Growing memory footprint of a node while using streams #7362
-
|
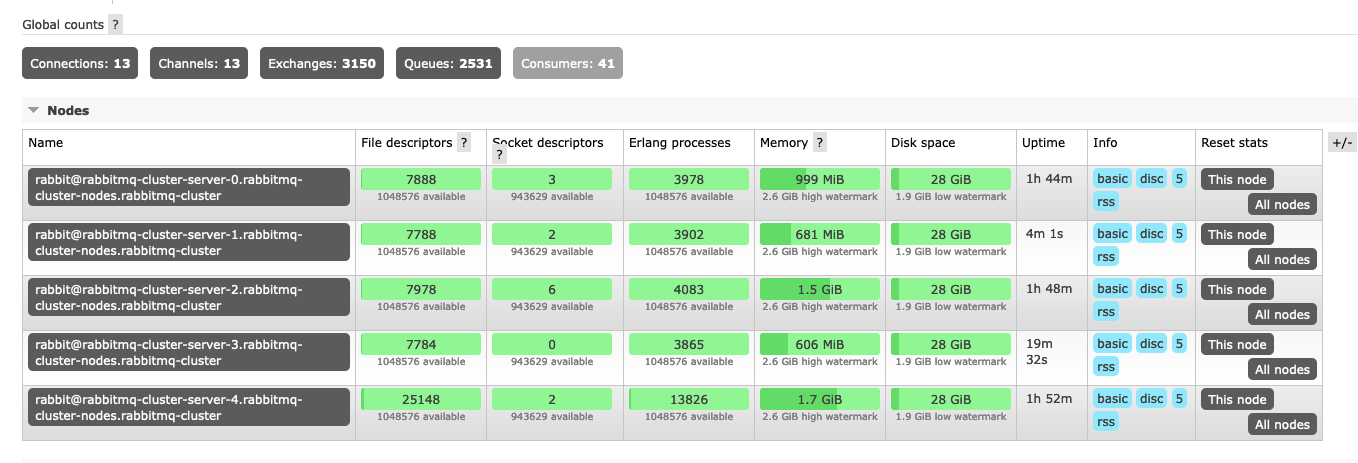
Hi, we rolled out RabbitMq with Webstomp+Stream-Queues for our vhosts (around 50 customers). Right now it seems that there is a memory leak somewhere, since our cluster grows in size after 120 minutes so I have to restart the nodes - but I can't really understand it. We have only 13 connections, but are running out of RAM after 1-2 hours?
Also there are not that many messages send (biggest queue has 150 messages in total). The memory inspection shows that this is related to binaries (message metadata etc) - but how can this be if this are stream queues?
Would be great if anyone could give me a hint... :( RabbitMQ 3.11.8 |


Beta Was this translation helpful? Give feedback.
Replies: 27 comments 150 replies
-
|
I really don't understand it, the memory consumption moves up linear, even though there is nearly nothing happening on the cluster.. |
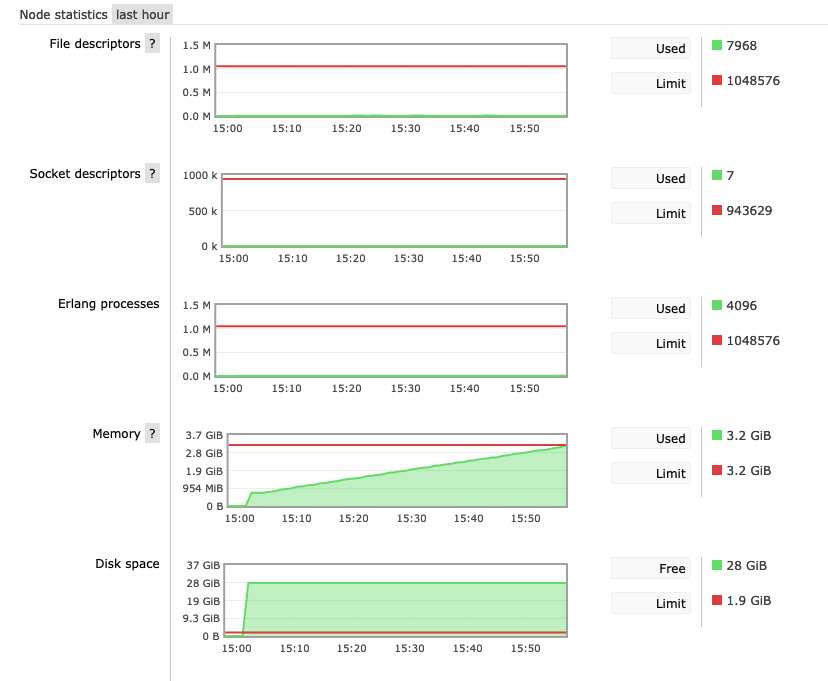
Beta Was this translation helpful? Give feedback.
-
|
Also the connection churn stats are not bad.. |
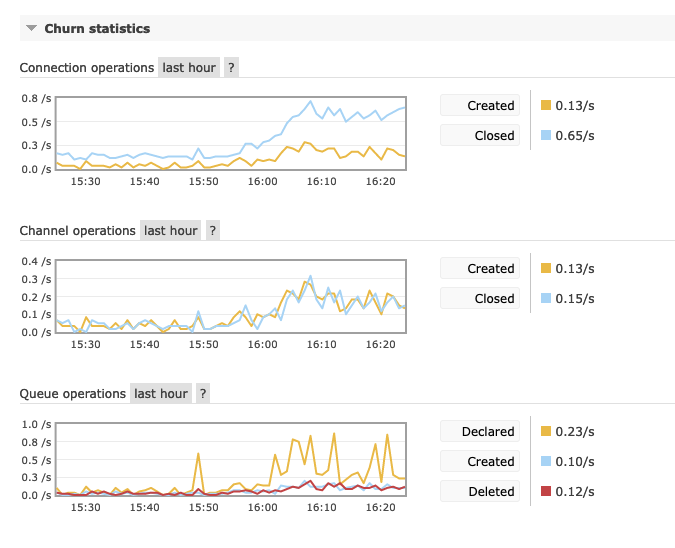
Beta Was this translation helpful? Give feedback.
-
|
Which version of RabbitMQ are you using?
…On Mon, 20 Feb 2023 at 15:26, h0jeZvgoxFepBQ2C ***@***.***> wrote:
[image: Bildschirmfoto 2023-02-20 um 16 25 15]
<https://user-images.githubusercontent.com/10075/220145997-18d09d76-ce06-41b0-80b1-3f63d715cda9.png>
Also the connection churn stats are not bad..
—
Reply to this email directly, view it on GitHub
<#7362 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAJAHFC4YCB5C5KYWPPTBRDWYOEKBANCNFSM6AAAAAAVBZRNTI>
.
You are receiving this because you are subscribed to this thread.Message
ID: <rabbitmq/rabbitmq-server/repo-discussions/7362/comments/5054676@
github.com>
--
*Karl Nilsson*
|
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
It's also strange that it seems that there are no persistance operations - even though streams are durable and lazy inherently as far as I read?
|
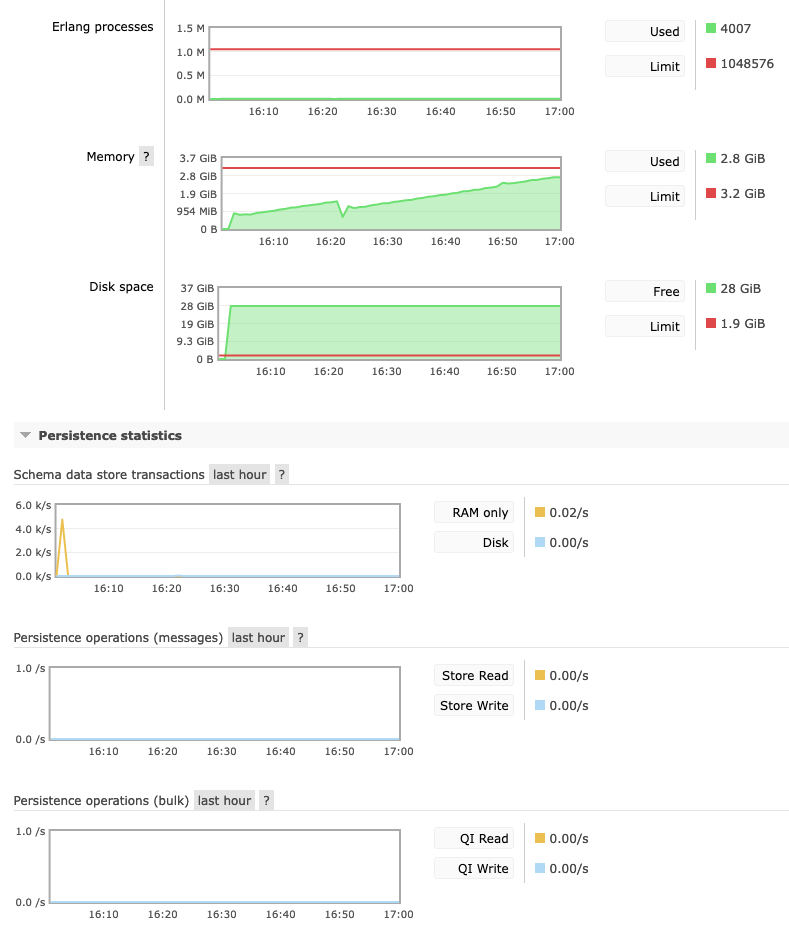

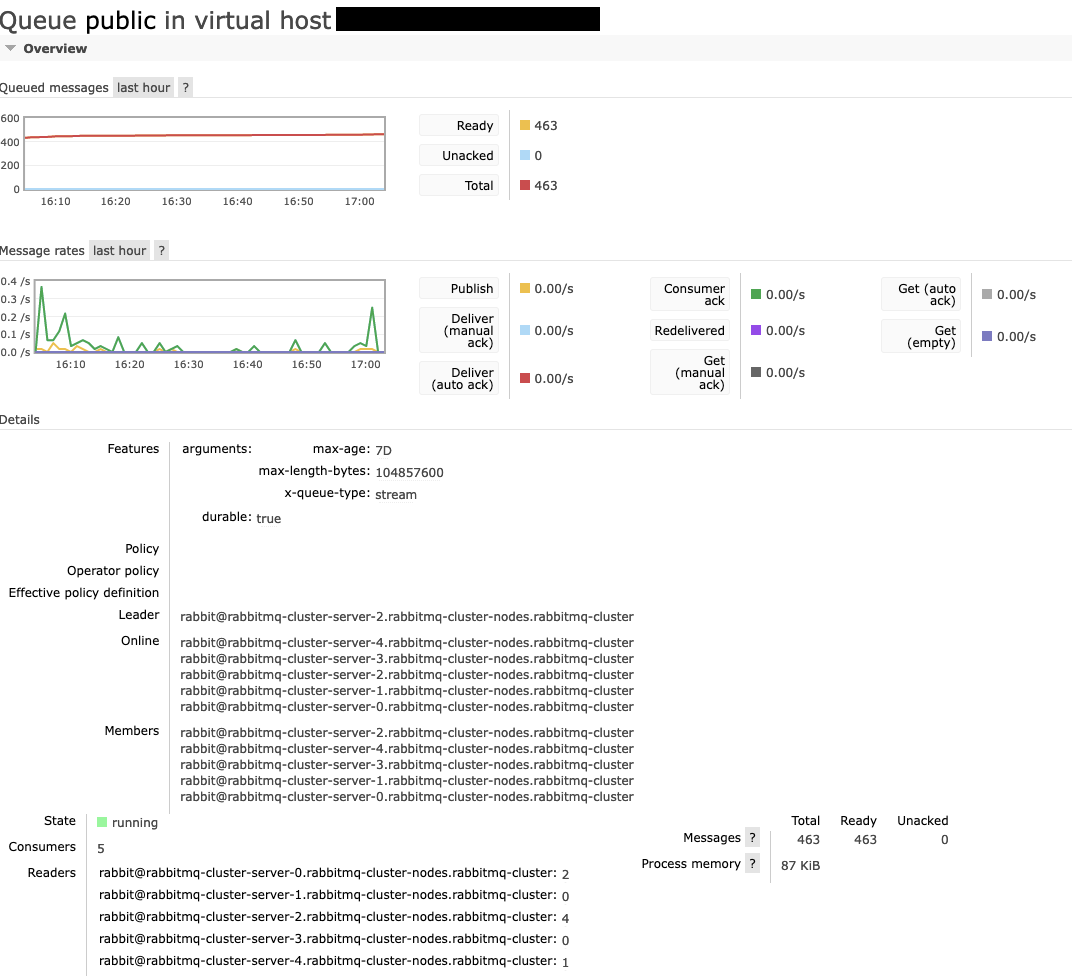
Beta Was this translation helpful? Give feedback.
-
|
Streams don't record persistence operations in the RabbitMQ node metrics.
Use OS level counters to see what IO is actually being performed.
Question: do your clients create a new connection per message, or very
often?
…On Mon, 20 Feb 2023 at 16:02, h0jeZvgoxFepBQ2C ***@***.***> wrote:
It's also strange that it seems that there are no persistance operations -
even though streams are durable and lazy inherently as far as I read?
[image: Bildschirmfoto 2023-02-20 um 17 01 57]
<https://user-images.githubusercontent.com/10075/220153667-5482d1b1-3814-4a39-852b-58b17d5f6869.png>
[image: Bildschirmfoto 2023-02-20 um 17 02 38]
<https://user-images.githubusercontent.com/10075/220153807-e2e61250-cc9c-416c-a011-8f8e121f938e.png>
—
Reply to this email directly, view it on GitHub
<#7362 (reply in thread)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAJAHFBFWFOJK6HTT6D7VOLWYOIS7ANCNFSM6AAAAAAVBZRNTI>
.
You are receiving this because you commented.Message ID:
***@***.***
com>
--
*Karl Nilsson*
|
Beta Was this translation helpful? Give feedback.
-
|
We are using rabbitmq in our case nearly only as readonly-websocket connection (so only one publisher and many read only consumers -> sending website updates). |
Beta Was this translation helpful? Give feedback.
-
|
Ok I have a suspicion as to what it can be. It may be that with your
pattern of use we may end up creating a lot of writer de-duplication ids
which would show up as binary data. These IDs are only trimmed when a
stream segment fills up which if the throughput is low would not be very
often.
I will take a look to see if this is the case but a quick look at the code
suggests it is.
What you can do for now is to adjust your publisher to retain a long
lived channel and connection rather than creating a new one for each
message. Also you could configure a smaller max segment size for these
streams.
…On Mon, 20 Feb 2023 at 16:22, h0jeZvgoxFepBQ2C ***@***.***> wrote:
We are using rabbitmq in our case nearly as readonly-websocket connection
(so only one publisher and many read only consumers).
The publisher is connecting, then publishing and then closing the channel
and connection again correctly. In general we don't have many messages
(like 10 published messages per hour), so it shouldn't be related to this
connections?
—
Reply to this email directly, view it on GitHub
<#7362 (reply in thread)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAJAHFFGUVLBQC7KY6DAPETWYOK55ANCNFSM6AAAAAAVBZRNTI>
.
You are receiving this because you commented.Message ID:
***@***.***
com>
--
*Karl Nilsson*
|
Beta Was this translation helpful? Give feedback.
-
|
Oh ok, sounds great that you have maybe an idea about this. Any recommendations for the segment size? as I mentioned, we don't have that many updates, so I guess the publish-traffic is something like max. 10mb per hour? You mean also this configuration key or: |
Beta Was this translation helpful? Give feedback.
-
|
Yes you can update it with a policy but it may not take effect until next
time the stream is restarted.
the best option is to retain a long lived channel/connection
…On Mon, 20 Feb 2023 at 16:39, h0jeZvgoxFepBQ2C ***@***.***> wrote:
Oh ok, sounds great that you have maybe an idea about this. Any
recommendations for the segment size? as I mentioned, we don't have that
many updates, so I guess the publish-traffic is something like max. 10mb
per hour?
You mean also this configuration key or: x-stream-max-segment-size-bytes?
—
Reply to this email directly, view it on GitHub
<#7362 (reply in thread)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAJAHFDE6AHAOY23ZOF7MRTWYOM4FANCNFSM6AAAAAAVBZRNTI>
.
You are receiving this because you commented.Message ID:
***@***.***
com>
--
*Karl Nilsson*
|
Beta Was this translation helpful? Give feedback.
-
|
The strange thing is also that it looks like this is happening only on 2 of the 5 nodes (server 0 and 2), whereas connections are to all others too?
|
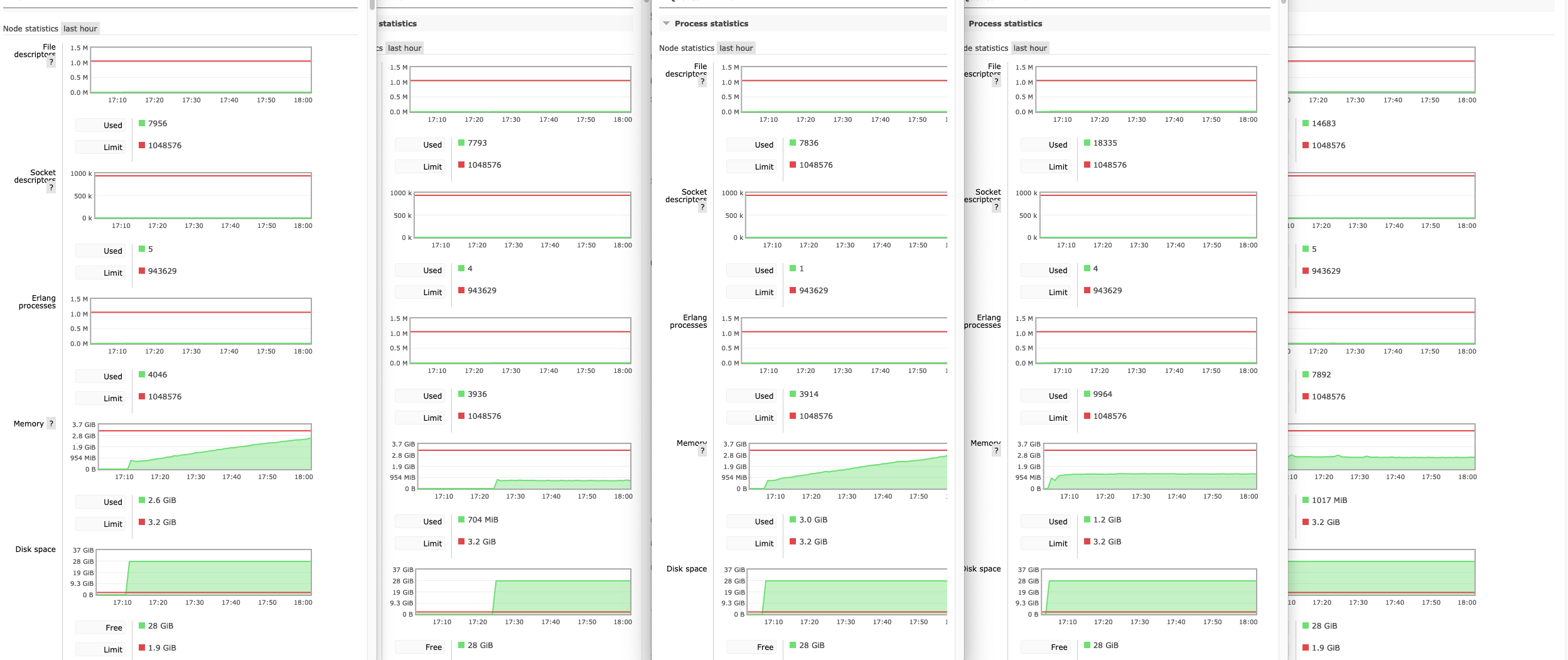
Beta Was this translation helpful? Give feedback.
-
|
It's the stream leader node that hangs on to these ids not the connection
nodes.
…On Mon, 20 Feb 2023 at 17:04, h0jeZvgoxFepBQ2C ***@***.***> wrote:
[image: Bildschirmfoto 2023-02-20 um 18 03 06]
<https://user-images.githubusercontent.com/10075/220165923-42dc1105-bcd2-4256-b6f2-ba0e38d24d45.png>
The strange thing is also that it looks like this is happening only on 2
of the 5 nodes (server 0 and 2), whereas connections are to all others too?
[image: Bildschirmfoto 2023-02-20 um 18 03 56]
<https://user-images.githubusercontent.com/10075/220166050-6c8fe701-099f-412e-9a0d-a78773562f70.png>
—
Reply to this email directly, view it on GitHub
<#7362 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAJAHFCQI6FNRDLYZWZ226TWYOP3TANCNFSM6AAAAAAVBZRNTI>
.
You are receiving this because you commented.Message ID:
***@***.***
com>
--
*Karl Nilsson*
|
Beta Was this translation helpful? Give feedback.
-
|
That said I just did a test and my scenario does result in increased memory
use but not for binaries so there is something else going on here.
Can you tell me more about your consumers? How they connect, if they are
long running etc. Also what kind of message sizes are used?
…On Mon, 20 Feb 2023 at 17:29, Karl Nilsson ***@***.***> wrote:
It's the stream leader node that hangs on to these ids not the connection
nodes.
On Mon, 20 Feb 2023 at 17:04, h0jeZvgoxFepBQ2C ***@***.***>
wrote:
> [image: Bildschirmfoto 2023-02-20 um 18 03 06]
> <https://user-images.githubusercontent.com/10075/220165923-42dc1105-bcd2-4256-b6f2-ba0e38d24d45.png>
>
> The strange thing is also that it looks like this is happening only on 2
> of the 5 nodes (server 0 and 2), whereas connections are to all others too?
>
> [image: Bildschirmfoto 2023-02-20 um 18 03 56]
> <https://user-images.githubusercontent.com/10075/220166050-6c8fe701-099f-412e-9a0d-a78773562f70.png>
>
> —
> Reply to this email directly, view it on GitHub
> <#7362 (comment)>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AAJAHFCQI6FNRDLYZWZ226TWYOP3TANCNFSM6AAAAAAVBZRNTI>
> .
> You are receiving this because you commented.Message ID:
> ***@***.***
> com>
>
--
*Karl Nilsson*
--
*Karl Nilsson*
|
Beta Was this translation helpful? Give feedback.
-
|
Oh, mabe I should have mentioned it, our webstomp configuration launches the stomp plugin with frames set to binary mode:
Maybe this is the reason why something appears as binary? In general we have a ruby on rails web platform, which has a sidekiq background worker running which is sending out push notifications via the bunny gem over rabbitmq. We are sending out msgpack encoded packets (still json in the end). Right now only 10 websocket connections, so not that much. msg size not more than 100kb. |
Beta Was this translation helpful? Give feedback.
-
|
Ah and on client side we are using the stompjs package with following channel configuration: |
Beta Was this translation helpful? Give feedback.
-
|
I recreated our cluster and set the segment size to 4MB, but it didn't change anything unfortunately - there were only 10 messages deployed and it's already growing and growing..
|
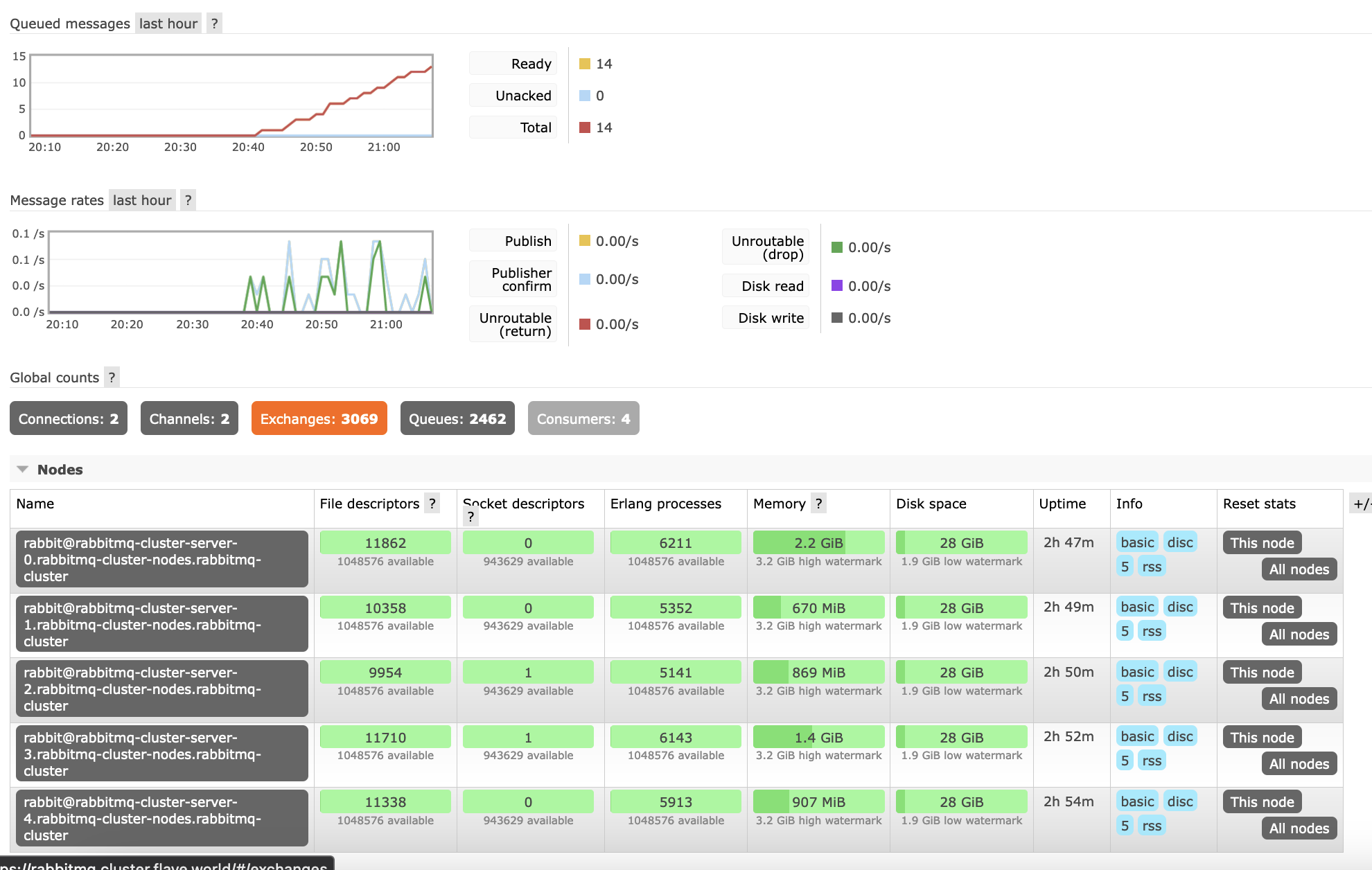
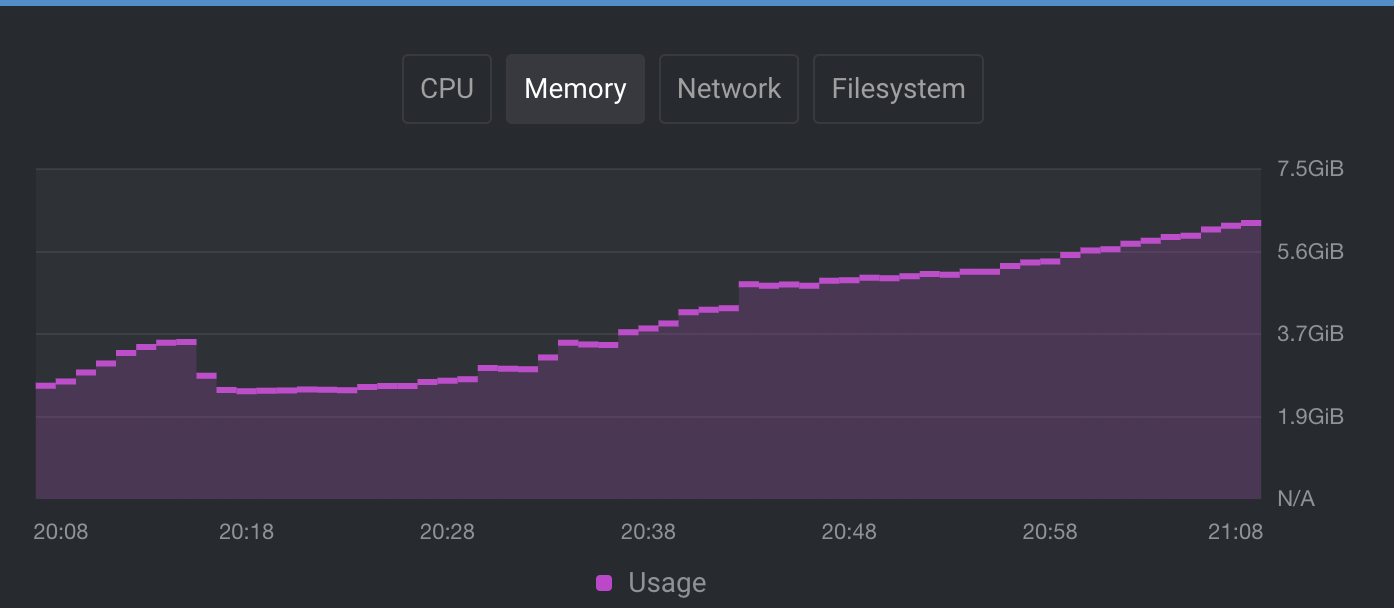
Beta Was this translation helpful? Give feedback.
-
|
Another strange thing is that I only have 2 connections, not more. So I'm not sure if it's really related to our publisher connecting. Since we connect and reconnect, only 10 connections happend in the last hour.. I dont think that 10 single sequential connections lead to such a memory leak? |
Beta Was this translation helpful? Give feedback.
-
|
Is there any chance you could procure a small as possible application that
reproduces the problem so we can test it here?
On Mon, 20 Feb 2023 at 20:14, h0jeZvgoxFepBQ2C ***@***.***> wrote:
Another strange thing is that I only have 2 connections, not more. So I'm
not sure if it's really related to our publisher connecting. Since we
connect and reconnect, only 10 connections happend in the last hour.. I
dont think that 10 single sequential connections lead to such a memory leak?
—
Reply to this email directly, view it on GitHub
<#7362 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAJAHFDFO2ZVM2CGB6DLVWDWYPGBPANCNFSM6AAAAAAVBZRNTI>
.
You are receiving this because you commented.Message ID:
***@***.***
com>
--
*Karl Nilsson*
|
Beta Was this translation helpful? Give feedback.
-
|
Not really, our application is quite big and embedded with a lot of custom stuff.. Also right now I try to make the connections work with
I even tried to pass the params manually too (in integer, in decimal, in string), still doesn't work - really don't understand why it's not working, since I provide the same values (it even gets provided by the same code place during creation and for handing params over to stompjs for the connection). |

Beta Was this translation helpful? Give feedback.
-
|
I even disabled now all customers and rebooted all nodes. But after waking up now it looks again like this: :( |

Beta Was this translation helpful? Give feedback.
-
|
If your version of RabbitMq ships with the Also outputs of You can also try |
Beta Was this translation helpful? Give feedback.
-
|
I tried it already with forcing the garbage collection, but it didn't change anything. node 0Memory breakdown: Node 1Node 2Node 3Node 4The diagnostics report is a bit hard to publish, since it contains a lot of customer names which I'm required to keep private.. But in general, when I enable the debug output, I can see many messages like this: Unfortunately my version doesn't ship with I'm thinking about two reasons which could maybe trigger this:
|
Beta Was this translation helpful? Give feedback.
-
|
Did you try rabbitmqctl force_gc?
…On Tue, 21 Feb 2023 at 10:22, h0jeZvgoxFepBQ2C ***@***.***> wrote:
I tried it already with forcing the garbage collection, but it didn't
change anything.
I also removed the ws binary frames setting and recreated everything, but
it didnt change anything, so it's not related to this option I guess.
node 0
Memory breakdown:
rabbitmq-cluster-server-0:/$ rabbitmq-diagnostics memory_breakdown
Reporting memory breakdown on node ***@***.***
binary: 7.9682 gb (91.69%)
other_proc: 0.2033 gb (2.34%)
allocated_unused: 0.1656 gb (1.91%)
other_ets: 0.0909 gb (1.05%)
stream_queue_replica_reader_procs: 0.0779 gb (0.9%)
code: 0.0381 gb (0.44%)
stream_queue_procs: 0.0366 gb (0.42%)
plugins: 0.0357 gb (0.41%)
other_system: 0.0317 gb (0.36%)
mgmt_db: 0.0189 gb (0.22%)
mnesia: 0.0179 gb (0.21%)
msg_index: 0.0025 gb (0.03%)
atom: 0.0015 gb (0.02%)
metrics: 0.0014 gb (0.02%)
connection_other: 0.0002 gb (0.0%)
connection_readers: 0.0 gb (0.0%)
quorum_ets: 0.0 gb (0.0%)
connection_channels: 0.0 gb (0.0%)
quorum_queue_procs: 0.0 gb (0.0%)
quorum_queue_dlx_procs: 0.0 gb (0.0%)
connection_writers: 0.0 gb (0.0%)
queue_procs: 0.0 gb (0.0%)
queue_slave_procs: 0.0 gb (0.0%)
stream_queue_coordinator_procs: 0.0 gb (0.0%)
reserved_unallocated: 0.0 gb (0.0%)
Node 1
rabbitmq-cluster-server-1:/$ rabbitmq-diagnostics memory_breakdown
Reporting memory breakdown on node ***@***.***
binary: 7.4785 gb (90.95%)
other_proc: 0.1916 gb (2.33%)
allocated_unused: 0.1551 gb (1.89%)
other_ets: 0.1211 gb (1.47%)
stream_queue_replica_reader_procs: 0.1036 gb (1.26%)
code: 0.0381 gb (0.46%)
stream_queue_procs: 0.0367 gb (0.45%)
other_system: 0.0338 gb (0.41%)
plugins: 0.0295 gb (0.36%)
mnesia: 0.0179 gb (0.22%)
mgmt_db: 0.0107 gb (0.13%)
msg_index: 0.0025 gb (0.03%)
metrics: 0.0015 gb (0.02%)
atom: 0.0015 gb (0.02%)
connection_other: 0.0008 gb (0.01%)
quorum_ets: 0.0 gb (0.0%)
queue_procs: 0.0 gb (0.0%)
quorum_queue_procs: 0.0 gb (0.0%)
quorum_queue_dlx_procs: 0.0 gb (0.0%)
connection_readers: 0.0 gb (0.0%)
connection_writers: 0.0 gb (0.0%)
connection_channels: 0.0 gb (0.0%)
queue_slave_procs: 0.0 gb (0.0%)
stream_queue_coordinator_procs: 0.0 gb (0.0%)
reserved_unallocated: 0.0 gb (0.0%)
Node 2
rabbitmq-cluster-server-2:/$ rabbitmq-diagnostics memory_breakdown
Reporting memory breakdown on node ***@***.***
binary: 8.4574 gb (91.55%)
other_proc: 0.1975 gb (2.14%)
allocated_unused: 0.1769 gb (1.91%)
other_ets: 0.1337 gb (1.45%)
stream_queue_replica_reader_procs: 0.0589 gb (0.64%)
plugins: 0.0552 gb (0.6%)
code: 0.0381 gb (0.41%)
stream_queue_procs: 0.0345 gb (0.37%)
other_system: 0.0319 gb (0.35%)
mgmt_db: 0.0301 gb (0.33%)
mnesia: 0.0179 gb (0.19%)
msg_index: 0.0025 gb (0.03%)
atom: 0.0015 gb (0.02%)
metrics: 0.0012 gb (0.01%)
connection_other: 0.0003 gb (0.0%)
connection_readers: 0.0 gb (0.0%)
quorum_ets: 0.0 gb (0.0%)
connection_channels: 0.0 gb (0.0%)
connection_writers: 0.0 gb (0.0%)
quorum_queue_procs: 0.0 gb (0.0%)
quorum_queue_dlx_procs: 0.0 gb (0.0%)
queue_procs: 0.0 gb (0.0%)
queue_slave_procs: 0.0 gb (0.0%)
stream_queue_coordinator_procs: 0.0 gb (0.0%)
reserved_unallocated: 0.0 gb (0.0%)
Node 3
rabbitmq-cluster-server-3:/$ rabbitmq-diagnostics memory_breakdown
Reporting memory breakdown on node ***@***.***
binary: 7.7231 gb (90.03%)
other_proc: 0.203 gb (2.37%)
allocated_unused: 0.1799 gb (2.1%)
other_ets: 0.172 gb (2.01%)
stream_queue_replica_reader_procs: 0.0958 gb (1.12%)
plugins: 0.0458 gb (0.53%)
code: 0.0381 gb (0.44%)
stream_queue_procs: 0.0374 gb (0.44%)
other_system: 0.0329 gb (0.38%)
mgmt_db: 0.026 gb (0.3%)
mnesia: 0.0179 gb (0.21%)
msg_index: 0.0025 gb (0.03%)
atom: 0.0015 gb (0.02%)
metrics: 0.0014 gb (0.02%)
connection_other: 0.0007 gb (0.01%)
connection_readers: 0.0 gb (0.0%)
quorum_ets: 0.0 gb (0.0%)
connection_channels: 0.0 gb (0.0%)
quorum_queue_procs: 0.0 gb (0.0%)
quorum_queue_dlx_procs: 0.0 gb (0.0%)
connection_writers: 0.0 gb (0.0%)
queue_procs: 0.0 gb (0.0%)
queue_slave_procs: 0.0 gb (0.0%)
stream_queue_coordinator_procs: 0.0 gb (0.0%)
reserved_unallocated: 0.0 gb (0.0%)
Node 4
rabbitmq-cluster-server-4:/$ rabbitmq-diagnostics memory_breakdown
Reporting memory breakdown on node ***@***.***
binary: 8.0914 gb (91.7%)
allocated_unused: 0.2626 gb (2.98%)
other_proc: 0.1243 gb (1.41%)
other_ets: 0.0844 gb (0.96%)
stream_queue_replica_reader_procs: 0.0834 gb (0.95%)
code: 0.0381 gb (0.43%)
stream_queue_procs: 0.0348 gb (0.39%)
plugins: 0.0335 gb (0.38%)
other_system: 0.0329 gb (0.37%)
mnesia: 0.0179 gb (0.2%)
mgmt_db: 0.014 gb (0.16%)
msg_index: 0.0025 gb (0.03%)
atom: 0.0015 gb (0.02%)
metrics: 0.0014 gb (0.02%)
connection_other: 0.0005 gb (0.01%)
connection_readers: 0.0001 gb (0.0%)
quorum_ets: 0.0 gb (0.0%)
queue_procs: 0.0 gb (0.0%)
connection_channels: 0.0 gb (0.0%)
connection_writers: 0.0 gb (0.0%)
quorum_queue_procs: 0.0 gb (0.0%)
quorum_queue_dlx_procs: 0.0 gb (0.0%)
queue_slave_procs: 0.0 gb (0.0%)
stream_queue_coordinator_procs: 0.0 gb (0.0%)
reserved_unallocated: 0.0 gb (0.0%)
The diagnostics report is a bit hard to publish, since it contains a lot
of customer names which I'm required to keep private..
But in general, when I enable the debug output, I can see many messages
like this:
2023-02-21 10:14:22.141661+00:00 <0.1551.1005> osiris: initialising reader. Spec: next
2023-02-21 10:14:25.938101+00:00 <0.11389.988> accepting AMQP connection <0.11389.988> (10.244.47.54:58210 -> 10.244.47.72:5672)
2023-02-21 10:14:25.938311+00:00 <0.11389.988> closing AMQP connection <0.11389.988> (10.244.47.54:58210 -> 10.244.47.72:5672):
2023-02-21 10:14:25.938311+00:00 <0.11389.988> connection_closed_with_no_data_received
2023-02-21 10:14:25.938678+00:00 <0.11391.988> Closing all channels from connection '10.244.47.54:58210 -> 10.244.47.72:5672' because it has been closed
2023-02-21 10:14:26.524878+00:00 <0.12018.988> Authentication using an OAuth 2/JWT token failed: provided token is invalid
2023-02-21 10:14:26.525008+00:00 <0.12018.988> User 'myadmin' failed authenticatation by backend rabbit_auth_backend_oauth2
2023-02-21 10:14:26.525082+00:00 <0.12018.988> User 'myadmin' authenticated successfully by backend rabbit_auth_backend_internal
2023-02-21 10:14:28.529266+00:00 <0.11477.1000> accepting AMQP connection <0.11477.1000> (10.244.48.46:35448 -> 10.244.48.103:5672)
2023-02-21 10:14:28.529421+00:00 <0.11477.1000> closing AMQP connection <0.11477.1000> (10.244.48.46:35448 -> 10.244.48.103:5672):
2023-02-21 10:14:28.529421+00:00 <0.11477.1000> connection_closed_with_no_data_received
2023-02-21 10:14:28.530113+00:00 <0.11481.1000> Closing all channels from connection '10.244.48.46:35448 -> 10.244.48.103:5672' because it has been closed
2023-02-21 10:14:29.214553+00:00 <0.27168.1014> accepting AMQP connection <0.27168.1014> (10.244.49.174:52152 -> 10.244.49.143:5672)
2023-02-21 10:14:29.214708+00:00 <0.27168.1014> closing AMQP connection <0.27168.1014> (10.244.49.174:52152 -> 10.244.49.143:5672):
2023-02-21 10:14:29.214708+00:00 <0.27168.1014> connection_closed_with_no_data_received
2023-02-21 10:14:29.215284+00:00 <0.27173.1014> Closing all channels from connection '10.244.49.174:52152 -> 10.244.49.143:5672' because it has been closed
2023-02-21 10:14:30.101644+00:00 <0.12697.1005> accepting AMQP connection <0.12697.1005> (10.244.45.187:34544 -> 10.244.45.188:5672)
2023-02-21 10:14:30.101801+00:00 <0.12697.1005> closing AMQP connection <0.12697.1005> (10.244.45.187:34544 -> 10.244.45.188:5672):
2023-02-21 10:14:30.101801+00:00 <0.12697.1005> connection_closed_with_no_data_received
2023-02-21 10:14:30.102272+00:00 <0.12700.1005> Closing all channels from connection '10.244.45.187:34544 -> 10.244.45.188:5672' because it has been closed
2023-02-21 10:14:31.094929+00:00 <0.32559.991> accepting AMQP connection <0.32559.991> (10.244.47.233:52442 -> 10.244.47.235:5672)
2023-02-21 10:14:31.095125+00:00 <0.32559.991> closing AMQP connection <0.32559.991> (10.244.47.233:52442 -> 10.244.47.235:5672):
2023-02-21 10:14:31.095125+00:00 <0.32559.991> connection_closed_with_no_data_received
2023-02-21 10:14:31.095624+00:00 <0.32564.991> Closing all channels from connection '10.244.47.233:52442 -> 10.244.47.235:5672' because it has been closed
2023-02-21 10:14:31.533355+00:00 <0.15800.1000> Authentication using an OAuth 2/JWT token failed: provided token is invalid
2023-02-21 10:14:31.533450+00:00 <0.15800.1000> User 'myadmin' failed authenticatation by backend rabbit_auth_backend_oauth2
2023-02-21 10:14:31.533666+00:00 <0.15800.1000> User 'myadmin' authenticated successfully by backend rabbit_auth_backend_internal
2023-02-21 10:14:35.938988+00:00 <0.21267.988> accepting AMQP connection <0.21267.988> (10.244.47.54:44842 -> 10.244.47.72:5672)
2023-02-21 10:14:35.939200+00:00 <0.21267.988> closing AMQP connection <0.21267.988> (10.244.47.54:44842 -> 10.244.47.72:5672):
2023-02-21 10:14:35.939200+00:00 <0.21267.988> connection_closed_with_no_data_received
2023-02-21 10:14:35.939628+00:00 <0.21271.988> Closing all channels from connection '10.244.47.54:44842 -> 10.244.47.72:5672' because it has been closed
2023-02-21 10:14:36.533006+00:00 <0.2245.1015> Authentication using an OAuth 2/JWT token failed: provided token is invalid
2023-02-21 10:14:36.533112+00:00 <0.2245.1015> User 'myadmin' failed authenticatation by backend rabbit_auth_backend_oauth2
2023-02-21 10:14:36.533206+00:00 <0.2245.1015> User 'myadmin' authenticated successfully by backend rabbit_auth_backend_internal
2023-02-21 10:14:38.528889+00:00 <0.23580.1000> accepting AMQP connection <0.23580.1000> (10.244.48.46:48284 -> 10.244.48.103:5672)
2023-02-21 10:14:38.529088+00:00 <0.23580.1000> closing AMQP connection <0.23580.1000> (10.244.48.46:48284 -> 10.244.48.103:5672):
2023-02-21 10:14:38.529088+00:00 <0.23580.1000> connection_closed_with_no_data_received
2023-02-21 10:14:38.529765+00:00 <0.23587.1000> Closing all channels from connection '10.244.48.46:48284 -> 10.244.48.103:5672' because it has been closed
2023-02-21 10:14:39.214338+00:00 <0.5888.1015> accepting AMQP connection <0.5888.1015> (10.244.49.174:37432 -> 10.244.49.143:5672)
2023-02-21 10:14:39.214485+00:00 <0.5888.1015> closing AMQP connection <0.5888.1015> (10.244.49.174:37432 -> 10.244.49.143:5672):
2023-02-21 10:14:39.214485+00:00 <0.5888.1015> connection_closed_with_no_data_received
2023-02-21 10:14:39.214781+00:00 <0.5890.1015> Closing all channels from connection '10.244.49.174:37432 -> 10.244.49.143:5672' because it has been closed
2023-02-21 10:14:40.100060+00:00 <0.23157.1005> accepting AMQP connection <0.23157.1005> (10.244.45.187:50550 -> 10.244.45.188:5672)
2023-02-21 10:14:40.100267+00:00 <0.23157.1005> closing AMQP connection <0.23157.1005> (10.244.45.187:50550 -> 10.244.45.188:5672):
2023-02-21 10:14:40.100267+00:00 <0.23157.1005> connection_closed_with_no_data_received
2023-02-21 10:14:40.100593+00:00 <0.23159.1005> Closing all channels from connection '10.244.45.187:50550 -> 10.244.45.188:5672' because it has been closed
2023-02-21 10:14:41.094479+00:00 <0.11513.992> accepting AMQP connection <0.11513.992> (10.244.47.233:52058 -> 10.244.47.235:5672)
2023-02-21 10:14:41.094620+00:00 <0.11513.992> closing AMQP connection <0.11513.992> (10.244.47.233:52058 -> 10.244.47.235:5672):
2023-02-21 10:14:41.094620+00:00 <0.11513.992> connection_closed_with_no_data_received
2023-02-21 10:14:41.094876+00:00 <0.11132.992> Closing all channels from connection '10.244.47.233:52058 -> 10.244.47.235:5672' because it has been closed
2023-02-21 10:14:41.541248+00:00 <0.23580.1005> Authentication using an OAuth 2/JWT token failed: provided token is invalid
2023-02-21 10:14:41.541367+00:00 <0.23580.1005> User 'myadmin' failed authenticatation by backend rabbit_auth_backend_oauth2
2023-02-21 10:14:41.541464+00:00 <0.23580.1005> User 'myadmin' authenticated successfully by backend rabbit_auth_backend_internal
2023-02-21 10:14:45.938707+00:00 <0.62.989> accepting AMQP connection <0.62.989> (10.244.47.54:35626 -> 10.244.47.72:5672)
2023-02-21 10:14:45.938886+00:00 <0.62.989> closing AMQP connection <0.62.989> (10.244.47.54:35626 -> 10.244.47.72:5672):
2023-02-21 10:14:45.938886+00:00 <0.62.989> connection_closed_with_no_data_received
2023-02-21 10:14:45.939219+00:00 <0.64.989> Closing all channels from connection '10.244.47.54:35626 -> 10.244.47.72:5672' because it has been closed
2023-02-21 10:14:46.094383+00:00 <0.31416.1000> Closing all channels from connection '10.244.48.211:38040 -> 10.244.48.103:15674' because it has been closed
2023-02-21 10:14:46.542348+00:00 <0.18947.992> Authentication using an OAuth 2/JWT token failed: provided token is invalid
2023-02-21 10:14:46.542466+00:00 <0.18947.992> User 'myadmin' failed authenticatation by backend rabbit_auth_backend_oauth2
2023-02-21 10:14:46.542595+00:00 <0.18947.992> User 'myadmin' authenticated successfully by backend rabbit_auth_backend_internal
2023-02-21 10:14:48.529033+00:00 <0.32376.1000> accepting AMQP connection <0.32376.1000> (10.244.48.46:54630 -> 10.244.48.103:5672)
2023-02-21 10:14:48.529211+00:00 <0.32376.1000> closing AMQP connection <0.32376.1000> (10.244.48.46:54630 -> 10.244.48.103:5672):
2023-02-21 10:14:48.529211+00:00 <0.32376.1000> connection_closed_with_no_data_received
2023-02-21 10:14:48.529697+00:00 <0.32379.1000> Closing all channels from connection '10.244.48.46:54630 -> 10.244.48.103:5672' because
Unfortunately my version doesn't ship with rabbitmq-streams restart_streamas
it seem?
rabbitmq-cluster-server-4:/$ rabbitmq-streams restart_stream
Command 'restart_stream' not found.
Usage
rabbitmq-streams [--node <node>] [--timeout <timeout>] [--longnames] [--quiet] <command> [<command options>]
Available commands:
Replication:
add_replica Adds a stream queue replica on the given node.
delete_replica Removes a stream queue replica on the given node.
Monitoring, observability and health checks:
stream_status Displays the status of a stream
Policies:
set_stream_retention_policy Sets the retention policy of a stream queue
Use 'rabbitmq-streams help <command>' to learn more about a specific command
I'm thinking about two reasons which could maybe trigger this:
- a Kubernetes problem where network connections are terminated before
they are closed correctly
- a Kubernetes problem with the readiness check (but since there is no
livenesscheck i guess this is not the case)
- webstomp websocket connections which are not closed correctly (since
they try to reconnect permanently if connection cannot be established)
- or its something different...
—
Reply to this email directly, view it on GitHub
<#7362 (reply in thread)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAJAHFAGBAZL6G6OCHBNTF3WYSJORANCNFSM6AAAAAAVBZRNTI>
.
You are receiving this because you commented.Message ID:
***@***.***
com>
--
*Karl Nilsson*
|
Beta Was this translation helpful? Give feedback.
-
|
Ok thank you: Yeah, so right now all nodes are full:
|

Beta Was this translation helpful? Give feedback.
-
|
I just want to mention out that I really appreciate your help and efforts to help some anonymous guy from the internet, thank you ❤️ |
Beta Was this translation helpful? Give feedback.
-
|
No worries we're keen to find these issues when they arise, problem is now we're running out of ideas without a means of reproducing it. So publishers are using AMQP with messages up to 100kb in size but at a low rate. Each message creates a new connection / channel after which it is closed. 10 webstomp consumers using binary mode that consume directly from a stream ( There are many queues and exchanges in your system. Are these also streams or are they other types? |
Beta Was this translation helpful? Give feedback.
-
|
Yes, right now your description is correct (there will be more websocket connections when we roll it out finally, but at the moment we are just testing it). We moved back now to json encoded messages and disabled the binary flag again (but yeah, nothing changed). The websocket connections bind to Queue: Exchange: In general we have around 30 queues+ 30 exchanges per customer so with 90 customers around 2700 channels + 2700 exchanges (all customer data is seperated, no sharing of data between them) - all seperated via vhosts. Each queue is a stream queue and created with the same arguments - right now: (We were not able to use the option Only one exchange is different for each customer, which is a topic exchange and sends out user-updates like: /amq/users, routing_key: user_id) - but this channel is not used right now and disabled since we wanted to get the streaming queues working first (so we removed the connection code from our websites to the user-topic-queue). So right now we have only one active test-customer, all other exchanges/queues are created, but not used. I will try to cut the connection now complately from the cluster/outside world and see if this issue still persists. |
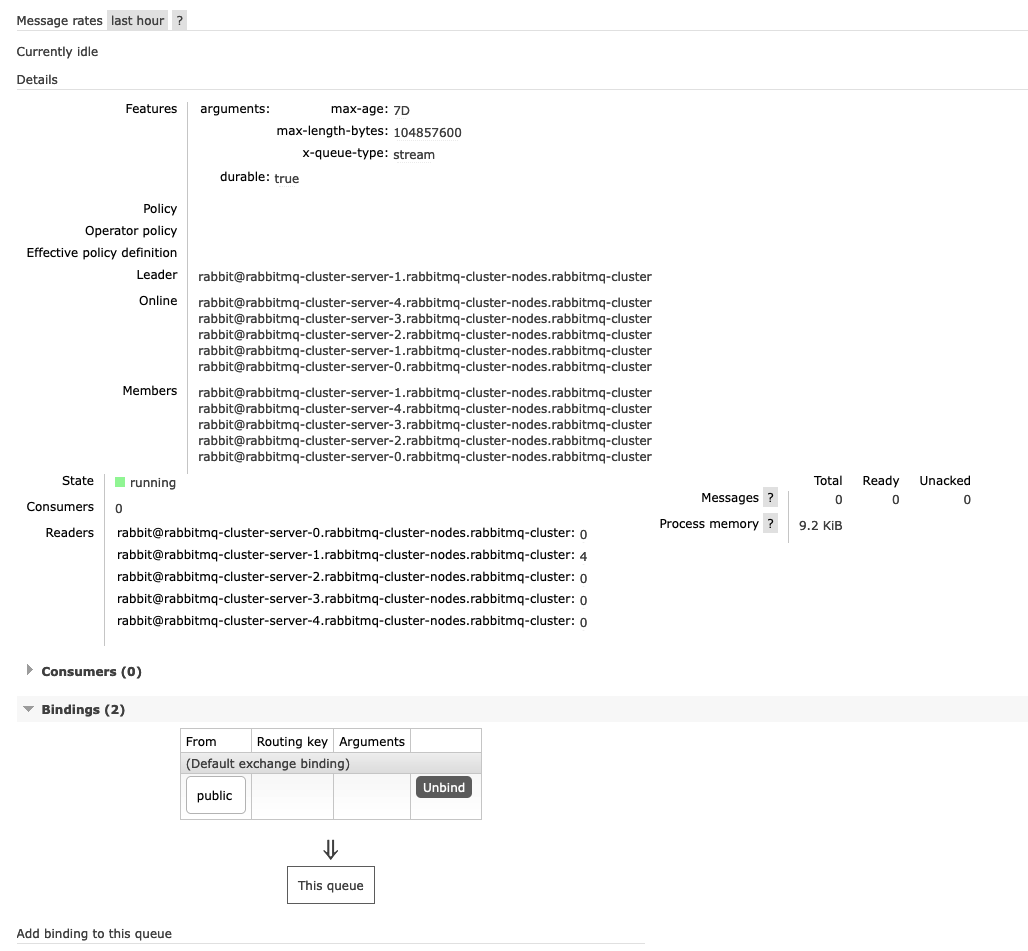
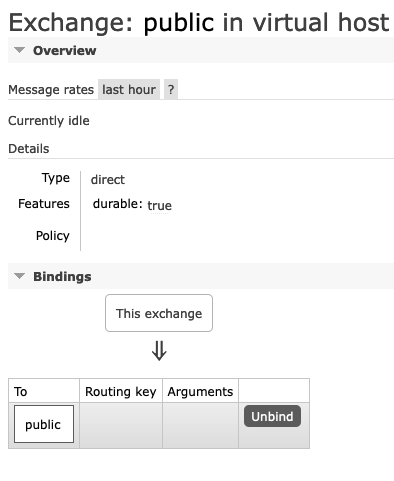
Beta Was this translation helpful? Give feedback.
-
|
This is btw our cluster.yam # kubectl -f cluster/rabbitmq-cluster/cluster.yaml apply
apiVersion: rabbitmq.com/v1beta1
kind: RabbitmqCluster
metadata:
name: rabbitmq-cluster
namespace: rabbitmq-cluster
annotations:
rabbitmq.com/topology-allowed-namespaces: "*"
spec:
replicas: 5
persistence:
storage: "30Gi"
rabbitmq:
additionalPlugins:
- rabbitmq_web_stomp
- rabbitmq_auth_backend_oauth2
additionalConfig: |
log.console = true
log.console.level = warning
auth_backends.1 = oauth2
auth_backends.2 = internal
cluster_partition_handling = pause_minority
auth_oauth2.resource_server_type = rabbitmq
auth_oauth2.resource_server_id = rabbitmq-cluster
# web_stomp.ws_frame = binary
advancedConfig: |
[
{rabbit, [
{auth_backends, [rabbit_auth_backend_oauth2, rabbit_auth_backend_internal]}
]},
{rabbitmq_management, [
{enable_uaa, false},
{oauth_enabled, false}
]},
{rabbitmq_auth_backend_oauth2, [
{resource_server_id, <<"rabbitmq-cluster">>},
{resource_server_type, <<"rabbitmq">>},
{key_config, [
{default_key, <<"key1">>},
{signing_keys, #{
<<"key1">> => {pem, <<"-----BEGIN PUBLIC KEY-----
...key...
-----END PUBLIC KEY-----">>}
}}
]}
]}
].
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app.kubernetes.io/name: rabbitmq-cluster
topologyKey: kubernetes.io/hostname
resources:
requests:
cpu: "1"
memory: 10Gi
limits:
# cpu: 800m
memory: 10Gi
|
Beta Was this translation helpful? Give feedback.
-
|
Another command that may provide some info:
you only need to run this one one node |
Beta Was this translation helpful? Give feedback.
-
|
I even disabled now the incoming-service for the rabbitmq cluster (so I removed the apmq port, prometheus, webstomp and stomp port) - only the management port is open and it's still growing. It really seems that this is not related to connections somehow. Will try now to disable the webstomp and stomp plugin next.. |
Beta Was this translation helpful? Give feedback.
-
|
I disabled now all plugins which I used, stomp / webstomp and the oauth plugin, but it didn't change much.. On some nodes the consumption stopped to grow, but started then on other nodes? I guess this is because i disabled the plugins manually with In general its still growing: at 17:30 i disabled webstom I will try the prometheus plugin next... |

Beta Was this translation helpful? Give feedback.
-
|
Node 0 Node 1 Node 2 Node 3 Node 4 Still no real change... total stateful set chart: |

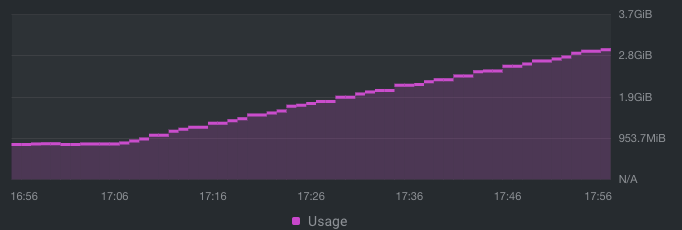

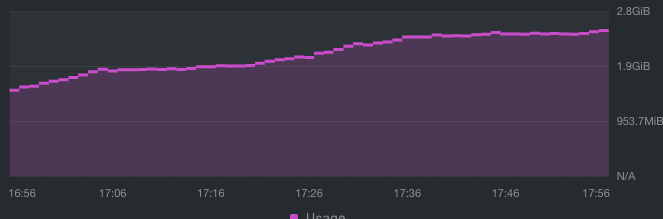
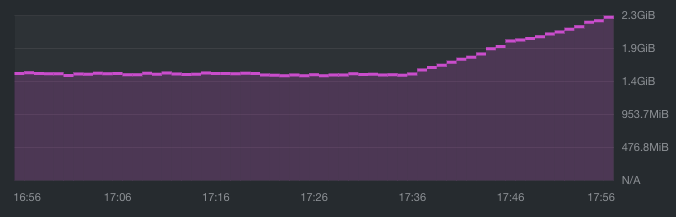

Beta Was this translation helpful? Give feedback.
-
|
The thing is, that I really dont know anymore what I should disable now.. Also the memory grows even over the limit: |
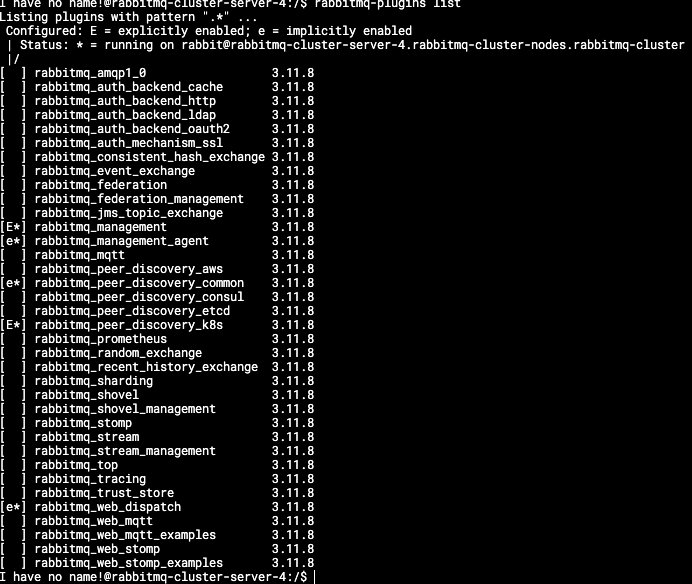
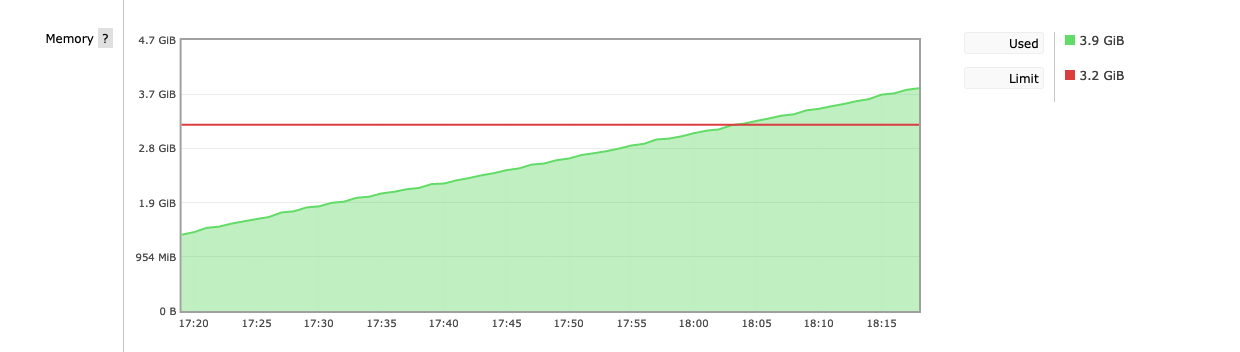
Beta Was this translation helpful? Give feedback.
-
|
Could you tell me how I can get this restart_stream command which you mentioned before? Do i need a special version of rabbitmq for this? |
Beta Was this translation helpful? Give feedback.
-
|
@h0jeZvgoxFepBQ2C - on nodes that are experiencing continuous memory growth, could you please run this and attach the generated Thanks. |
Beta Was this translation helpful? Give feedback.
-
|
I just was able to get the dashboard running and saw that here are "messages ready to deliver to users". Is this normal for stream queues? Or is there something wrong maybe with my configuration? |

Beta Was this translation helpful? Give feedback.
-
|
Streams are immutable so all messages in the stream will show up as ready messages. This is expected. |
Beta Was this translation helpful? Give feedback.
-
|
I see.. arrr.. |
Beta Was this translation helpful? Give feedback.
-
|
Btw just a related question: stomp-js/stompjs#528 Do you know if the stomp/webstomp plugin is filtering the |
Beta Was this translation helpful? Give feedback.
-
|
@kjnilsson Could you tell me how I can get this restart_stream command which you mentioned before? Do i need a special version of rabbitmq for this? Also would be great if you could answer following question:
Btw jfyi, we have updated to 3.11.10 and 3.12.0-beta1 and it didn't change anything. Right now we gave up on RabbitMQ, since we don't have any idea anymore what to do else. |
Beta Was this translation helpful? Give feedback.
-
|
I've deployed a cluster with idle streams and cannot reproduce. Initially there were 3 nodes and 100 streams. Later I went up to 2500 streams. Later on, I scaled the cluster to 7 nodes. Memory usage remains stable (all nodes are scraped by Prometheus).
There is not much we can do without steps to reproduce. |
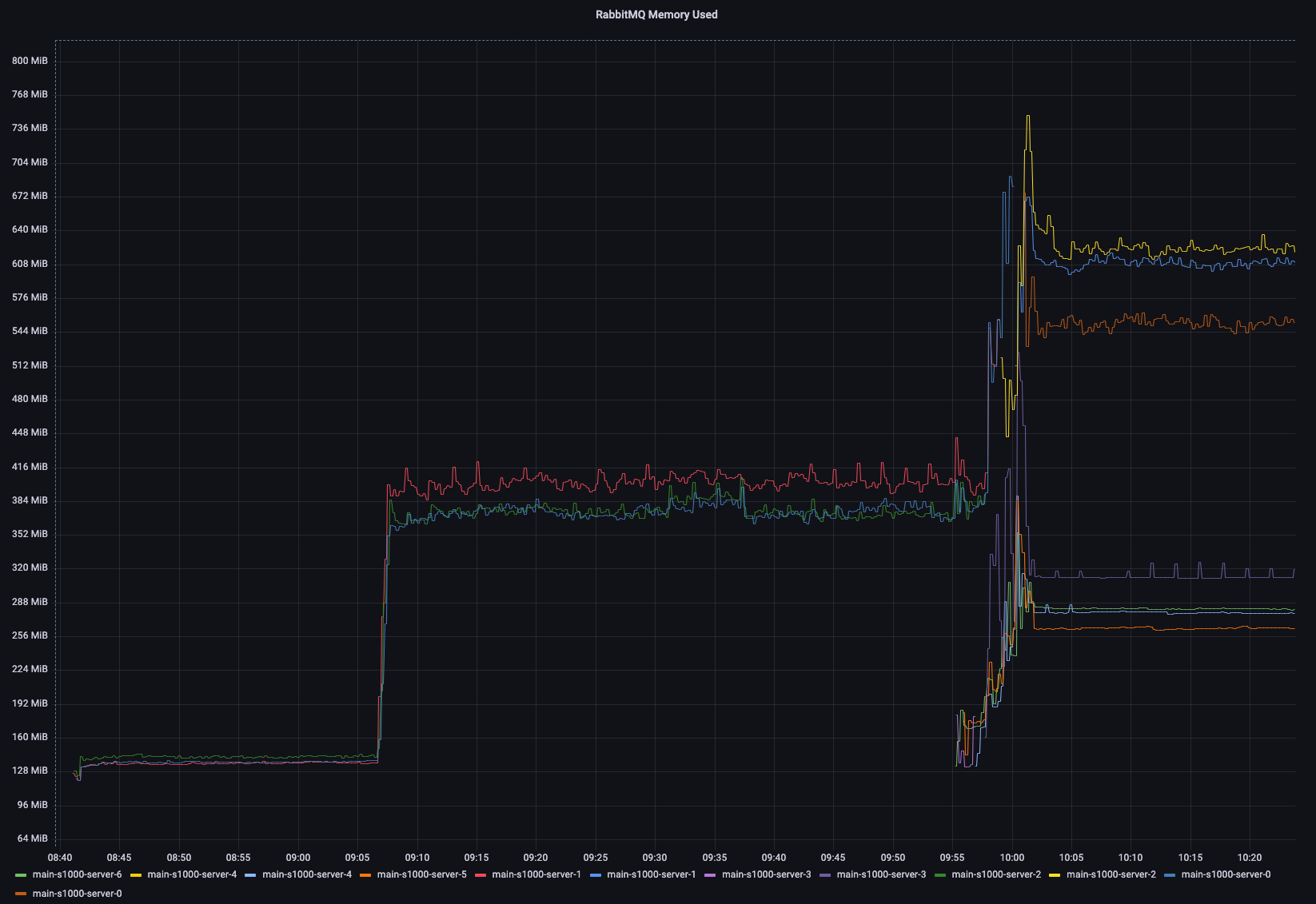
Beta Was this translation helpful? Give feedback.
-
No, it is not (if you add it, it is propagated, but not with the correct type). We will add it. |
Beta Was this translation helpful? Give feedback.
-
|
We pushed a fix for the |
Beta Was this translation helpful? Give feedback.
-
|
So great, thanks will try that! |
Beta Was this translation helpful? Give feedback.
-
|
Could you maybe also tell me how I can restart a stream like mentioned here? #7362 (comment) My container didnt have that command, can I install it somehow? |
Beta Was this translation helpful? Give feedback.
-
|
It's a new command coming in 3.12 |
Beta Was this translation helpful? Give feedback.
-
|
Ah I see, thanks! |
Beta Was this translation helpful? Give feedback.
-
|
Ok so I tried now to delete the vhosts again, but it's not working... in the logs I can only see following timeouts:
|
Beta Was this translation helpful? Give feedback.
-
|
We cannot suggest why the stream coordinator may not be running. See the rest of the logs. A node restart should help, according to the message it is hosted on the same |
Beta Was this translation helpful? Give feedback.
-
|
Hi, we are trying to use streams to replace our mirror queues and we experience the same memory behaviour: with many empty streams on a 3-node cluster, the memory of all nodes increases and goes higher than the watermark limit, then all incoming trafic is blocked. Here are the steps to reproduce:
As soon as we created the streams, we saw 3.8GiB for each node in "Memory details"->"Binaries". However there was nothing special in the "Binary reference" part and this was not reported in the "Resident Set Size". After a few minutes, the memory of each node increased until it reached around 2.2GiB (the watermark is 1.6GiB). At this point we added bindings between every stream and the amq.fanout exchange (through the HTTP API: POST /api/bindings/testvhost/e/amq.fanout/q/teststream. We tried publishing to amq.fanout through AMQP but the whole cluster is blocked and does not accept incoming AMQP trafic. We also tried publishing a message in amq.fanout from the management UI: the message was accepted and stored in all streams. The memory suddenly dropped below the watermark and the cluster could accept incoming AMQP trafic. Here is the memory metric for the whole test: Some other tests we did:
We hope there is enough information for you to reproduce the problem. |
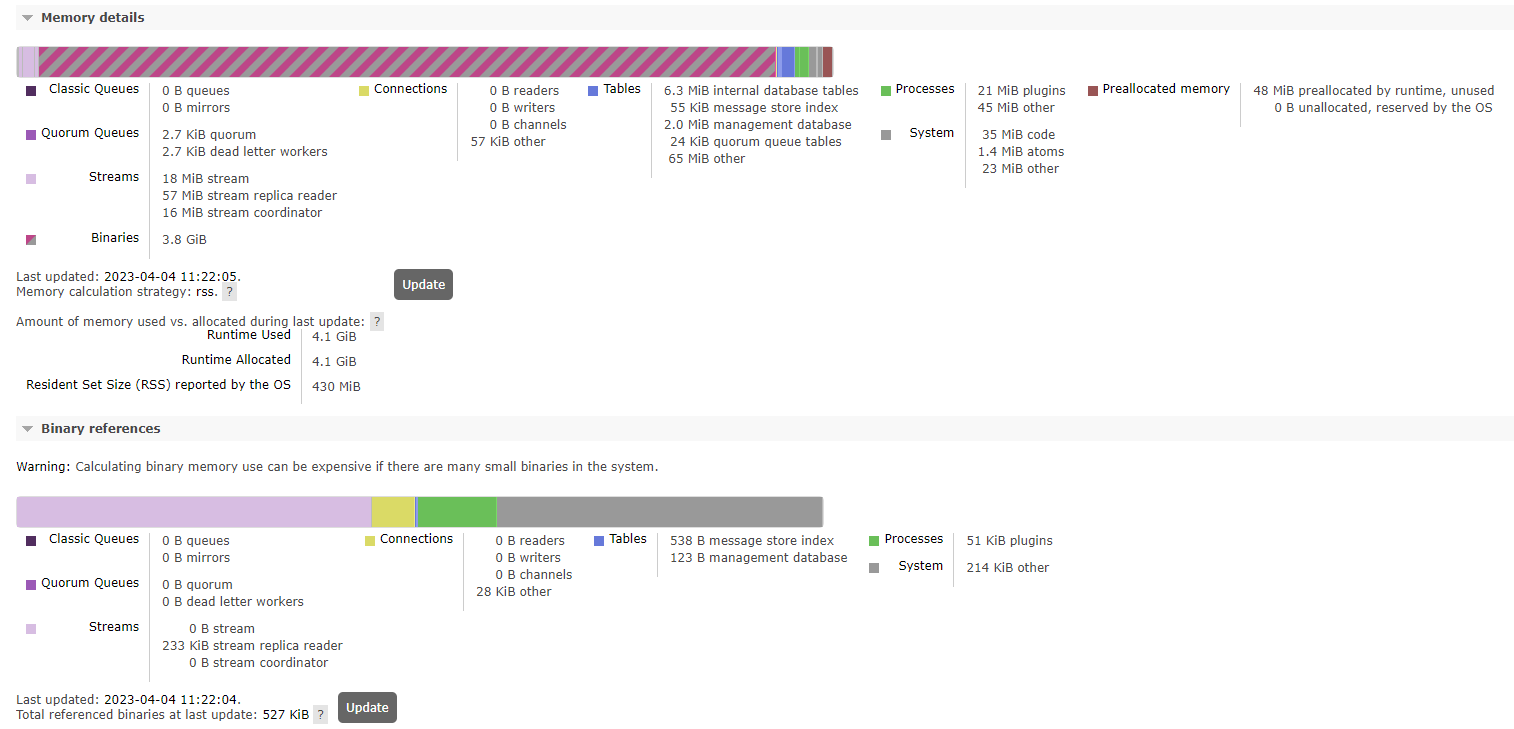
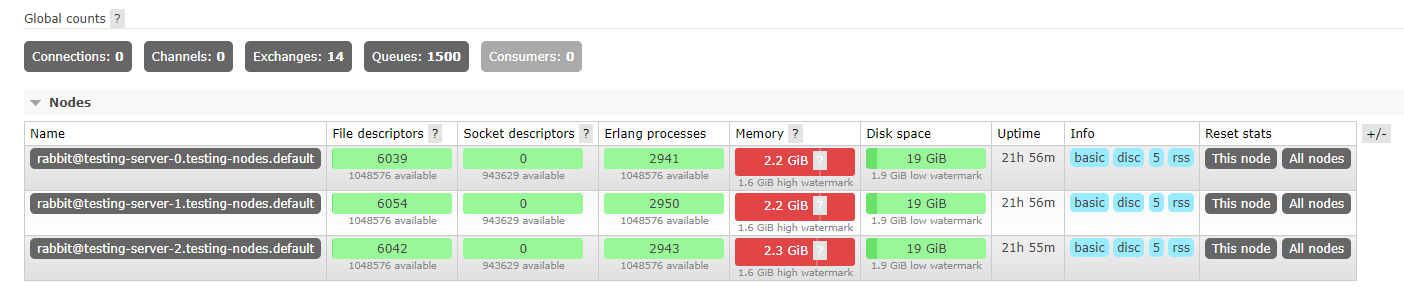
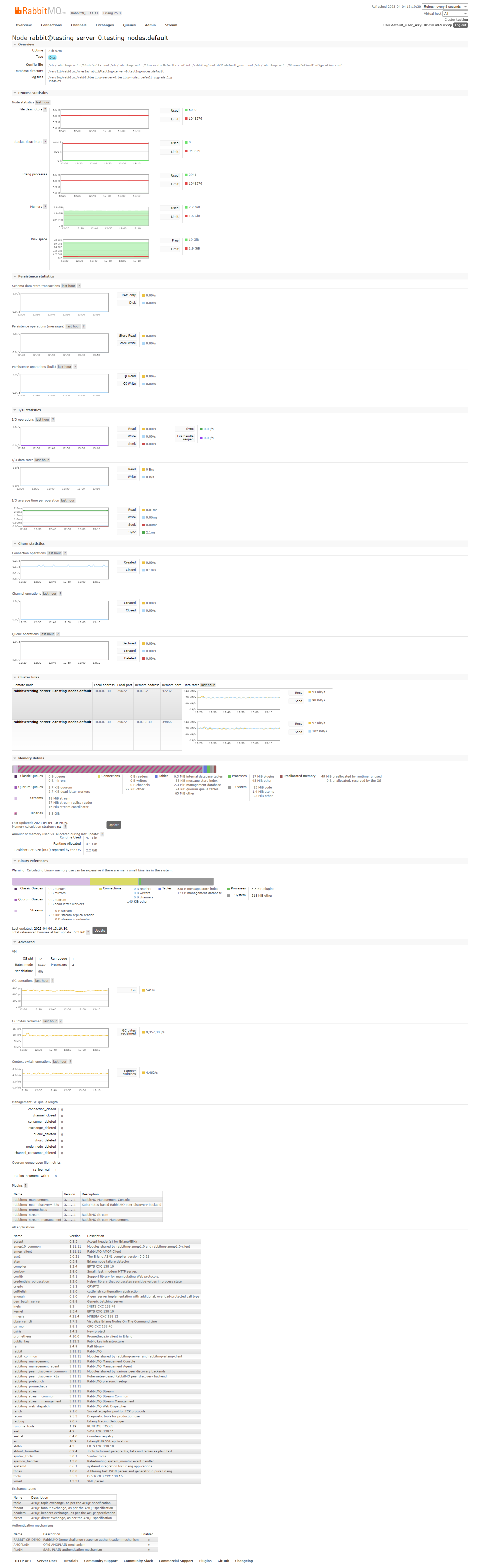

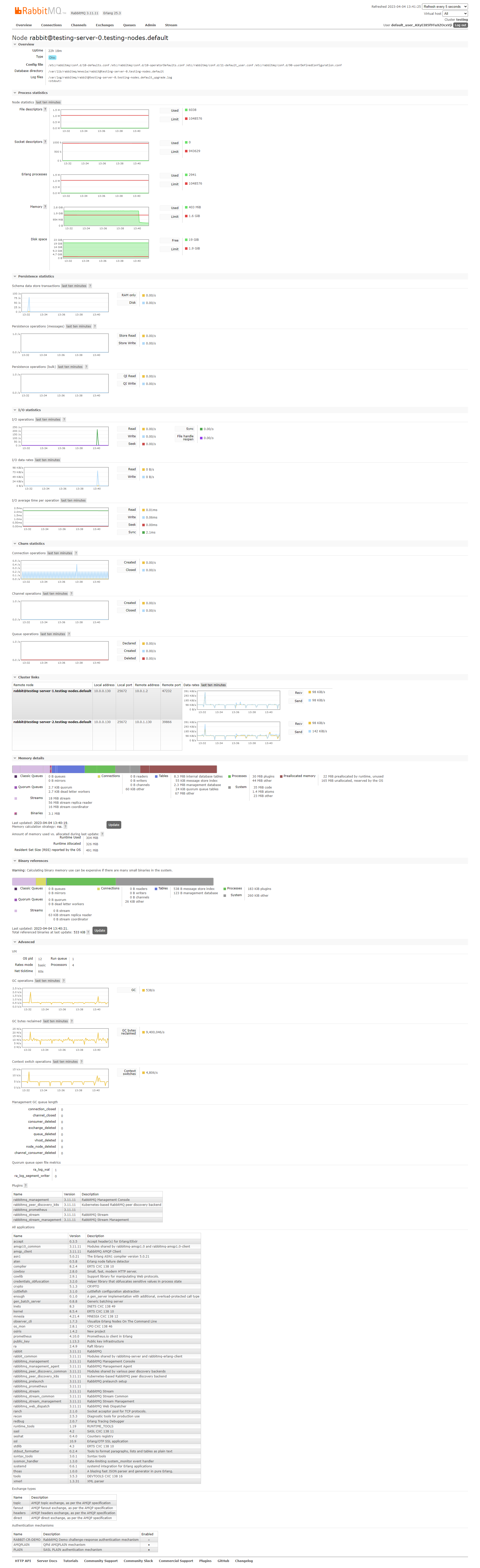
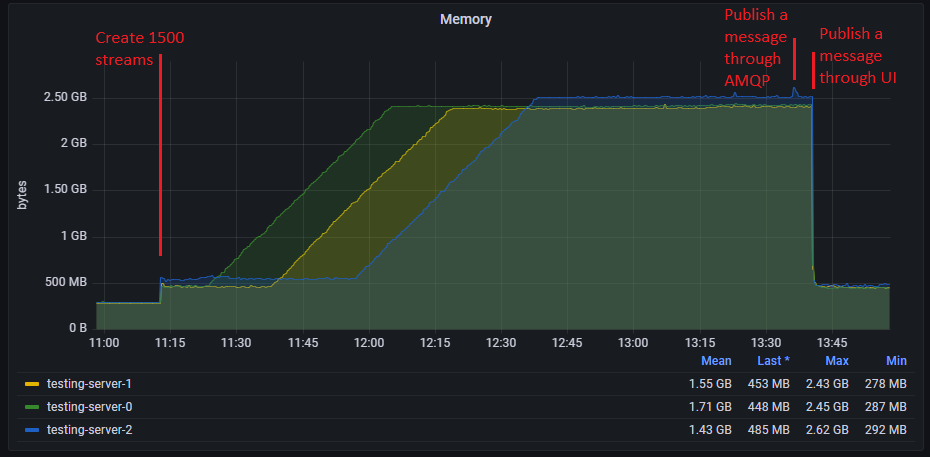
Beta Was this translation helpful? Give feedback.
-
|
Thanks, I will try to reproduce in my env. Just to confirm: you are saying that you see this problem without any client connections, correct? Just declare and wait? |
Beta Was this translation helpful? Give feedback.
-
|
I can't reproduce this (once again). I have the same version, a policy and 10 000 streams for good measure. Same plugins enabled, Prometheus scraping the metrics and the memory usage is low and stable. Can you repeat your steps, but rather than sending a message (the one that makes memory usage go down), run this: that's a Linux shell command to run an Erlang shell and then an Erlang function call. It should release the memory similarly to what you see when you send a message, but it will print out which Erlang processes released most of that memory (top 20). If you could repeat the steps on all nodes and share the output, that'd be very helpful. |
Beta Was this translation helpful? Give feedback.
-
Exactly I repeated the steps and waited for the memory usage to stabilize (higher than the watermark) then I ran the command but it does not print anything (same on other nodes): The memory usage did not drop after executing the command. |
Beta Was this translation helpful? Give feedback.
-
|
You need a full stop after recon:bin_leak(10).
…On Wed, 5 Apr 2023 at 09:55, Tatiana Neuer ***@***.***> wrote:
Just to confirm: you are saying that you see this problem without any
client connections, correct? Just declare and wait?
Exactly
I repeated the steps and waited for the memory usage to stabilize (higher
than the watermark) then I ran the command but it does not print anything
(same on other nodes):
$ kubectl exec --stdin --tty testing-server-0 -- /bin/bash
Defaulted container "rabbitmq" out of: rabbitmq, setup-container (init)
***@***.***:/$ rabbitmq-diagnostics remote_shell
Starting an interactive Erlang shell on node ***@***.*** Press 'Ctrl+G' then 'q' to exit.
Erlang/OTP 25 [erts-13.2] [source] [64-bit] [smp:4:3] [ds:4:3:10] [async-threads:1] [jit:ns]
Eshell V13.2 (abort with ^G)
***@***.***)1> recon:bin_leak(20)
***@***.***)1>
The memory usage did not drop after executing the command.
—
Reply to this email directly, view it on GitHub
<#7362 (reply in thread)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAJAHFEDBD74XVLAQ65FYTTW7UXQXANCNFSM6AAAAAAVBZRNTI>
.
You are receiving this because you were mentioned.Message ID:
***@***.***
com>
--
*Karl Nilsson*
|
Beta Was this translation helpful? Give feedback.
-
|
Adding the full stop triggers a syntax error: |
Beta Was this translation helpful? Give feedback.
-
|
is the the same shell session? try it again
…On Wed, 5 Apr 2023 at 10:08, Tatiana Neuer ***@***.***> wrote:
Adding the full stop triggers a syntax error:
***@***.***)1> recon:bin_leak(20).
* 2:1: syntax error before: recon
***@***.***)1>
—
Reply to this email directly, view it on GitHub
<#7362 (reply in thread)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAJAHFCFXFOGKQVNL3I6OOTW7UZB3ANCNFSM6AAAAAAVBZRNTI>
.
You are receiving this because you were mentioned.Message ID:
***@***.***
com>
--
*Karl Nilsson*
|
Beta Was this translation helpful? Give feedback.
-
|
@mkuratczyk could you please tell me on what OS you are trying to reproduce ? I am on Ubuntu 20.04.5 |
Beta Was this translation helpful? Give feedback.
-
|
I was using docker images ( I think what you are describing matches my understanding of the problem. Stream (Erlang) processes perform some initial work on startup and then if they sit idle, they are not garbage collected. Sending a message triggers GC and the memory usage goes down. I think we can add an explicit call to GC the process after startup to prevent idle streams from using excessive memory. |
Beta Was this translation helpful? Give feedback.
-
|
Shouldn't |
Beta Was this translation helpful? Give feedback.
-
|
I ran rabbitmqctl force_gc when the memory usage is high but it did not make any difference. It released only a few MiB, which is nothing compared to the memory released when sending a message. |
Beta Was this translation helpful? Give feedback.
-
|
Right, I forgot you had mentioned that before. I honestly have no theories right now... |
Beta Was this translation helpful? Give feedback.
-
|
We are having the same issue with version 3.11.5. We already have non stream topology working on rabbitmq. We wanted store some records the replay afterwards to train algorithms. So I created a stream and connected it to the already existing fanout. In a minute, the ram usage sky rocketed. The whole kubernetes cluster became unstable. I deleted the stream to revert things back. In overview section of rabbitmq management there were ready 300k message belonging to the stream even tho I deleted the stream. I waited for a while to things to stabilize but they did not, so I restarted rabbitmq then everything went back to normal. |
Beta Was this translation helpful? Give feedback.
-
I don't think it is related to our code. Just publish 600 bytes memory and it happens. We can arrange an online meeting if you prefer.
I can get permission. |
Beta Was this translation helpful? Give feedback.
-
|
Do you scrape the |
Beta Was this translation helpful? Give feedback.
-
|
We were hosting on Digital Ocean managed Kubernetes Cluster, if this helps somehow. |
Beta Was this translation helpful? Give feedback.
-
|
yep, this belongs to rabbitmq and the times are yesterday's test |

Beta Was this translation helpful? Give feedback.
-
|
@aeb-dev can you try setting a pod memory limit that is smaller than the available disk size and see if this changes anything? |
Beta Was this translation helpful? Give feedback.
-
|
To summarize today's findings from another environment with a similar behavior:
|
Beta Was this translation helpful? Give feedback.
-
|
https://kubernetes.io/docs/concepts/architecture/cgroups/ |
Beta Was this translation helpful? Give feedback.
-
|
Streams lead to a much higher page cache usage, because their files are not modified / deleted regularly as it happens with queues (in other words, stream segment files are much more cache-friendly) and cgroups2 includes page cache usage in the pod's memory usage if I understand correctly. |
Beta Was this translation helpful? Give feedback.
-
|
I believe so as well. I will try to check this in out development environment. This was a wild run :D Thank you all for allocating time and being patient! |
Beta Was this translation helpful? Give feedback.
-
|
Yeah, thanks for providing all the answers. The question remains - what can we do about it. :) I guess over time more and more people will be using cgroups2 but there's no obvious answer what we can do to make it work well. Some pointers for research: |
Beta Was this translation helpful? Give feedback.
-
|
I am planning on testing this at the end of the week. I will check SO link as well, thanks For rabbitmq side, I am not sure if I am the right person to give advice 😄 |
Beta Was this translation helpful? Give feedback.
-
|
Similar problems/effects here. Describing the observation, as they may help others. Running first on Kubernates 1.27.5 with RabbitMQ 3.8.34 Alpine image. 1.) Switching from classic (unmirrored) queues for 17 queues to quorum queues on RabbitMQ 3.8.34 Quorum Queues are using a LOT more memory. The default setting with raft.wal_max_size_bytes = 512 000 000 (512 MB) immediately lead to problems, even after doubling the memory in PROD to 8192 MB. 2.) Reduced wal_max_size_bytes If we check the memory usage we a lot memory usage in Binaries - growing from 10 MB up to 900 MB. If this is some kind of OS cache, then the labels and descriptions are missleading. I would exept the binary part to be almost constant. Second big portion is "quorum queue tables" (not "quorum queues"). And also her a large growing from 20 MB to somtimes over 400 MB. If the size of these tables are in some way depending on the number of messages in the queue , then in my opinion they should grow only to so kind of limit and if the number of messages still increases these tables need to be persisted to the volueme instead of eating more and more RAM (in updated Rabbit this seams to happen, see later). What is remakable: The memory used from rabbit changes a lot starting from IDLE to LOAD. In fact I would expect the memory consumption would stay almost the same, just the storage consumption would increase with more messages. IDLE: Started LOAD: LOAD, near to crash/halting queues: 3.) Updating to Rabbit 3.12.6 with Bitnami image (Debian) So on 3.12.6 Bitnami (Debian) image and kubernates 1.27.5 it looks good to me. |




Beta Was this translation helpful? Give feedback.
-
|
Resources that Quorum Queues Use. If you intend to run nodes with 700 MiB as a hard limit, perhaps lower the Raft WAL file size from 512 MiB to something like 128 MiB (for new clusters anyway, although this should be safe to lower with existing on disk WAL segment files). |
Beta Was this translation helpful? Give feedback.
-
|
"Quorum queue tables" is the Raft log entries kept in memory (as well as on disk) for efficient access, and moved completely to disk/flushed when the above limit is reached. It is expected to grow and shrink in a seesaw pattern, the docs say as much. Use streams if you want the lowest possible memory footprint even under close to peak load at the cost of much higher disk I/O, kernel page cache use (which specifically on Kubernetes can be a headache for reasons that RabbitMQ does not control, as demonstrated in this discussion), and the use of a wider port range for replication. |
Beta Was this translation helpful? Give feedback.
-
|
@bmaehr you are not really observing "the same effects" in your environment because in your case, it's not the kernel page cache that uses most of that memory, it is RabbitMQ's own in-memory Raft log table that is moved to a WAL file when a certain threshold is reached. These will be reported very differently by various monitoring tools, accounted differently by the kernel/cgroups, and required different mitigation strategies. |
Beta Was this translation helpful? Give feedback.
-
|
This findings from this and a couple of similar discussions with Kubernetes users have been briefly documented. This now attracts all kinds of "here is my memory footprint profile" comments, not related to streams, to the kernel page cache, or even to modern versions (3.8 has been out of support for some 15 months now). New discussions should be started instead => closing. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks to some research by @Kraego, we now know what specific combination of Kubernetes and cgroups version exhibits this behavior: upgrading to Kubernetes 1.25 with cgroups v2 should make it go away, see kubernetes/kubernetes#43916 (comment) and https://kubernetes.io/blog/2022/08/31/cgroupv2-ga-1-25/#:~:text=cgroup%20v2%20provides%20a%20unified,has%20graduated%20to%20general%20availability |
Beta Was this translation helpful? Give feedback.
-
|
Thanks to some research by @Kraego, we now know what specific combination of Kubernetes and cgroups version exhibits this behavior: upgrading to Kubernetes 1.25 with cgroups v2 should make it go away, see kubernetes/kubernetes#43916 (comment) and https://kubernetes.io/blog/2022/08/31/cgroupv2-ga-1-25/#:~:text=cgroup%20v2%20provides%20a%20unified,has%20graduated%20to%20general%20availability |
Beta Was this translation helpful? Give feedback.
This findings from this and a couple of similar discussions with Kubernetes users have been briefly documented.
This now attracts all kinds of "here is my memory footprint profile" comments, not related to streams, to the kernel page cache, or even to modern versions (3.8 has been out of support for some 15 months now). New discussions should be started instead => closing.