Looking for font supporting Nepali: IMPLEMENTED #398
-
|
I expected the variables a,b,c, e,f,g to be transferred to page. They re not transferred. Your piece of code to set metadata, and set TOC works as expected. Please help me. My os is windows 10, Python 3.6, Pymupdf 1.16 |
Beta Was this translation helpful? Give feedback.
Replies: 41 comments 33 replies
-
|
TTTT.pdf |
Beta Was this translation helpful? Give feedback.
-
|
In Here is an example snippet which puts some text in Hindi in a PDF: |
Beta Was this translation helpful? Give feedback.
-
|
It solved some of the problems, while it faced new challenges. Text is not properly rendered in the generated PDF. In attached image, I want the Expected line as is in PDF, not the second line. Sadly, when I copy the text generated in PDF (your attachment) to some other text editor with capabilities of UTF-8 encoding (windows notepad, and Notepad++), it works as expected. I generated the text back from PDF with added code Thank you. |

Beta Was this translation helpful? Give feedback.
-
|
Please post the script you are working with here. |
Beta Was this translation helpful? Give feedback.
-
|
The fact, that |
Beta Was this translation helpful? Give feedback.
-
|
I tested with multiple fonts that (do not)/have Devnagari block. Despite issues in page rendering, Unicode Text in TOC works fine as expected. Same as metadata. Attached file is nearly 2 MB as it includes all the fonts. |
Beta Was this translation helpful? Give feedback.
-
|
The rendering of metadata and TOC entries works, because of the PDF-internal mechanism. |
Beta Was this translation helpful? Give feedback.
-
|
@JorjMcKie Test Text = नि:शुल्क ज्ञानको लागी JoriMcKie लाई धन्यबाद |
In both cases, it worked fine. Font embedded. (Microsoft PDF - embedded CID+F1 Font, while LibreOffice embedded the actual font - Aparajita, Mangal or so on. I can confirm that - it is not the Font issue. Encoding: I need to test something related to Encoding. |
Beta Was this translation helpful? Give feedback.
-
|
Ah okay, I see. Microsoft also uses I am afraid I am out of advice here now. Especially because not all glyphs are wrong - just some, right? What I am doing in PyMuPDF is converting a unicode character to a 2 or 4 byte hexadecimal string. Which integer to take for this conversion depends on the font characteristics which I get from MuPDF. So I suspect the issue is inside MuPDF ☹. |
Beta Was this translation helpful? Give feedback.
-
|
When comparing the PDF output of LibreOffice, Word and PyMuPDF, I can see, that the office software kind of know when to combine two or more characters in a row into one new joint glyph. If you look at the Doing this kind of thing requires knowledge of the underlying language of course. |
Beta Was this translation helpful? Give feedback.
-
|
A take-away from our discussion is that I should more closely look at PyMuPDF's handling of text insertion. You have put your finger on a weakness there. In the meantime, I have found that the base library MuPDF does support this type of thing - how much is something to find out. Thank you for bringing this up! |
Beta Was this translation helpful? Give feedback.
-
|
@JorjMcKie Is it somehow related to the default encoding set (encoding=0) in the text insertion ? The valid encoding values are TEXT_ENCODING_LATIN (0), TEXT_ENCODING_GREEK (1), and TEXT_ENCODING_CYRILLIC (2, Russian) with Latin being the default. Encoding can be specified by all relevant font and text insertion methods. I wanted to test it by setting it to Devnagari, or remove the default encoding. I do not know how-to for both of the concerns. (PS: I figured - encoding = 4, 5, or even 6 - that are not available, work without producing error, but no change in PDF file). |
Beta Was this translation helpful? Give feedback.
-
These flags only play a role for the 3 Base14 PDF fonts Times-Romas, Courier and Helvetica ... to create variants for other than Latin encodings. |
Beta Was this translation helpful? Give feedback.
-
|
Sorry - didn't mean to close this! |
Beta Was this translation helpful? Give feedback.
-
|
How does (Py-)MuPDF handle Ligatures in font ? I was looking for it in MuPDF documentation, that talks about the extraction-handling only. Core-problem here, as i figured out is the ligatures defined in font are not handled well, so the letters as shown as typed. |
Beta Was this translation helpful? Give feedback.
-
|
Hi , unicode to Krutidev translation is needed for Hindi langauge Thanks, |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the information. I have read over it a few times, and what I finally understood is this (and maybe I am still wrong ...):
This seems to be what the Indic shaping engine on the provided MS web site does.
|
Beta Was this translation helpful? Give feedback.
-
|
I am experimenting with the following: >>> text = "नि:शुल्क ज्ञानको लागी लाई धन्यबाद"
>>> for c in text:
print(c, "=", ord(c))
न = 2344
ि = 2367
: = 58
श = 2358
ु = 2369
ल = 2354
् = 2381
क = 2325
= 32
ज = 2332
् = 2381
ञ = 2334
ा = 2366
न = 2344
क = 2325
ो = 2379
= 32
ल = 2354
ा = 2366
ग = 2327
ी = 2368
= 32
ल = 2354
ा = 2366
ई = 2312
= 32
ध = 2343
न = 2344
् = 2381
य = 2351
ब = 2348
ा = 2366
द = 2342
>>> Then I tried this: def switch_chars(text):
halves = (2367, 2366, 2379, 2368) # unicodes that seem to modfy the preceeding char
newtext = [c for c in text]
for i in range(1, len(text)):
ordi = ord(newtext[i])
if ordi in halves: # revert the sequ with previous char
newtext[i - 1], newtext[i] = newtext[i], newtext[i - 1]
return "".join(newtext)When I then write the string For me this looks like a promising path to go. I think you are in a better position to help complete the rules that must be implemented in some function like |
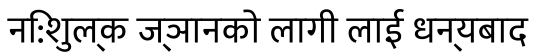
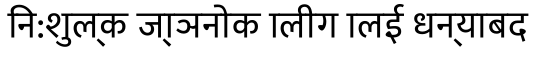

Beta Was this translation helpful? Give feedback.
-
|
I have not tried, but i think it will be a challenging idea, though not impossible. some issues are font level. Take an example : ज्ञ seems to be single character (and is in language). (taken from : ज्ञानको) from Unicode Table, it is formed with combination of 3 characters : ज = 2332 + ् = 2381 + ञ = 2334 Each font is free to define its ligature in its codepage. I think this is font level, meaning it may NOT have a global integer value. You are already one step ahead than i thin i could help you. |
Beta Was this translation helpful? Give feedback.
-
I agree. The Microsoft website you pointed me to explains exactly such an algorithm (on an abstreact level unfortunately). Obviously a complex algorithm, and your recent post confirms this. |
Beta Was this translation helpful? Give feedback.
-
|
@JorjMcKie |
Beta Was this translation helpful? Give feedback.
-
|
Unfortunately, there has been no progress in this area. We arre still at he same point 😒. |
Beta Was this translation helpful? Give feedback.
-
|
Sorry, but I wonder whether the issue here is a missing text shaping engine. If this is the case, Harfbuzz is a well-known open source shaping engine and it also has Python bindings. Just in case it might help. |
Beta Was this translation helpful? Give feedback.
-
|
I guess this would be a pending integration (to say the least). Python bindings for Harfbuzz are available https://github.com/harfbuzz/uharfbuzz. I’m afraid that main limitation for many developers is that they are only experienced with Latin script (or similar ones, such as Greek and Cyrillic scripts). This would be my case (if I were be able to code 😅). Just in case it might help. |
Beta Was this translation helpful? Give feedback.
-
|
Solution provided in the below discussion may help? I had hard time getting around the solution proposed, may be you can understand @JorjMcKie ? |
Beta Was this translation helpful? Give feedback.
-
Sorry, @arjunpaudyal, but the last part of the sentence is ambiguous to me. If you ask whether I understand what @JorjMcKie may be proposing, I’m afraid absolutely not (I wish I could). Sorry again, but I cannot even code (not to mention my basic lack of programming skill). |
Beta Was this translation helpful? Give feedback.
-
|
Sorry I think I was not clear in my statement. I was asking if @JorjMcKie can understand the solution proposed in the Google Groups post(link i posted earlier) to use Harfbuzz with PDF |
Beta Was this translation helpful? Give feedback.
-
|
@subalalithafl - sorry for getting into this discussion so late. Please give me some more time, I am very busy currently 🤷♂️. |
Beta Was this translation helpful? Give feedback.
-
|
I just confirmed, that PyMuPDF's Story feature does support Harfbuzz! This feature uses PyMuPDF in analogy to an internet browser: Here is a small, but complete example: Text copied from the Indian Wikipedia home page put into a simple html, and a script that outputs it. |
Beta Was this translation helpful? Give feedback.
-
|
@JorjMcKie Thanks a lot for this. Yes it is indeed working to create a PDF in Indic languages. I tried Tamil as well. But one issue though, I am not able to select the text properly. |
Beta Was this translation helpful? Give feedback.
-
|
what do you mean "select the text properly"? |
Beta Was this translation helpful? Give feedback.
-
|
If you replace a font with that script, then the story feature is not active - so the Harfbuzz mechanism is not invoked. |
Beta Was this translation helpful? Give feedback.
-
|
I mean text selection in the PDF. Highlighting a text and copying it. |
Beta Was this translation helpful? Give feedback.
-
|
what is going wrong when doing this? |
Beta Was this translation helpful? Give feedback.
-
|
Hindi seem to be good. I tried Tamil. This is what I am getting. Below is the PDF generted with Tamil Text. It looks good. Now if I try to select the text using pointer or just simply do CTRL+A, I get below. Not all text is selected as you can see If I copy the same and put it in a textpad, I do not see the proper Tamil text. It is broken like below |



Beta Was this translation helpful? Give feedback.
-
|
ok - I understand |
Beta Was this translation helpful? Give feedback.
-
|
Because we need the Story feature taking control, the output cannot as easily handled as with traditional ways of text writing. But there are ways to deal with some situations.
import fitz
import io
def story_maker(clip, text): # make a PDF of page size "clip" containing text
clip = fitz.Rect(clip) # ensure we have a Rect
clip += (-clip.x0, -clip.y0, -clip.x0, -clip.y0)
more = True
while more:
fp = io.BytesIO() # use for file output
writer = fitz.DocumentWriter(fp)
story = fitz.Story(html=text)
mediabox = clip
dev = writer.begin_page(mediabox)
more, _ = story.place(mediabox)
if more: # text did not fit in this clip, so enlarge and try again
clip *= 1.05 # enlarge by 5%
continue
story.draw(dev) # good, we stayed inside the clip
writer.end_page() # end the page
writer.close() # close the writer
break # lave the loop
doc = fitz.open("pdf", fp) # make a PDF from memory
return doc
tamil = "" # text in Tamil language, with or without styling
temp_pdf = story_maker(clip, tamil)
page.show_pdf_page(clip, temp_pdf, 0) |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the pointer. I will try this out with my scenario. It will take some time. Will reply back if facing issues. |
Beta Was this translation helpful? Give feedback.
-
|
Note: I have just tested / corrected the above function |
Beta Was this translation helpful? Give feedback.
-
|
Please see this announcement. |
Beta Was this translation helpful? Give feedback.
-
|
That's great @JorjMcKie . |
Beta Was this translation helpful? Give feedback.
-
|
You are free to use it immediately - without it already being released. All you have to do is import the script enabling this from an extra file like this: import fitz
import pathlib
from htmlbox import insert_htmlbox
fitz.Page.insert_htmlbox = insert_htmlbox # mix it into the Page object
text = "some mixture of plain text or html ..."
doc = fitz.open()
page = doc.new_page()
clip = fitz.Rect(200, 200, 500, 400)
css = "body {font-family: sans-serif;}" # example extra styling
rc = page.insert_htmlbox(clip, text,
css=None,
rotate=0, # one of 0, 90, 180, 270
adjust=True, # whether to reduce font size until text fits in clip
morph=None,
overlay=True,
)
print(rc) # float as in insert_textbox
doc.subset_fonts() # recommended
doc.ez_save("output.pdf")This is the code imported above: |
Beta Was this translation helpful? Give feedback.
-
|
Thank you @JorjMcKie this helped me a lot and can I change font color here..? |
Beta Was this translation helpful? Give feedback.
-
|
@JorjMcKie This seems to insert the complex language scripts with complex language glyphs. I am struggling to insert the font (of my choice) and get the same result as it does by default. Unlike the textbox method, the insert_htmlbox does not take font input. Apart from the inserting font, it is solved and solution tested on : |
Beta Was this translation helpful? Give feedback.
-
|
At @arjunpaudyal re this post: |
Beta Was this translation helpful? Give feedback.
-
|
@JorjMcKie I copied your custom function. A bit messier as i tested multiple things at once. Devanagari Unicode character rendering is working fine though. Thank you. full working code is here : |
Beta Was this translation helpful? Give feedback.
-
|
all you need is some knowledge about HTML and styling with CSS |
Beta Was this translation helpful? Give feedback.
-
|
Thank you @JorjMcKie |
Beta Was this translation helpful? Give feedback.
-
|
Hello @JorjMcKie could you please help me.. |
Beta Was this translation helpful? Give feedback.
-
|
@sanchayjain28 - I am not sure what you mean by "solid" background? Redactions can erase text, links, and image portions - not vector graphics. |
Beta Was this translation helpful? Give feedback.
-
|
BTW - if you are not referring to the language problem itself, it would be better to open a different discussion. |
Beta Was this translation helpful? Give feedback.
-
|
Yes,my issue is different and not referring to language problem |
Beta Was this translation helpful? Give feedback.
-
Ok, I see. |
Beta Was this translation helpful? Give feedback.
-
Beta Was this translation helpful? Give feedback.
-
|
It will work - it is documented, I just looked it up exclusively for you! Use |
Beta Was this translation helpful? Give feedback.
-
|
cannot be - works for me: import fitz
doc=fitz.open("v110-changes.pdf")
page=doc[0]
page.draw_rect(page.rect, fill=(0,1,0),overlay=False)
Point(0.0, 0.0)
for r in page.search_for("pixmap"):
page.add_redact_annot(r,fill=False)
'Redact' annotation on page 0 of v110-changes.pdf
'Redact' annotation on page 0 of v110-changes.pdf
'Redact' annotation on page 0 of v110-changes.pdf
'Redact' annotation on page 0 of v110-changes.pdf
'Redact' annotation on page 0 of v110-changes.pdf
'Redact' annotation on page 0 of v110-changes.pdf
'Redact' annotation on page 0 of v110-changes.pdf
'Redact' annotation on page 0 of v110-changes.pdf
'Redact' annotation on page 0 of v110-changes.pdf
'Redact' annotation on page 0 of v110-changes.pdf
'Redact' annotation on page 0 of v110-changes.pdf
'Redact' annotation on page 0 of v110-changes.pdf
'Redact' annotation on page 0 of v110-changes.pdf
'Redact' annotation on page 0 of v110-changes.pdf
'Redact' annotation on page 0 of v110-changes.pdf
page.apply_redactions()
True
doc.ez_save("z.pdf")Result: |


Beta Was this translation helpful? Give feedback.
-
|
can you share an example page? |
Beta Was this translation helpful? Give feedback.
-
|
Try this: The key thing is that you have an image background. The redaction application default is punching holes in images that overlap a redaction. |
Beta Was this translation helpful? Give feedback.
-
|
Thank You @JorjMcKie |
Beta Was this translation helpful? Give feedback.
You are free to use it immediately - without it already being released. All you have to do is import the script enabling this from an extra file like this: