-
|
Hi, Great work, congrats! Would it be possible to add a new language to the model by fine-tuning it on my own dataset, or in some other way? Thanks. |
Beta Was this translation helpful? Give feedback.
Replies: 6 comments 12 replies
-
|
We haven't tried fine-tuning, but it could be a good avenue for research evaluating Whisper models as pretrained representation for unseen language. We have observed some transfer between linguistically adjacent languages, such as Asturian <-> Spanish (Castillian) or Cebuano <-> Filipino (Tagalog). So if your language of interest has an adjacent language that works acceptably in Whisper, you could fine-tune on your dataset using that language token. |
Beta Was this translation helpful? Give feedback.
-
|
how does the accuracy of other languages affected after fine-tuning the model on single language? |
Beta Was this translation helpful? Give feedback.
-
|
Check-out this blog for fine-tuning Whisper for multilingual ASR with Hugging Face Transformers: https://huggingface.co/blog/fine-tune-whisper It provides a step-by-step guide to fine-tuning, right from data preparation to evaluation 🤗 There'a Google Colab so you can also run it as a notebook 😉 |
Beta Was this translation helpful? Give feedback.
-
|
Hi! I tried running your notebook, and it works well till the mapping part. |
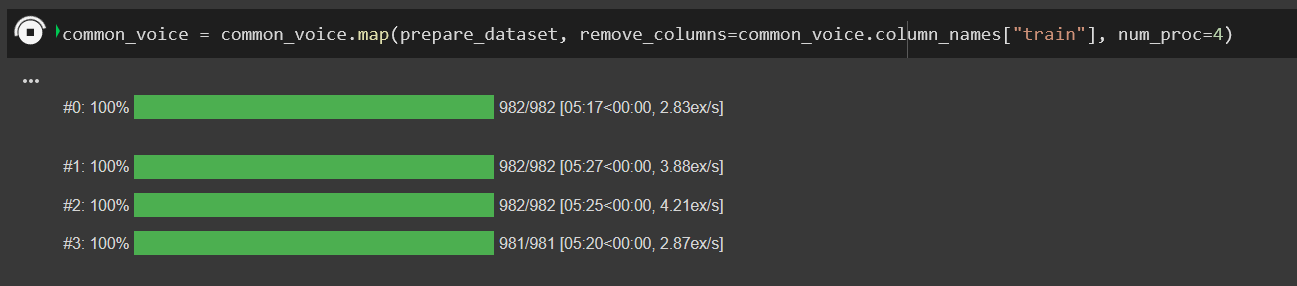
Beta Was this translation helpful? Give feedback.
-
|
Looks like multiprocessing has gotten stuck - the progress bars show that it only should have taken 5 mins! You can try with |
Beta Was this translation helpful? Give feedback.
-
|
Hi Sanchit, I followed your fine-tuning post for Hindi. The language Odia ("or") (a low-resource language spoken by 40M people!) isn't in the list of supported languages in tokenizer.py. It is closer to sanskrit bengali and hindi. I tried Odia audio with the demo app from your post detects it to be Italian! Could you suggest an approach to go about fine tuning for Odia. Thanks. |
Beta Was this translation helpful? Give feedback.
-
|
Hey @sukantan! You can try fine-tuning the Whisper model on Odia to boost it's performance in this language! Here, I'd recommend setting the tokenizer/processor language to the closest language available in Whisper to Odia (maybe Bengali?). Otherwise, the steps for fine-tuning are unchanged! There are a few Whisper models trained on Odia as part of the Whisper fine-tuning event: https://huggingface.co/spaces/autoevaluate/leaderboards?dataset=mozilla-foundation%2Fcommon_voice_11_0&only_verified=0&task=automatic-speech-recognition&config=or&split=test&metric=wer It could be worth trying these out to see whether the performance is any better than the zero-shot model! |
Beta Was this translation helpful? Give feedback.
-
|
Thank you! 🙂 |
Beta Was this translation helpful? Give feedback.
-
|
Hi! |
Beta Was this translation helpful? Give feedback.
-
|
Yes! Right now I'm in the Whisper+HF+Lambda fine-tuning event (which goes on for another week) and two people, myself included attempted Odia, a fairly low-resource language (but I speak it). |
Beta Was this translation helpful? Give feedback.
-
|
Feel free to join us @qunash! We've got over 7 days of the event left to go, so there's plenty of time to get involved and fine-tune a model on a language of your choice 🤗 We're providing scripts, resources and compute, so there's everything you need to participate! See the link for details and info on signing-up: https://github.com/huggingface/community-events/tree/main/whisper-fine-tuning-event |
Beta Was this translation helpful? Give feedback.
-
|
@aurotripathy That's super interesting! Would love to know how it went when you're done @sanchit-gandhi Thanks a lot for the invatation! I'd love to join, but unfortunately I can't right now 😞 |
Beta Was this translation helpful? Give feedback.
-
Would love to get involved when you have another event. |
Beta Was this translation helpful? Give feedback.
-
|
Can we fine-tune the whisper to Language identification task, using hugging face @sanchit-gandhi . |
Beta Was this translation helpful? Give feedback.
-
|
Yes! I did it here: https://huggingface.co/sanchit-gandhi/whisper-medium-fleurs-lang-id Expect a blog post shortly! Also see related PR here: huggingface/transformers#21754 |
Beta Was this translation helpful? Give feedback.
-
|
Hi, may i know can we fine-tune the whisper on new language for language identification task so that whisper can detect the new language? |
Beta Was this translation helpful? Give feedback.
-
|
I’ve completed a project where I fine-tuned Whisper-Tiny for translation tasks, and it worked great. You can check out my repo to see the process I followed, and it could help you solve the problem you're encountering. |
Beta Was this translation helpful? Give feedback.
We haven't tried fine-tuning, but it could be a good avenue for research evaluating Whisper models as pretrained representation for unseen language. We have observed some transfer between linguistically adjacent languages, such as Asturian <-> Spanish (Castillian) or Cebuano <-> Filipino (Tagalog). So if your language of interest has an adjacent language that works acceptably in Whisper, you could fine-tune on your dataset using that language token.