Reason for 30s audio length #1118
-
|
Hello, I understand that whisper can only access 30s of audio content, what is the reason behind that? Is it because larger than 30s is harder to train? I assume a window larger than 30 seconds since GPU can speed up the process. Assuming one was to retrain the model from scratch what are the benefits and drawbacks of using a smaller and larger window? |
Beta Was this translation helpful? Give feedback.
Replies: 2 comments 5 replies
-
|
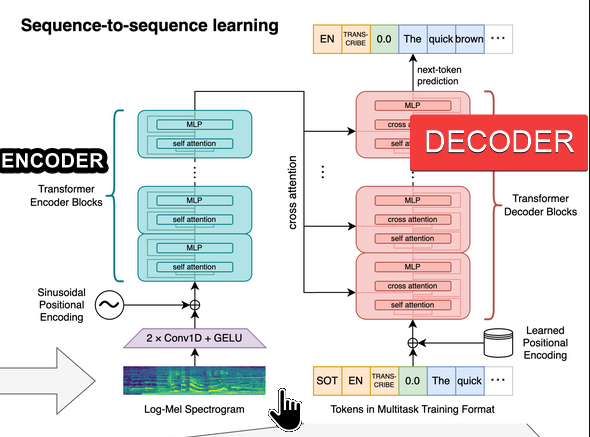
I'm not super academic about ML, so take this with a grain of salt, but speaking broadly, the whisper model is basically the same structure as a image-to-text that looks at a picture and comes up with a description of it. Instead of looking at pictures, it looks at 30s of audio spectrogram instead.
The encoder layers extract cross-attention weights describing aspects of semantic import and then the decoder generates tokens from that cross attention, keeping track of prior context (prompt) and parts that were already "transcribed/translated" (prefix). This is why we are limited to 30s of audio. Too short, and you'd lack surrounding context. You'd cut sentences more often. A lot of sentences would cease to make sense. Too long, and you'll need larger and larger models to contain the complexity of the meaning you want the model to keep track of. |
Beta Was this translation helpful? Give feedback.
-
|
I think you are right, in the sense that longer times would require larger complexity to handle the model. I also assume alot of other datasets use shorter audio, so the model might not learn the data properly when alot of data is padded. And if the window is shorter the model wouldn't be able to gather as much information. I assumed that for inference a longer window would be faster but forgot to look at the training aspect, which would take much longer and be more complex, and vice versa with shorter windows. |
Beta Was this translation helpful? Give feedback.
-
|
I also have a similar question. I am wondering the influence of audio length for the finetuning performance. To be specific, do we have some requirements of audio length for finetuning in order to get a good WER? Such as the proportion of data within a given range of audio length (say 15s~25s etc.)? What if the audio length for finetuning is fairly short? |
Beta Was this translation helpful? Give feedback.
-
|
I think 15-25s should work fairly well for fine-tuning. If the majority of the examples are very short, e.g. containing only a couple of words, the model may degrade into a mode that produces short outputs only. |
Beta Was this translation helpful? Give feedback.
-
|
Hi, thanks for your reply.
I am a little bit confused about this. Does it suggest that the model may produce more deletion errors due to the amount of fairly short audio data used during finetuning? |
Beta Was this translation helpful? Give feedback.
-
|
@jongwook Hi, I have a question. If I fine-tune whisper with short samples with padding (e.g., 4-5 secs), will it degrade the model's performance in long-form (over 30s) prediction? |
Beta Was this translation helpful? Give feedback.
-
|
To both: yes, that's my default guess, but it could be possible to fine-tune without degrading long-form transcription accuracy, if done with a careful hyperparameter selection. |
Beta Was this translation helpful? Give feedback.
I'm not super academic about ML, so take this with a grain of salt, but speaking broadly, the whisper model is basically the same structure as a image-to-text that looks at a picture and comes up with a description of it. Instead of looking at pictures, it looks at 30s of audio spectrogram instead.
The encoder layers extract cross-attention weights describing aspects of semantic import and then the decoder generates tokens from that cross attention, keeping track of prior context (prompt) and parts that were already "transcribed/translated" (prefix). This is why we are limited to 30s of audio. Too short, and you'd lack surrounding context. You'd cut sentences more often. A lot of sentenc…