Dataset/dataloader sharing (CPU or GPU) #6804
Replies: 5 comments 7 replies
-
|
|
Beta Was this translation helpful? Give feedback.
-
|
I'll try the example, I just thought DDP is useful when you have one large model and you have more than one device available. Just to clarify, will that example allow me to train in parallel multiple copies of the same architecture on one device? I don't need gradient synchronization, i.e. the compies of my model must be completely isolated. For context: I want to get confidence intervals on the predictions of my model, which is trained in an unsupervised way. After some fumbling, this is what seems to be working (but likely flat wrong in terms of saving memory): |
Beta Was this translation helpful? Give feedback.
-
|
Yes, I think this is how you would do it. I think it might make sense though to define a |
Beta Was this translation helpful? Give feedback.
-
|
Yes, but there's a problem with this apprach. Pytorch seems to still create copies of the data in GPU memory (see screenshot, device: A6000). I create 16 copies of the model (each with roughly 4500 parameters), the whole dataset is about 1.5 GB (when stored on disk via |
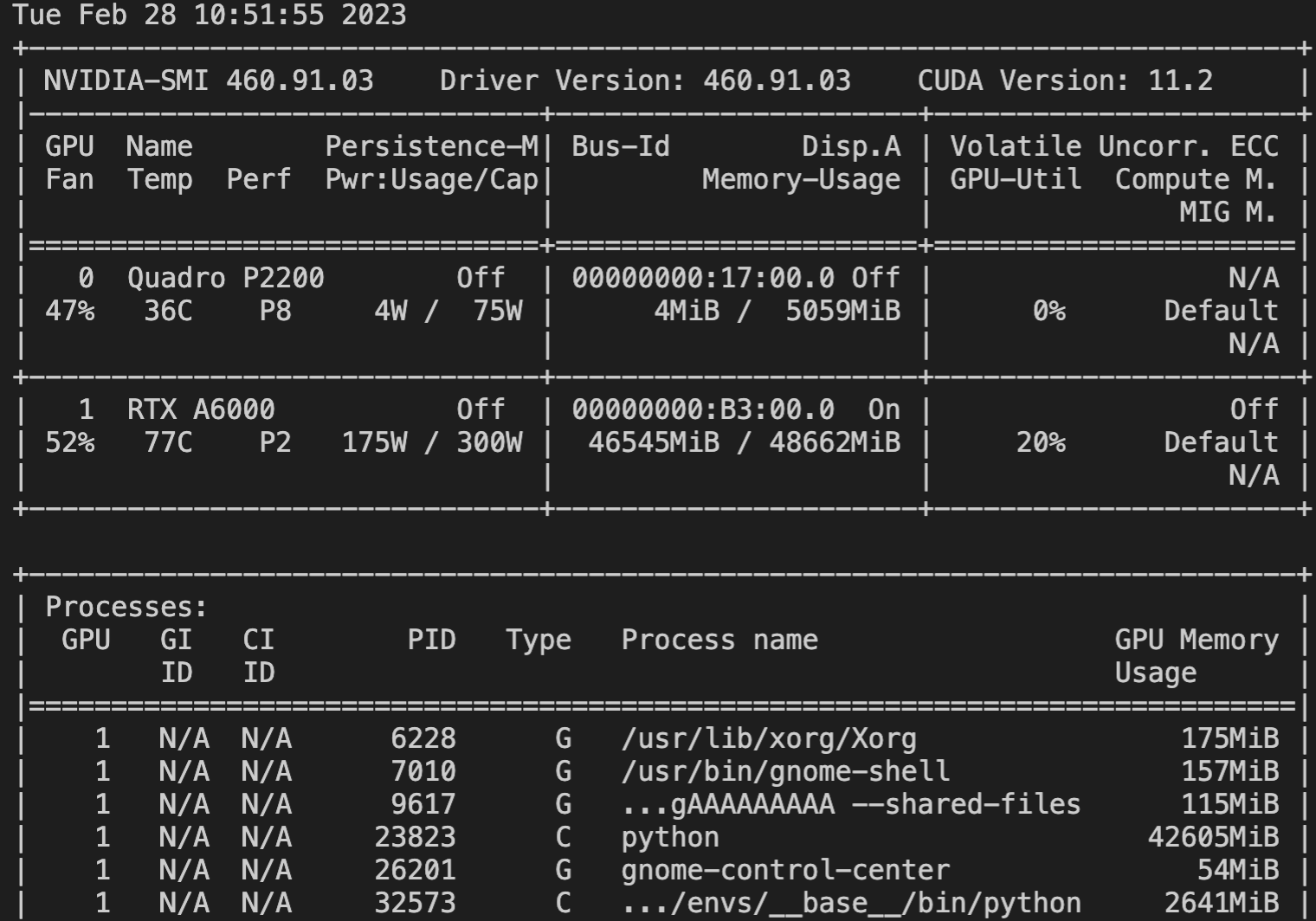
Beta Was this translation helpful? Give feedback.
-
|
I see. Is there any reason you need to move the dataset to each device beforehand? I would advice to keep it on CPU (in which case it should get correctly shared), and then just move sampled mini-batches to the GPU. |
Beta Was this translation helpful? Give feedback.
-
|
The reason to move to dataset to the device is to avoid the time-consuming
CPU-to-GPU copying overhead. I have a big good A6000 with 48GB of RAM, so
why not put the entire dataset on GPU? This is what I always do as long as
both the model and the data can fit into GPU memory.
…On Tue, Feb 28, 2023, 5:45 PM Matthias Fey ***@***.***> wrote:
I see. Is there any reason you need to move the dataset to each device
beforehand? I would advice to keep it on CPU (in which case it should get
correctly shared), and then just move sampled mini-batches to the GPU.
—
Reply to this email directly, view it on GitHub
<#6804 (reply in thread)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AGIRPJYMZ6CU7Q46CO5SEG3WZW3I3ANCNFSM6AAAAAAVI5LCWQ>
.
You are receiving this because you authored the thread.Message ID:
***@***.***
com>
|
Beta Was this translation helpful? Give feedback.
-
|
Ok, but in this case you can no longer share the data between processes AFAIK. |
Beta Was this translation helpful? Give feedback.
-
|
In the code I provided above, the sharing is between _threads_, not processes. Am I right that, threads do support memory sharing, but processes don’t? That was my idea for using threads instead of `torch.multiprocessing`.
… On 28 Feb 2023, at 19:58, Matthias Fey ***@***.***> wrote:
Ok, but in this case you can no longer share the data between processes AFAIK.
—
Reply to this email directly, view it on GitHub <#6804 (reply in thread)>, or unsubscribe <https://github.com/notifications/unsubscribe-auth/AGIRPJ546MWC4MPXZNLSE5LWZXK6NANCNFSM6AAAAAAVI5LCWQ>.
You are receiving this because you authored the thread.
|
Beta Was this translation helpful? Give feedback.
-
|
Can you take a look at https://pytorch.org/docs/stable/notes/multiprocessing.html? It looks like CUDA is indeed supported when using |
Beta Was this translation helpful? Give feedback.
-
|
@rusty1s It seems that with import torch, time, sys, os, copy
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
sys.path.append('../')
import torch
import torch.multiprocessing as mp
from torch.utils.data import DataLoader, TensorDataset
from termcolor import cprint
queue = mp.Queue()
# Define your model
class MyModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc1 = torch.nn.Linear(10, 10)
self.relu = torch.nn.ReLU()
self.fc2 = torch.nn.Linear(10, 2)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# Define a function to train a single copy of the model
def train_model(rank, queue, DEVICE):
# Set the random seed for reproducibility
torch.manual_seed(rank)
X, y = queue.get()
cprint(f'Rank: {rank}, X data_ptr: {X.data_ptr()}', color='yellow')
# Load your dataset
dataset = TensorDataset(
X,
y,
)
# Set the device to the current process's device
model = MyModel().to(DEVICE)
cprint(f'Rank: {rank}, model data_ptr: {list(model.parameters())[0].data_ptr()}', color='blue')
# Create a DataLoader for your dataset
dataloader = DataLoader(dataset, batch_size=32, shuffle=False)
# Define the loss function and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# Train the model
for epoch in range(100):
for i, (inputs, labels) in enumerate(dataloader):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if (i + 1) % 10 == 0:
print(
f"Process {rank} Epoch [{epoch + 1}/{100}], Step [{i + 1}/{len(dataloader)}], Loss: {loss.item():.4f}"
)
cprint(f'{rank} finished!', color='yellow')
# Spawn a separate process for each copy of the model
# mp.set_start_method('spawn') # must be not fork, but spawn
NUM_MODEL_COPIES = 10
DEVICE = 'cuda:0'
processes = []
for rank in range(NUM_MODEL_COPIES):
process = mp.Process(target=train_model, args=(rank, queue, DEVICE))
process.start()
processes.append(process)
time.sleep(2)
X = torch.rand(size=(10000, 10)).to(DEVICE)
y = torch.randint(2, size=(10000,)).to(DEVICE)
for rank in range(NUM_MODEL_COPIES):
queue.put((X, y))
# Wait for all processes to finish
for process in processes:
process.join()
While the dataset tensors in each process point to the same location in GPU memory, the model (each of which is created inside the separate processes) point to the same (!) address. How is that possible, if they are created inside indepedent processes? Here's the output of |
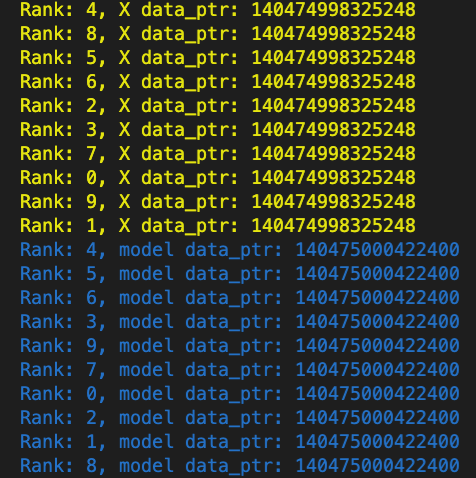
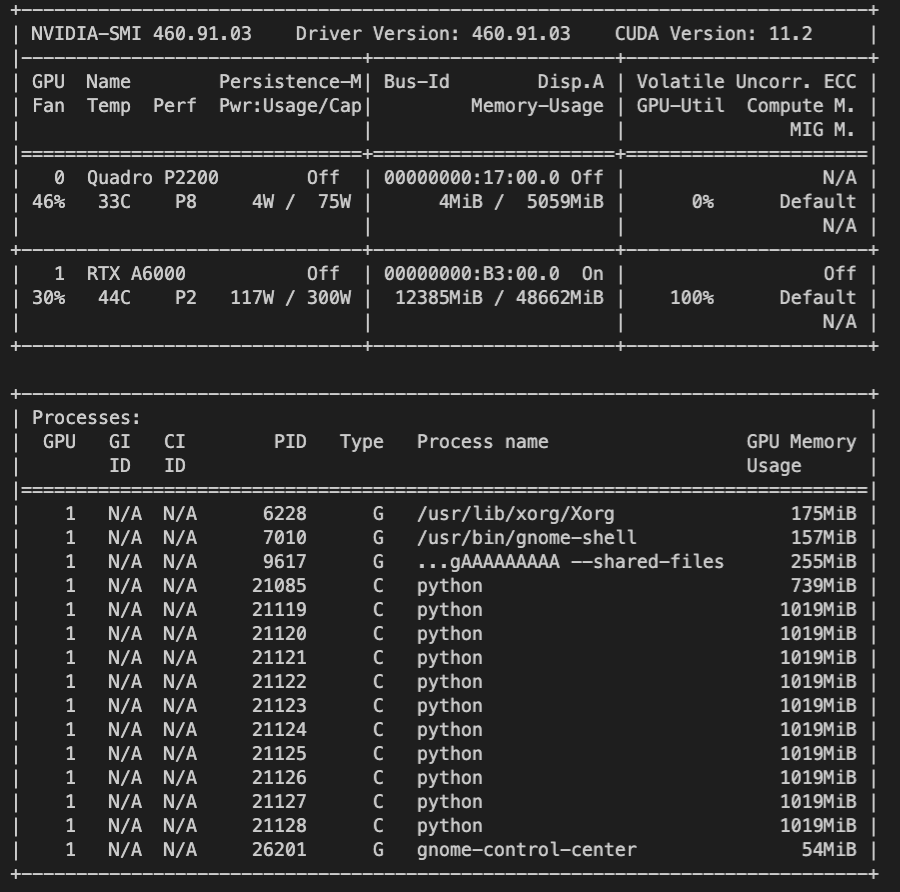
Beta Was this translation helpful? Give feedback.
-
|
Mh, I am not totally sure TBH. Can you confirm that they are truly shared? Does incrementing one parameter also increments the parameter in the other process? |
Beta Was this translation helpful? Give feedback.
-
|
I figured it out (almost everything).
One remaining concern is that a small model inside each process allocates 1 GB of GPU memory. I though that I would be able to train hundreds of small models on one GPU in parallel, but now that seems impossible (or is it?). Below is the complete code snippet to reproduce: import torch, time, sys, os, copy
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
sys.path.append('../')
import torch
import torch.multiprocessing as mp
from torch.utils.data import DataLoader, TensorDataset
from termcolor import cprint
# Spawn a separate process for each copy of the model
# mp.set_start_method('spawn') # must be not fork, but spawn
queue = mp.Queue()
# Define your model
class MyModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc1 = torch.nn.Linear(10, 10)
self.relu = torch.nn.ReLU()
self.fc2 = torch.nn.Linear(10, 2)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# Define a function to train a single copy of the model
def train_model(rank, queue, DEVICE):
# Set the random seed for reproducibility
torch.manual_seed(rank)
X, y, bias = queue.get()
cprint(f'Rank: {rank}, X data_ptr: {X.data_ptr()}', color='yellow')
# Load your dataset
dataset = TensorDataset(
X,
y,
)
# Set the device to the current process's device
with torch.no_grad():
model = MyModel().to(DEVICE)
model.fc1.bias = torch.nn.Parameter(bias)
if rank == 0:
# changing weight in one model in a separate process doesn't affect the weights in the model in another process, because the weight tensors are not shared
model.fc1.weight[0][0] = -33.0
# but changing bias (which is a shared tensor) should affect biases in the other processes
model.fc1.bias *= 4
cprint(f'RANK: {rank} | {list(model.parameters())[0][0,0]}', color='magenta')
if rank == 8:
cprint(f'RANK: {rank} | {list(model.parameters())[0][0,0]}', color='red')
cprint(f'RANK: {rank} | BIAS: {model.fc1.bias}', color='red')
ptr = model.fc1.weight[0][0].storage().data_ptr()
cprint(f'Rank: {rank}, model data_ptr: {ptr}', color='blue')
# Create a DataLoader for your dataset
dataloader = DataLoader(dataset, batch_size=32, shuffle=False)
# Define the loss function and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# Train the model
for epoch in range(100):
for i, (inputs, labels) in enumerate(dataloader):
if rank == 0:
cprint(f'RANK: {rank} | {list(model.parameters())[0][0,0]}', color='magenta')
cprint(f'RANK: {rank} | BIAS: {model.fc1.bias}', color='magenta')
if rank == 8:
cprint(f'RANK: {rank} | {list(model.parameters())[0][0,0]}', color='red')
cprint(f'RANK: {rank} | BIAS: {model.fc1.bias}', color='red')
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
# optimizer.step()
if (i + 1) % 10 == 0:
print(
f"Process {rank} Epoch [{epoch + 1}/{100}], Step [{i + 1}/{len(dataloader)}], Loss: {loss.item():.4f}"
)
cprint(f'{rank} finished!', color='yellow')
NUM_MODEL_COPIES = 10
DEVICE = 'cuda:0'
processes = []
for rank in range(NUM_MODEL_COPIES):
process = mp.Process(target=train_model, args=(rank, queue, DEVICE))
process.start()
processes.append(process)
time.sleep(2)
X = torch.rand(size=(10000, 10)).to(DEVICE)
y = torch.randint(2, size=(10000,)).to(DEVICE)
shared_bias = torch.ones(size=(10,), device=DEVICE)
for rank in range(NUM_MODEL_COPIES):
queue.put((X, y, shared_bias))
# Wait for all processes to finish
for process in processes:
process.join() |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
I have a small GNN (~ 2K parameters) and a rather large (~1.5GB) dataset. I want to train multiple instances of my model in parallel with different HPs (and initializations). I could do it with an MLP using
torch.multiprocessing, but it didn't work with a PyG model and a PyG dataset/dataloader object. Even iftorch.multiprocessingdid work, I suspect the dataset would be copied for each process (and I want each processes to use one single copy of the dataset). Any suggestions?Beta Was this translation helpful? Give feedback.
All reactions