Excluding outliers in calculation of average #10204
Replies: 5 comments 10 replies
-
|
You could try the median instead of the average. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the reply and the suggestions, I think sorting and taking an average from the middle (40-60%) could work. Raw list: Sorted |
Beta Was this translation helpful? Give feedback.
-
|
@MrTinkerman the mean and standard deviation of a dataset can be computed without storing the history of the samples. This is called the "running mean". The way to do it for the mean can be seen from the formula: so the next mean is So given only the previous mean, the next sample, and the number of samples, you can compute each successive mean. If you only want to include "recent" samples, you can weight the previous mean lower (essentially computing a moving average). For the running standard deviation see the always awesome John D Cook - https://www.johndcook.com/blog/standard_deviation/ |
Beta Was this translation helpful? Give feedback.
-
|
(Sweet use of Latex markup!) |
Beta Was this translation helpful? Give feedback.
-
|
I would want to find the physical cause of the outliers. Their characteristics are odd: they always increase the value, and usually by a fairly constant 30. Occasionally roughly double that. This isn't random noise: something interesting is going on... |
Beta Was this translation helpful? Give feedback.
-
|
Absolutely: The outliers mostly form a second mode: You have a multimodal distribution. Sensor noise + occasional change of electrical connections (breadboard) ?? |
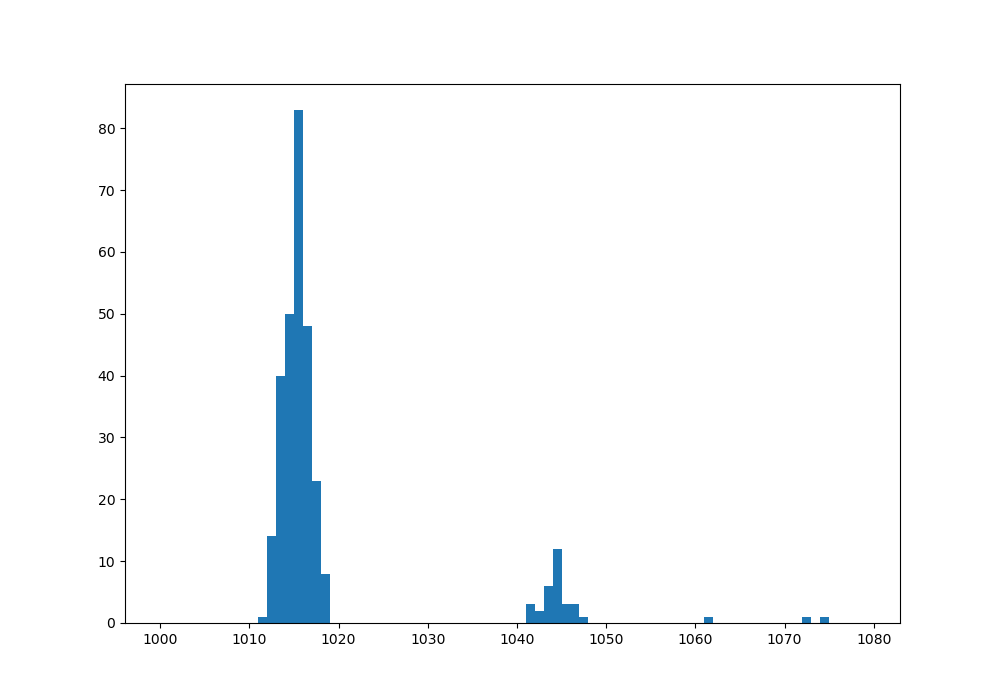
Beta Was this translation helpful? Give feedback.
-
Well, I'm using a VL53L0X Time-of-Flight sensor. Seeing that graph is interesting. |
Beta Was this translation helpful? Give feedback.
-
|
interesting! I bet you're getting some photons coming back after bouncing off your target at an angle, then bouncing off something else, then back to the TOF detector. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the input all, I have solved it taking your suggestions into consideration. I am using a 'rolling average' in a list. Each time I want a reference: My global readings list is 100 entries, the subset is 20. The code: |
Beta Was this translation helpful? Give feedback.
-
|
As the outliers are only shifted to higher values as @peterhinch noted, they are probably reflections - the light taking a longer path, with the above data 30 mm longer (pythagoras??). It could be interesting to also filter out the second mode and have a permanently updated display of it, together with its size (how many samples around that value). This way you could try out different positions of sensor and object, together with rearrangements of the environment, perhaps a black tube to narrow the cone of the sensor... |
Beta Was this translation helpful? Give feedback.
-
|
Have a look at the statistical median filter: https://www.robots.ox.ac.uk/~sjrob/Teaching/SP/l8.pdf I've used this in the past for removing spikey noise. This filter takes a windowed set of values adjacent to, and centred around, the input value. There are an odd number of values in the set. The set is sorted filter output is the median value, i.e. the middle value of the sorted set. As long as the spikes are single values and well separated they will never be the median value of a set and therefore will not make it to the output stream. I spotted in your sample that there's an instance of two adjacent outlying samples, so you will need a window size of at least 5. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the input, but man, my math/linear algebra is a bit rusty. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the input all, I wrote a 'sampler' class that fits my needs, your replies and hints have been helpful. # Class to take stable, custom average or mean from a range of sensor readings
# Readings that are 'not too far' from the current mean will be stored to have a stable rolling average
class sampler():
def __init__(self, size, sensor_max):
if (size%2) == 0: self.size = size + 1 # If size is even, add 1 to make it un-even so sample range
else: self.size = size # can have a single middle value, else if uneven, accept
self.middle_index = int((self.size - 1) / 2) # Calculate middle index
self.samples = [0]*self.size # Create list to hold sampled values
self.sensor_max = sensor_max # sensor_max is used to ignore rogue readings
self.index = 0 # Set index to zero
def set_baseline(self, reading): # When setting a baseline readings should not be
# tested against self.get_averaged_median()
if reading < self.sensor_max: # Reading should only be tested against sensor_max
self.samples[self.index] = reading # If the reading is valid, store it
self.index += 1 # This function should be called in a for loop:
if self.index == self.size: self.index = 0 # for index, val in enumerate(sampler.samples): sampler.set_baseline(read_sensor())
def store(self, new_reading): # When storing a single reading it should not be
# 'too far off' self.get_averaged_median(xx)
if abs(self.get_averaged_median(40) - new_reading) < 100: # This way the reference (averaged mean) can change slightly in time
self.samples[self.index] = new_reading # to account for sensor drift. While at the same time
self.index += 1 # alert readings do not influence the averaged mean
if self.index == self.size: self.index = 0
# Get single middle value
def get_median(self):
self.samples.sort() # Sort the list of samples
return self.samples[self.middle_index] # Return the middle value
# Get average of a middle subset
def get_averaged_median(self, percent):
offset = round(self.size * (percent/2) / 100) # Calculate start/end offset from middle
subset = self.samples[self.middle_index - offset : self.middle_index + offset] # Create subset
return round(sum(subset)/len(subset)) # Return average of subset |
Beta Was this translation helpful? Give feedback.
-
|
hi. I have just found this thread. I need to remove outliers in a list of distance sensor readings and your requirements seemed similar to mine. However, I am not great at understanding medians/averaged medians etc so am unsure as to what to call to get the "average" plus outliers. Do you have examples of the calls to these class functions with arrays and I guess the addition of new readings to the array as it appears that new readings are passed in separate to the ongoing array? I would be very grateful. As i loop to get reading every few milliseconds, I could adapt the calls to suit my data. |
Beta Was this translation helpful? Give feedback.
-
|
Here's a simple example from one of my projects. I pre-allocate an integer array and index as these have to persist between readings being taken. The following code uses the results of an analogue read that has been zero adjusted. This is about as simple as a statistical median filter can be. Hope this helps. |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Hi all,
I'testing a sensor and would like to establish a baseline reading.
The readings jump up and down quite a bit but I got to the point where
I have a function that calculates an average over say 250 readings (see below).
This seems to get consistent results. However, there are also outliers in the results (see below).
On first sight you'd say, ok, the average should be ~1015.
But how can I calculate this in MicroPython, excluding the outliers in the calculation?
Can I calculate a standard deviation and exclude results beyond that?
Thanks in advance!
Beta Was this translation helpful? Give feedback.
All reactions