Generating new PDF from another PDF with text only #1527
-
|
Hello, Looking to extract only text from a PDF and save the same as a new PDF. Found some relevant methods in the package, ie: Here's a sample working code snippet: import fitz
doc = fitz.open("pdfs/RPHT24.pdf")
page = doc[0]
textBlocks = page.get_text_blocks(0)
# open output PDF
newdoc = fitz.open()
# output page with same dimensions as input
newpage = newdoc.new_page(width=page.rect.width, height=page.rect.height)
blue = (0, 0, 1)
for textBlock in textBlocks:
r = fitz.Rect(textBlock[0], textBlock[1], textBlock[2], textBlock[3])
newpage.insert_text(fitz.Point(textBlock[0], textBlock[1]), textBlock[4], color=blue)
newdoc.save("x.pdf")Are there any other code samples that helps in rendering the text with full formatting and better positioning? Thanks! |
Beta Was this translation helpful? Give feedback.
Replies: 9 comments 58 replies
-
|
Sure! To see some code that actively uses this together with "TextWriter", look at this script. It is part of the font replacement utilities. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for your prompt response @JorjMcKie Had earlier come across Meanwhile, it would be helpful if you could point to a relatively simpler script. |
Beta Was this translation helpful? Give feedback.
-
|
I think your intention by its very nature implies the better part of the perceived complexity.
So I believe you must walk through all that mud if you want to do this kind of thing. |
Beta Was this translation helpful? Give feedback.
-
|
Certainly @JorjMcKie, there is a lot that needs to be done to ensure that the text is rendered correctly.
It is most likely this mud which will turn out to be gold😀
Yes, had planned to do so. |
Beta Was this translation helpful? Give feedback.
-
import fitz
doc = fitz.open("pdfs/RPHT24.pdf")
page = doc[0]
# open output PDF
newDocument = fitz.open()
# output page with same dimensions as input
newPage = newDocument.new_page(width=page.rect.width, height=page.rect.height)
font = fitz.Font("tibo")
tw = fitz.TextWriter(page.rect, color=(1, 0, 0))
# Get text blocks.
blocks = page.get_text("dict")["blocks"]
for textBlock in blocks:
if "lines" not in textBlock:
continue
lines = textBlock["lines"]
for line in lines:
for span in line["spans"]:
textBox = span['bbox']
text = span['text']
# tw.append(span["origin"], text, font=font, fontsize=span["size"])
tw.fill_textbox( # fill in above text
textBox, # keep text inside this
text, # the text
align=fitz.TEXT_ALIGN_LEFT, # alignment
warn=True, # keep going if too much text
fontsize=span["size"],
font=font,
)
outcolor = fitz.sRGB_to_pdf(span["color"]) # recover (r,g,b)
tw.write_text(page, color=outcolor)
newDocument.save("output/textBoundaries.pdf")The purpose of this script is to generate a new PDF with only the text. Had built the above script based on the samples and examples you created in the PyMuPDF utility libraries. However, due to some reason, it is not working as expected. Use the below two code chunks for writing the text in the PDF, both did not work. tw.append(span["origin"], text, font=font, fontsize=span["size"]) tw.fill_textbox( # fill in above text
textBox, # keep text inside this
text, # the text
align=fitz.TEXT_ALIGN_LEFT, # alignment
warn=True, # keep going if too much text
fontsize=span["size"],
font=font,
)Yet to find anything in the documentation. @JorjMcKie can you point and help in resolving what could be wrong here? |
Beta Was this translation helpful? Give feedback.
-
|
you did not mention what exactly went wrong |
Beta Was this translation helpful? Give feedback.
-
|
another point: |
Beta Was this translation helpful? Give feedback.
-
|
Sorry for the incomplete information. The issue is, no text is being rendered in the PDF. When using the Any ideas on how to get the |
Beta Was this translation helpful? Give feedback.
-
|
The warning means what it actually says: given the rectangle, the fontsize, the amount of text, ... then only x lines will fit where y lines have been generated that should be written. So enlarge the rectangle, decrease the fontsize, reduce the text amount, etc. Let me ask a silly question: if no text is rendered ... you did not forget to execute |
Beta Was this translation helpful? Give feedback.
-
Yes, had understood the warning. However, wanted to see how
|
Beta Was this translation helpful? Give feedback.
-
|
when looking at your code snippet: you want to write on a new, separate page, right? |
Beta Was this translation helpful? Give feedback.
-
Hmm, ok. Good that we know of it now.
Attempted running the script in one of pdfs, however, the rendering of the text is broken.
Fonts extracted from the PDF:
Type 3 fonts are anyway severely outdated from what I remember. The |

Beta Was this translation helpful? Give feedback.
-
|
@JorjMcKie Further experimented with text rendering styles and found some instances where the rendering is off.
Input PDF: PHT23.pdf While the usage of such rendering style would be rare, there are chances of such occurences - probably MuPDF does not support this. |

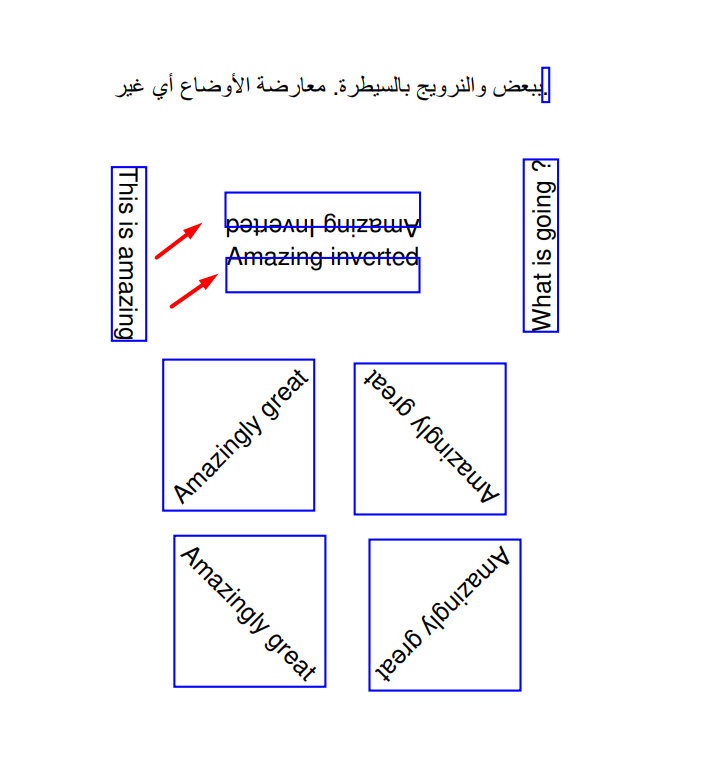
Beta Was this translation helpful? Give feedback.
-
|
Regarding Bounding Boxes: The bounding boxes for span parsed when using rawdict are different from when using dict for the Arabic text. Not sure why - either it's a bug, or, incorrect expectations. When using When using Script used: import fitz
fileName = "RPHT24"
fileName = "PHT22"
fileName = "PHT23"
doc = fitz.open("pdfs/%s.pdf" % fileName)
page = doc[0]
ndoc = fitz.open()
npage = ndoc.new_page(width=page.rect.width, height=page.rect.height)
extra_flags = fitz.TEXT_PRESERVE_LIGATURES | fitz.TEXT_PRESERVE_WHITESPACE
blocks = page.get_text("rawdict")["blocks"]
helv = fitz.Font("helv")
arial = fitz.Font(fontfile="C:/Windows/Fonts/arial.ttf")
for b in blocks:
if "lines" not in b:
continue
for l in b["lines"]:
cos, sin = l["dir"]
matrix = fitz.Matrix(cos, -sin, sin, cos, 0, 0)
for s in l["spans"]:
textBox = s['bbox']
fsize = s["size"]
fname = s["font"]
for c in s["chars"]:
if fname.lower().startswith("arial"):
font = arial
else:
font = helv
ch = c["c"]
origin = fitz.Point(c["origin"])
tw = fitz.TextWriter(page.rect)
tw.append(origin, ch, font=font, fontsize=fsize)
tw.write_text(npage, morph=(origin, matrix))
shape = npage.new_shape()
shape.draw_rect(textBox)
shape.finish(
fill=None, # fill color
color=(0, 0, 1), # line color
)
shape.commit()
npage.clean_contents() # recommended
ndoc.subset_fonts() # recommended
ndoc.ez_save("x.pdf", garbage=4) # garbage=4 recommended!! |
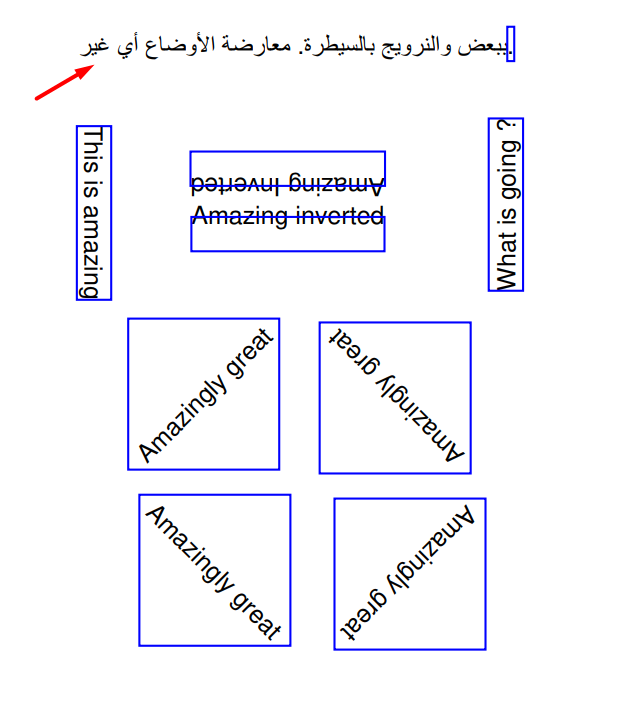

Beta Was this translation helpful? Give feedback.
-
|
Those are good examples! Helped me to identify a logic error in creating the matrix for the TextWriter. |
Beta Was this translation helpful? Give feedback.
-
|
Tested this @JorjMcKie. So the script now supports text rendering for all cases. Of course, during cases when font buffers do not work, font size can be computed using |
Beta Was this translation helpful? Give feedback.
-
|
just looked again at FontForge: you can use that for font conversion, too. |
Beta Was this translation helpful? Give feedback.
-
|
@JorjMcKie The CID related font error when processing the PDF using This is not directly related to PyMuPDF - posting here in case it can point to something in the library that could be improved. |
Beta Was this translation helpful? Give feedback.
-
|
I have reviewed again why spans are misplaced in some occasions, but not in others, and found another small wrinkle that is causing this. |
Beta Was this translation helpful? Give feedback.
-
|
Ran this script on 1.19.5 on Some text is rendered incorrectly. On inspecting, realized that the usage of |
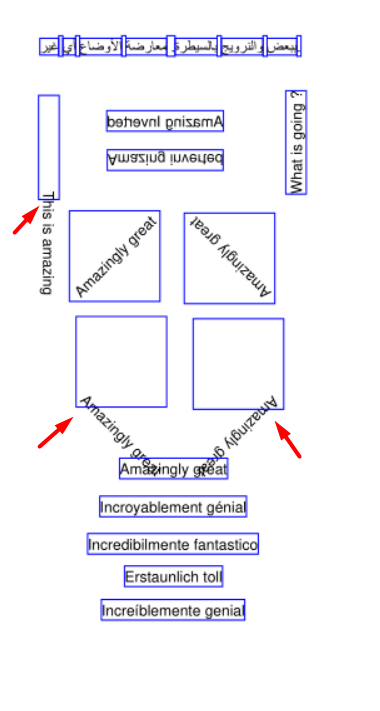
Beta Was this translation helpful? Give feedback.
-
|
oops - sorry gave you an old py38 wheel: |
Beta Was this translation helpful? Give feedback.
-
|
No problem. Will use this in sometime and post feedback here ✏️ |
Beta Was this translation helpful? Give feedback.
-
|
Tried with the above wheel - similar issue persists. Checking if it is due to a a local issue. |
Beta Was this translation helpful? Give feedback.
-
|
Worked as expected. Had to restart the PyCharm IDE.
|

Beta Was this translation helpful? Give feedback.
-
|
PyMuPDF-1.19.5-cp38-cp38-win_amd64.zip |
Beta Was this translation helpful? Give feedback.
-
|
You can now do your tests on WIndows or Linux |
Beta Was this translation helpful? Give feedback.
-
|
Is this the linux wheel for Python 3.6? |
Beta Was this translation helpful? Give feedback.
-
|
No, you seem to have Python 3.6 in the Linux of your WSL. If necessary, confirm via |
Beta Was this translation helpful? Give feedback.
-
|
Also, do consider to upgrade your Linux Python: as I mentioned, version 3.6 is out of maintenance since December 2021. Like PyMuPDF: I will not publish a 3.6 version for my v1.19.5 on PyPI (planned for end of January). Anyone needing this version for 3.6 would need to build it from sources by himself. |
Beta Was this translation helpful? Give feedback.
-
|
Sure, this makes sense. No matter how avoidable an update appears, it is always best to do it at the earliest. |
Beta Was this translation helpful? Give feedback.
-
|
@JorjMcKie The setup on Windows worked seamlessly. However, on Linux the following error is thrown: Looks like it is pointing towards an error in the |
Beta Was this translation helpful? Give feedback.
-
|
Have you checked whether this error message is actually true, e.g. via some other ZIP program? 7zip? |
Beta Was this translation helpful? Give feedback.
-
|
Command used: Output: Python: OS: Any ideas on why there is a failure? @JorjMcKie. Platforms appear to be correct. |
Beta Was this translation helpful? Give feedback.
-
|
WTF is going on there?! |
Beta Was this translation helpful? Give feedback.
-
|
It is not @JorjMcKie |
Beta Was this translation helpful? Give feedback.
-
|
I am out of good ideas for now 😒 |
Beta Was this translation helpful? Give feedback.
-
|
Hmm, would be great if you could let me know when something lights up. |
Beta Was this translation helpful? Give feedback.
-
|
Attempted to generate a PDF with only text using two approaches: PDF when using TTF files directly (image blurred in this case for confidentiality purposes): PDF when using fonts extracted from the PDF: Any ideas on why the PDF's font is broken when generated using the fonts in the PDF? |


Beta Was this translation helpful? Give feedback.
-
|
@JorjMcKie Any ideas on why the above is happening? |
Beta Was this translation helpful? Give feedback.
I have reviewed again why spans are misplaced in some occasions, but not in others, and found another small wrinkle that is causing this.
After implementing the change, your two example files PHT23.pdf / PHT22.pdf are now both processed correctly just using the "dict" option.
I will create a set of pre-wheels and will let you know when they are done.