Large graph classification #2884
Replies: 1 comment 9 replies
-
|
Yes, memory consumption is dependent on graph size. 20k nodes is pretty large already, but might well fit for deeper GNNs as well if you make use of memory-efficient aggregations using the |
Beta Was this translation helpful? Give feedback.
-
|
The only changes I made with the SparseTensor version is adding the transform = T.ToSparseTensor() line in the dataset constructor and changing edge_index to adj_t in my code. For 4 epochs, the sparsetensor took 3.5 minutes, the edge_index took <1 min. Here's the link to my saved datasets:
Here's the code for my model: https://colab.research.google.com/drive/1mTcKrB63iHm9oBsWrEQCYK_sjUN--9id?usp=sharing I will give the samplesubgraph approach a try later. Edit: I've tried the samplesubgraph on my dataset that had 9 dimensional edge_attr, on top of the 20k nodes and 5mil edges. Unfortunately, I am running out of memory on a 1 layer GENConv GNN (60k trainable parameters, hidden_dim = 128). |
Beta Was this translation helpful? Give feedback.
-
|
Anyway, my graphs are bipartite and directed, they are identical graphs and differ only in the values of the node features. It is also very likely not all nodes are important and some can be discarded. I've run my GNN on a simpler task and achieved perfect accuracy. I was wondering if there is a way to use my trained model to determine which nodes are important and which can be discarded? |
Beta Was this translation helpful? Give feedback.
-
|
Sorry, I haven't had time to look into the runtime issue yet. If you have a trained model, you may be able to modify |
Beta Was this translation helpful? Give feedback.
-
|
Thanks, I tried to modify GNNExplainer, however, I'm confused why the loss function introduces extra terms to the loss. In the article for GNNExplainer, the equation to minimize is |
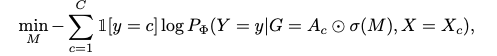
Beta Was this translation helpful? Give feedback.
-
|
The additional terms try to push as many edges/features to zero as possible. Without, a mask full of |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
I am currently using torch geometric for graph classification. My graphs (16 total graphs) have ~20000 nodes and ~6 million edges each, where each node has 2d features and no edge features. I am running my code on colab pro, yet whenever I try to make my model more complicated (with ~20000 trainable parameters), I get cuda out of memory.
Upon doing more searching, it seems it has something to do with batch_size. I've already set my batch_size to 1 but still get cuda out of memory... When I run a similar model on the https://ogb.stanford.edu/docs/graphprop/ datasets, there seems to be no problem, I can even add several more layers to the model. Do note that those datasets only have graphs with <2000 nodes and edges.
So here's my question: is the reason why I run out of memory because each of my graphs is so large? Is there some solution to this problem?
Thanks,
Ray
Beta Was this translation helpful? Give feedback.
All reactions