-
|
Hi, After checking the current implementation of GAT I have not been able to find the concatenation of [ Whi || Whj] described in the paper The original formulation says that: Thanks, |
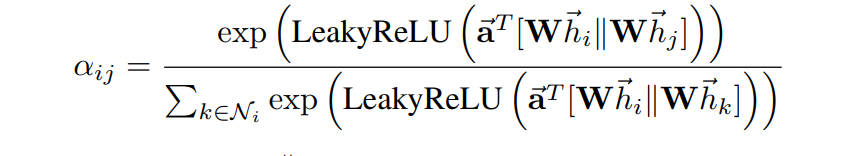
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 7 replies
-
|
We concatenate implicitly, leading to a smaller memory footprint. In particular, we hold two versions of the |
Beta Was this translation helpful? Give feedback.
-
|
Hi, after checking the code that you have pointed I have not been able to find where the dot product is implemented. What I am trying to do is modify the function Thanks! |
Beta Was this translation helpful? Give feedback.
-
|
Yes, this is in the code, i.e., line 265-268, in which attention coefficients are implemented via |
Beta Was this translation helpful? Give feedback.
-
|
I didn't realize that was the dot product. Sorry, but there is something that I do not understand why are you dividing the product for the sqrt of the number of channels? |
Beta Was this translation helpful? Give feedback.
-
|
This actually refers to the scaled dot-product attention, as introduced in the "Attention is All You Need" paper. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks! All my doubts have been clarified! |
Beta Was this translation helpful? Give feedback.
We concatenate implicitly, leading to a smaller memory footprint. In particular, we hold two versions of the
aparameter vector, one forW@h_i(namedatt_r) and one forW@h_j(namedatt_l). We then multiply the source and destination node features with these parameters and sum the resulting parts together. This is equivalent to first concatenating source and destination node features, and multiply with a single attention parameter vector afterwards. Hope this is understandable :)