|
1 | 1 | # Meilisearch Python Async |
2 | 2 |
|
3 | | -[](https://github.com/sanders41/meilisearch-python-async/actions?query=workflow%3ATesting+branch%3Amain+event%3Apush) |
4 | | -[](https://results.pre-commit.ci/latest/github/sanders41/meilisearch-python-async/main) |
5 | | -[](https://codecov.io/gh/sanders41/meilisearch-python-async) |
6 | | -[](https://badge.fury.io/py/meilisearch-python-async) |
7 | | -[](https://github.com/sanders41/meilisearch-python-async) |
| 3 | +:warning: |
| 4 | +This project has been renamed to [meilisearch-python-sdk](https://github.com/sanders41/meilisearch-python-sdk) |
| 5 | +:warning: |
8 | 6 |
|
9 | | -Meilisearch Python Async is a Python async client for the [Meilisearch](https://github.com/meilisearch/meilisearch) API. Meilisearch also has an official [Python client](https://github.com/meilisearch/meilisearch-python). |
10 | | - |
11 | | -Which of the two clients to use comes down to your particular use case. The purpose for this async client is to allow for non-blocking calls when working in async frameworks such as [FastAPI](https://fastapi.tiangolo.com/), or if your own code base you are working in is async. If this does not match your use case then the official client will be a better choice. |
| 7 | +Under the new name both an async and a sync client are provided. You should install the new package |
| 8 | +instead of this one. |
12 | 9 |
|
13 | 10 | ## Installation |
14 | 11 |
|
15 | | -Using a virtual environmnet is recommended for installing this package. Once the virtual environment is created and activated install the package with: |
16 | | - |
17 | | -```sh |
18 | | -pip install meilisearch-python-async |
19 | | -``` |
20 | | - |
21 | | -## Run Meilisearch |
22 | | - |
23 | | -There are several ways to [run Meilisearch](https://docs.meilisearch.com/reference/features/installation.html#download-and-launch). |
24 | | -Pick the one that works best for your use case and then start the server. |
25 | | - |
26 | | -As as example to use Docker: |
27 | | - |
28 | 12 | ```sh |
29 | | -docker pull getmeili/meilisearch:latest |
30 | | -docker run -it --rm -p 7700:7700 getmeili/meilisearch:latest ./meilisearch --master-key=masterKey |
31 | | -``` |
32 | | - |
33 | | -## Useage |
34 | | - |
35 | | -### Add Documents |
36 | | - |
37 | | -- Note: `client.index("books") creates an instance of an Index object but does not make a network call to send the data yet so it does not need to be awaited. |
38 | | - |
39 | | -```py |
40 | | -from meilisearch_python_async import Client |
41 | | - |
42 | | -async with Client('http://127.0.0.1:7700', 'masterKey') as client: |
43 | | - index = client.index("books") |
44 | | - |
45 | | - documents = [ |
46 | | - {"id": 1, "title": "Ready Player One"}, |
47 | | - {"id": 42, "title": "The Hitchhiker's Guide to the Galaxy"}, |
48 | | - ] |
49 | | - |
50 | | - await index.add_documents(documents) |
51 | | -``` |
52 | | - |
53 | | -The server will return an update id that can be used to [get the status](https://docs.meilisearch.com/reference/api/updates.html#get-an-update-status) |
54 | | -of the updates. To do this you would save the result response from adding the documets to a variable, |
55 | | -this will be a UpdateId object, and use it to check the status of the updates. |
56 | | - |
57 | | -```py |
58 | | -update = await index.add_documents(documents) |
59 | | -status = await client.index('books').get_update_status(update.update_id) |
60 | | -``` |
61 | | - |
62 | | -### Basic Searching |
63 | | - |
64 | | -```py |
65 | | -search_result = await index.search("ready player") |
66 | | -``` |
67 | | - |
68 | | -### Base Search Results: SearchResults object with values |
69 | | - |
70 | | -```py |
71 | | -SearchResults( |
72 | | - hits = [ |
73 | | - { |
74 | | - "id": 1, |
75 | | - "title": "Ready Player One", |
76 | | - }, |
77 | | - ], |
78 | | - offset = 0, |
79 | | - limit = 20, |
80 | | - nb_hits = 1, |
81 | | - exhaustive_nb_hits = bool, |
82 | | - facets_distributionn = None, |
83 | | - processing_time_ms = 1, |
84 | | - query = "ready player", |
85 | | -) |
86 | | -``` |
87 | | - |
88 | | -### Custom Search |
89 | | - |
90 | | -Information about the parameters can be found in the [search parameters](https://docs.meilisearch.com/reference/features/search_parameters.html) section of the documentation. |
91 | | - |
92 | | -```py |
93 | | -index.search( |
94 | | - "guide", |
95 | | - attributes_to_highlight=["title"], |
96 | | - filters="book_id > 10" |
97 | | -) |
| 13 | +pip install meilisearch-python-sdk |
98 | 14 | ``` |
99 | | - |
100 | | -### Custom Search Results: SearchResults object with values |
101 | | - |
102 | | -```py |
103 | | -SearchResults( |
104 | | - hits = [ |
105 | | - { |
106 | | - "id": 42, |
107 | | - "title": "The Hitchhiker's Guide to the Galaxy", |
108 | | - "_formatted": { |
109 | | - "id": 42, |
110 | | - "title": "The Hitchhiker's Guide to the <em>Galaxy</em>" |
111 | | - } |
112 | | - }, |
113 | | - ], |
114 | | - offset = 0, |
115 | | - limit = 20, |
116 | | - nb_hits = 1, |
117 | | - exhaustive_nb_hits = bool, |
118 | | - facets_distributionn = None, |
119 | | - processing_time_ms = 5, |
120 | | - query = "galaxy", |
121 | | -) |
122 | | -``` |
123 | | - |
124 | | -## Benchmark |
125 | | - |
126 | | -The following benchmarks compare this library to the official |
127 | | -[Meilisearch Python](https://github.com/meilisearch/meilisearch-python) library. Note that all |
128 | | -of the performance gains seen are achieved by taking advantage of asyncio. This means that if your |
129 | | -code is not taking advantage of asyncio or blocking the event loop the gains here will not be seen |
130 | | -and the performance between the two libraries will be very close to the same. |
131 | | - |
132 | | -### Add Documents in Batches |
133 | | - |
134 | | -This test compares how long it takes to send 1 million documents in batches of 1 thousand to the |
135 | | -Meilisearch server for indexing (lower is better). The time does not take into account how long |
136 | | -Meilisearch takes to index the documents since that is outside of the library functionality. |
137 | | - |
138 | | -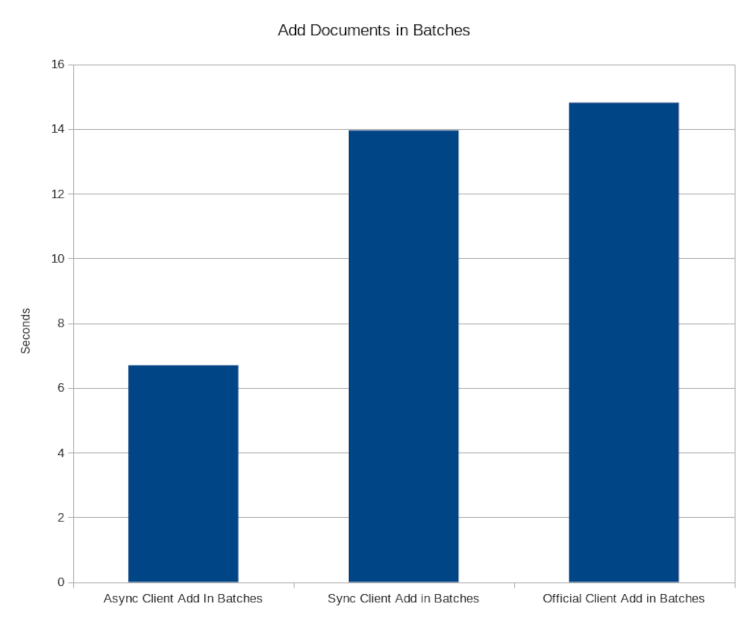 |
139 | | - |
140 | | -### Muiltiple Searches |
141 | | - |
142 | | -This test compares how long it takes to complete 1000 searches (lower is better) |
143 | | - |
144 | | -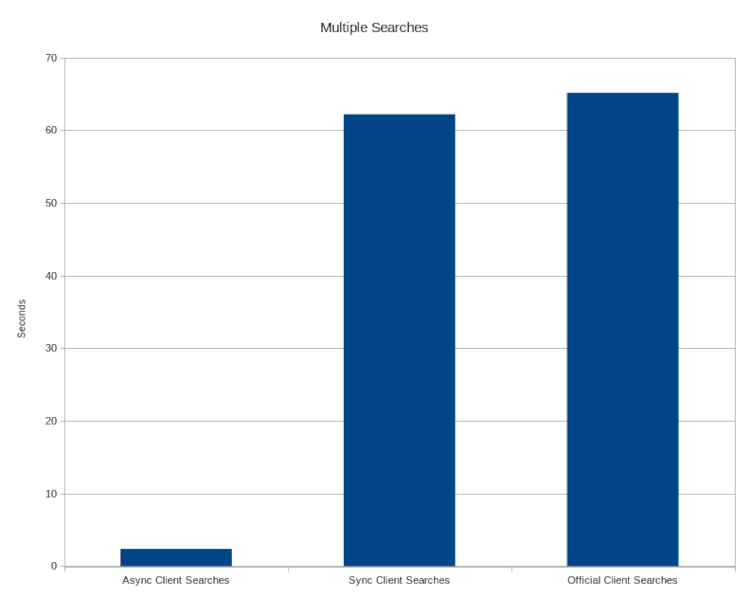 |
145 | | - |
146 | | -### Independent testing |
147 | | - |
148 | | -[Prashanth Rao](https://github.com/prrao87) did some independent testing and found this async client |
149 | | -to be ~30% faster than the sync client for data ingestion. You can find a good write-up of the results how he tested them |
150 | | -in his [blog post](https://thedataquarry.com/posts/meilisearch-async/). |
151 | | - |
152 | | -## Documentation |
153 | | - |
154 | | -See our [docs](https://meilisearch-python-async.paulsanders.dev) for the full documentation. |
155 | | - |
156 | | -## Contributing |
157 | | - |
158 | | -Contributions to this project are welcome. If you are interested in contributing please see our [contributing guide](CONTRIBUTING.md) |
0 commit comments