Cannot open broken documents #1991
-
|
Please provide all mandatory information! Describe the bug (mandatory)I have developed a python script using PyMuPDF to extract info from medical pdf and organize the data as I want, with graphs and stuff in mass, in a for loop. So it opens all docs (using fitz.open) in the folder, extracts text from a given page, cleans the text, tokanize it and builds excel sheets and graphs with target data. It works well, however I'm facing something strange when I try to use the script with a new kind document (based on the one that the script was developed), however shorter in number of pages with less info. As I run the code I get the error "cannot open broken document". But the document is based on the previous one that is working correctly (a pdf generated on MS word, based on a docx). What would defined a broken document? How can I certify it is indeed broken? I can provide a sample of documents if it is needed to verify the error. Furthermore, as I get this error and simply to try to reuse the script with the previous documents, the script stops working and I start to get the same error, even with the documents it worked before. I need to restart the computer or unzip the package in a new location. It is like the new documents spoil the script definitely. To Reproduce (mandatory)Traceback (most recent call last): Expected behavior (optional)I would expect it worked as it is intended. Screenshots (optional)
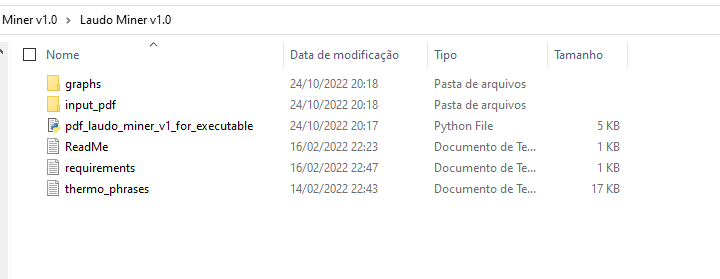
This is the structure of the script. In the input_pdf folder, I put all the documents I want to be mined. graphs is where frequency graphs of tokens are generated. Your configuration (mandatory)
"PyMuPDF 1.20.2: Python bindings for the MuPDF 1.20.3 library. Additional context (optional)Add any other context about the problem here. Thanks for your work in this libray. |
Beta Was this translation helpful? Give feedback.
Replies: 6 comments 8 replies
-
|
Please send me one example PDF that you cannot open. If possible please also send me the docx Word document from which that PDF has been created (presumably via the MS Word export function). To do more investigation yourself: # open your problem file
doc = fitz.open("file.pdf")
# after the exception do this:
print(fitz.TOOLS.mupdf_warnings())
# and inspect the outputThe output of the function shows a collection of error and warning messages issued (mostly) by the underlying MuPDF open routines. |
Beta Was this translation helpful? Give feedback.
-
|
I did some more investigation and I suppose maybe it is indeed related to the word/pdf conversion:
In this example I extracted text from page 2 from a "broken" pdf, however in the print I got text from page 3 as well, may it be because of the presence of page sections or breaks on word document? Because there page breaks in there. Out of curiosity here is the for loop code I'm using that is not working: `path = "./input_pdf" lis = []
Vox l masc.docx Thanks for your attention. |
Beta Was this translation helpful? Give feedback.
-
Obviously, the only remaining explanation now is some problem in your code, or something else in your setup. I recommend again to print those mupdf_warnings() whenever an open raises an exception. This may help to understand, what it is that PyMuPDF actually is trying to open. Who knows what has happened to the file on its way to where your script lives? I reviewed the two files you attached - and no problem whatsoever is popping up. So for the time being, your issue cannot be reproduced so far. |
Beta Was this translation helpful? Give feedback.
-
|
This is what I get in mupdf_warnings() printing: `>>> print(fitz.TOOLS.mupdf_warnings())
|
Beta Was this translation helpful? Give feedback.
-
|
Aha! |
Beta Was this translation helpful? Give feedback.
-
|
Wow! maybe an error during word conversion? it says for me it is a pdf file. Strange!
Thx for the help! |
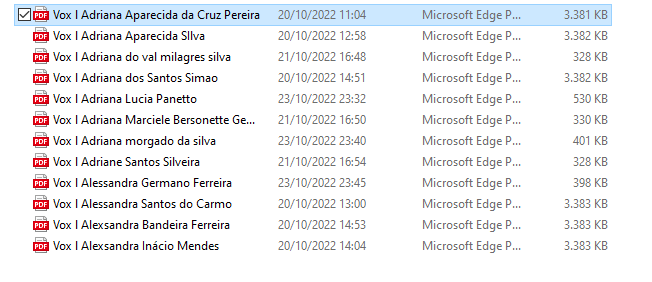
Beta Was this translation helpful? Give feedback.
-
|
At least it is now extremely improbably that we have a (Py-) MuPDF issue. Otherwise, we'll open a new issue. On the next open exception, do this please: import pathlib
import fitz
try:
doc = fitz.open(filename)
except:
print(fitz.TOOLS.mupdf_warnings())
pth = pathlib.Path(filename)
buffer = pth.read_bytes()
print(buffer[:200]) # shows the first few hundred bytes of the file
# save the file to another place for later investigation
out = open("test.pdf", "wb")
out.write(buffer)
out.close()Then please send me the output of the printout, and try to open "test.pdf" offline and see what happens. |
Beta Was this translation helpful? Give feedback.
-
|
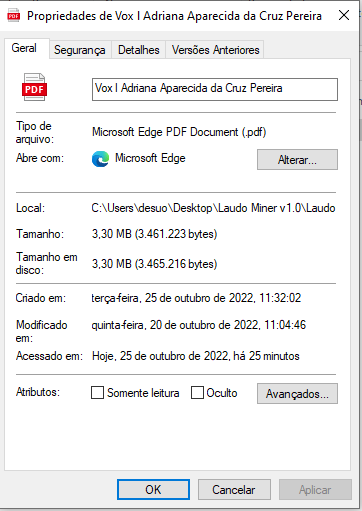
What you are looking at are just Windows explorer views to your files. That's no proof that those are valid PDF files. Windows only look at the file extension (.pdf) and assumes it's a PDF. |
Beta Was this translation helpful? Give feedback.
-
|
This is how a valid PDF version marker looks like version 1.5 in this case): |

Beta Was this translation helpful? Give feedback.
-
|
As I mentioned, when I try to open isolated outside the for loop it works, so the exception wont be called out, I removed it to get the printout either way. here is the printout: b'%PDF-1.3\n%\xe2\xe3\xcf\xd3\r\n2 0 obj\n<<\n/Length 17132\n>>\nstream\r\nq\n1 i \n11.999 666.681 221.76 163.32 re\nW n\n/GS1 gs\nq\n223.56 0 0 163.56 11.1214 666.6813 cm\n/Im1 Do\nQ\nQ\nq\n1 i \n11.999 503.121 221.76 163.56 re\nW n\n1 ' and yes I was able to open it offline as well. Which makes me think there is something in the for loop that causing the issue, which I also don't understand what could be because it works fines with other files and also works after I convert the docx to pdfs on my computer. As I don't have attachment to code and I just want it to work, I'm attaching the app in case you have time and/or interest to check it out. I still think it is more than a script error. I also included a folder with the "broken pdf". In the input folder there are two working pdfs which are basically the same of the broken ones, but generated on my PC. If you move the "broken" pdfs to the input folder the code should stop working. I'm far from being an expert coder, I'm giving the baby steps here, then it is probably not very well optimized, however it works for what I need. Thanks again! |
Beta Was this translation helpful? Give feedback.
-
|
The code looks harmless to me. I also tried the files in broken ... and they did work! |
Beta Was this translation helpful? Give feedback.
-
|
Oh well, lol...Probably something on my configuration then? make no sense to me and this is what I was afraid of. Some strange thing going on here, i will need to try to isolate it further. Thanks for your help! |
Beta Was this translation helpful? Give feedback.
-
|
Just a heads up, it was indeed a flaw in the script, specifically in the for loop. I don't know how or why it seems to be related to desktop.ini file, once the script was trying to get it and open as a pdf, or something like that. However it seems to be solved with a new for loop code:
and further in the code I also changed another line:
So yeah, nothing related to the PyMuPDF. Thanks so much for your help |
Beta Was this translation helpful? Give feedback.
-
|
Aha! Thanks for the information. |
Beta Was this translation helpful? Give feedback.
Obviously, the only remaining explanation now is some problem in your code, or something else in your setup.
I recommend again to print those mupdf_warnings() whenever an open raises an exception. This may help to understand, what it is that PyMuPDF actually is trying to open. Who knows what has happened to the file on its way to where your script lives?
I reviewed the two files you attached - and no problem whatsoever is popping up.
So for the time being, your issue cannot be reproduced so far.