Which audio file format is best? #41
-
|
I will use it to transcribe (speech to text) and generate subtitles for my free English Software Engineering Courses (SECourses) that I publish on YouTube : https://www.youtube.com/SECourses I have tried many free apps and all failed miserably The best I have found was Google Speech to Text premium API which costs a lot and Google were requesting flac mono I was using following command to extract audio from my videos for Google API
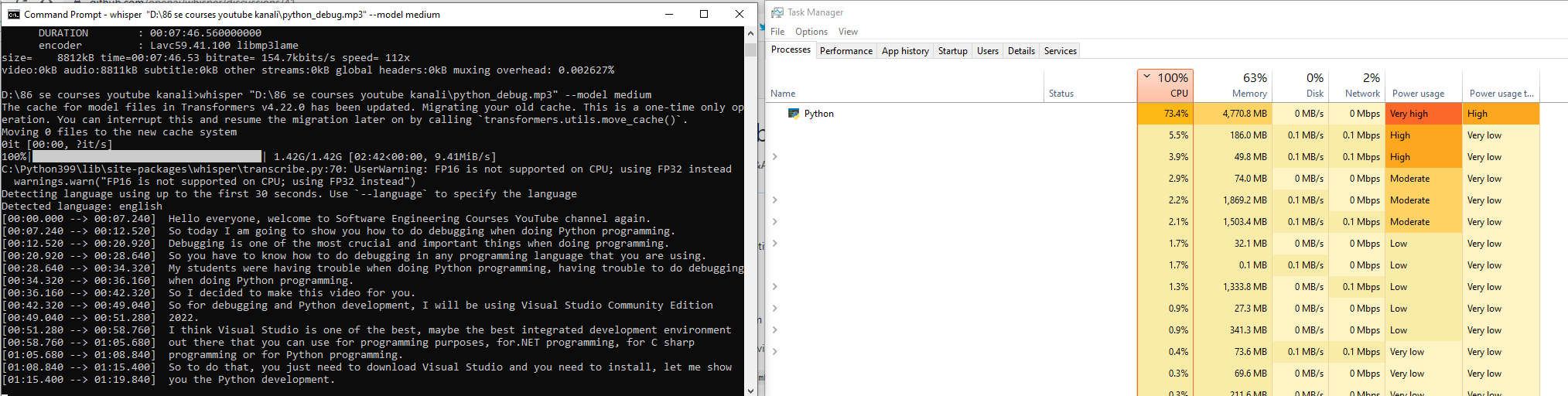
So what do you suggest me for providing into whisper Currently I am parsing this video and it is extremely slow : https://youtu.be/eWN4Ng08Y4U I have used this command to extract its audio :
And I have used this command start whisper speech to text (I hope I am correct?)
It looks even better than Google Speech to Text premium API so far accuracy is so amazing for a non-native speaker like me thank you so much guys
Uploaded generated subtitle with timing that AI generated Damn good congrats. First time ever I am seeing a not a cherry picked AI paper Select English subtitle at the video generated by whisper and I didn't edit at all currently : https://www.youtube.com/watch?v=eWN4Ng08Y4U |
Beta Was this translation helpful? Give feedback.
Replies: 3 comments 4 replies
-
|
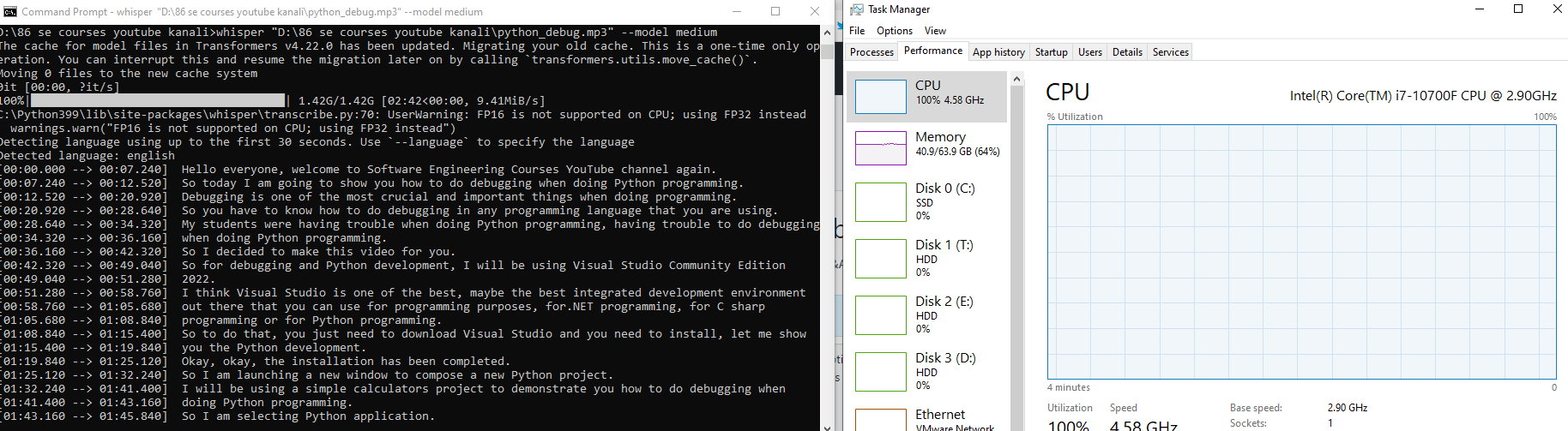
Ok i have put raw medium.en generated subtitle to the video and I am simply amazed (used the timings AI generated) Thank you so much guys this is an awesome tool
https://www.youtube.com/watch?v=eWN4Ng08Y4U edit : i just also manually fixed and there were only 5 words that had very minor errors and in 2 cases i said "were" which was supposed to be "was" and application has written them as was lol :D this is far better than even premium speech to text api of Google cloud services |
Beta Was this translation helpful? Give feedback.
-
|
The program converts your input with ffmpeg (effectively
There's your problem, this is a colossal language model... even on a RTX 3090 (high-end consumer) GPU, the medium model is only 3x-4x faster than playback time. On my CPU (AMD Ryzen 7 3700X), the small model did not finish transcribing a 1-minute sample in over 10 minutes. |
Beta Was this translation helpful? Give feedback.
-
|
Yes because of that I have purchased RTX 3060 12 GB Vram. Waiting it to arrive. Just too slow for CPU. But I am ok with slowness for better quality. That is why I liked Whisper very much. I wish they also had trained it for translation from english to other languages. I have tested it with forcing another language in google colabs but results were terrible. I am yet to test its speech recognition on foreign languages and translation from foreign language to English. Waiting my GPU to arrive. |
Beta Was this translation helpful? Give feedback.
-
|
Cost aside, which GPU will give the fastest performance? If I wanted to say use it to convert streaming audio in almost real-time. |
Beta Was this translation helpful? Give feedback.
-
best one in games probably. but be sure that vram capacity is enough for your target level. |
Beta Was this translation helpful? Give feedback.
-
|
What would be the most suitable GPU to purchase if I wanted to use the large model? |
Beta Was this translation helpful? Give feedback.
-
|
@georpat I would buy RTX 3060 12G if you have tight budget, othervise larger memory is better (NVIDIA) AMD GPUs may be problematic sometimes. |
Beta Was this translation helpful? Give feedback.
The program converts your input with ffmpeg (effectively
ffmpeg -i <recording> -ar 16000 -ac 1 -c:a pcm_s16le <output>.wav) and pre-processes it before doing any speech recognition. You can just give it your video files, except when that command wouldn't work (like if you have multiple audio languages and don't want the default track).There's your problem, this is a colossal language model... even on a RTX 3090 (high-end consumer) GPU, the medium model is only 3x-4x faster than playback time. On my CPU (AMD Ryzen 7 3700X), the small model did not finish transcribing a 1-minute sample in over 10 minutes.