Table of Contents
My best timeline of GPT efforts is listed here: https://lspace.swyx.io/p/open-source-ai
- WebText and OpenWebText
- GPT-2’s training data is based on Reddit, which according to Pew Internet Research’s 2016 survey, 67% of Reddit users in the US are men, 64% between ages 18 and 29. https://stanford-cs324.github.io/winter2022/lectures/data/
- Common Crawl: https://commoncrawl.org/
- We build and maintain an open repository of web crawl data that can be accessed and analyzed by anyone.
- January 2015 it was over 139TB in size and contains 1.82 billion webpages. https://commoncrawl.github.io/cc-crawl-statistics/plots/crawlsize
- growing steadily at 200-300 TB per month for the last few years.
- March 2021: 6.4 PB
- https://commoncrawl.github.io/cc-crawl-statistics/
- OSCAR corpus from INRIA. OSCAR is a huge multilingual corpus obtained by language classification and filtering of Common Crawl dumps of the Web.
- C4: https://paperswithcode.com/dataset/c4
- C4 is a colossal, cleaned version of Common Crawl's web crawl corpus. It was based on Common Crawl dataset: https://commoncrawl.org. It was used to train the T5 text-to-text Transformer models.
- It comes in four variants:
en: 305GB in JSON formaten.noblocklist: 380GB in JSON formaten.noclean: 2.3TB in JSON formatrealnewslike: 15GB in JSON format
- The Pile: https://arxiv.org/abs/2101.00027
- an 825 GiB English text corpus targeted at training large-scale language models. The Pile is constructed from 22 diverse high-quality subsets -- both existing and newly constructed -- many of which derive from academic or professional sources
- behind the scenes of the collection https://news.ycombinator.com/item?id=34359453
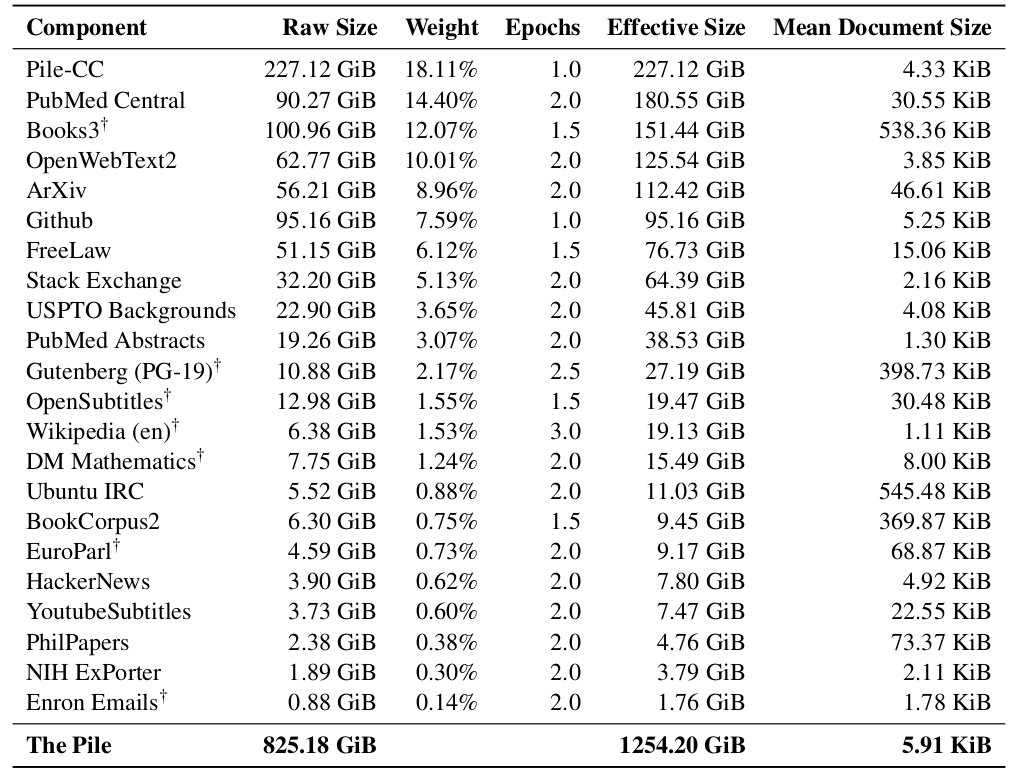
GPT3 data https://stanford-cs324.github.io/winter2022/lectures/data/#gpt-3-dataset

- GPT3 advanced a lot through 2020-2022 https://twitter.com/tszzl/status/1572350675014516738
- Eleuther's GPT-J-6B, GPT-NeoX
- Google
- PaLM 570B
- https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/
- FLAN-T5
-
- Flan-T5 checkpoints are publicly available (without requesting access)
- Flan-T5 11B outperforms OPT-IML on MMLU and Big-Bench Hard, despite being 10x more compute efficient
- https://huggingface.co/docs/transformers/model_doc/flan-t5
-
- PaLM 570B
- Yandex YaLM 100B https://medium.com/yandex/yandex-publishes-yalm-100b-its-the-largest-gpt-like-neural-network-in-open-source-d1df53d0e9a6
- It took us 65 days to train the model on a pool of 800 A100 graphics cards and 1.7 TB of online texts, books, and countless other sources.
- Tsinghua GLM-130B
- outperforms OpenAI's GPT-3 175B and Google's PALM 540B on critical benchmarks. AND it's open sourced, which means — you can run this model on your own machine, for free.
- only trained on 400B tokens (compared to 1.2T tokens for Chinchilla's 70B parameters)
- https://twitter.com/AndyChenML/status/1611529311390949376?s=20
- Meta
- OPT-175B https://opt.alpa.ai/ (bad reviews)
- OPT-IML (Instruction Meta-Learning): instruction tuned https://github.com/facebookresearch/metaseq/tree/main/projects/OPT-IML
- a new language model from Meta AI with 175B parameters, fine-tuned on 2,000 language tasks — openly available soon under a noncommercial license for research use cases.
- instruction-finetuned, leverages Chinchilla scaling laws, and has bells and whistles like 4-bit quantization and bidirectional attention. With 4-bit quantization, the model can run on 1 x 80 GB A100 or a consumer GPU rig.
- https://twitter.com/MetaAI/status/1605991218953191424
- underperforms Flan-T5 https://twitter.com/_jasonwei/status/1621333297891790848?s=20
- FlashAttention - 3-5x faster training (tweet, huggingface)
- GPT-JT for classification
- GPT 3.5 (https://beta.openai.com/docs/model-index-for-researchers)
- code-davinci-002 is a base model, so good for pure code-completion tasks
- text-davinci-002 is an InstructGPT model based on code-davinci-002
- text-davinci-003 is an improvement on text-davinci-002
- https://scale.com/blog/gpt-3-davinci-003-comparison
- 003 is 30% better at classifying, can rhyme, output iambic pentameter, is more verbose (42 words per sentence vs 23).
- https://twitter.com/amix3k/status/1597504050852859904
- https://twitter.com/_brivael_/status/1597625080418533377
- https://scale.com/blog/gpt-3-davinci-003-comparison
- InstructGPT https://openai.com/blog/instruction-following/
- ChatGPT: https://openai.com/blog/chatgpt/
- We’ve trained a model called ChatGPT which interacts in a conversational way. The dialogue format makes it possible for ChatGPT to answer followup questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests.

- gpt4 speculations and improvement directions https://mobile.twitter.com/mayfer/status/1607816595065409536
- https://twitter.com/RamaswmySridhar/status/1605603050403483652?s=20&t=0zl_ZGLHLxjgJ-FLk-m-Fg
- Biggest model size for GPT-4 will be 1T parameters. Up 6x. Not 100T - The reason is simple: instruction fine tuning achieves same quality with 100x smaller models.
- GPT-4 will use 10T tokens. Up 33x, and putting them on the Chinchilla scaling curve.
- We expect 16384 tokens
- Biggest pre-training modeling change? A loss function that looks like UL2
- Put together, at least 800x more compute for the pre-trained model.
GPT3 applications:
- text to graphviz https://twitter.com/goodside/status/1561549768987496449?s=21&t=rliacnWOIjJMiS37s8qCCw
- suspending to python for math
- Amelia paragraph sumarizer https://twitter.com/Wattenberger/status/1412480516268437512�
- Karina Nguyen Synevyr https://twitter.com/karinanguyen_/status/1566884536054677506
- Lex.page
- https://github.com/louis030195/obsidian-ava obsidian integration
- https://humanloop.com/ Playground that brings variable interpolation to prompts and lets you turn them into API endpoints. Once you're deployed, it also lets you collect past generations along with user behavioral feedback for fine-tunes.
- https://www.everyprompt.com/ extends Playground in a similar way: Putting variables in prompts and giving you a single button to go from prompt to API. Has nice developer-oriented touches in the UI too — e.g. displaying invisible chars as ghosts.
- explaining code diffs https://app.whatthediff.ai/dashboard
- LangChain https://twitter.com/hwchase17/status/1588183981312180225
- implements and lets you easily compose many published LLM prompting techniques. Implements self-asking, web search, REPL math, and several of my own prompts.
- All relevant chains now have a "verbose" option to highlight text according to the model or component (SQL DB, search engine, python REPL, etc) that it's from.
- https://dust.tt/ gives a collapsible tree UI for representing k-shot example datasets, prompt templates, and prompt chaining with intermediate JS code. Replaces a lot of code around prompt APIs.
- playing chess??? https://twitter.com/Raza_Habib496/status/1591514638520311809
- chrome extension
- simulating people
- Making stories with characters https://medium.com/@turc.raluca/introducing-rick-and-mortify-a14e56a8cb67
wiring up LLMs to python https://twitter.com/karpathy/status/1593081701454204930?s=20&t=2ra2Yfz0NFSbfJ_IGixNjA
- Overview
- Beginner
- go through all the GPT3 examples https://beta.openai.com/examples
- Intermediate
- and deploy GPT2 https://huggingface.co/gpt2
- play with the smaller GPT3 models https://beta.openai.com/docs/models/gpt-3
- technique: self-asking, two step prompts https://twitter.com/OfirPress/status/1577302998136819713
- chain of thought prompting https://twitter.com/OfirPress/status/1577303423602790401
- https://ai.googleblog.com/2022/05/language-models-perform-reasoning-via.html (emerges at around 100B params)
- Prompt structure with extensive examples
- review feedback extraction https://www.youtube.com/watch?v=3EjtHs_lXnk&t=1009s
- Ask Me Anything prompting
- using gpt3 for text2image prompts https://twitter.com/fabianstelzer/status/1554229347506176001
- Advanced
- write a blogpost with GPT3 https://www.youtube.com/watch?v=NC7990PmDfM
- solving advent of code https://github.com/max-sixty/aoc-gpt/blob/main/openai.py
- integrating Google Search with GPT3: https://twitter.com/OfirPress/status/1577302733383925762
- teach AI how to fish - You are X, you can do Y: https://github.com/nat/natbot/blob/main/natbot.py
- play with gpt-neoX and gpt-j https://neox.labml.ai/playground
- defense against prompt injection https://twitter.com/goodside/status/1578278974526222336
- whatever the f this is https://twitter.com/goodside/status/1578614244290924545
- https://github.com/dair-ai/Prompt-Engineering-Guide
- Applications:
- Approaches/Techniques:
- Ask Me Anything: A simple strategy for prompting language models
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
- AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts
- Large Language Models Are Human-Level Prompt Engineers
- Structured Prompting: Scaling In-Context Learning to 1,000 Examples
- Reframing Instructional Prompts to GPTk's Language
- Promptagator: Few-shot Dense Retrieval From 8 Examples
- Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm
- PromptChainer: Chaining Large Language Model Prompts through Visual Programming
- Academics
- P3: Public pool of prompts https://huggingface.co/datasets/bigscience/P3
- and Promptsource https://github.com/bigscience-workshop/promptsource
- Real-world Annotated Few-shot Tasks (RAFT) dataset https://huggingface.co/datasets/ought/raft
- Study chain of thought reasoning https://ai.googleblog.com/2022/05/language-models-perform-reasoning-via.html
- and self-consistency (Sample a diverse set of reasoning paths on the same model) to improve it https://arxiv.org/abs/2203.11171
- and UL2 20B https://ai.googleblog.com/2022/10/ul2-20b-open-source-unified-language.html
- building GPT-JT: https://www.together.xyz/blog/releasing-v1-of-gpt-jt-powered-by-open-source-ai
- P3: Public pool of prompts https://huggingface.co/datasets/bigscience/P3
- original paper Improving Language Understanding by Generative Pre-Training Radford et al 2018 https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
- https://github.com/karpathy/minGPT
- announcement https://twitter.com/karpathy/status/1295410274095095810
- used in https://www.mosaicml.com/blog/gpt-3-quality-for-500k
- check out nanoGPT too
- https://yaofu.notion.site/How-does-GPT-Obtain-its-Ability-Tracing-Emergent-Abilities-of-Language-Models-to-their-Sources-b9a57ac0fcf74f30a1ab9e3e36fa1dc1
- There are three important abilities that the initial GPT-3 exhibit: Language generation, In-context learning, World knowledge
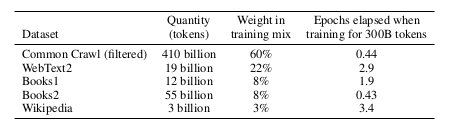
- to pretrain the 175B parameters model on 300B tokens (60% 2016 - 2019 C4 https://www.tensorflow.org/datasets/catalog/c4 + 22% WebText2 + 16% Books + 3% Wikipedia).
- Language generation comes from training objective
- World knowldge comes from 300b token corpus and stored in 175b model
- The ability of complex reasoning with chain-of-thought is likely to be a magical side product of training on code
- We have concluded:
- The language generation ability + basic world knowledge + in-context learning are from pretraining (
davinci) - The ability to store a large amount of knowledge is from the 175B scale.
- The ability to follow instructions and generalizing to new tasks are from scaling instruction tuning (
davinci-instruct-beta) - The ability to perform complex reasoning is likely to be from training on code (
code-davinci-002) - The ability to generate neutral, objective, safe, and informative answers are from alignment with human. Specifically:
- If supervised tuning, the resulting model is
text-davinci-002 - If RLHF, the resulting model is
text-davinci-003 - Either supervised or RLHF, the models cannot outperform code-davinci-002 on many tasks, which is called the alignment tax.
- If supervised tuning, the resulting model is
- The dialog ability is also from RLHF (
ChatGPT), specifically it tradeoffs in-context learning for:- Modeling dialog history
- Increased informativeness
- Rejecting questions outside the model’s knowledge scope
- The language generation ability + basic world knowledge + in-context learning are from pretraining (
- Reasoning: https://twitter.com/alexandr_wang/status/1588933553290870785
- Understanding: https://twitter.com/EMostaque/status/1585903983180537856
- Scientific language models like Meta's Galactica exist. Commentary https://news.ycombinator.com/item?id=33614608
- directory
- Jasper
- CopyAI
- Features of existing products
- NotionAI
- https://hashnode.com/neptune
- Email
- Ellie email https://twitter.com/JamesIvings/status/1602855048148500480
- Everyprompt mail
- https://merlin.foyer.work/
- Summarizers
- explainpaper
- kagi universal summarizer https://labs.kagi.com/ai/sum?url=airbyte.io
- SQL
- preplexity.ai/sql
- Newer
- https://www.protocol.com/generative-ai-startup-landscape-map
- https://metaphor.systems/
- dust.tt
- tools that make tools (toolbot.ai)
- https://lex.page (announcement)
- CLI https://twitter.com/KevinAFischer/status/1601883697061380096?s=20
- Zapier OpenAI integrations https://zapier.com/apps/openai/integrations
- SlackGPT https://zapier.com/shared/query-gpt-3-via-a-slack-channel/a7551c53beda75b3bf65c315f027de04a4b323ef
- got3discord moderator https://github.com/Kav-K/GPT3Discord
- extract gpt chrome extension https://twitter.com/kasrak/status/1624515411973922816?s=20
- Embra macos desktop chatgptlike
- https://twitter.com/zachtratar/status/1623015294569713665?s=20&t=hw_somO_R_JxGp4zQpFz0Q
- competes with Dust XP1
- Writing
- Verb (fiction) https://twitter.com/verbforwriters/status/1603051444134895616
- Orchard https://www.orchard.ink/doc/201a7f63-731e-4487-926a-fdf348f1b00c
- Deepmind Dramatron https://deepmind.github.io/dramatron/details.html for co-writing theatre scripts and screenplays. Starting from a log line, Dramatron interactively generates character descriptions, plot points, location descriptions and dialogue. These generations provide human authors with material for compilation, editing, and rewriting.
- BearlyAI https://twitter.com/TrungTPhan/status/1597623720239329280f
- google sheets https://twitter.com/mehran__jalali/status/1608159307513618433
mostly from https://twitter.com/goodside/status/1588247865503010816
- Humanloop.com Playground - variable interpolations + api endpoints, collect generations with feedback
- Everyprompt.com Playground - similar to above with ux improvements
- Introducing http://Promptable.ai The Ultimate Workspace for Prompt Engineering
-
- A Delightful Prompt Editor - Organize Prompts in Folders. - Stream completions. - Add variables. - Change Model Parameters (even custom models!)
-
- Batch Testing! We built a table that you can run completions on to evaluate your prompts How? - Add multiple inputs that your prompt needs to handle - Click run and process them in batch. - Add annotation columns (MultiSelect, Markdown) to keep track of the status of Inputs
-
- Version and Deploy. You're happy with your completions, You added some test cases. It's time to ship! Deploy your prompt and fetch the latest version from our API. Simple storage. No added latency between you and your LLM.
-
- Langchain python package - implements many techniques
- Lamdaprompt https://github.com/approximatelabs/lambdaprompt
- used in pandas extension https://github.com/approximatelabs/sketch
- https://gpt-index.readthedocs.io/en/latest/ GPT Index is a project consisting of a set of data structures designed to make it easier to use large external knowledge bases with LLMs.
- Dust.tt - tree UI for k-shot datasets, prompt templates, prompt chaining
- Spellbook from ScaleAI - automatically write k-shots, eval metrics for prompt varaints, prompts to spreadsheet functions
- Linus/thesephist tools
- tree of branches https://twitter.com/thesephist/status/1590545448066252800
- scrubbing a text for length https://twitter.com/thesephist/status/1587929014848540673
- Most knowledge work isn't a text-generation task, and your product shouldn't ship an implementation detail of LLMs as the end-user interface https://twitter.com/thesephist/status/1592924891208372224
- mozilla's readability-cli https://www.npmjs.com/package/readability-cli (tip)
- there is actually a paper by OpenAI themselves on summarizing long document. essentially, break a longer text into smaller chunks, and run a multi-stage sequential summarization. each chunk uses a trailing window of previous chunk as context, and run this recursively. https://arxiv.org/abs/2109.10862. more: https://news.ycombinator.com/item?id=34423822
- https://github.com/jerryjliu/gpt_index
- Current state: LLM’s have made phenomenal progress in encoding knowledge as well as reasoning. BUT a big limitation of LLM’s is context size (4096 in Davinci), and if you want to feed an LLM custom knowledge it will either need to fit in the prompt or be finetuned (expensive)!
- https://twitter.com/mathemagic1an/status/1609225733934616577?s=46&t=DgrykKeTlGWgdxRkv2_tKw
- godly ai https://godly.ai
- HyDE: Hypothetical Document Embeddings
- https://twitter.com/mathemagic1an/status/1615378778863157248
- Take your query => create hypothetical answer => embed hypothetical answer => use this to search through doc embeddings
- Structured Prompting: Scaling In-Context Learning to 1,000 Examples
- tokens are more 16x expensive for other languages https://denyslinkov.medium.com/why-is-gpt-3-15-77x-more-expensive-for-certain-languages-2b19a4adc4bc
- Galactica fallout
- https://twitter.com/quocleix/status/1583523186376785921
- Flan-T5 is instruction-finetuned on 1,800+ language tasks, leading to dramatically improved prompting and multi-step reasoning abilities.
- 7 min summary video https://www.youtube.com/watch?v=oqi0QrbdgdI
- OpenAI NarrativeQA Summarizing books https://openai.com/blog/summarizing-books/