AI agents are not apps. They are not APIs. They are not dashboards. They are repositories.
When you define an AI agent as files in a git repo — its identity in markdown, its config in YAML, its skills in folders — something remarkable happens. Fourteen patterns emerge for free. Not features someone built. Consequences of the medium.
These are the 14 git-native patterns behind GitAgent. Each one takes something hard about managing AI agents and makes it trivial — because git already solved it decades ago.
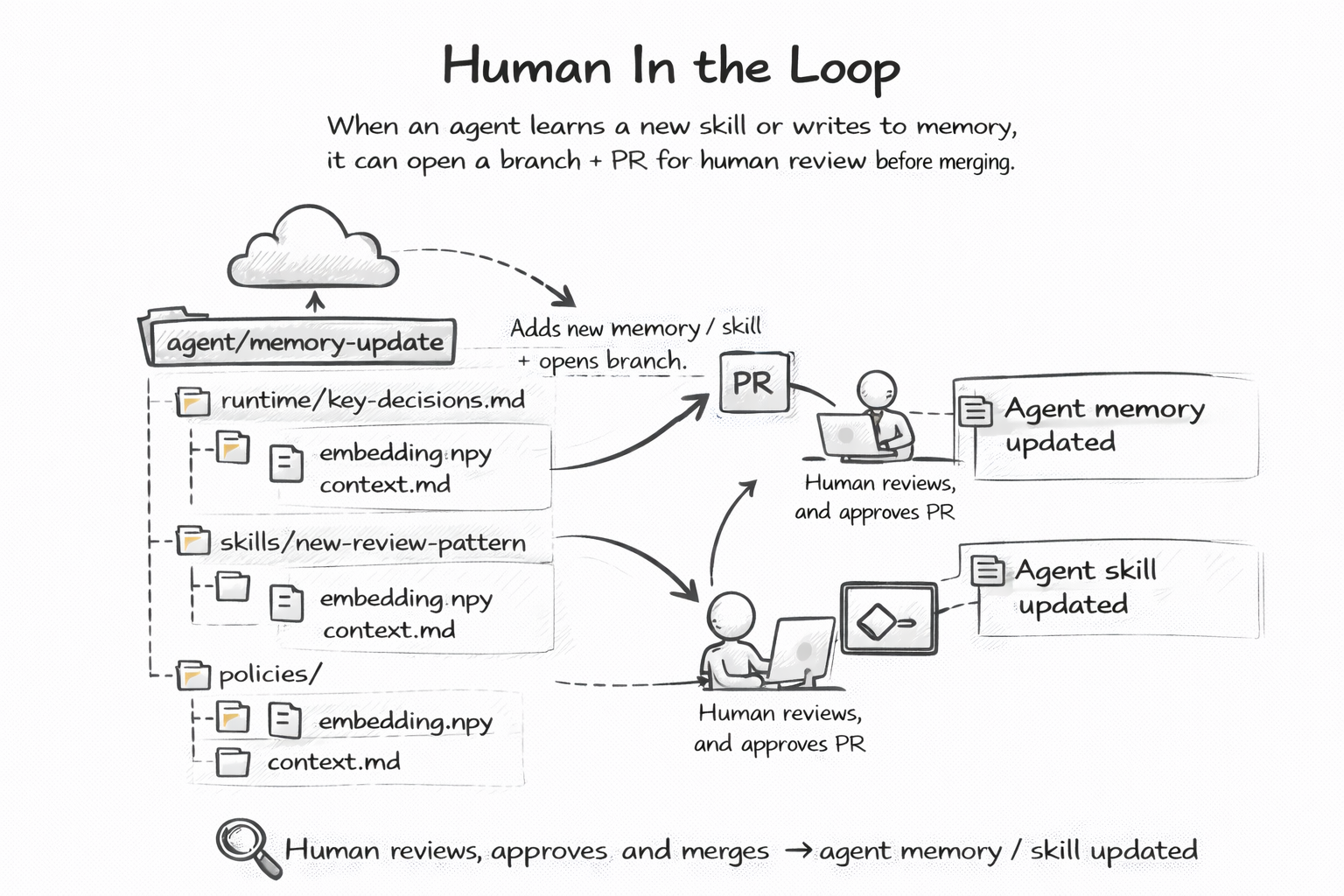
The hardest problem in AI is trust. You want agents to act autonomously, but you need a way to say "wait, let me check that first."
Most frameworks solve this with custom approval workflows — buttons in dashboards, webhook callbacks, queue systems. Git solved it in 2008 with pull requests.
When a git-native agent learns something new, it does not silently update itself. It opens a branch. It commits the change. It opens a PR. A human reviews the diff, leaves comments, and merges — or rejects.
This is not a metaphor. This is literally what happens. The agent writes to its own memory file, pushes a branch, and runs gh pr create. Your team reviews it in the same GitHub interface they already use for code. The same approval rules apply. The same CODEOWNERS file governs who can merge. The same branch protection policies enforce review requirements.
The beauty is that every agent decision becomes a reviewable artifact. Not a log line buried in a monitoring dashboard. A PR with a diff you can read, comment on, and audit months later.
You already have the infrastructure. You already have the muscle memory. You just never thought of using it for AI agents.
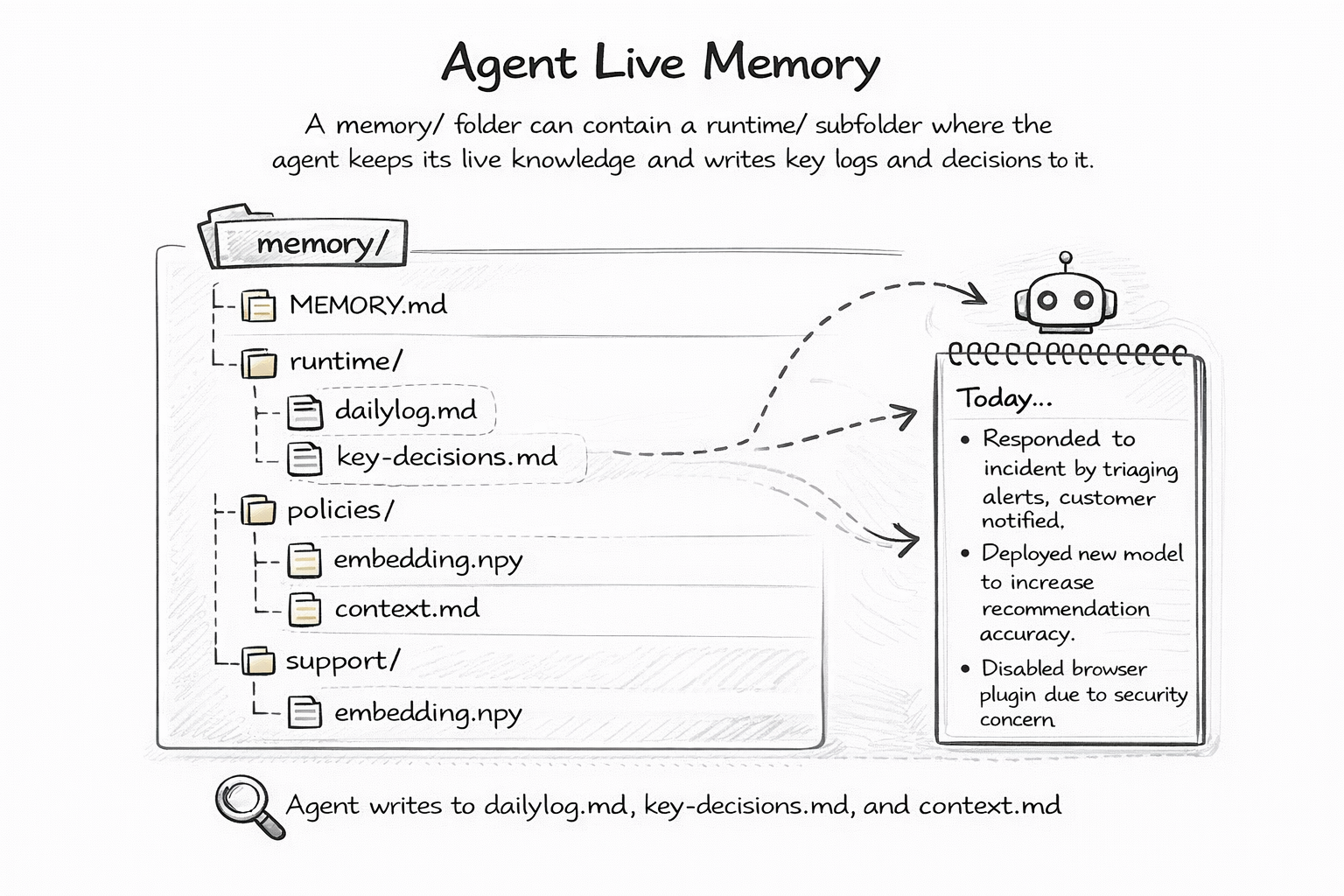
Every useful agent needs to remember things across sessions. What it learned yesterday. What decisions it made. What context it is operating in. Without memory, every conversation starts from zero.
The standard approach is a vector database. Embed the memory, store it in Pinecone or Weaviate or Chroma, retrieve it with similarity search. It works. But you cannot read it. You cannot diff it. You cannot revert it. You cannot review what your agent "knows" without writing queries against an opaque embedding store.
A git-native agent stores memory as plain files in a memory/ folder. A MEMORY.md file holds the current working state. A runtime/ subfolder holds daily logs, key decisions, and execution context. All markdown. All human-readable.
The implications are profound. You can git diff what your agent learned yesterday versus today. You can git revert a bad memory — say, a hallucinated fact the agent committed to its knowledge base. You can fork an agent's memory to create a variant that remembers different things. You can even have two humans independently edit an agent's memory and merge the changes.
Memory becomes a collaborative, version-controlled artifact. Not a black box you have to trust.
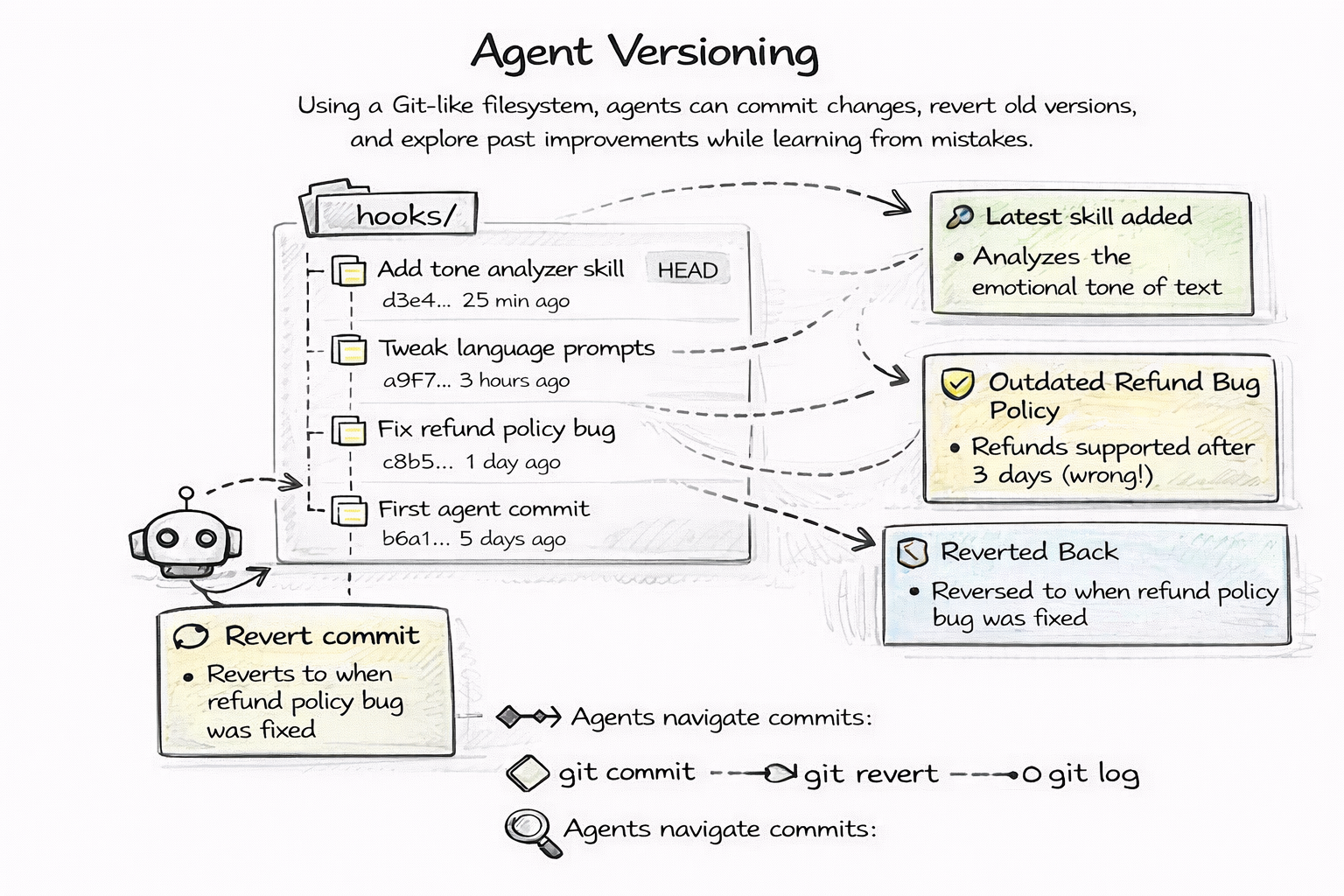
Every change to an agent — its personality, its rules, its skills, its knowledge — is a git commit. Full stop.
This means you get the entire version control toolkit for free. git log shows you the complete history of your agent's evolution. git diff shows you exactly what changed between any two versions. git bisect helps you find when a behavior regression was introduced. git revert undoes a bad change in seconds.
Think about what this replaces. Without git-native agents, rolling back a broken prompt means digging through a dashboard, finding a previous version in some proprietary UI, and hoping the platform kept a snapshot. With git, it is git checkout HEAD~1 -- SOUL.md. Done.
Your agent at any point in time is a specific commit hash. You can pin it. You can share it. You can reproduce it exactly. The agent you deployed last Friday at 3pm is not some ephemeral state — it is a5f3c2d and you can check it out right now.
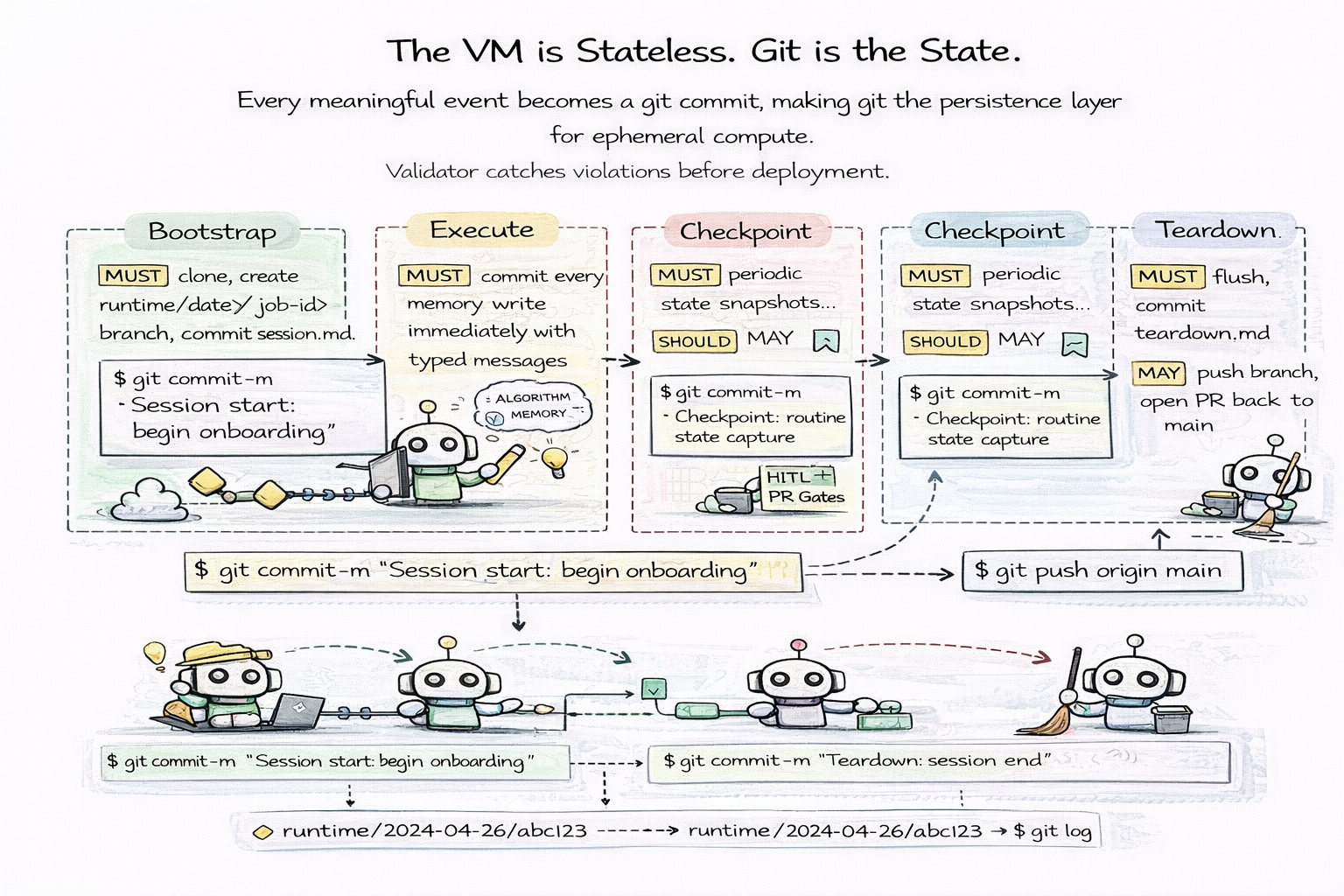
The VM is stateless. Git is the state.
This is the core principle of the runtime architecture. Instead of relying on persistent infrastructure — long-running servers, mounted volumes, database connections — agents run inside ephemeral compute environments where every meaningful event is recorded as a git commit. Git becomes the persistence layer, the audit log, and the recovery mechanism all at once.
The agent runtime follows a four-phase lifecycle. At bootstrap, the VM clones the repository and creates a runtime branch — runtime/<date>/<job-id> — committing a session file that marks the start of execution. During execute, every state change becomes a commit immediately. Memory updates, knowledge writes, decision logs, tool outputs — each one gets a typed commit message like memory: added customer escalation policy or decision: approved loan application #4521. This is not batch processing. Every mutation is committed the moment it happens.
At checkpoint, long-running agents periodically snapshot their current state. These commits serve as safe recovery points. For high-risk agents, checkpoints can optionally trigger human-in-the-loop PR gates — pausing execution until a human reviewer inspects and approves the changes before the agent continues. At teardown, the agent flushes remaining memory, writes a teardown log, commits the final state, and pushes the runtime branch.
The result is a complete, linear history of everything the agent did during its execution:
$ git log --oneline runtime/2024-04-26/abc123
f8a1b2c teardown: session end
d3e4f5a checkpoint: routine state capture
b7c8d9e memory: added customer escalation policy
a1b2c3d Session start: begin onboarding
This architecture provides three powerful guarantees. Deterministic replay — the entire execution can be reproduced from commit history. If something went wrong, you do not grep through log files. You replay the commits. Failure recovery — if the VM dies mid-execution, the last commit is always a safe recovery point. Spin up a new VM, checkout the runtime branch, and resume from the last checkpoint. No data loss. No corruption. Compliance by default — runtime branches are immutable audit logs. Every action the agent took, every decision it made, every piece of memory it wrote — all captured in tamper-evident git history.
The most profound implication is that the compute layer becomes truly disposable. VMs can crash, scale down, be replaced — it does not matter. The state is not in the VM. The state is in git. The agent's execution history outlives any infrastructure it ran on.
Instead of persisting state in databases or VM disks, agents persist their entire execution history directly into git. Git becomes the memory, the audit system, and the recovery mechanism for ephemeral AI compute.
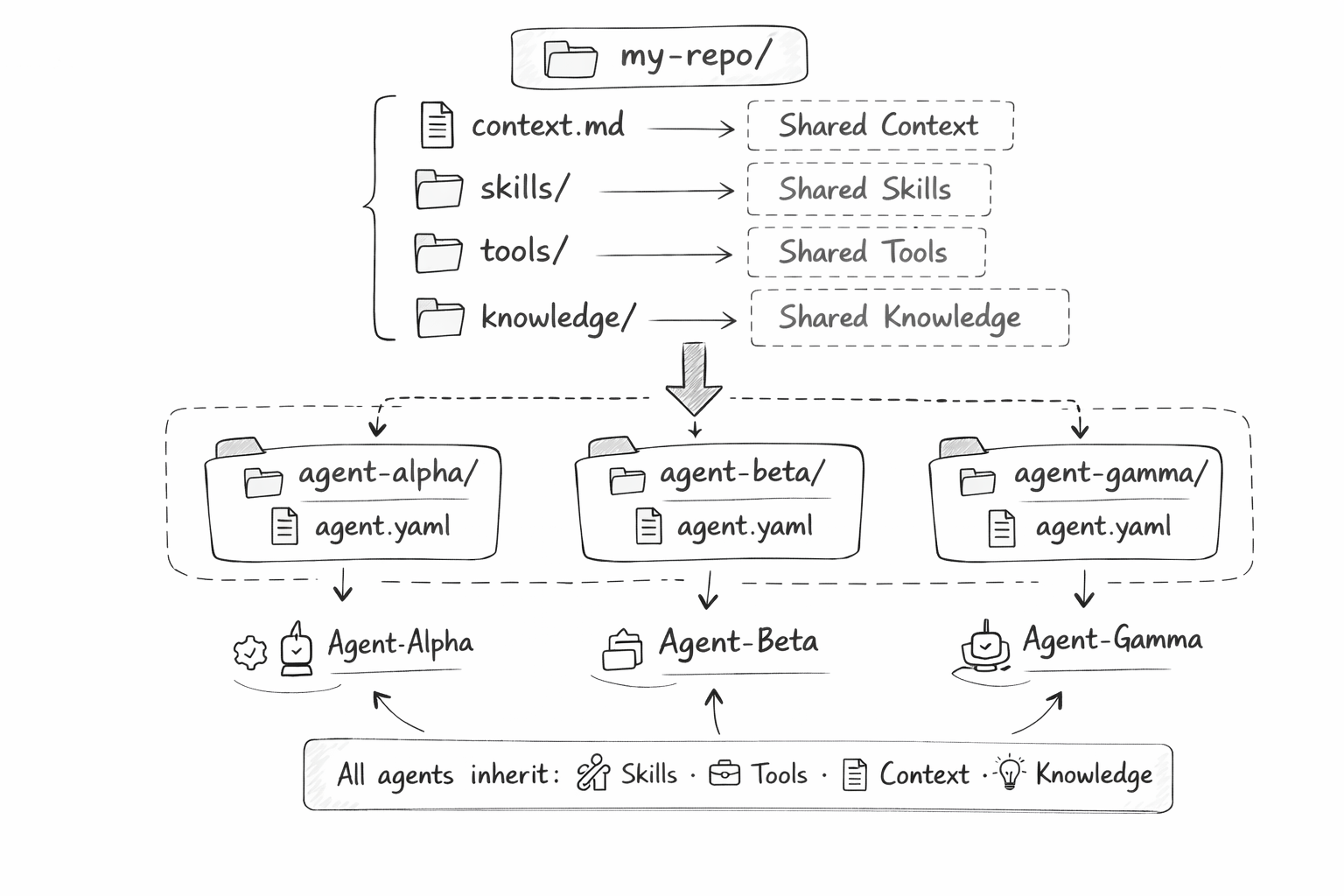
Organizations do not have one agent. They have dozens. A code review agent, a customer support agent, a data analysis agent, a compliance agent. Each one specialized, but all sharing the same organizational knowledge.
In most frameworks, you copy-paste shared context into each agent's configuration. When the company policy changes, you update twelve config files and hope you did not miss one.
In a git-native monorepo, shared context lives at the root. A context.md file with organizational knowledge. A skills/ folder with reusable capabilities. A knowledge/ directory with reference documents. Every agent in the agents/ subdirectory inherits them automatically.
When the company policy changes, you update one file. Every agent sees the change on the next run. No sync issues. No copy-paste drift. No "wait, the compliance agent has the old policy" moments at 2am.
This is the same monorepo pattern that Google, Meta, and Microsoft use for code. It works just as well for agents.
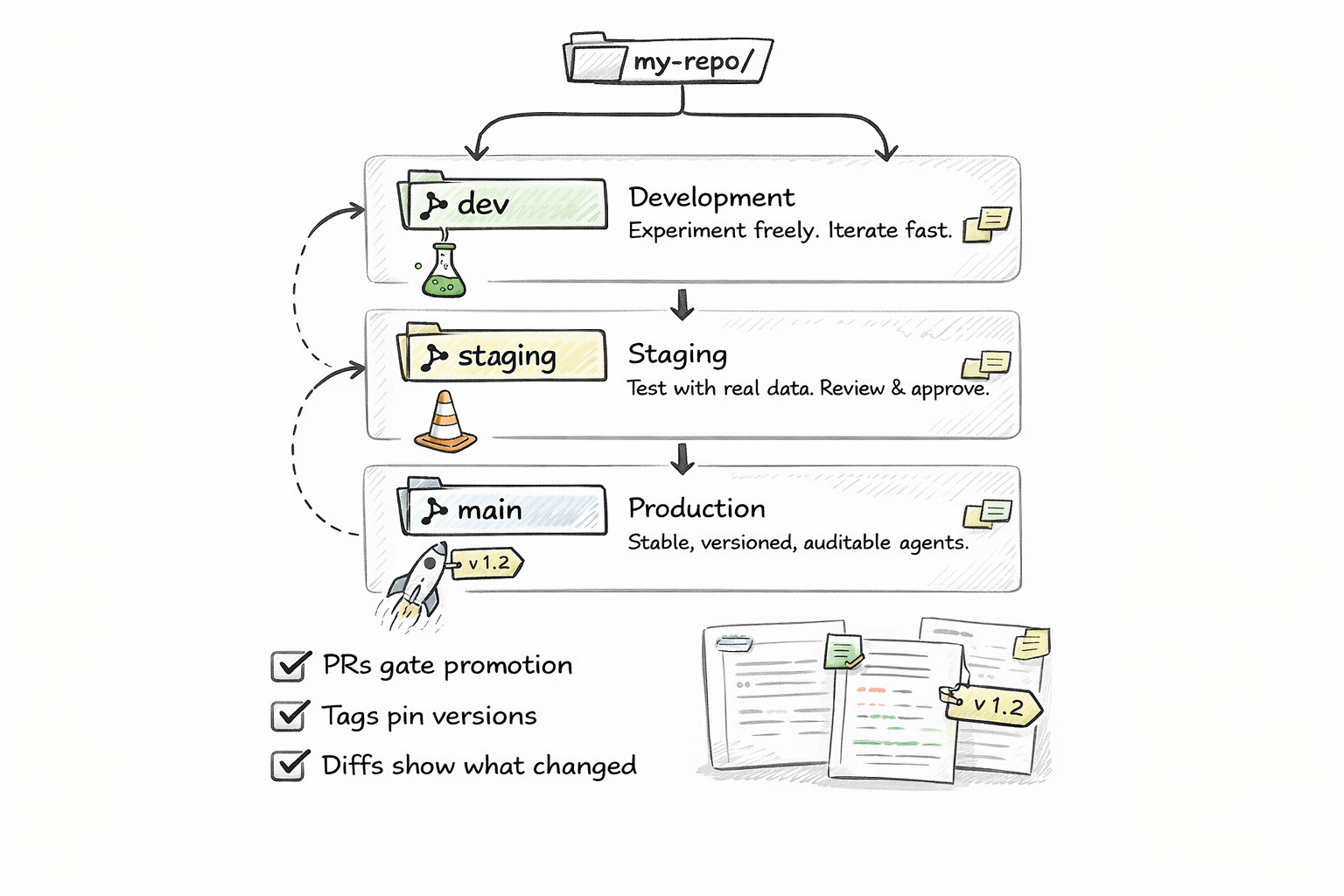
Software has a well-understood deployment model: feature branches for development, a staging branch for QA, a main branch for production. Merge to promote, revert to roll back.
Git-native agents inherit this model exactly. Your main branch is the production agent. Your staging branch is the QA version. Your feature branches are experiments.
Want to test a new personality for your customer support agent? Branch. Edit SOUL.md. Run it against test cases. If it works, merge to staging. If staging looks good, merge to main. If production breaks, git revert and you are back in sixty seconds.
No deployment pipelines to build. No environment configuration to manage. No "how do I promote this agent from dev to prod" conversations. Just git merge.
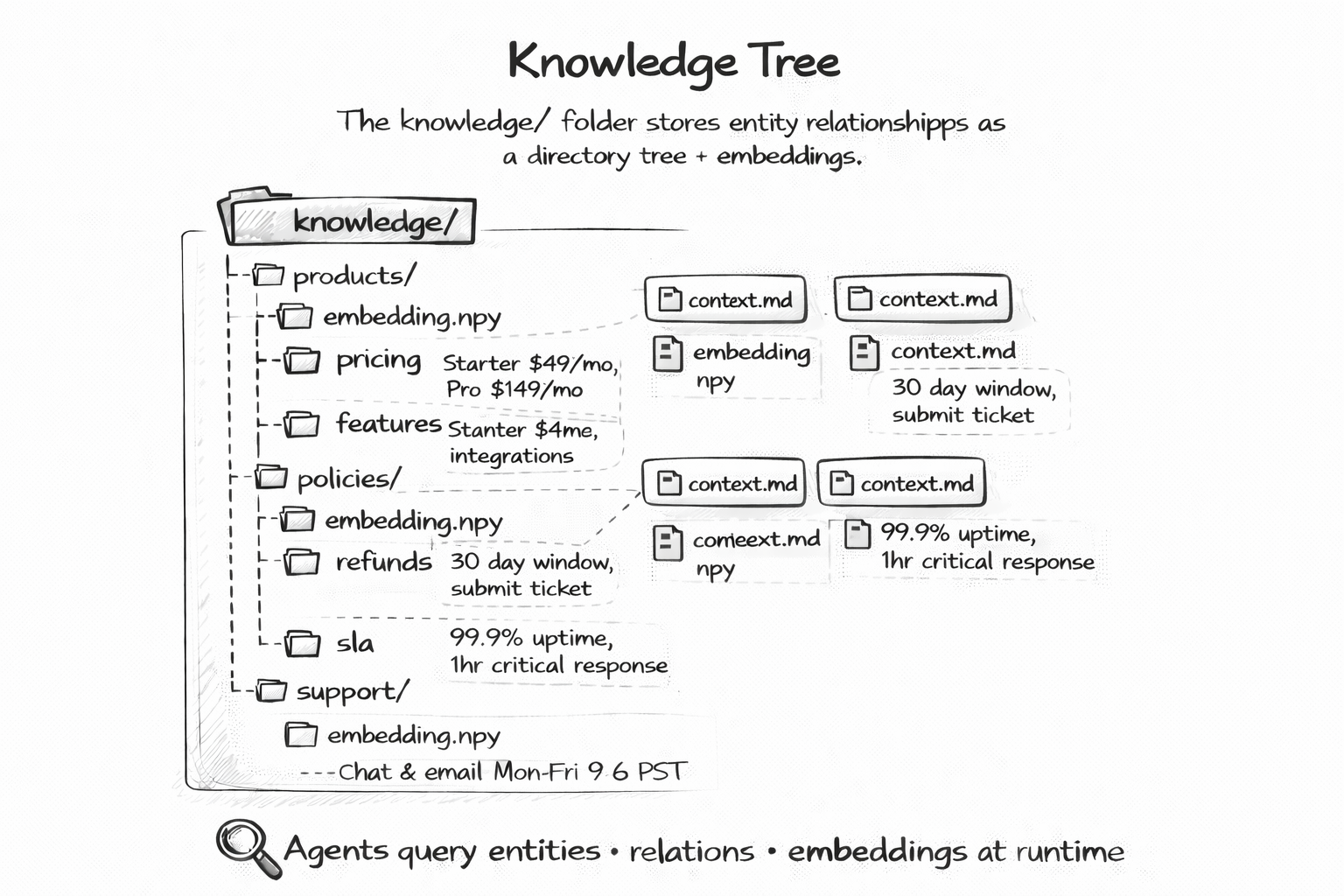
Agents need domain knowledge. Product details, pricing, policies, regulations, entity relationships. The standard approach is to embed everything into a vector store and hope that similarity search retrieves the right chunks at the right time.
A knowledge tree is different. It is a hierarchical folder structure in the knowledge/ directory. Products in one folder, policies in another, regulations in a third. Each document is plain markdown. The hierarchy itself encodes relationships — knowledge/products/pricing.md is obviously about product pricing.
This structure has three advantages over vector stores. First, it is human-readable. You can browse the knowledge tree and see exactly what your agent knows. Second, it is diffable. When someone updates the pricing document, git diff shows you exactly what changed. Third, it is reviewable. Knowledge updates go through the same PR review process as code changes.
You do not lose semantic search. You can still embed these documents if you want. But the source of truth is the tree — readable, versioned, and auditable.
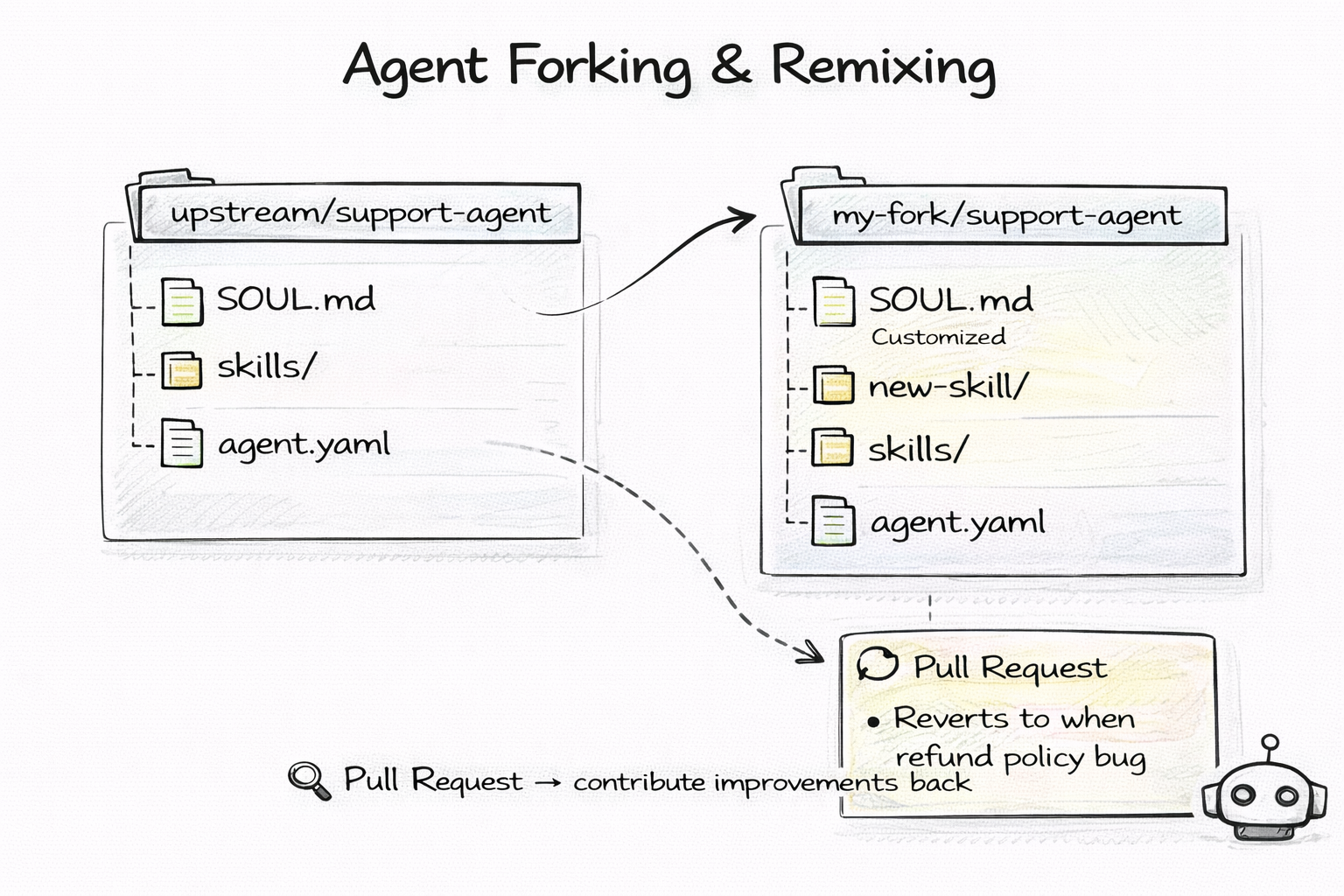
Open source changed software forever. The ability to fork a project, modify it, and contribute back created an ecosystem of shared innovation that no proprietary model could match.
Git-native agents bring this to AI. An agent is a repo. To customize someone else's agent, you fork it. Edit SOUL.md to change its personality. Add new skills to skills/. Remove rules from RULES.md. Push your changes and you have a custom variant.
The upstream agent improves? git pull to merge their updates into your fork. Your customization is better than the original? Open a PR upstream.
This changes the economics of agent development. Instead of every organization building agents from scratch, you start from a community-maintained base and customize. A "code review agent" template gets forked a thousand times, and the best improvements flow back upstream.
Agents stop being proprietary assets locked inside platforms. They become open-source projects that anyone can inspect, modify, and share.
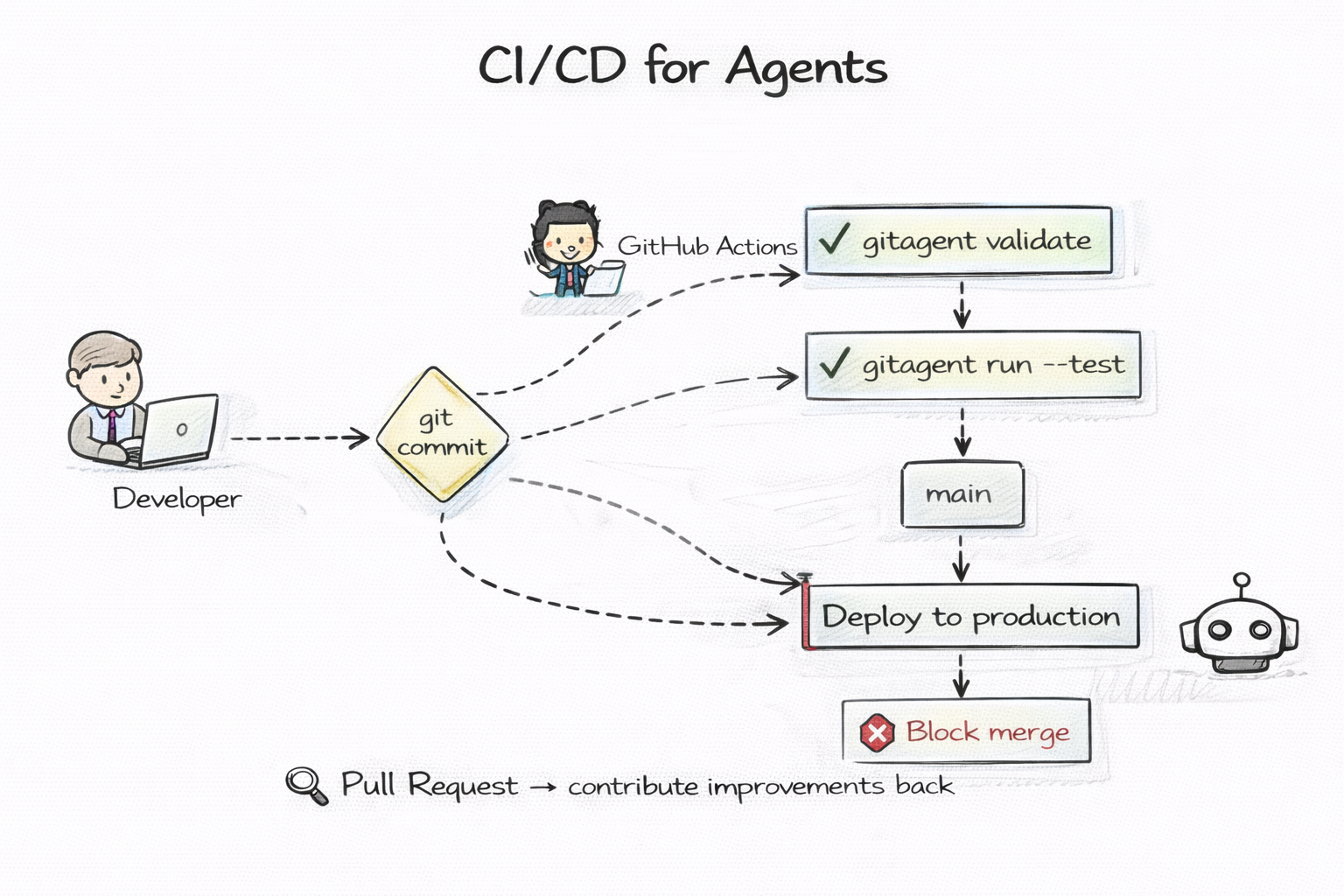
Software quality is enforced by CI/CD. Every push triggers automated tests. Every PR gets linted. Every merge to main runs the full test suite. Bad code does not ship because the pipeline catches it first.
Git-native agents plug into the same pipeline. A GitHub Actions workflow runs gitagent validate on every push. It checks that the agent.yaml manifest is valid, that SOUL.md exists, that skills reference real files, that the knowledge tree is well-formed.
But you can go further. Write test cases in the examples/ folder — sample inputs and expected outputs. Run them in CI against the actual agent. If the agent's responses drift from expected behavior after a prompt change, the pipeline fails and the merge is blocked.
Agent quality gates work exactly like code quality gates. Same tools. Same dashboards. Same Slack notifications when the build breaks. No new infrastructure. No agent-specific testing platform. Just your existing CI pipeline doing what it already does — ensuring nothing ships that should not ship.
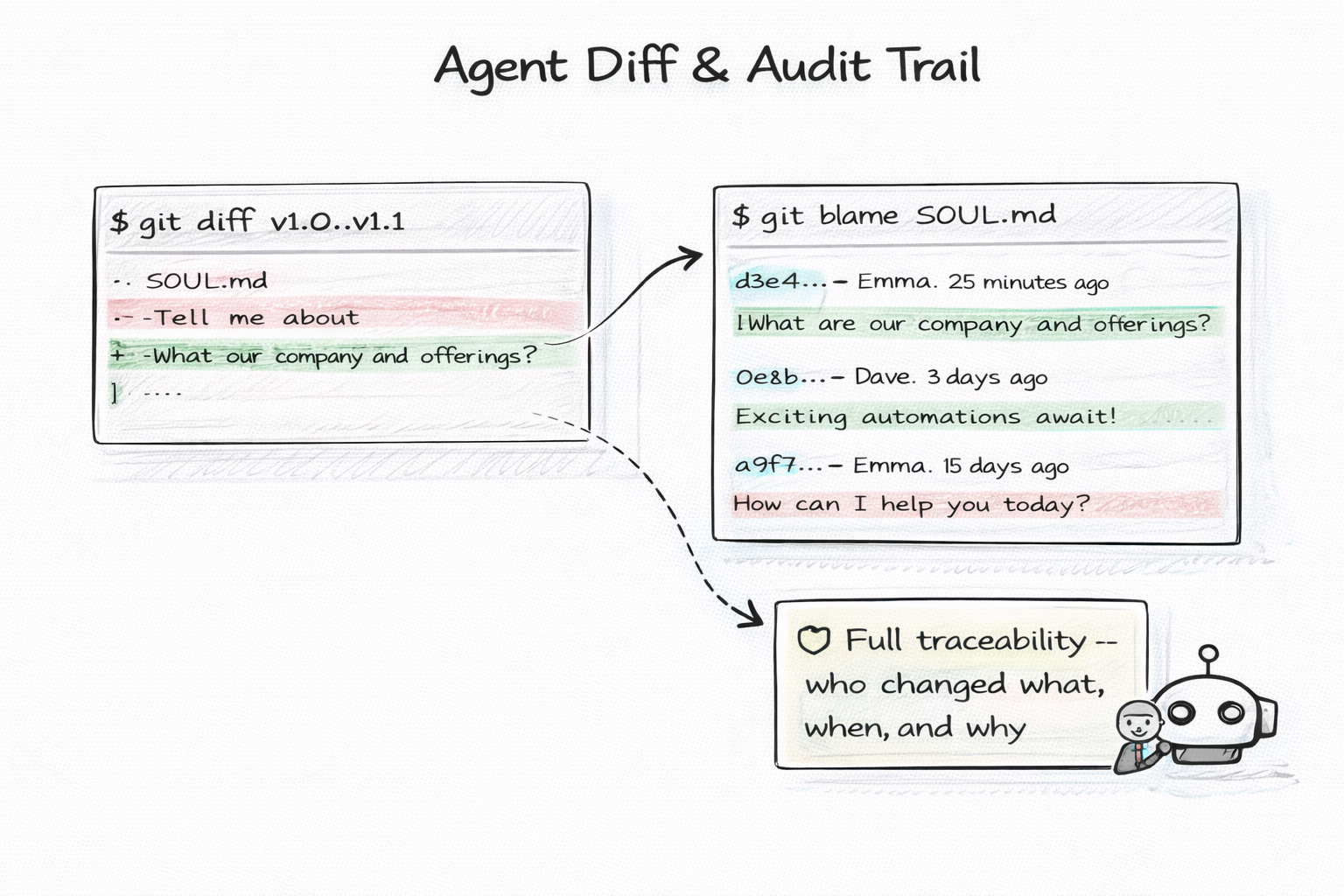
In regulated industries — finance, healthcare, legal — every change to an AI system must be traceable. Who changed what, when, and why. This is not optional. It is a regulatory requirement.
Most agent platforms treat this as a feature to be built. Audit logging. Change tracking. Compliance dashboards. Months of engineering.
Git gives you this for free. Every change is a commit with a timestamp, an author, and a message explaining why. git blame traces every line in every file to the person who wrote it. git log shows the complete history. git diff shows exactly what changed between any two points in time.
This is not a "good enough" audit trail. This is a cryptographically signed, tamper-evident, distributed audit trail that has been battle-tested by millions of software teams for two decades. No compliance officer will question it. No auditor will ask for more.
The audit trail is not a feature you add to your agent. It is an inherent property of storing your agent in git.
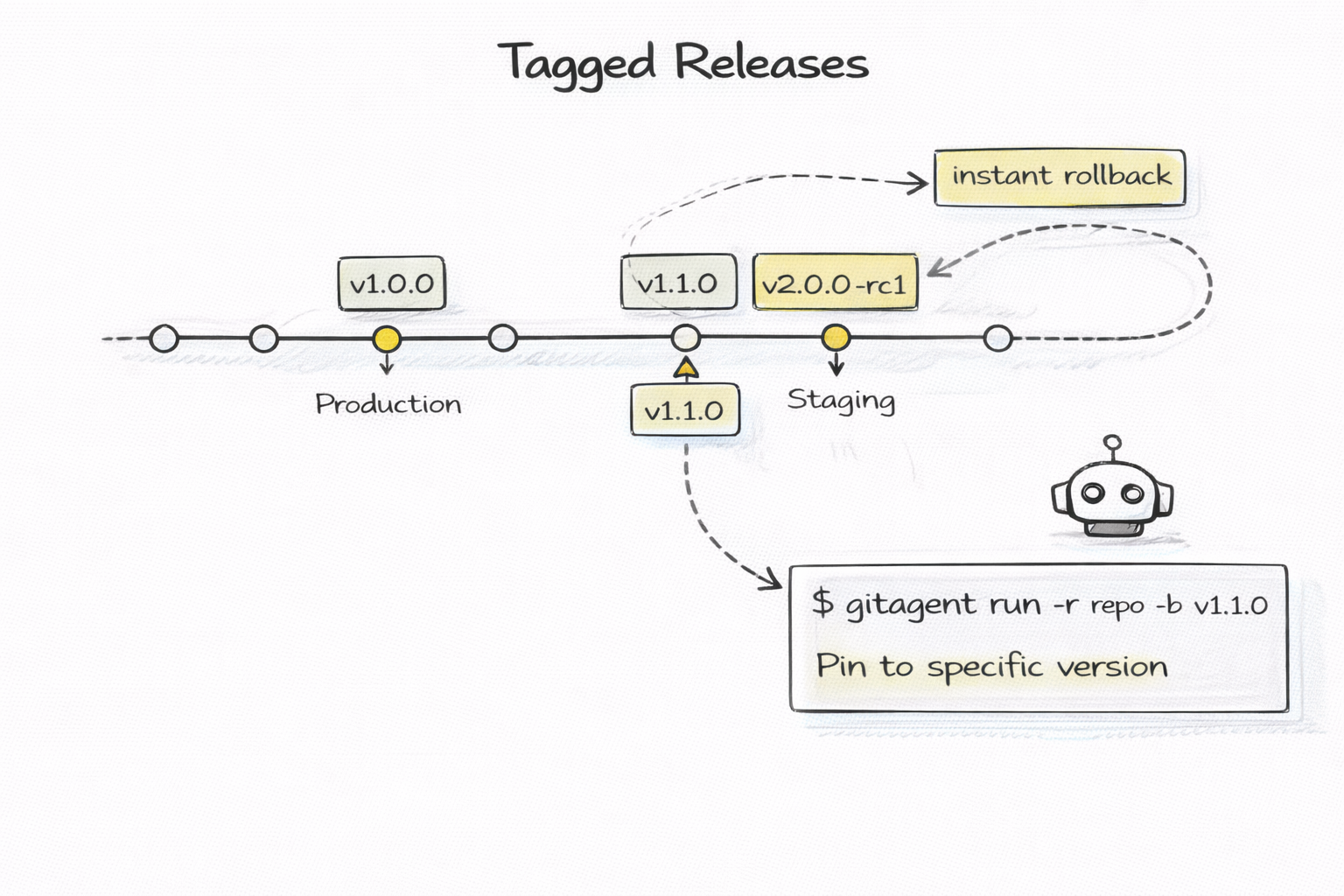
Software uses semantic versioning. v1.0.0 is the first stable release. v1.1.0 adds a feature. v2.0.0 is a breaking change. Tags mark specific commits as releases. Production runs a pinned tag. Rollback means pointing to the previous tag.
Git-native agents use the exact same model. Tag your agent with v1.1.0 when you add a new skill. Pin production to that tag. Run v1.2.0-beta on staging to canary a new behavior. If something breaks, point production back to v1.1.0 in seconds.
This also enables dependency management. If agent A depends on agent B, it can pin to a specific version — "use fact-checker v2.1.0" — and not break when the upstream agent changes. Stability through versioning, not hope.
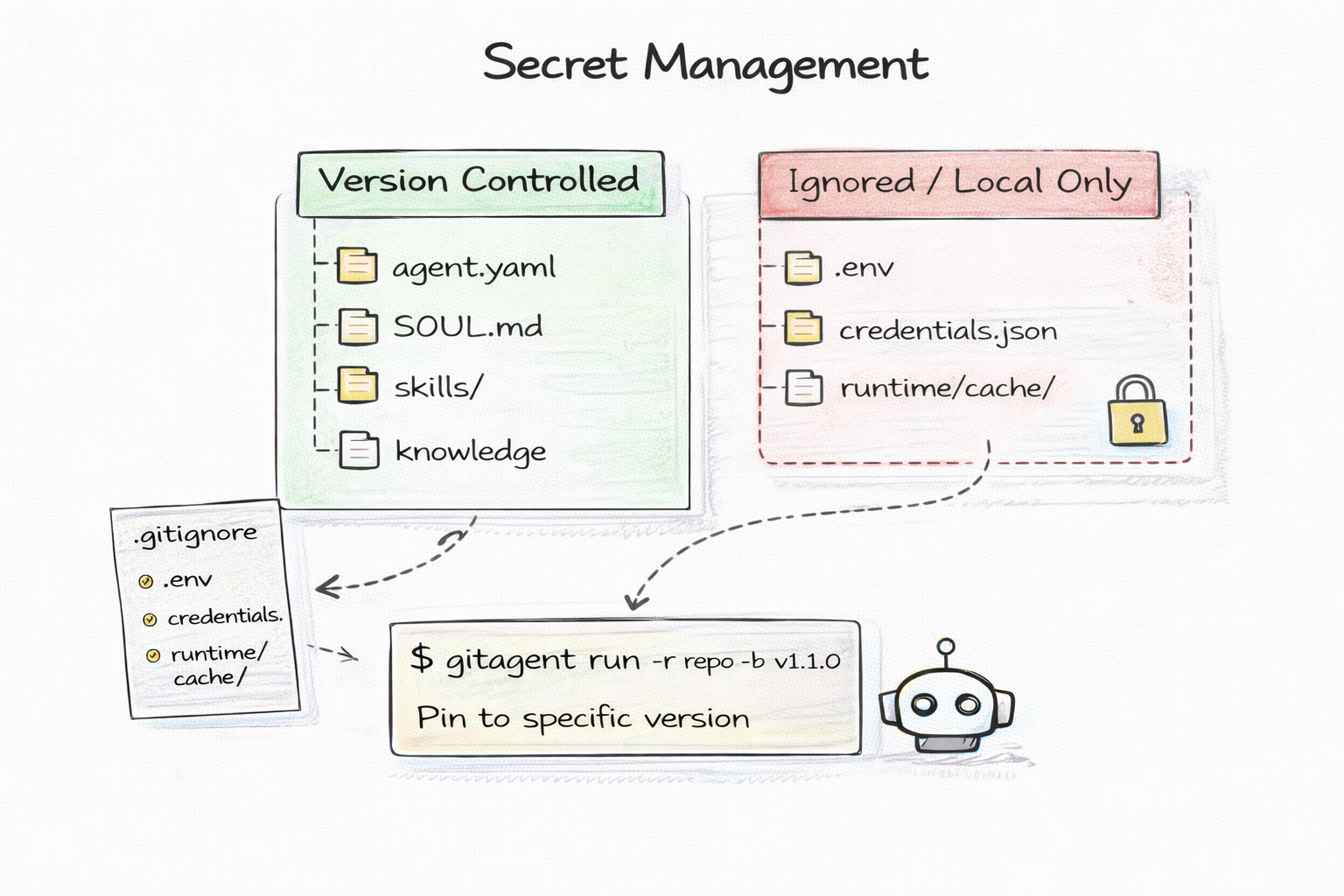
Agents need API keys. OpenAI keys, database credentials, third-party service tokens. These secrets must never be committed to version control. This is security 101.
Every web application solves this with .gitignore and .env files. The application code is committed. The secrets live in a local .env file that is gitignored. CI/CD injects secrets from a vault at deploy time.
Git-native agents use the same pattern. The agent definition — SOUL.md, RULES.md, skills/, knowledge/ — is fully shareable. Anyone can clone the repo and see the complete agent. But the .env file with API keys stays local. The .gitagent/ runtime directory stays local. Secrets never touch version control.
This means you can open-source an agent without exposing credentials. You can fork someone else's agent and plug in your own keys. The agent is portable. The secrets are not.
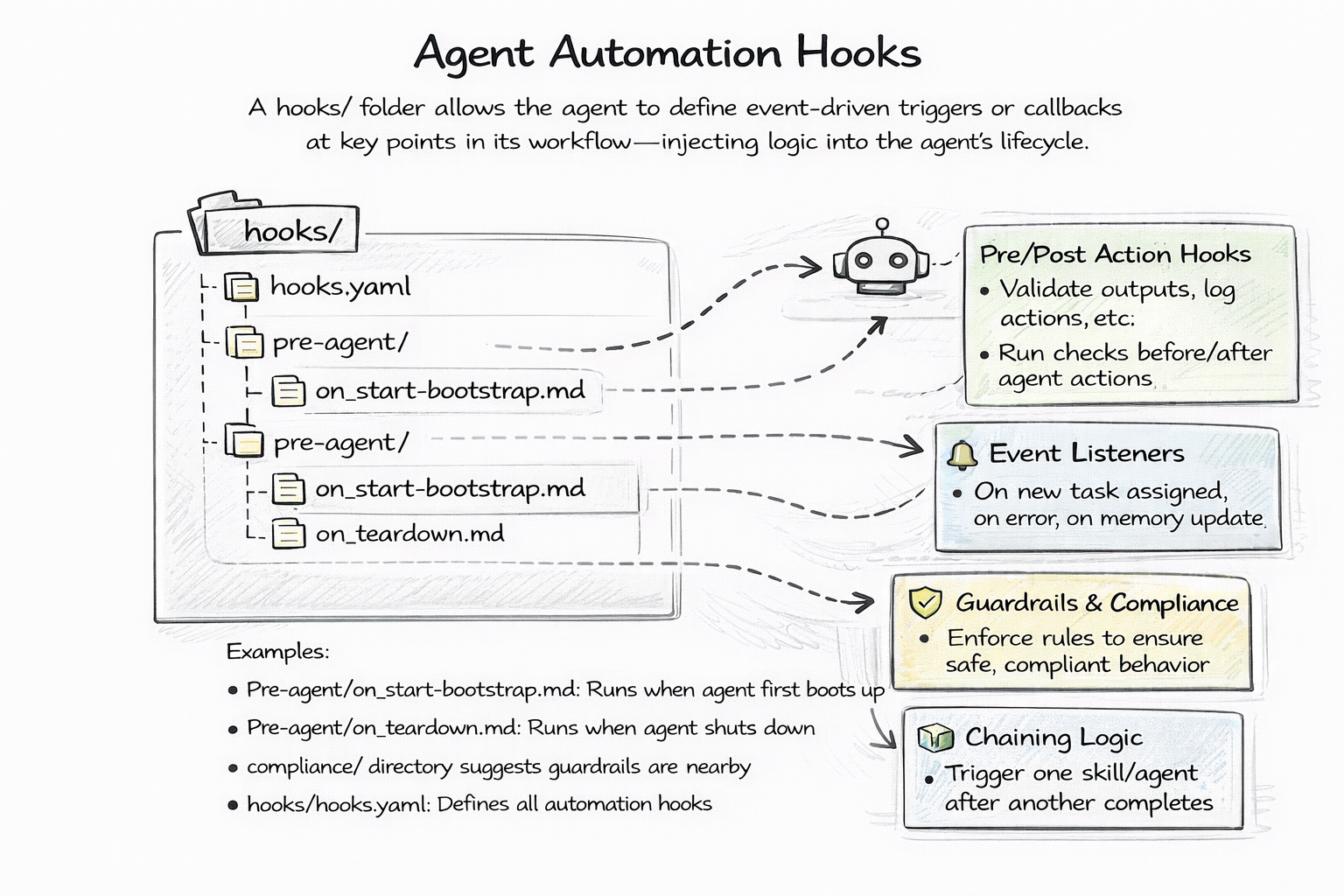
Agents need startup logic. Load a knowledge base before the first task. Check for updated context. Warm up connections. And they need shutdown logic. Persist state. Clean up resources. Log a summary.
Most frameworks handle this with callbacks, decorators, or event systems. Register a function to run on_startup. Subscribe to a shutdown event. Import a lifecycle module.
Git-native agents use hooks — markdown files in the hooks/ directory. A bootstrap.md file contains instructions the agent executes at startup. A teardown.md file contains shutdown instructions. Pre-task and post-task hooks control behavior around each execution.
The elegance is that hooks are the same format as everything else — markdown files in a folder. No code. No registration. No imports. You can read them, version them, review them in PRs. A new team member can open the hooks/ folder and immediately understand what happens at each lifecycle stage without reading any source code.
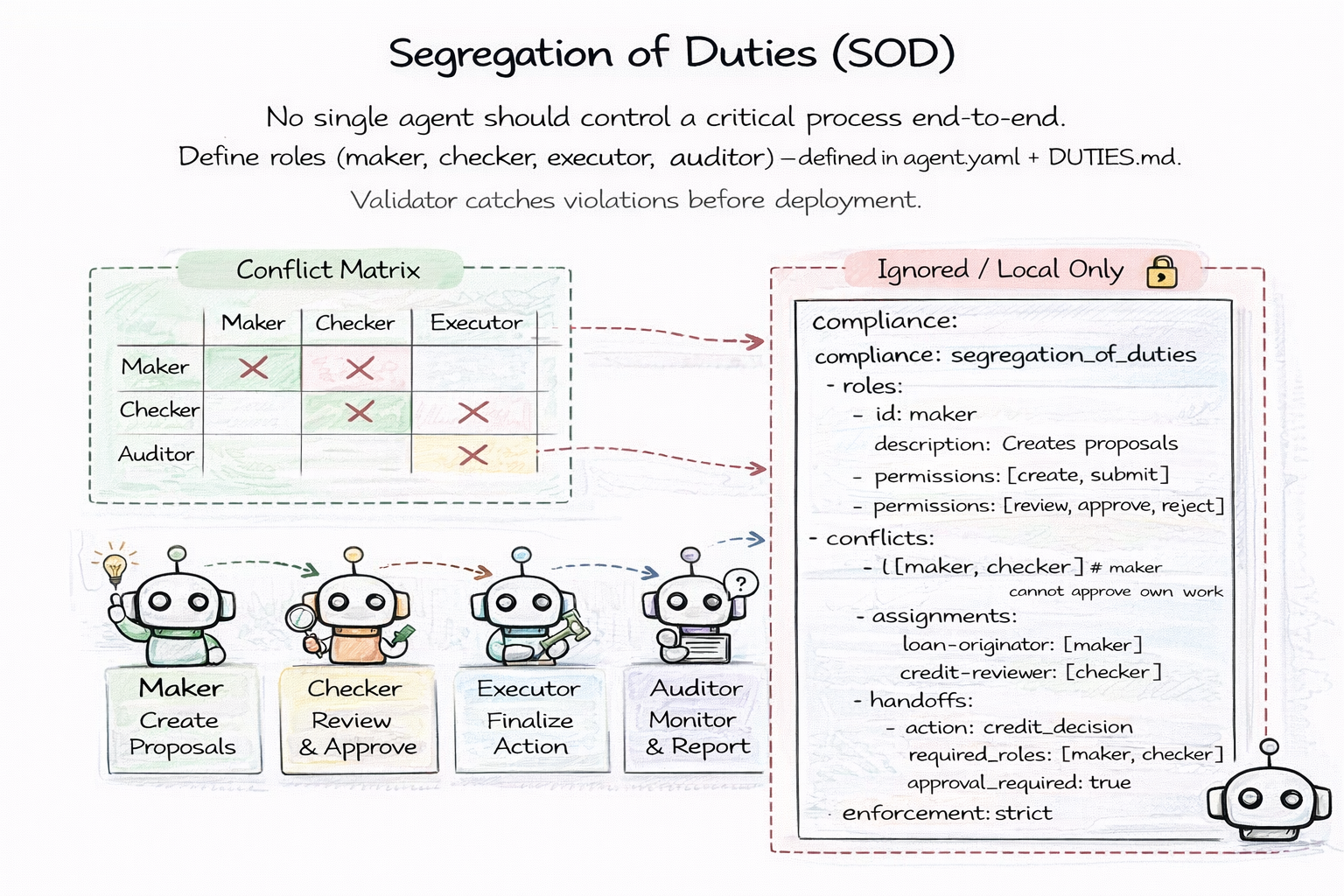
In any critical process — loan approvals, trade execution, medical decisions — no single person should control the entire pipeline. This is Segregation of Duties, and it is a regulatory requirement in finance (FINRA Rule 3110), healthcare, and anywhere the stakes are high enough that mistakes cannot be undone.
Most AI agent frameworks do not even acknowledge this problem. They assume one agent handles one task. But in production, agents form pipelines. An agent that originates a loan application should not be the same agent that approves it. An agent that generates a trade order should not be the same agent that executes and audits it.
GitAgent makes SOD a first-class, file-level concept. A DUTIES.md file declares the agent's role in the pipeline — maker, checker, executor, or auditor. The agent.yaml manifest defines a conflict matrix: maker and checker cannot coexist in the same agent. Handoff rules specify which actions require multi-role sign-off before proceeding.
The conflict matrix is not documentation. It is enforced. Run gitagent validate --compliance and it catches violations before deployment. An agent assigned the maker role that also has checker permissions? Blocked. A pipeline that skips the required checker step? Flagged. A handoff without the required approval? Rejected.
Because the SOD policy lives in version-controlled files, you get the same benefits as every other pattern. git diff shows when the policy changed. git blame shows who changed it. PRs ensure policy updates are reviewed. The audit trail is automatic. Compliance officers can read DUTIES.md directly — no dashboard, no query language, no specialized tooling. Just a markdown file that says exactly which roles this agent holds and which roles it conflicts with.
This turns a regulatory burden into a version-controlled, testable, CI-enforced artifact. The policy is a file. The enforcement is a command. The proof is git history.
These fourteen patterns share a single insight: git already solved agent management. We just did not realize it yet.
Version control, collaboration, deployment, auditing, secrets, lifecycle management — software engineering spent twenty years perfecting these workflows. Git-native agents inherit all of them by storing agent definitions as plain files in a git repository.
No new tools. No new platforms. No new paradigms. Just files, folders, and git.
That is what GitAgent formalizes — an open specification for git-native AI agents that works with every framework.
Try it:
npm install -g @shreyaskapale/gitagent
Read the spec, fork the repo, build an agent.