-
|
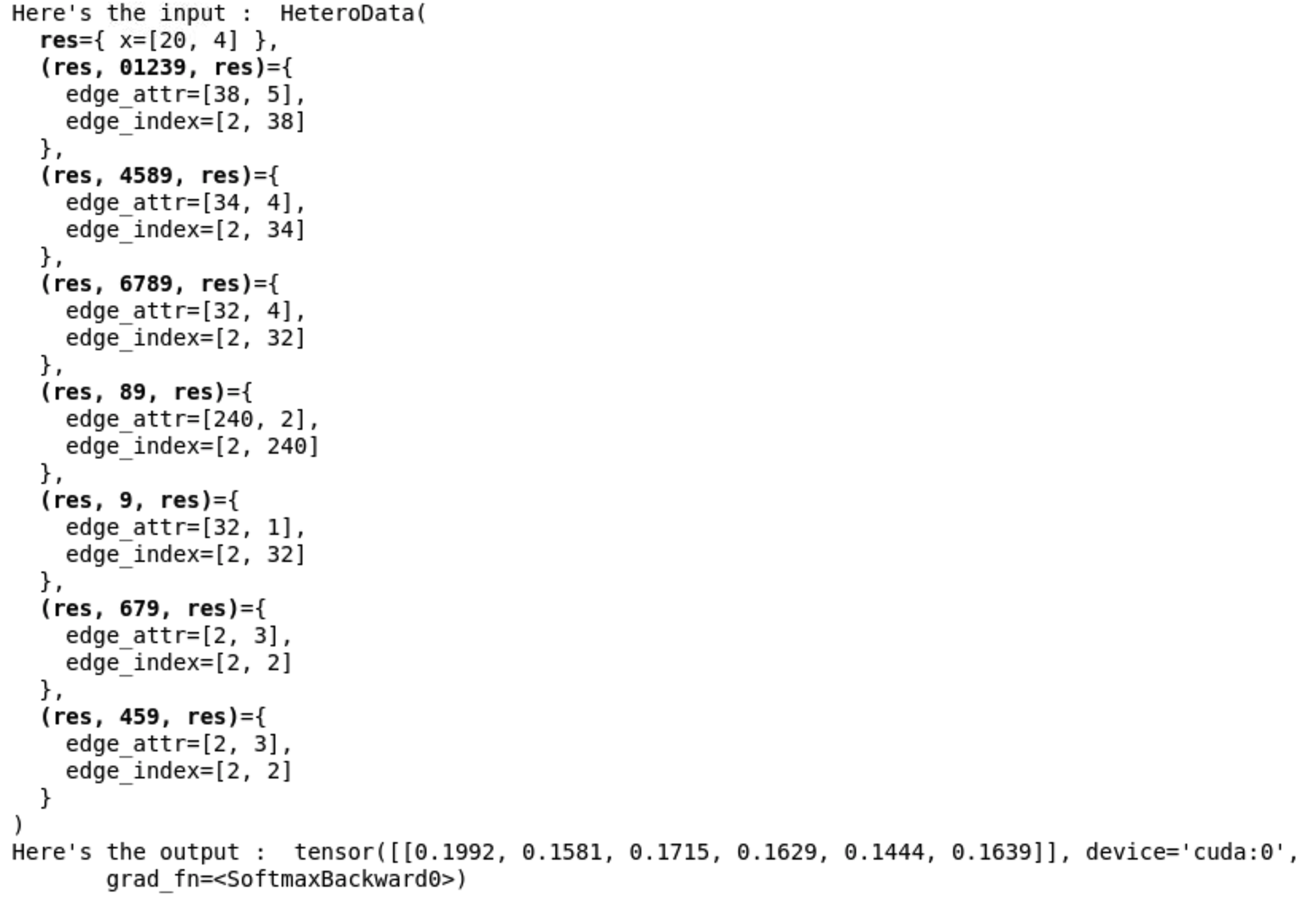
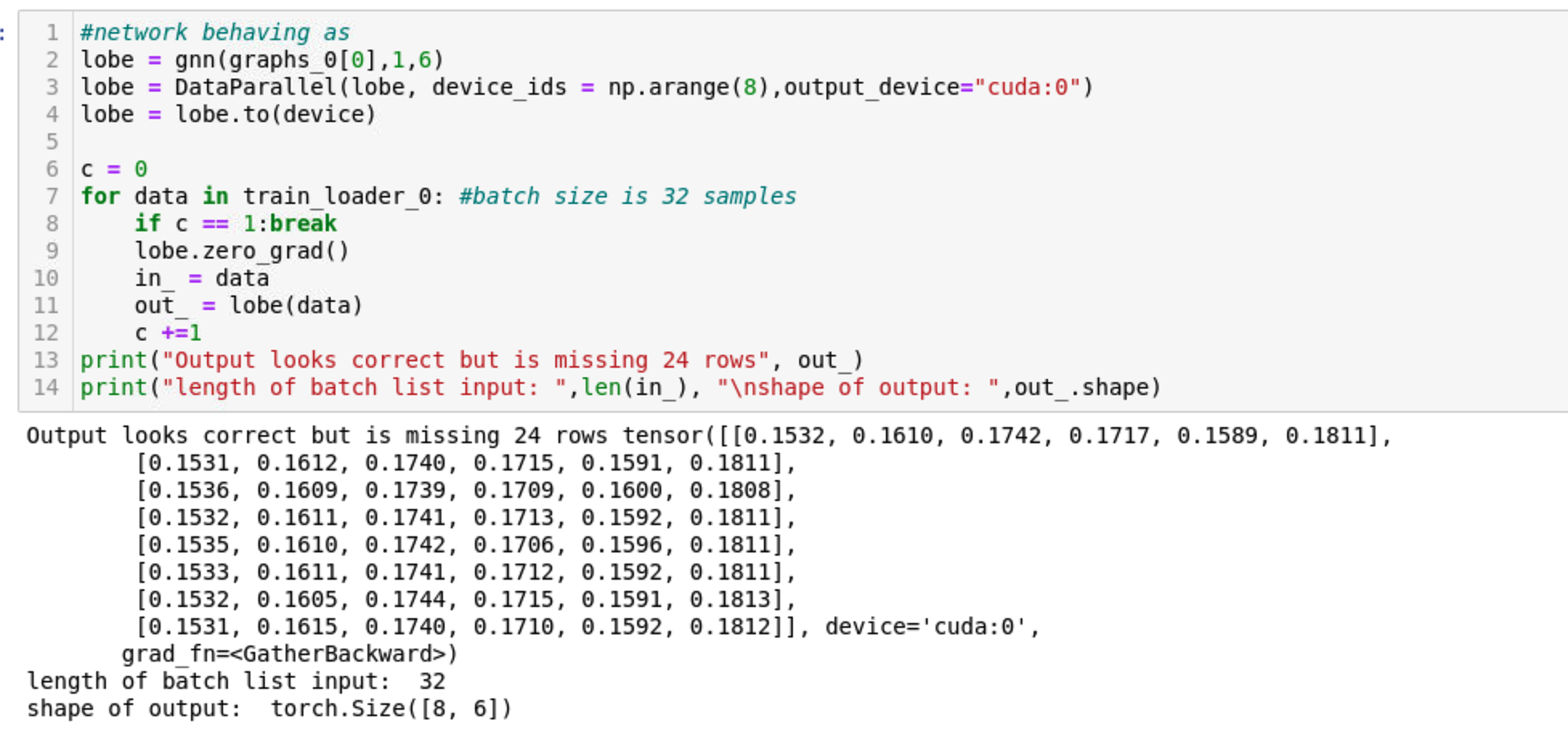
I am attempting to use DataParallel and DataListLoader to train the graph neural network shown below (ignoring all but the forward method) on 8 GPUs. The network takes a Heterograph as input and returns a softmax output. When I run a single sample through the network without applying DataParallel, I get the expected softmax output. However, when I apply DataParallel to the network module and pass a batch/list of graphs from DataListLoader through it in a training loop, I am only returned 8 tensors. Upon further inspection, I found that the number of outputs I get == the number of GPUs I specify in the DataParallel call. Below the forward method of the network I show the output I get outside of the training loop without applying DataParallel and after that I show the result of passing data through the model in a training loop where DataParallel is applied and the batch is loaded from DataListLoader. Simply put, I want to return the softmax output for all samples in the batch with the correct grad_fn (softmax) so I can input them into a user defined loss function i.e. a loss function not offered by PYG or regular torch. I am new to graph neural networks and am likely at fault here but I can't see any obvious reason why this problem would arise based on docs and example. Please let me know what I'm doing wrong :)
|


Beta Was this translation helpful? Give feedback.
Replies: 1 comment 1 reply
-
|
I am not totally sure if |
Beta Was this translation helpful? Give feedback.
-
|
Indeed, seamless! Thank you!! |
Beta Was this translation helpful? Give feedback.
I am not totally sure if
DataListLoaderworks withHeteroDataobjects TBH. The recommended approach is to useDistributedDataParallelfor this. Here is an example: https://github.com/pyg-team/pytorch_geometric/blob/master/examples/multi_gpu/distributed_batching.py which should work seamlessly withHeteroDataobjects as well.