Replies: 2 comments 3 replies
-
|
|
Beta Was this translation helpful? Give feedback.
-
|
I sadly don't have a good answer for you, but I think it is important to note that different GNN layers have different strengths and biases built into them, which might explain your observed issues. For example, GCN is good at smoothing the surrounding neighborhood into a single embedding, while GAT can learn more fine-granular patterns (e.g., to discard certain neighbors). |
Beta Was this translation helpful? Give feedback.
-
|
Thank you very much for your reply! |
Beta Was this translation helpful? Give feedback.
-
|
Yeah, this is just a guess though, but usually metapaths are pretty dense, and so GCN may provide a better job of integrating the average signal of neighbors here. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you very much for your guidance and help. I will continue to improve and learn from other aspects |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
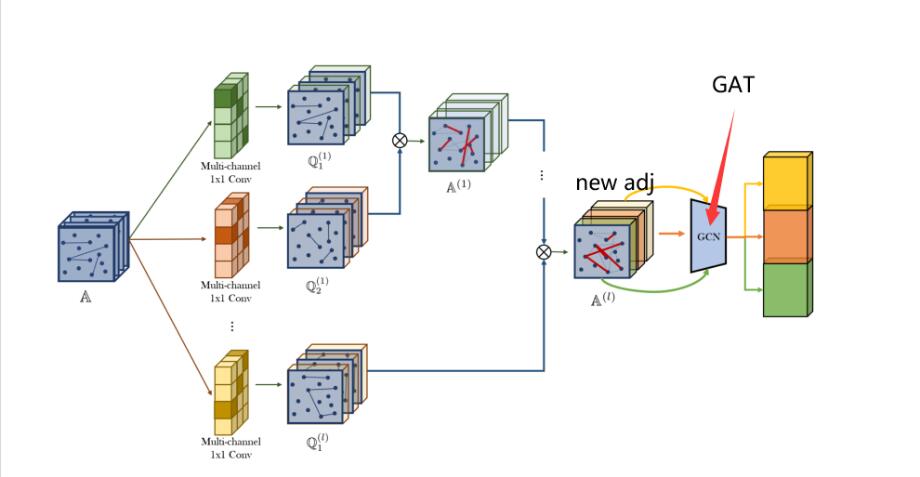
hello!, Dear professors.
In the process of learning, I made some changes to the GTN model. Some questions are raised about the experimental results.
The original model is to learn the adjacency matrix, automatically generate meta-paths, and combine to generate a new adjacency matrix, then learn through a layer of GCN, and finally output through two linear layers.
My change: replace GCN to GAT, but the experimental results were not ideal, from the original F1-score: 0.925 to 0.78The experimental effect of heads=1 is higher than heads=8, and GAT-layer=1 is better than GAT-layer=2.(The GAT model works similar whether it is defined or introduced from pyG)
The loss function is also difficult to reduce, down to 0.42 after 100 epoch
The dataset is used with the following data sets:ACM
Is GAT ineffective for meta-path-based learning?
How do you explain this reason?
Beta Was this translation helpful? Give feedback.
All reactions