Comparative and Absolute Probability phrase dataset #1008
Description
Please consider submitting this dataset as a pull request! See https://github.com/rfordatascience/tidytuesday/blob/main/pr_instructions.md to learn how.
Please fill out as much of this information as you can!
-
This dataset has not already been used in TidyTuesday.
-
The dataset will (probably) be less than 20MB when saved as a tidy CSV.
-
I can imagine a data visualization related to this dataset.
-
title: Comparative and Absolute Probability phrase dataset
-
article: An example of the dataset being used, such as a blog post or a README about the dataset.
- title: CAPphrase: Comparative and Absolute Probability phrase dataset
- url: https://adamkucharski.github.io/CAPphrase/
-
data_source: A source where the dataset can be downloaded.
- title: CAPphrase
- url: https://github.com/adamkucharski/CAPphrase
-
images: One or more images related to the dataset. For each image, provide:
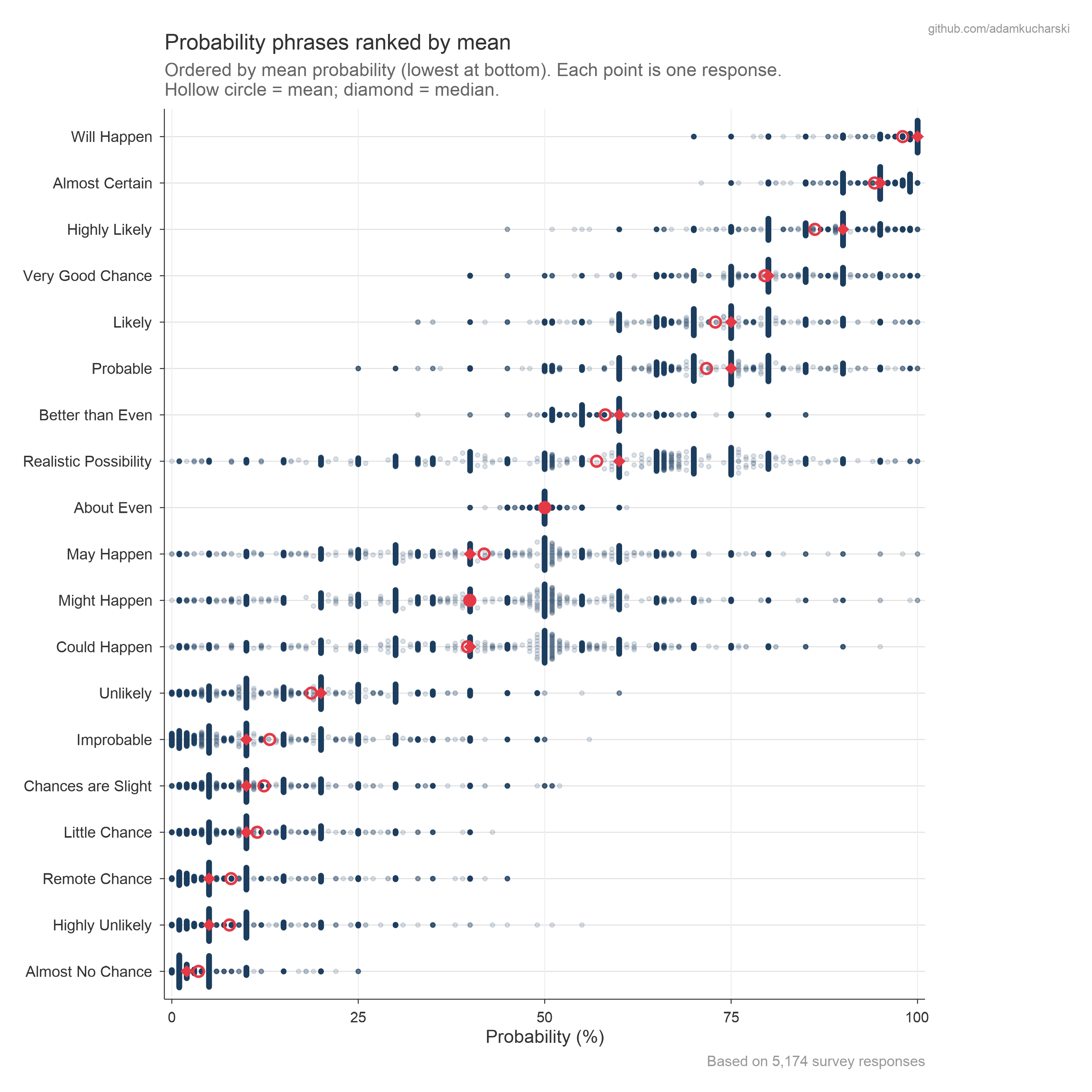
- file: https://adamkucharski.github.io/CAPphrase/output/01_words_means.png
- alt: Chart showing the distribution of estimated probabilities for different phrases, ranked by mean. Will Happen is top, and Almost No Chance is bottom.
-
cleaning_script: A script to fetch and clean the data, resulting in one or more data.frames (or equivalent structures) that can be saved as CSVs.
{kind=link}
No cleaning required (data is already a clean CSV just needs copying over from a different GitHub repo).
- data_dictionary: A description of each column in the dataset, including the column name, the data type of the column, and a description of the column.
| variable | class | description |
|---|---|---|
| VARIABLE | CLASS | DESCRIPTION |