Accelerate the Whisper decoding with CTranslate2 #937
Replies: 18 comments 113 replies
-
|
|


Beta Was this translation helpful? Give feedback.
-
|
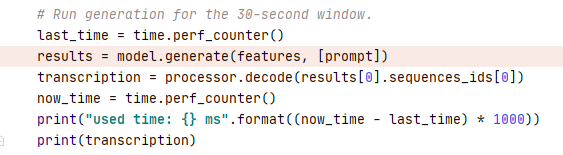
I'm using this audio, starting at about 43 seconds :https://www.youtube.com/watch?v=rOeRWRJ16yY |
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
Solved, thank you very much |
Beta Was this translation helpful? Give feedback.
-
|
Hello, I found some auditory hallucinations. Whisper didn't show up。 Whisper will also have the following hallucinations problem: |


Beta Was this translation helpful? Give feedback.
-
|
Hi Lingxiaoxue, you might find the answer in one of the issues of faster-whisper. I solved my problem with vad_filter=True.
|
Beta Was this translation helpful? Give feedback.
-
|
Do you have any templates/examples of how you would transcribe longer than 30s and does the |
Beta Was this translation helpful? Give feedback.
-
|
There was a small bug in the decoding code. Can you make sure you have the latest version |
Beta Was this translation helpful? Give feedback.
-
|
am using ctranslate2 version 3.5.1. |
Beta Was this translation helpful? Give feedback.
-
|
Is it possible for you to share the input audio file? |
Beta Was this translation helpful? Give feedback.
-
|
Sorry can't share audio as those are from my customers. Let me find audio which i can share |
Beta Was this translation helpful? Give feedback.
-
|
I suggest that you try again with the latest versions of Also note that the "large" model in openai/whisper is actually the new "large-v2" model. So you should make sure to use |
Beta Was this translation helpful? Give feedback.
-
|
Just ran into the following error trying to run this locally: |
Beta Was this translation helpful? Give feedback.
-
|
You probably need to update the |
Beta Was this translation helpful? Give feedback.
-
|
success, thank you! |
Beta Was this translation helpful? Give feedback.
-
Beta Was this translation helpful? Give feedback.
-
|
On Windows you currently get an error if you try to use the GPU. You can still use this project to run transcriptions on CPU which is also heavily optimized. But of course it will be much slower than the GPU. I will try to address this Windows limitation in the coming days. In the meantime, maybe WSL is a possible solution? https://learn.microsoft.com/en-us/windows/ai/directml/gpu-cuda-in-wsl |
Beta Was this translation helpful? Give feedback.
-
|
Good news! GPU execution on Windows is now working with the latest version of CTranslate2 ( You should install cuBLAS 11.x and cuDNN 8.x on the system and make sure to update the PATH environment variable accordingly. |
Beta Was this translation helpful? Give feedback.
-
|
Hi! Is there a way to convert the whisper weights that I have finetune on your code? Thanks. |
Beta Was this translation helpful? Give feedback.
-
|
Hi, I have not finetune with transformer framework, but i have a pt file. Can i convert from pt file in torch? Thank you. |
Beta Was this translation helpful? Give feedback.
-
|
Currently there is no direct way to convert a .pt Whisper model that is not coming from Transformers. |
Beta Was this translation helpful? Give feedback.
-
|
Hi @guillaumekln, Thank you for your reply, i have another question. Can i run faster-whisper with batch_size > 1 to make use of vram? |
Beta Was this translation helpful? Give feedback.
-
|
Hi, Currently faster-whisper implements the same algorithm as openai/whisper so there is no batch processing. |
Beta Was this translation helpful? Give feedback.
-
|
Hi, Thanks for your reply. |
Beta Was this translation helpful? Give feedback.
-
|
Hi, TypeError: WhisperModel.init() got an unexpected keyword argument 'num_workers' |
Beta Was this translation helpful? Give feedback.
-
|
Its working after taking latest. If num_workers =2 and am running on single GPU with 24 GB Memory, will it automatically do parellel processing. How can I initiate parellel processing. |
Beta Was this translation helpful? Give feedback.
-
|
It is explained in the docstring of this argument. You need to call However, this option is more useful for CPU execution than GPU execution. Even though each worker is using a different CUDA stream, you will most likely not see important gains on a single GPU. |
Beta Was this translation helpful? Give feedback.
-
I see this mentioned in doc-string. But how is it possible from the same process as i am trying to do the same using CPU, but i don't see any parallelization, does Python GIL not block other threads and allow only 1 thread to run for cpu computation. |
Beta Was this translation helpful? Give feedback.
-
FYI -> I am trying to do VAD filtering on single audio to generate mini audio batches & trying to execute those on model in parallel to achieve batch processing for even faster execution |
Beta Was this translation helpful? Give feedback.
-
|
The Python GIL is released when calling the model because it is fully running in C++ code. This enables parallelization from multiple Python threads. |
Beta Was this translation helpful? Give feedback.
-
|
I am using whisper large model and transcribe English as well as Spanish audios. What is best bean_size, compute_type and quantization parameters. Currently I am suing bean_size=5, compute_type =float16 and quantization = float 16 |
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
Will there be any impact on quality if we use compute_type as int8_float16 |
Beta Was this translation helpful? Give feedback.
-
|
In our experiments with the small model, we found that int8 quantization has almost no impact on quality. The WER score was only 0.1 lower. |
Beta Was this translation helpful? Give feedback.
-
|
with float16, missing some segments where voice is low. what other quantization or compute_type can give better results. Also, how can i use quantization as float 32 with whisper large model, I am getting error invalid choice float32 |
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
I worked on a new optimization to further reduce the memory usage (20 to 30% reduction) and slightly increase the execution speed. See the latest results in the Benchmark section of the README. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the workaround @guillaumekln . I'll give it a try during the weekend. Will report back. |
Beta Was this translation helpful? Give feedback.
-
|
With |
Beta Was this translation helpful? Give feedback.
-
|
@guillaumekln I am still having the RAM issue under colab but only with large-v2 model, here's my notebook. I am using latest code, with |
Beta Was this translation helpful? Give feedback.
-
|
When creating a transforms_converter = TransformersConverter(
model_name_or_path=f"openai/whisper-{model}",
copy_files=["tokenizer.json"],
load_as_float16=True,
)This parameter is automatically set when using the conversion script, but not when using the conversion API directly. |
Beta Was this translation helpful? Give feedback.
-
|
@guillaumekln Thanks so much, worked perfectly! |
Beta Was this translation helpful? Give feedback.
-
|
I encountered this error in GPU implementation. I hope you can help me. Could not load library libcudnn_ops_infer.so.8. Error: libcudnn_ops_infer.so.8: cannot open shared object file: No such file or directory |
Beta Was this translation helpful? Give feedback.
-
|
If the voice gets longer, he will lose the marker. |
Beta Was this translation helpful? Give feedback.
-
Yes. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you so much. I'm going to put a lot of money into running and see the final result, and then I'll give you feedback. But some of the punctuation marks are missing. I'll try it first. Thank you very much for your help. |
Beta Was this translation helpful? Give feedback.
-
|
Also found a serious problem, there are some words that are not our audio files, all in the last sentence? |
Beta Was this translation helpful? Give feedback.
-
|
That sounds like an issue with the Whisper model itself, not an issue with the faster-whisper implementation. |
Beta Was this translation helpful? Give feedback.
-
|
@guillaumekln First of all, thanks for this amazing library - it's an amazing improvement, and should really be the default implementation. I have a question on speaker separation. The audio files I'm working with have two speakers - one per stereo channel. How feasible would it be to process those files using faster-whisper? I can see you're mixing the audio to Mono to do the transcription, but I couldn't figure out from the code how you'd process two separate channels independently. |
Beta Was this translation helpful? Give feedback.
-
|
Can you check if something like this works? import av
import numpy as np
def decode_audio(input_file, sampling_rate=16000, split_stereo=False):
fifo = av.audio.fifo.AudioFifo()
resampler = av.audio.resampler.AudioResampler(
format="s16",
layout="stereo" if split_stereo else "mono",
rate=sampling_rate,
)
with av.open(input_file) as container:
# Decode and resample each audio frame.
for frame in container.decode(audio=0):
frame.pts = None
for new_frame in resampler.resample(frame):
fifo.write(new_frame)
# Flush the resampler.
for new_frame in resampler.resample(None):
fifo.write(new_frame)
frame = fifo.read()
# Convert s16 back to f32.
array = frame.to_ndarray().flatten().astype(np.float32) / 32768.0
if split_stereo:
left_channel = array[0::2]
right_channel = array[1::2]
return left_channel, right_channel
return array
left_audio, right_audio = decode_audio(audio_path, split_stereo=True)
# model.transcribe(left_audio)
# model.transcribe(right_audio)You need the latest commit of faster-whisper in order to directly pass the decoded audio to the |
Beta Was this translation helpful? Give feedback.
-
|
That works perfectly! Thanks |
Beta Was this translation helpful? Give feedback.
-
|
Is there an effective way to reorder the transcriptions from left audio and right audio so that we can reconstruct the full dialogue? |
Beta Was this translation helpful? Give feedback.
-
|
Did you try using the word-level timestamps returned with |
Beta Was this translation helpful? Give feedback.
-
|
Hello! Sorry for my bad english, it's not my native language. I'm a beginner in this language (py) and that's why I have some questions that may sound horrible. Today I already use How do I use your script in my native language (Portuguese)? I understood that I must run Again I apologize for such a lay question and my bad English. |
Beta Was this translation helpful? Give feedback.
-
|
Hi, At this time the faster-whisper project is just a Python library. It does not include command line tools. To run it from the command line you would need to define your own Python script as shown in the README. |
Beta Was this translation helpful? Give feedback.
-
|
This module was created recently which allows CLI access: https://github.com/jordimas/whisper-ctranslate2 |
Beta Was this translation helpful? Give feedback.
-
|
For command line Jordimas is the way. https://github.com/jordimas/whisper-ctranslate2 (Note that both of these projects use a different default beam size.) |
Beta Was this translation helpful? Give feedback.
-
|
The repository faster-whisper has been updated to support word-level timestamps! You can find a basic usage example in the README. |
Beta Was this translation helpful? Give feedback.
-
|
Sure! Here is a sample transcription. I am attaching the audio file as well. It is in Luxembourgish but setting the language as "German" works as well. Thanks in advance! Ctranslate2 version: Whisper library's version: |
Beta Was this translation helpful? Give feedback.
-
|
Thanks! Can you also specify the model size and transcription options you are using? I tried a few configurations but I was not able to reproduce this output. |
Beta Was this translation helpful? Give feedback.
-
|
You can actually use either the medium and large model. Here is some sample code for testing (the detected language is "de" and so the transcription text may be different from the above, but that is OK. You still get some filler words like "Oh!", even when you set the language to "en"): With Ctranslate2, I use the following code (same result without beam size or length penalty): |
Beta Was this translation helpful? Give feedback.
-
|
In openai/whisper, from faster_whisper import WhisperModel
model = WhisperModel(ct_model_path, device="cuda", compute_type="float16")
segments, info = model.transcribe(audio_file, beam_size=1) |
Beta Was this translation helpful? Give feedback.
-
|
Nice! That solved the issue. Thanks a lot! I tried other options earlier except beam_size=1. :-) Detected language 'de' with probability 0.462646 |
Beta Was this translation helpful? Give feedback.
-
|
Works amazing! I will move to use this on freesubtitles.ai , thanks for the great work! |
Beta Was this translation helpful? Give feedback.
-
|
I need your help now, encounter such a problem, I have such an audio, I am a dual-track voice, he is two people calling audio. How do I separate the results of his recognition by orbit. |
Beta Was this translation helpful? Give feedback.
-
|
What do you mean by orbit? In this release note https://github.com/guillaumekln/faster-whisper/releases/tag/v0.4.0 there is an example to separate stereo audio channels. |
Beta Was this translation helpful? Give feedback.
-
|
If I dismantle the mono and double channels, his recognition accuracy will be greatly reduced. If it is not dismantled, the recognition accuracy is relatively high. Is there any good way to identify it later? this can also speed up the recognition speed, because if it is dismantled, it will be identified twice, and if it is not dismantled, it will be enough. |
Beta Was this translation helpful? Give feedback.
-
|
Hi @guillaumekln , Because i use a custom model so that my model can not run an audio which is longer than 25s. Can I convert the weights from huggingface model to whisper-model and use CTranslate2 for my model to process on audio is longer than 25s. Thank you. |
Beta Was this translation helpful? Give feedback.
-
|
then convert huggingface -> faster whisper ctranslate2 and directly use faster whisper why openai whisper as an useless intermediary step ? |
Beta Was this translation helpful? Give feedback.
-
|
Hi @phineas-pta , Sorry for the late reply. Since the huggingface-model (the model I have finetuned) can only predict on audio files shorter than 30s, I want to convert the weights of the huggingface-model to the whisper-model to take advantage of whisper's framework to handle audio files longer than 30s. Then i can convert from this whisper-model to faster whisper for faster processing. |
Beta Was this translation helpful? Give feedback.
-
|
i think you misunderstand something about the 30s limit for training/fine-tuning programmers have to manually split audio to 30s chunks but for inferencing, splitting is automatically done by the backend/implementation you're using (original openai, ctranslate2 faster-whisper, huggingface transformers, ggml whisper.cpp, etc.) so, except if you want to write a completely new implementation (for e.g. nvidia tensorrt), you don't have to bother about the 30s limit when using it |
Beta Was this translation helpful? Give feedback.
-
|
Thank you for your reply, i understood this problem! When i predict with a audio longer than 30s i get this warning:
Does it have any troubles on my result? |
Beta Was this translation helpful? Give feedback.
-
|
how did you get that warning ? i never saw that in all 4 backends i mentioned anyway i think it was trying to calculate audio length so not much a problem |
Beta Was this translation helpful? Give feedback.
-
|
I am new to this stuffs... Please help me with this error. I donnot understand what this means? |


Beta Was this translation helpful? Give feedback.
-
|
use |
Beta Was this translation helpful? Give feedback.
-
|
I have finetuned the Whisper small model for specific use case, and I have also quantized it for faster transcription using
Is there any way to enhance the transcription speed for a 10-second audio on CPU? |
Beta Was this translation helpful? Give feedback.
-
|
Did you quantize model to "int8_float32"? |
Beta Was this translation helpful? Give feedback.
-
|
thanks @Purfview |
Beta Was this translation helpful? Give feedback.
-
|
hi @Purfview and for this segment it took 30 seconds and same for this segment (time- 28 seconds) Is there any way to reduce this delay? |
Beta Was this translation helpful? Give feedback.
-
|
It's because of fallback, you can disable it with |
Beta Was this translation helpful? Give feedback.
-
|
can i use it to text2text |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
Hello,
We integrated the Whisper model in CTranslate2, which is a fast inference engine for Transformer models. The project implements many useful inference features such as optimized CPU and GPU execution, asynchronous execution, multi-GPU execution, 8-bit quantization, etc.
The library only implements the decoding part (equivalent to
model.decodehere), but you can find a possible implementation of the full transcription logic in this repository:https://github.com/guillaumekln/faster-whisper
For example, here's the transcription time of 13 minutes of audio on a V100 for the same accuracy:
Hopefully this can be useful to some of you!
Feel free to ask questions here.
Best,
Guillaume
Beta Was this translation helpful? Give feedback.
All reactions