Bug: some models are stopping transcribing the video before the end. Why? Anything that can be done about it? #1164
Replies: 3 comments
-
|
I ran the
The remainder of the transcript was the text You might want to try using the parameter:
|
Beta Was this translation helpful? Give feedback.
-
|
FYI, I tried running your sample, mac, M1, CPU, large model, standard whisper - transcribes fine. |
Beta Was this translation helpful? Give feedback.
-
|
I am also using CPU (Intel Core i7-4790K CPU @ 4.00GHz × 4). Linux Mint 21.1 Cinnamon. Standard whisper. I tested some more (with the small 41s sample) and I was able to repeat the bug using the |
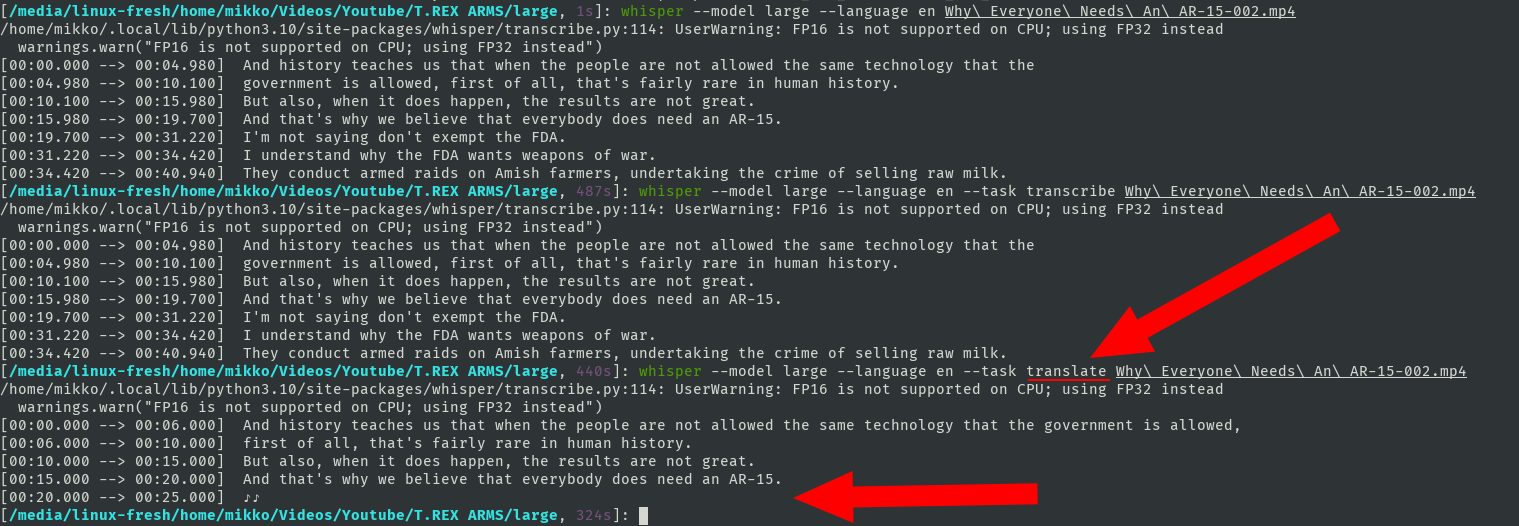
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Some models are stopping transcribing the video before the end.
I downloaded 1080p version of this 30min video using yt-dlp. Then I ran whisper on it, using the
base.enmodel. About 45s from the end were not transcribed. It was not feasible for me to test all the rest of the models using the full file.I cut the small version of the video (the last 41s) and ran models: tiny, tiny.en, base, base.en, small, small.en, medium, large. Of those, all the models worked fine except the
large. It did not transcribe everything, even though it stopped in different place than thebase.enmodel with the full file.This is an .mkv file renamed to .mp4 (because github would not allow uploading Matroska files; just download and run it locally):
https://user-images.githubusercontent.com/2521942/228718376-2a243cc3-819f-4dc7-ad2d-7ef9ddec9b8a.mp4
Can you confirm the existence of bug?
Is there anything that can be done about it? Any volunteers? Sadly I don't have enough expertise to fix the issue.
Beta Was this translation helpful? Give feedback.
All reactions