Something interesting happened while nobody was paying attention.
Claude Code shipped CLAUDE.md. Cursor shipped .cursorrules. GitHub Copilot started reading AGENTS.md. CrewAI shipped crew.yaml. OpenClaw shipped workspace directories. LangChain started loading tools from folders. Lyzr defined agents as API payloads backed by config files.
No coordination. No shared spec. No committee. And yet they all arrived at the same answer:
An AI agent is a folder.
Look at what happened independently across the ecosystem:
Claude Code — defines agents in CLAUDE.md, a markdown file at the repo root.
Cursor — defines agents in .cursorrules, a markdown file at the repo root.
GitHub Copilot — reads AGENTS.md, a markdown file at the repo root or in subdirectories.
OpenClaw — uses workspace config + AGENTS.md, YAML and markdown in the project directory.
CrewAI — uses crew.yaml + role definitions, YAML in the project directory.
LangChain — uses Python modules + config, Python and YAML in a package directory.
Lyzr — uses API payloads + environment config, JSON and YAML in the project directory.
OpenAI Agents SDK — uses Python classes + instructions, Python in a module directory.
Every single one of these frameworks defines agents as files in a directory. Not database rows. Not API objects. Not container images. Files.
The identity goes in a markdown file. The configuration goes in YAML or JSON. The skills go in subfolders. The knowledge goes in documents alongside the agent. The whole thing sits in a directory you can ls.
Look at AGENTS.md specifically. GitHub Copilot reads it. OpenClaw reads it. It is becoming the de facto convention for "tell the AI agent what to do" — a plain markdown file, sitting in your repo, checked into version control. No SDK. No API call. No dashboard. Just a file that says: here is who this agent is and what it should do. Multiple tools converged on the same filename independently because the idea is so obvious it barely needs explaining. A markdown file in a git repo is the most portable, most readable, most versionable way to define an agent.
This is not coincidence. This is convergent evolution.
There is a reason every framework landed here, and it is not because files are easy. It is because files give you git. And git gives you everything else for free.
The moment your agent definition lives in a file, it inherits the entire infrastructure that software engineering has built over the past two decades:
- Version control?
git log. - Collaboration? Pull requests.
- Code review?
git diff. - Deployment? Branches.
- Rollback?
git revert. - Audit trail?
git blame. - Distribution?
git clone.
No agent-specific tooling required. No new paradigm to learn. No vendor lock-in. Just git.
The filesystem is not the lowest common denominator. It is the highest common abstraction — the one surface that every tool, every CI system, every developer, and every operating system already understands.
This is the part most people miss. The filesystem convergence is not just about configuration files. It is about what happens when the agent's entire existence — its identity, its knowledge, its memory, its learned behavior — lives inside a git repository.
The repo stops being a place where you store an agent. The repo becomes the agent.
Think about what that means:
The agent learns — and you can see it. When an agent writes to memory/key-decisions.md after a session, that learning is a file diff. You can read it. You can review it. You can revert it. When the agent updates its knowledge/ tree with new facts it discovered, that knowledge delta is a commit. Not a hidden weight update in a neural network. Not a row in some vendor's database. A commit you can git show.
The agent evolves — and you control it. When you edit SOUL.md to sharpen the agent's personality, or add a new skill to skills/, or tighten a constraint in RULES.md — every change is a versioned, reversible, reviewable mutation. The agent you have today is a specific commit. The agent you had last Tuesday is git checkout HEAD~12. The agent your teammate forked for their use case is a branch.
The agent's history is its own documentation. Run git log on any agent repo and you see the full story of how that agent came to be. Who created it, what changed, when it broke, how it was fixed. The repository is not just the agent's source code — it is the agent's biography.
This is fundamentally different from every other approach to agent management. Platforms store agents as API objects you cannot inspect. Frameworks store agents as runtime state that evaporates when the process dies. Vector databases store agent knowledge as opaque embeddings you cannot read.
A git-native agent is none of those things. It is a directory of plain files in a repository. Readable. Diffable. Forkable. Mergeable. Alive in a way that API objects never are — because it participates in the same version control workflow as the rest of your software.
Clone a repo. Get an agent. That is the primitive. Everything else follows.
Once you accept that an agent is a folder in a git repo, fourteen powerful patterns emerge naturally. These are not features you have to build. They are consequences of the medium.
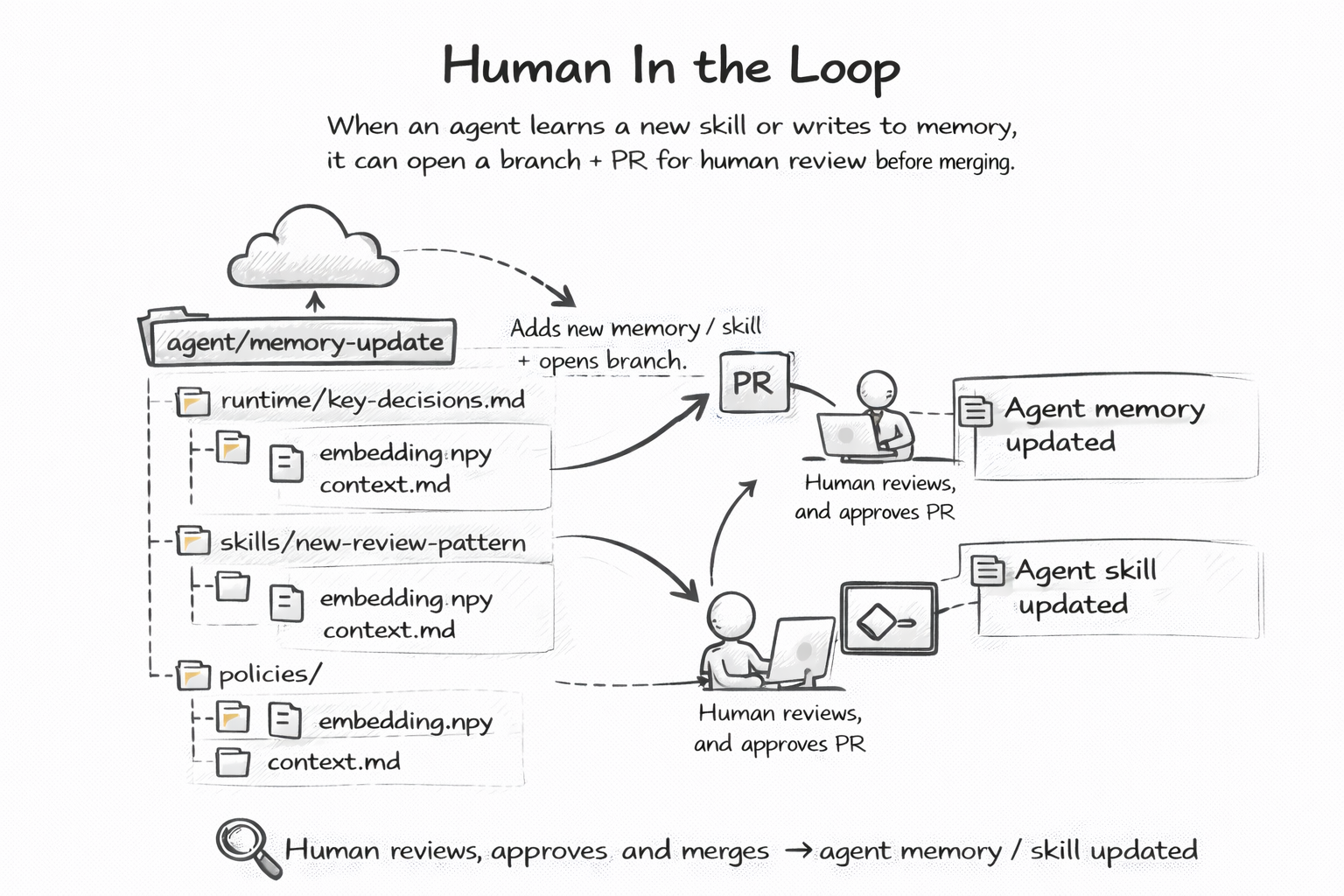
When an agent learns something new or wants to update its own behavior, it opens a branch and submits a PR. A human reviews, comments, and merges — or rejects. This is not a custom approval workflow bolted onto an agent framework. This is GitHub. The same review process your team already uses for code now governs your agent's evolution.
agent updates memory/key-decisions.md
→ git checkout -b agent/update-memory
→ git commit + push
→ gh pr create
→ human reviews and merges
Every agent change gets the same scrutiny as a code change. No new tools. No new dashboards. Just PRs.
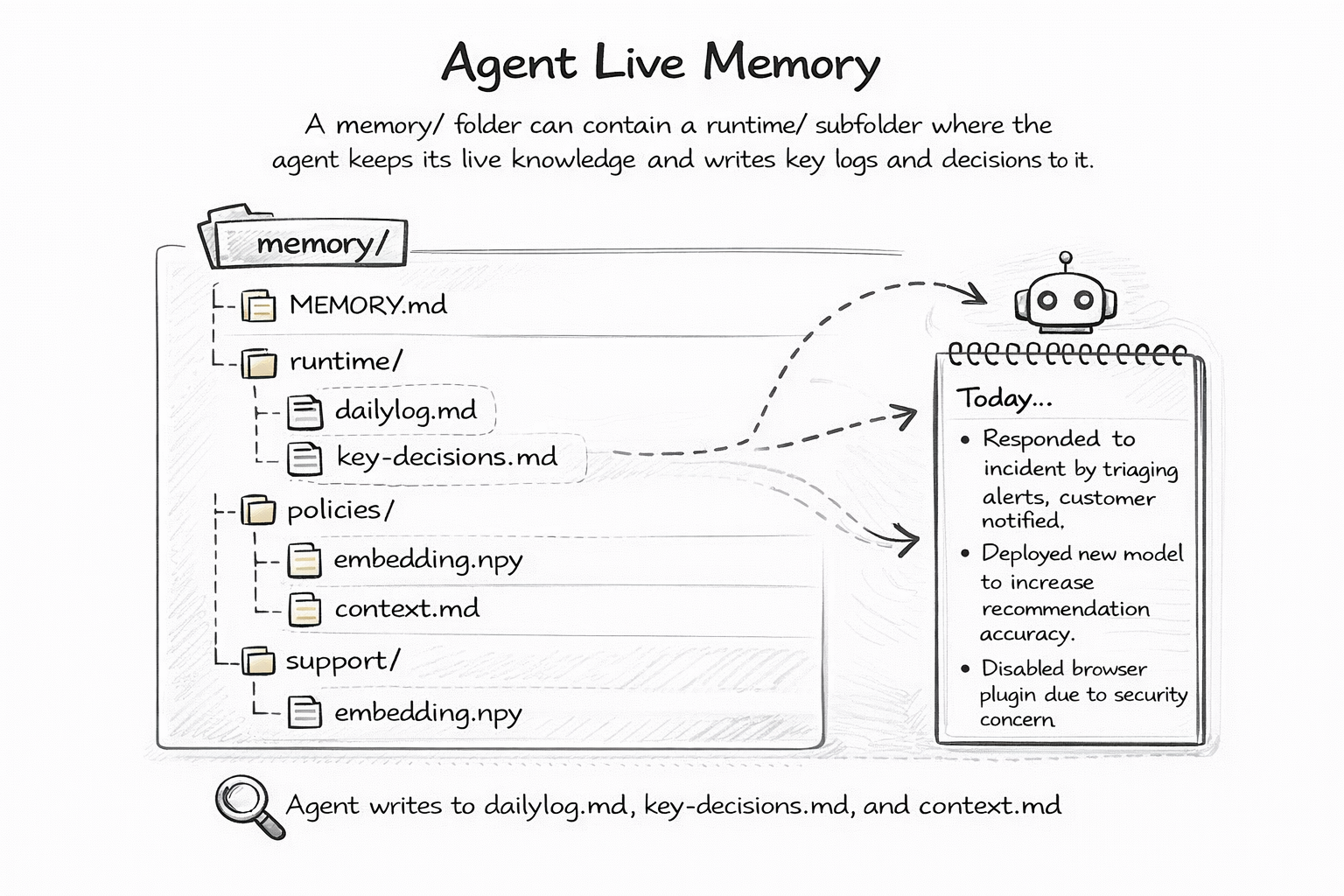
The memory/ folder is where agents persist knowledge across sessions. Daily logs, key decisions, learned context — all written as markdown files that humans can read, edit, and version-control.
memory/
├── MEMORY.md # Current working state
├── runtime/
│ ├── dailylog.md # What happened today
│ └── context.md # Execution context
Because memory lives in files, you can git diff what your agent learned yesterday versus today. You can revert a bad memory. You can even fork an agent's memory to create a variant with different knowledge. Try doing that with a vector database.
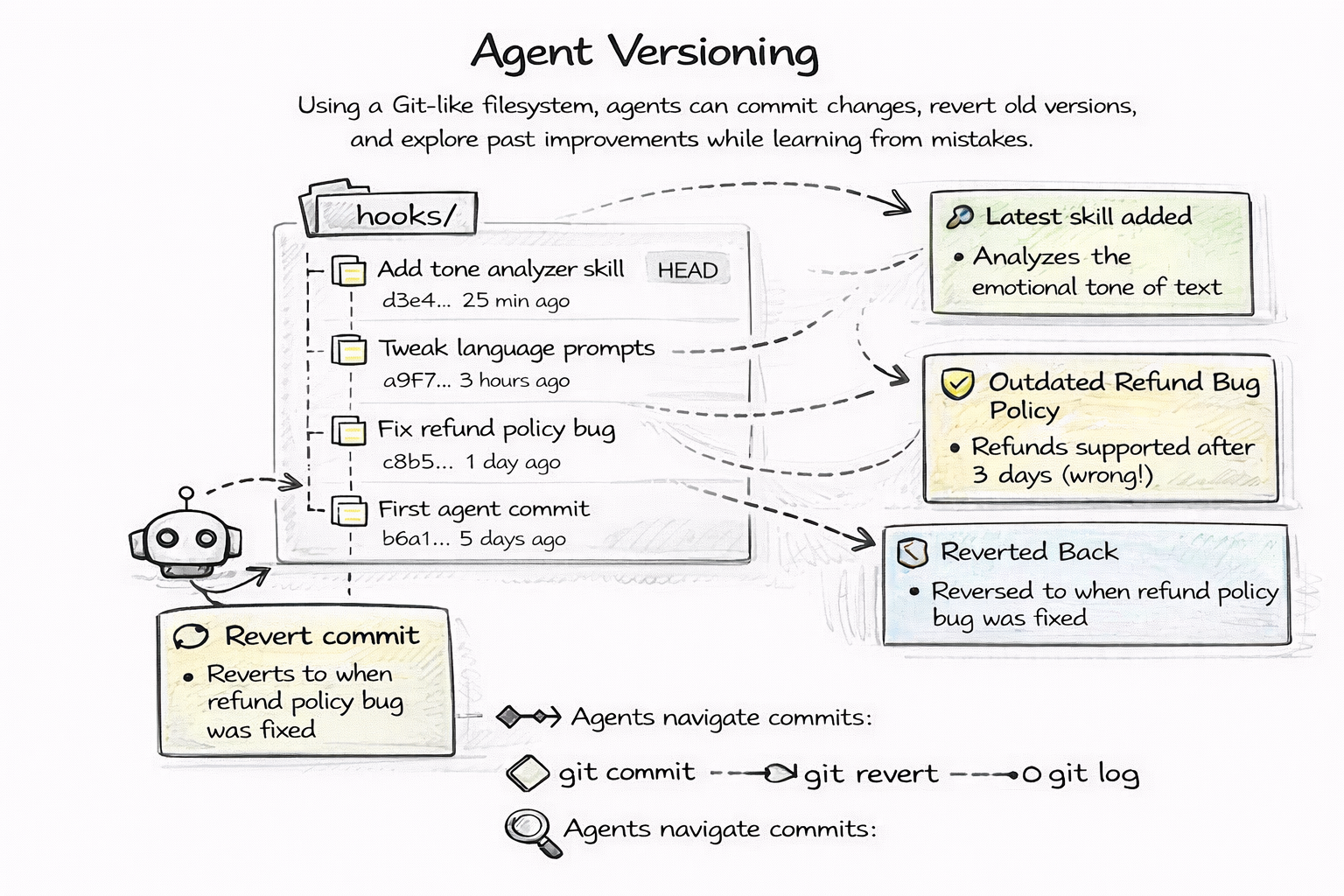
Every git commit is a version of your agent. Every change to its personality, its rules, its skills — all tracked with full history.
git log --oneline SOUL.md
# a1b2c3d Make agent more concise in responses
# d4e5f6a Add domain expertise in financial analysis
# 7g8h9i0 Initial agent identity
Roll back a broken prompt in seconds. Bisect to find when a behavior regression started. Compare any two versions of your agent side by side. This is not a feature. This is git.
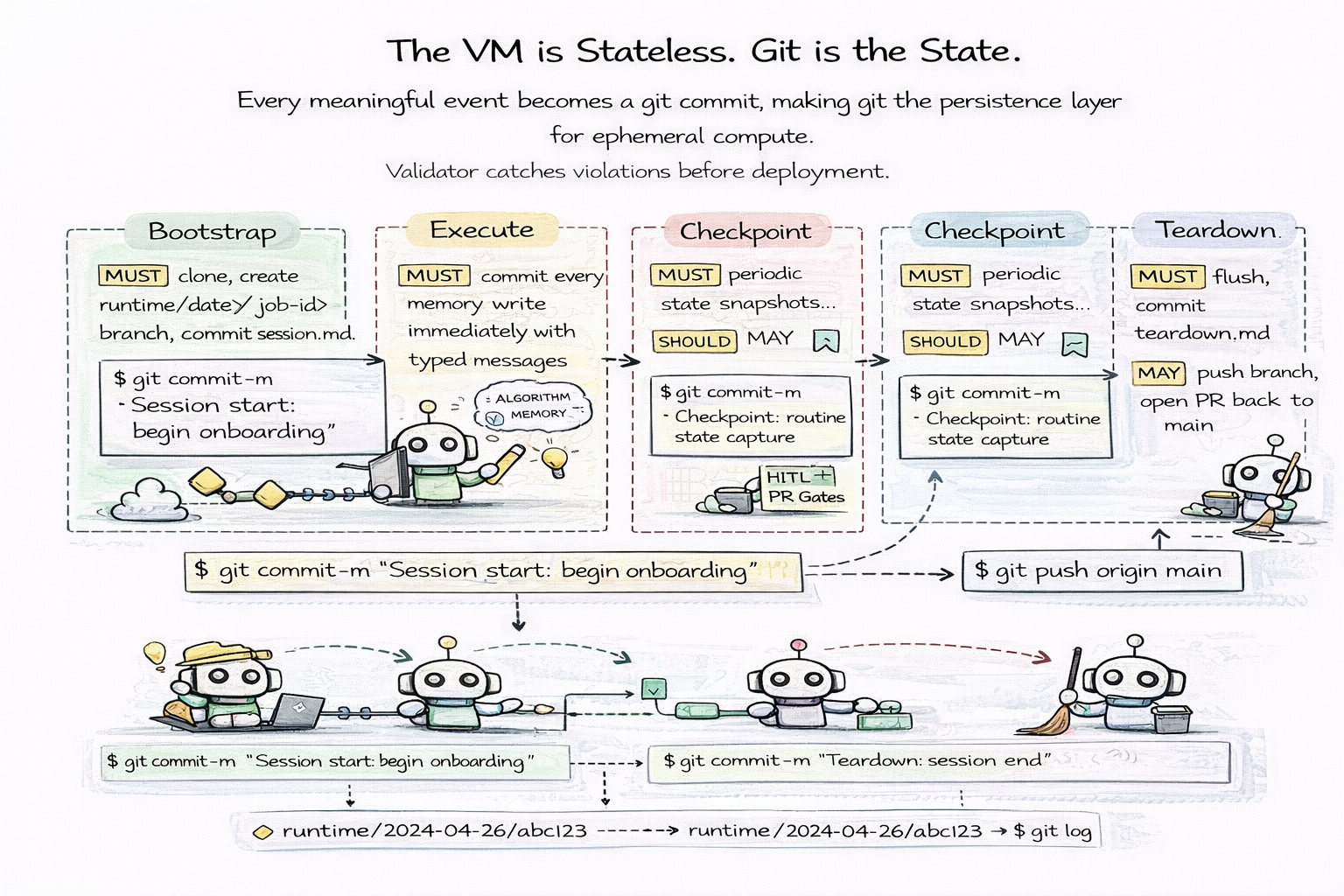
The VM is stateless. Git is the state.
Instead of relying on persistent infrastructure, agents run inside ephemeral compute environments where every meaningful event is recorded as a git commit. Git becomes the persistence layer, audit log, and recovery mechanism.
The agent runtime follows a four-phase lifecycle. At bootstrap, the VM clones the repository and creates a runtime branch — runtime/<date>/<job-id> — committing a session file that documents the start of execution. During execute, every state change — memory updates, knowledge writes, decision logs, tool outputs — immediately becomes a commit with a typed message like memory: added customer escalation policy. At checkpoint, long-running agents periodically snapshot their state, optionally triggering human-in-the-loop PR gates for review. At teardown, the agent flushes remaining memory, writes a teardown log, and pushes the runtime branch.
git commit -m "Session start: begin onboarding"
git commit -m "memory: added customer escalation policy"
git commit -m "checkpoint: routine state capture"
git commit -m "teardown: session end"
git push origin runtime/2024-04-26/abc123
This architecture provides deterministic replay — execution can be reproduced from commit history. Failure recovery is instant — the last commit is always a safe recovery point. And compliance is built in — runtime branches are immutable audit logs of every action the agent took.
Instead of persisting state in databases or VM disks, agents persist their entire execution history directly into git.
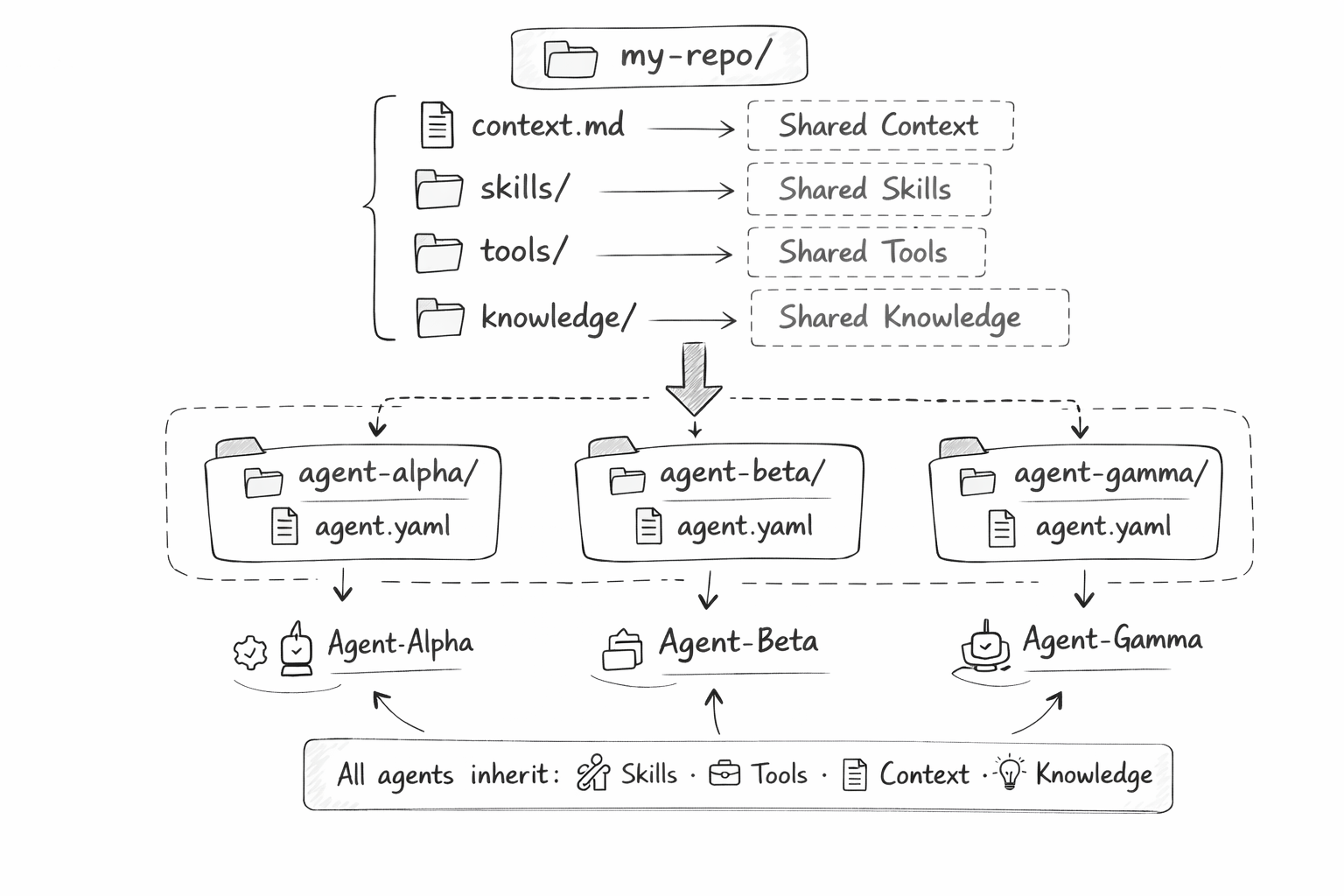
Root-level files are shared across every agent in a repository. Put your organization's knowledge in context.md at the root. Put shared capabilities in skills/. Every agent inherits them automatically.
my-org-agents/
├── context.md # Shared across all agents
├── skills/
│ └── code-review/ # Any agent can use this
├── agents/
│ ├── frontend-agent/ # Inherits root context + skills
│ └── backend-agent/ # Same shared foundation
One source of truth. No duplication. No sync issues. Monorepo patterns, applied to agents.
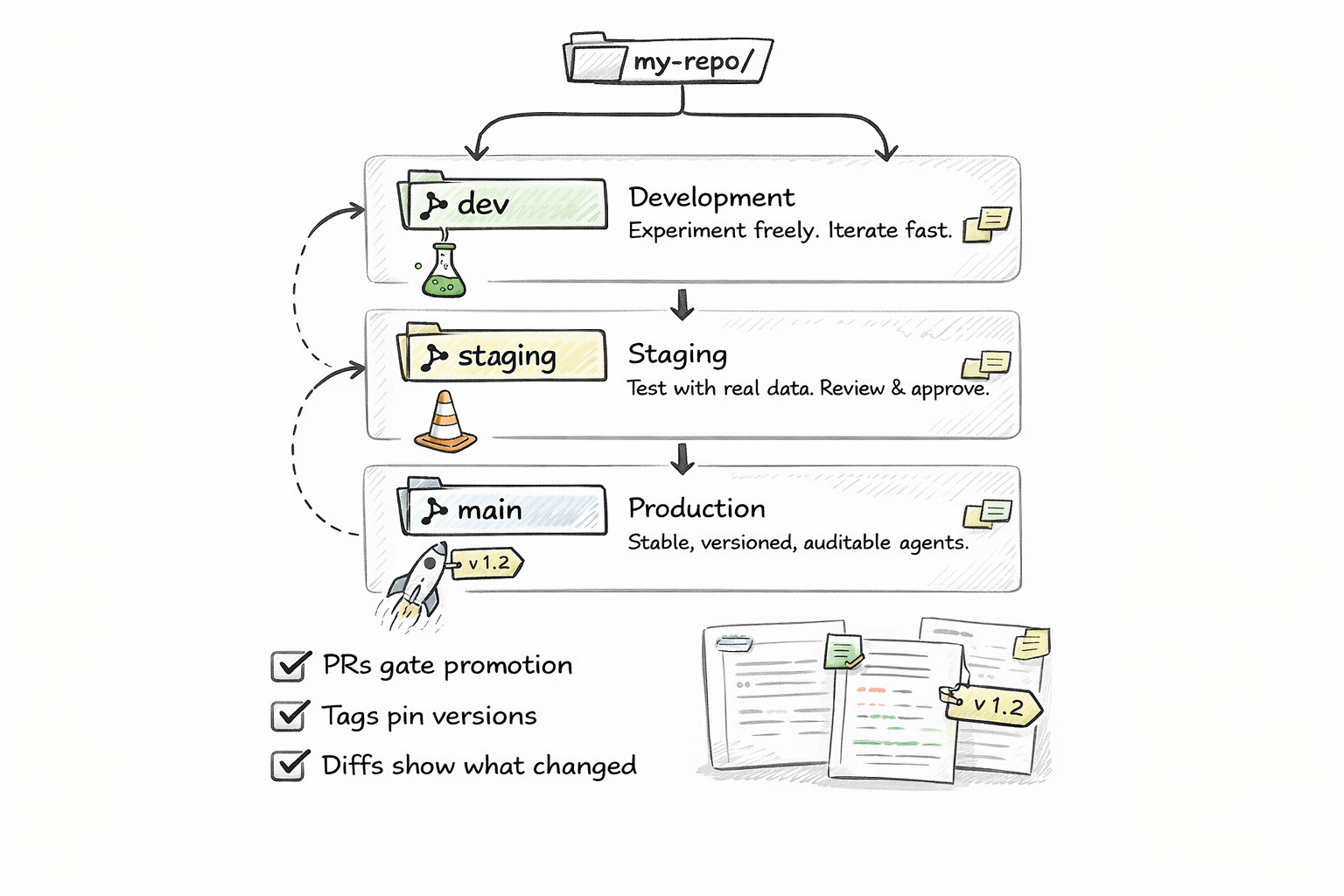
Promote agent changes through environments using branches:
feature/new-skill → dev → staging → main
Your main branch is production. Your staging branch is QA. Your feature branches are experiments. Merge when ready, revert when broken. The same deployment model your team already uses for applications now works for agents.
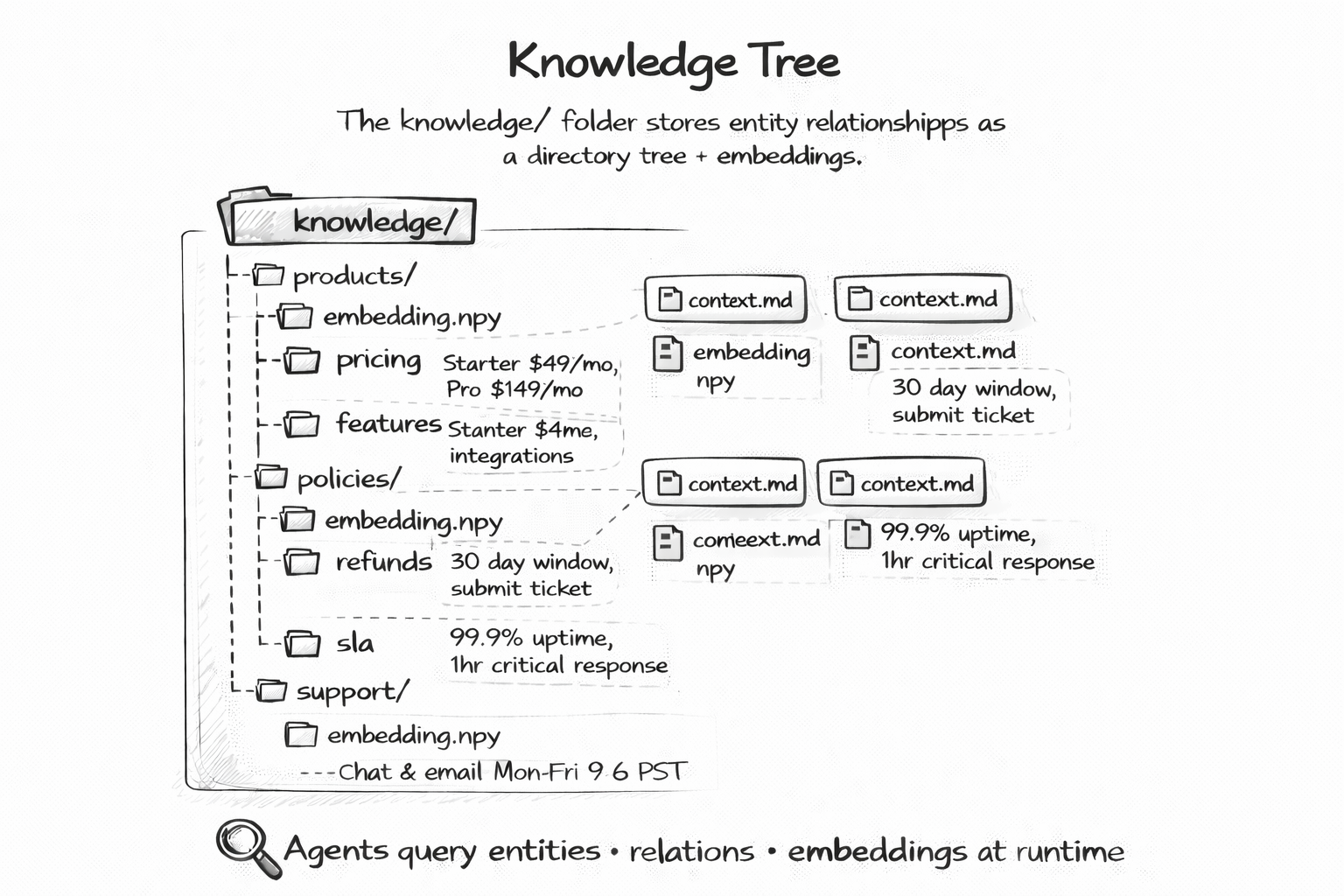
The knowledge/ folder stores structured reference documents — entity relationships, domain knowledge, regulatory requirements — as a hierarchical tree that agents can reason over at runtime.
knowledge/
├── products/
│ ├── pricing.md
│ └── features.md
├── policies/
│ └── compliance.md
└── README.md
Unlike opaque embedding stores, knowledge trees are human-readable, diffable, and reviewable. You can see exactly what your agent knows and change it with a commit.
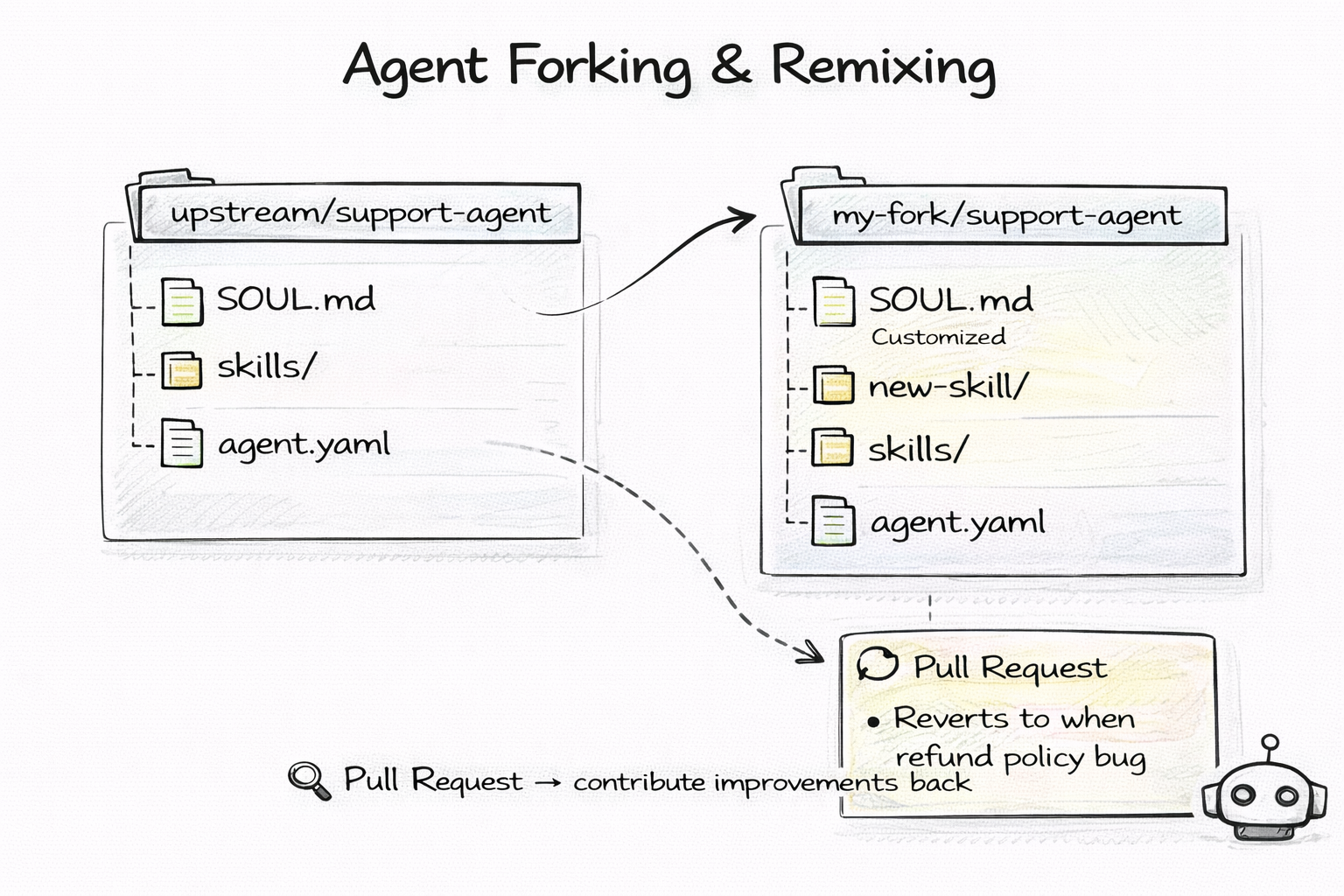
Want to customize someone else's agent? Fork the repo.
# Fork a public agent
gh repo fork open-gitagent/code-reviewer
# Customize its identity
vim SOUL.md
# Add your own skills
cp -r my-skills/ skills/
# PR improvements back upstream
gh pr create --repo open-gitagent/code-reviewer
Open-source collaboration patterns — forking, remixing, contributing back — now apply to AI agents. An agent is not a black box. It is a repo you can read, modify, and share.
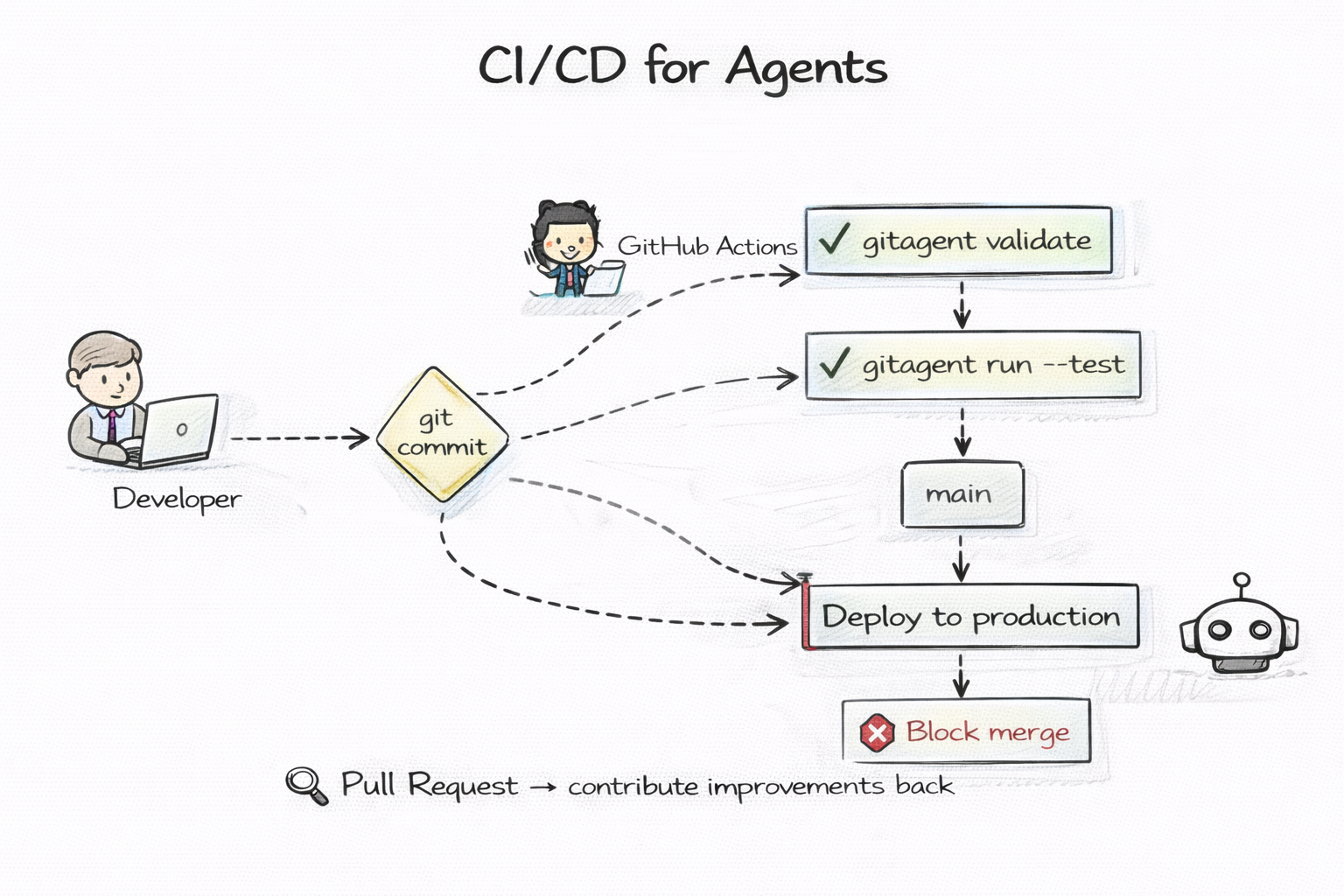
Run validation on every push. Test agent behavior in CI. Block bad merges. Auto-deploy validated agents.
# .github/workflows/validate.yml
on: [push, pull_request]
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: npm install -g @shreyaskapale/gitagent
- run: gitagent validate
Agent quality gates work exactly like code quality gates. Linting, validation, compliance checks — all in your existing CI pipeline. No agent-specific infrastructure needed.
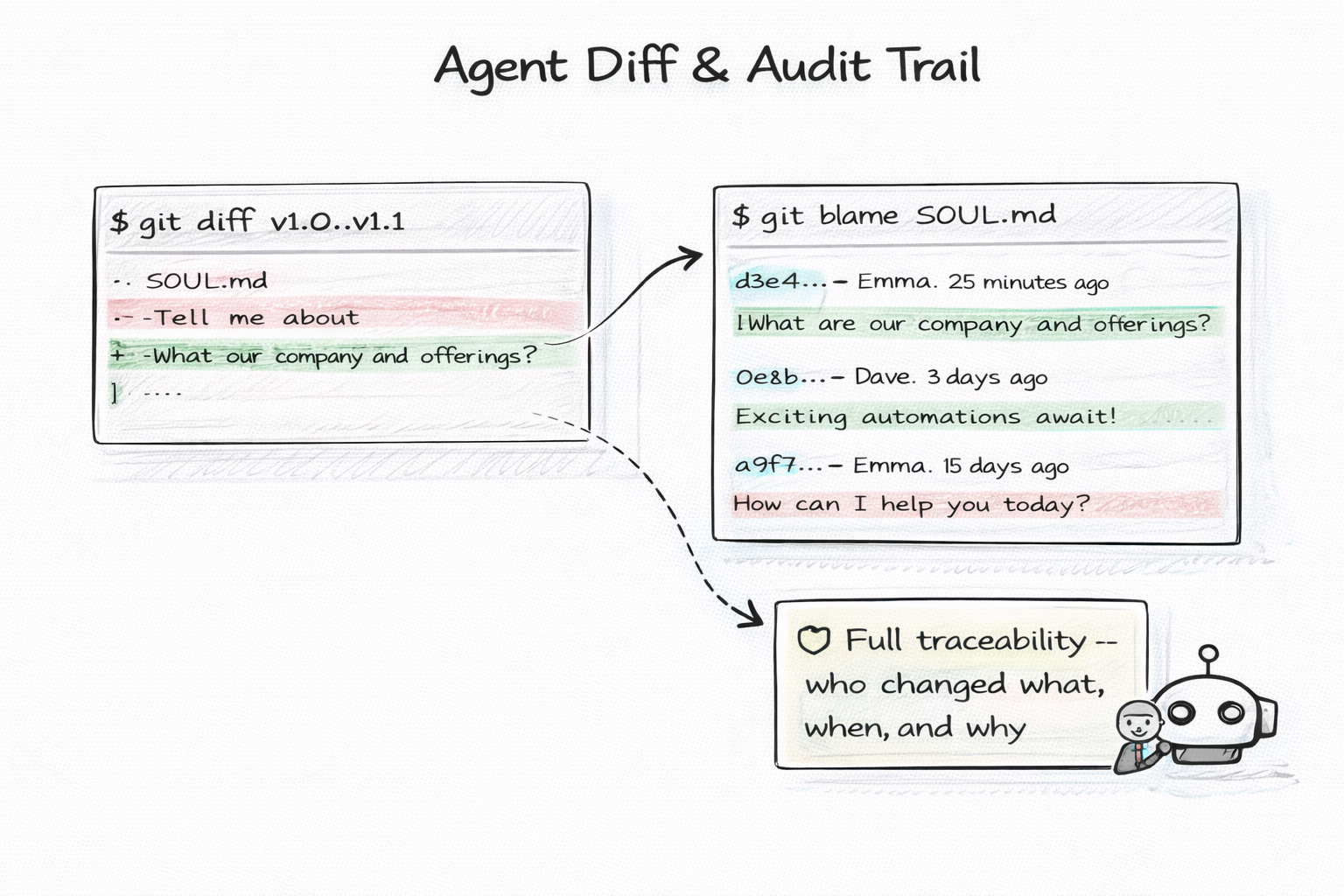
# What changed in the last release?
git diff v1.0.0..v1.1.0
# Who changed the agent's rules and when?
git blame RULES.md
# Full history of every change
git log --all --oneline
For regulated industries, this is not optional. Every change to an agent's behavior must be traceable. Git gives you a complete, tamper-evident audit trail by default. No additional logging infrastructure. No compliance add-ons. Just git log.
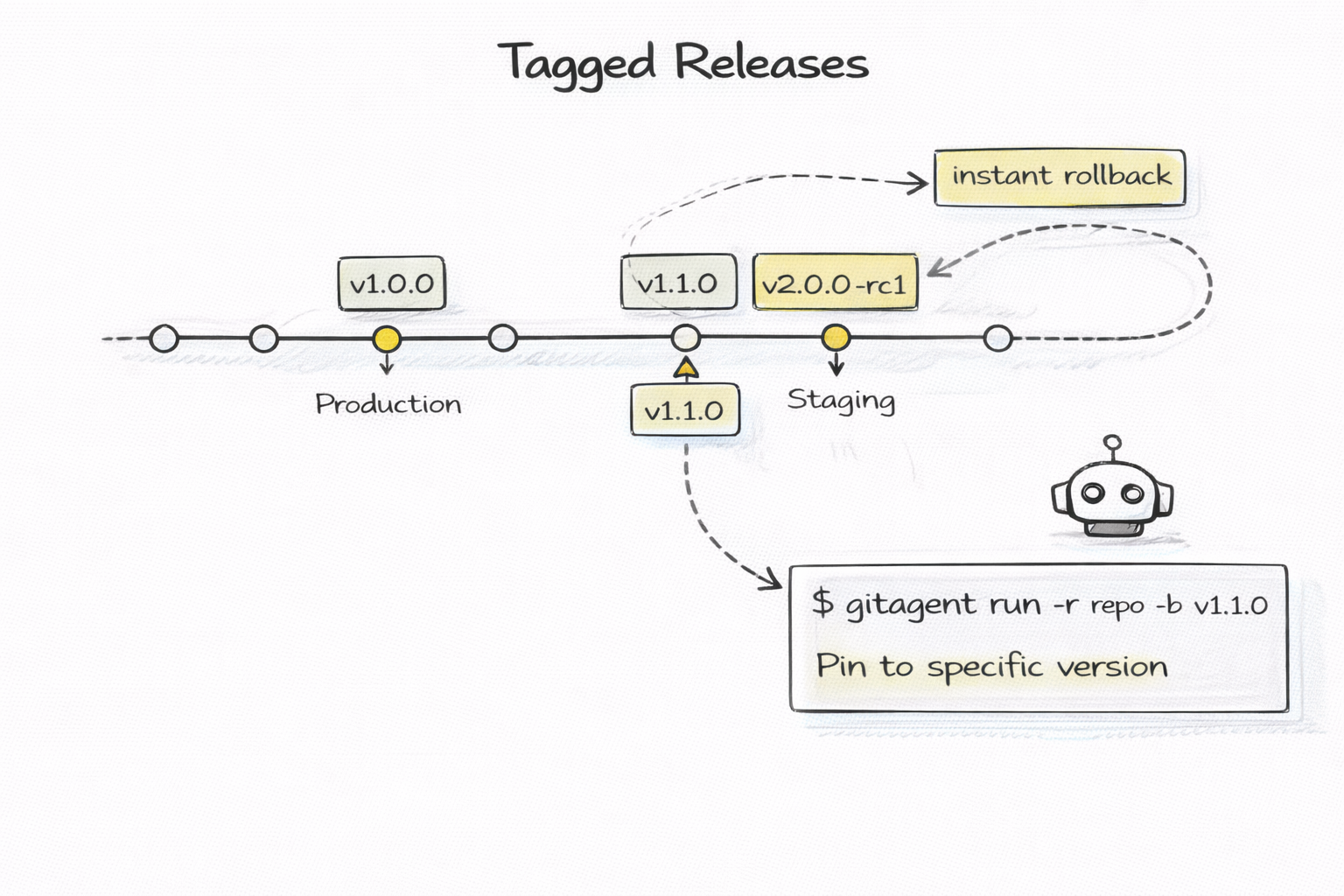
git tag -a v1.1.0 -m "Added financial analysis skill"
git push origin v1.1.0
Pin production to a tag. Canary new versions on staging. Instant rollback if something breaks. Semantic versioning for agents works exactly like semantic versioning for libraries — because an agent is just another artifact in your repo.
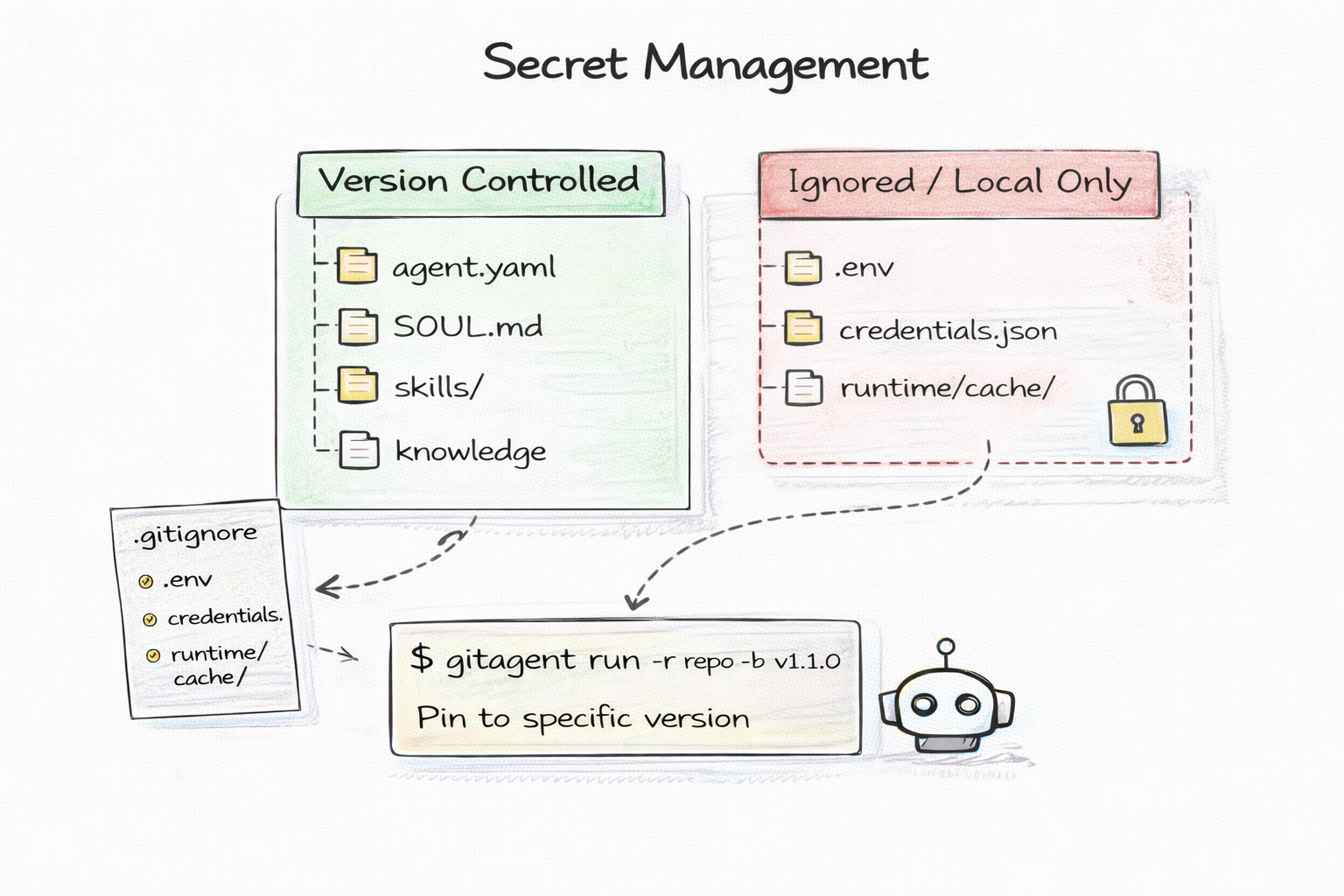
# .gitignore
.env
.gitagent/
Agent configuration is shareable. Secrets stay local. API keys live in .env, which is gitignored. The agent definition is portable; the credentials are not. This is the same pattern every web application already uses.
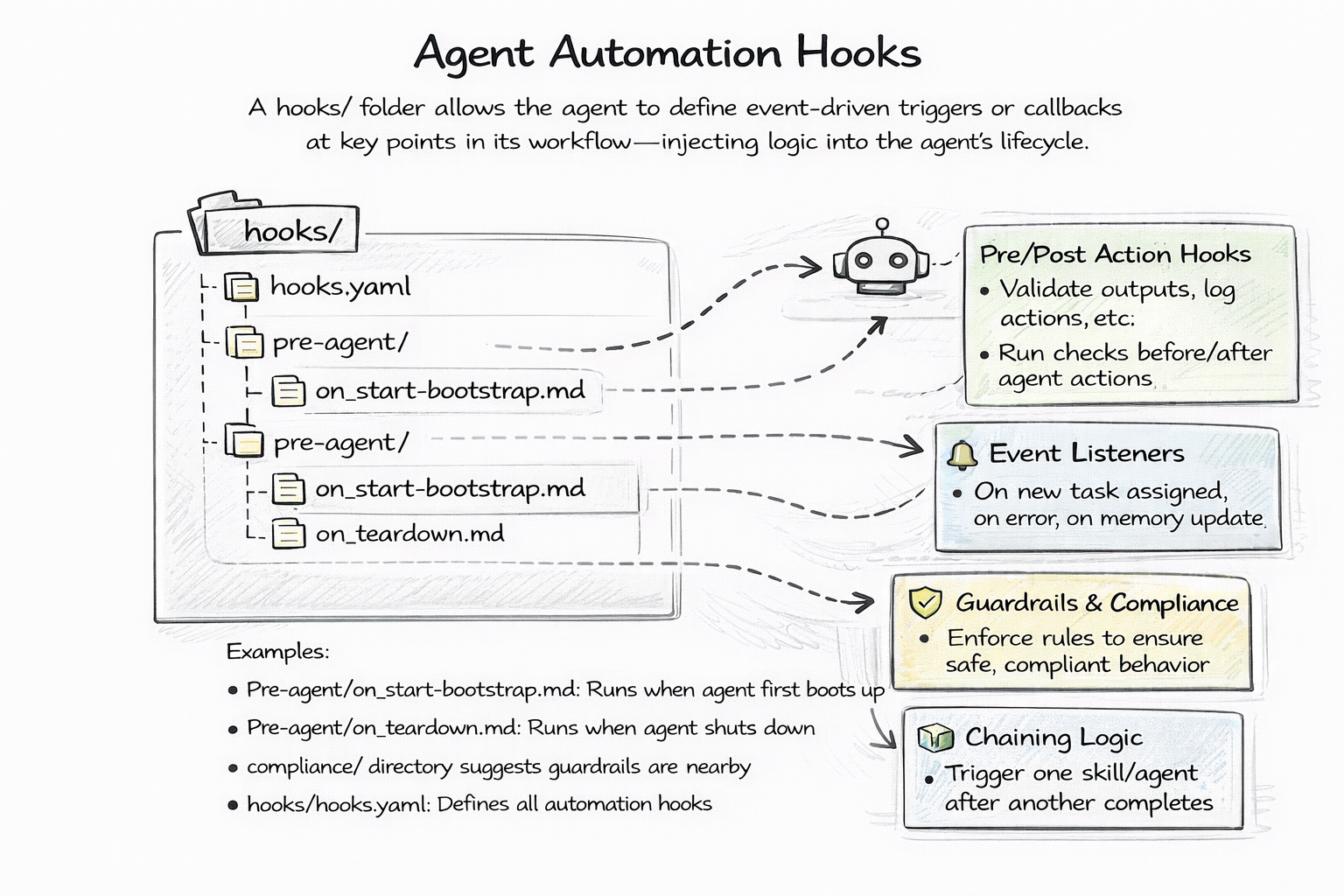
hooks/
├── bootstrap.md # Runs at agent startup
└── teardown.md # Runs before shutdown
Inject logic at key lifecycle points — initialization, shutdown, pre-task, post-task. Hooks are just files in the hooks/ directory. No event bus. No pub/sub. No callback registration. Files.
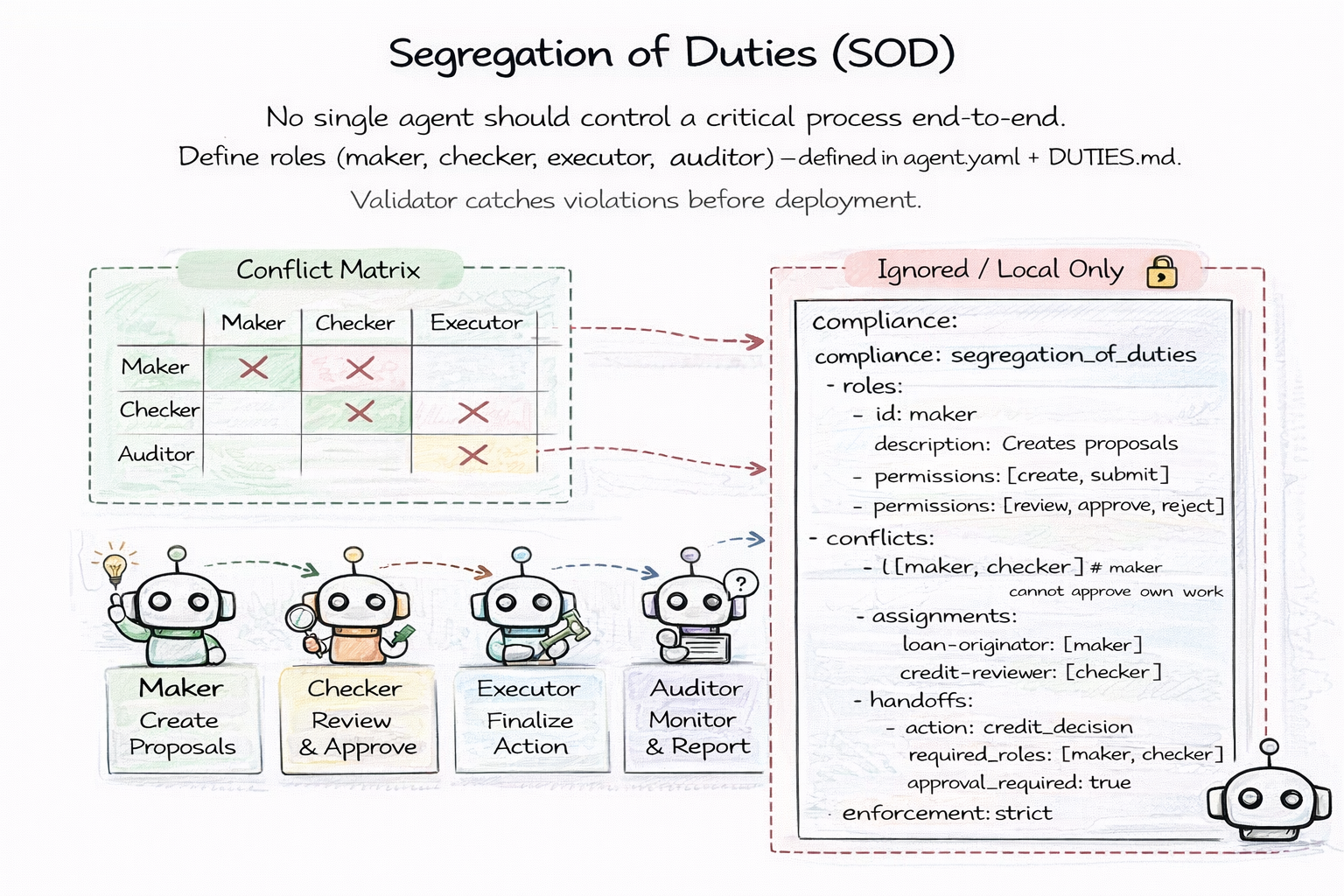
No single agent should control a critical process end-to-end. In regulated industries — finance, healthcare, legal — this is not a best practice. It is a requirement. The agent that creates a proposal cannot be the same agent that approves it. The agent that executes a trade cannot be the same agent that audits it.
GitAgent enforces this at the file level. A DUTIES.md file declares the agent's role — maker, checker, executor, or auditor. The agent.yaml manifest defines a conflict matrix specifying which roles cannot coexist in the same agent, and handoff rules specifying which actions require multi-role sign-off.
compliance:
segregation_of_duties:
roles:
- id: maker
permissions: [create, submit]
- id: checker
permissions: [review, approve, reject]
conflicts:
- [maker, checker] # maker cannot approve own work
handoffs:
- action: credit_decision
required_roles: [maker, checker]
approval_required: true
enforcement: strict
Run gitagent validate --compliance and it catches SOD violations before deployment. An agent assigned the maker role that also has checker permissions? Blocked. A handoff that skips a required role? Flagged. The conflict matrix is not advisory — it is enforced in CI.
This turns a compliance requirement into a version-controlled, testable, auditable artifact. The policy is a file. The enforcement is a CLI command. The audit trail is git.
Because convergence without coordination creates fragmentation.
Every framework arrived at "agents are files" independently. But they all chose different file names, different structures, different conventions. CLAUDE.md is not crew.yaml is not .cursorrules is not AGENTS.md. The idea is the same. The implementations are incompatible.
This is the moment where a standard matters. Not to replace any framework, but to sit above them — a single agent definition that exports to all of them.
That is what GitAgent is.
GitAgent formalizes the filesystem convergence into an open specification — not just for defining agents, but for the full lifecycle of an agent that learns, remembers, evolves, and ships through git.
Your repository is not a config dump. It is the agent. The SOUL.md is who it is. The memory/ folder is what it has learned. The knowledge/ tree is what it knows. The skills/ directory is what it can do. The git history is everything it has ever been. And every framework can read it:
my-agent/
├── agent.yaml # Manifest — name, version, model, skills
├── SOUL.md # Identity and personality
├── RULES.md # Hard constraints
├── AGENTS.md # Framework-agnostic fallback (Copilot, Cursor, OpenClaw)
├── DUTIES.md # Segregation of duties policy and role boundaries
├── skills/ # Reusable capabilities
├── tools/ # Tool definitions
├── knowledge/ # Reference documents
├── memory/ # Persistent state
├── hooks/ # Lifecycle handlers
└── workflows/ # Multi-step procedures
Only two files are required: agent.yaml and SOUL.md. Everything else is optional. Start minimal, grow as needed.
Then export to any framework:
gitagent export --format claude-code # → CLAUDE.md
gitagent export --format crewai # → crew.yaml
gitagent export --format openai # → Python module
gitagent export --format system-prompt # → Universal markdown
Or run directly:
# Run any agent from a git URL
gitagent run -r "https://github.com/you/your-agent" -a claude
Write once. Run anywhere. Version everything. Your repository is your agent — learning, evolving, shipping through git. That is the promise of git-native agents.
npm install -g @shreyaskapale/gitagent
# Scaffold an agent
gitagent init --template standard
# Validate it
gitagent validate
# Export to your framework
gitagent export --format claude-code
# Run it
gitagent run . -a claude
The specification is open. The CLI is MIT-licensed. The repo accepts contributions.
Every framework already agreed that agents are files. GitAgent makes it official — and makes your git repository the living, breathing, version-controlled home for your AI agent.
Clone a repo. Get an agent. Ship it with git.