after crop page, then get_images() #2140
-
|
HI I just want to get_images in specify range in a page. So I crop the page, then use function get_images. But it still get all images in this page. page.set_cropbox(fitz.Rect(100, 100, 550, 700)) How to get images in specify range in a page? |
Beta Was this translation helpful? Give feedback.
Replies: 3 comments 14 replies
-
|
This is because that method looks at PDF definitions only and does not inspect the page's appearance source code. To at least restrict the above list to images that are actually referenced by this page anywhere on the MediaBox, do a To restrict that list to visible images (CropBox) do this: imglist = page.get_images()
visibles = [item for item in imglist if page.get_image_rects(item[0])[0] in page.cropbox]
|
Beta Was this translation helpful? Give feedback.
-
|
Thank you so much. But it seems not as I want. I test it in my code
|
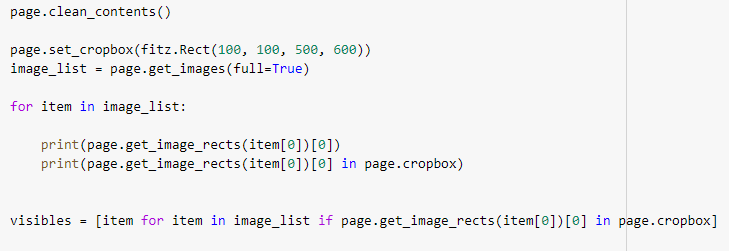

Beta Was this translation helpful? Give feedback.
-
|
Anyway I just want to extract images in a fixed position in pdf. based on rect can't get the correct image I need. |
Beta Was this translation helpful? Give feedback.
-
|
There must be some misconception. Can you let me have the PDF and the page number in question? |
Beta Was this translation helpful? Give feedback.
-
|
Ok,just sent pdf to your email |
Beta Was this translation helpful? Give feedback.
-
|
As I suspected, you have been hiding major information items! |
Beta Was this translation helpful? Give feedback.
-
|
HI Jorj X. McKie, thanks for you help. Finally I found pdfplumber can solve my problem. Cos pdfplumber can export crop page to image directly. So I set a fixed crop bbox in the page, !apt install imagemagick import pdfplumber pdf = pdfplumber.open('/content/015-23C110164.pdf') |
Beta Was this translation helpful? Give feedback.
-
|
Ah, it is only now that I understand what you actually wanted! With the current solution you do not actually extract the underlying image of the PDF: pix = page.get_pixmap(dpi=300, clip=(120,130,700,500))
pix.save("dddd.png") |
Beta Was this translation helpful? Give feedback.
-
|
Sorry for my poor English. I can't clearly express my meaning. Image rect is so dynamics,this way should be the best. |
Beta Was this translation helpful? Give feedback.
-
|
That's ok. BTW I am sure that PyMuPDF is faster here, too. What brought me on the wrong track was that talk about changing the cropbox. But this was not at all what you wanted - you needed a subimage of the full page like a photo. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks. It is faster and simple. I need to read the pymupdf document carefully first. |
Beta Was this translation helpful? Give feedback.
page.get_images()may even list images that are not at all used by the page - not to mention what you are asking.This is because that method looks at PDF definitions only and does not inspect the page's appearance source code.
To at least restrict the above list to images that are actually referenced by this page anywhere on the MediaBox, do a
page.clean_contents()first.To restrict that list to visible images (CropBox) do this:
get_image_rectswalks through the page's appearance instructions to determine each bbox of one image (given by its xrefitem[0]) on the page. In…