-
|
We've had one node lose data. Node A is the node to remove. It is offline and configured to be Watcher. When I start the RavenDB service on the server, the situation doesn't change. As usually with increased load, there is constant voting in progress, and the Term increases steadily (by one every couple of seconds). What is the best way to recover from this situation? We also see the following: Formatted/unescaped inner exception: |
Beta Was this translation helpful? Give feedback.
Replies: 2 comments 8 replies
-
|
After further investigation, it seems that the source of the issue is that the B node has a wrong state (index/term mismatch). Because of this, it won't accept the noop RAFT message from node C, which would change C's state from LeaderElect to Leader. The suggested fix described at https://issues.hibernatingrhinos.com/issue/RavenDB-18590#focus=Comments-67-356384.0-0 is the following:
However, it's not possible to demote the node B, as only the leader node can do that, and C is not the leader yet. Is it possible to either forcefully demote a node or force a node to become the leader? Alternatively, is it possible to reach a state of the cluster to get out of this situation? The cluster is currently in the following state: The cluster diagram shows node A to be active and also the connection between C and A to be active, even though node A doesn't run. Should this be the case?
|
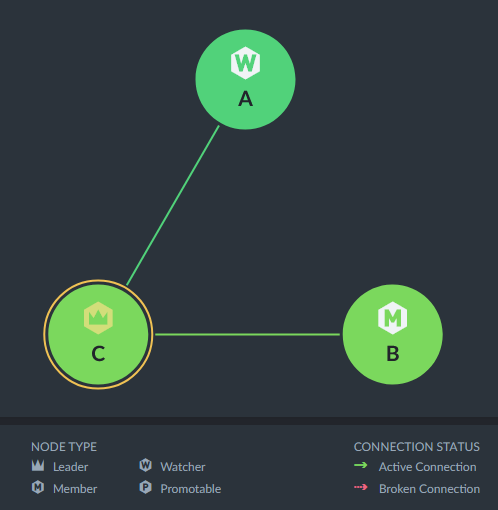
Beta Was this translation helpful? Give feedback.
-
|
Hi If you are running with encryption ? if not, you can you try to stop RavenDB service on node A, rename (delete) the system database folder, and start the service ? This should replicate the system DB from scratch, then you can elect a leader and should be able to Request a snapshot by running server.serverStore.RequestSnapshot() in the JS admin console |
Beta Was this translation helpful? Give feedback.
-
|
I have an additional question, @karmeli87, @garayx. Is the above process (stop the node, remove system database, start the node) safe to do in that the cluster will restore the database from healthy nodes? We suspect that the cluster doesn't behave quite as expected, so we'd like to eliminate the possibility of system database inconsistencies causing this. Resetting the system database on the last remaining node (C) would likely ensure that it is synchronized across the cluster even though it should be already the case - the system database on node B was restored from the database on node C. However, I want to check that triggering this shouldn't have other adverse effects under otherwise normal operating conditions. |
Beta Was this translation helpful? Give feedback.
-
|
Given that the cluster was broken it might happened that database topology was not consistent no all nodes and was unable to be updated because of the issue above. In a normal operation rebuilding the database would cause that node to move into rehab due to the high document count difference recognized by the cluster observer. Also, your current cluster topology is 2 Members and 1 Watcher, meaning that if one of the member nodes fail (like happened for B) you will not be able to elect a leader because it will require a majority. In your case it will require both member nodes to be functional. Hope it make sense :-) |
Beta Was this translation helpful? Give feedback.
-
|
Yes, that makes sense. Having node A as a watcher was supposed to be a temporary state, and the problem with the leader being unable to take office started soon after demoting node A. I believe that node A was the leader before, and after stepping down and demoting it, the cluster got to the state described earlier. After we provision the new server, we'll add it to the database groups and wait for the replication. Since it will be brand new, the recovery should occur without inconsistency issues, I hope. But I want to confirm again: If I were to remove the system database on the currently healthy node C, it should recover the data from node B without any adverse effects, right? The current topology is that node A is offline, and nodes B and C are nominally operational on both the cluster level and database level for all databases. |
Beta Was this translation helpful? Give feedback.
-
|
when you remove the system folder and turn the node back on, the leader will send the snapshot of the cluster to that node |
Beta Was this translation helpful? Give feedback.
-
|
Great, thanks for the information, Egor. |
Beta Was this translation helpful? Give feedback.
Hi
If you are running with encryption ? if not, you can you try to stop RavenDB service on node A, rename (delete) the system database folder, and start the service ? This should replicate the system DB from scratch, then you can elect a leader and should be able to Request a snapshot by running server.serverStore.RequestSnapshot() in the JS admin console