-
|
The documentation mentions that the following formula for message passing is adopted in Pytorch geometric: Then, it mentions about the function |
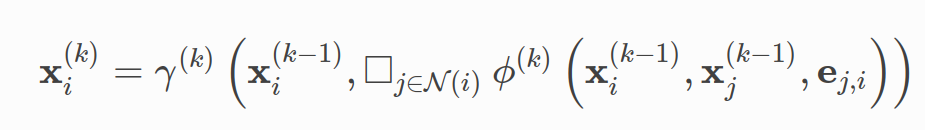
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 7 replies
-
|
Yes, that does not make a real difference. The reason we do this here is due to the fact that it is more memory-friendly to perform the transformation node-wise instead of edge_wise, i.e.: x = x @ self.weight # [num_nodes, out_channels]
self.propagate(edge_index, x=x)is faster than doing self.propagate(edge_index, x=x)
def message(self, x_j):
return x_j @ self.weight # [num_edges, out_channels]since usually, |
Beta Was this translation helpful? Give feedback.
-
|
I think I get it. The problem that you're referring to is that x_j and the other edge_level matrix that is produced from |
Beta Was this translation helpful? Give feedback.
-
|
That is correct :) |
Beta Was this translation helpful? Give feedback.
-
|
This is somewhat related, but based on our discussion, this (which is in the docs under "Memory-Efficient Aggregations"): |

Beta Was this translation helpful? Give feedback.
-
|
Actually, the MLP needs to be applied in the message function as its both dependent on source and target node representations. There is no way to out-source that as a pre-processing step since MLP(x_i) - MLP(x_j) is different from MLP(x_j - x_i), with the latter being more powerful as it can learn different messages dependent on the source node. |
Beta Was this translation helpful? Give feedback.
-
|
This holds only true for non-linear transformations though, not for linear ones. |
Beta Was this translation helpful? Give feedback.
Yes, that does not make a real difference. The reason we do this here is due to the fact that it is more memory-friendly to perform the transformation node-wise instead of edge_wise, i.e.:
is faster than doing
since usually,
|E| >> |N|.