{kind=link}
{kind=link}
{kind=link}
The Naive Bayes Classifier is a simple yet highly effective algorithm based on Bayes’ Theorem.
It assumes that all features are independent (naive assumption) but still delivers strong performance on many datasets.
💡 Ideal for quick, interpretable, and accurate classification.
- Prior Probability — How frequent each class is in the dataset.
- Likelihood — Probability of a feature value for each class.
- Posterior Probability — Combining prior & likelihood using Bayes’ Theorem.
- Prediction — Selecting the class with the highest posterior probability.
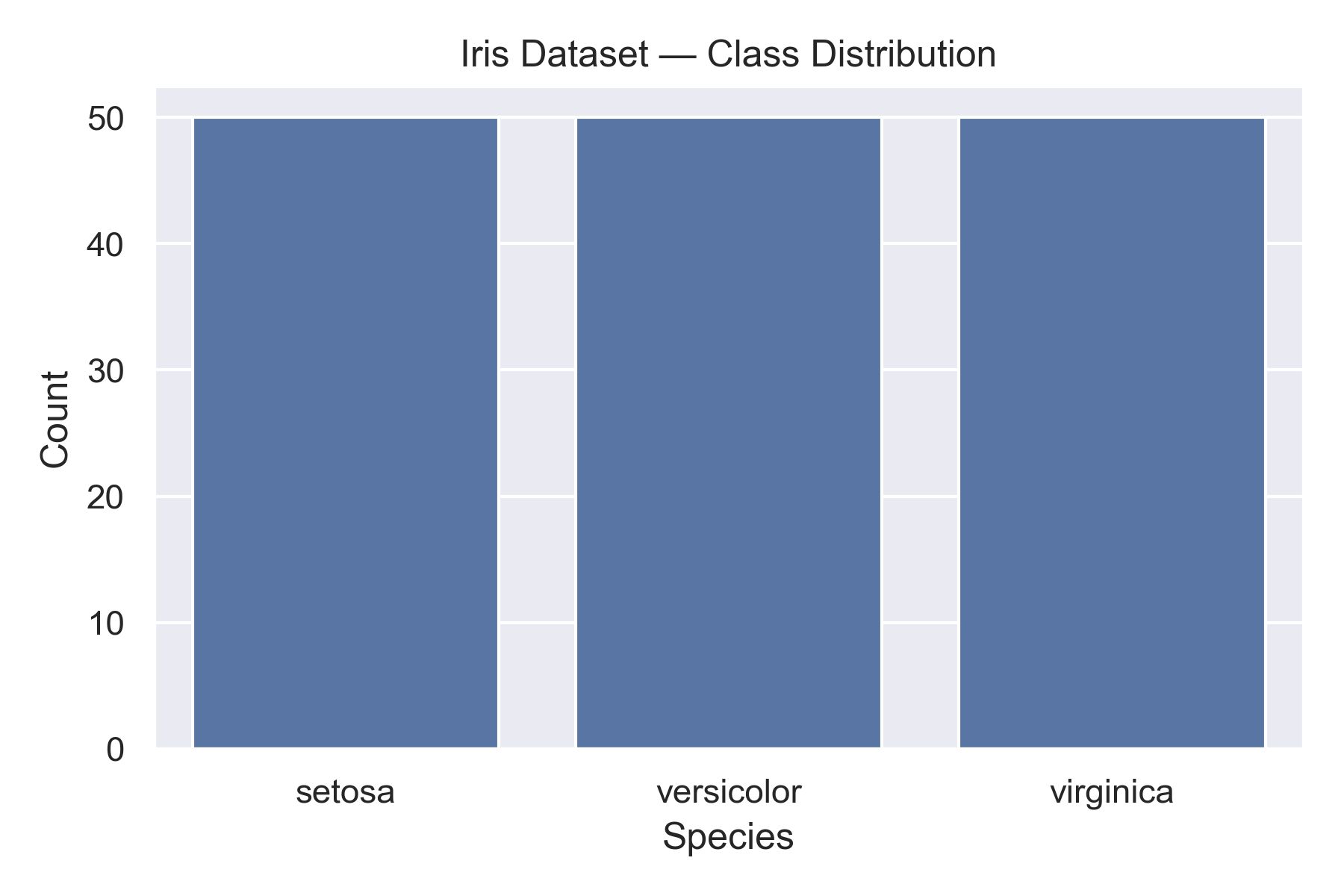
- Name: Iris Dataset
- Samples: 150
- Features: Sepal Length, Sepal Width, Petal Length, Petal Width
- Classes: Setosa, Versicolor, Virginica
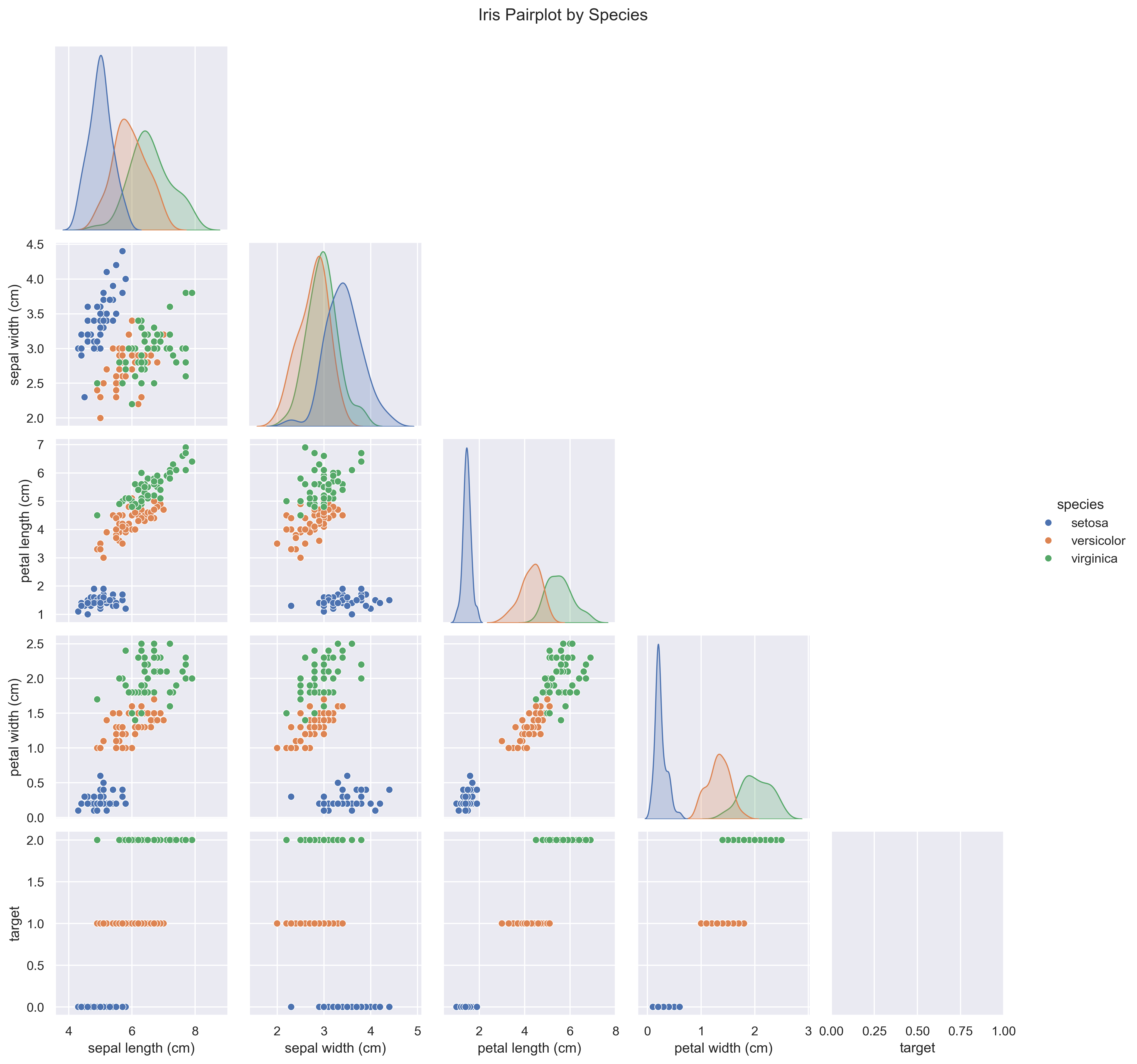
The pairplot shows strong class separability, especially in Petal Length and Petal Width, making Naive Bayes well-suited for this dataset.
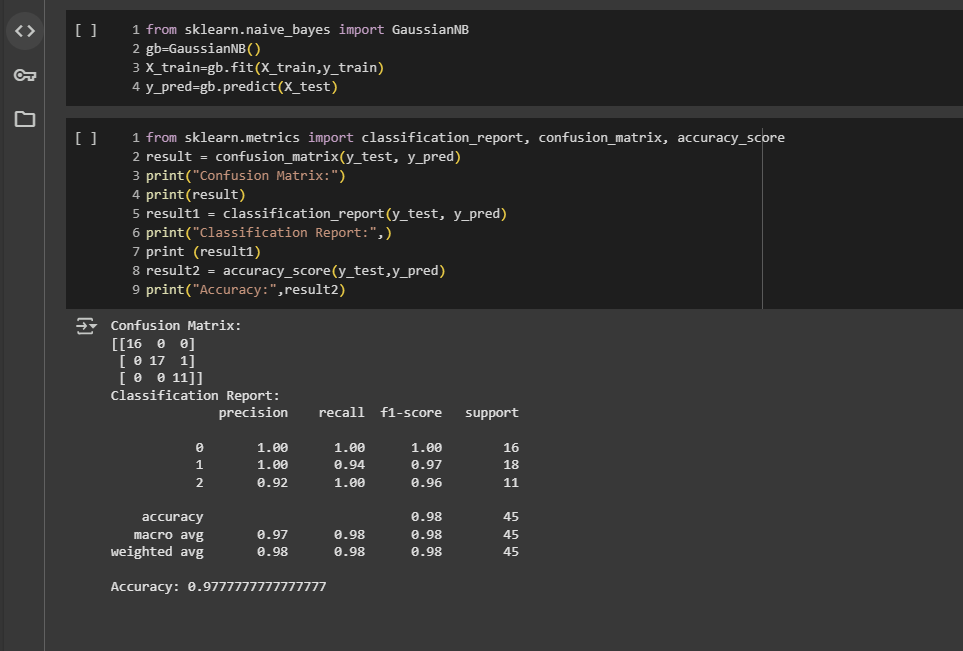
Accuracy: 97.77% ✅
| Class | Precision | Recall | F1-score |
|---|---|---|---|
| Setosa | 1.00 | 1.00 | 1.00 |
| Versicolor | 1.00 | 0.94 | 0.97 |
| Virginica | 0.92 | 1.00 | 0.96 |
- ⚡ Fast — Training & prediction happen in milliseconds.
- 📊 Accurate — Nearly perfect classification on Iris.
- 🧠 Simple — Easy to interpret & explain.
- 🎯 Multi-class Ready — Handles 3+ classes without extra steps.
This project is part of the Machine Learning Blueprints — a curated set of ML implementations with clean code, real datasets, and visual insights.
⭐ If you enjoyed this, please star the repository to support more high-quality ML projects.