diff --git a/notebooks/qwen3-omni-chatbot/README.md b/notebooks/qwen3-omni-chatbot/README.md
new file mode 100644
index 00000000000..ab4a729e96d
--- /dev/null
+++ b/notebooks/qwen3-omni-chatbot/README.md
@@ -0,0 +1,42 @@
+# Omnimodal assistant with Qwen3-Omni and OpenVINO
+
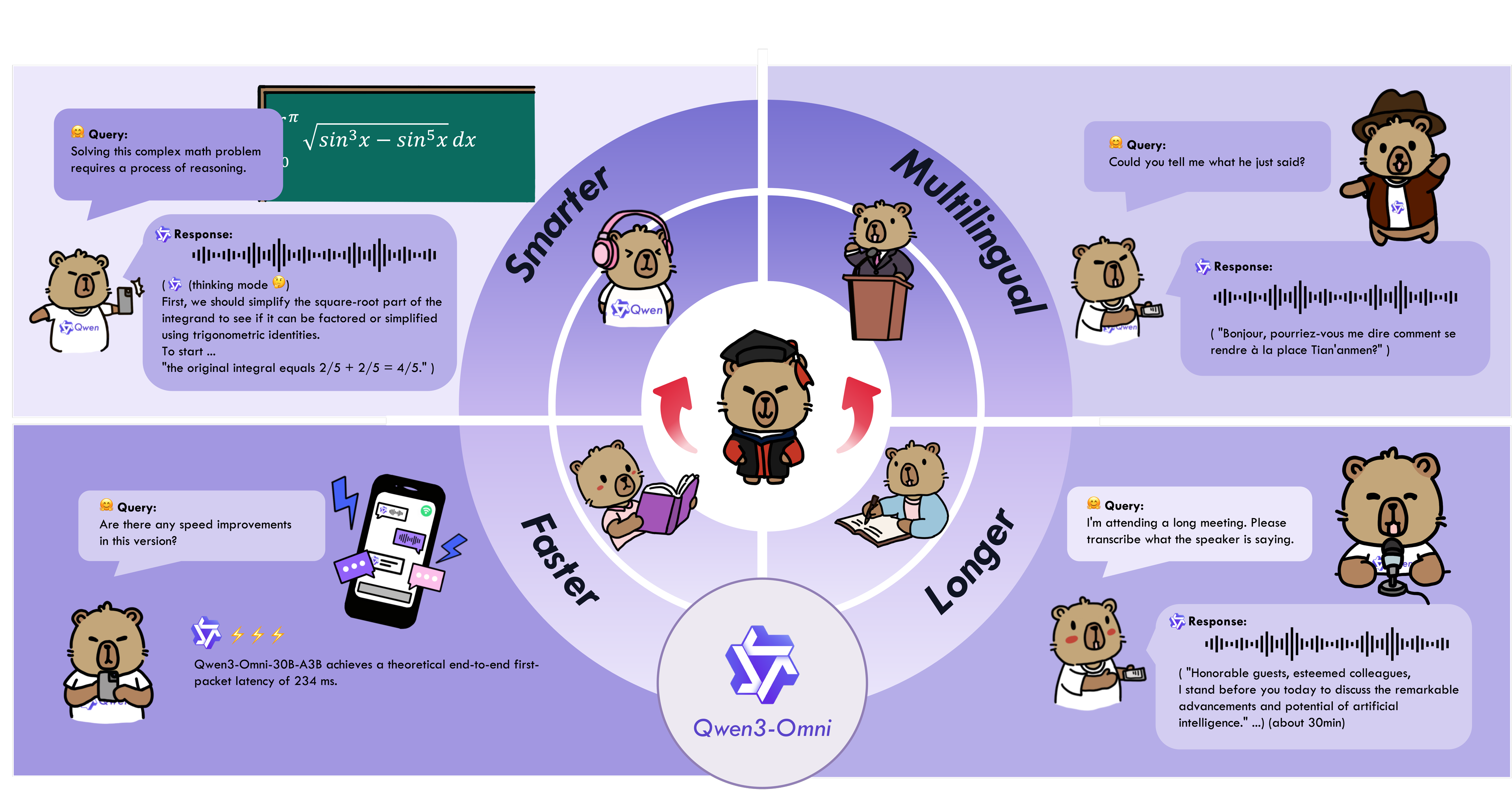
+Qwen3-Omni is the natively end-to-end multilingual omni-modal foundation models. It processes text, images, audio, and video, and delivers real-time streaming responses in both text and natural speech. We introduce several architectural upgrades to improve performance and efficiency. Key features:
+
+* **State-of-the-art across modalities**: Early text-first pretraining and mixed multimodal training provide native multimodal support. While achieving strong audio and audio-video results, unimodal text and image performance does not regress. Reaches SOTA on 22 of 36 audio/video benchmarks and open-source SOTA on 32 of 36; ASR, audio understanding, and voice conversation performance is comparable to Gemini 2.5 Pro.
+
+* **Multilingual**: Supports 119 text languages, 19 speech input languages, and 10 speech output languages.
+ - **Speech Input**: English, Chinese, Korean, Japanese, German, Russian, Italian, French, Spanish, Portuguese, Malay, Dutch, Indonesian, Turkish, Vietnamese, Cantonese, Arabic, Urdu.
+ - **Speech Output**: English, Chinese, French, German, Russian, Italian, Spanish, Portuguese, Japanese, Korean.
+
+* **Novel Architecture**: MoE-based Thinker–Talker design with AuT pretraining for strong general representations, plus a multi-codebook design that drives latency to a minimum.
+
+* **Real-time Audio/Video Interaction**: Low-latency streaming with natural turn-taking and immediate text or speech responses.
+
+* **Flexible Control**: Customize behavior via system prompts for fine-grained control and easy adaptation.
+
+* **Detailed Audio Captioner**: Qwen3-Omni-30B-A3B-Captioner is now open source: a general-purpose, highly detailed, low-hallucination audio captioning model that fills a critical gap in the open-source community.
+
+
+  +
+
+
+More details about model can be found in [model card](https://huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Instruct) and original [repo](https://github.com/QwenLM/Qwen3-Omni/tree/main).
+
+## Notebook contents
+The tutorial consists from following steps:
+
+- Install requirements
+- Download PyTorch model
+- Convert model to OpenVINO Intermediate Representation (IR)
+- Compress Language Model weights
+- Run OpenVINO model inference
+- Launch Interactive demo
+
+In this demonstration, you'll create interactive chatbot that can answer questions about provided image's content. Image bellow shows a result of model work.
+
+
+
+## Installation instructions
+This is a self-contained example that relies solely on its own code.
+We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.
+For details, please refer to [Installation Guide](../../README.md).
diff --git a/notebooks/qwen3-omni-chatbot/qwen3-omni-chatbot.ipynb b/notebooks/qwen3-omni-chatbot/qwen3-omni-chatbot.ipynb
new file mode 100644
index 00000000000..e5e630d2246
--- /dev/null
+++ b/notebooks/qwen3-omni-chatbot/qwen3-omni-chatbot.ipynb
@@ -0,0 +1,915 @@
+{
+ "cells": [
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "5918b41c-dad7-4f7b-9e39-b3026933dddf",
+ "metadata": {},
+ "source": [
+ "# Omnimodal assistant with Qwen3-Omni and OpenVINO\n",
+ "\n",
+ "Qwen3-Omni is the natively end-to-end multilingual omni-modal foundation models. It processes text, images, audio, and video, and delivers real-time streaming responses in both text and natural speech. We introduce several architectural upgrades to improve performance and efficiency. Key features:\n",
+ "\n",
+ "* **State-of-the-art across modalities**: Early text-first pretraining and mixed multimodal training provide native multimodal support. While achieving strong audio and audio-video results, unimodal text and image performance does not regress. Reaches SOTA on 22 of 36 audio/video benchmarks and open-source SOTA on 32 of 36; ASR, audio understanding, and voice conversation performance is comparable to Gemini 2.5 Pro.\n",
+ "\n",
+ "* **Multilingual**: Supports 119 text languages, 19 speech input languages, and 10 speech output languages.\n",
+ " - **Speech Input**: English, Chinese, Korean, Japanese, German, Russian, Italian, French, Spanish, Portuguese, Malay, Dutch, Indonesian, Turkish, Vietnamese, Cantonese, Arabic, Urdu.\n",
+ " - **Speech Output**: English, Chinese, French, German, Russian, Italian, Spanish, Portuguese, Japanese, Korean.\n",
+ "\n",
+ "* **Novel Architecture**: MoE-based Thinker–Talker design with AuT pretraining for strong general representations, plus a multi-codebook design that drives latency to a minimum.\n",
+ "\n",
+ "* **Real-time Audio/Video Interaction**: Low-latency streaming with natural turn-taking and immediate text or speech responses.\n",
+ "\n",
+ "* **Flexible Control**: Customize behavior via system prompts for fine-grained control and easy adaptation.\n",
+ "\n",
+ "* **Detailed Audio Captioner**: Qwen3-Omni-30B-A3B-Captioner is now open source: a general-purpose, highly detailed, low-hallucination audio captioning model that fills a critical gap in the open-source community.\n",
+ "\n",
+ "
\n",
+ "  \n",
+ "
\n",
+ "
\n",
+ "\n",
+ "More details about model can be found in [model card](https://huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Instruct) and original [repo](https://github.com/QwenLM/Qwen3-Omni/tree/main).\n",
+ "\n",
+ "In this tutorial we consider how to convert and optimize Qwen3-Omni model for creating omnimodal chatbot. Additionally, we demonstrate how to apply stateful transformation on LLM part and model optimization techniques like weights compression using [NNCF](https://github.com/openvinotoolkit/nncf)\n",
+ "\n",
+ "#### Table of contents:\n",
+ "\n",
+ "- [Prerequisites](#Prerequisites)\n",
+ "- [Convert model to OpenVINO Intermediate Representation](#Convert-model-to-OpenVINO-Intermediate-Representation)\n",
+ " - [Compress Language Model Weights to 4 bits](#Compress-Language-Model-Weights-to-4-bits)\n",
+ "- [Prepare model inference pipeline](#Prepare-model-inference-pipeline)\n",
+ " - [Select device](#Select-device)\n",
+ " - [Initialize model tasks](#Initialize-model-tasks)\n",
+ "- [Run OpenVINO model inference](#Run-OpenVINO-model-inference)\n",
+ " - [Text-only input and Audio output](#Text-only-input-and-Audio-output)\n",
+ " - [Text-Image input](#Text-Image-input)\n",
+ " - [Audio-Text input](#Audio-Text-input)\n",
+ " - [Video-text input](#Video-text-input)\n",
+ "- [Interactive demo](#Interactive-demo)\n",
+ "\n",
+ "\n",
+ "### Installation Instructions\n",
+ "\n",
+ "This is a self-contained example that relies solely on its own code.\n",
+ "\n",
+ "We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.\n",
+ "For details, please refer to [Installation Guide](https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/README.md#-installation-guide).\n"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "8ff80f4e-08df-4bcd-a72a-4f77bdd5768b",
+ "metadata": {},
+ "source": [
+ "## Prerequisites\n",
+ "[back to top ⬆️](#Table-of-contents:)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "1534e378-1b87-4f1b-94e8-09061e960700",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Requirement already satisfied: openvino>=2026.0.0 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (2026.0.0)\n",
+ "Requirement already satisfied: nncf>=2.18.0 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (2.19.0)\n",
+ "Requirement already satisfied: numpy<2.5.0,>=1.16.6 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from openvino>=2026.0.0) (1.26.4)\n",
+ "Requirement already satisfied: openvino-telemetry>=2023.2.1 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from openvino>=2026.0.0) (2025.2.0)\n",
+ "Requirement already satisfied: jsonschema>=3.2.0 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from nncf>=2.18.0) (4.26.0)\n",
+ "Requirement already satisfied: natsort>=7.1.0 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from nncf>=2.18.0) (8.4.0)\n",
+ "Requirement already satisfied: networkx<3.5.0,>=2.6 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from nncf>=2.18.0) (3.4.2)\n",
+ "Requirement already satisfied: ninja<1.14,>=1.10.0.post2 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from nncf>=2.18.0) (1.13.0)\n",
+ "Requirement already satisfied: packaging>=20.0 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from nncf>=2.18.0) (25.0)\n",
+ "Requirement already satisfied: pandas<2.4,>=1.1.5 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from nncf>=2.18.0) (2.3.3)\n",
+ "Requirement already satisfied: psutil in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from nncf>=2.18.0) (7.2.1)\n",
+ "Requirement already satisfied: pydot<=3.0.4,>=1.4.1 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from nncf>=2.18.0) (3.0.4)\n",
+ "Requirement already satisfied: pymoo>=0.6.0.1 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from nncf>=2.18.0) (0.6.1.6)\n",
+ "Requirement already satisfied: rich>=13.5.2 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from nncf>=2.18.0) (14.2.0)\n",
+ "Requirement already satisfied: safetensors>=0.4.1 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from nncf>=2.18.0) (0.7.0)\n",
+ "Requirement already satisfied: scikit-learn>=0.24.0 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from nncf>=2.18.0) (1.7.2)\n",
+ "Requirement already satisfied: scipy>=1.3.2 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from nncf>=2.18.0) (1.15.3)\n",
+ "Requirement already satisfied: tabulate>=0.9.0 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from nncf>=2.18.0) (0.9.0)\n",
+ "Requirement already satisfied: python-dateutil>=2.8.2 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from pandas<2.4,>=1.1.5->nncf>=2.18.0) (2.9.0.post0)\n",
+ "Requirement already satisfied: pytz>=2020.1 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from pandas<2.4,>=1.1.5->nncf>=2.18.0) (2025.2)\n",
+ "Requirement already satisfied: tzdata>=2022.7 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from pandas<2.4,>=1.1.5->nncf>=2.18.0) (2025.3)\n",
+ "Requirement already satisfied: pyparsing>=3.0.9 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from pydot<=3.0.4,>=1.4.1->nncf>=2.18.0) (3.3.1)\n",
+ "Requirement already satisfied: attrs>=22.2.0 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from jsonschema>=3.2.0->nncf>=2.18.0) (25.4.0)\n",
+ "Requirement already satisfied: jsonschema-specifications>=2023.03.6 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from jsonschema>=3.2.0->nncf>=2.18.0) (2025.9.1)\n",
+ "Requirement already satisfied: referencing>=0.28.4 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from jsonschema>=3.2.0->nncf>=2.18.0) (0.37.0)\n",
+ "Requirement already satisfied: rpds-py>=0.25.0 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from jsonschema>=3.2.0->nncf>=2.18.0) (0.30.0)\n",
+ "Requirement already satisfied: moocore>=0.1.7 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from pymoo>=0.6.0.1->nncf>=2.18.0) (0.2.0)\n",
+ "Requirement already satisfied: autograd>=1.4 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from pymoo>=0.6.0.1->nncf>=2.18.0) (1.8.0)\n",
+ "Requirement already satisfied: cma>=3.2.2 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from pymoo>=0.6.0.1->nncf>=2.18.0) (4.4.1)\n",
+ "Requirement already satisfied: matplotlib>=3 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from pymoo>=0.6.0.1->nncf>=2.18.0) (3.10.7)\n",
+ "Requirement already satisfied: alive_progress in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from pymoo>=0.6.0.1->nncf>=2.18.0) (3.3.0)\n",
+ "Requirement already satisfied: Deprecated in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from pymoo>=0.6.0.1->nncf>=2.18.0) (1.3.1)\n",
+ "Requirement already satisfied: contourpy>=1.0.1 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from matplotlib>=3->pymoo>=0.6.0.1->nncf>=2.18.0) (1.3.2)\n",
+ "Requirement already satisfied: cycler>=0.10 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from matplotlib>=3->pymoo>=0.6.0.1->nncf>=2.18.0) (0.12.1)\n",
+ "Requirement already satisfied: fonttools>=4.22.0 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from matplotlib>=3->pymoo>=0.6.0.1->nncf>=2.18.0) (4.61.1)\n",
+ "Requirement already satisfied: kiwisolver>=1.3.1 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from matplotlib>=3->pymoo>=0.6.0.1->nncf>=2.18.0) (1.4.9)\n",
+ "Requirement already satisfied: pillow>=8 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from matplotlib>=3->pymoo>=0.6.0.1->nncf>=2.18.0) (10.4.0)\n",
+ "Requirement already satisfied: cffi>=1.17.1 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from moocore>=0.1.7->pymoo>=0.6.0.1->nncf>=2.18.0) (2.0.0)\n",
+ "Requirement already satisfied: platformdirs in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from moocore>=0.1.7->pymoo>=0.6.0.1->nncf>=2.18.0) (4.5.1)\n",
+ "Requirement already satisfied: pycparser in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from cffi>=1.17.1->moocore>=0.1.7->pymoo>=0.6.0.1->nncf>=2.18.0) (2.23)\n",
+ "Requirement already satisfied: six>=1.5 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from python-dateutil>=2.8.2->pandas<2.4,>=1.1.5->nncf>=2.18.0) (1.17.0)\n",
+ "Requirement already satisfied: typing-extensions>=4.4.0 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from referencing>=0.28.4->jsonschema>=3.2.0->nncf>=2.18.0) (4.15.0)\n",
+ "Requirement already satisfied: markdown-it-py>=2.2.0 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from rich>=13.5.2->nncf>=2.18.0) (4.0.0)\n",
+ "Requirement already satisfied: pygments<3.0.0,>=2.13.0 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from rich>=13.5.2->nncf>=2.18.0) (2.19.2)\n",
+ "Requirement already satisfied: mdurl~=0.1 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from markdown-it-py>=2.2.0->rich>=13.5.2->nncf>=2.18.0) (0.1.2)\n",
+ "Requirement already satisfied: joblib>=1.2.0 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from scikit-learn>=0.24.0->nncf>=2.18.0) (1.5.3)\n",
+ "Requirement already satisfied: threadpoolctl>=3.1.0 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from scikit-learn>=0.24.0->nncf>=2.18.0) (3.6.0)\n",
+ "Requirement already satisfied: about-time==4.2.1 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from alive_progress->pymoo>=0.6.0.1->nncf>=2.18.0) (4.2.1)\n",
+ "Requirement already satisfied: graphemeu==0.7.2 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from alive_progress->pymoo>=0.6.0.1->nncf>=2.18.0) (0.7.2)\n",
+ "Requirement already satisfied: wrapt<3,>=1.10 in /home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages (from Deprecated->pymoo>=0.6.0.1->nncf>=2.18.0) (2.0.1)\n"
+ ]
+ }
+ ],
+ "source": [
+ "import requests\n",
+ "from pathlib import Path\n",
+ "import sys\n",
+ "\n",
+ "\n",
+ "if not Path(\"qwen_3_omni_moe_helper.py\").exists():\n",
+ " r = requests.get(url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/qwen3-omni-chatbot/qwen_3_omni_moe_helper.py\")\n",
+ " open(\"qwen_3_omni_moe_helper.py\", \"w\").write(r.text)\n",
+ "\n",
+ "\n",
+ "if not Path(\"gradio_helper.py\").exists():\n",
+ " r = requests.get(url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/qwen3-omni-chatbot/gradio_helper.py\")\n",
+ " open(\"gradio_helper.py\", \"w\").write(r.text)\n",
+ "\n",
+ "if not Path(\"notebook_utils.py\").exists():\n",
+ " r = requests.get(url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py\")\n",
+ " open(\"notebook_utils.py\", \"w\").write(r.text)\n",
+ "\n",
+ "if not Path(\"pip_helper.py\").exists():\n",
+ " r = requests.get(\n",
+ " url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/pip_helper.py\",\n",
+ " )\n",
+ " open(\"pip_helper.py\", \"w\").write(r.text)\n",
+ "\n",
+ "from pip_helper import pip_install\n",
+ "\n",
+ "pip_install(\n",
+ " \"-q\",\n",
+ " \"transformers==4.57.0\",\n",
+ " \"torch==2.8\",\n",
+ " \"torchvision==0.23.0\",\n",
+ " \"accelerate\",\n",
+ " \"gradio>=4.19\",\n",
+ " \"--no-cache-dir\",\n",
+ " \"--extra-index-url\",\n",
+ " \"https://download.pytorch.org/whl/cpu\",\n",
+ ")\n",
+ " \n",
+ "pip_install(\"-Uq\", \"qwen-omni-utils\")\n",
+ "pip_install(\"openvino>=2026.0.0\", \"nncf>=2.18.0\")\n",
+ "\n",
+ "# Read more about telemetry collection at https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-telemetry\n",
+ "from notebook_utils import collect_telemetry\n",
+ "\n",
+ "collect_telemetry(\"qwen3-omni-chatbot.ipynb\")"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "539aae31-dded-4036-8946-67a4ec9e6034",
+ "metadata": {},
+ "source": [
+ "## Convert model to OpenVINO Intermediate Representation\n",
+ "[back to top ⬆️](#Table-of-contents:)\n",
+ "\n",
+ "OpenVINO supports PyTorch models via conversion to OpenVINO Intermediate Representation (IR). [OpenVINO model conversion API](https://docs.openvino.ai/2024/openvino-workflow/model-preparation.html#convert-a-model-with-python-convert-model) should be used for these purposes. `ov.convert_model` function accepts original PyTorch model instance and example input for tracing and returns `ov.Model` representing this model in OpenVINO framework. Converted model can be used for saving on disk using `ov.save_model` function or directly loading on device using `core.complie_model`.\n",
+ "\n",
+ "`qwen_3_omni_moe_helper.py` script contains helper function for model conversion, please check its content if you interested in conversion details.\n",
+ "\n",
+ "### Qwen3-Omni-MoE Architecture Overview\n",
+ "\n",
+ "**Qwen3-Omni-MoE** is a multimodal Mixture-of-Experts (MoE) model capable of processing text, images, video, and audio inputs, and generating both text and speech outputs. The architecture consists of two main components: **Thinker** and **Talker**.\n",
+ "\n",
+ "#### 1. Thinker (Understanding Module)\n",
+ "\n",
+ "The Thinker is responsible for understanding multimodal inputs and generating semantic representations.\n",
+ "\n",
+ "**Sub-models:**\n",
+ "\n",
+ "- **Thinker Audio Encoder**: Processes audio features through convolutional layers (conv2d1, conv2d2, conv2d3) and extracts audio embeddings\n",
+ "- **Thinker Vision Encoder**: Processes images/videos using Vision Transformer with rotary positional embeddings (Qwen2-VL style)\n",
+ "- **Thinker Vision Positional Encoder**: Computes 3D rope indices for spatial-temporal features\n",
+ "- **Thinker Vision Merger**: Merges multi-scale visual features using spatial merge strategy\n",
+ "- **Thinker Embedding**: Text token embeddings for language input\n",
+ "- **Thinker Language Model**: MoE-based decoder with sparse experts (Qwen3MoeThinkerTextExperts) that processes fused multimodal embeddings and generates hidden states\n",
+ "- **Thinker Patcher/Merger**: Combines text, audio, and visual embeddings with DeepStack visual features across layers\n",
+ "\n",
+ "#### 2. Talker (Speech Generation Module)\n",
+ "\n",
+ "The Talker generates speech outputs from the Thinker's representations.\n",
+ "\n",
+ "**Sub-models:**\n",
+ "\n",
+ "- **Talker Embedding**: Converts input tokens to embeddings\n",
+ "- **Talker Hidden Projection**: Projects Thinker's hidden states to Talker's hidden space\n",
+ "- **Talker Text Projection**: Additional projection layer for text features\n",
+ "- **Talker Language Model**: MoE decoder (Qwen3MoeTalkerTextExperts) that processes projected features and generates codec predictions\n",
+ "- **Talker Code Predictor**: Predicts audio codec codes for speech synthesis (with separate embedding and decoder)\n",
+ "\n",
+ "#### 3. Code2Wav Module\n",
+ "\n",
+ "Converts predicted audio codes into waveform audio output (vocoder).\n",
+ "\n",
+ "Let's convert each model part."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "id": "840d08db",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "7104335cadc545ada68144104792f54b",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "Dropdown(description='Model:', options=('Qwen/Qwen3-Omni-30B-A3B-Instruct', 'Qwen/Qwen3-Omni-30B-A3B-Thinking'…"
+ ]
+ },
+ "execution_count": 2,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "import ipywidgets as widgets\n",
+ "\n",
+ "model_ids = [\"Qwen/Qwen3-Omni-30B-A3B-Instruct\", \"Qwen/Qwen3-Omni-30B-A3B-Thinking\"]\n",
+ "\n",
+ "model_id = widgets.Dropdown(\n",
+ " options=model_ids,\n",
+ " default=model_ids[0],\n",
+ " description=\"Model:\",\n",
+ ")\n",
+ "\n",
+ "model_id"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "ff007127-7421-448e-9668-b3fdb32eca51",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_id = model_id.value\n",
+ "model_dir = Path(model_id.split(\"/\")[-1])"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "82f37188-7434-4dc9-ba3c-a9779cd4cdc8",
+ "metadata": {},
+ "source": [
+ "### Compress Thinker Model Weights to 4 bits\n",
+ "[back to top ⬆️](#Table-of-contents:)\n",
+ "\n",
+ "For reducing memory consumption, weights compression optimization can be applied using [NNCF](https://github.com/openvinotoolkit/nncf). \n",
+ "\n",
+ "\n",
+ " Click here for more details about weight compression
\n",
+ "Weight compression aims to reduce the memory footprint of a model. It can also lead to significant performance improvement for large memory-bound models, such as Large Language Models (LLMs). LLMs and other models, which require extensive memory to store the weights during inference, can benefit from weight compression in the following ways:\n",
+ "\n",
+ "* enabling the inference of exceptionally large models that cannot be accommodated in the memory of the device;\n",
+ "\n",
+ "* improving the inference performance of the models by reducing the latency of the memory access when computing the operations with weights, for example, Linear layers.\n",
+ "\n",
+ "[Neural Network Compression Framework (NNCF)](https://github.com/openvinotoolkit/nncf) provides 4-bit / 8-bit mixed weight quantization as a compression method primarily designed to optimize LLMs. The main difference between weights compression and full model quantization (post-training quantization) is that activations remain floating-point in the case of weights compression which leads to a better accuracy. Weight compression for LLMs provides a solid inference performance improvement which is on par with the performance of the full model quantization. In addition, weight compression is data-free and does not require a calibration dataset, making it easy to use.\n",
+ "\n",
+ "`nncf.compress_weights` function can be used for performing weights compression. The function accepts an OpenVINO model and other compression parameters. Compared to INT8 compression, INT4 compression improves performance even more, but introduces a minor drop in prediction quality.\n",
+ "\n",
+ "More details about weights compression, can be found in [OpenVINO documentation](https://docs.openvino.ai/2024/openvino-workflow/model-optimization-guide/weight-compression.html).\n",
+ "\n",
+ " \n",
+ "\n",
+ "> **Note:** weights compression process may require additional time and memory for performing. You can disable it using widget below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "6e938ae8-7e49-4c61-88b9-0b73c8fa8407",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "⌛ Qwen/Qwen3-Omni-30B-A3B-Instruct conversion started. Be patient, it may takes some time.\n",
+ "⌛ Load Original model\n"
+ ]
+ },
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "Unrecognized keys in `rope_scaling` for 'rope_type'='default': {'interleaved', 'mrope_interleaved', 'mrope_section'}\n",
+ "Unrecognized keys in `rope_scaling` for 'rope_type'='default': {'interleaved', 'mrope_section'}\n"
+ ]
+ },
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "1445c5204fc543cdac01d19d5ca77ecd",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "Loading checkpoint shards: 0%| | 0/15 [00:00\n"
+ ],
+ "text/plain": []
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "INFO:nncf:Statistics of the bitwidth distribution:\n",
+ "┍━━━━━━━━━━━━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┑\n",
+ "│ Weight compression mode │ % all parameters (layers) │ % ratio-defining parameters (layers) │\n",
+ "┝━━━━━━━━━━━━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┥\n",
+ "│ int8_asym, per-channel │ 21% (3805 / 18673) │ 20% (3804 / 18672) │\n",
+ "├───────────────────────────┼─────────────────────────────┼────────────────────────────────────────┤\n",
+ "│ int4_asym, group size 128 │ 79% (14868 / 18673) │ 80% (14868 / 18672) │\n",
+ "┕━━━━━━━━━━━━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┙\n"
+ ]
+ },
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "55d3440b65e94898ad9831ed341212de",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "Output()"
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ },
+ {
+ "data": {
+ "text/html": [
+ "
\n"
+ ],
+ "text/plain": []
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "✅ Weights compression finished\n",
+ "✅ Thinker model conversion finished. You can find results in Qwen3-Omni-30B-A3B-Instruct\n",
+ "⌛ Convert talker embedding model\n",
+ "✅ Talker embedding model successfully converted\n",
+ "⌛ Convert talker hidden_projection model\n",
+ "✅ Talker hidden_projection model successfully converted\n",
+ "⌛ Convert talker text_projection model\n",
+ "✅ Talker text_projection model successfully converted\n",
+ "⌛ Convert Talker Language model (MoE)\n"
+ ]
+ },
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "/home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages/transformers/models/qwen3_omni_moe/modeling_qwen3_omni_moe.py:2901: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!\n",
+ " if position_ids.ndim == 3 and position_ids.shape[0] == 4:\n"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "✅ Talker language model (MoE) successfully converted\n",
+ "✅ Talker model conversion finished. You can find results in Qwen3-Omni-30B-A3B-Instruct\n",
+ "⌛ Convert talker code predictor embedding model\n",
+ "✅ Talker Code Predictor Embedding model successfully converted\n",
+ "⌛ Convert Talker Code Predictor model\n",
+ "✅ Talker Code Predictor model successfully converted\n",
+ "✅ Talker Code Predictor model conversion finished. You can find results in Qwen3-Omni-30B-A3B-Instruct\n",
+ "⌛ Convert code2wav model\n"
+ ]
+ },
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "/home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages/transformers/models/qwen3_omni_moe/modeling_qwen3_omni_moe.py:3739: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!\n",
+ " if codes.shape[1] != self.config.num_quantizers:\n",
+ "/home/ethan/intel/openvino_notebooks/py_env/lib/python3.10/site-packages/transformers/masking_utils.py:738: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!\n",
+ " if batch_size != position_ids.shape[0]:\n",
+ "/home/ethan/intel/openvino_notebooks/notebooks/qwen3-omni-chatbot/qwen_3_omni_moe_helper.py:56: TracerWarning: torch.tensor results are registered as constants in the trace. You can safely ignore this warning if you use this function to create tensors out of constant variables that would be the same every time you call this function. In any other case, this might cause the trace to be incorrect.\n",
+ " ideal_length = (torch.ceil(torch.tensor(n_frames)).to(torch.int64) - 1) * self.stride + (self.kernel_size - self.padding)\n",
+ "/home/ethan/intel/openvino_notebooks/notebooks/qwen3-omni-chatbot/qwen_3_omni_moe_helper.py:56: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.detach().clone() or sourceTensor.detach().clone().requires_grad_(True), rather than torch.tensor(sourceTensor).\n",
+ " ideal_length = (torch.ceil(torch.tensor(n_frames)).to(torch.int64) - 1) * self.stride + (self.kernel_size - self.padding)\n"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "✅ Code2Wav model successfully converted\n",
+ "✅ Qwen/Qwen3-Omni-30B-A3B-Instruct model conversion finished. You can find results in Qwen3-Omni-30B-A3B-Instruct\n"
+ ]
+ }
+ ],
+ "source": [
+ "import nncf\n",
+ "from qwen_3_omni_moe_helper import convert_qwen3_omni_moe_model\n",
+ "\n",
+ "compression_configuration = {\n",
+ " \"mode\": nncf.CompressWeightsMode.INT4_ASYM,\n",
+ " \"group_size\": 128,\n",
+ " \"ratio\": 0.8,\n",
+ "}\n",
+ "\n",
+ "convert_qwen3_omni_moe_model(model_id, model_dir, compression_configuration)"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "43855dca-3ef2-4cea-8fc2-3700f769dd06",
+ "metadata": {},
+ "source": [
+ "## Prepare model inference pipeline\n",
+ "[back to top ⬆️](#Table-of-contents:)\n",
+ "\n",
+ "As discussed, the Qwen3-Omni-MoE model comprises multiple specialized components including Vision Encoder, Audio Encoder, Thinker (understanding module), Talker (speech generation module), and Code2Wav vocoder. In `qwen_3_omni_moe_helper.py` we defined the Thinker inference class `OVQwen3OmniMoeThinkerForConditionalGeneration`, the Talker inference class `OVQwen3OmniMoeTalkerForConditionalGeneration`, and the Talker Code Predictor class `OVQwen3OmniMoeTalkerCodePredictorModelForConditionalGeneration` that represent the generation cycle. These classes are based on [HuggingFace Transformers `GenerationMixin`](https://huggingface.co/docs/transformers/main_classes/text_generation) and look similar to [Optimum Intel](https://huggingface.co/docs/optimum/intel/index) `OVModelForCausalLM` used for LLM inference, with the key difference that they can accept multimodal input embeddings and support MoE architecture. The general multimodal model class `OVQwen3OmniMoeModel` orchestrates the entire pipeline, handling multimodal input processing (text, image, video, audio) and generating both text and speech outputs."
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "06eada4a-cac9-4501-bed0-059c4e585d57",
+ "metadata": {},
+ "source": [
+ "### Select device\n",
+ "[back to top ⬆️](#Table-of-contents:)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "e56db20f-7cf0-4ead-b6af-8e048e61b059",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "fd59e3e961eb409a9f46c5b447d3359f",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "Dropdown(description='Thinker device', options=('CPU', 'AUTO'), value='CPU')"
+ ]
+ },
+ "execution_count": 6,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "from notebook_utils import device_widget\n",
+ "\n",
+ "thinker_device = device_widget(default=\"CPU\", exclude=[\"NPU\"], description=\"Thinker device\")\n",
+ "\n",
+ "thinker_device"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "1d5d9f46-4d35-444e-ac46-cef1cf70bb0c",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "ac5adb59a32143ce9868904709c00413",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "Dropdown(description='Talker device', options=('CPU', 'AUTO'), value='CPU')"
+ ]
+ },
+ "execution_count": 7,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "talker_device = device_widget(default=\"CPU\", exclude=[\"NPU\"], description=\"Talker device\")\n",
+ "\n",
+ "talker_device"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "89a32bac-4b33-4bbb-abc6-3ea8b4ef60e7",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "f10d0b7fd996426db89faaf8100a9d20",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "Dropdown(description='Code2Wav device', options=('CPU', 'AUTO'), value='CPU')"
+ ]
+ },
+ "execution_count": 8,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "code2wav_device = device_widget(default=\"CPU\", exclude=[\"NPU\"], description=\"Code2Wav device\")\n",
+ "\n",
+ "code2wav_device"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "523fdc7d-7c4c-4f91-9c48-42fc2e39210a",
+ "metadata": {},
+ "source": [
+ "### Initialize model tasks\n",
+ "[back to top ⬆️](#Table-of-contents:)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "8d1cbb31",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "Unrecognized keys in `rope_scaling` for 'rope_type'='default': {'interleaved', 'mrope_interleaved', 'mrope_section'}\n",
+ "Unrecognized keys in `rope_scaling` for 'rope_type'='default': {'interleaved', 'mrope_section'}\n"
+ ]
+ }
+ ],
+ "source": [
+ "from transformers import Qwen3OmniMoeProcessor\n",
+ "from qwen_3_omni_moe_helper import OVQwen3OmniMoeModel\n",
+ "\n",
+ "ov_model = OVQwen3OmniMoeModel(model_dir, thinker_device=thinker_device.value, talker_device=talker_device.value, code2wav_device=code2wav_device.value)\n",
+ "processor = Qwen3OmniMoeProcessor.from_pretrained(model_dir)"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "8328887c",
+ "metadata": {},
+ "source": [
+ "## Run model inference\n",
+ "[back to top ⬆️](#Table-of-contents:)\n",
+ "\n",
+ "Let's explore model capabilities using multimodal input and output."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b3424ef7-f254-4199-97eb-62e4c7feb728",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "Setting `pad_token_id` to `eos_token_id`:151645 for open-end generation.\n",
+ "The following generation flags are not valid and may be ignored: ['temperature']. Set `TRANSFORMERS_VERBOSITY=info` for more details.\n",
+ "The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.\n",
+ "Setting `pad_token_id` to `eos_token_id`:2150 for open-end generation.\n",
+ "The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.\n"
+ ]
+ }
+ ],
+ "source": [
+ "from qwen_omni_utils import process_mm_info\n",
+ "import soundfile as sf\n",
+ "from notebook_utils import download_file\n",
+ "\n",
+ "if not Path(\"cars.jpg\").exists():\n",
+ " download_file(\"https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cars.jpg\", \"cars.jpg\")\n",
+ "\n",
+ "if not Path(\"cough.wav\").exists():\n",
+ " download_file(\"https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cough.wav\", \"cough.wav\")\n",
+ "\n",
+ "conversation = [\n",
+ " {\n",
+ " \"role\": \"user\",\n",
+ " \"content\": [\n",
+ " {\"type\": \"image\", \"image\": \"cars.jpg\"},\n",
+ " {\"type\": \"audio\", \"audio\": \"cough.wav\"},\n",
+ " {\"type\": \"text\", \"text\": \"What can you see and hear? Answer in one short sentence.\"}\n",
+ " ],\n",
+ " },\n",
+ "]\n",
+ "\n",
+ "# Set whether to use audio in video\n",
+ "USE_AUDIO_IN_VIDEO = True\n",
+ "\n",
+ "# Preparation for inference\n",
+ "text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)\n",
+ "audios, images, videos = process_mm_info(conversation, use_audio_in_video=USE_AUDIO_IN_VIDEO)\n",
+ "inputs = processor(text=text, \n",
+ " audio=audios, \n",
+ " images=images, \n",
+ " videos=videos, \n",
+ " return_tensors=\"pt\", \n",
+ " padding=True, \n",
+ " use_audio_in_video=USE_AUDIO_IN_VIDEO)\n",
+ "\n",
+ "# Inference: Generation of the output text and audio\n",
+ "text_ids, audio = ov_model.generate(**inputs, \n",
+ " speaker=\"Ethan\", \n",
+ " thinker_return_dict_in_generate=True,\n",
+ " use_audio_in_video=USE_AUDIO_IN_VIDEO)\n",
+ "\n",
+ "text = processor.batch_decode(text_ids.sequences[:, inputs[\"input_ids\"].shape[1] :],\n",
+ " skip_special_tokens=True,\n",
+ " clean_up_tokenization_spaces=False)\n",
+ "print(text)\n",
+ "if audio is not None:\n",
+ " sf.write(\n",
+ " \"output_ov.wav\",\n",
+ " audio.reshape(-1).detach().cpu().numpy(),\n",
+ " samplerate=24000,\n",
+ " )\n"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "1ff8cc97",
+ "metadata": {},
+ "source": [
+ "## Interactive demo\n",
+ "[back to top ⬆️](#Table-of-contents:)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "id": "e01645bc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from gradio_helper import make_demo\n",
+ "\n",
+ "demo = make_demo(ov_model, processor)\n",
+ "\n",
+ "try:\n",
+ " demo.launch(debug=True)\n",
+ "except Exception:\n",
+ " demo.launch(debug=True, share=True)\n",
+ "# if you are launching remotely, specify server_name and server_port\n",
+ "# demo.launch(server_name='your server name', server_port='server port in int')\n",
+ "# Read more in the docs: https://gradio.app/docs/"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.12"
+ },
+ "openvino_notebooks": {
+ "imageUrl": "https://github.com/user-attachments/assets/600798db-c80e-4d1d-ab00-fa945cdcd583",
+ "tags": {
+ "categories": [
+ "Model Demos",
+ "AI Trends"
+ ],
+ "libraries": [],
+ "other": [],
+ "tasks": [
+ "Visual Question Answering",
+ "Image-to-Text",
+ "Text Generation",
+ "Audio Generation",
+ "Speech Recognition"
+ ]
+ }
+ },
+ "widgets": {
+ "application/vnd.jupyter.widget-state+json": {
+ "state": {
+ "05134cea5e3b46968b24749f435cc8da": {
+ "model_module": "@jupyter-widgets/base",
+ "model_module_version": "2.0.0",
+ "model_name": "LayoutModel",
+ "state": {}
+ },
+ "1606efa359604bd09f079d6ad29507b0": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_module_version": "2.0.0",
+ "model_name": "DropdownModel",
+ "state": {
+ "_options_labels": [
+ "Qwen/Qwen2.5-Omni-3B",
+ "Qwen/Qwen2.5-Omni-7B"
+ ],
+ "description": "Model:",
+ "index": 0,
+ "layout": "IPY_MODEL_768b5ab84f8b4ba499f11eb89bb67aa0",
+ "style": "IPY_MODEL_b6bd1a60172b419783cba12ee8fc5662"
+ }
+ },
+ "2f09cede86e64e799a1f0baa7dd1ca7d": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_module_version": "2.0.0",
+ "model_name": "DescriptionStyleModel",
+ "state": {
+ "description_width": ""
+ }
+ },
+ "5eeec30c85334a718fde4a2cc6bd630b": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_module_version": "2.0.0",
+ "model_name": "DescriptionStyleModel",
+ "state": {
+ "description_width": ""
+ }
+ },
+ "767dd31f417948aca84f756d95786707": {
+ "model_module": "@jupyter-widgets/base",
+ "model_module_version": "2.0.0",
+ "model_name": "LayoutModel",
+ "state": {}
+ },
+ "768b5ab84f8b4ba499f11eb89bb67aa0": {
+ "model_module": "@jupyter-widgets/base",
+ "model_module_version": "2.0.0",
+ "model_name": "LayoutModel",
+ "state": {}
+ },
+ "96c78b29b9a54e78847100ac4619bc0d": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_module_version": "2.0.0",
+ "model_name": "DropdownModel",
+ "state": {
+ "_options_labels": [
+ "CPU",
+ "AUTO"
+ ],
+ "description": "Talker device",
+ "index": 1,
+ "layout": "IPY_MODEL_767dd31f417948aca84f756d95786707",
+ "style": "IPY_MODEL_5eeec30c85334a718fde4a2cc6bd630b"
+ }
+ },
+ "9cc862536027461f91fc3b0ffd782bd2": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_module_version": "2.0.0",
+ "model_name": "DropdownModel",
+ "state": {
+ "_options_labels": [
+ "CPU",
+ "AUTO"
+ ],
+ "description": "Token2Wav device",
+ "index": 0,
+ "layout": "IPY_MODEL_e4c6ac0c3b5741f8bd7000b9eaadfce9",
+ "style": "IPY_MODEL_2f09cede86e64e799a1f0baa7dd1ca7d"
+ }
+ },
+ "b135b255a1ce4fd1bf4311284797568d": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_module_version": "2.0.0",
+ "model_name": "DescriptionStyleModel",
+ "state": {
+ "description_width": ""
+ }
+ },
+ "b6bd1a60172b419783cba12ee8fc5662": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_module_version": "2.0.0",
+ "model_name": "DescriptionStyleModel",
+ "state": {
+ "description_width": ""
+ }
+ },
+ "e153361cb39f4c5d8ef1cecf7df58e41": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_module_version": "2.0.0",
+ "model_name": "DropdownModel",
+ "state": {
+ "_options_labels": [
+ "CPU",
+ "AUTO"
+ ],
+ "description": "Thinker device",
+ "index": 1,
+ "layout": "IPY_MODEL_05134cea5e3b46968b24749f435cc8da",
+ "style": "IPY_MODEL_b135b255a1ce4fd1bf4311284797568d"
+ }
+ },
+ "e4c6ac0c3b5741f8bd7000b9eaadfce9": {
+ "model_module": "@jupyter-widgets/base",
+ "model_module_version": "2.0.0",
+ "model_name": "LayoutModel",
+ "state": {}
+ }
+ },
+ "version_major": 2,
+ "version_minor": 0
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/notebooks/qwen3-omni-chatbot/qwen_3_omni_moe_helper.py b/notebooks/qwen3-omni-chatbot/qwen_3_omni_moe_helper.py
new file mode 100644
index 00000000000..44754d7a486
--- /dev/null
+++ b/notebooks/qwen3-omni-chatbot/qwen_3_omni_moe_helper.py
@@ -0,0 +1,2870 @@
+import gc
+import types
+from dataclasses import dataclass
+from pathlib import Path
+from typing import Any, Callable, Dict, Optional, Tuple, Union
+from torch.nn import functional as F
+import numpy as np
+import nncf
+import openvino as ov
+import torch
+from huggingface_hub import snapshot_download
+from torch import nn
+from transformers import (
+ AutoConfig,
+ AutoProcessor,
+ Qwen3OmniMoeForConditionalGeneration,
+ masking_utils,
+)
+from transformers.cache_utils import Cache, DynamicCache, DynamicLayer
+from transformers.generation import GenerationConfig, GenerationMixin
+from transformers.modeling_outputs import (
+ BaseModelOutput,
+ CausalLMOutputWithPast,
+ MoeCausalLMOutputWithPast,
+)
+from transformers.models.qwen3_omni_moe.configuration_qwen3_omni_moe import (
+ Qwen3OmniMoeConfig,
+)
+from transformers.models.qwen3_omni_moe.modeling_qwen3_omni_moe import (
+ Qwen3OmniMoeTalkerCodePredictorOutputWithPast,
+ Qwen3OmniMoeTalkerOutputWithPast,
+ Qwen3OmniMoeThinkerTextSparseMoeBlock,
+ Qwen3OmniMoeThinkerCausalLMOutputWithPast,
+ Qwen3OmniMoeTalkerTextSparseMoeBlock,
+ Qwen3OmniMoeVisionRotaryEmbedding,
+ Qwen3OmniMoeCausalConvNet,
+)
+from transformers.utils import is_torch_xpu_available, is_torchdynamo_compiling
+
+try:
+ from openvino import opset13
+except ImportError:
+ from openvino.runtime import opset13
+
+from openvino.frontend.pytorch.patch_model import __make_16bit_traceable
+from transformers.masking_utils import ALL_MASK_ATTENTION_FUNCTIONS
+
+# logging.basicConfig(level=logging.DEBUG)
+
+
+def _new_get_extra_padding_for_conv1d(self, hidden_state: torch.Tensor) -> int:
+ length = hidden_state.shape[-1]
+ n_frames = (length - self.kernel_size + self.padding) / self.stride + 1
+ # original implementation with math.ceil
+ # ideal_length = (math.ceil(n_frames) - 1) * self.stride + (self.kernel_size - self.padding)
+ ideal_length = (torch.ceil(torch.tensor(n_frames)).to(torch.int64) - 1) * self.stride + (self.kernel_size - self.padding)
+
+ return ideal_length - length
+
+def patched_dynamic_layer_update(
+ self, key_states: torch.Tensor, value_states: torch.Tensor, cache_kwargs: dict[str, Any] | None = None
+) -> tuple[torch.Tensor, torch.Tensor]:
+ if self.keys is None:
+ self.keys = key_states
+ self.values = value_states
+ self.device = key_states.device
+ self.dtype = key_states.dtype
+ self.is_initialized = True
+ else:
+ self.keys = torch.cat([self.keys, key_states], dim=-2)
+ self.values = torch.cat([self.values, value_states], dim=-2)
+ return self.keys, self.values
+
+DynamicLayer.update = patched_dynamic_layer_update
+
+def find_packed_sequence_indices(position_ids: torch.Tensor) -> torch.Tensor:
+ """
+ Find the indices of the sequence to which each new query token in the sequence belongs when using packed
+ tensor format (i.e. several sequences packed in the same batch dimension).
+
+ Args:
+ position_ids (`torch.Tensor`)
+ A 2D tensor of shape (batch_size, query_length) indicating the positions of each token in the sequences.
+
+ Returns:
+ A 2D tensor where each similar integer indicates that the tokens belong to the same sequence. For example, if we
+ pack 3 sequences of 2, 3 and 1 tokens respectively along a single batch dim, this will return [[0, 0, 1, 1, 1, 2]].
+ """
+ # What separate different sequences is when 2 consecutive positions_ids are separated by more than 1. So
+ # taking the diff (by prepending the first value - 1 to keep correct indexing) and applying cumsum to the result
+ # gives exactly the sequence indices
+ # Note that we assume that a single sequence cannot span several batch dimensions, i.e. 1 single sequence
+ # cannot be part of the end of the first batch dim and the start of the 2nd one for example
+ first_dummy_value = position_ids[:, :1] - 1 # We just need the diff on this first value to be 1
+ # Alternative implementation using concat instead of prepend
+ position_diff = torch.cat([torch.ones_like(first_dummy_value), position_ids[:, 1:] - position_ids[:, :-1]], dim=-1)
+ packed_sequence_mask = (position_diff != 1).cumsum(-1)
+
+ # Here it would be nice to return None if we did not detect packed sequence format, i.e. if `packed_sequence_mask[:, -1] == 0`
+ # but it causes issues with export
+ return packed_sequence_mask
+
+masking_utils.find_packed_sequence_indices = find_packed_sequence_indices
+
+def patch_cos_sin_cached_fp32(model):
+ if (
+ hasattr(model, "layers")
+ and hasattr(model.layers[0], "self_attn")
+ and hasattr(model.layers[0].self_attn, "rotary_emb")
+ and hasattr(model.layers[0].self_attn.rotary_emb, "dtype")
+ and hasattr(model.layers[0].self_attn.rotary_emb, "inv_freq")
+ and hasattr(model.layers[0].self_attn.rotary_emb, "max_position_embeddings")
+ and hasattr(model.layers[0].self_attn.rotary_emb, "_set_cos_sin_cache")
+ ):
+ for layer in model.layers:
+ if layer.self_attn.rotary_emb.dtype != torch.float32:
+ layer.self_attn.rotary_emb._set_cos_sin_cache(
+ seq_len=layer.self_attn.rotary_emb.max_position_embeddings,
+ device=layer.self_attn.rotary_emb.inv_freq.device,
+ dtype=torch.float32,
+ )
+
+def causal_mask_function(batch_idx: int, head_idx: int, q_idx: int, kv_idx: int) -> bool:
+ """
+ This creates a basic lower-diagonal causal mask.
+ """
+ return kv_idx <= q_idx
+
+def prepare_padding_mask(
+ attention_mask: Optional[torch.Tensor], kv_length: int, kv_offset: int, _slice: bool = True
+) -> Optional[torch.Tensor]:
+ """
+ From the 2D attention mask, prepare the correct padding mask to use by potentially padding it, and slicing
+ according to the `kv_offset` if `_slice` is `True`.
+ """
+ local_padding_mask = attention_mask
+ if attention_mask is not None:
+ # Pad it if necessary
+ if (padding_length := kv_length + kv_offset - attention_mask.shape[-1]) > 0:
+ local_padding_mask = torch.nn.functional.pad(attention_mask, (0, padding_length))
+ # For flex, we should not slice them, only use an offset
+ if _slice:
+ # Equivalent to: `local_padding_mask = attention_mask[:, kv_offset : kv_offset + kv_length]`,
+ # but without data-dependent slicing (i.e. torch.compile friendly)
+ mask_indices = torch.arange(kv_length, device=local_padding_mask.device)
+ mask_indices += kv_offset
+ local_padding_mask = local_padding_mask[:, mask_indices]
+ return local_padding_mask
+
+def and_masks(*mask_functions: list[Callable]) -> Callable:
+ """Returns a mask function that is the intersection of provided mask functions"""
+ if not all(callable(arg) for arg in mask_functions):
+ raise RuntimeError(f"All inputs should be callable mask_functions: {mask_functions}")
+
+ def and_mask(batch_idx, head_idx, q_idx, kv_idx):
+ result = q_idx.new_ones((), dtype=torch.bool)
+ for mask in mask_functions:
+ result = result & mask(batch_idx, head_idx, q_idx, kv_idx).to(result.device)
+ return result
+
+ return and_mask
+
+def padding_mask_function(padding_mask: torch.Tensor) -> Callable:
+ """
+ This return the mask_function function corresponding to a 2D padding mask.
+ """
+
+ def inner_mask(batch_idx: int, head_idx: int, q_idx: int, kv_idx: int) -> bool:
+ # Note that here the mask should ALWAYS be at least of the max `kv_index` size in the dimension 1. This is because
+ # we cannot pad it here in the mask_function as we don't know the final size, and we cannot try/except, as it is not
+ # vectorizable on accelerator devices
+ return padding_mask[batch_idx, kv_idx]
+
+ return inner_mask
+
+def _ignore_causal_mask_sdpa(
+ padding_mask: Optional[torch.Tensor],
+ query_length: int,
+ kv_length: int,
+ kv_offset: int,
+ local_attention_size: Optional[int] = None,
+) -> bool:
+ """
+ Detects whether the causal mask can be ignored in case PyTorch's SDPA is used, rather relying on SDPA's `is_causal` argument.
+
+ In case no token is masked in the 2D `padding_mask` argument, if `query_length == 1` or
+ `key_value_length == query_length`, we rather rely on SDPA `is_causal` argument to use causal/non-causal masks,
+ allowing to dispatch to the flash attention kernel (that can otherwise not be used if a custom `attn_mask` is
+ passed).
+ """
+ is_tracing = torch.jit.is_tracing() or isinstance(padding_mask, torch.fx.Proxy) or is_torchdynamo_compiling()
+ if padding_mask is not None and padding_mask.shape[-1] > kv_length:
+ mask_indices = torch.arange(kv_length, device=padding_mask.device)
+ mask_indices += kv_offset
+ padding_mask = padding_mask[:, mask_indices]
+
+ # When using `torch.export` or `torch.onnx.dynamo_export`, we must pass an example input, and `is_causal` behavior is
+ # hard-coded to the forward. If a user exports a model with query_length > 1, the exported model will hard-code `is_causal=True`
+ # which is in general wrong (see https://github.com/pytorch/pytorch/issues/108108). Thus, we only set
+ # `ignore_causal_mask = True` if we are not tracing
+ if (
+ not is_tracing
+ # only cases when lower and upper diags are the same, see https://github.com/pytorch/pytorch/issues/108108
+ and (query_length == 1 or (kv_length == query_length or is_torch_xpu_available))
+ # in this case we need to add special patterns to the mask so cannot be skipped otherwise
+ and (local_attention_size is None or kv_length < local_attention_size)
+ # In this case, we need to add padding to the mask, so cannot be skipped otherwise
+ and (
+ padding_mask is None
+ or (
+ padding_mask.all()
+ if not is_torch_xpu_available or query_length == 1
+ else padding_mask[:, :query_length].all()
+ )
+ )
+ ):
+ return True
+
+ return False
+
+def sdpa_mask_without_vmap(
+ batch_size: int,
+ cache_position: torch.Tensor,
+ kv_length: int,
+ kv_offset: int = 0,
+ mask_function: Optional[Callable] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ local_size: Optional[int] = None,
+ allow_is_causal_skip: bool = True,
+ **kwargs,
+) -> Optional[torch.Tensor]:
+ if mask_function is None:
+ mask_function = causal_mask_function
+
+ q_length = cache_position.shape[0]
+ # Potentially pad the 2D mask, and slice it correctly
+ padding_mask = prepare_padding_mask(attention_mask, kv_length, kv_offset, _slice=False)
+
+ # Under specific conditions, we can avoid materializing the mask, instead relying on the `is_causal` argument
+ if allow_is_causal_skip and _ignore_causal_mask_sdpa(padding_mask, q_length, kv_length, kv_offset, local_size):
+ return None
+
+ # Potentially add the padding 2D mask
+ if padding_mask is not None:
+ mask_function = and_masks(mask_function, padding_mask_function(padding_mask))
+
+ # Create broadcatable indices
+ device = cache_position.device
+ q_indices = cache_position[None, None, :, None]
+ head_indices = torch.arange(1, dtype=torch.long, device=device)[None, :, None, None]
+ batch_indices = torch.arange(batch_size, dtype=torch.long, device=device)[:, None, None, None]
+ kv_indices = torch.arange(kv_length, dtype=torch.long, device=device)[None, None, None, :] + kv_offset
+
+ # Apply mask function element-wise through broadcasting
+ causal_mask = mask_function(batch_indices, head_indices, q_indices, kv_indices)
+ # Expand the mask to match batch size and query length if they weren't used in the mask function
+ causal_mask = causal_mask.expand(batch_size, -1, q_length, kv_length)
+
+ return causal_mask
+
+# Adapted from https://github.com/huggingface/transformers/blob/v4.53.0/src/transformers/masking_utils.py#L433
+# Specifically for OpenVINO, we use torch.finfo(torch.float16).min instead of torch.finfo(dtype).min
+def eager_mask_without_vmap(*args, **kwargs) -> Optional[torch.Tensor]:
+ kwargs.pop("allow_is_causal_skip", None)
+ dtype = kwargs.get("dtype", torch.float32)
+ mask = sdpa_mask_without_vmap(*args, allow_is_causal_skip=False, **kwargs)
+ # we use torch.finfo(torch.float16).min instead torch.finfo(dtype).min to avoid an overflow but not
+ # sure this is the right way to handle this, we are basically pretending that -65,504 is -inf
+ mask = torch.where(
+ mask,
+ torch.tensor(0.0, device=mask.device, dtype=dtype),
+ torch.tensor(torch.finfo(torch.float16).min, device=mask.device, dtype=dtype),
+ )
+ return mask
+
+
+# for OpenVINO, we use torch.finfo(torch.float16).min instead of torch.finfo(dtype).min
+# Although I'm not sure this is the right way to handle this, we are basically pretending that -65,504 is -inf
+ALL_MASK_ATTENTION_FUNCTIONS.register("eager", eager_mask_without_vmap)
+
+# for decoder models, we use eager mask without vmap for sdpa as well
+# to avoid a nan output issue in OpenVINO that only happens in case of:
+# non-stateful models on cpu and stateful models on npu
+ALL_MASK_ATTENTION_FUNCTIONS.register("sdpa", sdpa_mask_without_vmap)
+
+
+def model_has_state(ov_model: ov.Model):
+ return len(ov_model.get_sinks()) > 0
+
+
+def model_has_input_output_name(ov_model: ov.Model, name: str):
+ """
+ Helper function for checking that model has specified input or output name
+ """
+ return name in sum([list(t.get_names()) for t in ov_model.inputs + ov_model.outputs], [])
+
+
+def fuse_cache_reorder(
+ ov_model: ov.Model,
+ not_kv_inputs: list[str],
+ key_value_input_names: list[str],
+ gather_dim: int,
+):
+ """
+ Fuses reordered cache during generate cycle into ov.Model for MoE models.
+ """
+ if model_has_input_output_name(ov_model, "beam_idx"):
+ raise ValueError("Model already has fused cache")
+ input_batch = ov_model.input("inputs_embeds").get_partial_shape()[0]
+ beam_idx = opset13.parameter(name="beam_idx", dtype=ov.Type.i32, shape=ov.PartialShape([input_batch]))
+ beam_idx.output(0).get_tensor().add_names({"beam_idx"})
+ ov_model.add_parameters([beam_idx])
+ not_kv_inputs.append(ov_model.inputs[-1])
+
+ for input_name in key_value_input_names:
+ parameter_output_port = ov_model.input(input_name)
+ consumers = parameter_output_port.get_target_inputs()
+ gather = opset13.gather(parameter_output_port, beam_idx, opset13.constant(gather_dim))
+ for consumer in consumers:
+ consumer.replace_source_output(gather.output(0))
+ ov_model.validate_nodes_and_infer_types()
+
+
+def build_state_initializer(ov_model: ov.Model, batch_dim: int):
+ """
+ Build initialization ShapeOf Expression for all ReadValue ops for MoE models
+ """
+ input_ids = ov_model.input("inputs_embeds")
+ batch = opset13.gather(
+ opset13.shape_of(input_ids, output_type="i64"),
+ opset13.constant([0]),
+ opset13.constant(0),
+ )
+ for op in ov_model.get_ops():
+ if op.get_type_name() == "ReadValue":
+ dims = [dim.min_length for dim in list(op.get_output_partial_shape(0))]
+ dims[batch_dim] = batch
+ dims = [(opset13.constant(np.array([dim], dtype=np.int64)) if isinstance(dim, int) else dim) for dim in dims]
+ shape = opset13.concat(dims, axis=0)
+ broadcast = opset13.broadcast(opset13.constant(0.0, dtype=op.get_output_element_type(0)), shape)
+ op.set_arguments([broadcast])
+ ov_model.validate_nodes_and_infer_types()
+
+
+def make_stateful(
+ ov_model: ov.Model,
+ not_kv_inputs: list[str],
+ key_value_input_names: list[str],
+ key_value_output_names: list[str],
+ batch_dim: int,
+ num_attention_heads: int,
+ num_beams_and_batch: int = None,
+):
+ """
+ Hides kv-cache inputs and outputs inside the MoE model as variables.
+ """
+ from openvino._offline_transformations import apply_make_stateful_transformation
+
+ input_output_map = {}
+
+ if num_beams_and_batch is not None:
+ for input in not_kv_inputs:
+ shape = input.get_partial_shape()
+ if shape.rank.get_length() <= 2:
+ shape[0] = num_beams_and_batch
+ input.get_node().set_partial_shape(shape)
+
+ for kv_name_pair in zip(key_value_input_names, key_value_output_names):
+ input_output_map[kv_name_pair[0]] = kv_name_pair[1]
+ if num_beams_and_batch is not None:
+ input = ov_model.input(kv_name_pair[0])
+ shape = input.get_partial_shape()
+ shape[batch_dim] = num_beams_and_batch * num_attention_heads
+ input.get_node().set_partial_shape(shape)
+
+ if num_beams_and_batch is not None:
+ ov_model.validate_nodes_and_infer_types()
+
+ apply_make_stateful_transformation(ov_model, input_output_map)
+ if num_beams_and_batch is None:
+ build_state_initializer(ov_model, batch_dim)
+
+
+def patch_stateful(ov_model, dim):
+ key_value_input_names = [key.get_any_name() for key in ov_model.inputs[2:-1]]
+ key_value_output_names = [key.get_any_name() for key in ov_model.outputs[dim:]]
+ not_kv_inputs = [input for input in ov_model.inputs if not any(name in key_value_input_names for name in input.get_names())]
+ if not key_value_input_names or not key_value_output_names:
+ return
+ batch_dim = 0
+ num_attention_heads = 1
+
+ fuse_cache_reorder(ov_model, not_kv_inputs, key_value_input_names, batch_dim)
+ make_stateful(
+ ov_model,
+ not_kv_inputs,
+ key_value_input_names,
+ key_value_output_names,
+ batch_dim,
+ num_attention_heads,
+ None,
+ )
+
+
+def cleanup_torchscript_cache():
+ """
+ Helper for removing cached model representation
+ """
+ torch._C._jit_clear_class_registry()
+ torch.jit._recursive.concrete_type_store = torch.jit._recursive.ConcreteTypeStore()
+ torch.jit._state._clear_class_state()
+
+
+core = ov.Core()
+
+# File naming conventions for Qwen3OmniMoe
+THINKER_LANGUAGE_NAME = "openvino_thinker_language_model.xml"
+THINKER_AUDIO_NAME = "openvino_thinker_audio_model.xml"
+THINKER_AUDIO_STATE_NAME = "openvino_thinker_audio_state_model.xml"
+THINKER_VISION_NAME = "openvino_thinker_vision_model.xml"
+THINKER_VISION_POS_NAME = "openvino_thinker_vision_pos_model.xml"
+THINKER_VISION_MERGER_NAME = "openvino_thinker_vision_merger_model.xml"
+THINKER_EMBEDDING_NAME = "openvino_thinker_embedding_model.xml"
+THINKER_PATCHER_NAME = "openvino_thinker_patcher_model.xml"
+THINKER_PATCHER_NAME = "openvino_thinker_patcher_model.xml"
+THINKER_MERGER_NAME = "openvino_thinker_merger_model.xml"
+
+TALKER_LANGUAGE_NAME = "openvino_talker_language_model.xml"
+TALKER_EMBEDDING_NAME = "openvino_talker_embedding_model.xml"
+TALKER_TEXT_PROJECTION_NAME = "openvino_talker_text_projection_model.xml"
+TALKER_HIDDEN_PROJECTION_NAME = "openvino_talker_hidden_projection_model.xml"
+
+TALKER_CODE_PREDICTOR_EMBEDDING_NAME = "openvino_talker_code_predictor_embedding_model.xml"
+TALKER_CODE_PREDICTOR_NAME = "openvino_talker_code_predictor_model.xml"
+
+CODE2WAV_NAME = "openvino_code2wav_model.xml"
+
+
+def _get_feat_extract_output_lengths(input_lengths):
+ """
+ Computes the output length of the convolutional layers and the output length of the audio encoder
+ """
+
+ input_lengths_leave = input_lengths % 100
+ feat_lengths = (input_lengths_leave - 1) // 2 + 1
+ output_lengths = ((feat_lengths - 1) // 2 + 1 - 1) // 2 + 1 + (input_lengths // 100) * 13
+ return output_lengths
+
+
+def qwen3_moe_thinker_forward_patched(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ batch_size, sequence_length, hidden_dim = hidden_states.shape
+ hidden_states = hidden_states.view(-1, hidden_dim)
+ # router_logits: (batch * sequence_length, n_experts)
+ router_logits = self.gate(hidden_states)
+
+ routing_weights = torch.nn.functional.softmax(router_logits, dim=1, dtype=torch.float)
+ routing_weights, selected_experts = torch.topk(routing_weights, self.top_k, dim=-1)
+ if self.norm_topk_prob: # only diff with mixtral sparse moe block!
+ routing_weights /= routing_weights.sum(dim=-1, keepdim=True)
+ # we cast back to the input dtype
+ routing_weights = routing_weights.to(hidden_states.dtype)
+
+ final_hidden_states = torch.zeros(
+ (batch_size * sequence_length, hidden_dim), dtype=hidden_states.dtype, device=hidden_states.device
+ )
+
+ # expert_mask: [num_experts, top_k, batch*seq_len]
+ expert_mask = torch.nn.functional.one_hot(selected_experts, num_classes=self.num_experts).permute(2, 1, 0)
+
+ # Use arithmetic masking instead of torch.where + index_add_ to avoid NonZero ops
+ # that produce data-dependent shapes and crash OpenVINO apply_moc_transformations.
+ for expert_idx in range(self.num_experts):
+ expert_layer = self.experts[expert_idx]
+ # token_weights: [batch*seq_len] — routing weight for this expert per token (0 if not routed here)
+ token_weights = (expert_mask[expert_idx].to(routing_weights.dtype) * routing_weights.T).sum(0)
+ current_hidden_states = expert_layer(hidden_states) * token_weights.unsqueeze(-1)
+ final_hidden_states = final_hidden_states + current_hidden_states.to(hidden_states.dtype)
+
+ final_hidden_states = final_hidden_states.reshape(batch_size, sequence_length, hidden_dim)
+ return final_hidden_states, router_logits
+
+def qwen3_moe_talker_forward_patched(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ batch_size, sequence_length, hidden_dim = hidden_states.shape
+ hidden_states = hidden_states.view(-1, hidden_dim)
+ # router_logits: (batch * sequence_length, n_experts)
+ router_logits = self.gate(hidden_states)
+
+ routing_weights = torch.nn.functional.softmax(router_logits, dim=1, dtype=torch.float)
+ routing_weights, selected_experts = torch.topk(routing_weights, self.top_k, dim=-1)
+ if self.norm_topk_prob: # only diff with mixtral sparse moe block!
+ routing_weights /= routing_weights.sum(dim=-1, keepdim=True)
+ # we cast back to the input dtype
+ routing_weights = routing_weights.to(hidden_states.dtype)
+
+ final_hidden_states = torch.zeros(
+ (batch_size * sequence_length, hidden_dim), dtype=hidden_states.dtype, device=hidden_states.device
+ )
+
+ # expert_mask: [num_experts, top_k, batch*seq_len]
+ expert_mask = torch.nn.functional.one_hot(selected_experts, num_classes=self.num_experts).permute(2, 1, 0)
+
+ # Use arithmetic masking instead of torch.where + index_add_ to avoid NonZero ops
+ # that produce data-dependent shapes and crash OpenVINO apply_moc_transformations.
+ for expert_idx in range(self.num_experts):
+ expert_layer = self.experts[expert_idx]
+ # token_weights: [batch*seq_len] — routing weight for this expert per token (0 if not routed here)
+ token_weights = (expert_mask[expert_idx].to(routing_weights.dtype) * routing_weights.T).sum(0)
+ current_hidden_states = expert_layer(hidden_states) * token_weights.unsqueeze(-1)
+ final_hidden_states = final_hidden_states + current_hidden_states.to(hidden_states.dtype)
+
+ shared_expert_output = self.shared_expert(hidden_states)
+ shared_expert_output = torch.nn.functional.sigmoid(self.shared_expert_gate(hidden_states)) * shared_expert_output
+
+ final_hidden_states = final_hidden_states + shared_expert_output
+
+ final_hidden_states = final_hidden_states.reshape(batch_size, sequence_length, hidden_dim)
+ return final_hidden_states, router_logits
+
+
+def qwen3_moe_thinker_expert_forward_patched(self, hidden_states: torch.Tensor, top_k_index: torch.Tensor, top_k_weights: torch.Tensor
+ ) -> torch.Tensor:
+
+ final_hidden_states = torch.zeros_like(hidden_states)
+ expert_mask = torch.nn.functional.one_hot(top_k_index, num_classes=self.num_experts).permute(2, 1, 0)
+
+ # TODO: we loop over all possible experts instead of hitted ones to avoid issues in graph execution.
+ # expert_hitted = torch.greater(expert_mask.sum(dim=(-1, -2)), 0).nonzero()
+ # Loop over all available experts in the model and perform the computation on each expert
+ for expert_idx in range(self.num_experts):
+ idx, top_x = torch.where(expert_mask[expert_idx].squeeze(0))
+
+ # Index the correct hidden states and compute the expert hidden state for
+ # the current expert. We need to make sure to multiply the output hidden
+ # states by `routing_weights` on the corresponding tokens (top-1 and top-2)
+ current_state = hidden_states[None, top_x].reshape(-1, hidden_states.shape[-1])
+ current_hidden_states = self[expert_idx](current_state) * top_k_weights[top_x, idx, None]
+ final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype))
+ return final_hidden_states
+
+def qwen3_moe_talker_text_forward_patched(self, hidden_states: torch.Tensor, top_k_index: torch.Tensor, top_k_weights: torch.Tensor
+ ) -> torch.Tensor:
+ final_hidden_states = torch.zeros_like(hidden_states)
+ expert_mask = torch.nn.functional.one_hot(top_k_index, num_classes=self.num_experts).permute(2, 1, 0)
+
+ # TODO: we loop over all possible experts instead of hitted ones to avoid issues in graph execution.
+ # expert_hitted = torch.greater(expert_mask.sum(dim=(-1, -2)), 0).nonzero()
+ # Loop over all available experts in the model and perform the computation on each expert
+ for expert_idx in range(self.num_experts):
+ idx, top_x = torch.where(expert_mask[expert_idx].squeeze(0))
+ current_state = hidden_states[None, top_x].reshape(-1, hidden_states.shape[-1])
+ current_hidden_states = self[expert_idx](current_state) * top_k_weights[top_x, idx, None]
+ final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype))
+ return final_hidden_states
+
+def patch_qwen2vl_vision_blocks(model, force_new_behaviour=False):
+ # Modified from https://github.com/huggingface/transformers/blob/v4.49.0/src/transformers/models/qwen2_vl/modeling_qwen2_vl.py#L391
+ # added attention_mask input instead of internal calculation (unsupported by tracing due to cycle with dynamic len)
+ def sdpa_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: torch.Tensor,
+ rotary_pos_emb: torch.Tensor = None,
+ position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
+ ):
+ def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+ def apply_rotary_pos_emb_vision(
+ q: torch.Tensor, k: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ orig_q_dtype = q.dtype
+ orig_k_dtype = k.dtype
+ q, k = q.float(), k.float()
+ cos, sin = cos.unsqueeze(-2), sin.unsqueeze(-2)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ q_embed = q_embed.to(orig_q_dtype)
+ k_embed = k_embed.to(orig_k_dtype)
+ return q_embed, k_embed
+
+ seq_length = hidden_states.shape[0]
+ q, k, v = self.qkv(hidden_states).reshape(seq_length, 3, self.num_heads, -1).permute(1, 0, 2, 3).unbind(0)
+ if position_embeddings is None:
+ emb = torch.cat((rotary_pos_emb, rotary_pos_emb), dim=-1)
+ cos = emb.cos().float()
+ sin = emb.sin().float()
+ else:
+ cos, sin = position_embeddings
+ q, k = apply_rotary_pos_emb_vision(q, k, cos, sin)
+ q = q.transpose(0, 1)
+ k = k.transpose(0, 1)
+ v = v.transpose(0, 1)
+ attn_output = torch.nn.functional.scaled_dot_product_attention(q, k, v, attention_mask, dropout_p=0.0)
+ attn_output = attn_output.transpose(0, 1)
+ attn_output = attn_output.reshape(seq_length, -1)
+ attn_output = self.proj(attn_output)
+ return attn_output
+
+ # Modified from https://github.com/huggingface/transformers/blob/v4.49.0/src/transformers/models/qwen2_vl/modeling_qwen2_vl.py#L446
+ # added attention_mask input propagation to self.attn
+ def block_forward(
+ self,
+ hidden_states,
+ attention_mask,
+ rotary_pos_emb: Optional[torch.Tensor] = None,
+ position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
+ ) -> torch.Tensor:
+ hidden_states = hidden_states + self.attn(
+ self.norm1(hidden_states),
+ attention_mask=attention_mask,
+ rotary_pos_emb=rotary_pos_emb,
+ position_embeddings=position_embeddings,
+ )
+ hidden_states = hidden_states + self.mlp(self.norm2(hidden_states))
+ return hidden_states
+
+ for block in model.blocks:
+ block._orig_forward = block.forward
+ block.forward = types.MethodType(block_forward, block)
+ block.attn._orig_forward = block.attn.forward
+ block.attn.forward = types.MethodType(sdpa_attn_forward, block.attn)
+
+def convert_qwen3_omni_moe_model(model_id, output_dir, quantization_config=None, use_local_dir=False):
+ thinker_output_dir = Path(output_dir) / "thinker"
+ talker_output_dir = Path(output_dir) / "talker"
+
+ thinker_lang_path = thinker_output_dir / THINKER_LANGUAGE_NAME
+ thinker_audio_path = thinker_output_dir / THINKER_AUDIO_NAME
+ thinker_audio_state_path = thinker_output_dir / THINKER_AUDIO_STATE_NAME
+ thinker_vision_path = thinker_output_dir / THINKER_VISION_NAME
+ thinker_vision_pos_path = thinker_output_dir / THINKER_VISION_POS_NAME
+ thinker_vision_merger_path = thinker_output_dir / THINKER_VISION_MERGER_NAME
+ thinker_embedding_path = thinker_output_dir / THINKER_EMBEDDING_NAME
+ talker_lang_path = talker_output_dir / TALKER_LANGUAGE_NAME
+ talker_text_projection_path = talker_output_dir / TALKER_TEXT_PROJECTION_NAME
+ talker_hidden_projection_path = talker_output_dir / TALKER_HIDDEN_PROJECTION_NAME
+ talker_embedding_path = talker_output_dir / TALKER_EMBEDDING_NAME
+ talker_code_predictor_embedding_path = talker_output_dir / TALKER_CODE_PREDICTOR_EMBEDDING_NAME
+
+ talker_code_predictor_path = talker_output_dir / TALKER_CODE_PREDICTOR_NAME
+
+ code2wav_path = Path(output_dir) / CODE2WAV_NAME
+
+ if all([
+ thinker_lang_path.exists(),
+ thinker_audio_path.exists(),
+ thinker_audio_state_path.exists(),
+ thinker_embedding_path.exists(),
+ thinker_vision_path.exists(),
+ thinker_vision_pos_path.exists(),
+ thinker_vision_merger_path.exists(),
+ talker_lang_path.exists(),
+ talker_embedding_path.exists(),
+ talker_text_projection_path.exists(),
+ talker_hidden_projection_path.exists(),
+ talker_code_predictor_embedding_path.exists(),
+ talker_code_predictor_path.exists(),
+ code2wav_path.exists(),
+ ]):
+ print(f"✅ {model_id} model already converted. You can find results in {output_dir}")
+ return
+
+ print(f"⌛ {model_id} conversion started. Be patient, it may takes some time.")
+ print("⌛ Load Original model")
+
+ if use_local_dir:
+ ckpt = Path(output_dir) / "ckpt"
+ if not ckpt.exists():
+ snapshot_download(model_id, local_dir=ckpt, force_download=True)
+ else:
+ ckpt = model_id
+
+ config = Qwen3OmniMoeConfig.from_pretrained(ckpt)
+ config.thinker_config.text_config._attn_implementation_autoset = False
+ config.thinker_config.text_config._attn_implementation = "sdpa"
+ config.talker_config.text_config._attn_implementation_autoset = False
+ config.talker_config.text_config._attn_implementation = "sdpa"
+ model = Qwen3OmniMoeForConditionalGeneration.from_pretrained(ckpt, config=config, torch_dtype=torch.float16)
+ model.eval()
+ processor = AutoProcessor.from_pretrained(ckpt)
+
+ # TO adapt the old implementation
+ Qwen3OmniMoeThinkerTextSparseMoeBlock.forward = qwen3_moe_thinker_forward_patched
+ Qwen3OmniMoeTalkerTextSparseMoeBlock.forward = qwen3_moe_talker_forward_patched
+ Qwen3OmniMoeCausalConvNet._get_extra_padding_for_conv1d = _new_get_extra_padding_for_conv1d
+ # Qwen3OmniMoeThinkerTextExperts.forward = qwen3_moe_thinker_expert_forward_patched
+ # Qwen3OmniMoeTalkerTextExperts.forward = qwen3_moe_talker_text_forward_patched
+
+ config.save_pretrained(output_dir)
+ processor.save_pretrained(output_dir)
+ print("✅ Original model successfully loaded")
+
+ # Convert thinker embedding model
+ if not thinker_embedding_path.exists():
+ print("⌛ Convert thinker embedding model")
+ __make_16bit_traceable(model.thinker.model.get_input_embeddings())
+ ov_model = ov.convert_model(
+ model.thinker.model.get_input_embeddings(),
+ example_input=torch.ones([2, 2], dtype=torch.int64),
+ )
+ ov.save_model(ov_model, thinker_embedding_path)
+ del ov_model
+ cleanup_torchscript_cache()
+ gc.collect()
+ print("✅ Thinker embedding model successfully converted")
+
+ # Convert audio models (similar to Qwen2.5-Omni but adapted for MoE)
+ def forward_wrap_audio(self, padded_feature):
+ padded_embed = nn.functional.gelu(self.conv2d1(padded_feature.unsqueeze(1)))
+ padded_embed = nn.functional.gelu(self.conv2d2(padded_embed))
+ padded_embed = nn.functional.gelu(self.conv2d3(padded_embed))
+ b, c, f, t = padded_embed.size()
+ padded_embed = self.conv_out(padded_embed.permute(0, 3, 1, 2).contiguous().view(b, t, c * f))
+
+ return padded_embed
+
+ def forward_wrap_audio_state(self, hidden_states, cu_seqlens):
+ for encoder_layer in self.layers:
+ layer_outputs = encoder_layer(
+ hidden_states,
+ cu_seqlens,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ hidden_states = self.ln_post(hidden_states)
+ hidden_states = self.proj1(hidden_states)
+ hidden_states = self.act(hidden_states)
+ hidden_states = self.proj2(hidden_states)
+ return hidden_states
+
+ audio = model.thinker.audio_tower
+ audio._orig_forward = audio.forward
+ if not thinker_audio_path.exists():
+ print("⌛ Convert thinker audio model")
+ __make_16bit_traceable(audio)
+ audio.forward = types.MethodType(forward_wrap_audio, audio)
+ ov_model = ov.convert_model(
+ audio,
+ example_input={
+ # Ethan
+ "padded_feature": torch.randn([3, 128, 100], dtype=torch.float32),
+ },
+ )
+ ov.save_model(ov_model, thinker_audio_path)
+ del ov_model
+ cleanup_torchscript_cache()
+ gc.collect()
+ print("✅ Thinker audio model successfully converted")
+
+ if not thinker_audio_state_path.exists():
+ print("⌛ Convert thinker audio state model")
+ audio.forward = audio._orig_forward
+ audio.forward = types.MethodType(forward_wrap_audio_state, audio)
+ __make_16bit_traceable(audio)
+ ov_model = ov.convert_model(
+ audio,
+ example_input={
+ # Ethan
+ "hidden_states": torch.randn([5, 1280], dtype=torch.float32),
+ "cu_seqlens": torch.tensor([0, 5], dtype=torch.int32),
+ },
+ )
+ ov.save_model(ov_model, thinker_audio_state_path)
+ del ov_model
+ cleanup_torchscript_cache()
+ gc.collect()
+ print("✅ Thinker audio state model successfully converted")
+
+
+ # Convert vision models (adapted for MoE with DeepStack)
+ if not thinker_vision_path.exists() or not thinker_vision_merger_path.exists() or not thinker_vision_pos_path.exists():
+ print("⌛ Convert image embedding model")
+
+ vision_embed_tokens = model.thinker.visual
+ if not thinker_vision_path.exists():
+ __make_16bit_traceable(vision_embed_tokens.patch_embed)
+ ov_model = ov.convert_model(
+ vision_embed_tokens.patch_embed,
+ # Ethan
+ example_input={"hidden_states": torch.randn([8, 1536])},
+ )
+ ov.save_model(ov_model, thinker_vision_path)
+ del ov_model
+ cleanup_torchscript_cache()
+
+ vision_embed_pos = model.thinker.visual.pos_embed
+ if not thinker_vision_pos_path.exists():
+ __make_16bit_traceable(vision_embed_pos)
+ ov_model = ov.convert_model(
+ vision_embed_pos,
+ # Ethan
+ example_input={"input": torch.randn([4, 8])},
+ )
+ ov.save_model(ov_model, thinker_vision_pos_path)
+ del ov_model
+ cleanup_torchscript_cache()
+
+ def image_embed_forward(
+ self, hidden_states: torch.Tensor, attention_mask: torch.Tensor, rotary_pos_emb: torch.Tensor
+ ) -> torch.Tensor:
+ deepstack_feature_lists = []
+ for layer_num, blk in enumerate(self.blocks):
+ hidden_states = blk(hidden_states, attention_mask=attention_mask, rotary_pos_emb=rotary_pos_emb)
+ if layer_num in self.deepstack_visual_indexes:
+ deepstack_feature = self.deepstack_merger_list[self.deepstack_visual_indexes.index(layer_num)](
+ hidden_states
+ )
+ deepstack_feature_lists.append(deepstack_feature)
+ last_hidden_state = self.merger(hidden_states)
+ return last_hidden_state, torch.stack(deepstack_feature_lists, dim=0)
+
+ if not thinker_vision_merger_path.exists():
+ vision_embed_tokens.forward = types.MethodType(image_embed_forward, vision_embed_tokens)
+ patch_qwen2vl_vision_blocks(vision_embed_tokens)
+ __make_16bit_traceable(vision_embed_tokens)
+ ov_model = ov.convert_model(
+ vision_embed_tokens,
+ # Ethan
+ example_input={
+ "hidden_states": torch.randn([8, 1152], dtype=torch.float32),
+ "attention_mask": torch.randn([1, 8, 8], dtype=torch.float32),
+ "rotary_pos_emb": torch.randn([8, 36], dtype=torch.float32),
+ },
+ )
+ ov.save_model(ov_model, thinker_vision_merger_path)
+ del ov_model
+ cleanup_torchscript_cache()
+ del vision_embed_tokens
+ gc.collect()
+ print("✅ Image embedding model successfully converted")
+
+ # Convert Thinker Language model (MoE version)
+ if not thinker_lang_path.exists():
+ print("⌛ Convert Thinker Language model (MoE)")
+
+ def forward_wrap_thinker(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[list[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ visual_pos_masks: Optional[torch.Tensor] = None,
+ deepstack_visual_embeds: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ output_router_logits: Optional[bool] = None,
+ ):
+ if past_key_values is not None:
+ past_key_values = DynamicCache.from_legacy_cache(past_key_values)
+
+ outputs = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ visual_pos_masks=visual_pos_masks,
+ deepstack_visual_embeds=deepstack_visual_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=True,
+ return_dict=return_dict,
+ cache_position=cache_position,
+ output_router_logits=output_router_logits,
+ )
+ if past_key_values is not None:
+ outputs["past_key_values"] = outputs["past_key_values"].to_legacy_cache()
+ hidden_states = outputs[0]
+ logits = self.lm_head(hidden_states)
+ output = (logits, outputs.hidden_states[config.talker_config.accept_hidden_layer], outputs.past_key_values)
+
+ return output
+
+ lang_model = model.thinker
+ hidden_size = lang_model.model.config.hidden_size
+ patch_cos_sin_cached_fp32(lang_model)
+ if hasattr(lang_model, "model"):
+ patch_cos_sin_cached_fp32(lang_model.model)
+ lang_model._orig_forward = lang_model.forward
+ lang_model.forward = types.MethodType(forward_wrap_thinker, lang_model)
+
+ num_pkv = lang_model.model.config.num_hidden_layers
+ pkv_shape = (
+ 2,
+ lang_model.model.config.num_key_value_heads,
+ 2,
+ lang_model.model.config.head_dim,
+ )
+
+ cache_position = torch.arange(2, 4)
+ position_ids = cache_position.view(1, 1, -1).expand(3, 2, -1)
+
+ input_embeds = torch.randn((2, 2, hidden_size))
+ attention_mask = torch.ones([2, 4], dtype=torch.long)
+ input_names = ["attention_mask", "position_ids"]
+ output_names = ["logits", "hidden_states"]
+ past_key_values = []
+ for i in range(num_pkv):
+ kv = [torch.randn(pkv_shape) for _ in range(2)]
+ past_key_values.append(kv)
+ input_names.extend([f"past_key_values.{i}.key", f"past_key_values.{i}.value"])
+ output_names.extend([f"present.{i}.key", f"present.{i}.value"])
+ input_names.extend(["inputs_embeds", "visual_pos_masks", "deepstack_visual_embeds"])
+
+ example_input = {
+ "inputs_embeds": input_embeds,
+ "attention_mask": attention_mask,
+ "position_ids": position_ids,
+ "past_key_values": past_key_values,
+ "visual_pos_masks": torch.ones(2, 2, hidden_size, dtype=torch.bool),
+ "deepstack_visual_embeds": torch.randn([3, 4, hidden_size]),
+ }
+
+ input_shapes = [
+ ov.PartialShape([-1, -1]),
+ ov.PartialShape([3, -1, -1]),
+ ]
+ input_shapes += (
+ [
+ ov.PartialShape(
+ [
+ -1,
+ lang_model.model.config.num_key_value_heads,
+ -1,
+ lang_model.model.config.head_dim,
+ ]
+ )
+ ]
+ * 2
+ * num_pkv
+ )
+ input_shapes += [ov.PartialShape([-1, -1, input_embeds.shape[-1]])]
+ input_shapes += [ov.PartialShape([-1, -1, hidden_size])]
+ input_shapes += [ov.PartialShape([-1, -1, hidden_size])]
+ __make_16bit_traceable(lang_model)
+ ov_model = ov.convert_model(lang_model, example_input=example_input, input=input_shapes)
+ for input, input_name in zip(ov_model.inputs, input_names):
+ input.get_tensor().set_names({input_name})
+
+ for output, output_name in zip(ov_model.outputs, output_names):
+ output.get_tensor().set_names({output_name})
+ patch_stateful(ov_model, 2)
+ print("✅ Thinker language model (MoE) successfully converted")
+
+ if quantization_config is not None:
+ print(f"⌛ Weights compression with {quantization_config['mode']} mode started")
+ ov_model = nncf.compress_weights(ov_model, **quantization_config)
+ print("✅ Weights compression finished")
+
+ ov.save_model(ov_model, thinker_lang_path)
+ del ov_model
+ cleanup_torchscript_cache()
+ gc.collect()
+ print(f"✅ Thinker model conversion finished. You can find results in {output_dir}")
+
+ # Convert talker embedding model
+ if not talker_embedding_path.exists():
+ print("⌛ Convert talker embedding model")
+ __make_16bit_traceable(model.talker.model.get_input_embeddings())
+ ov_model = ov.convert_model(
+ model.talker.model.get_input_embeddings(),
+ example_input=torch.ones([2, 2], dtype=torch.int64),
+ )
+ ov.save_model(ov_model, talker_embedding_path)
+ del ov_model
+ cleanup_torchscript_cache()
+ gc.collect()
+ print("✅ Talker embedding model successfully converted")
+
+ # Convert talker text_projection model
+ if not talker_hidden_projection_path.exists():
+ print("⌛ Convert talker hidden_projection model")
+ __make_16bit_traceable(model.talker.hidden_projection)
+ ov_model = ov.convert_model(
+ model.talker.hidden_projection,
+ example_input=torch.ones([1, 2048], dtype=torch.float32),
+ )
+ ov.save_model(ov_model, talker_hidden_projection_path)
+ del ov_model
+ cleanup_torchscript_cache()
+ gc.collect()
+ print("✅ Talker hidden_projection model successfully converted")
+
+ # Convert talker text_projection model
+ if not talker_text_projection_path.exists():
+ print("⌛ Convert talker text_projection model")
+ __make_16bit_traceable(model.talker.text_projection)
+ ov_model = ov.convert_model(
+ model.talker.text_projection,
+ example_input=torch.ones([1, 3, 2048], dtype=torch.float32),
+ )
+ ov.save_model(ov_model, talker_text_projection_path)
+ del ov_model
+ cleanup_torchscript_cache()
+ gc.collect()
+ print("✅ Talker text_projection model successfully converted")
+
+ # Convert Talker Language model (MoE version)
+ if not talker_lang_path.exists():
+ print("⌛ Convert Talker Language model (MoE)")
+
+ def forward_wrap_talker(
+ self,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[list[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ output_router_logits: Optional[bool] = None,
+ ):
+ if past_key_values is not None:
+ past_key_values = DynamicCache.from_legacy_cache(past_key_values)
+
+ # MoE-specific processing with text and hidden projections
+ outputs = self.model(
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=True,
+ return_dict=return_dict,
+ output_router_logits=output_router_logits,
+ )
+ if past_key_values is not None:
+ outputs["past_key_values"] = outputs["past_key_values"].to_legacy_cache()
+
+ hidden_states = outputs[0]
+ logits = self.codec_head(hidden_states)
+ logits = logits.float()
+ output = (logits, hidden_states, outputs.past_key_values)
+
+ return output
+
+ lang_model = model.talker
+ num_pkv = lang_model.model.config.num_hidden_layers
+ embedding_size = lang_model.model.config.hidden_size
+ patch_cos_sin_cached_fp32(lang_model)
+ if hasattr(lang_model, "model"):
+ patch_cos_sin_cached_fp32(lang_model.model)
+ lang_model._orig_forward = lang_model.forward
+ lang_model.forward = types.MethodType(forward_wrap_talker, lang_model)
+
+ pkv_shape = (
+ 2,
+ lang_model.model.config.num_key_value_heads,
+ 2,
+ lang_model.model.config.head_dim,
+ )
+
+ cache_position = torch.arange(2, 4)
+ position_ids = cache_position.view(1, 1, -1).expand(3, 2, -1)
+
+ input_embeds = torch.randn((2, 2, embedding_size))
+ attention_mask = torch.ones([2, 4], dtype=torch.long)
+ input_names = ["attention_mask", "position_ids"]
+ output_names = ["logits", "hidden_states"]
+ past_key_values = []
+ for i in range(num_pkv):
+ kv = [torch.randn(pkv_shape) for _ in range(2)]
+ past_key_values.append(kv)
+ input_names.extend([f"past_key_values.{i}.key", f"past_key_values.{i}.value"])
+ output_names.extend([f"present.{i}.key", f"present.{i}.value"])
+ input_names.append("inputs_embeds")
+
+ example_input = {
+ "inputs_embeds": input_embeds,
+ "attention_mask": attention_mask,
+ "position_ids": position_ids,
+ "past_key_values": past_key_values,
+ }
+
+ input_shapes = [
+ ov.PartialShape([-1, -1]),
+ ov.PartialShape([3, -1, -1]),
+ ]
+ input_shapes += (
+ [
+ ov.PartialShape(
+ [
+ -1,
+ lang_model.model.config.num_key_value_heads,
+ -1,
+ lang_model.model.config.head_dim,
+ ]
+ )
+ ]
+ * 2
+ * num_pkv
+ )
+ input_shapes += [ov.PartialShape([-1, -1, input_embeds.shape[-1]])]
+ __make_16bit_traceable(lang_model)
+
+ ov_model = ov.convert_model(lang_model, example_input=example_input, input=input_shapes)
+ for input, input_name in zip(ov_model.inputs, input_names):
+ input.get_tensor().set_names({input_name})
+
+ for output, output_name in zip(ov_model.outputs, output_names):
+ output.get_tensor().set_names({output_name})
+ patch_stateful(ov_model, 2)
+ print("✅ Talker language model (MoE) successfully converted")
+
+ # if quantization_config is not None:
+ # print(f"⌛ Weights compression with {quantization_config['mode']} mode started")
+ # ov_model = nncf.compress_weights(ov_model, **quantization_config)
+ # print("✅ Weights compression finished")
+
+ ov.save_model(ov_model, talker_lang_path)
+ del ov_model
+ cleanup_torchscript_cache()
+ gc.collect()
+ print(f"✅ Talker model conversion finished. You can find results in {output_dir}")
+
+
+ if not talker_code_predictor_embedding_path.exists():
+ print("⌛ Convert talker code predictor embedding model")
+ def forward_wrap_code_predictor_embedding(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ generation_steps: Optional[int] = None,
+ ):
+ # Only compute the embedding for the current generation step to avoid unnecessary computation
+ # Get all embeddings for different generation steps
+ # TODO: avoid redundant computation
+ all_embeddings = torch.stack([self.get_input_embeddings()[i](input_ids) for i in range(len(self.get_input_embeddings()))])
+
+ # Select appropriate embedding based on generation_steps using torch.where
+ selected_embedding = all_embeddings[generation_steps]
+ return selected_embedding
+ # return self.get_input_embeddings()[generation_steps](input_ids)
+
+ talker_code_predictor = model.talker.code_predictor.model
+
+ talker_code_predictor._orig_forward = talker_code_predictor.forward
+ talker_code_predictor.forward = types.MethodType(forward_wrap_code_predictor_embedding, talker_code_predictor)
+
+ __make_16bit_traceable(talker_code_predictor.get_input_embeddings())
+ ov_model = ov.convert_model(
+ talker_code_predictor,
+ example_input={
+ "input_ids": torch.ones([2, 2], dtype=torch.int64),
+ "generation_steps": torch.tensor(1, dtype=torch.long),
+ },
+ )
+ ov.save_model(ov_model, talker_code_predictor_embedding_path)
+ del ov_model
+ cleanup_torchscript_cache()
+ gc.collect()
+ talker_code_predictor.forward = talker_code_predictor._orig_forward
+ print("✅ Talker Code Predictor Embedding model successfully converted")
+
+ if not talker_code_predictor_path.exists():
+ print("⌛ Convert Talker Code Predictor model")
+
+ def forward_wrap_code_predictor(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[list[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ generation_steps: Optional[int] = None,
+ **kwargs,
+ ):
+ if past_key_values is not None:
+ past_key_values = DynamicCache.from_legacy_cache(past_key_values)
+
+
+ # Code predictor forward pass
+ outputs = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=True,
+ return_dict=return_dict,
+ **kwargs,
+ )
+ if past_key_values is not None:
+ outputs["past_key_values"] = outputs["past_key_values"].to_legacy_cache()
+
+ hidden_states = outputs.last_hidden_state
+
+ # Use torch.where to select the appropriate head based on generation_steps
+ # TODO: avoid redundant computation
+ all_logits = torch.stack([head(hidden_states) for head in self.lm_head])
+ logits = all_logits[generation_steps]
+ # Update generation steps
+
+ output = (logits, outputs.hidden_states[0], outputs.past_key_values)
+ return output
+
+ code_predictor_model = model.talker.code_predictor
+ patch_cos_sin_cached_fp32(code_predictor_model)
+ if hasattr(code_predictor_model, "model"):
+ patch_cos_sin_cached_fp32(code_predictor_model.model)
+ num_pkv = code_predictor_model.model.config.num_hidden_layers
+ hidden_size = code_predictor_model.model.config.hidden_size
+ num_code_groups = code_predictor_model.model.config.num_code_groups
+
+ code_predictor_model._orig_forward = code_predictor_model.forward
+ code_predictor_model.forward = types.MethodType(forward_wrap_code_predictor, code_predictor_model)
+
+ pkv_shape = (
+ 2,
+ code_predictor_model.model.config.num_key_value_heads,
+ 2,
+ code_predictor_model.model.config.head_dim,
+ )
+
+ cache_position = torch.arange(2, 4)
+ position_ids = cache_position.view(1, -1) # Code predictor uses 2D position_ids
+
+ input_embeds = torch.randn((2, 2, hidden_size))
+ attention_mask = torch.ones([2, 4], dtype=torch.long)
+ generation_steps = torch.tensor(1, dtype=torch.long)
+
+ input_names = ["attention_mask", "position_ids"]
+ output_names = ["logits", "mid_residual_hiddens"]
+ past_key_values = []
+ for i in range(num_pkv):
+ kv = [torch.randn(pkv_shape) for _ in range(2)]
+ past_key_values.append(kv)
+ input_names.extend([f"past_key_values.{i}.key", f"past_key_values.{i}.value"])
+ output_names.extend([f"present.{i}.key", f"present.{i}.value"])
+ input_names.extend(["inputs_embeds", "generation_steps"])
+
+ example_input = {
+ "inputs_embeds": input_embeds,
+ "attention_mask": attention_mask,
+ "position_ids": position_ids,
+ "past_key_values": past_key_values,
+ "generation_steps": generation_steps,
+ }
+
+ input_shapes = [
+ ov.PartialShape([-1, -1]), # attention_mask
+ ov.PartialShape([-1, -1]), # position_ids (2D for code predictor)
+ ]
+ input_shapes += (
+ [
+ ov.PartialShape(
+ [
+ -1,
+ code_predictor_model.model.config.num_key_value_heads,
+ -1,
+ code_predictor_model.model.config.head_dim,
+ ]
+ )
+ ]
+ * 2
+ * num_pkv
+ )
+ input_shapes += [
+ ov.PartialShape([-1, -1, hidden_size]), # inputs_embeds
+ ov.PartialShape([]), # generation_steps (scalar)
+ ]
+
+ __make_16bit_traceable(code_predictor_model)
+
+ ov_model = ov.convert_model(code_predictor_model, example_input=example_input, input=input_shapes)
+ for input, input_name in zip(ov_model.inputs, input_names):
+ input.get_tensor().set_names({input_name})
+
+ for output, output_name in zip(ov_model.outputs, output_names):
+ output.get_tensor().set_names({output_name})
+
+ # Code predictor doesn't need stateful patch for KV cache in the same way
+ # as it's used for multi-step codec generation
+ patch_stateful(ov_model, 2)
+ print("✅ Talker Code Predictor model successfully converted")
+
+ # if quantization_config is not None:
+ # print(f"⌛ Weights compression with {quantization_config['mode']} mode started")
+ # ov_model = nncf.compress_weights(ov_model, **quantization_config)
+ # print("✅ Weights compression finished")
+
+ ov.save_model(ov_model, talker_code_predictor_path)
+ del ov_model
+ cleanup_torchscript_cache()
+ gc.collect()
+ print(f"✅ Talker Code Predictor model conversion finished. You can find results in {output_dir}")
+
+ # Convert Code2Wav model (new architecture for Qwen3OmniMoe)
+ if not code2wav_path.exists():
+ print("⌛ Convert code2wav model")
+ __make_16bit_traceable(model.code2wav)
+
+ input_shapes = [
+ ov.PartialShape([-1, model.code2wav.config.num_quantizers, -1]),
+ ]
+ ov_model = ov.convert_model(
+ model.code2wav,
+ example_input={
+ "codes": torch.ones([1, model.code2wav.config.num_quantizers, 300], dtype=torch.int64),
+ # "codes": torch.randint(0, 1024, [1, model.code2wav.config.num_quantizers, 300], dtype=torch.long),
+ },
+ # input=input_shapes,
+ )
+ ov.save_model(ov_model, code2wav_path)
+ del ov_model
+ cleanup_torchscript_cache()
+ gc.collect()
+ print("✅ Code2Wav model successfully converted")
+ print(f"✅ {model_id} model conversion finished. You can find results in {output_dir}")
+ del model
+
+def get_llm_pos_ids_for_vision(
+ start_idx: int,
+ vision_idx: int,
+ spatial_merge_size: int,
+ t_index: list[torch.Tensor],
+ grid_hs: list[torch.Tensor],
+ grid_ws: list[torch.Tensor],
+):
+ llm_pos_ids_list = []
+ llm_grid_h = grid_hs[vision_idx] // spatial_merge_size
+ llm_grid_w = grid_ws[vision_idx] // spatial_merge_size
+ h_index = torch.arange(llm_grid_h).view(1, -1, 1).expand(len(t_index), -1, llm_grid_w).flatten().float()
+ w_index = torch.arange(llm_grid_w).view(1, 1, -1).expand(len(t_index), llm_grid_h, -1).flatten().float()
+ t_index = torch.Tensor(t_index).view(-1, 1).expand(-1, llm_grid_h * llm_grid_w).flatten().float()
+ _llm_pos_ids = torch.stack([t_index, h_index, w_index])
+ llm_pos_ids_list.append(_llm_pos_ids + start_idx)
+ llm_pos_ids = torch.cat(llm_pos_ids_list, dim=1)
+ return llm_pos_ids
+
+def get_rope_index(
+ config,
+ input_ids: Optional[torch.LongTensor] = None,
+ image_grid_thw: Optional[torch.LongTensor] = None,
+ video_grid_thw: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ use_audio_in_video: bool = False,
+ audio_seqlens: Optional[torch.LongTensor] = None,
+ second_per_grids: Optional[torch.Tensor] = None,
+) -> tuple[torch.Tensor, torch.Tensor]:
+ """
+ Calculate the 3D rope index based on image and video's temporal, height and width in LLM.
+
+ Explanation:
+ Each embedding sequence contains vision embedding and text embedding or just contains text embedding.
+
+ For pure text embedding sequence, the rotary position embedding has no difference with modern LLMs.
+ Examples:
+ input_ids: [T T T T T], here T is for text.
+ temporal position_ids: [0, 1, 2, 3, 4]
+ height position_ids: [0, 1, 2, 3, 4]
+ width position_ids: [0, 1, 2, 3, 4]
+
+ For vision and text embedding sequence, we calculate 3D rotary position embedding for vision part
+ and 1D rotary position embedding for text part.
+ Examples:
+ Temporal (Time): 3 patches, representing different segments of the video in time.
+ Height: 2 patches, dividing each frame vertically.
+ Width: 2 patches, dividing each frame horizontally.
+ We also have some important parameters:
+ fps (Frames Per Second): The video's frame rate, set to 1. This means one frame is processed each second.
+ tokens_per_second: This is a crucial parameter. It dictates how many "time-steps" or "temporal tokens" are conceptually packed into a one-second interval of the video. In this case, we have 25 tokens per second. So each second of the video will be represented with 25 separate time points. It essentially defines the temporal granularity.
+ temporal_patch_size: The number of frames that compose one temporal patch. Here, it's 2 frames.
+ interval: The step size for the temporal position IDs, calculated as tokens_per_second * temporal_patch_size / fps. In this case, 25 * 2 / 1 = 50. This means that each temporal patch will be have a difference of 50 in the temporal position IDs.
+ input_ids: [V V V V V V V V V V V V T T T T T], here V is for vision.
+ vision temporal position_ids: [0, 0, 0, 0, 50, 50, 50, 50, 100, 100, 100, 100]
+ vision height position_ids: [0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1]
+ vision width position_ids: [0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1]
+ text temporal position_ids: [101, 102, 103, 104, 105]
+ text height position_ids: [101, 102, 103, 104, 105]
+ text width position_ids: [101, 102, 103, 104, 105]
+ Here we calculate the text start position_ids as the max vision position_ids plus 1.
+
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+ image_grid_thw (`torch.LongTensor` of shape `(num_images, 3)`, *optional*):
+ The temporal, height and width of feature shape of each image in LLM.
+ video_grid_thw (`torch.LongTensor` of shape `(num_videos, 3)`, *optional*):
+ The temporal, height and width of feature shape of each video in LLM.
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ use_audio_in_video (`bool`, *optional*):
+ If set to `True`, use the audio in video.
+ audio_seqlens (`torch.LongTensor` of shape `(num_audios)`, *optional*):
+ The length of feature shape of each audio in LLM.
+ second_per_grids (`torch.LongTensor` of shape `(num_videos)`, *optional*):
+ The time interval (in seconds) for each grid along the temporal dimension in the 3D position IDs.
+
+ Returns:
+ position_ids (`torch.LongTensor` of shape `(3, batch_size, sequence_length)`)
+ mrope_position_deltas (`torch.Tensor` of shape `(batch_size)`)
+ """
+ if hasattr(config, "vision_config"):
+ spatial_merge_size = config.vision_config.spatial_merge_size
+ else:
+ spatial_merge_size = config.spatial_merge_size
+ image_token_id = config.image_token_id
+ video_token_id = config.video_token_id
+ audio_token_id = config.audio_token_id
+ vision_start_token_id = config.vision_start_token_id
+ audio_start_token_id = config.audio_start_token_id
+ position_id_per_seconds = config.position_id_per_seconds
+
+ mrope_position_deltas = []
+ if input_ids is not None and (image_grid_thw is not None or video_grid_thw is not None):
+ total_input_ids = input_ids
+ if attention_mask is not None:
+ attention_mask = attention_mask == 1
+ position_ids = torch.zeros(
+ 3,
+ input_ids.shape[0],
+ input_ids.shape[1],
+ dtype=torch.float,
+ device=input_ids.device,
+ )
+ image_idx, video_idx, audio_idx = 0, 0, 0
+ for i, input_ids in enumerate(total_input_ids):
+ if attention_mask is not None:
+ input_ids = input_ids[attention_mask[i]]
+ image_nums, video_nums, audio_nums = 0, 0, 0
+ vision_start_indices = torch.argwhere(input_ids == vision_start_token_id).squeeze(1)
+ vision_tokens = input_ids[vision_start_indices + 1]
+ audio_nums = torch.sum(input_ids == audio_start_token_id)
+ image_nums = (vision_tokens == image_token_id).sum()
+ video_nums = (
+ (vision_tokens == audio_start_token_id).sum()
+ if use_audio_in_video
+ else (vision_tokens == video_token_id).sum()
+ )
+ input_tokens = input_ids.tolist()
+ llm_pos_ids_list: list = []
+ st = 0
+ remain_images, remain_videos, remain_audios = image_nums, video_nums, audio_nums
+ multimodal_nums = (
+ image_nums + audio_nums if use_audio_in_video else image_nums + video_nums + audio_nums
+ )
+ for _ in range(multimodal_nums):
+ st_idx = llm_pos_ids_list[-1].max() + 1 if len(llm_pos_ids_list) > 0 else 0
+ if (image_token_id in input_tokens or video_token_id in input_tokens) and (
+ remain_videos > 0 or remain_images > 0
+ ):
+ ed_vision_start = input_tokens.index(vision_start_token_id, st)
+ else:
+ ed_vision_start = len(input_tokens) + 1
+ if audio_token_id in input_tokens and remain_audios > 0:
+ ed_audio_start = input_tokens.index(audio_start_token_id, st)
+ else:
+ ed_audio_start = len(input_tokens) + 1
+ min_ed = min(ed_vision_start, ed_audio_start)
+
+ text_len = min_ed - st
+ if text_len != 0:
+ llm_pos_ids_list.append(torch.arange(text_len).view(1, -1).expand(3, -1) + st_idx)
+ st_idx += text_len
+ # Audio in Video
+ if min_ed == ed_vision_start and ed_vision_start + 1 == ed_audio_start:
+ bos_len, eos_len = 2, 2
+ else:
+ bos_len, eos_len = 1, 1
+ llm_pos_ids_list.append(torch.arange(bos_len).view(1, -1).expand(3, -1) + st_idx)
+ st_idx += bos_len
+ # Audio Only
+ if min_ed == ed_audio_start:
+ audio_len = _get_feat_extract_output_lengths(audio_seqlens[audio_idx])
+ llm_pos_ids = torch.arange(audio_len).view(1, -1).expand(3, -1) + st_idx
+ llm_pos_ids_list.append(llm_pos_ids)
+
+ st += int(text_len + bos_len + audio_len + eos_len)
+ audio_idx += 1
+ remain_audios -= 1
+
+ # Image Only
+ elif min_ed == ed_vision_start and input_ids[ed_vision_start + 1] == image_token_id:
+ grid_t = image_grid_thw[image_idx][0]
+ grid_hs = image_grid_thw[:, 1]
+ grid_ws = image_grid_thw[:, 2]
+ t_index = (torch.arange(grid_t) * 1 * position_id_per_seconds).float()
+ llm_pos_ids = get_llm_pos_ids_for_vision(
+ st_idx, image_idx, spatial_merge_size, t_index, grid_hs, grid_ws
+ )
+ image_len = image_grid_thw[image_idx].prod() // (spatial_merge_size**2)
+ llm_pos_ids_list.append(llm_pos_ids)
+
+ st += int(text_len + bos_len + image_len + eos_len)
+ image_idx += 1
+ remain_images -= 1
+
+ # Video Only
+ elif min_ed == ed_vision_start and input_ids[ed_vision_start + 1] == video_token_id:
+ grid_t = video_grid_thw[video_idx][0]
+ grid_hs = video_grid_thw[:, 1]
+ grid_ws = video_grid_thw[:, 2]
+ t_index = (
+ torch.arange(grid_t) * second_per_grids[video_idx].cpu().float() * position_id_per_seconds
+ ).float()
+ llm_pos_ids = get_llm_pos_ids_for_vision(
+ st_idx, video_idx, spatial_merge_size, t_index, grid_hs, grid_ws
+ )
+ video_len = video_grid_thw[video_idx].prod() // (spatial_merge_size**2)
+ llm_pos_ids_list.append(llm_pos_ids)
+
+ st += int(text_len + bos_len + video_len + eos_len)
+ video_idx += 1
+ remain_videos -= 1
+
+ # Audio in Video
+ elif min_ed == ed_vision_start and ed_vision_start + 1 == ed_audio_start:
+ audio_len = _get_feat_extract_output_lengths(audio_seqlens[audio_idx])
+ audio_llm_pos_ids = torch.arange(audio_len).view(1, -1).expand(3, -1) + st_idx
+ grid_t = video_grid_thw[video_idx][0]
+ grid_hs = video_grid_thw[:, 1]
+ grid_ws = video_grid_thw[:, 2]
+
+ t_index = (
+ torch.arange(grid_t) * second_per_grids[video_idx].cpu().float() * position_id_per_seconds
+ ).float()
+ video_llm_pos_ids = get_llm_pos_ids_for_vision(
+ st_idx, video_idx, spatial_merge_size, t_index, grid_hs, grid_ws
+ )
+ video_data_index, audio_data_index = 0, 0
+ while (
+ video_data_index < video_llm_pos_ids.shape[-1]
+ and audio_data_index < audio_llm_pos_ids.shape[-1]
+ ):
+ if video_llm_pos_ids[0][video_data_index] <= audio_llm_pos_ids[0][audio_data_index]:
+ llm_pos_ids_list.append(video_llm_pos_ids[:, video_data_index : video_data_index + 1])
+ video_data_index += 1
+ else:
+ llm_pos_ids_list.append(audio_llm_pos_ids[:, audio_data_index : audio_data_index + 1])
+ audio_data_index += 1
+ if video_data_index < video_llm_pos_ids.shape[-1]:
+ llm_pos_ids_list.append(
+ video_llm_pos_ids[:, video_data_index : video_llm_pos_ids.shape[-1]]
+ )
+ if audio_data_index < audio_llm_pos_ids.shape[-1]:
+ llm_pos_ids_list.append(
+ audio_llm_pos_ids[:, audio_data_index : audio_llm_pos_ids.shape[-1]]
+ )
+ video_len = video_grid_thw[video_idx].prod() // (spatial_merge_size**2)
+
+ st += int(text_len + bos_len + audio_len + video_len + eos_len)
+
+ audio_idx += 1
+ video_idx += 1
+ remain_videos -= 1
+ remain_audios -= 1
+ st_idx = llm_pos_ids_list[-1].max() + 1 if len(llm_pos_ids_list) > 0 else 0
+ llm_pos_ids_list.append(torch.arange(eos_len).view(1, -1).expand(3, -1) + st_idx)
+
+ if st < len(input_tokens):
+ st_idx = llm_pos_ids_list[-1].max() + 1 if len(llm_pos_ids_list) > 0 else 0
+ text_len = len(input_tokens) - st
+ llm_pos_ids_list.append(torch.arange(text_len).view(1, -1).expand(3, -1) + st_idx)
+ llm_positions = torch.cat([item.float() for item in llm_pos_ids_list], dim=1).reshape(3, -1)
+
+ position_ids[..., i, attention_mask[i] == 1] = llm_positions.to(position_ids.device)
+ mrope_position_deltas.append(llm_positions.max() + 1 - len(input_ids))
+ mrope_position_deltas = torch.tensor(mrope_position_deltas, device=input_ids.device).unsqueeze(1)
+
+ return position_ids, mrope_position_deltas
+ else:
+ position_ids = attention_mask.float().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ position_ids = position_ids.unsqueeze(0).expand(3, -1, -1).to(attention_mask.device)
+ max_position_ids = position_ids.max(0, keepdim=False)[0].max(-1, keepdim=True)[0]
+ mrope_position_deltas = max_position_ids + 1 - torch.sum(attention_mask, dim=-1, keepdim=True)
+
+ return position_ids, mrope_position_deltas
+
+class SinusoidsPositionEmbedding(nn.Module):
+ def __init__(self, length, channels, max_timescale=10000):
+ super().__init__()
+ if channels % 2 != 0:
+ raise ValueError("SinusoidsPositionEmbedding needs even channels input")
+ log_timescale_increment = np.log(max_timescale) / (channels // 2 - 1)
+ inv_timescales = torch.exp(-log_timescale_increment * torch.arange(channels // 2).float())
+ scaled_time = torch.arange(length)[:, np.newaxis] * inv_timescales[np.newaxis, :]
+ self.register_buffer(
+ "positional_embedding",
+ torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], dim=1),
+ persistent=False,
+ )
+
+ def forward(self, seqlen: int):
+ return self.positional_embedding[:seqlen, :]
+
+
+class OVQwen3OmniMoeThinkerForConditionalGeneration(GenerationMixin):
+ _is_stateful = False
+
+ def __init__(self, model_dir, device, config):
+ self.model = core.read_model(model_dir / THINKER_LANGUAGE_NAME)
+ self.audio = core.compile_model(model_dir / THINKER_AUDIO_NAME, device)
+ self.audio_state = core.compile_model(model_dir / THINKER_AUDIO_STATE_NAME, device)
+ self.vision_embeddings = core.compile_model(model_dir / THINKER_VISION_NAME, device)
+ self.vision_embeddings_pos = core.compile_model(model_dir / THINKER_VISION_POS_NAME, device)
+ self.vision_embeddings_merger = core.compile_model(model_dir / THINKER_VISION_MERGER_NAME, device)
+ self.embed_tokens = core.compile_model(model_dir / THINKER_EMBEDDING_NAME, device)
+ self.get_input_embeddings = lambda: self._embedding_wrapper
+ self._embedding_wrapper = self._create_embedding_wrapper()
+ self.input_names = {key.get_any_name(): idx for idx, key in enumerate(self.model.inputs)}
+ self.output_names = {key.get_any_name(): idx for idx, key in enumerate(self.model.outputs)}
+ compiled_model = core.compile_model(self.model, device)
+ self.request = compiled_model.create_infer_request()
+ self.main_input_name = "input_ids"
+ self.config = config
+ self.max_source_positions = self.config.audio_config.max_source_positions
+ embed_dim = self.config.audio_config.d_model
+ self.n_window_infer = self.config.audio_config.n_window_infer
+
+ self.positional_embedding = SinusoidsPositionEmbedding(self.max_source_positions, embed_dim)
+ head_dim = self.config.vision_config.hidden_size // config.vision_config.num_heads
+ self.rotary_pos_emb = Qwen3OmniMoeVisionRotaryEmbedding(head_dim // 2)
+ self.num_grid_per_side = int(self.config.vision_config.num_position_embeddings**0.5)
+ self.n_window = self.config.audio_config.n_window
+ self.generation_config = GenerationConfig.from_model_config(self.config)
+ self.device = torch.device("cpu")
+ self.num_pkv = 2
+ self._past_length = None
+ self.next_beam_idx = None
+ self.spatial_merge_size = self.config.vision_config.spatial_merge_size
+ self.patch_size = self.config.vision_config.patch_size
+ self.spatial_merge_unit = self.config.vision_config.spatial_merge_size * self.config.vision_config.spatial_merge_size
+ self._skip_keys_device_placement = "past_key_values"
+ self._supports_flash_attn_2 = True
+ self._supports_sdpa = True
+ self._supports_static_cache = True
+
+
+ self.num_layers = len(self.config.vision_config.deepstack_visual_indexes)
+ self.emd_dim = self.config.text_config.hidden_size
+
+ def _create_embedding_wrapper(self):
+ """Create a callable wrapper for embeddings that works with OpenVINO"""
+ def embedding_fn(input_ids):
+ result = self.embed_tokens(input_ids)[0]
+ return torch.from_numpy(result)
+ return embedding_fn
+
+ def can_generate(self):
+ """Returns True to validate the check that the model using `GenerationMixin.generate()` can indeed generate."""
+ return True
+
+
+ def fast_pos_embed_interpolate(self, grid_thw):
+ grid_ts, grid_hs, grid_ws = grid_thw[:, 0], grid_thw[:, 1], grid_thw[:, 2]
+
+ idx_list = [[] for _ in range(4)]
+ weight_list = [[] for _ in range(4)]
+
+ for t, h, w in zip(grid_ts, grid_hs, grid_ws):
+ h_idxs = torch.linspace(0, self.num_grid_per_side - 1, h)
+ w_idxs = torch.linspace(0, self.num_grid_per_side - 1, w)
+
+ h_idxs_floor = h_idxs.int()
+ w_idxs_floor = w_idxs.int()
+ h_idxs_ceil = (h_idxs.int() + 1).clip(max=self.num_grid_per_side - 1)
+ w_idxs_ceil = (w_idxs.int() + 1).clip(max=self.num_grid_per_side - 1)
+
+ dh = h_idxs - h_idxs_floor
+ dw = w_idxs - w_idxs_floor
+
+ base_h = h_idxs_floor * self.num_grid_per_side
+ base_h_ceil = h_idxs_ceil * self.num_grid_per_side
+
+ indices = [
+ (base_h[None].T + w_idxs_floor[None]).flatten(),
+ (base_h[None].T + w_idxs_ceil[None]).flatten(),
+ (base_h_ceil[None].T + w_idxs_floor[None]).flatten(),
+ (base_h_ceil[None].T + w_idxs_ceil[None]).flatten(),
+ ]
+
+ weights = [
+ ((1 - dh)[None].T * (1 - dw)[None]).flatten(),
+ ((1 - dh)[None].T * dw[None]).flatten(),
+ (dh[None].T * (1 - dw)[None]).flatten(),
+ (dh[None].T * dw[None]).flatten(),
+ ]
+
+ for i in range(4):
+ idx_list[i].extend(indices[i].tolist())
+ weight_list[i].extend(weights[i].tolist())
+
+ idx_tensor = torch.tensor(idx_list)
+ weight_tensor = torch.tensor(weight_list)
+ pos_embeds = torch.from_numpy(self.vision_embeddings_pos(idx_tensor)[0]) * weight_tensor[:, :, None]
+ patch_pos_embeds = pos_embeds[0] + pos_embeds[1] + pos_embeds[2] + pos_embeds[3]
+
+ patch_pos_embeds = patch_pos_embeds.split([h * w for h, w in zip(grid_hs, grid_ws)])
+
+ patch_pos_embeds_permute = []
+ merge_size = self.config.vision_config.spatial_merge_size
+ for pos_embed, t, h, w in zip(patch_pos_embeds, grid_ts, grid_hs, grid_ws):
+ pos_embed = pos_embed.repeat(t, 1)
+ pos_embed = (
+ pos_embed.view(t, h // merge_size, merge_size, w // merge_size, merge_size, -1)
+ .permute(0, 1, 3, 2, 4, 5)
+ .flatten(0, 4)
+ )
+ patch_pos_embeds_permute.append(pos_embed)
+ patch_pos_embeds = torch.cat(patch_pos_embeds_permute)
+ return patch_pos_embeds
+
+ def visual(self, hidden_states, grid_thw, **kwargs):
+ hidden_states = torch.from_numpy(self.vision_embeddings(hidden_states)[0])
+ pos_embeds = self.fast_pos_embed_interpolate(grid_thw)
+ hidden_states = hidden_states + pos_embeds
+
+ rotary_pos_emb = self.rot_pos_emb(grid_thw)
+ seq_len, _ = hidden_states.size()
+ hidden_states = hidden_states.reshape(seq_len, -1)
+ rotary_pos_emb = rotary_pos_emb.reshape(seq_len, -1)
+ cu_seqlens = torch.repeat_interleave(grid_thw[:, 1] * grid_thw[:, 2], grid_thw[:, 0]).cumsum(
+ dim=0, dtype=torch.int32
+ )
+ cu_seqlens = torch.nn.functional.pad(cu_seqlens, (1, 0), value=0)
+ attention_mask = torch.zeros((1, hidden_states.shape[0], hidden_states.shape[0]), dtype=torch.bool)
+ causal_mask = torch.zeros_like(attention_mask, dtype=torch.float32)
+ for i in range(1, len(cu_seqlens)):
+ attention_mask[..., cu_seqlens[i - 1] : cu_seqlens[i], cu_seqlens[i - 1] : cu_seqlens[i]] = True
+
+ causal_mask.masked_fill_(torch.logical_not(attention_mask), float("-inf"))
+
+ res = self.vision_embeddings_merger(
+ [hidden_states, causal_mask, rotary_pos_emb]
+ )
+ return torch.from_numpy(res[0]), torch.from_numpy(res[1])
+
+ def get_video_features(
+ self, pixel_values_videos: torch.FloatTensor, video_grid_thw: Optional[torch.LongTensor] = None
+ ):
+ """
+ Encodes videos into continuous embeddings that can be forwarded to the language model.
+
+ Args:
+ pixel_values_videos (`torch.FloatTensor` of shape `(batch_size, num_channels, image_size, image_size)`):
+ The tensors corresponding to the input videos.
+ video_grid_thw (`torch.LongTensor` of shape `(num_videos, 3)`, *optional*):
+ The temporal, height and width of feature shape of each video in LLM.
+ """
+ video_embeds = self.visual(pixel_values_videos, grid_thw=video_grid_thw)
+ return video_embeds
+
+ def get_image_features(self, pixel_values: torch.FloatTensor, image_grid_thw: Optional[torch.LongTensor] = None):
+ """
+ Encodes images into continuous embeddings that can be forwarded to the language model.
+
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, image_size, image_size)`):
+ The tensors corresponding to the input images.
+ image_grid_thw (`torch.LongTensor` of shape `(num_images, 3)`, *optional*):
+ The temporal, height and width of feature shape of each image in LLM.
+ """
+ image_embeds = self.visual(pixel_values, grid_thw=image_grid_thw)
+ return image_embeds
+
+ def audio_tower(
+ self,
+ input_features,
+ feature_lens=None,
+ aftercnn_lens=None,
+ ):
+ r"""
+ feature_lens (`torch.LongTensor` of shape `(batch_size,)`):
+ mel length
+ aftercnn_lens (`torch.LongTensor` of shape `(batch_size,)`):
+ mel length after cnn
+ """
+ aftercnn_lens = _get_feat_extract_output_lengths(feature_lens)
+ chunk_num = torch.ceil(feature_lens / (self.n_window * 2)).long()
+
+ chunk_lengths = torch.tensor(
+ [self.n_window * 2] * chunk_num.sum(),
+ dtype=torch.long,
+ device=feature_lens.device,
+ )
+ tail_chunk_index = torch.nn.functional.pad(chunk_num, (1, 0), value=-1).cumsum(0)[1:]
+ chunk_lengths[tail_chunk_index] = feature_lens % (self.n_window * 2)
+ chunk_lengths[chunk_lengths == 0] = self.n_window * 2
+
+ chunk_list = input_features.T.split(chunk_lengths.tolist(), dim=0)
+ padded_feature = nn.utils.rnn.pad_sequence(chunk_list, batch_first=True).transpose(1, 2)
+ feature_lens_after_cnn = _get_feat_extract_output_lengths(chunk_lengths)
+ padded_mask_after_cnn = nn.utils.rnn.pad_sequence(
+ [torch.ones(length, dtype=torch.bool, device=padded_feature.device) for length in feature_lens_after_cnn],
+ batch_first=True,
+ )
+ # Split to chunk to avoid OOM during convolution
+ padded_embed = torch.from_numpy(self.audio(padded_feature)[0])
+
+ positional_embedding = (
+ self.positional_embedding.positional_embedding[: padded_embed.shape[1], :]
+ .unsqueeze(0)
+ .to(padded_embed.dtype)
+ )
+ padded_embed = padded_embed + positional_embedding
+ hidden_states = padded_embed[padded_mask_after_cnn]
+ cu_chunk_lens = [0]
+ window_aftercnn = padded_mask_after_cnn.shape[-1] * (self.n_window_infer // (self.n_window * 2))
+ for cnn_len in aftercnn_lens:
+ cu_chunk_lens += [window_aftercnn] * (cnn_len // window_aftercnn)
+ remainder = cnn_len % window_aftercnn
+ if remainder != 0:
+ cu_chunk_lens += [remainder]
+ cu_seqlens = torch.tensor(cu_chunk_lens, device=aftercnn_lens.device).cumsum(-1, dtype=torch.int32)
+ hidden_states = torch.from_numpy(self.audio_state([hidden_states, cu_seqlens])[0])
+ return BaseModelOutput(last_hidden_state=hidden_states)
+
+ def get_audio_features(
+ self,
+ input_features: torch.FloatTensor,
+ feature_attention_mask: Optional[torch.LongTensor] = None,
+ audio_feature_lengths: Optional[torch.LongTensor] = None,
+ ):
+ """
+ Encodes audios into continuous embeddings that can be forwarded to the language model.
+
+ Args:
+ input_features (`torch.FloatTensor`):
+ The tensors corresponding to the input audios.
+ feature_attention_mask (`torch.LongTensor`, *optional*):
+ Mask to avoid performing attention on padding feature indices. Mask values selected in `[0, 1]`:
+ audio_feature_lengths (`torch.LongTensor` of shape `(num_audios)`, *optional*):
+ The length of feature shape of each audio in LLM.
+ """
+ if feature_attention_mask is not None:
+ audio_feature_lengths = torch.sum(feature_attention_mask, dim=1)
+ input_features = input_features.permute(0, 2, 1)[feature_attention_mask.bool()].permute(1, 0)
+ else:
+ audio_feature_lengths = None
+
+ feature_lens = audio_feature_lengths if audio_feature_lengths is not None else feature_attention_mask.sum(-1)
+ audio_outputs = self.audio_tower(
+ input_features,
+ feature_lens=feature_lens,
+ )
+ audio_features = audio_outputs.last_hidden_state
+
+ return audio_features
+
+ def get_placeholder_mask(
+ self,
+ input_ids: torch.LongTensor,
+ inputs_embeds: torch.FloatTensor,
+ image_features: Optional[torch.FloatTensor] = None,
+ video_features: Optional[torch.FloatTensor] = None,
+ ):
+ """
+ Obtains multimodal placeholder mask from `input_ids` or `inputs_embeds`, and checks that the placeholder token count is
+ equal to the length of multimodal features. If the lengths are different, an error is raised.
+ """
+ if input_ids is None:
+ special_image_mask = inputs_embeds == self.get_input_embeddings()(
+ torch.tensor(self.config.image_token_id, dtype=torch.long, device=inputs_embeds.device)
+ )
+ special_image_mask = special_image_mask.all(-1)
+ special_video_mask = inputs_embeds == self.get_input_embeddings()(
+ torch.tensor(self.config.video_token_id, dtype=torch.long, device=inputs_embeds.device)
+ )
+ special_video_mask = special_video_mask.all(-1)
+ special_audio_mask = (
+ inputs_embeds
+ == self.get_input_embeddings()(
+ torch.tensor(self.config.audio_token_id, dtype=torch.long, device=inputs_embeds.device)
+ )
+ ).all(-1)
+ else:
+ special_image_mask = input_ids == self.config.image_token_id
+ special_video_mask = input_ids == self.config.video_token_id
+ special_audio_mask = input_ids == self.config.audio_token_id
+
+ n_image_tokens = special_image_mask.sum()
+ special_image_mask = special_image_mask.unsqueeze(-1).expand_as(inputs_embeds).to(inputs_embeds.device)
+ if image_features is not None and inputs_embeds[special_image_mask].numel() != image_features.numel():
+ raise ValueError(
+ f"Image features and image tokens do not match: tokens: {n_image_tokens}, features {image_features.shape[0]}"
+ )
+
+ n_video_tokens = special_video_mask.sum()
+ special_video_mask = special_video_mask.unsqueeze(-1).expand_as(inputs_embeds).to(inputs_embeds.device)
+ if video_features is not None and inputs_embeds[special_video_mask].numel() != video_features.numel():
+ raise ValueError(
+ f"Videos features and image tokens do not match: tokens: {n_video_tokens}, features {video_features.shape[0]}"
+ )
+
+ special_audio_mask = special_audio_mask.unsqueeze(-1).expand_as(inputs_embeds).to(inputs_embeds.device)
+ return special_image_mask, special_video_mask, special_audio_mask
+
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ attention_mask=None,
+ inputs_embeds=None,
+ cache_position=None,
+ position_ids=None,
+ use_cache=True,
+ pixel_values=None,
+ pixel_values_videos=None,
+ image_grid_thw=None,
+ video_grid_thw=None,
+ input_features=None,
+ feature_attention_mask=None,
+ use_audio_in_video=False,
+ video_second_per_grid=None,
+ **kwargs,
+ ):
+ if past_key_values != ((),):
+ past_key_values = None
+ model_inputs = super().prepare_inputs_for_generation(
+ input_ids,
+ past_key_values=past_key_values,
+ attention_mask=attention_mask,
+ inputs_embeds=inputs_embeds,
+ cache_position=cache_position,
+ position_ids=position_ids,
+ use_cache=use_cache,
+ pixel_values=pixel_values,
+ pixel_values_videos=pixel_values_videos,
+ image_grid_thw=image_grid_thw,
+ video_grid_thw=video_grid_thw,
+ input_features=input_features,
+ feature_attention_mask=feature_attention_mask,
+ use_audio_in_video=use_audio_in_video,
+ video_second_per_grid=video_second_per_grid,
+ **kwargs,
+ )
+ model_inputs["position_ids"] = None
+
+ if cache_position[0] != 0:
+ model_inputs["pixel_values"] = None
+ model_inputs["pixel_values_videos"] = None
+ model_inputs["input_features"] = None
+
+ return model_inputs
+
+ def rot_pos_emb(self, grid_thw: torch.Tensor) -> torch.Tensor:
+ merge_size = self.spatial_merge_size
+
+ max_hw = int(grid_thw[:, 1:].max().item())
+ freq_table = self.rotary_pos_emb(max_hw) # (max_hw, dim // 2)
+ device = freq_table.device
+
+ total_tokens = int(torch.prod(grid_thw, dim=1).sum().item())
+ pos_ids = torch.empty((total_tokens, 2), dtype=torch.long, device=device)
+
+ offset = 0
+ for num_frames, height, width in grid_thw:
+ merged_h, merged_w = height // merge_size, width // merge_size
+
+ block_rows = torch.arange(merged_h, device=device) # block row indices
+ block_cols = torch.arange(merged_w, device=device) # block col indices
+ intra_row = torch.arange(merge_size, device=device) # intra-block row offsets
+ intra_col = torch.arange(merge_size, device=device) # intra-block col offsets
+
+ # Compute full-resolution positions
+ row_idx = block_rows[:, None, None, None] * merge_size + intra_row[None, None, :, None]
+ col_idx = block_cols[None, :, None, None] * merge_size + intra_col[None, None, None, :]
+
+ row_idx = row_idx.expand(merged_h, merged_w, merge_size, merge_size).reshape(-1)
+ col_idx = col_idx.expand(merged_h, merged_w, merge_size, merge_size).reshape(-1)
+
+ coords = torch.stack((row_idx, col_idx), dim=-1)
+
+ if num_frames > 1:
+ coords = coords.repeat(num_frames, 1)
+
+ num_tokens = coords.shape[0]
+ pos_ids[offset : offset + num_tokens] = coords
+ offset += num_tokens
+
+ embeddings = freq_table[pos_ids] # lookup rotary embeddings
+ embeddings = embeddings.flatten(1)
+ return embeddings
+
+ def __call__(
+ self,
+ input_ids: torch.LongTensor = None,
+ pixel_values: torch.Tensor = None,
+ position_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.BoolTensor] = None,
+ past_key_values: Optional[tuple[tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ **kwargs,
+ ) -> CausalLMOutputWithPast:
+ return self.forward(
+ input_ids=input_ids,
+ pixel_values=pixel_values,
+ attention_mask=attention_mask,
+ past_key_values=past_key_values,
+ position_ids=position_ids,
+ inputs_embeds=inputs_embeds,
+ **kwargs,
+ )
+
+ def forward(
+ self,
+ input_ids=None,
+ input_features=None,
+ pixel_values=None,
+ pixel_values_videos=None,
+ image_grid_thw=None,
+ video_grid_thw=None,
+ attention_mask=None,
+ feature_attention_mask=None,
+ audio_feature_lengths=None,
+ position_ids=None,
+ past_key_values=None,
+ inputs_embeds=None,
+ rope_deltas=None,
+ labels=None,
+ use_cache=None,
+ output_router_logits: Optional[bool] = None,
+ use_audio_in_video=None,
+ cache_position=None,
+ video_second_per_grid=None,
+ **kwargs,
+ ) -> Union[tuple, Qwen3OmniMoeThinkerCausalLMOutputWithPast]:
+ output_router_logits = (
+ output_router_logits if output_router_logits is not None else self.config.text_config.output_router_logits
+ )
+
+ if inputs_embeds is None:
+ inputs_embeds = self.get_input_embeddings()(input_ids)
+
+ visual_embeds_multiscale = None
+ visual_pos_masks = None
+ # 2. Merge text , audios , image and video
+ if input_features is not None:
+ audio_features = self.get_audio_features(
+ input_features,
+ feature_attention_mask=feature_attention_mask,
+ audio_feature_lengths=audio_feature_lengths,
+ )
+ audio_features = audio_features.to(inputs_embeds.device, inputs_embeds.dtype)
+ _, _, audio_mask = self.get_placeholder_mask(input_ids, inputs_embeds=inputs_embeds)
+ inputs_embeds = inputs_embeds.masked_scatter(audio_mask, audio_features)
+
+ if pixel_values is not None:
+ image_embeds, image_embeds_multiscale = self.get_image_features(pixel_values, image_grid_thw)
+ image_embeds = image_embeds.to(inputs_embeds.device, inputs_embeds.dtype)
+ image_mask, _, _ = self.get_placeholder_mask(
+ input_ids, inputs_embeds=inputs_embeds, image_features=image_embeds
+ )
+ inputs_embeds = inputs_embeds.masked_scatter(image_mask, image_embeds)
+
+ visual_pos_masks = image_mask
+ visual_embeds_multiscale = image_embeds_multiscale
+
+ if pixel_values_videos is not None:
+ video_embeds, video_embeds_multiscale = self.get_video_features(pixel_values_videos, video_grid_thw)
+
+ video_embeds = video_embeds.to(inputs_embeds.device, inputs_embeds.dtype)
+ _, video_mask, _ = self.get_placeholder_mask(
+ input_ids, inputs_embeds=inputs_embeds, video_features=video_embeds
+ )
+ inputs_embeds = inputs_embeds.masked_scatter(video_mask, video_embeds)
+
+ if visual_embeds_multiscale is None:
+ visual_embeds_multiscale = video_embeds_multiscale
+ visual_pos_masks = video_mask
+ else:
+ visual_pos_masks = video_mask | image_mask
+ visual_embeds_multiscale_joint = ()
+ image_mask_joint = image_mask[visual_pos_masks]
+ video_mask_joint = video_mask[visual_pos_masks]
+ for img_embed, vid_embed in zip(visual_embeds_multiscale, video_embeds_multiscale):
+ embed_joint = img_embed.new_zeros(visual_pos_masks.sum(), img_embed.shape[-1])
+ embed_joint[image_mask_joint, :] = img_embed
+ embed_joint[video_mask_joint, :] = vid_embed
+ visual_embeds_multiscale_joint = visual_embeds_multiscale_joint + (embed_joint,)
+ visual_embeds_multiscale = visual_embeds_multiscale_joint
+
+ if feature_attention_mask is not None:
+ audio_feature_lengths = torch.sum(feature_attention_mask, dim=1)
+ else:
+ audio_feature_lengths = None
+
+ if attention_mask is not None and position_ids is None:
+ if (
+ cache_position is None
+ or (cache_position is not None and cache_position[0] == 0)
+ or self.rope_deltas is None
+ ):
+ delta0 = (1 - attention_mask).sum(dim=-1).unsqueeze(1)
+ position_ids, rope_deltas = get_rope_index(self.config,
+ input_ids,
+ image_grid_thw,
+ video_grid_thw,
+ attention_mask,
+ use_audio_in_video,
+ audio_feature_lengths,
+ video_second_per_grid,
+ )
+ rope_deltas = rope_deltas - delta0
+ self.rope_deltas = rope_deltas
+ else:
+ batch_size, seq_length = input_ids.shape
+ delta = cache_position[0] + self.rope_deltas if cache_position is not None else 0
+ position_ids = torch.arange(seq_length, device=input_ids.device)
+ position_ids = position_ids.view(1, -1).expand(batch_size, -1)
+ position_ids = position_ids.add(delta)
+ position_ids = position_ids.unsqueeze(0).expand(3, -1, -1)
+
+ if past_key_values is None:
+ self.request.reset_state()
+ self.next_beam_idx = np.arange(inputs_embeds.shape[0], dtype=int)
+ self._past_length = 0
+
+ inputs = {}
+ inputs["inputs_embeds"] = inputs_embeds
+ inputs["attention_mask"] = attention_mask
+ inputs["position_ids"] = position_ids
+
+ # Add DeepStack visual features if available
+ if visual_pos_masks is not None:
+ inputs["visual_pos_masks"] = visual_pos_masks
+ else:
+ inputs["visual_pos_masks"] = torch.zeros((1, 1, self.emd_dim), dtype=torch.bool)
+ if visual_embeds_multiscale is not None:
+ inputs["deepstack_visual_embeds"] = torch.Tensor(visual_embeds_multiscale)
+ else:
+ inputs["deepstack_visual_embeds"] = torch.zeros((self.num_layers, 1, self.emd_dim), dtype=torch.float32)
+
+ if "beam_idx" in self.input_names:
+ inputs["beam_idx"] = self.next_beam_idx if self.next_beam_idx is not None else np.arange(inputs_embeds.shape[0], dtype=int)
+ self.request.start_async(inputs, share_inputs=True)
+ self.request.wait()
+ logits = self.request.get_tensor("logits").data
+ hidden_states = self.request.get_tensor("hidden_states").data
+ logits = torch.from_numpy(logits).to(self.device)
+ hidden_states = torch.from_numpy(hidden_states).to(self.device)
+ past_key_values = ((),)
+ embeds_to_talker = inputs_embeds.clone()
+ hidden_states_output = hidden_states.clone()
+ return Qwen3OmniMoeThinkerCausalLMOutputWithPast(
+ logits=logits,
+ past_key_values=past_key_values,
+ rope_deltas=rope_deltas,
+ hidden_states=(embeds_to_talker, hidden_states_output),
+ )
+
+ def _reorder_cache(self, past_key_values: tuple[tuple[torch.Tensor]], beam_idx: torch.Tensor) -> tuple[tuple[torch.Tensor]]:
+ """
+ This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or
+ [`~PreTrainedModel.beam_sample`] is called.
+ This is required to match `past_key_values` with the correct beam_idx at every generation step.
+ """
+ self.next_beam_idx = np.array(beam_idx) # save beam_idx to be used as an input in the next iteration
+ return past_key_values
+
+ def _get_past_length(self, past_key_values=None):
+ if past_key_values is None:
+ return 0
+ return self._past_length
+
+
+
+class OVQwen3OmniMoeTalkerCodePredictorModelForConditionalGeneration(GenerationMixin):
+ _is_stateful = False
+
+ def __init__(self, model_dir, device, config):
+ self.config = config
+ self.code_predictor_embedding = core.compile_model(model_dir / TALKER_CODE_PREDICTOR_EMBEDDING_NAME, "CPU")
+ self.model = core.read_model(model_dir / TALKER_CODE_PREDICTOR_NAME)
+ self.input_names = {key.get_any_name(): idx for idx, key in enumerate(self.model.inputs)}
+ self.output_names = {key.get_any_name(): idx for idx, key in enumerate(self.model.outputs)}
+ compiled_model = core.compile_model(self.model, device)
+ self.request = compiled_model.create_infer_request()
+ self.get_input_embeddings = lambda: self._embedding_wrapper
+ self._embedding_wrapper = self._create_embedding_wrapper()
+ self.main_input_name = "input_ids"
+ self.device = torch.device("cpu")
+ self.generation_config = GenerationConfig.from_model_config(self.config)
+ self.num_pkv = 2
+ self._past_length = None
+ self.next_beam_idx = None
+ self._skip_keys_device_placement = "past_key_values"
+ self._supports_flash_attn_2 = True
+ self._supports_sdpa = True
+ self._supports_cache_class = True
+ self._supports_static_cache = True
+
+ def _create_embedding_wrapper(self):
+ """Create a callable wrapper for embeddings that works with OpenVINO"""
+ def embedding_fn(input_ids, generation_steps):
+ result = self.code_predictor_embedding([input_ids, generation_steps])[0]
+ return torch.from_numpy(result)
+ return embedding_fn
+
+
+ def can_generate(self):
+ """Returns True to validate the check that the model using `GenerationMixin.generate()` can indeed generate."""
+ return True
+
+ def __call__(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ position_ids=None,
+ past_key_values=None,
+ inputs_embeds=None,
+ labels=None,
+ use_cache=None,
+ cache_position=None,
+ generation_steps=None,
+ **kwargs,
+ ) -> CausalLMOutputWithPast:
+ return self.forward(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ labels=labels,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ generation_steps=generation_steps,
+ **kwargs,
+ )
+
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ position_ids=None,
+ past_key_values=None,
+ inputs_embeds=None,
+ labels=None,
+ use_cache=None,
+ cache_position=None,
+ generation_steps=None,
+ **kwargs,
+ ) -> CausalLMOutputWithPast:
+ r"""
+ Args:
+ generation_steps (`int`):
+ generation step of code predictor, 0..num_code_groups-1
+ """
+ # Prefill stage
+ if inputs_embeds is not None and inputs_embeds.shape[1] > 1:
+ generation_steps = inputs_embeds.shape[1] - 2 # hidden & layer 0
+ # Generation stage
+ else:
+ inputs_embeds = self.get_input_embeddings()(input_ids, generation_steps - 1)
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ if past_key_values is None:
+ self.request.reset_state()
+ self.next_beam_idx = np.arange(inputs_embeds.shape[0], dtype=int)
+ self._past_length = 0
+ inputs = {}
+ inputs["inputs_embeds"] = inputs_embeds
+ inputs["attention_mask"] = attention_mask
+ inputs["position_ids"] = position_ids
+ inputs["generation_steps"] = generation_steps
+
+ if "beam_idx" in self.input_names:
+ inputs["beam_idx"] = self.next_beam_idx if self.next_beam_idx is not None else np.arange(inputs_embeds.shape[0], dtype=int)
+
+ self.request.start_async(inputs, share_inputs=False)
+ self.request.wait()
+ logits = self.request.get_tensor("logits").data
+ mid_residual_hiddens = self.request.get_tensor("mid_residual_hiddens").data
+ logits = torch.from_numpy(logits).to(self.device)
+ hidden_states = torch.from_numpy(mid_residual_hiddens).to(self.device)
+ past_key_values = ((),)
+ hidden_states = hidden_states.clone()
+
+
+ return Qwen3OmniMoeTalkerCodePredictorOutputWithPast(
+ logits=logits,
+ past_key_values=past_key_values,
+ hidden_states=hidden_states,
+ generation_steps=generation_steps + 1,
+ )
+
+
+ def _update_model_kwargs_for_generation(self, outputs, model_kwargs, is_encoder_decoder=False, num_new_tokens=1):
+ model_kwargs = super()._update_model_kwargs_for_generation(
+ outputs, model_kwargs, is_encoder_decoder, num_new_tokens
+ )
+ model_kwargs["generation_steps"] = outputs.generation_steps
+ return model_kwargs
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids: torch.LongTensor,
+ past_key_values: Optional[Cache] = None,
+ attention_mask: Optional[torch.LongTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs,
+ ):
+ if past_key_values != ((),):
+ past_key_values = None
+ model_inputs = super().prepare_inputs_for_generation(
+ input_ids=input_ids,
+ past_key_values=past_key_values,
+ attention_mask=attention_mask,
+ inputs_embeds=inputs_embeds,
+ cache_position=cache_position,
+ **kwargs,
+ )
+ return model_inputs
+
+class OVQwen3OmniMoeTalkerForConditionalGeneration(GenerationMixin):
+ _is_stateful = False
+
+ def __init__(self, model_dir, device, config):
+ self.model = core.read_model(model_dir / TALKER_LANGUAGE_NAME)
+ self.embed_tokens = core.compile_model(model_dir / TALKER_EMBEDDING_NAME, "CPU")
+ self.text_projection = core.compile_model(model_dir / TALKER_TEXT_PROJECTION_NAME, "CPU")
+ self.hidden_projection = core.compile_model(model_dir / TALKER_HIDDEN_PROJECTION_NAME, "CPU")
+ # Code Predictor models
+ self.code_predictor = OVQwen3OmniMoeTalkerCodePredictorModelForConditionalGeneration(model_dir, device, config.code_predictor_config)
+
+ self.input_names = {key.get_any_name(): idx for idx, key in enumerate(self.model.inputs)}
+ self.output_names = {key.get_any_name(): idx for idx, key in enumerate(self.model.outputs)}
+ compiled_model = core.compile_model(self.model, device)
+ self.request = compiled_model.create_infer_request()
+ self.get_input_embeddings = lambda: self._embedding_wrapper
+ self._embedding_wrapper = self._create_embedding_wrapper()
+ # Code Predictor request
+
+ self.config = config
+ self.generation_config = GenerationConfig.from_model_config(self.config)
+ self.dtype = torch.float16
+
+ self.main_input_name = "input_ids"
+ self.device = torch.device("cpu")
+ self.num_pkv = 2
+ self._past_length = None
+ self.next_beam_idx = None
+ self.spatial_merge_size = self.config.spatial_merge_size
+ self._skip_keys_device_placement = "past_key_values"
+ self._supports_flash_attn_2 = True
+ self._supports_sdpa = True
+ self._supports_cache_class = True
+ self._supports_static_cache = True
+
+ # MoE specific attributes
+ # self.num_experts = config.talker_config.text_config.num_experts
+ # self.num_experts_per_tok = config.talker_config.text_config.num_experts_per_tok
+ # self.router_aux_loss_coef = config.talker_config.text_config.router_aux_loss_coef
+
+
+ def _create_embedding_wrapper(self):
+ """Create a callable wrapper for embeddings that works with OpenVINO"""
+ def embedding_fn(input_ids):
+ result = self.embed_tokens(input_ids)[0]
+ return torch.from_numpy(result)
+ return embedding_fn
+
+
+ def can_generate(self):
+ """Returns True to validate the check that the model using `GenerationMixin.generate()` can indeed generate."""
+ return True
+
+
+ def __call__(
+ self,
+ input_ids: torch.LongTensor = None,
+ pixel_values: torch.Tensor = None,
+ position_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.BoolTensor] = None,
+ past_key_values: Optional[tuple[tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ **kwargs,
+ ) -> CausalLMOutputWithPast:
+ return self.forward(
+ input_ids=input_ids,
+ pixel_values=pixel_values,
+ attention_mask=attention_mask,
+ past_key_values=past_key_values,
+ position_ids=position_ids,
+ inputs_embeds=inputs_embeds,
+ **kwargs,
+ )
+
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ use_audio_in_video=None,
+ audio_feature_lengths=None,
+ video_second_per_grid=None,
+ image_grid_thw=None,
+ video_grid_thw=None,
+ position_ids=None,
+ past_key_values=None,
+ inputs_embeds=None,
+ labels=None,
+ use_cache=None,
+ output_router_logits=None,
+ cache_position=None,
+ residual_codes=None,
+ trailing_text_hidden=None,
+ tts_pad_embed=None,
+ generation_step=None,
+ talker_input_ids=None,
+ **kwargs,
+ ) -> MoeCausalLMOutputWithPast:
+
+ # Main talker processing
+ if inputs_embeds is not None and inputs_embeds.shape[1] > 1:
+ generation_step = -1
+ residual_codes = None
+ if attention_mask is not None:
+ if (
+ cache_position is None
+ or (cache_position is not None and cache_position[0] == 0)
+ or self.rope_deltas is None
+ ):
+ delta0 = (1 - attention_mask).sum(dim=-1).unsqueeze(1)
+ position_ids, rope_deltas = get_rope_index(self.config,
+ talker_input_ids,
+ image_grid_thw,
+ video_grid_thw,
+ attention_mask,
+ use_audio_in_video,
+ audio_feature_lengths,
+ video_second_per_grid,
+ )
+ rope_deltas = rope_deltas - delta0
+ self.rope_deltas = rope_deltas
+ else:
+ batch_size, seq_length = input_ids.shape
+ delta = cache_position[0] + self.rope_deltas if cache_position is not None else 0
+ position_ids = torch.arange(seq_length, device=input_ids.device)
+ position_ids = position_ids.view(1, -1).expand(batch_size, -1)
+ position_ids = position_ids.add(delta)
+ position_ids = position_ids.unsqueeze(0).expand(3, -1, -1)
+
+ if past_key_values is None:
+ self.request.reset_state()
+ self.next_beam_idx = np.arange(inputs_embeds.shape[0], dtype=int)
+ self._past_length = 0
+
+ inputs = {}
+ inputs["inputs_embeds"] = inputs_embeds
+ inputs["attention_mask"] = attention_mask
+ inputs["position_ids"] = position_ids
+
+ if "beam_idx" in self.input_names:
+ inputs["beam_idx"] = self.next_beam_idx if self.next_beam_idx is not None else np.arange(inputs_embeds.shape[0], dtype=int)
+
+ self.request.start_async(inputs, share_inputs=False)
+ self.request.wait()
+ logits = self.request.get_tensor("logits").data
+ hidden_states = self.request.get_tensor("hidden_states").data
+ logits = torch.from_numpy(logits).to(self.device)
+ hidden_states = torch.from_numpy(hidden_states).to(self.device)
+ past_key_values = ((),)
+ hidden_states_output = hidden_states.clone()
+
+ return Qwen3OmniMoeTalkerOutputWithPast(
+ logits=logits,
+ past_key_values=past_key_values,
+ hidden_states=(
+ hidden_states_output,
+ residual_codes,
+ ),
+ generation_step=generation_step + 1,
+ )
+
+ def _reorder_cache(self, past_key_values: tuple[tuple[torch.Tensor]], beam_idx: torch.Tensor) -> tuple[tuple[torch.Tensor]]:
+ """
+ This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or
+ [`~PreTrainedModel.beam_sample`] is called.
+ This is required to match `past_key_values` with the correct beam_idx at every generation step.
+ """
+ self.next_beam_idx = np.array(beam_idx) # save beam_idx to be used as an input in the next iteration
+ return past_key_values
+
+ def _get_past_length(self, past_key_values=None):
+ if past_key_values is None:
+ return 0
+ return self._past_length
+
+ def get_input_embeddings(self):
+ return self.model.get_input_embeddings()
+
+ def _update_model_kwargs_for_generation(self, outputs, model_kwargs, is_encoder_decoder=False, num_new_tokens=1):
+ model_kwargs = super()._update_model_kwargs_for_generation(
+ outputs, model_kwargs, is_encoder_decoder, num_new_tokens
+ )
+ model_kwargs["hidden_states"] = outputs.hidden_states
+ model_kwargs["generation_step"] = outputs.generation_step
+ return model_kwargs
+
+ def prepare_inputs_for_generation(
+ self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, cache_position=None, **kwargs
+ ):
+ hidden_states = kwargs.pop("hidden_states", None)
+ if past_key_values != ((),):
+ past_key_values = None
+ inputs = super().prepare_inputs_for_generation(
+ input_ids, past_key_values, attention_mask, inputs_embeds, cache_position, **kwargs
+ )
+ # Decode stage
+ # TODO(raushan, gante): Refactor this part to a utility function
+ if cache_position[0] != 0:
+ input_ids = input_ids[:, -1:]
+ generation_step = kwargs.get("generation_step")
+ trailing_text_hidden = kwargs.get("trailing_text_hidden")
+ tts_pad_embed = kwargs.get("tts_pad_embed")
+ last_id_hidden = self.get_input_embeddings()(input_ids)
+ past_hidden = hidden_states[0][:, -1:, :].to(last_id_hidden.device) # hidden, last layer, last token
+ predictor_result = self.code_predictor.generate(
+ inputs_embeds=torch.cat((past_hidden, last_id_hidden), dim=1),
+ max_new_tokens=self.config.num_code_groups - 1,
+ do_sample=False,
+ # top_k=50,
+ # top_p=0.8,
+ output_hidden_states=True,
+ return_dict_in_generate=True,
+ )
+ residual_codes = torch.cat((input_ids, predictor_result.sequences.to(input_ids.device)), dim=-1)
+
+ mid_residual_hiddens = [hid.to(last_id_hidden.device) for hid in predictor_result.hidden_states[1:]]
+ last_residual_hidden = self.code_predictor.get_input_embeddings()(
+ predictor_result.sequences[..., -1:], -1
+ ).to(last_id_hidden.device)
+ codec_hiddens = torch.cat(
+ [last_id_hidden] + mid_residual_hiddens + [last_residual_hidden],
+ dim=1,
+ )
+ inputs_embeds = codec_hiddens.sum(1, keepdim=True)
+
+ if generation_step < trailing_text_hidden.shape[1]:
+ inputs_embeds = inputs_embeds + trailing_text_hidden[:, generation_step].unsqueeze(1).to(
+ inputs_embeds.device
+ )
+ else:
+ inputs_embeds = inputs_embeds + tts_pad_embed.to(inputs_embeds.device)
+ inputs["inputs_embeds"] = inputs_embeds
+ inputs["residual_codes"] = residual_codes
+ return inputs
+
+
+class OVQwen3OmniMoeCode2Wav():
+ def __init__(self, model_dir, device, config):
+ self.code2wav = core.compile_model(model_dir / CODE2WAV_NAME, device)
+ self.config = config
+ self.total_upsample = np.prod(config.upsample_rates + config.upsampling_ratios)
+ self.device = torch.device("cpu")
+
+ def chunked_decode(self, codes, chunk_size=300, left_context_size=25):
+ wavs = []
+ start_index = 0
+ while start_index < codes.shape[-1]:
+ end_index = min(start_index + chunk_size, codes.shape[-1])
+ context_size = left_context_size if start_index - left_context_size > 0 else start_index
+ codes_chunk = codes[..., start_index - context_size : end_index]
+ wav_chunk = torch.from_numpy(self.code2wav(codes_chunk)[0])
+ wavs.append(wav_chunk[..., context_size * self.total_upsample :])
+ start_index = end_index
+ return torch.cat(wavs, dim=-1)
+
+
+class OVQwen3OmniMoeModel(GenerationMixin):
+
+ def __init__(self, model_dir, thinker_device="CPU", talker_device="CPU", code2wav_device="CPU"):
+ self.model_path = Path(model_dir)
+ self.talker_device = talker_device
+ self.code2wav_device = code2wav_device
+ self.config = AutoConfig.from_pretrained(model_dir, trust_remote_code=True)
+ self.thinker = OVQwen3OmniMoeThinkerForConditionalGeneration(self.model_path / "thinker", thinker_device, self.config.thinker_config)
+ self.has_talker = self.config.enable_audio_output
+ if self.has_talker:
+ self.enable_talker()
+
+ # self.post_init()
+
+ def enable_talker(self):
+ self.talker = OVQwen3OmniMoeTalkerForConditionalGeneration(self.model_path / "talker", self.talker_device, self.config.talker_config)
+ self.code2wav = OVQwen3OmniMoeCode2Wav(self.model_path, self.code2wav_device, self.config.code2wav_config)
+
+ def disable_talker(self):
+ if hasattr(self, "talker"):
+ del self.talker
+ if hasattr(self, "code2wav"):
+ del self.code2wav
+ self.has_talker = False
+
+ def _get_talker_user_parts(
+ self, im_start_index, segment_end_index, multimodal_mask, thinker_hidden, thinker_embed
+ ):
+ user_talker_part = torch.empty(
+ (1, segment_end_index - im_start_index, self.config.talker_config.text_config.hidden_size),
+ device=self.talker.device,
+ )
+
+ user_mm_mask = multimodal_mask[:, im_start_index:segment_end_index]
+ # Multimodal data exists
+ if user_mm_mask.any():
+ user_thinker_hidden_mm = thinker_hidden[:, im_start_index:segment_end_index][user_mm_mask]
+ mm_hidden = torch.from_numpy(self.talker.hidden_projection(user_thinker_hidden_mm)[0]).to(self.talker.device)
+ user_talker_part[user_mm_mask] = mm_hidden
+ user_thinker_embed = thinker_embed[:, im_start_index:segment_end_index][~user_mm_mask]
+ user_text_hidden = torch.from_numpy(self.talker.text_projection(user_thinker_embed.unsqueeze(0))[0]).to(self.talker.device)
+ user_talker_part[~user_mm_mask] = user_text_hidden
+ return user_talker_part
+
+ def _get_talker_assistant_parts(
+ self, im_start_index, segment_end_index, speaker_id, thinker_embed, tts_pad_embed, tts_bos_embed, tts_eos_embed
+ ):
+ assistant_hidden = torch.from_numpy(self.talker.text_projection(thinker_embed[:, im_start_index:segment_end_index])[0]).to(
+ self.talker.device
+ ) # [1 t d]
+ assistant_text_hidden = torch.cat(
+ (
+ assistant_hidden[:, :3],
+ tts_pad_embed.expand(-1, 4, -1),
+ tts_bos_embed,
+ assistant_hidden[:, 3:4], # First text
+ ),
+ dim=1,
+ )
+ codec_special_tokens = torch.tensor(
+ [
+ [
+ self.config.talker_config.codec_nothink_id,
+ self.config.talker_config.codec_think_bos_id,
+ self.config.talker_config.codec_think_eos_id,
+ speaker_id,
+ self.config.talker_config.codec_pad_id,
+ self.config.talker_config.codec_bos_id,
+ ]
+ ],
+ device=self.talker.device,
+ dtype=torch.long,
+ )
+ assistant_codec_hidden = torch.cat(
+ (
+ torch.zeros(
+ (1, 3, self.config.talker_config.text_config.hidden_size),
+ device=self.talker.device,
+ dtype=self.talker.dtype,
+ ),
+ self.talker.get_input_embeddings()(codec_special_tokens),
+ ),
+ dim=1,
+ )
+ trailing_text_hidden = torch.cat(
+ (
+ assistant_hidden[:, 4:],
+ tts_eos_embed,
+ ),
+ dim=1,
+ )
+
+ input_embeds = assistant_text_hidden + assistant_codec_hidden
+ input_ids = torch.full(
+ (1, assistant_text_hidden.shape[1]),
+ fill_value=self.config.tts_pad_token_id,
+ dtype=torch.long,
+ device=assistant_text_hidden.device,
+ )
+ return input_embeds, input_ids, trailing_text_hidden
+
+ @torch.no_grad()
+ def generate(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ speaker: str = "Ethan",
+ use_audio_in_video: bool = False,
+ return_audio: Optional[bool] = None,
+ thinker_max_new_tokens: int = 1024,
+ thinker_eos_token_id: int = 151645,
+ talker_max_new_tokens: int = 4096,
+ talker_do_sample: bool = True,
+ talker_top_k: int = 50,
+ talker_top_p: float = 1.0,
+ talker_temperature: float = 0.9,
+ talker_repetition_penalty: float = 1.05,
+ **kwargs,
+ ):
+ if return_audio and not self.has_talker:
+ raise ValueError(
+ "Cannot use talker when talker module not initialized. Use `enable_talker` method or set enable_talker in config to enable talker."
+ )
+ if return_audio is None:
+ return_audio = self.has_talker
+
+ shared_kwargs = {"use_audio_in_video": use_audio_in_video}
+ thinker_kwargs = {
+ "max_new_tokens": thinker_max_new_tokens,
+ "eos_token_id": thinker_eos_token_id,
+ }
+
+ talker_kwargs = {}
+ token2wav_kwargs = {}
+ if return_audio:
+ speaker_id = self.config.talker_config.speaker_id.get(speaker.lower())
+ if speaker_id is None:
+ raise NotImplementedError(f"Speaker {speaker} not implemented")
+ if input_ids.shape[0] != 1:
+ raise NotImplementedError("Qwen3-Omni currently does not support batched inference with audio output")
+ talker_supppressed_tokens = [
+ i
+ for i in range(
+ self.config.talker_config.text_config.vocab_size - 1024,
+ self.config.talker_config.text_config.vocab_size,
+ )
+ if i not in (self.config.talker_config.codec_eos_token_id,)
+ ] # Suppress additional special tokens, should not be predicted
+ talker_kwargs = {
+ "max_new_tokens": talker_max_new_tokens,
+ "do_sample": talker_do_sample,
+ "top_k": talker_top_k,
+ "top_p": talker_top_p,
+ "temperature": talker_temperature,
+ "eos_token_id": self.config.talker_config.codec_eos_token_id,
+ "repetition_penalty": talker_repetition_penalty,
+ "suppress_tokens": talker_supppressed_tokens,
+ "output_hidden_states": True,
+ "return_dict_in_generate": True,
+ }
+ token2wav_kwargs = {}
+
+ for key, value in kwargs.items():
+ if key.startswith("thinker_"):
+ thinker_kwargs[key[len("thinker_") :]] = value
+ elif key.startswith("talker_"):
+ talker_kwargs[key[len("talker_") :]] = value
+ elif key.startswith("token2wav_"):
+ token2wav_kwargs[key[len("token2wav_") :]] = value
+ # Process special input values
+ elif key == "feature_attention_mask":
+ thinker_kwargs[key] = value
+ talker_kwargs["audio_feature_lengths"] = torch.sum(value, dim=1)
+ elif key in ("input_features", "attention_mask"):
+ thinker_kwargs[key] = value
+ # Put other key to shared kwargs
+ else:
+ shared_kwargs[key] = value
+
+ # Merge kwargs
+ for key, value in shared_kwargs.items():
+ if key not in thinker_kwargs:
+ thinker_kwargs[key] = value
+ if key not in talker_kwargs and key in ["image_grid_thw", "video_grid_thw", "video_second_per_grid"]:
+ talker_kwargs[key] = value
+ if key not in token2wav_kwargs:
+ token2wav_kwargs[key] = value
+
+ # 1. Generate from thinker module
+ generate_audio = return_audio and self.has_talker
+ if generate_audio:
+ thinker_kwargs["output_hidden_states"] = True
+ thinker_kwargs["return_dict_in_generate"] = True
+
+ thinker_result = self.thinker.generate(input_ids=input_ids, **thinker_kwargs)
+
+ if not generate_audio:
+ return thinker_result, None
+
+ # 2. Prepare talker input
+ thinker_embed = torch.cat([hidden_states[0] for hidden_states in thinker_result.hidden_states], dim=1).to(
+ self.talker.device
+ ) # [1 t d]
+ thinker_hidden = torch.cat(
+ [
+ hidden_states[1].to(self.talker.device)
+ for hidden_states in thinker_result.hidden_states
+ ],
+ dim=1,
+ ).to(self.talker.device) # [1 t d]
+ im_start_indexes = torch.cat(
+ (
+ torch.nonzero(input_ids[0] == self.config.im_start_token_id).squeeze(),
+ torch.tensor([thinker_result.sequences.shape[-1]], device=input_ids.device, dtype=input_ids.dtype),
+ ),
+ dim=-1,
+ ).to(self.talker.device) # Shape [n_starts + 1]; Take batch 0 since batched inference is not supported here.
+ multimodal_mask = (
+ (thinker_result.sequences == self.config.thinker_config.audio_token_id) |
+ (thinker_result.sequences == self.config.thinker_config.image_token_id) |
+ (thinker_result.sequences == self.config.thinker_config.video_token_id)
+ ).to(self.talker.device) # [1 t] # fmt: skip
+
+ talker_special_tokens = torch.tensor(
+ [[self.config.tts_bos_token_id, self.config.tts_eos_token_id, self.config.tts_pad_token_id]],
+ device=self.thinker.device,
+ dtype=input_ids.dtype,
+ )
+ inputs_embeds = self.thinker.get_input_embeddings()(talker_special_tokens)
+ tts_bos_embed, tts_eos_embed, tts_pad_embed = (
+ torch.from_numpy(self.talker.text_projection(inputs_embeds)[0])
+ .to(self.talker.device)
+ .chunk(3, dim=1)
+ ) # 3 * [1 1 d]
+
+ talker_input_embeds = [] # [1 t d]
+ talker_input_ids = []
+ # For every chatml parts
+ for i in range(len(im_start_indexes) - 1):
+ im_start_index = im_start_indexes[i]
+ segment_end_index = im_start_indexes[i + 1]
+ role_token = input_ids[0][im_start_index + 1]
+ # Talker should ignore thinker system prompt
+ if role_token == self.config.system_token_id:
+ continue
+ # Talker takes word embeddings for tokens and hidden state from `accept_hidden_layer` for multimodal inputs
+ elif role_token == self.config.user_token_id:
+ talker_user_part = self._get_talker_user_parts(
+ im_start_index, segment_end_index, multimodal_mask, thinker_hidden, thinker_embed
+ )
+ talker_input_embeds.append(talker_user_part)
+ talker_input_ids.append(thinker_result.sequences[:, im_start_index:segment_end_index])
+ # Take assistant output (for now)
+ elif role_token == self.config.assistant_token_id and i == len(im_start_indexes) - 2:
+ talker_assistant_embeds, talker_assistant_ids, trailing_text_hidden = self._get_talker_assistant_parts(
+ im_start_index,
+ segment_end_index,
+ speaker_id,
+ thinker_embed,
+ tts_pad_embed,
+ tts_bos_embed,
+ tts_eos_embed,
+ )
+ talker_input_embeds.append(talker_assistant_embeds)
+ talker_input_ids.append(talker_assistant_ids)
+ # History assistant output (ignore for now)
+ elif role_token == self.config.assistant_token_id and i != len(im_start_indexes) - 2:
+ continue
+ else:
+ raise AssertionError("Expect role id after <|im_start|> (assistant, user, system)")
+ talker_input_embed = torch.cat([embed.to(self.talker.device) for embed in talker_input_embeds], dim=1)
+ talker_input_id = torch.cat([embed.to(self.talker.device) for embed in talker_input_ids], dim=1)
+ talker_kwargs['do_sample'] = False # For debug purpose, set do_sample to False
+
+ talker_result = self.talker.generate(
+ inputs_embeds=talker_input_embed,
+ trailing_text_hidden=trailing_text_hidden,
+ tts_pad_embed=tts_pad_embed,
+ talker_input_ids=talker_input_id, # Not use input_ids to prevent repetation penalty out of bound
+ **talker_kwargs,
+ )
+ talker_codes = (
+ torch.stack([hid[-1] for hid in talker_result.hidden_states if hid[-1] is not None], dim=1)
+ .transpose(1, 2)
+ .to(self.code2wav.device)
+ )
+
+ talker_wavs = self.code2wav.chunked_decode(talker_codes, chunk_size=300, left_context_size=25)
+
+ return thinker_result, talker_wavs.float()
\ No newline at end of file