-
Prerequisite
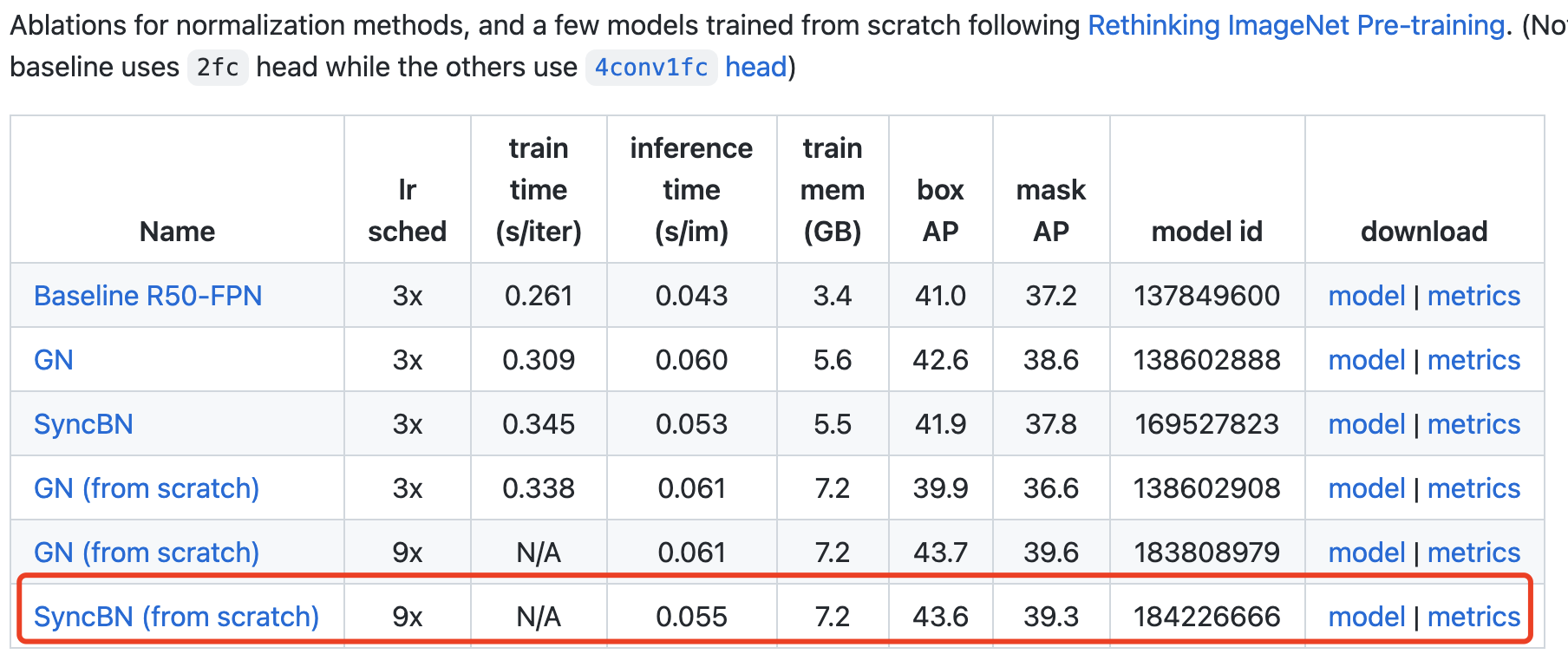
🐞 Describe the bugI write a scrip to transfer the Mask R-CNN weights from detectron2 and then transfer to mmdet. All keys are loaded correctly, then this config is used to evaluate the result. The pre-trained model from detectron2 is here, with 43.6 box_mAP and 39.3 seg_mAP tested with detectron2 If I do not change the norm_cfg order, the result tested by mmdet is 38.9 (box_mAP) and 34.9 (seg_mAP) However, there are still huge gap between the results, could you please check that?
Click to show the code for transfer weightsimport argparse
from collections import OrderedDict
import mmcv
import numpy as np
import torch
def convert(src, dst):
src_model = mmcv.load(src)
dst_state_dict = OrderedDict()
for k, v in src_model['model'].items():
if 'pixel' in k:
continue
key_name_split = k.split('.')
if 'backbone.fpn_lateral' in k and 'norm' not in k:
lateral_id = int(key_name_split[1][-1])
name = f'neck.lateral_convs.{lateral_id-2}.conv.{key_name_split[-1]}'
elif 'backbone.fpn_lateral' in k and 'norm' in k:
lateral_id = int(key_name_split[1][-1])
name = f'neck.lateral_convs.{lateral_id-2}.bn.{key_name_split[-1]}'
elif 'backbone.fpn_output' in k and 'norm' not in k:
lateral_id = int(key_name_split[1][-1])
name = f'neck.fpn_convs.{lateral_id-2}.conv.{key_name_split[-1]}'
elif 'backbone.fpn_output' in k and 'norm' in k:
lateral_id = int(key_name_split[1][-1])
name = f'neck.fpn_convs.{lateral_id-2}.bn.{key_name_split[-1]}'
elif 'backbone.fpn_output' in k:
lateral_id = int(key_name_split[1][-1])
name = f'neck.fpn_convs.{lateral_id-2}.conv.{key_name_split[-1]}'
elif 'backbone.bottom_up.stem.conv1.norm.' in k:
name = f'backbone.bn1.{key_name_split[-1]}'
elif 'backbone.bottom_up.stem.conv1.' in k:
name = f'backbone.conv1.{key_name_split[-1]}'
elif 'backbone.bottom_up.res' in k:
weight_type = key_name_split[-1]
res_id = int(key_name_split[2][-1]) - 1
# deal with short cut
if 'shortcut' in key_name_split[4]:
if 'shortcut' == key_name_split[-2]:
name = f'backbone.layer{res_id}.{key_name_split[3]}.downsample.0.{key_name_split[-1]}'
elif 'shortcut' == key_name_split[-3]:
name = f'backbone.layer{res_id}.{key_name_split[3]}.downsample.1.{key_name_split[-1]}'
else:
print(f'Unvalid key {k}')
# deal with conv
elif 'conv' in key_name_split[-2]:
conv_id = int(key_name_split[-2][-1])
name = f'backbone.layer{res_id}.{key_name_split[3]}.conv{conv_id}.{key_name_split[-1]}'
# deal with BN
elif key_name_split[-2] == 'norm':
conv_id = int(key_name_split[-3][-1])
name = f'backbone.layer{res_id}.{key_name_split[3]}.bn{conv_id}.{key_name_split[-1]}'
else:
print(f'{k} is invalid')
elif 'proposal_generator.anchor_generator' in k:
continue
elif 'rpn' in k:
if 'conv' in key_name_split[2]:
name = f'rpn_head.rpn_conv.{key_name_split[-1]}'
elif 'objectness_logits' in key_name_split[2]:
name = f'rpn_head.rpn_cls.{key_name_split[-1]}'
elif 'anchor_deltas' in key_name_split[2]:
name = f'rpn_head.rpn_reg.{key_name_split[-1]}'
else:
print(f'{k} is invalid')
elif 'roi_heads' in k:
if key_name_split[1] == 'box_head' and 'conv' in key_name_split[2]:
fc_id = int(key_name_split[2][-1]) - 1
if 'norm' in key_name_split:
name = f'roi_head.bbox_head.shared_convs.{fc_id}.bn.{key_name_split[-1]}'
else:
name = f'roi_head.bbox_head.shared_convs.{fc_id}.conv.{key_name_split[-1]}'
elif key_name_split[1] == 'box_head' and 'fc' in key_name_split[2]:
fc_id = int(key_name_split[2][-1]) - 1
name = f'roi_head.bbox_head.shared_fcs.{fc_id}.{key_name_split[-1]}'
elif 'cls_score' == key_name_split[2]:
name = f'roi_head.bbox_head.fc_cls.{key_name_split[-1]}'
elif 'bbox_pred' == key_name_split[2]:
name = f'roi_head.bbox_head.fc_reg.{key_name_split[-1]}'
elif 'mask_fcn' in key_name_split[2]:
conv_id = int(key_name_split[2][-1]) - 1
if 'norm' in key_name_split:
name = f'roi_head.mask_head.convs.{conv_id}.bn.{key_name_split[-1]}'
else:
name = f'roi_head.mask_head.convs.{conv_id}.conv.{key_name_split[-1]}'
elif 'deconv' in key_name_split[2]:
name = f'roi_head.mask_head.upsample.{key_name_split[-1]}'
elif 'roi_heads.mask_head.predictor' in k:
name = f'roi_head.mask_head.conv_logits.{key_name_split[-1]}'
elif 'roi_heads.mask_coarse_head.reduce_spatial_dim_conv' in k:
name = f'roi_head.mask_head.downsample_conv.conv.{key_name_split[-1]}'
elif 'roi_heads.mask_coarse_head.prediction' in k:
name = f'roi_head.mask_head.fc_logits.{key_name_split[-1]}'
elif key_name_split[1] == 'mask_coarse_head':
fc_id = int(key_name_split[2][-1]) - 1
name = f'roi_head.mask_head.fcs.{fc_id}.{key_name_split[-1]}'
elif 'roi_heads.mask_point_head.predictor' in k:
name = f'roi_head.point_head.fc_logits.{key_name_split[-1]}'
elif key_name_split[1] == 'mask_point_head':
fc_id = int(key_name_split[2][-1]) - 1
name = f'roi_head.point_head.fcs.{fc_id}.conv.{key_name_split[-1]}'
else:
print(f'{k} is invalid')
else:
print(f'{k} is not converted!!')
if not isinstance(v, np.ndarray) and not isinstance(v, torch.Tensor):
raise ValueError(
'Unsupported type found in checkpoint! {}: {}'.format(
k, type(v)))
if not isinstance(v, torch.Tensor):
dst_state_dict[name] = torch.from_numpy(v)
print(f'{k} => {name}')
mmdet_model = dict(state_dict=dst_state_dict, meta=dict())
torch.save(mmdet_model, dst)
def main():
parser = argparse.ArgumentParser(description='Convert model keys')
parser.add_argument('src', help='src detectron model path')
parser.add_argument('dst', help='save path')
args = parser.parse_args()
convert(args.src, args.dst)
if __name__ == '__main__':
main()EnvironmentAny enviroments |
Beta Was this translation helpful? Give feedback.
Replies: 1 comment
-
|
Hi @mitming , |
Beta Was this translation helpful? Give feedback.
Hi @mitming ,
The original model trained in Detectron2 uses caffe-style backbone. Therefore, after changing the norm_cfg, you should also change the style in the backbone from
style='pytorch'tostyle='caffe'