Replies: 5 comments
-
|
Although it won't help with accuracy, I wanted the time positions in milliseconds, instead of the slowness of parsing and storage size of having times in human readable format, when internally, I need timings in milliseconds to begin with, for #233 . See my pull request at #228 |
Beta Was this translation helpful? Give feedback.
-
|
I've the same problem, all timestamps have 000 milliseconds and they cut words because of that or they start at .000 and have additional word sometimes because they should start at .420 etc. Is it technically possible to make it more accurate just changing the code? or this is some property of the model and it will not be more accurate? |
Beta Was this translation helpful? Give feedback.
-
|
Take a look at #435 it might be an effort you can get some ideas or switch to using as it seems focused on timestamp accuracy |
Beta Was this translation helpful? Give feedback.
-
|
Thanks, I've seen that and tried it but it's even less accurate than default whisper. The problem is that I'm cutting audio based on the timestamps as it is used as training data for another model, so I could get 200 audio files from a 10 minute audio, that's why milliseconds precision is so important as cutting at .000 cuts words from the audio while they still exist in text. Problem is that transcribe function results have only seconds precision in start/end variables e.g. |
Beta Was this translation helpful? Give feedback.
-
|
If you are using whisper in command-line, try to add |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
As the question shows, I need to output a more precise time
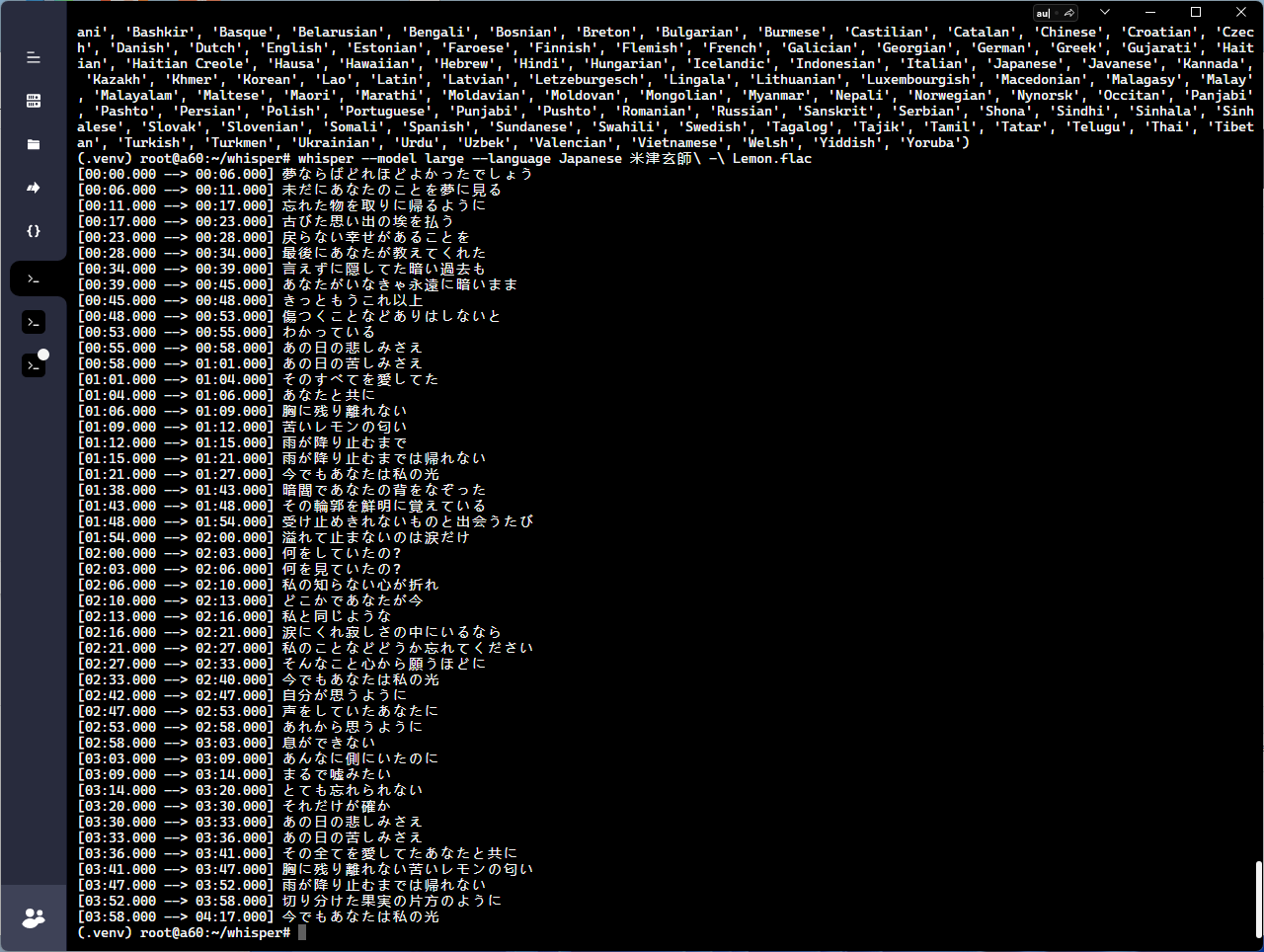
Beta Was this translation helpful? Give feedback.
All reactions