Spotting text in PDF table cells #1657
-
|
Hi i'm working on a user case where i need to de-structure the whole pdf document and restructure in the flutter app.
tables, drawings and extracted images will fit under Problem This should work for drawings in the provided documents. i expect this to work for tables as well but no text has been extracted if there's a table as drawing. The Documents are attached. Please help me out I've tried the rects in get_texttrace as well they're also not returning the full text. I've been stuck at this for days given the potential of pymupdf this is best for for my use case if i can just get all the text for tables as well just like i'm extracting for drawings that'll solve a lot of my problems. |
Beta Was this translation helpful? Give feedback.
Replies: 8 comments 11 replies
-
|
I haven't yet looked into details, but here a first hint: |
Beta Was this translation helpful? Give feedback.
-
|
Thank you for your reply, the problem is not the rects that I get from get_drawings() are returning text for the drawings but not for the tables. for tables they're just returning the header's text. |
Beta Was this translation helpful? Give feedback.
-
|
When i recreate this workflow in this document this is what I get when I recreate the table in this document this is what I get |
Beta Was this translation helpful? Give feedback.
-
|
Ok, I see. |
Beta Was this translation helpful? Give feedback.
-
|
yes, i've thought that initially but when I check if there's any line being drawn using the following, there's no line only rects length of paths and trect is the same i-e 156. |
Beta Was this translation helpful? Give feedback.
-
|
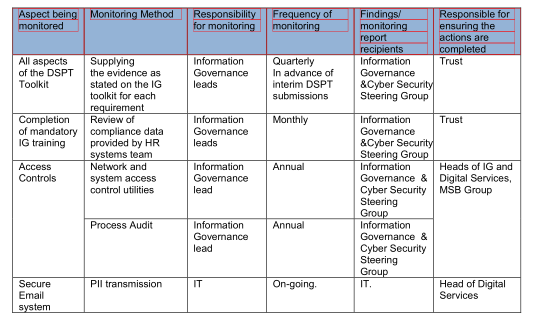
Indeed, if you do this: doc=fitz.open(doc.name)
page=doc[26]
for p in paths:
for item in p["items"]:
if item[0] == "re":
r=item[1]
if r.width >2 and r.height>2:
page.draw_rect(item[1],color=(1,0,0),width=0.3)You get this: |
Beta Was this translation helpful? Give feedback.
-
|
i see, is there any way i can extract the text from rest of the cells? |
Beta Was this translation helpful? Give feedback.
-
|
Depends on how lines are drawn. Many PDF creators do not actually draw lines, but thin rectangles instead. |
Beta Was this translation helpful? Give feedback.
-
|
For example MS Word and LibreOffice do that in their PDF exports. Obviously because thin rectangles behave more consistent under zooms than drawn lines do. |
Beta Was this translation helpful? Give feedback.
-
|
i have a set of pdfs available and this behaviour is same across all the pdfs, getting the text from headers but not from all cells. i'd appreciate if you can provide some insight in this regard. i can get text from whole page using |
Beta Was this translation helpful? Give feedback.
-
|
As I wrote: you are on your own here. |
Beta Was this translation helpful? Give feedback.
-
|
Okay thank you for the explanation. much appreciated |
Beta Was this translation helpful? Give feedback.
-
|
I am not sure what your ultimate goal actually is. |
Beta Was this translation helpful? Give feedback.
-
|
the ultimate goal is to se structure the whole pdf document into a json and from that json the document will be recreated in the mobile app for better visualization where we can increase or decrease the text or change the color for visually impaired individuals. tables, images and drawings needs to be extracted as an image. as per the rest of the text its not a much of a problem I can still get every line, heading or prefix. if I can successfully get the tables in an image I can then iterate over all the page's text and do a standard keyword matching between the keywords of the text from whole page and of the table to replace that text with the table image. hope this makes sense. |
Beta Was this translation helpful? Give feedback.
-
|
Sorry for bothering you again there's one thing I don't understand when I remove this condition also all of the items in paths doesn't contain |
Beta Was this translation helpful? Give feedback.
-
|
As I wrote: your PDF creator has decided to not draw lines, but instead thin rectangles. MS Word, LibreOffice always do the same when exporting office documents to PDF. |
Beta Was this translation helpful? Give feedback.
-
|
ahh, i see it now. Thanks now I know what the problem is |
Beta Was this translation helpful? Give feedback.
-
|
I am taking the liberty to change the issue title to something which gives others an idea what it is all about. |
Beta Was this translation helpful? Give feedback.
-
|
Hi, i've found a solution to my problem by using Thank you for such a beautiful package. :) |
Beta Was this translation helpful? Give feedback.
Indeed, if you do this:
You get this:
So except for the header, no text is extracted based on drawing rectangles.