Preserve layered text when saving images #2198
-
|
Hello! I'm presently working on a personal project of mine that deals with the extraction of images from a PDF. It was suggested to try out this library along with python. It has been a very impressive library and even with my limited know how of python, it was easy to set up and fulfil the need I had. I would like to augment my process and wanted to check if its a practical ask. When extracting an image from the PDF, I get the images that I need from the page, however any of the text that is layered over it does not transfer over to the image, after saving. For example (You can see that there are some demarcations on the map) This is what happens when I extract the image from the PDF, the text is not carried over. After some tinkering around, I realized that the text must be another layer or maybe something like a background and foreground sort of deal. I had a look with get_text("blocks") and it did show me that the text and the images are separate blocks. During the creation of the pdf perhaps they were layered over each other to present as a singular image? My question pertains to whether or not its practically possible to preserve this text over the image and then save the file as a .jpeg or .png. I will be honest, I don't know a lot about python or this library as I just started looking it recently. After doing some searches on the internet and the discussions here, I have not found anything similar to go against. Any help with advice or by way or an example to get me started will be greatly appreciated. |
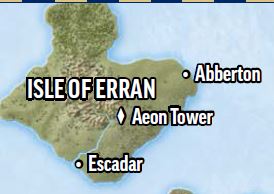
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 1 reply
-
|
Thanks for using PyMuPDF to start with. Of course the result quality will depend on the DPI you choose for the pixmap. bbox = page.get_image_rects(xref)[0] # delivers list, because one image maybe displayed multiple times
pix = page.get_pixmap(dpi=150, clip=bbox)
pix.save("interesting.png") |
Beta Was this translation helpful? Give feedback.
-
|
Edit : Thank you @JorjMcKie This was an excellent solution! |
Beta Was this translation helpful? Give feedback.
Thanks for using PyMuPDF to start with.
The easiest way to achieve your goal surprisingly (maybe) is to not extract the image, but to make a "photo" from the area where the image is visible - and save this as an image.
Step 1: Identify the image
Step 2: Compute the area where displayed by the page
Step 3: Make a Pixmap from that area. This will contain everything visible: the image and possible other stuff.
Step 4: Save the Pixmap as an image file.
Of course the result quality will depend on the DPI you choose for the pixmap.
Here is a snippet. I am assuming you have the xref of the image of interest: