Several issues introduced in version 20230306 on audio with silences (repeated text, segment "id" not unique/increasing) #1058
-
|
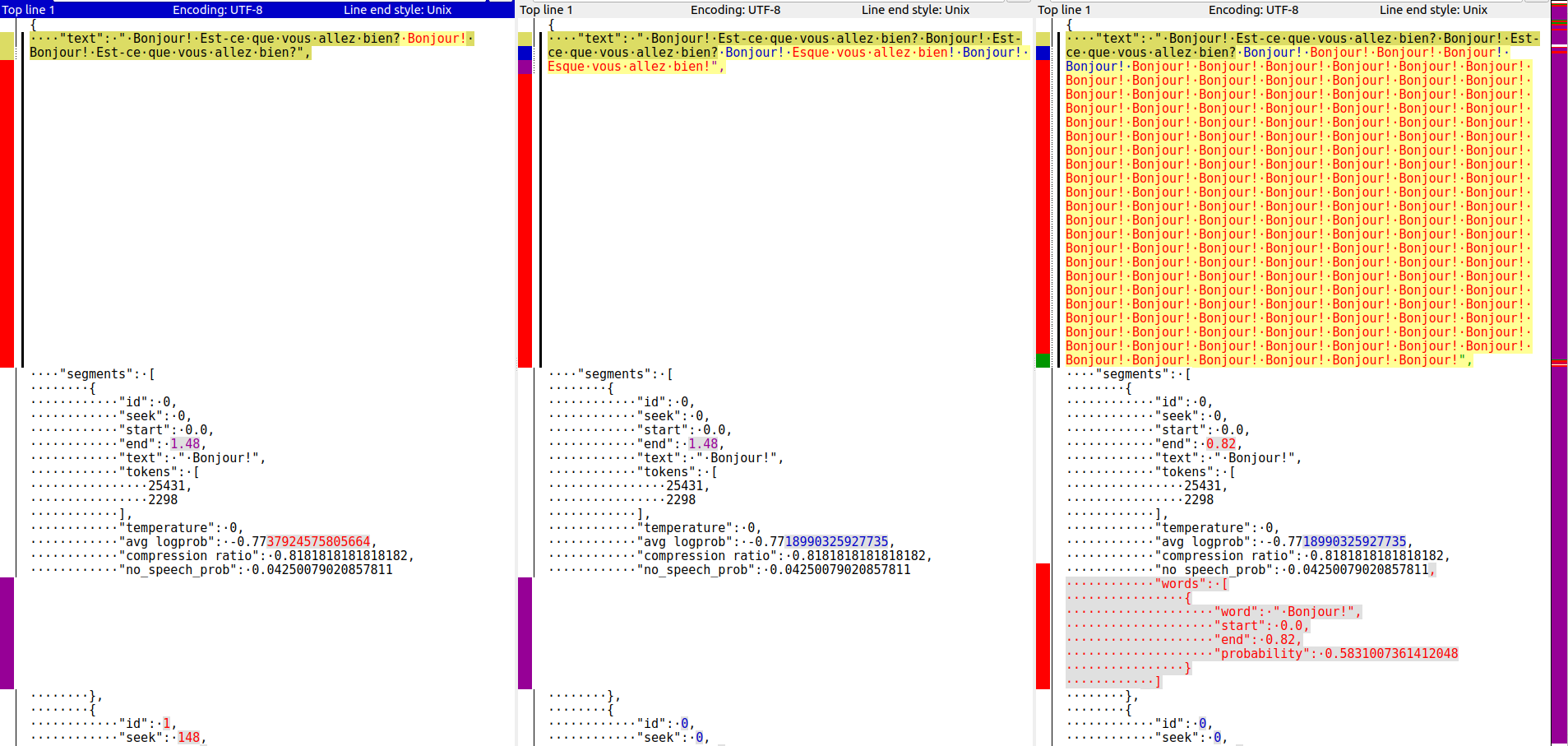
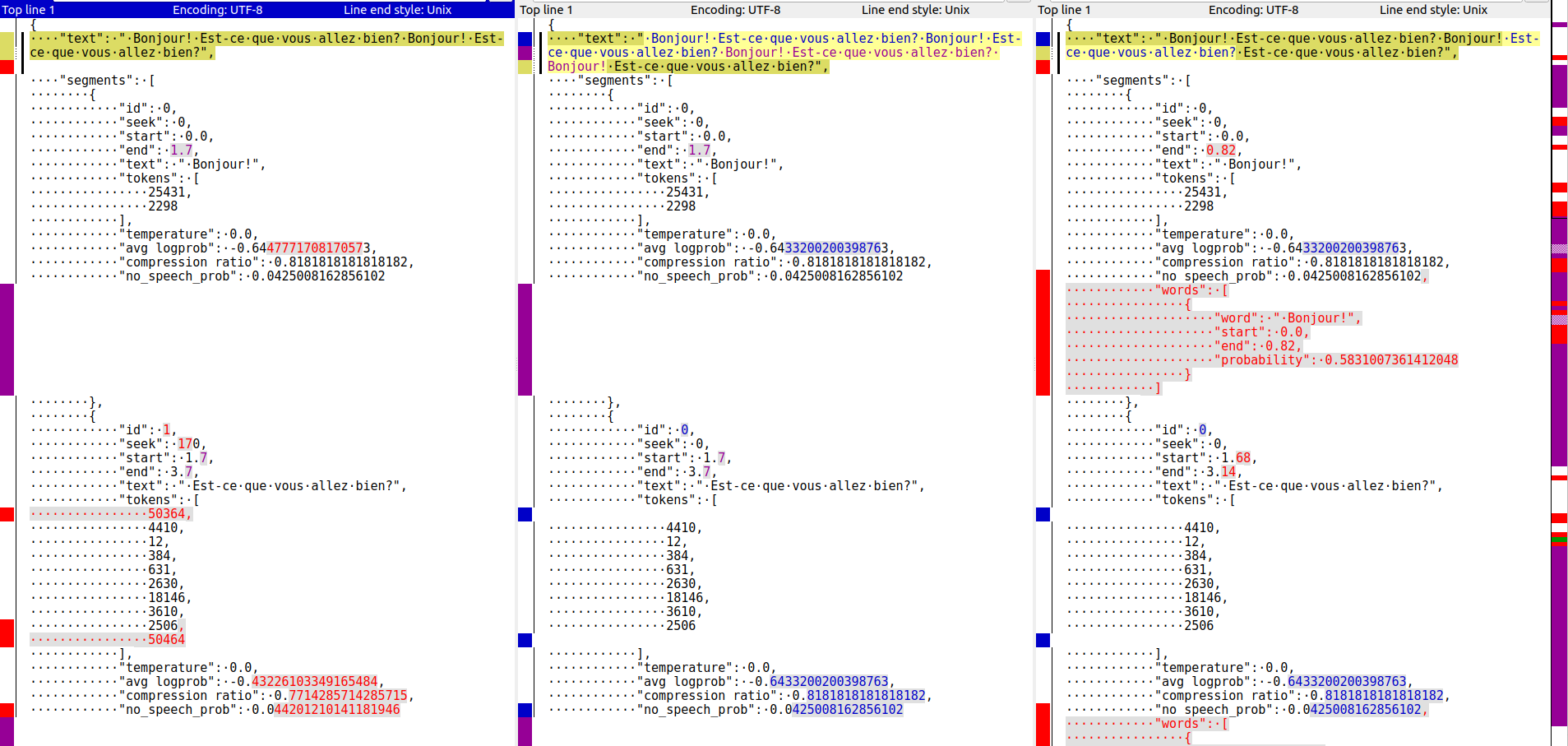
This issue looks more general than #1046 and it might be related to #730 (however this was after v20230306). Take this audio: bonjour_vous_allez_bien.mp3 For this command: below are the differences between outputs of previous version 20230124 (left), new version 20230306 (middle) and 20230306 with
This became obvious when I used greedy decoding, but a similar thing can be observed with less options (with beam search). On this command, the differences between outputs of previous version 20230124 (left), new version 20230306 (middle) and 20230306 with
I also noticed that the following command is particularly long to run: It takes 1 minute with 4 CPU, whereas it takes 6 sec without |
Beta Was this translation helpful? Give feedback.
Replies: 4 comments 7 replies
-
|
I've just tested 20230307 and the two problems are still here:
|
Beta Was this translation helpful? Give feedback.
-
|
This looks like the repetition is unique to the .json output, the others (.txt, .srt, etc) look correct. Do you agree? |
Beta Was this translation helpful? Give feedback.
-
|
I can reproduce this problem only with the tiny model, and only for the .json output. Small and medium and other outputs seem to be ok. If I don't supply |
Beta Was this translation helpful? Give feedback.
-
|
Had the same issue with JSON, used |
Beta Was this translation helpful? Give feedback.
-
Yes, correct. |
Beta Was this translation helpful? Give feedback.
-
|
Hi! Thanks for reporting this. The non-unique About the discrepancy between ["text"] and segment["text"], I think it has something to do with these lines: Lines 345 to 356 in aac47c9 EDIT: the culprit was actually this line: Line 290 in aac47c9 will push a fix soon. |
Beta Was this translation helpful? Give feedback.
-
|
This was an issue where the new I have a fix merged in #1060, so hopefully this resolves your issue! Please let me know if it continues. |
Beta Was this translation helpful? Give feedback.
-
|
Great. Thank you @jongwook |
Beta Was this translation helpful? Give feedback.
-
|
I think the |
Beta Was this translation helpful? Give feedback.
-
|
A PR was opened to fix this issue: #1224. |
Beta Was this translation helpful? Give feedback.
-
|
oop, didn't think to look there. thanks for the pointer! |
Beta Was this translation helpful? Give feedback.
This was an issue where the new
transcribe()was mishandling theall_tokensvariable which affected the prompts to be more prone to repetitions and also caused the discrepancy between the top-level"text"field and the segment-level"text"fields in the JSON response.I have a fix merged in #1060, so hopefully this resolves your issue! Please let me know if it continues.