-
|
Please provide all mandatory information! Describe the bug (mandatory)I am working on image extraction from PDF. But pymupdf generates some png images inverted color, some png images inverted by x coordinate, and some images meet expectation. To Reproduce (mandatory)This is test pdf: My test code is: And I also use PyMuPDF-Utilities exmaple https://github.com/pymupdf/PyMuPDF-Utilities/blob/master/examples/extract-images/extract.py to test extract images, which get the same result. The result is:
|





Beta Was this translation helpful? Give feedback.
Replies: 5 comments 9 replies
-
|
As is mentioned in the documentation: But you actually are lucky: your 2100+ images seem to have no transparency and with only 6 exceptions they all are extracted correctly! >>> blocks[0].keys()
dict_keys(['number', 'type', 'bbox', 'width', 'height', 'ext', 'colorspace', 'xres', 'yres', 'bpc', 'transform', 'size', 'image'])
>>> blocks[0]["bpc"]
1
>>> blocks[0]["transform"]
(3.0, 0.0, -0.0, -1.8461999893188477, 294.5830078125, 414.6283874511719)This shows:
pix = fitz.Pixmap(blocks[0]["image"])
pix.invert_irect()
pix.save("inverted.png") |
Beta Was this translation helpful? Give feedback.
-
|
Thanks. But this method don't solve my problems. I also have some problems as follows:
|
Beta Was this translation helpful? Give feedback.
-
|
You may have questions, so I am converting this to a "Discussions" item. |
Beta Was this translation helpful? Give feedback.
-
A 1:1 correspondence between To recover images in the same way as a page shows them, you must investigate the import fitz
from PIL import Image
import io
from matrix_property import matprop
doc=fitz.open("Test.pdf")
page = doc[8]
imgb = [b for b in page.get_text("dict")["blocks"] if b["type==1]]
for i, b in enumerate(imgb):
image0 = Image.open(io.BytesIO(b["image"]))
mat = fitz.Matrix(b["transform"])
if matprop(mat)[0] == 2: # this is an up-down flip!
image1 = image0.transpose(Image.Transpose.FLIP_TOP_BOTTOM)
image1.save(f"img{i}.{b"ext"})This will produce the following images: |
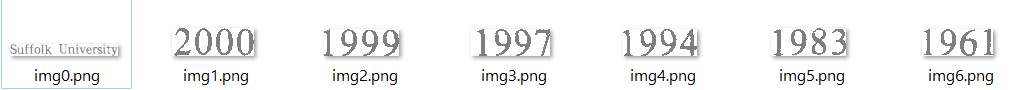
Beta Was this translation helpful? Give feedback.
-
|
Thanks a lot! But I can't find the answer of No.2 problem.
|
Beta Was this translation helpful? Give feedback.
-
No, this is a misconception. All the images in your test file are intransparent, meaning they do not have an alpha channel.
To find out the transform matrix in this situation again, use |
Beta Was this translation helpful? Give feedback.
-
I don't know why these images are black background color when they are extracted by get_text(). But show white background color in pdf file. The smask of all these images is 0. I know I can use pix.invert_irect() to handle these six images. But how can I detect which image should be inverted in other pdf files? Does it mean when bpc is 1, I should inverted that? |
Beta Was this translation helpful? Give feedback.
-
|
bpc=1 is the only case where this is necessary. |
Beta Was this translation helpful? Give feedback.
-
|
Both of this image |
Beta Was this translation helpful? Give feedback.
-
|
Another question about extract image. I extract the first image in page 0 by two ways.
I use for reference your method, but get some errors. In addition, the bpc of this image is 8, not 1, so I don't use pix.invert_irect() api to invert it. |
Beta Was this translation helpful? Give feedback.
-
|
This is a base image with an SMask (= alpha channel) stored. So the You can remove the alpha channel from the base image before you add the SMask pixmap: if pix14.alpha: # check if alpha channel there
pix14 = fitz.Pixmap(pix14, 0) # remove alpha channel
pix = fitz.Pixmap(pix14, pix15) |
Beta Was this translation helpful? Give feedback.
-
|
Almighty! You can solve everything. Thanks a lot! |
Beta Was this translation helpful? Give feedback.
-
|
smask = 0 does not determine whether or not to invert the pixmap - the existence of an smask > 0 only says we need an alpha channel. |
Beta Was this translation helpful? Give feedback.
-
|
Okay! Thanks again!!! |
Beta Was this translation helpful? Give feedback.
A 1:1 correspondence between
page.get_images()and the image blocks inpage.get_text()cannot exist / be guaranteed, see the documentation here.To recover images in the same way as a page shows them, you must investigate the
transformmatrix and use a package like Pillow to back-transform the extracted image accordingly.I have once written a little function
matprop, that does this investigation. Here is a ZIP of it:matrix_property.zip
Lets look at page 8 of your test file and see how to use it:
import