GNN parameter optimization for whole graph classification task #2891
Replies: 1 comment 7 replies
-
|
What do you exactly mean with parameter optimization? Do you mean hyperparameter search? In general, a two-layer GNN with hidden feature sizes of 64, 128 or 256 work well in general, using a learning rate of 0.01 or 0.001. In addition, batch normalization and dropout after each GNN layer might be critical to achieve good performance/generalization. If you can share some more details, I'm happy to help. |
Beta Was this translation helpful? Give feedback.
-
|
As an alternative to |
Beta Was this translation helpful? Give feedback.
-
|
Thank you again, I am experimenting and will let you know how it goes. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you again for advice as it has allowed me to make some progress. Please let me continue the topic. I'm now using the following GNN and parameters: hidden_channels = 92
number_of_features = 43
number_of_classes = 2
lr = 0.0001
patience = 25
batch_size = 4
class GAT(torch.nn.Module):
def __init__(self, hidden_channels, number_of_features, number_of_classes):
super(GAT, self).__init__()
out_dimension = hidden_channels
self.ds = 0.05
heads1 = 16
heads2 = 16
in_dimension = out_dimension * heads1
lin_dimension = hidden_channels
self.conv1 = GATConv(in_channels=number_of_features, out_channels=out_dimension, heads=heads1, dropout=self.ds)
self.bn1 = BatchNorm(hidden_channels*heads1)
# On the Pubmed dataset, use heads=8 in conv2.
self.conv2 = GATConv(in_channels=in_dimension, out_channels=out_dimension, heads=heads2, concat=False,
dropout=self.ds)
self.bn2 = BatchNorm(out_dimension)
self.lin = Linear(lin_dimension, number_of_classes)
def forward(self, x, edge_index, batch):
ds = 0.8
x = F.elu(self.conv1(x, edge_index))
x = self.bn1(x)
x = F.dropout(x, p=ds, training=self.training)
x = self.conv2(x, edge_index)
x = self.bn2(x)
x = F.dropout(x, p=ds, training=self.training)
x = global_mean_pool(x, batch)
# 3. Apply a final classifier
x = F.dropout(x, p=ds, training=self.training)
x = self.lin(x)
return xAs you can see I have 2 different dropout values for GATConv and F.dropout. I found that the GATConv dropout is a very sensitive parameter, and that the dropout value used by F.dropout can have a great influence on overfitting. I also believe there is a strong relation between the number of hidden_channels and the F.dropout value. Having said that, unfortunately the training plots look for example as below. The final test accuracy (holdout set) is about ~0.7 at best. The data set consists of 408 graph instances. Can I ask you for any further tips/advice regarding the direction I could take? Best, |
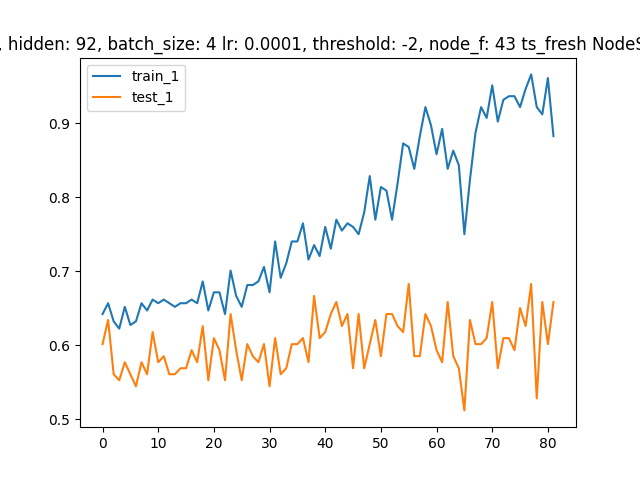
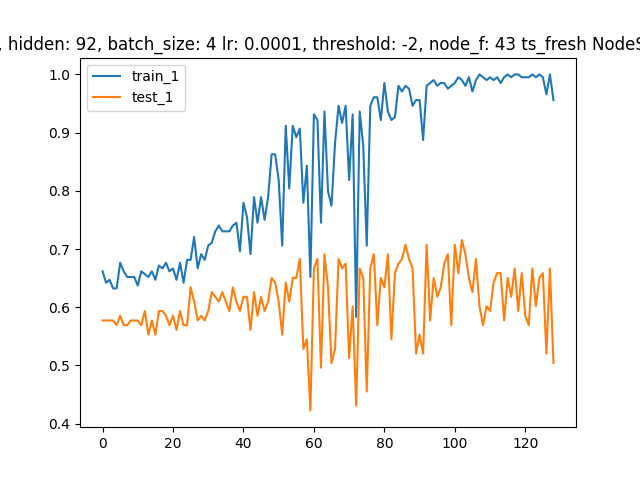
Beta Was this translation helpful? Give feedback.
-
|
Your model and code looks fine to me. Good job. You can also play around with adding additional skip-connections, see here. On the other hand, it's impossible for me to say what's exactly causing your model to overfit, in particular because it looks like testing performance does not really increase at all. I think the usual answer to this question is: "get more data" :( You also might be able to increase test performance by pre-training your model, e.g., via Deep Graph Infomax. You can also try out different non-GNN models to see whether the problem lies in the data or the model. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you again @rusty1s for your time. It's really great to have your opinion on the code. |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Hi,
I'm working on whole graph classification, in particular I'm addressing fMRI-based classification with use of data from Human Connectome Project (HCP).
I've prepared a whole ML pipeline and was able to test it first on some open non-fMRI data sets to make sure it's all working, later I explored the task-based fMRI classification (easier task) and now I'm on the resting-state data. This is challenging because:
Best,
Chris
Beta Was this translation helpful? Give feedback.
All reactions