Replies: 17 comments 137 replies
-
|
Beta Was this translation helpful? Give feedback.
-
Hi, when there is no edge type and all edges are undirected, does it mean, only one SAGEConv is needed when the source and target nodes have the same type (e.g. paper->paper), and two SAGEConvs are needed if the source and target are different (e.g. paper->author)? Thanks. |
Beta Was this translation helpful? Give feedback.
-
|
Yes, if there are no more than 1 edge type and node type then we don't need separate SAGEConv layers. It will work like in case of a homogeneous graph. Please correct me if I am wrong! |
Beta Was this translation helpful? Give feedback.
-
|
Hello, in the case we have author_related_author and rev_author_related_author, it is sensible to use the same Conv layer for both, right? |
Beta Was this translation helpful? Give feedback.
-
|
Yes, that works. Alternatively, you can merge the two edge types into one. |
Beta Was this translation helpful? Give feedback.
-
|
Ok thank you. As I am dealing with a graph with multiple edgetypes (some between the same and some between different entities), I rather keep both directions separate in the dataset, for consistency across edgetypes |
Beta Was this translation helpful? Give feedback.
-
|
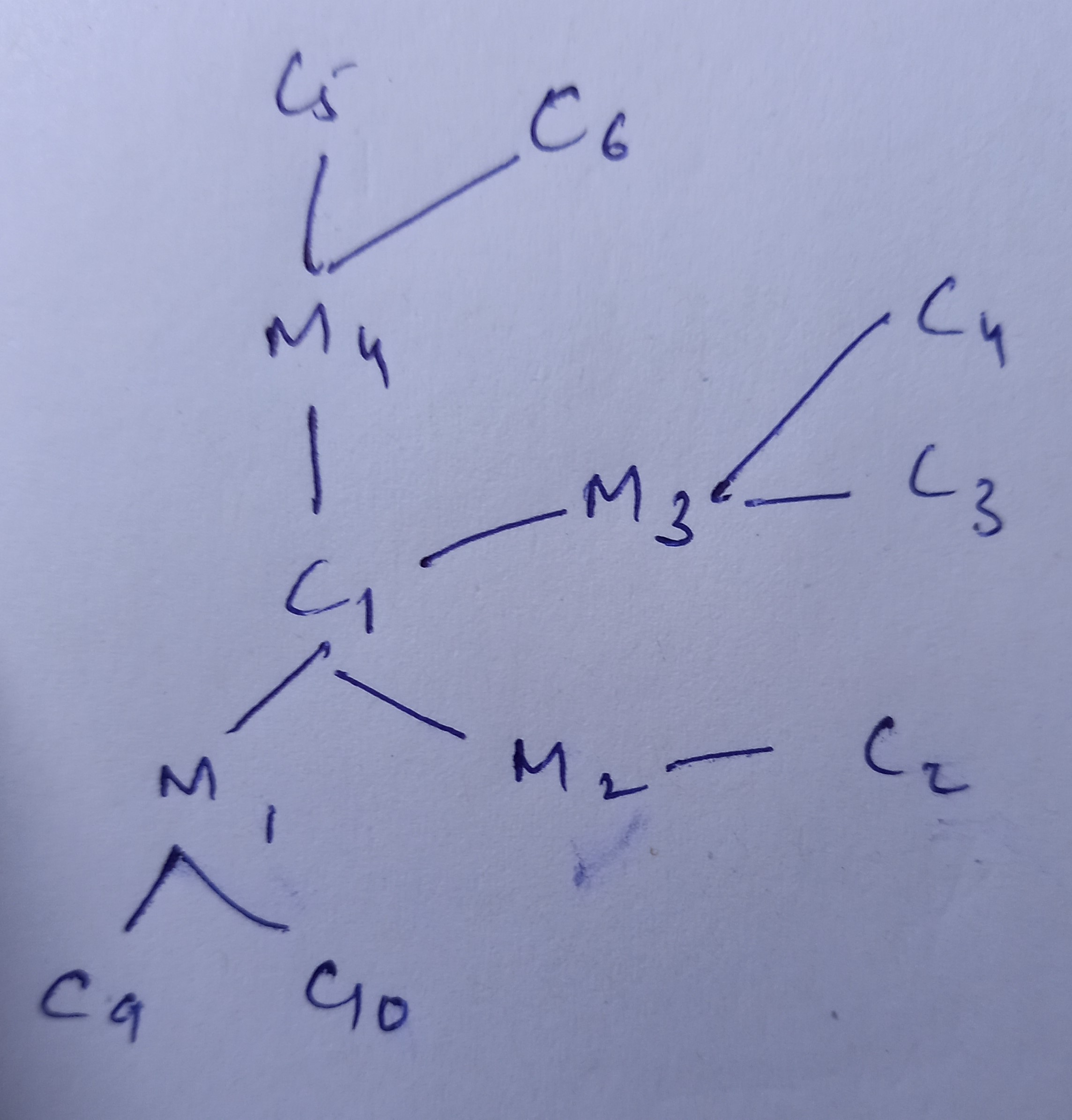
Also, if we have 2 node types ( papers and authors) and 2 edge types (paper -> author and reverse of these) and the objective is to classify the paper nodes, then how the figure (architecture) given in Could you please help me with this? I am not able to draw an architecture in this case by myself. Thank you once again! |
Beta Was this translation helpful? Give feedback.
-
|
Refer to the answer above. Now since you have to predict only on |
Beta Was this translation helpful? Give feedback.
-
|
Thanks a lot for your kind replies! :) |
Beta Was this translation helpful? Give feedback.
-
Thanks very much for your kind and so quick replies! :) |
Beta Was this translation helpful? Give feedback.
-
|
So if I understand correctly, if the source node type is paper and the destination node type is author, the features of author are passed to paper and aggregated to update the paper node. But what if the feature dimension of author is e.g. 500 and that of paper only 50? |
Beta Was this translation helpful? Give feedback.
-
|
That's is supported by passing in a tuple of input features to the layer, e.g. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for your answer. I looked a little deeper at the sageconv layer and am I correct to assume that if you have (paper, to, author) edge, the representation of author is updated using the features of paper? |
Beta Was this translation helpful? Give feedback.
-
|
That is correct. |
Beta Was this translation helpful? Give feedback.
-
|
Hi, Hope you are doing good! On the basis of our discussion, I have a couple of questions:
The task which I am working on is as follows: Currently I am just running the same model as in this link Thanks so much! :) |
Beta Was this translation helpful? Give feedback.
-
|
Sorry for the super late response. Sad to see that imbalanced sampling did not bring any gains. It is hard to tell what you can do to improve performance. Is your model overfitting or underfitting? |
Beta Was this translation helpful? Give feedback.
-
|
No worries at all :) I don't think the model is overfitting or underfitting. The loss from the beginning is very low (around 0.0746), so there is not much change after a few epochs. I stopped training it at 35 epochs as after these many epochs, the loss was changing by less than 0.0001. |
Beta Was this translation helpful? Give feedback.
-
|
Does normalizing your features help? |
Beta Was this translation helpful? Give feedback.
-
|
yes, I am normalizing the features and still getting this poor performance. :( |
Beta Was this translation helpful? Give feedback.
-
|
Yes, it could be because of imbalancing in the dataset. Could you please
elaborate how I can oversample given that I would need to create node
features as well as its corresponding edges.
…On Fri, Dec 23, 2022 at 4:55 PM zzzLemon ***@***.***> wrote:
Hi, Hope you are doing good!
On the basis of our discussion, I have a couple of questions:
1. I noticed when I used ImbalancedSampler during training GNN model,
the performance of the model is not better as to the model when we didn't
use this function.
2. How to further improve the performance of model.
The task which I am working on is as follows: I have 2 sets of nodes
(let's say type 1 and type 2), and a lot of edges between type 1 and type
2. The data stats are: #edges: 116828882, #nodes type 1: 15327758 and type
2: 5018597. I am trying to classify node type 2 either as 1 or 0 where
#nodes in class 1 node type 2 are 77281 and #nodes in class 0 node type 2
are 4941316.
Currently I am just running the same model as in this link
https://github.com/pyg-team/pytorch_geometric/blob/master/examples/hetero/hetero_conv_dblp.py.
Request you to help me what can be done to improve further the F1 score.
Currently, class 0 precision/recall are 0.98/1.00 and class 1
precision/recall are 0.40/0.03.
Thanks so much! :)
Is it because of the labels are imbalanced? i.e. nodes in class 0 type2 is
much more than nodes in class 1 node type2, maybe you can try
under/oversampling? Correct me if i understand your problem wrongly :)
—
Reply to this email directly, view it on GitHub
<#5999 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/A2ZQPGBVNTYCYR4ELEAKYPLWOWD2BANCNFSM6AAAAAASDKCLTA>
.
You are receiving this because you authored the thread.Message ID:
***@***.***
com>
|
Beta Was this translation helpful? Give feedback.
-
|
The most easiest way would be to re-weight your loss function according to class distribution, i.e. define the |
Beta Was this translation helpful? Give feedback.
-
|
Sure, I can try this quickly. Thanks once again for your kind suggestions! :) |
Beta Was this translation helpful? Give feedback.
-
|
Hi, I did try this but doesn't work. I think what you said is correct, its a data issue. Need to think of feature engineering and nodes sampling. |
Beta Was this translation helpful? Give feedback.
-
|
I think oversampling or downsampling is needed. I found an interesting paper that do oversampling for graph classification |
Beta Was this translation helpful? Give feedback.
-
|
Hi, thanks very much for your suggestion. Yes I could use SMOTE for generating new node features. But what do you suggest I should do for generating the edge set of those new nodes? |
Beta Was this translation helpful? Give feedback.
-
|
I'm also new of gnn... Do you have edge features? If not then I guess you dont need to do anything for the edge |
Beta Was this translation helpful? Give feedback.
-
|
By Edge set I mean, the connections of new nodes. We will have to create some edges (connections) for the new nodes (not the features). |
Beta Was this translation helpful? Give feedback.
-
|
Also, could you please suggest me some better ways to encode the categorical features in an efficient way for my heterogeneous graph? |
Beta Was this translation helpful? Give feedback.
-
|
Hi, no its not working for me. How shall I install torch-scatter now? That means other GNNs will be able to use GPU even if torch-scatter is CPU only? If yes, then can I keep the same CPU version if I am not using GATConv? |
Beta Was this translation helpful? Give feedback.
-
|
Not all GNN layers make use of |
Beta Was this translation helpful? Give feedback.
-
|
Oh Okay! Sure, will follow "Pip Wheel" installation guide as you suggested. Thanks very much.
|
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
Great! Yes, I am using PyG>2.0. :) Thanks very much! :) |
Beta Was this translation helpful? Give feedback.
-
|
Hi, I am not sure if the code I have written is correct and hence I intend to request you if you could please guide me if the following code is error free. Thanks very much! :)
Test code: Loading the new data, normalizing it, creating hetero graph (as I did in training file above)
|
Beta Was this translation helpful? Give feedback.
-
|
Hi @rusty1s
This is the forward function Case 1: I am not loading data in batches and passing the entire graph to the saved model which is trained on c nodes. Is the following script correct if I need to get the m node embeddings: Case 2: I am passing data in batches made on the basis of c nodes and scoring as following: How shall I get the m nodes embeddings** in this case? As the batches are made regarding the c nodes but my aim is to get the embeddings of m nodes.
It keeps throwing not enough memory error. Am I going wrong somewhere? |
Beta Was this translation helpful? Give feedback.
-
|
If you want to get the Where does the OOM gets thrown? |
Beta Was this translation helpful? Give feedback.
-
|
Thank you so much for your reply! Sorry, I didn't understand :(
|
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
Thanks so much! :) This is the log file (for data.subgraph) { |
Beta Was this translation helpful? Give feedback.
-
|
I am creating a 2 layered GNN. This is the sampler

|
{kind=link}
Beta Was this translation helpful? Give feedback.
-
|
Thanks a lot! I understand wrt to the full graph which is as follows:
2.1 This thread says, In this case, how are going to retrieve the x1 (in my understanding the final update will give x2 directly (it is having 2 hops information))? 2.2 Then, it says the following: It seems understandable if, for all 3 operations in 1st prop, we are using the raw input attributes and then in 2nd prop we are using the updated embeddings from the 1st prop (not the ones calculated in the same prop, i.e., in I am sorry for asking stupid questions. |
Beta Was this translation helpful? Give feedback.
-
|
I think your understanding is correct. In your case, you would just return the last embeddings and the previous embeddings as part of x1 = conv(x, edge_index)
x2 = conv(x1, edge_index)
return x2, x1This way, you can access the embeddings of |
Beta Was this translation helpful? Give feedback.
-
|
What about Does the explanations (in above post) specifically in |
Beta Was this translation helpful? Give feedback.
-
|
Yes, you can also make use of Yes, all your points are correct IMO. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks a lot for patiently clearing all my doubts. :) |
Beta Was this translation helpful? Give feedback.
-
|
Hi @rusty1s ! I also tried to use unsupervised methods to train embeddings. I took help from the codes available for link prediction and modified a bit to be able to train in mini batches and leverage the LinkLoader.
During training the loss is coming as follows: I couldn't understand what is wrong in the implementation. Could you please guide me why model could be behaving like this? Thanks very much! |
Beta Was this translation helpful? Give feedback.
-
|
Sorry for not being clear. You would need to drop the |
Beta Was this translation helpful? Give feedback.
-
|
Thank you! :) |
Beta Was this translation helpful? Give feedback.
-
|
A follow up ques: My aim is to learn node embeddings in an unsupervised manner and use these embeddings for node classification task. |
Beta Was this translation helpful? Give feedback.
-
|
Yes, in this case you would need to drop the |
Beta Was this translation helpful? Give feedback.
-
|
Thank you so much! :) |
Beta Was this translation helpful? Give feedback.
-
|
Hi! Is there any way I can use a distribution to sample neighbors in neighborloader. I intend to mimic this (page 4, equation 4) behavior for neigbor sampling. |
Beta Was this translation helpful? Give feedback.
-
|
Currently no, but it is on our agenda :) |
Beta Was this translation helpful? Give feedback.
-
|
Great to hear this. Thank you for this wonderful package :) |
Beta Was this translation helpful? Give feedback.
-
|
Hi @rusty1s I declared a scalar learnable weight which is multiplied to the embeddings before running a classifier. It is throwing : KeyError: 'w1' Could you guide me where I am going wrong? |
Beta Was this translation helpful? Give feedback.
-
|
I have installed PyG using master version (PyG =2.4.0). I keep getting the following error (when I try to use captum): |
Beta Was this translation helpful? Give feedback.
-
|
Run |
Beta Was this translation helpful? Give feedback.
-
|
Thanks! It got resolved but another error came:
|
Beta Was this translation helpful? Give feedback.
-
from torch_geometric.explain import Explainer |
Beta Was this translation helpful? Give feedback.
-
|
Thank you! It worked! |
Beta Was this translation helpful? Give feedback.
-
|
Hi @rusty1s! In my Hetero Data (2 node types and edges going from node type 1 to node type 2), I have very few positive label nodes of type 1 (my target class, which I want to classify). That's why I was planning to train the model by combining supervised and unsupervised losses together. My doubt was: For each batch I minimize the cross entropy loss for node type 1 labels. Now, I would like to introduce an unsupervised loss along with classification loss. Questions:
|
Beta Was this translation helpful? Give feedback.
-
|
Thanks very much for replying even on vacation. I was thinking of combining classification loss and link prediction loss (I had edited my previous comment). Currently, for classification loss, I am running as follows:
**Now, I was thinking to do link prediction (LP) task for each batch in train_loader (without dividing the batch further into train/test/val sets for LP task). ** There won't be any leakage wrt node labels or edges (since I will be using negative sampling)? |
Beta Was this translation helpful? Give feedback.
-
|
It's a bit tricky to train both node-level and link-level tasks end to end, since |
Beta Was this translation helpful? Give feedback.
-
|
Oh Yes! But if I combine |
Beta Was this translation helpful? Give feedback.
-
|
Mh, that is true. You might want to alpha a different weight on the node-level loss to account for that. |
Beta Was this translation helpful? Give feedback.
-
|
Oh, got it! Thank you :) |
Beta Was this translation helpful? Give feedback.
-
|
Hi @rusty1s! I am working on a Hetero graph with 2 node types, c and m and creating batches using**** NeighborLoader where the seed nodes are c. Could you please guide me if in a single batch can we have repeated m nodes or not? Also, if the m nodes repeating will have the same embedding or not? Thank you!! |
Beta Was this translation helpful? Give feedback.
-
|
Also, I keep getting this warning: Could you suggest if I need to do something regarding this? |
Beta Was this translation helpful? Give feedback.
-
|
The The warning seems to be related to something else. Do you have an example to reproduce? |
Beta Was this translation helpful? Give feedback.
-
|
Thank you, @rusty1s! I will try to share a reproducible code with you at the earliest. What happens is, sometimes it throws this warning and sometimes it doesn't. I didn't know if there is something wrong with the code. |
Beta Was this translation helpful? Give feedback.
-
|
Hi @rusty1s ! Sharing the code below which throws the warning shared above . This is the test code not the training code. |
Beta Was this translation helpful? Give feedback.
-
|
I ran import argparse
import os.path as osp
import warnings
from typing import List, Optional, Tuple, Union
import torch
import torch.nn as nn
import torch.nn.functional as F
from sklearn.metrics import classification_report, confusion_matrix
from torch import Tensor
from torch.nn import LSTM, Dropout, ReLU
from tqdm import tqdm
import torch_geometric
import torch_geometric.transforms as T
import torch_geometric.typing
from torch_geometric.data import HeteroData
from torch_geometric.datasets import OGB_MAG
from torch_geometric.loader import HGTLoader, NeighborLoader
from torch_geometric.nn import (
GATConv,
GATv2Conv,
GCNConv,
GraphConv,
Linear,
SAGEConv,
Sequential,
to_hetero,
)
from torch_geometric.typing import Adj, OptPairTensor, Size
class SAGE_Conv(torch_geometric.nn.conv.SAGEConv):
def __init__(self, in_channels=(-1, -1), out_channels=64, aggr="sum",
root_weight: bool = True, bias: bool = True, **kwargs):
super(SAGE_Conv, self).__init__(in_channels=in_channels,
out_channels=out_channels)
self.in_channels = in_channels
self.out_channels = out_channels
aggr_out_channels = out_channels * 3
self.lin_l = Linear(aggr_out_channels, out_channels, bias=bias)
self.update_lin0 = Linear(in_channels[0], out_channels, bias=bias)
self.update_lin1 = Linear(in_channels[1], out_channels, bias=bias)
self.reset_parameters()
def reset_parameters(self):
super().reset_parameters()
if hasattr(self, 'update_lin0'):
self.update_lin0.reset_parameters()
if hasattr(self, 'update_lin1'):
self.update_lin1.reset_parameters()
self.lin_l.reset_parameters()
if self.root_weight:
self.lin_r.reset_parameters()
def forward(self, x: Union[Tensor, OptPairTensor], edge_index: Adj,
size: Size = None) -> Tensor:
if isinstance(x, Tensor):
x: OptPairTensor = (x, x)
x = (self.act(self.update_lin0(x[0])), x[1])
out = self.propagate(edge_index, x=x, size=size)
x_r = (self.update_lin1(x[1])).relu()
new_embedding = self.lin_l(torch.add(out, x_r))
return new_embedding
class Classifier(torch.nn.Module):
def __init__(self, hidden_channels=64, out_channels=1):
super().__init__()
self.linear1 = Linear(-1, 128, weight_initializer='kaiming_uniform')
def forward(self, x2):
x3 = self.linear1(x2)
return x3.reshape((x3.shape[0]))
class GNN(torch.nn.Module):
def __init__(self, hidden_channels, out_channels):
super().__init__()
self.conv1 = SAGE_Conv((-1, -1), hidden_channels)
self.conv2 = SAGE_Conv((-1, -1), hidden_channels)
def forward(self, x, edge_index):
x1 = (self.conv1(x.float(), edge_index.long()))
x1 = x1.relu()
x2 = (self.conv2(x1, edge_index.long()))
x2 = x2.relu()
return x2
class Model(torch.nn.Module):
def __init__(self, hidden_channels=64, out_channels=1):
super().__init__()
self.gnn = GNN(hidden_channels=hidden_channels, out_channels=1)
self.gnn = to_hetero(
self.gnn,
metadata=(['x', 'y'], [('x', 'to', 'y'), ('y', 'to', 'x')]),
aggr='mean',
)
self.classifier = Classifier(hidden_channels, out_channels)
def forward(self, x, edge_index):
x2 = self.gnn(x, edge_index)
out_cc = self.classifier(x2['c'])
return out_cc
model = Model(hidden_channels=128, out_channels=1)and it works fine for me. |
Beta Was this translation helpful? Give feedback.
-
|
Hi @rusty1s ! I am running some experiments on Heterogeneous graphs. I tried SAGEConv (using neighborloader since graph is very huge) which is giving decent score. When I tried GraphConv without neighborloader, it is also giving decent score but when I tried GraphConv (aggr set to 'mean') with neighborloader, it is giving very poor results. I thought it should work similar to sageconv. Could you please guide me regarding this issue. Thank you! |
Beta Was this translation helpful? Give feedback.
-
|
Also, could you guide me if there is any example code of contrastive learning for large scale bipartite (or hetero) graphs? |
Beta Was this translation helpful? Give feedback.
-
|
You can take a look at |
Beta Was this translation helpful? Give feedback.
-
|
Thank you, @rusty1s ! :) |
Beta Was this translation helpful? Give feedback.
-
|
Hi @rusty1s ! The dataset (edge file, node features file) I am working with is very large with 1B edges. Currently, I have to load all the files in dataframes and create a graph out of them. Afterwards, I train the GNN in batches. But loading such a huge dataset in memory and creating a graph out of it requires lot of memory. Do you know if there is any algorithm/paper which creates a connected graph in batches. Thank you! |
Beta Was this translation helpful? Give feedback.
-
|
There exists various ways to do this. We are currently working on a 1B edges should roughly be 15GB, so eventually you are able to hold it in CPU memory and then use our loaders to train the GNN in mini-batches. |
Beta Was this translation helpful? Give feedback.
-
|
Hi @rusty1s ! My graph is a large graph and is heterogenous. I am using NeighborLoader to create mini batches which is sampling neighbors till 2 hops. I want to ask that in a batch, will there be unique nodes (of each type) or there could be repetitions since a particular node can be a neighbor of 2 or more than 2 nodes. Thank you!! |
Beta Was this translation helpful? Give feedback.
-
|
By default, all nodes will be unique. This only changes if you enable the |
Beta Was this translation helpful? Give feedback.
-
|
Hi @rusty1s ! Hope you are doing good. I am writing the above code to get the 1st and 2nd layer embeddings. Then on these 2 embeddings I am training a classifier to train the model. Further, once the model is trained, then I am using these embeddings to train a separate tree-based model with both the layers' embeddings (this is for some task in which we are supposed to use the GNN embeddings along with some raw features, so both the models' training is separate. Only embeddings are used from GNN output.). My issue is, I am getting low accuracy on this tree-based model. Can you help me if there is some mistake in considering these GNN layers' outputs as the embeddings? or should i consider adding activation function or if I am missing something else. I am stuck since a long so thought of taking your help. Thank you! |
Beta Was this translation helpful? Give feedback.
-
|
Hey! I ran as you said, and getting similar results. |
Beta Was this translation helpful? Give feedback.
-
|
Also, I have another doubt: my data looks like this: But when I use neighborloader with batch size of 100K and 20K seed nodes, I get the following batch: Seed node type is 'm' and 20K seed nodes are there. I am sampling 50 neighbors at each hop. Having 2 hops. My doubt is: is it possible to have so many merchants and so less (c, uses, m) edges. Also, is it possible to have less number of 2 hop edges i.e., (m, rev_uses, c) than (c, uses, m). Sorry for asking lame questions but I got confused with the batch structure. |
Beta Was this translation helpful? Give feedback.
-
|
That looks correct to me. You start sampling from merchants (via the (c, uses, m) edge type), and for every c you sample merchants again (via the (m, rev_uses, c) edge type). So the number of edges in the second hop is much larger. |
Beta Was this translation helpful? Give feedback.
-
|
Ohh, I thought, merchants would be sampled via (m, rev_uses, c) edge type and then cards would be sampled by (c, uses, m) edge type. Is this understanding not correct? |
Beta Was this translation helpful? Give feedback.
-
|
Actually it is the reverse. If we want to read out |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
Hi, I am working on Heterogeneous GNN. I have following queries regarding the same:
https://pytorch-geometric.readthedocs.io/en/latest/notes/heterogeneous.htmlIn this link, the author has explained GNN model for Heterogeneous graphs through a diagram. Could you please explain me why there is one SAGEConv layer between x_paper and x_author nodes? I thought the output of the same SAGEConv layer which is used to calculate hidden features of paper node will be passed to the x_author nodes but they have added a seperate SAGEConv layer.Also, could you please explain the working behind the NeighbourhoodLoader (how the batches are being created and does the function consider all the neighbors of the nodes in the current batch and then their neighbors (i.e., neighbors of neighbors of nodes). If yes then it can lead to all the nodes in the same batch. I am extremely sorry for such a vague explanation.
Thanks very much!
Beta Was this translation helpful? Give feedback.
All reactions