09:55.668007 |
+ +--------------+----------+---------+-----------+-------+-----------+------------+---------+---------+-------------+---------------------+---------------------+-------------+---------------+-----------------+------------------+--------+----------------------------+
+ 1 row in set
+ ```
+
+#### View the locations of partition replicas
+
+According to the implementation logic of ODP routing, ODP parses SQL statements to obtain table and partition information, and then obtains the locations of corresponding partition leaders based on the information.
+
+OceanBase Database 4.x supports tenant-level replica management strategies. All tables of a tenant conform to the same primary zone rule. In the `sys` tenant, you can query tenant information from the `oceanbase.DBA_OB_TENANTS` view. Here is a sample statement:
+
+```sql
+select * from oceanbase.DBA_OB_TENANTS;
+```
+
+The output is as follows:
+
+```shell
++-----------+-------------+-------------+----------------------------+----------------------------+--------------+---------------+-------------------+--------------------+--------+---------------+--------+-------------+-------------------+------------------+---------------------+---------------------+---------------------+---------------------+--------------+----------------------------+----------+------------+-----------+
+| TENANT_ID | TENANT_NAME | TENANT_TYPE | CREATE_TIME | MODIFY_TIME | PRIMARY_ZONE | LOCALITY | PREVIOUS_LOCALITY | COMPATIBILITY_MODE | STATUS | IN_RECYCLEBIN | LOCKED | TENANT_ROLE | SWITCHOVER_STATUS | SWITCHOVER_EPOCH | SYNC_SCN | REPLAYABLE_SCN | READABLE_SCN | RECOVERY_UNTIL_SCN | LOG_MODE | ARBITRATION_SERVICE_STATUS | UNIT_NUM | COMPATIBLE | MAX_LS_ID |
++-----------+-------------+-------------+----------------------------+----------------------------+--------------+---------------+-------------------+--------------------+--------+---------------+--------+-------------+-------------------+------------------+---------------------+---------------------+---------------------+---------------------+--------------+----------------------------+----------+------------+-----------+
+| 1 | sys | SYS | 2024-04-10 10:48:59.526612 | 2024-04-10 10:48:59.526612 | RANDOM | FULL{1}@zone1 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | NULL | NULL | NULL | NULL | NOARCHIVELOG | DISABLED | 1 | 4.2.3.0 | 1 |
+| 1001 | META$1002 | META | 2024-04-10 10:49:30.029481 | 2024-04-10 10:50:27.254959 | zone1 | FULL{1}@zone1 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | NULL | NULL | NULL | NULL | NOARCHIVELOG | DISABLED | 1 | 4.2.3.0 | 1 |
+| 1002 | mysql | USER | 2024-04-10 10:49:30.048284 | 2024-04-10 10:50:27.458529 | zone1 | FULL{1}@zone1 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | 1717384184174664001 | 1717384184174664001 | 1717384184174664001 | 4611686018427387903 | NOARCHIVELOG | DISABLED | 1 | 4.2.3.0 | 1001 |
++-----------+-------------+-------------+----------------------------+----------------------------+--------------+---------------+-------------------+--------------------+--------+---------------+--------+-------------+-------------------+------------------+---------------------+---------------------+---------------------+---------------------+--------------+----------------------------+----------+------------+-----------+
+3 rows in set
+```
+
+In the `sys` tenant, you can query the partition locations of all tables under each tenant from the `oceanbase.cdb_ob_table_locations` view. Here is a sample statement:
+
+```sql
+select * from oceanbase.cdb_ob_table_locations where table_name = 't1';
+```
+
+The output is as follows:
+
+```shell
++-----------+---------------+------------+----------+------------+----------------+-------------------+------------+---------------+-----------+-------+-------+--------------+----------+--------+--------------+-----------------+-----------+-----------------+---------------+----------+
+| TENANT_ID | DATABASE_NAME | TABLE_NAME | TABLE_ID | TABLE_TYPE | PARTITION_NAME | SUBPARTITION_NAME | INDEX_NAME | DATA_TABLE_ID | TABLET_ID | LS_ID | ZONE | SVR_IP | SVR_PORT | ROLE | REPLICA_TYPE | DUPLICATE_SCOPE | OBJECT_ID | TABLEGROUP_NAME | TABLEGROUP_ID | SHARDING |
++-----------+---------------+------------+----------+------------+----------------+-------------------+------------+---------------+-----------+-------+-------+--------------+----------+--------+--------------+-----------------+-----------+-----------------+---------------+----------+
+| 1 | oceanbase | t1 | 500010 | USER TABLE | NULL | NULL | NULL | NULL | 200003 | 1 | zone1 | xx.xxx.xx.20 | 22602 | LEADER | FULL | NONE | 500010 | NULL | NULL | NULL |
+| 1002 | test | t1 | 500087 | USER TABLE | NULL | NULL | NULL | NULL | 200049 | 1001 | zone1 | xx.xxx.xx.20 | 22602 | LEADER | FULL | NONE | 500087 | NULL | NULL | NULL |
+| 1004 | test | t1 | 500003 | USER TABLE | NULL | NULL | NULL | NULL | 200001 | 1001 | zone1 | xx.xxx.xx.20 | 22602 | LEADER | FULL | NONE | 500003 | NULL | NULL | NULL |
++-----------+---------------+------------+----------+------------+----------------+-------------------+------------+---------------+-----------+-------+-------+--------------+----------+--------+--------------+-----------------+-----------+-----------------+---------------+----------+
+3 rows in set
+```
+
+In a user tenant, you can query the partition locations of all tables under the current tenant from the `oceanbase.dba_ob_table_locations` view.
+
+```sql
+select database_name, table_name, table_id, table_type, zone, svr_ip, role from oceanbase.dba_ob_table_locations where table_name = 't1';
+```
+
+The output is as follows:
+
+```shell
++---------------+------------+----------+------------+-------+--------------+--------+
+| database_name | table_name | table_id | table_type | zone | svr_ip | role |
++---------------+------------+----------+------------+-------+--------------+--------+
+| test | t1 | 500087 | USER TABLE | zone1 | xx.xxx.xx.20 | LEADER |
++---------------+------------+----------+------------+-------+--------------+--------+
+1 row in set
+```
+
+#### View and modify LDC settings
+
+LDC-based routing can resolve the issue of latency caused by remote routing when multiple IDCs are deployed across multiple regions in a distributed relational database.
+
+As a typical high-availability distributed relational database system, OceanBase Database uses the Paxos protocol for log synchronization. OceanBase Database natively supports multi-region and multi-IDC deployment to ensure high disaster tolerance and reliability. However, every database deployed across multiple regions and IDCs has a latency issue caused by routing. OceanBase Database provides the LDC routing feature to address this issue. If the region and IDC attributes are specified for each zone in an OceanBase cluster and the IDC name attribute is specified for ODP, when a data request is sent to ODP, ODP will select an OBServer node in the following sequence: an OBServer node in the same IDC, an OBServer node in the same region, and a remote OBServer node. For more information, see [Strategy-based routing](https://en.oceanbase.com/docs/common-odp-doc-en-10000000001177670).
+
+
+
+OceanBase Database allows you to modify the system variables to change the default routing strategies. For more information, see [SQL routing](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001377970).
+
+## High Availability Based on ODP Routing
+
+High availability means that OceanBase Database is tolerant of server faults, which makes the faults transparent and imperceptible to applications. When ODP finds that an OBServer node is faulty, it excludes the faulty node and selects a healthy node during routing. ODP also allows failed SQL statements to be retried. High availability is implemented by using fault detection, the blocklist mechanism, and the retry logic. As shown in the following figure, ODP adds the faulty OBServer node 1 to the blocklist and selects a healthy node during routing.
+
+
+
+You can design routing strategies based on the factors affecting data routing and the principles of data routing. In principle, the status and data distribution of OBServer nodes must be monitored in real time. However, this is almost impossible in practice. Therefore, the routing strategies must achieve a balance between functionality, performance, and high availability to make OceanBase Database easier to use.
+
+## Routing Features and Strategies of ODP
+
+ODP allows you to access different servers of different tenants in different clusters through cluster routing, tenant routing, and intra-tenant routing. This section describes the routing features of ODP in terms of these three aspects.
+
+### Cluster routing
+
+Cluster routing allows you to access different clusters. The key to cluster routing is to obtain the mapping between a cluster name and a RootService list.
+
+- In the startup method in which the RootService list is specified by using a startup parameter, the mapping between a cluster name and the RootService list is also specified by using a startup parameter.
+
+- In the startup method in which the `config_server_url` parameter is specified, the mapping between a cluster name and a RootService list is obtained from the access URL.
+
+Note that the RootService list does not need to contain all the cluster servers. ODP obtains the list of servers in a cluster from a view. Generally, the RootService list contains servers where RootService is located.
+
+
+
+As can be seen from the preceding figure, OceanBase Cloud Platform (OCP) is a key module in cluster routing. If cluster routing issues occur in your production environment, check whether OCP operates properly.
+
+ODP obtains the RootService list when you log in to access a cluster for the first time. ODP then saves the RootService list to the memory. In subsequent access to the cluster, ODP can obtain the RootService list from the memory.
+
+Cluster routing allows you to access different clusters. Therefore, when you use ODP to connect to a cluster, you must specify `user_name`, `tenant_name`, as well as `cluster_name` in the command. If OceanBase Developer Center (ODC) is deployed, you must use ODP to connect to clusters. When you configure a connection string in ODC, you must also add `cluster_name` to the connection string. Here is an example (assuming that the IP address and port number of ODP are `127.0.0.1` and `2883`, respectively):
+
+```shell
+mysql -h 127.0.0.1 -u user_name@tenant_name#cluster_name -P2883 -Ddatabase_name -pPASSWORD
+```
+
+If you directly connect to an OBServer node without using ODP, you can specify `user_name` and `tenant_name` in the statement, without specifying `cluster_name`. Here is an example (assuming that the IP address and port number of OBServer node are `1.2.3.4` and `12345`):
+
+```shell
+mysql -h 1.2.3.4 -u user_name@tenant_name -P12345 -Ddatabase_name -pPASSWORD
+```
+
+### Tenant routing
+
+In OceanBase Database, a cluster has multiple tenants. The tenant routing feature of ODP allows you to access different tenants. Different from other tenants, the `sys` tenant is similar to an administrator tenant, and is related to cluster management. This section separately describes routing for the `sys` tenant and routing for a user tenant.
+
+#### Routing for the `sys` tenant
+
+After completing cluster routing, ODP obtains the RootService list of the cluster. In this case, ODP logs in to a server in the RootService list with the `proxyro@sys` account and obtains all the servers in the cluster from the `DBA_OB_SERVERS` view.
+
+In the implementation of OceanBase Database, the `sys` tenant is distributed on each node. Therefore, the result retrieved from the `DBA_OB_SERVERS` view is the routing information of the `sys` tenant.
+
+ODP accesses the `DBA_OB_SERVERS` view every 15 seconds to maintain the latest routing information and to perceive node changes in the cluster. In addition to the cluster server list, ODP also obtains information such as the partition distribution information, zone information, and tenant information from the `sys` tenant.
+
+#### Routing for a user tenant
+
+Unlike the routing information of the `sys` tenant, the routing information of a user tenant is about the servers where the tenant resources are located.
+
+ODP does not obtain routing information of a user tenant from a unit-related table, but by using the special table name `__all_dummy`, which indicates a query for the tenant information. ODP obtains the server list of the tenant from the internal table `__all_virtual_proxy_schema`. For ODP to access the `__all_virtual_proxy_schema` table, you must specify the table name `__all_dummy` and the tenant name to obtain the node information of the tenant.
+
+
+
+ODP stores the obtained tenant information in the local memory and updates the cache information according to certain strategies. For the `sys` tenant, ODP initiates a pull task every 15 seconds to obtain the latest information. For user tenants, ODP refreshes the routing cache in accordance with the following strategies:
+
+- Creation: When you access a user tenant for the first time, ODP accesses the `__all_virtual_proxy_schema` table to obtain the routing information of the tenant and creates the routing cache.
+
+- Eviction: ODP disables the cache when the OBServer node returns the `OB_TENANT_NOT_IN_SERVER` error code.
+
+- Update: ODP accesses the `__all_virtual_proxy_schema` table again to obtain the routing information of the user tenant when the cache is disabled.
+
+In summary, in the multi-tenant architecture, ODP obtains metadata information from the `sys` tenant. The routing information of the `sys` tenant is a list of servers in the cluster. Then, ODP obtains the routing information of tenants from the metadata information. With the tenant routing feature, ODP supports the multi-tenant architecture of OceanBase Database.
+
+#### Intra-tenant routing
+
+##### SQL routing strategy for strong-consistency reads
+
+ODP supports many routing strategies. This section describes a part of them from simple ones to complex ones.
+
+- In the strong-consistency read strategy, ODP routes SQL statements to the node that hosts the leader replica of the accessed table partition. This strategy is easy to understand, but the routing of SQL statements can be complicated.
+
+- If an SQL statement accesses two tables, ODP will identify the node that hosts the leader replica of the accessed partition in the first table based on the first accessed table and its partitioning conditions. If the identification fails, ODP routes the SQL statement to a random node. Therefore, in an SQL statement that joins multiple tables, the order of tables can affect the routing strategy, which in turn affects the database performance.
+
+- When ODP needs to identify the node that hosts the leader of the accessed partition in a partitioned table, ODP checks whether the partitioning key is specified as an equivalence condition in the SQL statement. If not, ODP cannot identify the partition to be accessed. In this case, ODP routes the SQL statement to a random node that hosts a partition of the table.
+
+- When a transaction starts, the node to which the first SQL statement in the transaction is routed serves as the destination node of subsequent SQL statements in the transaction until the transaction is committed or rolled back.
+
+- After ODP routes an SQL statement to a node, the execution of the SQL statement is divided into the following three cases:
+
+ - Local execution: If the leader of the partition to be accessed exists on that node, the SQL statement is executed on that node based on a local execution plan. The value of the `plan_type` parameter is `1`.
+
+ - Remote execution: If the leader of the partition to be accessed does not exist on that node, the SQL statement is forwarded by the OBServer node, and is executed on another node based on a remote execution plan. The value of the `plan_type` parameter is `2`.
+
+ - Distributed execution: If replicas of the partition to be accessed are distributed on multiple nodes, the SQL statement is executed based on a distributed execution plan. The value of the `plan_type` parameter is `3`.
+
+- If a transaction contains an SQL statement that reads a replicated table, and the SQL statement is routed to a node where a follower of the replicated table exists, the SQL statement can read the local follower. This is because all followers of the replicated table are strongly consistent with the leader. The SQL statement is executed based on a local execution plan.
+
+In real-world scenarios, complex SQL statements are often used. As a result, ODP uses complex routing strategies. Therefore, the routing result may be inaccurate. If the routing does not meet the design requirements, bugs will occur. However, the bugs may also be triggered by design. After all, the current version of ODP can parse only simple SQL statements, while OceanBase Database can parse complete execution plans.
+
+When many complex business SQL statements are involved, remote and distributed SQL executions are unavoidable. In this case, you must note the proportions of remote and distributed SQL executions. If the proportions are large, the overall execution performance of business SQL statements will not be good. To improve the execution performance, you need to minimize remote and distributed SQL executions by using methods such as creating table groups, using replicated tables, and setting the `PRIMARY_ZONE` parameter.
+
+##### SQL routing strategy for weak-consistency reads
+
+By default, OceanBase Database uses the strong-consistency read mode, which is also known as read-after-write consistency. This mode allows you to view changes right after you make the changes. In the strong-consistency read strategy, ODP routes SQL statements first to the node that hosts the leader replica of the accessed table partition.
+
+Weak-consistency read is the opposite of strong-consistency read, which means that you cannot view the data right after you write the data. In the weak-consistency read strategy, ODP routes an SQL statement that accesses a table partition to a node that hosts the leader or follower replicas of the partition. Generally, ODP routes the SQL statement to a node that hosts three or more replicas.
+
+However, if the LDC feature is enabled for both OceanBase Database and ODP, the SQL routing strategy for weak-consistency reads may change and an SQL statement is routed to a node in the following order:
+
+- A node in the same IDC or region and not in the In Major Compaction state
+
+- A node in the same region and in the In Major Compaction state
+
+- A node in another region
+
+ODP prefers nodes that are not in the In Major Compaction state. However, if you disable rotating major compaction for an OceanBase cluster by setting the `enable_merge_by_turn` parameter to `false`, ODP cannot avoid nodes in the In Major Compaction state because all nodes are involved in major compaction.
+
+In addition to SQL statements that are used for data access, some SQL statements are used for viewing or setting variable values. Here is an example:
+
+```sql
+set @@autocommit=off
+show variables like 'autocommit';
+```
+
+These SQL statements are routed to a random node. In the random routing strategy, if the LDC feature is enabled for OceanBase Database and ODP, SQL statements are also routed in the preceding order.
+
+Generally, weak-consistency reads are used in scenarios where data reads and writes are separated. However, if the `PRIMARY_ZONE` parameter of a tenant is set to `RANDOM`, the leaders of all partitions of the tenant are distributed across all zones. In this case, the weak-consistency read strategy does not make much difference.
+
+However, if you use read-only replicas and deploy the node that hosts read-only replicas in a separate IDC, you can deploy ODP in the same IDC to route SQL statements to the node that hosts the read-only replicas.
+
+##### Other routing strategies
+
+ODP supports many routing strategies. This section briefly describes a part of them. You can focus on the ODP routing strategies for strong-consistency reads and weak-consistency reads.
+
+ODP supports the following intra-tenant routing strategies:
+
+- IP address-based routing
+
+ In this mode, an OBServer node is specified by using the `target_db_server` parameter of ODP or by using a hint in the statement. ODP routes the statement to the specified OBServer node. This routing mode has the highest priority. If an IP address is specified, ODP will ignore other routing modes. For more information, see [IP address-based routing](https://en.oceanbase.com/docs/common-odp-doc-en-10000000001177666).
+
+- Partitioned table-based routing for strong-consistency reads
+
+ In this mode, the partitioning key, partitioning key expression, or partition name is provided in a strong-consistency read statement on a partitioned table. ODP accurately routes the statement to the OBServer node that hosts the leader of the partition where the data resides. For more information, see [Partitioned table-based routing for strong-consistency reads](https://en.oceanbase.com/docs/common-odp-doc-en-10000000001177668).
+
+- Global index table-based routing for strong-consistency reads
+
+ In this mode, the column value, value expression, or index partition name of the global index table is provided in a strong-consistency read statement on the primary table. ODP accurately routes the statement to the OBServer node that hosts the leader of the index partition where the data resides. For more information, see [Global index table-based routing for strong-consistency reads](https://en.oceanbase.com/docs/common-odp-doc-en-10000000001177667).
+
+- Replicated table-based routing for strong-consistency reads
+
+ For a strong-consistency read statement on a replicated table, ODP routes the statement to the OBServer node nearest to ODP. For more information, see [Replication table-based routing for strong-consistency reads](https://en.oceanbase.com/docs/common-odp-doc-en-10000000001177669).
+
+- Primary zone-based routing for strong-consistency reads
+
+ In this mode, the primary zone is configured by using an ODP parameter. ODP routes a strong-consistency read statement for which routing calculation cannot be performed to an OBServer node in the primary zone. For more information, see [Primary zone-based routing for strong-consistency reads](https://en.oceanbase.com/docs/common-odp-doc-en-10000000001177672).
+
+- Strategy-based routing
+
+ ODP routes statements based on rules of the configured routing strategy. For more information, see [Strategy-based routing](https://en.oceanbase.com/docs/common-odp-doc-en-10000000001177670).
+
+- Distributed transaction routing
+
+ After distributed transaction routing is enabled by using the ODP parameter `enable_transaction_internal_routing`, statements in a transaction do not need to be force routed to the OBServer node that starts the transaction. For more information, see [Distributed transaction routing](https://en.oceanbase.com/docs/common-odp-doc-en-10000000001177671).
+
+- Rerouting
+
+ Rerouting is enabled by using an ODP parameter. After a statement is routed to an OBServer node, if no partition is hit or the distributed transaction cannot be executed on this OBServer node, ODP can accurately reroute the statement. For more information, see [Rerouting](https://en.oceanbase.com/docs/common-odp-doc-en-10000000001177675).
+
+- Forcible routing
+
+ ODP decides whether to perform forcible routing. Forcible routing is performed in the following cases. For more information, see [Forcible routing](https://en.oceanbase.com/docs/common-odp-doc-en-10000000001177673).
+
+ - For non-distributed transaction routing, statements in a transaction are force routed to the OBServer node that starts the transaction.
+
+ - For session-level temporary table-based routing, a query is force routed to the OBServer node where the temporary table is queried for the first time.
+
+ - Session reuse-based routing: If routing calculation fails and the `enable_cached_server` parameter is set to `True`, ODP force routes a query to the OBServer node where the session resides the last time.
+
+ - Cursor/Piece-based routing: When the client uses cursors/pieces to obtain/upload data, all requests are force routed to the same OBServer node.
+
+ ## References
+ - Blog in the OceanBase community forum: [ODP: High-Performance Data Access Middleware](https://open.oceanbase.com/blog/topics/3983484160)。
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/02_show_trace.md b/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/02_show_trace.md
new file mode 100644
index 000000000..a00356534
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/02_show_trace.md
@@ -0,0 +1,201 @@
+---
+title: Check Whether ODP Causes a Performance Bottleneck
+weight: 2
+---
+
+> When the SQL performance is not as expected, you first need to execute the `SHOW TRACE` statement to query the time spent in each phase and identify the phase that takes the longest time.
+>
+> **This topic describes how to use the `SHOW TRACE` statement to check whether poor SQL performance occurs because OceanBase Database Proxy (ODP) causes a performance bottleneck. If you are skilled in analyzing SQL performance issues by using the `SHOW TRACE` statement, skip this topic. **
+
+## End-to-end Tracing
+
+Data is processed through the following link: application server <-> ODP <-> OBServer node. Specifically, an application server connects to and sends requests to ODP by calling database drivers. Then, ODP forwards the requests to the most appropriate OBServer nodes of OceanBase Database, which stores user data in multiple partitions and replicas across OBServer nodes in its distributed architecture. OBServer nodes execute the requests and return the execution results to the user. OBServer nodes also support request forwarding. If a request cannot be executed on the current OBServer node, it is forwarded to the appropriate OBServer node.
+
+In the case of an end-to-end performance issue, such as long response time (RT) detected on the application server, you need to first find the component that has caused the issue on the database access link, and then troubleshoot the component.
+
+
+
+Two paths are involved in end-to-end tracing:
+
+- An application sends a request to ODP through a client, such as Java Database Connectivity (JDBC) or Oracle Call Interface (OCI), ODP forwards the request to an OBServer node, and then the OBServer node returns the result to the application.
+
+- An application directly sends a request to an OBServer node through a client, and then the OBServer node returns the result to the application.
+
+### Examples
+
+Here is an example:
+
+1. Use ODP to connect to OceanBase Database, create a table, and insert data into the table.
+
+ ```sql
+ create table t1(c1 int);
+
+ insert into t1 values(123);
+ ```
+
+2. Enable end-to-end tracing for the current session.
+
+ ```sql
+ SET ob_enable_show_trace = ON;
+ ```
+
+3. Execute a simple query statement.
+
+ ```sql
+ SELECT c1 FROM t1 LIMIT 2;
+ ```
+
+ The output is as follows:
+
+ ```shell
+ +------+
+ | c1 |
+ +------+
+ | 123 |
+ +------+
+ 1 row in set
+ ```
+
+4. Execute the `SHOW TRACE` statement.
+
+ ```sql
+ SHOW TRACE;
+ ```
+
+ The output is as follows:
+
+ ```shell
+ +-----------------------------------------------------------+----------------------------+------------+
+ | Operation | StartTime | ElapseTime |
+ +-----------------------------------------------------------+----------------------------+------------+
+ | ob_proxy | 2024-03-20 15:07:46.419433 | 191.999 ms |
+ | ├── ob_proxy_partition_location_lookup | 2024-03-20 15:07:46.419494 | 181.839 ms |
+ | ├── ob_proxy_server_process_req | 2024-03-20 15:07:46.601697 | 9.138 ms |
+ | └── com_query_process | 2024-03-20 15:07:46.601920 | 8.824 ms |
+ | └── mpquery_single_stmt | 2024-03-20 15:07:46.601940 | 8.765 ms |
+ | ├── sql_compile | 2024-03-20 15:07:46.601984 | 7.666 ms |
+ | │ ├── pc_get_plan | 2024-03-20 15:07:46.602051 | 0.029 ms |
+ | │ └── hard_parse | 2024-03-20 15:07:46.602195 | 7.423 ms |
+ | │ ├── parse | 2024-03-20 15:07:46.602201 | 0.137 ms |
+ | │ ├── resolve | 2024-03-20 15:07:46.602393 | 0.555 ms |
+ | │ ├── rewrite | 2024-03-20 15:07:46.603104 | 1.055 ms |
+ | │ ├── optimize | 2024-03-20 15:07:46.604194 | 4.298 ms |
+ | │ │ ├── inner_execute_read | 2024-03-20 15:07:46.605959 | 0.825 ms |
+ | │ │ │ ├── sql_compile | 2024-03-20 15:07:46.606078 | 0.321 ms |
+ | │ │ │ │ └── pc_get_plan | 2024-03-20 15:07:46.606124 | 0.147 ms |
+ | │ │ │ ├── open | 2024-03-20 15:07:46.606418 | 0.129 ms |
+ | │ │ │ └── do_local_das_task | 2024-03-20 15:07:46.606606 | 0.095 ms |
+ | │ │ └── close | 2024-03-20 15:07:46.606813 | 0.240 ms |
+ | │ │ ├── close_das_task | 2024-03-20 15:07:46.606879 | 0.022 ms |
+ | │ │ └── end_transaction | 2024-03-20 15:07:46.607009 | 0.023 ms |
+ | │ ├── code_generate | 2024-03-20 15:07:46.608527 | 0.374 ms |
+ | │ └── pc_add_plan | 2024-03-20 15:07:46.609375 | 0.207 ms |
+ | └── sql_execute | 2024-03-20 15:07:46.609677 | 0.832 ms |
+ | ├── open | 2024-03-20 15:07:46.609684 | 0.156 ms |
+ | ├── response_result | 2024-03-20 15:07:46.609875 | 0.327 ms |
+ | │ └── do_local_das_task | 2024-03-20 15:07:46.609905 | 0.136 ms |
+ | └── close | 2024-03-20 15:07:46.610221 | 0.225 ms |
+ | ├── close_das_task | 2024-03-20 15:07:46.610229 | 0.029 ms |
+ | └── end_transaction | 2024-03-20 15:07:46.610410 | 0.019 ms |
+ +-----------------------------------------------------------+----------------------------+------------+
+ 29 rows in set
+ ```
+
+ The query result shows that:
+
+ - The execution of the SQL statement took a total of 191.999 ms.
+
+ - The `ob_proxy_partition_location_lookup` operation took 181.839 ms, which was the time taken by ODP to search for the location of the leader of the `t1` table. This operation took a long time because the `t1` table was newly created and ODP had not cached its location information in the location. However, ODP will directly get the location information from the location cache upon next access to the table.
+
+ - The `com_query_process` operation on the OBServer node to which the SQL statement was forwarded took 8.824 ms.
+
+ > Other important operations in the query result are described as follows:
+ >
+ > - **ob_proxy**: the operation that spans from when ODP receives an SQL request to when it returns a complete response to the client.
+ >
+ > - **ob_proxy_server_process_req**: the operation that spans from when an SQL request is sent to when a response is first received from the OBServer node. The time taken by this operation equals the value of the processing time on the OBServer node plus the time consumed to transmit the request over the network.
+ >
+ > - **com_query_process**: the operation that spans from when the OBServer node receives an SQL request to when it forwards a response.
+
+5. Execute the `SELECT c1 FROM t1 LIMIT 2;` statement in the same session again, and then execute the `SHOW TRACE` statement.
+
+ ```sql
+ SHOW TRACE;
+ ```
+
+ The output is as follows:
+
+ ```shell
+ +-----------------------------------------------+----------------------------+------------+
+ | Operation | StartTime | ElapseTime |
+ +-----------------------------------------------+----------------------------+------------+
+ | ob_proxy | 2024-03-20 15:34:14.879559 | 7.390 ms |
+ | ├── ob_proxy_partition_location_lookup | 2024-03-20 15:34:14.879652 | 4.691 ms |
+ | ├── ob_proxy_server_process_req | 2024-03-20 15:34:14.884785 | 1.514 ms |
+ | └── com_query_process | 2024-03-20 15:34:14.884943 | 1.237 ms |
+ | └── mpquery_single_stmt | 2024-03-20 15:34:14.884959 | 1.207 ms |
+ | ├── sql_compile | 2024-03-20 15:34:14.884997 | 0.279 ms |
+ | │ └── pc_get_plan | 2024-03-20 15:34:14.885042 | 0.071 ms |
+ | └── sql_execute | 2024-03-20 15:34:14.885300 | 0.809 ms |
+ | ├── open | 2024-03-20 15:34:14.885310 | 0.139 ms |
+ | ├── response_result | 2024-03-20 15:34:14.885513 | 0.314 ms |
+ | │ └── do_local_das_task | 2024-03-20 15:34:14.885548 | 0.114 ms |
+ | └── close | 2024-03-20 15:34:14.885847 | 0.190 ms |
+ | ├── close_das_task | 2024-03-20 15:34:14.885856 | 0.030 ms |
+ | └── end_transaction | 2024-03-20 15:34:14.885997 | 0.019 ms |
+ +-----------------------------------------------+----------------------------+------------+
+ 14 rows in set
+ ```
+
+ The query result shows that:
+
+ - The execution time of the SQL statement was shortened from 191.999 ms to 7.390 ms.
+
+ - The time taken by ODP to search for routing information and forward the SQL statement was shortened from 181.839 ms to 4.691 ms. This is because ODP directly obtained the location information from the location cache.
+
+ - The time taken by the `com_query_process` operation on the OBServer node to which the SQL statement was forwarded was shortened from 8.824 ms to 1.237 ms. The execution of the preceding SQL statement was divided into two phases. In the compilation phase, the optimizer generated an execution plan. In the execution phase, the execution engine calculated results based on the execution plan. During the second execution, the time spent in the compilation phase was shortened. This is because an execution plan (`pc_get_plan`) has been generated and stored in the plan cache during the first execution and no plan needed to be generated again during the second execution. This way, the overhead of the `hard_parse` operation to parse the SQL statement and generate a plan was eliminated.
+
+6. Directly connect to the OBServer node to log in to OceanBase Database, execute the `SELECT c1 FROM t1 LIMIT 2;` statement again, and then execute the `SHOW TRACE` statement.
+
+ ```sql
+ SHOW TRACE;
+ ```
+
+ The output is as follows:
+
+ ```shell
+ +-------------------------------------------+----------------------------+------------+
+ | Operation | StartTime | ElapseTime |
+ +-------------------------------------------+----------------------------+------------+
+ | com_query_process | 2024-03-20 15:54:38.772699 | 1.746 ms |
+ | └── mpquery_single_stmt | 2024-03-20 15:54:38.772771 | 1.647 ms |
+ | ├── sql_compile | 2024-03-20 15:54:38.772835 | 0.356 ms |
+ | │ └── pc_get_plan | 2024-03-20 15:54:38.772900 | 0.143 ms |
+ | └── sql_execute | 2024-03-20 15:54:38.773209 | 1.052 ms |
+ | ├── open | 2024-03-20 15:54:38.773232 | 0.150 ms |
+ | ├── response_result | 2024-03-20 15:54:38.773413 | 0.421 ms |
+ | │ └── do_local_das_task | 2024-03-20 15:54:38.773479 | 0.192 ms |
+ | └── close | 2024-03-20 15:54:38.773857 | 0.379 ms |
+ | ├── close_das_task | 2024-03-20 15:54:38.773913 | 0.069 ms |
+ | └── end_transaction | 2024-03-20 15:54:38.774139 | 0.058 ms |
+ +-------------------------------------------+----------------------------+------------+
+ 11 rows in set
+ ```
+
+ The query result shows that:
+
+ - The direct connection to the OBServer node eliminated ODP-related overheads.
+
+ - The execution plan for the SQL statement was stored in the plan cache of the OBServer node. Therefore, hard parsing was not required in the compilation phase of the next execution.
+
+**After the analysis, run the following command to disable session-level end-to-end tracing to avoid compromising the performance of subsequent SQL statements. **
+```
+set ob_enable_show_trace='off';
+```
+
+### Summary
+For an SQL statement whose performance is not as expected, you can execute the `SHOW TRACE` statement to check whether most of the time is spent in the ODP forwarding phase, plan generation phase, or execution phase. You can see details about the time spent in each phase and further analyze the slow operations.
+
+If ODP forwarding is slow, check whether the network between ODP and the OBServer node fails or whether ODP has not cached location information.
+
+If the execution is slow, check whether the index used in the execution plan is inappropriate and perform SQL tuning as needed. For more information, see the [SQL performance diagnostics and tuning](https://oceanbase.github.io/docs/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/performance_tuning) topic of this tutorial.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/03_connection_diagnosis.md b/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/03_connection_diagnosis.md
new file mode 100644
index 000000000..2f3a05fda
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/03_connection_diagnosis.md
@@ -0,0 +1,440 @@
+---
+title: Troubleshoot ODP Connection Issues
+Weight: 3
+---
+
+> When OceanBase Database Proxy (ODP) is used, the execution link of a request is as follows: a client sends a request to ODP, ODP routes the request to the corresponding OBServer node, the OBServer node processes the request and returns a response to ODP, and ODP forwards the response to the client.
+>
+> A disconnection may occur on the link in the following cases: the client does not receive a response from ODP due to a long request processing time, login fails due to incorrect cluster or tenant information, or an internal error occurs in ODP or OceanBase Database.
+
+## Troubleshooting Procedure
+
+> **We recommend that you carefully read this section. You can handle most exceptions according to logs retrieved based on trace IDs. **
+
+The troubleshooting procedure for ODP is similar to that for OBServer nodes.
+
+For example, if a connection error occurs, check the error log.
+```
+[xiaofeng.lby@sqaobnoxdn011161204091.sa128 /home/xiaofeng.lby]
+$obclient -h 127.0.0.1 -P2883 -uroot@sys#xiaofeng_91_435 -Dtest
+ERROR 4669 (HY000): cluster not exist
+```
+> This is not a very good example though. When the first error "cluster not exist" is returned, you already know what the problem is.
+
+If you are not sure whether the problem is caused by ODP, you can run the `grep "ret=-4669" *` command in the `/oceanbase/log` directory. If the log directory contains many log files, replace the asterisk (*) behind `grep` with a specific log file name like `observer.log.202412171219*` based on the actual situation.
+```
+[xiaofeng.lby@sqaobnoxdn011161204091.sa128 /home/xiaofeng.lby/oceanbase/log]
+$sudo grep "ret=-4669" *
+```
+
+If the `grep` command does not find any error information in the `observer` directory, the problem is probably caused by ODP. In this case, you can run the `grep` command in the `/obproxy/log` directory.
+
+```
+[xiaofeng.lby@sqaobnoxdn011161204091.sa128 /home/xiaofeng.lby/obproxy/log]
+$grep "ret=-4669" *
+
+# The output here is originally one line, and is manually split into multiple lines for display on the web page.
+obproxy.log:[2024-12-17 14:34:14.024891]
+WDIAG [PROXY.SM] setup_get_cluster_resource (ob_mysql_sm.cpp:1625)
+[125907][Y0-00007F630AAA2A70] [lt=0] [dc=0]
+cluster does not exist, this connection will disconnect
+(sm_id=26403246, is_clustername_from_default=false, cluster_name=xiaofeng_91_435, ret=-4669)
+```
+
+You can see in the log that the cluster named `xiaofeng_91_435` does not exist. Therefore, the disconnection occurs.
+
+
+
+You can also obtain the trace ID `[Y0-00007F630AAA2A70]` from the preceding log. You can run the `grep` command based on this trace ID to obtain all logs related to this operation.
+
+
+```
+[xiaofeng.lby@sqaobnoxdn011161204091.sa128 /home/xiaofeng.lby/obproxy/log]
+$grep Y0-00007F630AAA2A70 *
+
+obproxy_diagnosis.log:[2024-12-17 14:34:14.024938] [125907][Y0-00007F630AAA2A70] [LOGIN](trace_type="LOGIN_TRACE", connection_diagnosis={cs_id:278640, ss_id:0, proxy_session_id:0, server_session_id:0, client_addr:"127.0.0.1:9988", server_addr:"*Not IP address [0]*:0", cluster_name:"xiaofeng_91_435", tenant_name:"sys", user_name:"root", error_code:-4669, error_msg:"cluster does not exist", request_cmd:"OB_MYSQL_COM_LOGIN", sql_cmd:"OB_MYSQL_COM_LOGIN", req_total_time(us):196}{internal_sql:"", login_result:"failed"})
+
+obproxy_error.log:2024-12-17 14:34:14.024960,xiaofeng_cluster_430_proxy,,,,xiaofeng_91_435:sys:,OB_MYSQL,,,OB_MYSQL_COM_LOGIN,,failed,-4669,,194us,0us,0us,0us,Y0-00007F630AAA2A70,,127.0.0.1:9988,,0,,cluster not exist,
+
+obproxy.log:[2024-12-17 14:34:13.584801] INFO [PROXY.NET] accept (ob_mysql_session_accept.cpp:36) [125907][Y0-00007F630AAA2A70] [lt=0] [dc=0] [ObMysqlSessionAccept:main_event] accepted connection(netvc=0x7f630aa7d2e0, client_ip={127.0.0.1:9980})
+...
+```
+
+After a disconnection occurs, ODP generates a disconnection log in the `obproxy_diagnosis.log` file to record detailed information about the disconnection. The following is a disconnection log that records a login failure due to an incorrect tenant name.
+
+```shell
+# The output here is originally one line, and is manually split into multiple lines for display on the web page.
+[2023-08-23 20:11:08.567425]
+[109316][Y0-00007F285BADB4E0] [CONNECTION]
+(trace_type="LOGIN_TRACE",
+connection_diagnosis={
+ cs_id:1031798792, ss_id:0, proxy_session_id:0, server_session_id:0,
+ client_addr:"10.10.10.1:58218", server_addr:"*Not IP address [0]*:0",
+ cluster_name:"undefined", tenant_name:"test", user_name:"root",
+ error_code:-4043,
+ error_msg:"dummy entry is empty, please check if the tenant exists", request_cmd:"COM_SLEEP", sql_cmd:"COM_LOGIN"}{internal_sql:""})
+```
+
+You can guess the reason for the disconnection based on the `please check if the tenant exists` information in the error message.
+
+> **The latter part of this topic is all "dictionary" content that you can consult when necessary. You only need to browse through the content to get a general idea. **
+>
+> **We recommend that you add this topic to your favorites first. If an error occurs, pull the error log and search for the corresponding solution based on the key information provided in the log. **
+
+The general fields in an obproxy_diagnosis log are described as follows:
+
+* `LOG_TIME`: the time when the log was recorded, which is `2023-08-23 20:11:08.567425` in this example.
+
+* `TID`: the ID of the thread, which is `109316` in this example.
+
+* `TRACE_ID`: the trace ID, which is `Y0-00007F285BADB4E0` in this example. You can associate the log with other logs based on the trace ID.
+
+* `CONNECTION`: indicates that this log is related to connection diagnostics.
+
+* `trace_type`: the diagnostic type, which varies based on the cause of disconnection. Valid values:
+
+ * `LOGIN_TRACE`: indicates that the disconnection is caused by a login failure.
+
+ * `SERVER_INTERNAL_TRACE`: indicates that the disconnection is caused by an internal error in OceanBase Database.
+
+ * `PROXY_INTERNAL_TRACE`: indicates that the disconnection is caused by an internal error in ODP.
+
+ * `CLIENT_VC_TRACE`: indicates that the disconnection is actively initiated by the client.
+
+ * `SERVER_VC_TRACE`: indicates that the disconnection is actively initiated by OceanBase Database.
+
+ * `TIMEOUT_TRACE`: indicates that the disconnection is caused by an execution timeout of the ODP process.
+
+* `CS_ID`: the internal ID used by ODP to identify the client connection.
+
+* `SS_ID`: the internal ID used by ODP to identify the connection between ODP and OceanBase Database.
+
+* `PROXY_SS_ID`: the ID generated by ODP to identify the client connection. This ID is passed to OceanBase Database and can be used to filter OceanBase Database logs or the sql_audit table.
+
+* `SERVER_SS_ID`: the ID generated by OceanBase Database to identify the connection between ODP and OceanBase Database.
+
+* `CLIENT_ADDR`: the IP address of the client.
+
+* `SERVER_ADDR`: the IP address of the OBServer node where an error or disconnection occurs.
+
+* `CLUSTER_NAME`: the name of the cluster.
+
+* `TENANT_NAME`: the name of the tenant.
+
+* `USER_NAME`: the username.
+
+* `ERROR_CODE`: the error code.
+
+* `ERROR_MSG`: the error message, which is the key information for diagnosing disconnections.
+
+* `REQUEST_CMD`: the type of the statement being processed by ODP, which can be an internal request.
+
+* `SQL_CMD`: the type of the user statement.
+
+Besides the preceding general information, a diagnostic log can contain additional diagnostic information, which is subject to the diagnostic type.
+
+
+
+## General Disconnection Scenarios
+
+This section describes several common disconnection scenarios and how to locate and resolve these disconnections.
+
+### Disconnection upon a login failure
+
+The diagnostic type is `LOGIN_TRACE`. Here is a sample diagnostic log that records a disconnection caused by an incorrect tenant name during login.
+
+```shell
+[2023-09-08 10:37:21.028960] [90663][Y0-00007F8EB76544E0] [CONNECTION](trace_type="LOGIN_TRACE", connection_diagnosis={cs_id:1031798785, ss_id:0, proxy_session_id:0, server_session_id:0, client_addr:"10.10.10.1:44018", server_addr:"*Not IP address [0]*:0", cluster_name:"undefined", tenant_name:"sys", user_name:"root", error_code:-10018, error_msg:"fail to check observer version, empty result", request_cmd:"COM_SLEEP", sql_cmd:"COM_LOGIN"}{internal_sql:"SELECT ob_version() AS cluster_version"})
+```
+
+The additional diagnostic information is `internal_sql`, which indicates that an internal request is being processed by ODP.
+
+The causes of a disconnection upon a login failure are complex. This section describes the causes and solutions from the perspectives of user operations and OceanBase Database.
+
+The following table describes the disconnection scenarios of user operations and the corresponding solutions.
+
+| Scenario | Error code | Error message | Solution |
+|---------|-------------|-------------|-----------|
+| The cluster name is incorrect. | 4669 | cluster xxx does not exist | Make sure that the corresponding cluster exists and the cluster name is correct. You can directly connect to the OBServer node and run the `show parameters like 'cluster';` command for verification. The `value` value in the output is the name of the cluster to connect to. |
+| The tenant name is incorrect. | 4043 | dummy entry is empty, please check if the tenant exists | Make sure that the corresponding tenant exists. You can directly connect to the OBServer node as the `root@sys` user and execute the `SELECT * FROM DBA_OB_TENANTS;` statement to view all tenants in the cluster. |
+| ODP allowlist verification fails. | 8205 | user xxx@xxx can not pass white list | Check whether ODP allowlists are correctly configured in the console. For more information, see "Allowlists" in [OceanBase Cloud documentation](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001715111). |
+| OceanBase Database allowlist verification fails. | 1227 | Access denied | View the [ob_tcp_invited_nodes](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001105243) variable to check whether OceanBase Database allowlists are correctly configured. |
+| The number of client connections reaches the upper limit. | 5059 | too many sessions | Execute the `ALTER proxyconfig SET = ;` statement to modify the ODP parameter `client_max_connections` to work around this issue. |
+| ODP is configured to use the SSL protocol but a user request is initiated by using a non-SSL protocol. | 8004 | obproxy is configured to use ssl connection | Change the value of the `enable_client_ssl` parameter to `false`, which specifies not to use SSL for connections, or initiate an SSL access request. |
+| The proxyro@sys user is used to directly access OceanBase Database. | 10021 | user proxyro is rejected while proxyro_check on | You cannot directly access OceanBase Database as the `proxyro@sys` user. |
+| A cloud user uses a username in the three-segment format for access when `enable_cloud_full_user_name` is disabled. | 10021 | connection with cluster name and tenant name is rejected while cloud_full_user_name_check off | A cloud user cannot use a username in the three-segment format for access when `enable_cloud_full_user_name` is disabled You can enable the `enable_cloud_full_user_name` parameter or access by using a regular username not in the three-segment format. |
+| The password of the proxyro user is incorrect. | 10018 | fail to check observer version, proxyro@sys access denied, error resp ``{ code:1045, msg:Access denied for user xxx }`` | If the default password for the `proxyro` user is retained, this error will not occur. If you manually change the password of the `proxyro@sys` user in OceanBase Database, make sure that the value of the ODP parameter `observer_sys_password` is the same as the new password of the `proxyro@sys` user. |
+| The configured RootService list is unavailable when ODP is started. | 10018 | fail to check observer version, empty result | Directly connect to the OBServer node and execute the `SHOW PARAMETERS LIKE 'rootservice_list';` statement to view RootService of OceanBase Database to check whether the configured server IP addresses are available when ODP is started. |
+
+The following table describes the disconnection scenarios of OceanBase Database and the corresponding solutions.
+
+| Scenario | Error code | Error message | Solution |
+|---------|-------------|-------------|-----------|
+| The return result of a cluster information query is empty. | 4669 | cluster info is empty | Directly connect to OceanBase Database and execute an SQL statement. Then, view the `internal_sql` column in the output to check whether the cluster information returned from OceanBase Database is empty. |
+| Cluster information query fails. | 10018 | fail to check observer version
fail to check cluster info
fail to init server state | Directly connect to OceanBase Database and execute an SQL statement. Then, view the `internal_sql` column in the output to check whether the cluster information returned from OceanBase Database is empty. |
+| Information query on the config server fails. | 10301 | fail to fetch root server list from config server
fail to fetch root server list from local | Manually pull the config server URL specified by the `obproxy_config_server_url` parameter at startup to check whether the information returned by the config server is normal. |
+
+### Disconnection upon timeout
+
+The diagnostic type is `TIMEOUT_TRACE`. Here is a sample diagnostic log that records a disconnection caused by the timeout of cluster information.
+
+```shell
+[2023-08-17 17:10:46.834897] [119826][Y0-00007FBF120324E0] [CONNECTION](trace_type="TIMEOUT_TRACE", connection_diagnosis={cs_id:1031798785, ss_id:7, proxy_session_id:7230691830869983235, server_session_id:3221504994, client_addr:"10.10.10.1:42468", server_addr:"10.10.10.1:21100", cluster_name:"undefined", tenant_name:"sys", user_name:"root", error_code:-10022, error_msg:"OBProxy inactivity timeout", request_cmd:"COM_SLEEP", sql_cmd:"COM_END"}{timeout:1, timeout_event:"CLIENT_DELETE_CLUSTER_RESOURCE", total_time(us):21736})
+```
+
+The additional fields are described as follows:
+
+* `timeout_event`: indicates the timeout event.
+
+* `total_time`: indicates the request execution time.
+
+The following table describes how to resolve disconnections caused by different timeout events.
+
+| Timeout event | Scenario | Error code | Related parameter | Solution |
+|-------------|--------|---------------|------------|----------|
+| CLIENT_DELETE_CLUSTER_RESOURCE | The cluster information is changed. | 10022 | ODP parameter [cluster_expire_time](https://en.oceanbase.com/docs/common-odp-doc-en-10000000001736050) | Execute the `ALTER proxyconfig SET = ;` statement to modify the ODP parameter `cluster_expire_time` to work around this issue. The default value of `cluster_expire_time` is 1 day. The modification takes effect for new requests. |
+| CLIENT_INTERNAL_CMD_TIMEOUT | The execution of an internal request times out. | 10022 | Fixed value of 30s | This timeout event is abnormal. We recommend that you contact OceanBase Technical Support for help. |
+| CLIENT_CONNECT_TIMEOUT | The connection establishment between the client and ODP times out. | 10022 | Fixed value of 10s | This timeout event is abnormal. We recommend that you contact OceanBase Technical Support for help. |
+| CLIENT_NET_READ_TIMEOUT | A timeout event occurs when ODP waits for requested data. | 10022 | System variable [net_read_timeout](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001105252) of OceanBase Database | Modify the system variable `net_read_timeout`. Note that the modification of a global system variable does not take effect for existing connections. |
+| CLIENT_NET_WRITE_TIMEOUT | A timeout event occurs when ODP waits for a response packet. | 10022 | System variable [net_write_timeout](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001105358) of OceanBase Database | Modify the system variable `net_write_timeout`. Note that the modification of a global system variable does not take effect for existing connections. |
+| CLIENT_WAIT_TIMEOUT | The client connection times out after being left idle for a long period during a user request. | 10022 | System variable [wait_timeout](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001105353) of OceanBase Database | Modify the system variable `wait_timeout` to work around this issue. |
+| SERVER_QUERY_TIMEOUT | A user query request times out. | 10022 | System variable [ob_query_timeout](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001105285) of OceanBase Database and [query_timeout](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001108045) specified in a hint | Modify the `ob_query_timeout` system variable to work around this issue. |
+| SERVER_TRX_TIMEOUT | The transaction execution times out. | 10022 | System variable [ob_trx_timeout](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001105262) of OceanBase Database | Modify the `ob_trx_timeout` system variable to work around this issue. |
+| SERVER_WAIT_TIMEOUT | The connection to OceanBase Database times out after being left idle for a long period during a user request. | 10022 | System variable [wait_timeout](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001105353) of OceanBase Database | Modify the `wait_timeout` system variable to work around this issue. |
+
+### Disconnection initiated by OceanBase Database
+
+The diagnostic type is `SERVER_VC_TRACE`. Here is a sample diagnostic log that records a disconnection when ODP fails to establish a connection with OceanBase Database.
+
+```shell
+[2023-08-10 23:35:00.132805] [32339][Y0-00007F74C9A244E0] [CONNECTION](trace_type="SERVER_VC_TRACE", connection_diagnosis={cs_id:838860809, ss_id:0, proxy_session_id:7230691830869983240, server_session_id:0, client_addr:"10.10.10.1:45765", server_addr:"", cluster_name:"undefined", tenant_name:"sys", user_name:"root", error_code:-10013, error_msg:"Fail to build connection to observer", request_cmd:"COM_QUERY", sql_cmd:"COM_HANDSHAKE"}{vc_event:"unknown event", total_time(us):2952626, user_sql:"select 1 from dual"})
+```
+
+The additional fields are described as follows:
+
+* `vc_event`: indicates the disconnection event. You do not need to be concerned about this field.
+
+* `total_time`: indicates the request execution time.
+
+* `user_sql`: indicates a user request.
+
+The following table describes the scenarios of disconnection actively initiated by OceanBase Database and the corresponding solutions.
+
+| Scenario | Error code | Error message | Solution |
+|---------|-------------|-------------|-----------|
+| ODP fails to establish a connection with OceanBase Database. | 10013 | Fail to build connection to observer | Perform diagnostics based on relevant logs of OceanBase Database. |
+| The connection is disconnected when ODP transmits a request to OceanBase Database. | 10016 | An EOS event received while proxy transferring request | Perform diagnostics based on relevant logs of OceanBase Database. |
+| The connection is disconnected when ODP transmits the packet returned from OceanBase Database. | 10014 | An EOS event received while proxy reading response | Perform diagnostics based on relevant logs of OceanBase Database. |
+
+
+ Note
+ When OceanBase Database actively disconnects from ODP, ODP cannot collect detailed information. If the status of the OBServer node configured in ODP is normal, you need to perform diagnostics based on the relevant logs of OceanBase Database.
+
+
+### Disconnection initiated by the client
+
+The diagnostic type is `CLIENT_VC_TRACE`. Here is a sample diagnostic log that records a disconnection initiated by the client when ODP reads the request.
+
+```shell
+[2023-08-10 23:28:24.699168] [32339][Y0-00007F74C9A244E0] [CONNECTION](trace_type="CLIENT_VC_TRACE", connection_diagnosis={cs_id:838860807, ss_id:26, proxy_session_id:7230691830869983239, server_session_id:3221698209, client_addr:"10.10.10.1:44701", server_addr:"10.10.10.1:21100", cluster_name:"undefined", tenant_name:"sys", user_name:"root", error_code:-10010, error_msg:"An EOS event received from client while obproxy reading request", request_cmd:"COM_SLEEP", sql_cmd:"COM_END"}{vc_event:"VC_EVENT_EOS", total_time(us):57637, user_sql:""})
+```
+
+The additional fields are described as follows:
+
+* `vc_event`: indicates the disconnection event. You do not need to concern about this field.
+
+* `total_time`: indicates the request execution time.
+
+* `user_sql`: indicates a user request.
+
+The following table describes the scenarios of disconnection actively initiated by the client.
+
+| Scenario | Error code | Error message | Solution |
+|---------|-------------|-------------|-----------|
+| The client actively disconnects from ODP when ODP receives or sends a request. | 10010 | An EOS event received from client while obproxy reading request | Perform diagnostics based on relevant logs of the client. |
+| The client actively disconnects from ODP when ODP processes a request. | 10011 | An EOS event received from client while obproxy handling response | Perform diagnostics based on relevant logs of the client. |
+| The client actively disconnects from ODP when ODP returns a packet. | 10012 | An EOS event received from client while obproxy transferring response | Perform diagnostics based on relevant logs of the client. |
+
+
+ Note
+ When the client is disconnected from ODP, ODP cannot collect detailed information and records only the action of the client to actively disconnect from ODP. Active disconnections can be triggered by driver timeout, initiated by middleware such as Druid, HikariCP, and Nginx, or caused by network jitters. You can perform diagnostics based on relevant logs of the client.
+
+
+### Disconnection upon internal errors of ODP or OceanBase Database
+
+The diagnostic type is `PROXY_INTERNAL_TRACE` for disconnections caused by internal errors of ODP, and is `SERVER_INTERNAL_TRACE` for disconnections caused by internal errors of OceanBase Database. Here is a sample diagnostic log that records a disconnection caused by an internal error of ODP.
+
+```shell
+[2023-08-10 23:26:12.558201] [32339][Y0-00007F74C9A244E0] [CONNECTION](trace_type="PROXY_INTERNAL_TRACE", connection_diagnosis={cs_id:838860805, ss_id:0, proxy_session_id:7230691830869983237, server_session_id:0, client_addr:"10.10.10.1:44379", server_addr:"", cluster_name:"undefined", tenant_name:"sys", user_name:"root", error_code:-10019, error_msg:"OBProxy reached the maximum number of retrying request", request_cmd:"COM_QUERY", sql_cmd:"COM_QUERY"}{user_sql:"USE `ý<8f>ý<91>ý<92>`"})
+```
+
+`user_sql` is an additional field that indicates the user request SQL.
+
+The following table describes the scenarios of disconnections caused by internal errors of ODP or OceanBase Database and the corresponding solutions.
+
+| Diagnostic type | Scenario | Error code | Error message | Solution |
+|------------|---------|-------------|-------------|-----------|
+| PROXY_INTERNAL_TRACE | The query for tenant partition information fails. | 4664 | dummy entry is empty, disconnect | This is an unexpected error scenario. You can contact OceanBase Technical Support for help or submit your question in the [Q&A](https://ask.oceanbase.com/) forum of the OceanBase community. |
+| PROXY_INTERNAL_TRACE | The execution of some internal requests of ODP fails. | 10018 | proxy execute internal request failed, received error resp, error_type: xxx | This is an unexpected error scenario. You can contact OceanBase Technical Support for help or submit your question in the [Q&A](https://ask.oceanbase.com/) forum of the OceanBase community. |
+| PROXY_INTERNAL_TRACE | The number of retries in ODP reaches the upper limit. | 10019 | OBProxy reached the maximum number of retrying request | This is an unexpected error scenario. You can contact OceanBase Technical Support for help or submit your question in the [Q&A](https://ask.oceanbase.com/) forum of the OceanBase community. |
+| PROXY_INTERNAL_TRACE | The target session is closed in ODP. | 10001 | target session is closed, disconnect | This is an unexpected error scenario. You can contact OceanBase Technical Support for help or submit your question in the [Q&A](https://ask.oceanbase.com/) section forum of the OceanBase community. |
+| PROXY_INTERNAL_TRACE | Other unexpected error scenarios | 10001 | The diagnostic information is empty. | This is an unexpected error scenario. You can contact OceanBase Technical Support for help or submit your question in the [Q&A](https://ask.oceanbase.com/) forum of the OceanBase community. |
+| SERVER_INTERNAL_TRACE | A checksum verification error occurs. | 10001 | ora fatal error | This is an unexpected error scenario. You can contact OceanBase Technical Support for help or submit your question in the [Q&A](https://ask.oceanbase.com/) forum of the OceanBase community. |
+| SERVER_INTERNAL_TRACE | A primary/standby switchover is performed. | 10001 | primary cluster switchover to standby, disconnect | During a primary/standby switchover, a disconnection is expected. |
+
+### Other scenarios
+
+Besides the preceding scenarios, the following disconnection scenarios are expected and recorded in diagnostic logs. The diagnostic type is `PROXY_INTERNAL_TRACE`.
+
+| Scenario | Error code | Error message | Remarks |
+|---------|-------------|-------------|-----------|
+| The current session is killed. | 5065 | connection was killed by user self, cs_id: xxx | This is an expected scenario and is recorded in diagnostic logs. |
+| Other sessions are killed. | 5065 | connection was killed by user session xxx | This is an expected scenario and is recorded in diagnostic logs. |
+
+Here is a sample diagnostic log. `user_sql` is an additional field that indicates the user request SQL.
+
+```shell
+[2023-08-10 23:27:15.107427] [32339][Y0-00007F74CAAE84E0] [CONNECTION](trace_type="PROXY_INTERNAL_TRACE", connection_diagnosis={cs_id:838860806, ss_id:21, proxy_session_id:7230691830869983238, server_session_id:3221695443, client_addr:"10.10.10.1:44536", server_addr:"10.10.10.1:21100", cluster_name:"undefined", tenant_name:"sys", user_name:"", error_code:-5065, error_msg:"connection was killed by user self, cs_id: 838860806", request_cmd:"COM_QUERY", sql_cmd:"COM_QUERY"}{user_sql:"kill 838860806"})
+```
+
+## Examples
+
+The following figure shows the general links of requests initiated by a client to OceanBase Database.
+
+
+
+A request initiated by a client to OceanBase Database needs to pass multiple nodes. The client connection can be disconnected when an error occurs on any node. Therefore, when a connection is disconnected but the client does not receive any explicit error packet to indicate the cause of the disconnection, identify the node where the disconnection occurs and then find the cause based on the relevant logs on this node. Specifically, perform the following operations:
+
+### Step 1: Identify the node where the disconnection occurs
+
+If the current ODP is capable of connection diagnostics, you can quickly identify the node where the disconnection occurs based on the `obproxy_diagnosis.log` file. You can quickly find the disconnection log based on information such as the username, tenant name, cluster name, thread ID (corresponding to `cs_id` in the log file) obtained from the driver, and the time when the disconnection occurred. Then, determine the node where the disconnection occurs based on the `trace_type` field. Valid values of `trace_type` are as follows:
+
+* `CLIENT_VC_TRACE`: indicates that the disconnection is initiated by the client.
+
+* `SERVER_VC_TRACE`: indicates that the disconnection is initiated by OceanBase Database.
+
+* `SERVER_INTERNAL_TRACE`: indicates that the disconnection is caused by an internal error in OceanBase Database.
+
+* `PROXY_INTERNAL_TRACE`: indicates that the disconnection is caused by an internal error in ODP.
+
+* `LOGIN_TRACE`: indicates that the disconnection is caused by a login failure.
+
+* `TIMEOUT_TRACE`: indicates that the disconnection is caused by a timeout.
+
+### Step 2: Identify the cause of disconnection
+
+You can identify the cause of the disconnection based on the node where the disconnection occurs.
+
+#### Disconnection initiated by the client
+
+The default value of `socketTimeout` is `0` for Java Database Connectivity (JDBC), which indicates that socket timeouts will not occur. However, some clients such as Druid and MyBatis have a socket timeout control parameter. If a disconnection occurs due to a long request execution time, you can first check the value of the socket timeout control parameter. For more information, see [Database connection pool configuration](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001106115) in OceanBase Database documentation.
+
+1. View basic information about the disconnection in the connection diagnostic logs of ODP.
+
+ ```shell
+ [2023-09-07 15:59:52.308553] [122701][Y0-00007F7071D194E0] [CONNECTION](trace_type="CLIENT_VC_TRACE", connection_diagnosis={cs_id:524328, ss_id:0, proxy_session_id:7230691833961840700, server_session_id:0, client_addr:"10.10.10.1:38877", server_addr:"10.10.10.2:50110", cluster_name:"ob1.changluo.cc.10.10.10.2", tenant_name:"mysql", user_name:"root", error_code:-10011, error_msg:"An unexpected connection event received from client while obproxy handling request", request_cmd:"COM_QUERY", sql_cmd:"COM_QUERY"}{vc_event:"VC_EVENT_EOS", total_time(us):5016353, user_sql:"select sleep(20) from dual"})
+ ```
+
+ The fields in the diagnostic information are described as follows:
+
+ * `trace_type`: the diagnostic type, which is `CLIENT_VC_TRACE` in this example, indicating that the disconnection is initiated by the client.
+
+ * `error_msg`: the error message, which is `An unexpected connection event received from client while obproxy handling request` in this example, indicating that the client initiates a disconnection when ODP processes a request.
+
+ * `total_time`: the request execution time, which is `5016353` in this example, indicating that the total request execution time is about 5s. You can check the timeout value on the client.
+
+2. View the JDBC stack of the client.
+
+ ```shell
+ The last packet successfully received from the server was 5,016 milliseconds ago. The last packet sent successfully to the server was 5,011 milliseconds ago.
+ at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
+ at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
+ at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
+ at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
+ at com.mysql.jdbc.Util.handleNewInstance(Util.java:411)
+ at com.mysql.jdbc.SQLError.createCommunicationsException(SQLError.java:1129)
+ at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3720)
+ at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3609)
+ at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4160)
+ at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2617)
+ at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2778)
+ at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2819)
+ at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2768)
+ at com.mysql.jdbc.StatementImpl.execute(StatementImpl.java:949)
+ at com.mysql.jdbc.StatementImpl.execute(StatementImpl.java:795)
+ at odp.Main.main(Main.java:12)
+ Caused by: java.net.SocketTimeoutException: Read timed out
+ at java.net.SocketInputStream.socketRead0(Native Method)
+ at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
+ at java.net.SocketInputStream.read(SocketInputStream.java:170)
+ at java.net.SocketInputStream.read(SocketInputStream.java:141)
+ at com.mysql.jdbc.util.ReadAheadInputStream.fill(ReadAheadInputStream.java:114)
+ at com.mysql.jdbc.util.ReadAheadInputStream.readFromUnderlyingStreamIfNecessary(ReadAheadInputStream.java:161)
+ at com.mysql.jdbc.util.ReadAheadInputStream.read(ReadAheadInputStream.java:189)
+ at com.mysql.jdbc.MysqlIO.readFully(MysqlIO.java:3163)
+ at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3620)
+ 9 more
+ ```
+
+ The stack and packet sending and receiving time indicate that the client initiates a disconnection due to socket timeout.
+
+#### Disconnection initiated by ODP
+
+ODP reads the `net_write_timeout` value from OceanBase Database to control the timeout value for packet transmission. The default value is 60s. In the case of extreme network environment conditions or if OceanBase Database does not return a packet after a long period of time, ODP may be disconnected due to a timeout. Here takes the scenario where a timeout occurs when ODP waits for a response packet from OceanBase Database as an example.
+
+Determine the node where the disconnection occurs based on the diagnostic logs of ODP.
+
+```shell
+[2023-09-08 01:22:17.229436] [81506][Y0-00007F455197E4E0] [CONNECTION](trace_type="TIMEOUT_TRACE", connection_diagnosis={cs_id:1031798827, ss_id:342, proxy_session_id:7230691830869983244, server_session_id:3221753829, client_addr:"10.10.10.1:34901", server_addr:"10.10.10.1:21102", cluster_name:"undefined", tenant_name:"mysql", user_name:"root", error_code:-10022, error_msg:"OBProxy inactivity timeout", request_cmd:"COM_QUERY", sql_cmd:"COM_QUERY"}{timeout(us):6000000, timeout_event:"CLIENT_NET_WRITE_TIMEOUT", total_time(us):31165295})
+```
+
+The fields in the diagnostic information are described as follows:
+
+* `trace_type`: the diagnostic type, which is `TIMEOUT_TRACE` in this example, indicating that the disconnection occurs due to an execution timeout of ODP.
+
+* `timeout_event`: the timeout event, which is `CLIENT_NET_WRITE_TIMEOUT` in this example, indicating that a timeout occurs when ODP waits for a response packet from OceanBase Database.
+
+The diagnostic information indicates that net_write_timeout is triggered. The client connection is disconnected after being left idle for more than 6s (which is not the default value). In this case, you can change the timeout period to a larger value to work around this issue.
+
+#### Login failure
+
+This section provides two scenarios.
+
+* Scenario 1: The OBServer node specified in the RootService list is unavailable. Here is a sample diagnostic log.
+
+ ```shell
+ [2023-09-08 10:37:21.028960] [90663][Y0-00007F8EB76544E0] [CONNECTION](trace_type="LOGIN_TRACE", connection_diagnosis={cs_id:1031798785, ss_id:0, proxy_session_id:0, server_session_id:0, client_addr:"10.10.10.1:44018", server_addr:"*Not IP address [0]*:0", cluster_name:"undefined", tenant_name:"sys", user_name:"root", error_code:-10018, error_msg:"fail to check observer version, empty result", request_cmd:"COM_SLEEP", sql_cmd:"COM_LOGIN"}{internal_sql:"SELECT ob_version() AS cluster_version"})
+ ```
+
+ The fields in the diagnostic information are described as follows:
+
+ * `trace_type`: the diagnostic type, which is `LOGIN_TRACE` in this example, indicating that the disconnection is caused by a login failure.
+
+ * `internal_sql`: the internal request being processed by ODP, which is `SELECT ob_version() AS cluster_version` in this example, indicating that ODP fails to execute this internal request during login.
+
+ * `error_msg`: the error message, which is `fail to check observer version, empty result` in this example, indicating that the request execution failure is caused by an empty result set.
+
+ To sum up, ODP fails to execute the internal request `SELECT ob_version() AS cluster_version` because the result set is empty. The SQL statement `SELECT ob_version() AS cluster_version` is a request for ODP to query the cluster version. ODP executes this request to verify the cluster information when you log in for the first time. If the RootService list configured when ODP is started is incorrect or if the OBServer node breaks down, the query will fail, thereby causing a login failure.
+
+* Scenario 2: The number of client connections reaches the upper limit of ODP.
+
+ You can troubleshoot the issue by using the following methods:
+
+ * Method 1: Check the connection diagnostic logs.
+
+ ```shell
+ [2023-09-08 11:19:26.617385] [110562][Y0-00007FE1F06AC4E0] [CONNECTION](trace_type="LOGIN_TRACE", connection_diagnosis={cs_id:1031798805, ss_id:0, proxy_session_id:0, server_session_id:0, client_addr:"127.0.0.1:40004", server_addr:"*Not IP address [0]*:0", cluster_name:"undefined", tenant_name:"sys", user_name:"root", error_code:-5059, error_msg:"Too many sessions", request_cmd:"COM_SLEEP", sql_cmd:"COM_LOGIN"}{internal_sql:""})
+ ```
+
+ The fields in the diagnostic information are described as follows:
+
+ * `trace_type`: the diagnostic type, which is `LOGIN_TRACE` in this example, indicating that the disconnection is caused by a login failure.
+
+ * `error_msg`: the error message, which is `Too many session` in this example, indicating that the login fails because the number of connections reaches the upper limit.
+
+ * Method 2: Check the error message. The error message `Too many sessions` is returned when you run a connection command.
+
+ ```shell
+ $ obclient -h127.0.0.1 -P2899 -uroot@sys -Dtest -A -c
+ ERROR 1203 (42000): Too many sessions
+ ```
diff --git a/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/04_routing_diagnosis.md b/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/04_routing_diagnosis.md
new file mode 100644
index 000000000..45b5fa0a8
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/04_routing_diagnosis.md
@@ -0,0 +1,490 @@
+---
+title: Troubleshoot ODP Routing Issues
+Weight: 4
+---
+
+> This topic describes the background of the routing diagnostics feature, how to obtain diagnostic information, and how to locate and solve issues based on diagnostic information.
+
+OceanBase Database Proxy (ODP) serves as the access and routing layers of OceanBase Database and routing is its core feature. In earlier versions, routing issues are difficult to troubleshoot. Therefore, ODP V4.2.1 provides the routing diagnostics feature. This feature allows you to set diagnostic points during the routing process of an SQL statement in ODP to record key status information. The diagnostic points are then returned in logs or the result set.
+
+You can analyze the diagnostic points to learn about the routing process of an SQL statement in ODP.
+
+## Routing Diagnostics Procedure
+
+To use the routing diagnostics feature for troubleshooting, perform the following steps:
+
+1. Obtain diagnostic information. For more information, see the "Obtain Diagnostic Information" section of this topic.
+
+2. Perform troubleshooting based on the diagnostic information. For more information, see the "Overview" section of this topic.
+
+
+## Obtain Diagnostic Information
+
+This topic describes two methods for obtaining diagnostic information.
+
+### Obtain diagnostic information by running a command
+
+You can run the `explain route ;` command to obtain the routing status information of an SQL statement. If the value of `route_diagnosis_level` is not `0`, this command will return detailed diagnostic information. The statement specified by `` will undergo the forwarding process in ODP without being actually forwarded to an OBServer node.
+
+`route_diagnosis_level` is a global parameter that controls how detailed the routing status information is. The value is an integer. The default value is `2`, which indicates that the output information can cover level-2 diagnostic points.
+
+The value range of the `route_diagnosis_level` parameter is [0, 4]. A larger value indicates more detailed status information. The value `0` specifies to disable this module. When this module is disabled, it does not occupy the memory of ODP or affect the performance of ODP.
+
+This command does not apply to the following statements:
+
+* COM_STMT_PREPARE
+
+* COM_STMT_PREPARE_EXECUTE
+
+* COM_STMT_CLOSE
+
+* COM_STMT_RESET
+
+* `PREPARE statement_name FROM preparable_SQL_statement;`
+
+* `{DEALLOCATE | DROP} PREPARE stmt_name;`
+
+* Internal statements of ODP
+
+#### Examples
+
+Execute the `SELECT * FROM test.list_sub_parts_my_01 WHERE c3='1999-09-09' AND c1=mod(1999,1000) AND c2='tiger0'` statement to query a table that does not exist.
+
+```sql
+obclient> EXPLAIN ROUTE SELECT * FROM test.list_sub_parts_my_01 WHERE c3='1999-09-09' AND c1=mod(1999,1000) AND c2='tiger0'\G
+```
+
+The output is as follows:
+
+```sql
+*************************** 1. row ***************************
+Route Plan:
+Trans First Query:"SELECT * FROM test.list_sub_parts_my_01"
+Trans Current Query:"EXPLAIN ROUTE SELECT * FROM test.list_sub_parts_my_01 WHERE c3='1999-09-09' AND c1=mod(1999,1000) AND c2='tiger0'"
+Route Prompts
+-----------------
+> ROUTE_INFO
+ [INFO] Will do table partition location lookup to decide which OBServer to route to
+> TABLE_ENTRY_LOOKUP_DONE
+ [INFO] No available entry because table entry lookup failed
+> ROUTE_INFO
+ [INFO] Will route to cached connected server(10.10.10.1:4001)
+
+Route Plan
+-----------------
+> SQL_PARSE:{cmd:"COM_QUERY", table:"list_sub_parts_my_01"}
+> ROUTE_INFO:{route_info_type:"USE_PARTITION_LOCATION_LOOKUP", in_transaction:true}
+> LOCATION_CACHE_LOOKUP:{mode:"oceanbase"}
+ > TABLE_ENTRY_LOOKUP_START:{}
+ > FETCH_TABLE_RELATED_DATA:{table_entry:"partition information does not exist"}
+ > TABLE_ENTRY_LOOKUP_DONE:{is_lookup_succ:true, entry_from_remote:false}
+> ROUTE_INFO:{route_info_type:"USE_CACHED_SESSION", svr_addr:"10.10.10.1:4001", in_transaction:true}
+> CONGESTION_CONTROL:{svr_addr:"10.10.10.1:4001"}
+```
+
+The result set is described as follows:
+
+* `Trans First Query`: the first statement in the transaction.
+
+* `Trans Current Query`: the current statement in the transaction.
+
+* `Route Prompts`: the description of steps in the routing process. Two types of prompts exist: `[INFO]` and `[WARN]`.
+
+ * `[INFO]`: some information returned during normal routing to help you understand the routing process. In this example, `[INFO]` information is returned in the `ROUTE_INFO` section. The information indicates that ODP routes the request to an OBServer node based on the partition location.
+
+ * `[WARN]`: information returned when an exception occurs in a step of the routing process.
+
+* `Route Plan`: the forwarding process in ODP. `SQL_PARSE`, `ROUTE_INFO`, and `LOCATION_CACHE_LOOKUP` are diagnostic points. Diagnostic points can be at the same level or in hierarchical relationships and are displayed in a tree structure.
+
+The `FETCH_TABLE_RELATED_DATA:{table_entry:"partition information does not exist"}` information in the `Route Plan` section indicates that ODP queries the partition information about this table but no partition information exists.
+
+In most cases, you can locate an issue based on the information returned in the `Route Prompts` and `Route Plan` sections.
+
+### Diagnostic logs
+
+If an SQL statement meets any of the following conditions, ODP will record the actual routing process in the `obproxy_diagnosis.log` file.
+
+* The statement is not an `EXPLAIN ROUTE executable_sql;` statement.
+
+* No partition is hit (`is_partition_hit = false`) or the value of `route_diagnosis_level` is `4`.
+
+The log level is WARN or TRACE, depending on the scenario of the current statement.
+
+* WARN logs are recorded in the following cases:
+
+ * The current statement belongs to a distributed transaction.
+
+ * The statement is the first statement of a transaction.
+
+* TRACE logs are recorded in the following cases:
+
+ * The current statement belongs to a regular transaction.
+
+ * The table name is left empty in the statement.
+
+ * The length of the statement exceeds the value of `request_buffer_length`.
+
+ * Partition key calculation fails.
+
+The following command words are supported in diagnostic logs:
+
+* COM_QUERY
+
+* COM_STMT_PREPARE_EXECUTE
+
+* COM_STMT_PREPARE
+
+* COM_STMT_SEND_PIECE_DATA
+
+* COM_STMT_GET_PIECE_DATA
+
+* COM_STMT_FETCH
+
+* COM_STMT_SEND_LONG_DATA
+
+* Non-internal statements of ODP
+
+#### Examples
+
+In the `obproxy_diagnosis.log` file, find the target row by keyword and replace '/n' with '\n' to obtain the diagnostic process in a tree structure.
+
+The command is `grep "some_key_word" obproxy_diagnosis.log | sed "s/\/n/\n/g"`. Here is an example:
+
+```shell
+$ grep "2023-08-17 16:56:46.521180" obproxy_diagnosis.log | sed "s/\/n/\n/g"
+```
+
+The output is as follows:
+
+```shell
+[2023-08-17 16:56:46.521180] [31792][Y0-00007F38DAAF34E0] [ROUTE]((*route_diagnosis=
+Trans Current Query:"select * from test.range_sub_parts_my_01 where c1=22222 and c2=111111 and c3=abcd"
+...
+> PARTITION_ID_CALC_DONE
+ [WARN] Fail to calculate first part idx may use route policy or cached server session
+
+Route Plan
+> SQL_PARSE:{cmd:"COM_QUERY", table:"range_sub_parts_my_01"}
+> ROUTE_INFO:{route_info_type:"USE_PARTITION_LOCATION_LOOKUP"}
+> LOCATION_CACHE_LOOKUP:{mode:"oceanbase"}
+ > TABLE_ENTRY_LOOKUP_DONE:{table:"range_sub_parts_my_01", table_id:1099511677778, partition_num:16, table_type:"USER TABLE", entry_from_remote:false}
+ > PARTITION_ID_CALC_START:{}
+ > EXPR_PARSE:{col_val:[[0]["c1", "22222"], [1]["c2", "111111"], [2]["c3", ""]]}
+ > RESOLVE_EXPR:{error:-4002, sub_part_range:"(111111,MIN ; 111111,MAX)"}
+ > RESOLVE_TOKEN:{resolve:{"BIGINT":22222}, token_type:"TOKEN_INT_VAL", token:"22222"}
+ > RESOLVE_TOKEN:{resolve:{"BIGINT":111111}, token_type:"TOKEN_INT_VAL", token:"111111"}
+ > RESOLVE_TOKEN:{error:-4002, , token_type:"TOKEN_COLUMN", token:"abcd"}
+ > PARTITION_ID_CALC_DONE:{error:-4002, partition_id:-1, level:2, partitions:"(p-1sp-1)"}
+> ROUTE_POLICY:{replica:"10.10.10.1:50110", idc_type:"SAME_IDC", zone_type:"ReadWrite", role:"FOLLOWER", type:"FULL", chosen_route_type:"ROUTE_TYPE_NONPARTITION_UNMERGE_LOCAL", route_policy:"MERGE_IDC_ORDER_OPTIMIZED", trans_consistency:"STRONG", session_consistency:"STRONG"}
+> CONGESTION_CONTROL:{svr_addr:"10.10.10.1:50110"}
+> HANDLE_RESPONSE:{is_parititon_hit:"false", state:"CONNECTION_ALIVE"}
+)
+```
+
+The diagnostic procedure is as follows:
+
+1. Based on the `[WARN] Fail to calculate first part idx may use route policy or cached server session` information in `PARTITION_ID_CALC_DONE`, partition ID calculation fails, and the request is routed based on the routing strategy or by reusing a session.
+
+2. Check the data near the `PARTITION_ID_CALC_DONE` diagnostic point. The `RESOLVE_TOKEN:{error:-4002, , token_type:"TOKEN_COLUMN", token:"abcd"}` information indicates that ODP encounters an error in parsing `c3=abcd`.
+
+
+## Overview
+
+> A diagnostic point describes a key procedure in the routing and forwarding process on ODP. You can view diagnostic points to learn about the routing and forwarding process. This topic describes how to troubleshoot issues based on diagnostic points.
+
+### Troubleshooting procedure
+
+After you obtain diagnostic information, you can perform different troubleshooting operations based on whether the routed request is in the transaction.
+
+#### Request in the transaction
+
+If a request in a transaction is inaccurately routed, two cases are involved.
+
+* Distributed transaction routing
+
+ * If the current request is inaccurately routed, check the diagnostic points based on the diagnostic procedure.
+
+ * If the current request is routed to the coordinator node, extract the SQL statement in `Trans First Query`, pass the statement to the `explain route` command to execute the statement again, and check the diagnostic points based on the diagnostic procedure.
+
+* Non-distributed transaction routing
+
+ The current request is routed together with the first statement in the transaction. In this case, extract the SQL statement in `Trans First Query`, pass the statement to the `explain route` command to execute the statement again, and check the diagnostic points based on the diagnostic procedure.
+
+#### Request not in the transaction
+
+If an inaccurately routed request is not in a transaction, you can directly check the diagnostic points based on the diagnostic procedure.
+
+### Diagnostic procedure
+
+After you obtain diagnostic information by running the `explain route` command or from diagnostic logs, you can check each diagnostic point based on the following procedure. For more information about the variables to diagnose at each diagnostic point, see the following topics of diagnostic points.
+
+The following table summarizes the diagnostic points based on the execution sequence. A higher diagnostic level indicates more detailed diagnostic information.
+
+
+ Note
+
+ -
+
Not all data of diagnostic points is recorded in logs or returned in the result set. Only data useful to the current situation is recorded or returned.
+
+ -
+
The TABLE_ENTRY_LOOKUP_START and PARTITION_ID_CALC_START diagnostic points have no data and are used only to maintain the tree structure of diagnostic points.
+
+
+
+
+
+
+
+ | Diagnostic phase |
+ Diagnostic point |
+ Diagnostic point level |
+
+
+
+ | Syntax parsing |
+ SQL_PARSE |
+ 1 |
+
+
+ | Routing information acquisition |
+ ROUTE_INFO |
+ 1 |
+
+
+ | Replica location acquisition |
+ LOCATION_CACHE_LOOKUP |
+ 1 |
+
+
+ | ROUTINE_ENTRY_LOOKUP_DONE |
+ 2 |
+
+
+ | TABLE_ENTRY_LOOKUP_START |
+ 2 |
+
+
+ | FETCH_TABLE_RELATED_DATA |
+ 3 |
+
+
+ | TABLE_ENTRY_LOOKUP_DONE |
+ 2 |
+
+
+ | PARTITION_ID_CALC_START |
+ 2 |
+
+
+ | EXPR_PARSE |
+ 3 |
+
+
+ | CALC_ROWID |
+ 3 |
+
+
+ | RESOLVE_EXPR |
+ 3 |
+
+
+ | RESOLVE_TOKEN |
+ 4 |
+
+
+ | CALC_PARTITION_ID |
+ 3 |
+
+
+ | PARTITION_ID_CALC_DONE |
+ 2 |
+
+
+ | PARTITION_ENTRY_LOOKUP_DONE |
+ 2 |
+
+
+ | Node selection based on the routing strategy |
+ ROUTE_POLICY |
+ 1 |
+
+
+ | Replica access control |
+ CONGESTION_CONTROL |
+ 1 |
+
+
+ | Response handling |
+ HANDLE_RESPONSE |
+ 1 |
+
+
+ | Replica selection and retry |
+ RETRY |
+ 1 |
+
+
+
+#### Diagnostic tips
+
+* Pay attention to the WARN information in `Route Prompts` and the diagnostic data near the corresponding diagnostic point.
+
+* Pay attention to the error information in `Route Plan`.
+
+* Set `route_diagnosis_level` to `4` and `monitor_log_level` to 'TRACE' and view the diagnostic results of all user requests in the diagnostic logs.
+
+ For more information about `route_diagnosis_level`, see [route_diagnosis_level](https://en.oceanbase.com/docs/common-odp-doc-en-10000000001736104). For more information about `monitor_log_level`, see [monitor_log_level](https://en.oceanbase.com/docs/common-odp-doc-en-10000000001736057).
+
+**Diagnostic points are not described here. These diagnostic points involve too much content related to the ODP workflow and specific implementations. If you can directly understand and analyze the diagnostic information obtained by using `EXPLAIN ROUTE` based on your background knowledge (mainly based on intuition), that would be great. If you cannot understand the information, record the diagnostic information obtained and contact the on-duty staff in the OceanBase community forum for assistance in troubleshooting. **
+
+## Examples
+
+This topic provides several examples to describe how to use the routing diagnostics feature in MySQL mode.
+
+> The following examples assume that route_diagnosis_level is set to `4`.
+
+### Example 1: PS/PL statement call
+
+If it is difficult to find the actually executed statement when a prepared statement (PS)/PL statement call is inaccurately routed, you can view the corresponding diagnostic logs.
+
+```shell
+[2023-09-19 18:48:49.079458] [106700][Y0-00007FD892AB64E0] [ROUTE]((*route_diagnosis=
+Trans Current Query:"execute stmt"
+Route Prompts
+--------------
+> ROUTE_INFO
+ [INFO] Will do table partition location lookup to decide which OBServer to route to
+> ROUTE_POLICY
+ [INFO] Will route to table's partition leader replica(10.10.10.1:4001) using non route policy because query for STRONG read
+Route Plan
+--------------
+> SQL_PARSE:{cmd:"COM_QUERY", table:"t0"}
+> ROUTE_INFO:{route_info_type:"USE_PARTITION_LOCATION_LOOKUP"}
+> LOCATION_CACHE_LOOKUP:{mode:"oceanbase"}
+ > TABLE_ENTRY_LOOKUP_DONE:{table:"t0", table_id:"500078", table_type:"USER TABLE", partition_num:64, entry_from_remote:false}
+ > PARTITION_ID_CALC_START:{}
+ > EXPR_PARSE:{col_val:"=88888888,=1111111"}
+ > RESOLVE_EXPR:{part_range:"[88888888 ; 88888888]", sub_part_range:"[1111111 ; 1111111]"}
+ > RESOLVE_TOKEN:{token_type:"TOKEN_INT_VAL", resolve:"BIGINT:88888888", token:"88888888"}
+ > RESOLVE_TOKEN:{token_type:"TOKEN_INT_VAL", resolve:"BIGINT:1111111", token:"1111111"}
+ > CALC_PARTITION_ID:{part_description:"partition by hash(INT) partitions 8 subpartition by hash(INT) partitions 8"}
+ > PARTITION_ID_CALC_DONE:{partition_id:200073, level:2, partitions:"(p0sp7)", parse_sql:"prepare stmt from 'insert into t0 values(88888888,1111111,9999999)'"}
+ > PARTITION_ENTRY_LOOKUP_DONE:{leader:"10.10.10.1:4001", entry_from_remote:false}
+> ROUTE_POLICY:{chosen_route_type:"ROUTE_TYPE_LEADER"}
+> CONGESTION_CONTROL:{svr_addr:"10.10.10.1:4001"}
+```
+
+You can find the output of the executed statement in the `parse_sql` field of the diagnostic information of the `PARTITION_ID_CALC_DONE` diagnostic point.
+
+### Example 2: Partitioned table query
+
+#### Inaccurate partitioned table-based routing because partitioning key values are not provided
+
+Assume that `t0` is a subpartitioned table and the executed statement `select * from t0 where c1=1` is inaccurately routed. Run the following command for routing diagnostics:
+
+```sql
+obclient> EXPLAIN ROUTE select * from t0 where c1=1\G
+```
+
+The output is as follows:
+
+```shell
+Trans Current Query:"select * from t0 where c1=1"
+Route Prompts
+--------------
+> ROUTE_INFO
+ [INFO] Will do table partition location lookup to decide which OBServer to route to
+> PARTITION_ID_CALC_DONE
+ [WARN] Fail to use partition key value to calculate sub part idx
+Route Plan
+--------------
+> SQL_PARSE:{cmd:"COM_QUERY", table:"t0"}
+> ROUTE_INFO:{route_info_type:"USE_PARTITION_LOCATION_LOOKUP"}
+> LOCATION_CACHE_LOOKUP:{mode:"oceanbase"}
+ > TABLE_ENTRY_LOOKUP_DONE:{table:"t0", table_id:"500078", table_type:"USER TABLE", partition_num:64, entry_from_remote:false}
+ > PARTITION_ID_CALC_START:{}
+ > EXPR_PARSE:{col_val:"c1=1"}
+ > RESOLVE_EXPR:{part_range:"[1 ; 1]", sub_part_range:"(MIN ; MAX)always true"}
+ > RESOLVE_TOKEN:{token_type:"TOKEN_INT_VAL", resolve:"BIGINT:1", token:"1"}
+ > CALC_PARTITION_ID:{error:-4002, part_description:"partition by hash(INT) partitions 8 subpartition by hash(INT) partitions 8"}
+> PARTITION_ID_CALC_DONE:{error:-4002, partition_id:-1, level:2, partitions:"(p1sp-1)"}
+```
+
+Check the diagnostic result.
+
+1. The `PARTITION_ID_CALC_DONE [WARN] Fail to use partition key value to calculate sub part idx` information in `Route Prompts` indicates that subpartition location calculation fails.
+
+2. Check whether relevant information exists near `PARTITION_ID_CALC_DONE` in `Route Plan`.
+
+3. The diagnostic information at the diagnostic point `RESOLVE_EXPR:{part_range:"[1 ; 1]", sub_part_range:"(MIN ; MAX)always true"}` indicates that the subpartition range is `MIN:MAX`. Therefore, the subpartition location cannot be determined.
+
+4. It can be deemed that subpartitioning key values are not provided in `Trans Current Query:"select * from t0 where c1=1"`.
+
+#### Inaccurate partitioned table-based routing when partitioning key values are calculated by using an unsupported expression
+
+Assume that `t0` is a partitioned table and the executed statement `select * from t0 where c1=abs(-100.123);` is inaccurately routed. View the corresponding diagnostic log.
+
+```shell
+[2023-09-19 19:43:11.029616] [106683][Y0-00007FD890E544E0] [ROUTE]((*route_diagnosis=
+Trans Current Query:"select * from t0 where c1=abs(-100.123)"
+Route Prompts
+--------------
+> ROUTE_INFO
+ [INFO] Will do table partition location lookup to decide which OBServer to route to
+> RESOLVE_TOKEN
+ [WARN] Not support to resolve expr func(abs)
+Route Plan
+--------------
+> SQL_PARSE:{cmd:"COM_QUERY", table:"t0"}
+> ROUTE_INFO:{route_info_type:"USE_PARTITION_LOCATION_LOOKUP"}
+> LOCATION_CACHE_LOOKUP:{mode:"oceanbase"}
+ > TABLE_ENTRY_LOOKUP_DONE:{table:"t0", table_id:"500078", table_type:"USER TABLE", partition_num:64, entry_from_remote:false}
+ > PARTITION_ID_CALC_START:{}
+ > EXPR_PARSE:{col_val:"c1=abs"}
+ > RESOLVE_EXPR:{error:-5055, part_range:"(MIN ; MAX)always true", sub_part_range:"(MIN ; MAX)always true"}
+ > RESOLVE_TOKEN:{error:-5055, token_type:"TOKEN_FUNC", token:"abs"}
+ > PARTITION_ID_CALC_DONE:{error:-5055, partition_id:-1, level:2, partitions:"(p-1sp-1)"}
+> ROUTE_INFO:{route_info_type:"USE_CACHED_SESSION", svr_addr:"10.10.10.1:4001"}
+> CONGESTION_CONTROL:{svr_addr:"10.10.10.1:4001"}
+> HANDLE_RESPONSE:{is_parititon_hit:"true", send_action:"SERVER_SEND_REQUEST", state:"CMD_COMPLETE"}
+)
+```
+
+In the diagnostic result, the information `RESOLVE_TOKEN [WARN] Not support to resolve expr func(abs)` indicates that the abs expression fails to be parsed. As a result, the partitioning key values cannot be correctly calculated, leading to inaccurate routing.
+
+### Strategy-based routing
+
+Assume that the `SELECT 100 - max(round(total / mem_limit * 100)) FROM oceanbase.gv$ob_memstore` statement is not routed as expected. Run the following command for routing diagnostics:
+
+```sql
+obclient> EXPLAIN ROUTE SELECT 100 - max(round(total / mem_limit * 100)) FROM oceanbase.gv$ob_memstore\G
+```
+
+The output is as follows:
+
+```shell
+*************************** 1. row ***************************
+Route Plan:
+Trans Current Query:"EXPLAIN ROUTE SELECT 100 - max(round(total / mem_limit * 100)) FROM oceanbase.gv$ob_memstore"
+Route Prompts
+-----------------
+> ROUTE_INFO
+ [INFO] Will do table partition location lookup to decide which OBServer to route to
+> TABLE_ENTRY_LOOKUP_DONE
+ [INFO] Non-partition table will be routed by ROUTE_POLICY
+> ROUTE_POLICY
+ [INFO] All OBServers treated as the SAME_IDC with OBProxy because 'proxy_idc_name' is not configured
+ [INFO] Will route to routing type(NONPARTITION_UNMERGE_LOCAL) matched replica(10.10.10.1:4001) using default route policy MERGE_IDC_ORDER because query for STRONG read
+```
+
+The information `[INFO] All OBServers treated as the SAME_IDC with OBProxy because 'proxy_idc_name' is not configured` indicates that the `proxy_idc_name` parameter is not configured. Therefore, ODP considers that all OBServer nodes are in the same IDC. As a result, LDC-based routing becomes invalid.
+
+
+
+## References
+
+- [Overview](https://en.oceanbase.com/docs/common-odp-doc-en-10000000001736148)
+
+ > A complete ODP routing diagnostics document is available on the official website of OceanBase Database.
+ >
+ > The content of this topic is based on the documentation on the official website, with some deletions and additions. Specifically, the introduction of each diagnostic point is deleted. Diagnostic points are used by OceanBase Technical Support and R&D engineers for fault analysis. You do not need to dive deep into this, but feel free to gain a basic understanding if it interests you.
\ No newline at end of file
diff --git a/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/_category_.yml b/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/_category_.yml
new file mode 100644
index 000000000..552438178
--- /dev/null
+++ b/docs/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/_category_.yml
@@ -0,0 +1 @@
+label: ODP Community Edition Troubleshooting Manual
diff --git a/docs/user_manual/operation_and_maintenance/zh-CN/tool_emergency_handbook/01_oms_troubleshooting_guide.md b/docs/user_manual/operation_and_maintenance/zh-CN/tool_emergency_handbook/01_oms_troubleshooting_guide.md
index 426ec2546..dfac906dc 100644
--- a/docs/user_manual/operation_and_maintenance/zh-CN/tool_emergency_handbook/01_oms_troubleshooting_guide.md
+++ b/docs/user_manual/operation_and_maintenance/zh-CN/tool_emergency_handbook/01_oms_troubleshooting_guide.md
@@ -304,7 +304,7 @@ slice 分片-> source 读取源端-> dispatcher 数据分发-> sink 写入目标
wget 'localhost:17006/p_47qaxxxsu8_source-000-0' --post-data 'filter.conditions=*.*.*&checkpoint=1667996779'
```
-
+
## 典型使用场景和功能
diff --git a/docusaurus.config.ts b/docusaurus.config.ts
index fc2cb70dc..fbc3bd1cd 100644
--- a/docusaurus.config.ts
+++ b/docusaurus.config.ts
@@ -24,6 +24,10 @@ const user_manual = [
label: 'Operation And Maintenance Manual (in Chinese)',
to: '/docs/user_manual/operation_and_maintenance/zh-CN/about_this_manual/overview',
},
+ {
+ label: 'Operation And Maintenance Manual (in English)',
+ to: '/docs/user_manual/operation_and_maintenance/en-US/about_this_manual/overview',
+ },
];
const dev_manual = [
@@ -79,8 +83,8 @@ const community = [
href: 'http://github.com/oceanbase/oceanbase/discussions',
},
{
- label: 'Slack',
- href: 'https://join.slack.com/t/oceanbase/shared_invite/zt-1e25oz3ol-lJ6YNqPHaKwY_mhhioyEuw',
+ label: 'Discord',
+ href: 'https://discord.gg/74cF8vbNEs',
},
{
label: 'Forum (in Chinese)',
diff --git a/sidebars.ts b/sidebars.ts
index dbcaa4976..bc5f79a88 100644
--- a/sidebars.ts
+++ b/sidebars.ts
@@ -201,6 +201,64 @@ const sidebars: SidebarsConfig = {
}]
},
],
+ operation_and_maintenanceEnglishSidebar: [
+ {
+ type: 'category',
+ label: 'About "DBA Advanced Tutorial"',
+ items: [{
+ type: 'autogenerated',
+ dirName: 'user_manual/operation_and_maintenance/en-US/about_this_manual'
+ }]
+ },
+ {
+ type: 'category',
+ label: 'Disaster Recovery Architecture Design',
+ items: [{
+ type: 'autogenerated',
+ dirName: 'user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design'
+ }]
+ },
+ {
+ type: 'category',
+ label: 'Operation and Maintenance Management',
+ items: [{
+ type: 'autogenerated',
+ dirName: 'user_manual/operation_and_maintenance/en-US/operations_and_maintenance'
+ }]
+ },
+ {
+ type: 'category',
+ label: 'Best Practice Scenarios',
+ items: [{
+ type: 'autogenerated',
+ dirName: 'user_manual/operation_and_maintenance/en-US/scenario_best_practices'
+ }]
+ },
+ {
+ type: 'category',
+ label: 'Development Specification',
+ items: [{
+ type: 'autogenerated',
+ dirName: 'user_manual/operation_and_maintenance/en-US/development_specification'
+ }]
+ },
+ {
+ type: 'category',
+ label: 'OBServer Emergency Handbook',
+ items: [{
+ type: 'autogenerated',
+ dirName: 'user_manual/operation_and_maintenance/en-US/emergency_handbook'
+ }]
+ },
+ {
+ type: 'category',
+ label: 'Community Tools Troubleshooting Guide',
+ items: [{
+ type: 'autogenerated',
+ dirName: 'user_manual/operation_and_maintenance/en-US/tool_emergency_handbook'
+ }]
+ },
+ ],
blogsSidebar: [{ type: 'autogenerated', dirName: 'blogs' }],
}
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/about_this_manual/001.png b/static/img/user_manual/operation_and_maintenance/en-US/about_this_manual/001.png
new file mode 100644
index 000000000..102eec2ac
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/about_this_manual/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/about_this_manual/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/about_this_manual/001.psd
new file mode 100644
index 000000000..06fa8a4c6
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/about_this_manual/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/development_specification/01_object_specification/001.png b/static/img/user_manual/operation_and_maintenance/en-US/development_specification/01_object_specification/001.png
new file mode 100644
index 000000000..2be8bd3fb
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/development_specification/01_object_specification/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/development_specification/02_charset_specification/001.png b/static/img/user_manual/operation_and_maintenance/en-US/development_specification/02_charset_specification/001.png
new file mode 100644
index 000000000..dd4f6e000
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/development_specification/02_charset_specification/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/01-001.png b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/01-001.png
new file mode 100644
index 000000000..34dbfd7b9
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/01-001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/01-001.psd b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/01-001.psd
new file mode 100644
index 000000000..61bdd5a8c
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/01-001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(1).png b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(1).png
new file mode 100644
index 000000000..28f2b68ea
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(1).png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(1).psd b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(1).psd
new file mode 100644
index 000000000..c50aeb81d
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(1).psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(2).png b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(2).png
new file mode 100644
index 000000000..1f0b1d1ef
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(2).png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(2).psd b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(2).psd
new file mode 100644
index 000000000..364e723c2
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(2).psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(3).png b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(3).png
new file mode 100644
index 000000000..98301c70d
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(3).png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(3).psd b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(3).psd
new file mode 100644
index 000000000..ed1f889fd
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(3).psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(4).png b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(4).png
new file mode 100644
index 000000000..60af2327b
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(4).png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(4).psd b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(4).psd
new file mode 100644
index 000000000..275e03758
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/disaster_recovery_architecture_design/04(4).psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/01_emergency_overview/001.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/01_emergency_overview/001.png
new file mode 100644
index 000000000..5a7824e23
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/01_emergency_overview/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/01_emergency_overview/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/01_emergency_overview/001.psd
new file mode 100644
index 000000000..fc1f03f1c
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/01_emergency_overview/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/001.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/001.png
new file mode 100644
index 000000000..1917b6f75
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/001.psd
new file mode 100644
index 000000000..b0c522796
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/002.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/002.png
new file mode 100644
index 000000000..d53dd5a42
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/002.psd b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/002.psd
new file mode 100644
index 000000000..5eeafc64d
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/002.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/003.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/003.png
new file mode 100644
index 000000000..54cd2ade0
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/003.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/004.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/004.png
new file mode 100644
index 000000000..646a85e38
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/004.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/005.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/005.png
new file mode 100644
index 000000000..41c0f2d3a
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/005.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/005.psd b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/005.psd
new file mode 100644
index 000000000..87570e61b
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/005.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/006.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/006.png
new file mode 100644
index 000000000..a19e2bbb0
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/006.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/007.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/007.png
new file mode 100644
index 000000000..d3aa5874d
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/007.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/007.psd b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/007.psd
new file mode 100644
index 000000000..d8682735d
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/007.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/Thumbs.db b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/Thumbs.db
new file mode 100644
index 000000000..eace387f3
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/02_slow_response/Thumbs.db differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/001.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/001.png
new file mode 100644
index 000000000..dec8532f6
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/001.psd
new file mode 100644
index 000000000..5e5a95059
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/002.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/002.png
new file mode 100644
index 000000000..8de88f557
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/3.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/3.png
new file mode 100644
index 000000000..c76fc043c
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/3.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/4.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/4.png
new file mode 100644
index 000000000..234a005ef
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/4.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/5.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/5.png
new file mode 100644
index 000000000..eed7714a8
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/5.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/6.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/6.png
new file mode 100644
index 000000000..f6988b480
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/6.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/8.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/8.png
new file mode 100644
index 000000000..c76fc043c
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/03_cpu_high/8.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/04_node_breakdown/001.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/04_node_breakdown/001.png
new file mode 100644
index 000000000..71e3ff4c2
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/04_node_breakdown/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/04_node_breakdown/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/04_node_breakdown/001.psd
new file mode 100644
index 000000000..c6f496512
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/04_node_breakdown/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/002.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/002.png
new file mode 100644
index 000000000..d9ee4a180
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/002.psd b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/002.psd
new file mode 100644
index 000000000..bdbe962f6
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/002.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/003.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/003.png
new file mode 100644
index 000000000..6b95da8f7
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/003.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/003.psd b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/003.psd
new file mode 100644
index 000000000..d0e487281
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/003.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/1.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/1.png
new file mode 100644
index 000000000..a1dd454f5
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/1.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/4.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/4.png
new file mode 100644
index 000000000..47562f175
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/05_network_problem/4.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/06_disk_problem/1.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/06_disk_problem/1.png
new file mode 100644
index 000000000..009f5a4d0
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/06_disk_problem/1.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/06_disk_problem/2.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/06_disk_problem/2.png
new file mode 100644
index 000000000..1faabd27f
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/06_disk_problem/2.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/08_how_to_ask/001.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/08_how_to_ask/001.png
new file mode 100644
index 000000000..8b1dfcb0c
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/08_how_to_ask/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/08_how_to_ask/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/08_how_to_ask/001.psd
new file mode 100644
index 000000000..19cb2349c
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/08_how_to_ask/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/08_how_to_ask/002.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/08_how_to_ask/002.png
new file mode 100644
index 000000000..778dedd49
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/08_how_to_ask/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/08_how_to_ask/3.png b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/08_how_to_ask/3.png
new file mode 100644
index 000000000..b5eef23e1
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/emergency_handbook/08_how_to_ask/3.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/001.png b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/001.png
new file mode 100644
index 000000000..533b9806b
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/001.psd
new file mode 100644
index 000000000..4ac0ba223
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/002.png b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/002.png
new file mode 100644
index 000000000..8c4ce1799
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/002.psd b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/002.psd
new file mode 100644
index 000000000..3060a3f89
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/002.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/003.png b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/003.png
new file mode 100644
index 000000000..c4f510c6a
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/003.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/003.psd b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/003.psd
new file mode 100644
index 000000000..931494d28
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/003.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/005.png b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/005.png
new file mode 100644
index 000000000..fe7d56e3e
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/005.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/005.psd b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/005.psd
new file mode 100644
index 000000000..6388e04b8
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/005.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/006.png b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/006.png
new file mode 100644
index 000000000..d389c665f
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/006.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/007.png b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/007.png
new file mode 100644
index 000000000..4020cd950
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/007.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/008.png b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/008.png
new file mode 100644
index 000000000..41efd151b
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/008.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/009.png b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/009.png
new file mode 100644
index 000000000..432d385f1
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/009.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/010.png b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/010.png
new file mode 100644
index 000000000..7ecc189fa
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/010.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/010.psd b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/010.psd
new file mode 100644
index 000000000..c5320a14c
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/010.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/Thumbs.db b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/Thumbs.db
new file mode 100644
index 000000000..8f56d8974
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/01_version_upgrade_path/Thumbs.db differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/02_commonly_used_sql/001.png b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/02_commonly_used_sql/001.png
new file mode 100644
index 000000000..efde4eb95
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/02_commonly_used_sql/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/02_commonly_used_sql/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/02_commonly_used_sql/001.psd
new file mode 100644
index 000000000..5a43bae9e
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/02_commonly_used_sql/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/02_commonly_used_sql/Thumbs.db b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/02_commonly_used_sql/Thumbs.db
new file mode 100644
index 000000000..304dcc159
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/operations_and_maintenance/02_commonly_used_sql/Thumbs.db differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/001.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/001.png
new file mode 100644
index 000000000..ad9d6812b
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/002.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/002.png
new file mode 100644
index 000000000..0a5b426ef
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/003.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/003.png
new file mode 100644
index 000000000..9a382ddf2
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/003.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/004.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/004.png
new file mode 100644
index 000000000..12c265a4b
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/004.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/005.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/005.png
new file mode 100644
index 000000000..f7911b608
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/005.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/006.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/006.png
new file mode 100644
index 000000000..3c067a404
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/006.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/007.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/007.png
new file mode 100644
index 000000000..9712fa5d3
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/007.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/008.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/008.png
new file mode 100644
index 000000000..944916edf
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/01_parameter_templates/008.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/01_introduction/001.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/01_introduction/001.png
new file mode 100644
index 000000000..c173a69b4
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/01_introduction/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/01_introduction/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/01_introduction/001.psd
new file mode 100644
index 000000000..6db15d029
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/01_introduction/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/01_introduction/002.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/01_introduction/002.png
new file mode 100644
index 000000000..d5845db99
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/01_introduction/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/01_introduction/Thumbs.db b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/01_introduction/Thumbs.db
new file mode 100644
index 000000000..1feac20ea
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/01_introduction/Thumbs.db differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/001.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/001.png
new file mode 100644
index 000000000..6887cf7b0
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/001.psd
new file mode 100644
index 000000000..f5368b68c
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/002.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/002.png
new file mode 100644
index 000000000..f79ae4745
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/002.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/002.psd
new file mode 100644
index 000000000..b770361d6
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/002.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/003.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/003.png
new file mode 100644
index 000000000..d29cff5a7
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/003.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/003.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/003.psd
new file mode 100644
index 000000000..02c4fe9a6
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/003.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/004.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/004.png
new file mode 100644
index 000000000..8cb8f6e94
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/004.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/004.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/004.psd
new file mode 100644
index 000000000..9f4c26256
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/004.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/Thumbs.db b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/Thumbs.db
new file mode 100644
index 000000000..f616e9c9e
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/02_background_knowledge/Thumbs.db differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/03_resource_isolation_between_tenants/001.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/03_resource_isolation_between_tenants/001.png
new file mode 100644
index 000000000..8d39f1f8f
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/03_resource_isolation_between_tenants/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config/001.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config/001.png
new file mode 100644
index 000000000..4b7f90a9c
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config/001.psd
new file mode 100644
index 000000000..1e5268430
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config/002.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config/002.png
new file mode 100644
index 000000000..08678c64c
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config/002.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config/002.psd
new file mode 100644
index 000000000..44b4bbce4
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config/002.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config/Thumbs.db b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config/Thumbs.db
new file mode 100644
index 000000000..06c5c0dd7
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/02_cgroup_config/Thumbs.db differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/001.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/001.png
new file mode 100644
index 000000000..260c71e94
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/001.psd
new file mode 100644
index 000000000..c1401023d
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/002.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/002.png
new file mode 100644
index 000000000..d82026ee6
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/002.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/002.psd
new file mode 100644
index 000000000..75f5f2d3f
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/002.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/003.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/003.png
new file mode 100644
index 000000000..de497c9f3
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/003.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/004.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/004.png
new file mode 100644
index 000000000..ab93211b8
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/004.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/005.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/005.png
new file mode 100644
index 000000000..e0c5b2557
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/005.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/006.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/006.png
new file mode 100644
index 000000000..b6bc8e87d
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/006.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/Thumbs.db b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/Thumbs.db
new file mode 100644
index 000000000..07aed055b
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_01_multi_tenants/04_resource_isolation_within_a_tenant/05_effect_of_resource_isolation/Thumbs.db differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction/001.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction/001.png
new file mode 100644
index 000000000..30f851a5b
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction/001.psd
new file mode 100644
index 000000000..fd7bd40aa
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction/002.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction/002.png
new file mode 100644
index 000000000..55ee8405d
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction/002.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction/002.psd
new file mode 100644
index 000000000..1fd485eeb
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction/002.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction/Thumbs.db b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction/Thumbs.db
new file mode 100644
index 000000000..49ba1b108
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/01_introduction/Thumbs.db differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/001.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/001.png
new file mode 100644
index 000000000..3581229ae
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/001.psd
new file mode 100644
index 000000000..34aa959f9
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/002.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/002.png
new file mode 100644
index 000000000..48021eaca
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/002.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/002.psd
new file mode 100644
index 000000000..e07be87af
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/002.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/003.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/003.png
new file mode 100644
index 000000000..3a883566b
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/003.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/003.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/003.psd
new file mode 100644
index 000000000..d110e00e6
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/003.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/004.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/004.png
new file mode 100644
index 000000000..5ad8e34f3
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/004.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/004.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/004.psd
new file mode 100644
index 000000000..c5d0abede
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/004.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/005.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/005.png
new file mode 100644
index 000000000..b1f8bdf3a
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/005.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/005.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/005.psd
new file mode 100644
index 000000000..49f2b1df8
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/005.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/006.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/006.png
new file mode 100644
index 000000000..b3ce749cc
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/006.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/006.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/006.psd
new file mode 100644
index 000000000..369166d3b
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/006.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/007.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/007.png
new file mode 100644
index 000000000..eadf56bb0
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/007.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/007.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/007.psd
new file mode 100644
index 000000000..6079e01cd
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/007.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/Thumbs.db b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/Thumbs.db
new file mode 100644
index 000000000..a73c9ffd2
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/02_background_knowledge/Thumbs.db differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/001.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/001.png
new file mode 100644
index 000000000..21e23b1a5
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/001.psd
new file mode 100644
index 000000000..de7f9372e
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/002.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/002.png
new file mode 100644
index 000000000..2c3b4b87c
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/002.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/002.psd
new file mode 100644
index 000000000..d28f73a4c
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/002.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/003.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/003.png
new file mode 100644
index 000000000..f5997cd5f
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/003.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/004.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/004.png
new file mode 100644
index 000000000..61acfcc19
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/004.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/005.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/005.png
new file mode 100644
index 000000000..52b0e398a
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/005.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/006.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/006.png
new file mode 100644
index 000000000..ccf29f237
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/006.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/007.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/007.png
new file mode 100644
index 000000000..00e9682b7
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/007.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/008.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/008.png
new file mode 100644
index 000000000..e49739efa
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/008.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/009.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/009.png
new file mode 100644
index 000000000..3c4ed7f8e
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/009.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/010.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/010.png
new file mode 100644
index 000000000..0555ac959
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/010.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/Thumbs.db b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/Thumbs.db
new file mode 100644
index 000000000..422918d1c
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_02_archive_database/03_data_archive_best_practices/Thumbs.db differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/001.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/001.png
new file mode 100644
index 000000000..c7039d24e
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/001.psd
new file mode 100644
index 000000000..7fffc7fa8
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/002.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/002.png
new file mode 100644
index 000000000..ee7bca0ef
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/002.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/002.psd
new file mode 100644
index 000000000..414a87202
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/002.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/003.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/003.png
new file mode 100644
index 000000000..9f62ed406
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/003.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/003.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/003.psd
new file mode 100644
index 000000000..fd7ac9832
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/003.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/004.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/004.png
new file mode 100644
index 000000000..6c27258c6
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/004.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/004.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/004.psd
new file mode 100644
index 000000000..0869061d2
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/004.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/005.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/005.png
new file mode 100644
index 000000000..12dfb5e82
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/005.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/005.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/005.psd
new file mode 100644
index 000000000..828f78eb4
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/005.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/006.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/006.png
new file mode 100644
index 000000000..e1b1b4b85
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/006.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/006.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/006.psd
new file mode 100644
index 000000000..150ed196a
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/006.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/Thumbs.db b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/Thumbs.db
new file mode 100644
index 000000000..6bed65ffc
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/01_introduction/Thumbs.db differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/02_background_knowledge/001.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/02_background_knowledge/001.png
new file mode 100644
index 000000000..4e2934e7a
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/02_background_knowledge/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/02_background_knowledge/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/02_background_knowledge/001.psd
new file mode 100644
index 000000000..bc576e607
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/02_background_knowledge/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/02_background_knowledge/Thumbs.db b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/02_background_knowledge/Thumbs.db
new file mode 100644
index 000000000..14184144d
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/02_background_knowledge/Thumbs.db differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/001.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/001.png
new file mode 100644
index 000000000..08c320803
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/001.psd
new file mode 100644
index 000000000..ad20e7e8c
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/002.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/002.png
new file mode 100644
index 000000000..71ab30abb
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/002.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/002.psd
new file mode 100644
index 000000000..a9e93002a
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/002.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/003.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/003.png
new file mode 100644
index 000000000..351b344f5
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/003.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/004.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/004.png
new file mode 100644
index 000000000..3417f73c3
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/004.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/004.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/004.psd
new file mode 100644
index 000000000..46731f9be
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/004.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/Thumbs.db b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/Thumbs.db
new file mode 100644
index 000000000..c5cafa0bc
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/03_read_write_separation_best_practices/Thumbs.db differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/001.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/001.png
new file mode 100644
index 000000000..44f56de46
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/001.psd
new file mode 100644
index 000000000..0a727325c
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/002.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/002.png
new file mode 100644
index 000000000..5d0483f24
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/002.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/002.psd
new file mode 100644
index 000000000..4e33182ac
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/002.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/003.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/003.png
new file mode 100644
index 000000000..f1e528ab5
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/003.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/003.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/003.psd
new file mode 100644
index 000000000..832531aba
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/003.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/004.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/004.png
new file mode 100644
index 000000000..6ddb13191
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/004.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/004.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/004.psd
new file mode 100644
index 000000000..b1cea7a35
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/004.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/005.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/005.png
new file mode 100644
index 000000000..fe2580123
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/005.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/005.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/005.psd
new file mode 100644
index 000000000..759617fe4
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/005.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/006.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/006.png
new file mode 100644
index 000000000..94bb979fc
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/006.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/006.psd b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/006.psd
new file mode 100644
index 000000000..954d1d6ba
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/006.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/Thumbs.db b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/Thumbs.db
new file mode 100644
index 000000000..3e686761e
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/04_htap_best_practices/Thumbs.db differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/05_performance_tuning/001.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/05_performance_tuning/001.png
new file mode 100644
index 000000000..6d7920393
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/05_performance_tuning/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/05_performance_tuning/002.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/05_performance_tuning/002.png
new file mode 100644
index 000000000..834335d91
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/05_performance_tuning/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/05_performance_tuning/003.png b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/05_performance_tuning/003.png
new file mode 100644
index 000000000..82a253656
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/scenario_best_practices/chapter_03_htap/05_performance_tuning/003.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/001.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/001.png
new file mode 100644
index 000000000..6dd9a1e69
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/001.psd
new file mode 100644
index 000000000..c060d152c
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/002.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/002.png
new file mode 100644
index 000000000..d4d3a0e69
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/003.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/003.png
new file mode 100644
index 000000000..88d089048
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/003.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/004.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/004.png
new file mode 100644
index 000000000..451f3f8a9
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/004.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/005.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/005.png
new file mode 100644
index 000000000..5f64f9749
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/005.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/005.psd b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/005.psd
new file mode 100644
index 000000000..88b8fb068
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/005.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/zh-CN/tool_emergency_handbook/01_oms_troubleshooting_guide/006png.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/006.png
similarity index 100%
rename from static/img/user_manual/operation_and_maintenance/zh-CN/tool_emergency_handbook/01_oms_troubleshooting_guide/006png.png
rename to static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/006.png
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/007.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/007.png
new file mode 100644
index 000000000..484098318
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/007.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/007.psd b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/007.psd
new file mode 100644
index 000000000..201baf1fa
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/01_oms_troubleshooting_guide/007.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/000.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/000.png
new file mode 100644
index 000000000..940c11d8a
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/000.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/000.psd b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/000.psd
new file mode 100644
index 000000000..698383828
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/000.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/001.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/001.png
new file mode 100644
index 000000000..2e85cc67f
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/001.psd
new file mode 100644
index 000000000..7e5d9905e
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/002.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/002.png
new file mode 100644
index 000000000..1c1736d73
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/002.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/002.psd b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/002.psd
new file mode 100644
index 000000000..e7eeefeb8
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/002.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/003.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/003.png
new file mode 100644
index 000000000..275575f27
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/003.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/004.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/004.png
new file mode 100644
index 000000000..895406ffa
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/004.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/005.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/005.png
new file mode 100644
index 000000000..a3fdb4e97
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/005.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/006.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/006.png
new file mode 100644
index 000000000..ebea8ff9a
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/006.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/006.psd b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/006.psd
new file mode 100644
index 000000000..ed397e4ed
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/006.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/007.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/007.png
new file mode 100644
index 000000000..f9e08af30
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/007.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/007.psd b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/007.psd
new file mode 100644
index 000000000..ff05e52bd
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/007.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/008.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/008.png
new file mode 100644
index 000000000..7b60b9760
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/008.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/008.psd b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/008.psd
new file mode 100644
index 000000000..34b178375
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/008.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/009.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/009.png
new file mode 100644
index 000000000..6ff3ff4c2
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/009.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/009.psd b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/009.psd
new file mode 100644
index 000000000..20a6e479f
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/01_introduction/009.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/02_show_trace/001.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/02_show_trace/001.png
new file mode 100644
index 000000000..a4b314296
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/02_show_trace/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/02_show_trace/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/02_show_trace/001.psd
new file mode 100644
index 000000000..c57e83a0a
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/02_show_trace/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/03_connection_diagnosis/001.png b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/03_connection_diagnosis/001.png
new file mode 100644
index 000000000..dfa06c052
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/03_connection_diagnosis/001.png differ
diff --git a/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/03_connection_diagnosis/001.psd b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/03_connection_diagnosis/001.psd
new file mode 100644
index 000000000..c9ea1e1ac
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/en-US/tool_emergency_handbook/odp_troubleshooting_guide/03_connection_diagnosis/001.psd differ
diff --git a/static/img/user_manual/operation_and_maintenance/zh-CN/tool_emergency_handbook/01_oms_troubleshooting_guide/006.png b/static/img/user_manual/operation_and_maintenance/zh-CN/tool_emergency_handbook/01_oms_troubleshooting_guide/006.png
new file mode 100644
index 000000000..36e597d91
Binary files /dev/null and b/static/img/user_manual/operation_and_maintenance/zh-CN/tool_emergency_handbook/01_oms_troubleshooting_guide/006.png differ