Node fails to start due to incompatible feature flags #6755
Replies: 8 comments 27 replies
-
|
Please ATTACH your complete Kubernetes configuration and In addition, RabbitMQ and Kubernetes logs will be helpful. At the moment you're asking us to guess how to reproduce this issue. |
Beta Was this translation helpful? Give feedback.
-
|
This does not happen in most environments so we need to know exactly how the nodes are started. It's also curious that this affects one specific feature flag. I can think of two workarounds:
As of #6682 this feature flag will become required (auto-enabled) but that would only ship in |
Beta Was this translation helpful? Give feedback.
-
|
We have also been consistently hitting this issue. I can confirm that it is not a parallel node startup. We are using bitnami rabbitmq chart that is based on Kubernetes StateFullSet that ensures that a cluster nodes are started one after another. Will the following workaround help until we migrate to the fixed version. |
Beta Was this translation helpful? Give feedback.
-
|
@s-srakshe can you please provide step-by-step description to reproduce this issue? Here is what I did: #!/usr/bin/env bash
set -euo pipefail
for i in {1..10}; do
echo "Running #$i"
helm install \
--set replicaCount=3 \
--set image.tag=3.11.7-debian-11-r5 my-release bitnami/rabbitmq
sleep 20
kubectl wait --for=jsonpath='{.status.readyReplicas}'=3 statefulset my-release-rabbitmq --timeout=10m
kubectl exec my-release-rabbitmq-1 -c rabbitmq -- rabbitmqctl list_feature_flags --formatter=pretty_table
helm delete my-release --wait
sleep 10
doneIn all 10 runs, the RabbitMQ nodes booted without issues and all feature flags got successfully enabled. |
Beta Was this translation helpful? Give feedback.
-
|
Report for Bitnami Chart 11.5.1 with Rabbitmq 3.11.7 Bitnami Chart 10.3.9 with Rabbitmq version 3.10.8 Report for Bitnami Chart 11.5.1 with Rabbitmq 3.11.7Note: Bitnami rabbitmq container brings up rabbitmq in two stages, This is same in Bitnami chart 10.3.9 and 11.5.1 When the node 0 is started for the first time On subsequent boots I am not sure if abrupt stopping of rabbitmq server in Stage 1 (step 5) during the first time boot is messing up the node 0. After node 0 is up and running, What we are observing is that node 1 and node 2 during their first bootup are failing to start rabbitmq in Stage 1 - step 2, We see two kinds of failures. (a) failed enabling direct_exchange_routing_v2 or (b) error:{case_clause,{{error,{merge_schema_failed,"Bad cookie in table definition rabbit_node_maintenance_states node 1 and node 2 crash and restart , if force boot is not enabled then they repeatedly crash and re-start. If force boot enabled then they bootup but are not clustered with node 0. Links for Bitnami container files, entrypoints invokes setup.sh (stage 1) and run.sh (stage 2)
|
Beta Was this translation helpful? Give feedback.
-
|
#6701 can also be relevant here. |
Beta Was this translation helpful? Give feedback.
-
|
@ares-the-god-of-war, as @lukebakken wrote, please provide exact reproduction steps including any configuration files and how the RabbitMQ nodes get clustered. You don't use https://github.com/rabbitmq/cluster-operator, do you? |
Beta Was this translation helpful? Give feedback.
-
|
Dear all, I have done several tests. Attached you can find some minimalistic definitions.json which reproduces the error for me. Once I encountered not only the direct_exchange_routing_v2 feature_flag being disabled, but also the drop_unroutable_metric and empty_basic_get_metric. So the issue seems to not only affect the direct_exchange_routing_v2 feature flag, but it is the feature flag it at least occurs with in ALL reproduction attempts I use configuration in rabbitmq.conf for peer discovery: cluster_formation.k8s.address_type = hostname cluster_formation.node_cleanup.interval = 30 @ansd, we do not use the cluster-operator. |
Beta Was this translation helpful? Give feedback.
-
|
I'm also interested in the RabbitMQ logs from all nodes with the debug log level enabled. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you @ares-the-god-of-war. Is there any chance you could test your clustering setup against the docker image pivotalrabbitmq/rabbitmq:direct-exchange-routing-v2-migration-otp-max-bazel? It contains the potential fix in #6847. That would be super helpful. Thanks again @ares-the-god-of-war! |
Beta Was this translation helpful? Give feedback.
-
|
@ansd I am willing to test this version for you. However, policy compels me to use official repositories only. What kind of repository is the pivotalrabbitmq? Is this an official Rabbitmq repository? Please let me know so I can make my case to test this. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @ares-the-god-of-war. Yes, the pivotalrabbitmq org is owned by the RabbitMQ team at VMware (formerly Pivotal). The repo https://hub.docker.com/r/pivotalrabbitmq/rabbitmq contains the official dev images built by GitHub actions via this workflow. |
Beta Was this translation helpful? Give feedback.
-
|
Actually, if you are allowed, try instead with this image: Same repo but different tag: This image points to the latest 3.11.x branch. |
Beta Was this translation helpful? Give feedback.
-
|
Dear @ansd, I received permission to test the provided image and have been able to perform the same upgrade with the new image. 3.11.x branch Unfortunately, the issue remains. There is a slight change in behaviour. The feature flag direct_exchange_routing_v2 is no longer disabled when node 2 (rabbitmq-1) starts up. (see image). Like previously, the nodes are started 1 after the other and waiting the previous node to complete its startup before starting the new node. We start with an empty database disk. Attached you find the complete logs of RabbitMQ node 2 (rabbitmq-1) which still crashes. |
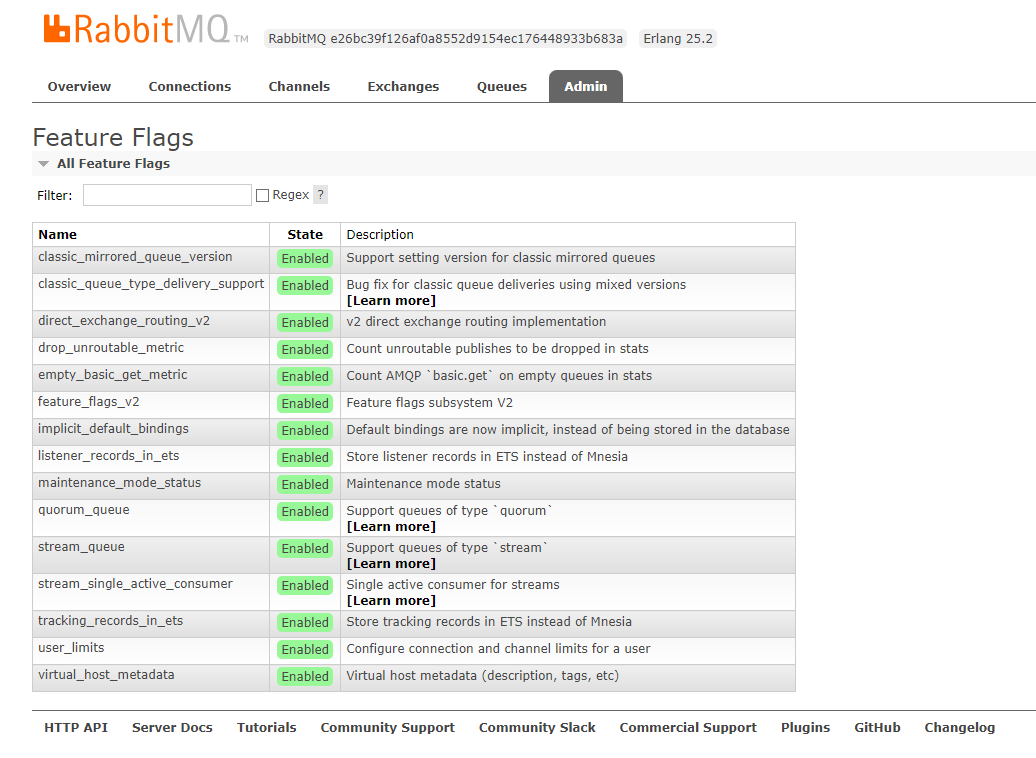
Beta Was this translation helpful? Give feedback.
-
If I understand correctly, the If you try to restart node 2 again, does it succeed? |
Beta Was this translation helpful? Give feedback.
-
|
That is correct. Previously, when testing with 3.11.5, I enabled the direct_exchange_routing_v2 flag when it was disabled. Then node 2 would start properly. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you so much for testing @ares-the-god-of-war! |
Beta Was this translation helpful? Give feedback.
-
|
@ansd Except for the logging the behaviour of node 2 is the same as with pivotalrabbitmq/rabbitmq:e26bc39f126af0a8552d9154ec176448933b683a-otp-max-bazel |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @ares-the-god-of-war. At this point, as asked in #6755 (comment) would it be possible that you could share all relevant Kubernetes YAML files with us so that we can reproduce this issue on our own? |
Beta Was this translation helpful? Give feedback.
-
|
We're running rabbitmq-3.11.7 (includes a potential fix #6847) here in Azure Kubernetes Services, and are still running into this issue most of the time.
|
Beta Was this translation helpful? Give feedback.
-
|
@ansd We don't use cluster-operator, we deploy via a stateful set manually. The first pod boots fine, the second fails and the third one naturally doesn't appear at all. Details are below, logs attached (note that I already fixed the event writing returning 403s). I tested 3.11.3 to 3.11.6 and the issue did not appear. Only on 3.11.7 it does not boot up properly (in my experience).
enabled_plugins: rabbitmq.conf: definitions.json: statefulset: rabbitmq-statefulset-0-log.txt |

Beta Was this translation helpful? Give feedback.
-
|
Thank you @kevinharing. Unfortunately, this is just a snippet of YAML files. It contains only the StatefulSet.
I'd like to run a Could you please share a complete (and if possible minimal) example to reproduce this issue? |
Beta Was this translation helpful? Give feedback.
-
|
The logs suggest that there are clustering issues: I suggest using https://github.com/rabbitmq/cluster-operator because it solves clustering and common gotchas in K8s. |
Beta Was this translation helpful? Give feedback.
-
|
You should compare the timestamps of the two files. Statefulset-1 already restarted a few times before I exported the log of it. |
Beta Was this translation helpful? Give feedback.
-
|
Can confirm version 3.11.8 fixed this issue. |
Beta Was this translation helpful? Give feedback.
-
|
@ansd im sorry for the unresponsiveness. I had a little vacation. In my mail i saw there might be another fix for this issue. I will try to find time tomorrow to test again, the following image as linked in I will confirm whether or not this is fixed for us as well. |
Beta Was this translation helpful? Give feedback.
-
|
@michaelklishin @ansd I could not test 3.11.8 as that image does not seem to exist yet. I have run the image provided in #7068 and the RabbitMQ nodes have started properly without any restarts (and therefore without crashing). Once the image 3.11.8 is available, I will also test that one. For now this pivotalrabbitmq image seems to fix the issue for us as well. |
Beta Was this translation helpful? Give feedback.
-
|
@michaelklishin is there any ETA on the availability of the Docker image for 3.11.8? |
Beta Was this translation helpful? Give feedback.
-
|
@ares-the-god-of-war Team RabbitMQ does not manage the docker image. As you can see here the update to 3.11.8 just happened. I don't know how long it takes that update to propagate to the official docker images 🤷♂️ |
Beta Was this translation helpful? Give feedback.
-
|
https://github.com/docker-library/faq#an-images-source-changed-in-git-now-what |
Beta Was this translation helpful? Give feedback.
-
|
It usually takes some 48 hours in practice for new images to end up on Docker Hub, you can see that 3.10.16 still isn't there some 24 hours later. |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
Good day,
I am running RabbitMQ in an Kubernetes environment with 3 nodes. I want to start from scratch with predefined configuration with RabbitMQ version 3.11.5, (docker image rabbitmq:3.11.5). I have got the predefined configuration in a configuration map containing definitions.json. The following steps will lead to node 2 and 3 crash.
Beta Was this translation helpful? Give feedback.
All reactions