Replies: 16 comments 17 replies
-
|
The implementation of the trace can be found here in my fork of Summary: I added a More Details on Tracing: Adding additional optimizations to the inserted traces would be possible, but the biggest influence on performance seemed how the profiler chose traces itself. My profiler is quite simple. It attempts to create intraprocederal traces of maximum length 5 instructions, starting at the first executed instruction, rejecting instructions which could have "side effects" (e.g. ret, call, print). It additionally adds the unneeded constraint that all traces should be disjoint to avoid ambiguity when traces start on the same instruction and reduce otherwise ballooning code size inserting the traces was causing. The number 5 is arbitrary but testing larger numbers didn't yield significantly different traces. It seemed for the benchmarks I tested, an unhandled instruction most often stopped a trace. This method of finding traces occasionally finds a common path, but as much as that finds short traces with lots of ignored instructions for which inserting them into the IR using speculation can only slow down the program. Results: Except for programs with many chained jumps, this implementation of speculative execution increases the dynamic instruction count. A table can be seen below. Listed in the dynamic instruction count with the input used to generate that count in parenthesis:
These show between a 40-60% increase in dynamic instruction count. The results are mostly unsurprising. My explanation for why ackermann performs notably worse than the other two benchmarks is due to the tracing algorithm happening to find a really small trace in the recursive case which inserted proportionally more extra instructions compared to the other tests. Due to the simplicity of my tracing algorithm and also the more deterministic nature of the benchmarks I was tracing, I found the traces were pretty stable for varying inputs after a given size threshold. These results point to the best places for immediate improvements would be in smarter trace collection, such as a heuristic for when to start traces to help choose longer, explicit hot paths for traces or traces which the compiler can optimize. One possible heuristic could be starting traces on The Hardest Part: I found the most challenging part to be dealing with terminating basic block terminators. My code initially made the incorrect assumption that traces should fall through to the instruction following them. This is clearly incorrect but took a bit to debug. Additionally, I'd never programmed in typescript before (and had extremely minimal javascript experience), so hacking the interpreter had a bit of a learning curve. Star(s)?: I think this is star worthy work. It implements tracing and then the insertion of these traces into the profiled programs. It then does a straightforward description of this implementation and a brief analysis of quantitative results. The analysis then makes an argument for admittedly somewhat obvious improvements to the implementation. As I didn't actually implement these, I don't think the work is multi-star worthy, but I also think there is enough here to disqualify no stars, hence one star. |
Beta Was this translation helpful? Give feedback.
-
|
Very impressive, @jku20! Especially because you finished this before we even did the lesson about tracing. :) I think it's a cool idea to collect a lot of small traces; I think it will be just as common (or more) for people to approach this task by just attempting to take one big trace. Going this route led you to think about the space of possible heuristics for finding good traces to collect, which is great! |
Beta Was this translation helpful? Give feedback.
-
|
Source: https://github.com/Mond45/bril/tree/trace What I DidFor tracing, I modified the reference TypeScript Bril interpreter to output a trace for every executed instruction. The trace starts from the beginning of the For the trace injector, I built a TypeScript script that wraps the input trace with I also wrote another script for creating traces and generating the optimized programs by injecting the built traces. The Hardest PartI initially aimed to implement the interprocedural tracer, but ultimately gave up because of limited time and the increasing complexity of the implementation details. I also spent quite some time debugging my test creation script, where it failed weirdly because I forgot to close the intermediate trace output file. The intraprocedural tracer and the injector were fairly straightforward to implement, though they required some effort to navigate and get used to the TypeScript Bril implementation. TestingI tested the optimized programs with injected traces on a selected subset of core Bril benchmarks. These tests were chosen such that each source contains only a The benchmarks tested were:
The dynamic instructions counts for the unoptimized version versus the injected trace version are shown below:
ConclusionI believe I deserve a Michelin star for this task. Even though the work was not that ambitious, I managed to correctly implement the tracer and the optimizer, thoroughly verify their correctness, and build a script to automate the test creation process. |
Beta Was this translation helpful? Give feedback.
-
|
Good job! It would be include data on whether the optimizations didn't break the programs! |
Beta Was this translation helpful? Give feedback.
-
|
Source Code: https://github.com/jeffreyqdd/toy_trace_jit What I DidTracingThis was a really interesting project, and I realized how precise I needed to be with tracing. For starters, I modified the reference TypeScript Bril interpreter to output a trace when I provide the "--trace" flag. For fun, I made the trace span the entire program execution. A sample trace output from the modified BRIL interpreter looks like: So each instruction execution would give me 4 pieces of information delimited by &*&
JITThe interesting question now is: "How do we detect hot parts of the code?" To tackle this question, I defined For simplicity, I opted not to have a hot-path segment execute instructions that could have side effects ( After generating the guarded trace, I iteratively move guards closer to the start of the speculation block to reduce the number of instructions that are flushed when a guard fails.
TestingI had a toy example that looked like
Unfortunately, even with my very conservative optimization threshold, a few benchmarks still performed considerably worse. I'm not too surprised. The JIT tries to aggressively use speculation on the longest repeated sequence, and the cost incurred for a "mis-predict" is very high (this reminds me of pipeline flushing on incorrect branch-predicts).
ConclusionI believe I deserve a Michelin star because my code systematically identifies hot code sections and inserts "optimized" traces to reduce dynamic instruction counts (in one case 😞). The result was a trace-based compiler that works for programs that make repeated function calls with similar arguments. This is most definitely not multi-Michelin-star-worthy, since I did not support interprocedural calls or the "undoing" of operations with side effects. Unfortunately, I was not feeling ambitious enough to write this in Rust. |
Beta Was this translation helpful? Give feedback.
-
|
Nice! Yes it's difficult to optimize programs with trace analyses, but I think it was cool to see it optimize a program, even if it was more artificial! |
Beta Was this translation helpful? Give feedback.
-
Team & CodeMembers: Jake Hyun. The core lesson code resides in the lesson12 directory, and the tracing interpreter fork (branch What I DidImplemented a trace-based speculative optimizer: modified fork of I created and injected special functions into the bril programs for both the trace and trace metadata information, and this proved to be a simple readable design. Testing and ResultsHarness ( Example execution on Plot
ObservationsThe static instruction ratios are greater than one because of the duplicated prefix and the inserted guards. I wasn't ambitious on this assignment: no trace-local optimizations (such as dead code elimination inside the trace, constant folding of hoisted invariants, or guard specialization) were attempted. The dynamic instruction ratios mostly show a modest speculative overhead, which stems from the abort cost and the duplicate guards. Two benchmarks ( The correctness coverage is ninety successes out of ninety-two benchmarks. The two failures ( Hardest PartContinuation placement was the most fragile part of the implementation and is also the part where I spent the most time debugging. Generative AII used ChatGPT to port my evaluation harness from lesson 6/8 to this lesson, adapting it for the new optimization while maintaining similar structure and functionality. This accelerated iteration and helped spot subtle correctness issues. Michelin StarNot a star, but clean separation of profiling, injection, measurement for comprehensive evaluation. |
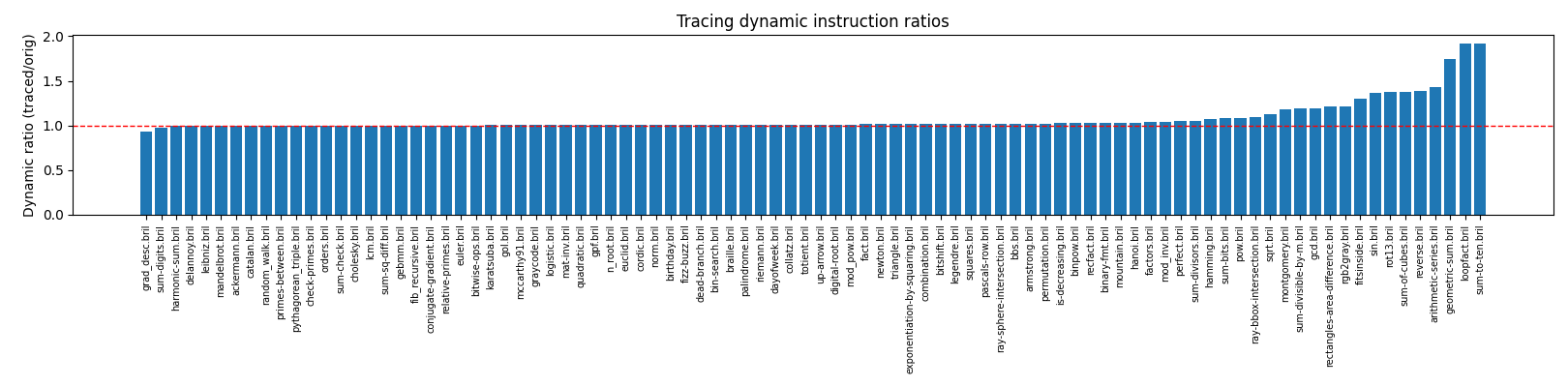
Beta Was this translation helpful? Give feedback.
-
|
Awesome, nice analysis on the data and why some benchmarks saw improvements, and why some failed! |
Beta Was this translation helpful? Give feedback.
-
Team MembersNing Wang (nw366), Jiale Lao (jl4492) Source Codehttps://github.com/NingWang0123/cs6120/tree/main/assa10 Implementation SummaryWe implemented a trace-based speculative optimizer for Bril that mimics tracing JIT compilation in a profile-guided AOT setting. The system has three main phases:
The implementation extracts a single hot execution path, wraps it with speculation primitives, and measures performance using dynamic instruction counting. We did not implement trace optimization and the interprocedural version because of time limitation. Testing MethodologyWe tested the implementation on 4 benchmarks from the Bril core suite, each with multiple inputs:
Test Benchmarks
Evaluation ResultsPerformance Summary
Aggregate Statistics:
Key Findings
Visualization (visualize_simple.py is generated by GPT-5 model)Dynamic Instruction Counts Comparison
The visualization shows the dynamic instruction count for each test case, comparing baseline (green) vs. traced (orange) execution. The Hardest PartWe initially tried to implement both trace optimization and inter-procedual version, but finally gave up because of time limits. This task requires more understanding of the speculation and implementation details, which takes us more time than previous tasks. Also the overhead is large, which highlights the importance of trace optimization in real JITs. Michelin StarWe believe we deserve a michelin star, because of correct implementation, testing on 4 benchmarks with different inputs, and a good visualization. We did not have time for trace optimization and inter-procedural version, but we did understand and implement the core ideas of a dynamic compiler. |
Beta Was this translation helpful? Give feedback.
-
|
Good job, nice use of gen AI to make the graphs! |
Beta Was this translation helpful? Give feedback.
-
|
Team Members What We DidFor our tracing setup, we modified the Bril interpreter (brili.ts) to record at most 10 dynamic instructions, giving us a short, bounded trace. After generating this trace, our trace.cpp tool processed it by rewriting branches into guard instructions and reconstructing function calls and returns. We then wrapped the transformed trace in a speculative region. If all guards succeed at runtime, execution reaches the trace_success label and commits the speculative state. Otherwise, any mismatch triggers the guard_failed label, which falls back to the original program. TestingWe evaluated our trace program on three tests: a custom For each test, we created four versions in the directory:
In each case, we used the original ( Here, we have a table comparing the dynamic instructions before and after tracing.
Hardest PartThe hardest part was properly reconstructing the control flow and behavior from the raw trace file. This is because it is fundamentally stream-based and gives relatively little context. Michelin StarWe believe that we deserve a michelin star because we produced a clean, working optimizer that correctly reconstructs control flow, handles calls and returns, inserts guards, and preserves program behavior across all our tests. |
Beta Was this translation helpful? Give feedback.
-
|
Good job! Yes it's difficult to actually get a more optimal program with this task, and that's okay :) |
Beta Was this translation helpful? Give feedback.
-
Dynamic compilationBy Helen and Pedro, at our Codeberg repo We implemented a dynamic compilation flow by obtaining traces from the interpreter given a source line range and a function name, and then using those traces in combination with the speculative extension for Bril to run the transformed trace during interpretation. EvaluationOur JIT does not optimize, but we refined it as instructed on three benchmarks:
We compared our outputs for these three benchmarks with the reference ones on a range of inputs and found them to be correct. Our JIT seemed to break some benchmarks, such as StarWe think so! We produced correct output on a range of inputs, and despite not managing to increase performance, we think we got the core of it working, so we are satisfied. We had to make interesting choices about tracing, inlining, and passing data between the interpreter and our compiler toolkit. |
Beta Was this translation helpful? Give feedback.
-
|
the breakage occurs on situations with multiple exit blocks, hence the selection of the chosen benchmarks. otherwise, the JIT simplifies minimally because we only run a basic DCE on it, which doesn't appear to affect the selected traces much. we didn't implement LVN because our LVN implementation would require some non-trivial refactoring to work with our trace format. |
Beta Was this translation helpful? Give feedback.
-
|
Cool! I wonder what you felt was the most difficult part of the task was? |
Beta Was this translation helpful? Give feedback.
-
|
Source code The results are as the following
AI usage Star? |
Beta Was this translation helpful? Give feedback.
-
|
Good job! I like the thorough evaluation which includes the delta as well as the correctness of the optimization |
Beta Was this translation helpful? Give feedback.
-
|
Team: Adnan Al Armouti, Tobias Weinberg ApproachFor this assignment, we implemented a trace-based speculative optimizer for Bril.
Whenever a trace included instructions unsafe to run while speculating — such as CorrectnessAcross multiple inputs, our transformed programs produced correct outputs. ResultsWe filtered for benchmarks where both baseline and JIT produced valid numeric dynamic instruction counts. These were the programs where our pass ran end-to-end successfully:
In every benchmark, the JIT version executed more dynamic instructions than the baseline. DiscussionThe slowdowns are an expected consequence of how our system behaves:
Although our system didn’t deliver speedups, it confirmed that our speculation framework was structurally correct, and it made clear how fragile speculative optimization is without good guard predicates. Takeaways
GenAI DisclaimerWe used ChatGPT (GPT-5) to help debug issues in our toolchain and to sanity-check our Bril transformations. It was particularly helpful for explaining parts of the speculation extension and for drafting shell commands, but it also hallucinated Bril syntax, made up interpreter flags, and occasionally mixed up behaviors across different versions of our tooling. This caused several detours until we verified what was actually happening by reading the Bril docs, checking the reference interpreter, and inspecting execution traces manually. Once we learned to fact-check everything, ChatGPT was a useful debugging assistant |
Beta Was this translation helpful? Give feedback.
-
|
Awesome!
This makes it sound like there are programs that didn't run the pass successfully. I wonder if that's that case, and if so, if you've looked into why the pass didn't run successfully on the programs! Also not that important, but I think |
Beta Was this translation helpful? Give feedback.
-
|
Source: HERE Implementation: I implemented a straight forward tracer. I modified brili to print out the trace of a given output, if (as above) a -t flag was given to the execution. Then, I created a new program to add this trace to the previous benchmark and then I ran the execution to ensure correctness. Testing: I only had time to test this on one bechmark and one input, the fizzbuzz benchmark with input 10. On input 10, there were 362 dynamic instructions (compared to 370 normally) but on 11 the dynamic instructions were 400, which implies this was a very small scoped optimization. Michelin Star: I think I generated a tracing program and successfully benchmarked it, earning a star |
Beta Was this translation helpful? Give feedback.
-
|
Hi, @tf-mac! Glad this worked out as anticipated. Too bad about only getting this to work on one benchmark, but that's life. Your writeup is also somewhat sparse here—it would have been great to know more about what you had to decide along the way to your implementation. |
Beta Was this translation helpful? Give feedback.
-
SourceLink What We DidWe modified brili to implement a trace-based speculative optimizer. Our optimizer detects "hot" loops by checking whether a current label has been encountered earlier in the execution. If so, it begins collecting the trace as it walks through subsequent lines, and stops tracing when it encounters the same label once more. We bail if we ever encounter a EvaluationWe tested it out on multiple benchmarks using multiple inputs. We generate the trace for the optimization from one of the inputs, and test the optimized and non-optimized programs on other inputs to check for correctness. For measuring performance, we just used the
StarWe believe that we deserve a Michelin star for a well-tested implementation that maintained correctness on multiple benchmarks. |
Beta Was this translation helpful? Give feedback.
-
|
Cool! I wonder if the evaluation could include whether the produced optimized programs gave the same output as the baseline! |
Beta Was this translation helpful? Give feedback.
-
|
Interprocedural Optimization: Ambitiously Inlining Calls Speculatively! What I did I implemented in Racket an interprocedural optimization to inline calls speculatively using the speculative extension. This speculative inlining is only performed for short functions, where I define short functions as functions which do not call other functions, do not have control flow, and are called in the main function. Implementation My approach uses a two-pass transformation with dynamic trace collection:
Calling Convention My speculative inlining uses a lightweight calling convention with specially-named variables:
This convention ensures complete isolation between the caller and inlined callee through explicit variable renaming, while the For example, the main function of the Armstrong benchmark: is transformed to, after applied optimizations: Testing
Results Total: 56 | Improved: 24 (42.9%) | Worsened: 26 (46.4%) | Unchanged: 6 (10.7%) 
Overall, speculative inlining improves about 43% of the benchmarks. Hardest Part Conclusion *GenAI I used Cursor to modify the Bril interpreter for tracing call instructions. GenAI was especially useful for coming up with a working code quite quickly. |
Beta Was this translation helpful? Give feedback.
-
|
This is seriously impressive, @maheshejs. Your design with a special "calling convention" for collapsed function calls is really cool and a good way to make this project more flexible and realistic than the basic intraprocedural tracing approach. And the results definitely indicate that it paid off. Super awesome!! 👏👏👏 |
Beta Was this translation helpful? Give feedback.
-
|
Implementation Testing star |

Beta Was this translation helpful? Give feedback.
-
|
Hi, @zc579—cool that you got this to work once (for one benchmark with a single input). To be confident that you got things correct, however, it would be important to make sure that (a) it works on multiple benchmarks, hopefully a large swath of core benchmarks, and (b) it works even when you change the input, to be sure that your fallback on guard failure works. |
Beta Was this translation helpful? Give feedback.
-
|
What I Did First, I modified the Bril interpreter to support a Next, I wrote a shell script ( I then wrote a Python script (
Finally, I wrote a merging script ( Evaluation and Results I wrote an evaluation script (
41 out of 55 core benchmarks work correctly (producing the right output), which I'm pretty happy about! However, unfortunately, none of them actually show performance improvements with this optimization approach. The optimized versions all have higher instruction counts than the baseline due to the speculation overhead. I think there are a few reasons for this not-so-good performance. First, I'm just capturing traces from the start of Hardest Part But even that wasn't sufficient! It took me some time to realize that I needed something like a "program counter" - the line number of the last instruction in my trace - to know where execution should resume when speculation succeeds. This required going back and adding more machinery to the Bril interpreter to track and output instruction indices, which was more invasive than I initially planned. AI Statement I used AI assistance on this assignment, primarily for writing string parsing and data processing code. Primarily, I used it for the shell script for running benchmarks and capturing trace and the evaluation script for comparing results, computing statistics, and generating visualizations. I also don't know TypeScript that well so it helped me out a lot with modifying the Conclusion |

Beta Was this translation helpful? Give feedback.
-
|
Awesome! Nice analysis on the evaluation and why some benchmarks failed. |
Beta Was this translation helpful? Give feedback.
-
|
Cynthia Shao and Jonathan Brown worked together on this task. SummaryWe implemented tracing for Bril. For our testing, we used brench to validate correctness and dynamic instruction count comparisons. Overall this assignment was very fun and gave us great insight on how a tracing JIT works. TracingWe implemented tracing within the bril-ts interpreter by adding the ‘-t’ flag. I added simple checks to only trace if the function is main, and if we haven’t reached a label that is a backedge. Our optimizer only optimizes main, and does not support calls, memory, or other extensions beyond simple bril. This strategy mainly optimizes loops that have a heavy setup and first iteration, as we know the possible input of the entry of the loop, and thus can optimize the first iteration. We run LVN and DCE on this resulting trace inserted code, and we see a varying amount of decreased instruction count! Testing and BenchmarkingFor testing, we used Turnt and brench. Brench was used to get the dynamic instruction count and validate correctness, and used Turnt for snapshot testing. Here are the benchmark comparisons: We added support for separate argument inputs into the tracing optimization function via comments at the top of the Bril benchmarks. Thus, the correctness and snapshot testing should be able to guard against cases where the tracing optimization “overfits” and we end up with code that only works on one input. Hardest PartThe hardest part was adding support across the stack! Creating the tracing optimization to wrap both the interpreter and apply all the possible optimizations to the trace inserted code was very difficult to keep track of, and it ended up that our benchmarks and testing suite did much of the heavy lifting. Another difficulty we faced was debugging the Brench and Turnt outputs. Because the pipeline for optimizations was so deep, we had a hard time debugging correctness issues without much debugging support. Self AssessmentWe believe we deserve a Michelin star because we are proud of our work! We brainstormed an implementation of the tracing, and thoroughly tested it. We tested thoroughly using the Brench and Turnt with our test cases that had separate arguments for our tracing optimization and correctness checking. We also practiced good team coding practices with git, and learned a lot about tracing JITs, ensuring correctness across all programs! We believe we deserve a Michelin star for the tenacity and persistence put into the task. |

Beta Was this translation helpful? Give feedback.
-
|
Good job! It's nice to see that the pass optimized some benchmarks :) |
Beta Was this translation helpful? Give feedback.
-
|
I implemented a trace-based speculative optimizer for Bril, by extending the reference interpreter ( A Python trace optimizer ( As a sanity check, I used a simple sum from 1 to input loop: I compared dynamic instruction counts for baseline vs optimized versions over several inputs. For input 5 and 100, the optimized version executed fewer instructions (47 → 45; 807 → 710). For input 0 the guard immediately fails and speculation rolls back, resulting in overhead (7 → 10).
|
Beta Was this translation helpful? Give feedback.
-
|
Cool! Thanks for the detailed description of how your tracing and "injection" machinery worked. While it's cool that this seems to have worked for this specific loop, it would be good to know—on a wider variety of more realistic benchmarks—that this (a) still produces the right answer, (b) even when the input changes, so speculation failures are handled correctly, and (c) can even improve performance in at least a few cases. |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Here's the thread for the dynamic compilers task, which involves doing some speculative transformations on Bril IR!
Beta Was this translation helpful? Give feedback.
All reactions