|
| 1 | +--- |
| 2 | +slug: the-way-to-build-voice-ai-agent |
| 3 | +title: "End-to-End vs. ASR-LLM-TTS: Which One Is The Right Choice to Build Voice AI Agent?" |
| 4 | +tags: [echokit] |
| 5 | +--- |
| 6 | + |
| 7 | + |
| 8 | +The race to build the perfect Voice AI Agent has primarily split into two lanes: the seamless, ultra-low latency **End-to-End (E2E) model** (like Gemini Live), and the highly configurable **ASR-LLM-TTS modular pipeline**. While the **speed and fluidity** of the End-to-End approach have garnered significant attention, we argue that for enterprise-grade applications, the modular ASR-LLM-TTS architecture provides the **strategic advantage of control, customization, and long-term scalability.** |
| 9 | + |
| 10 | +This is not simply a technical choice; it is a **business decision** that determines whether your AI Agent will be a generic tool or a highly specialized, branded extension of your operations. |
| 11 | + |
| 12 | +### The Allure of the Integrated Black Box (Low Latency, High Constraint) |
| 13 | + |
| 14 | +End-to-End models are technologically impressive. By integrating the speech-to-text (ASR), large language model (LLM), and text-to-speech (TTS) functions into a single system, they achieve **significantly lower latency** compared to pipeline systems. The resulting conversation feels incredibly fluid, with minimal pauses—an experience that is highly compelling in demonstrations. |
| 15 | + |
| 16 | +However, this integration creates a **“black box”**. Once the user's voice enters the system, you lose visibility and the ability to intervene until the synthesized voice comes out. For general consumer-grade assistants, this simplification works. But for companies with specialized vocabulary, unique brand voices, and strict compliance needs, simplicity comes at the cost of **surgical control**. |
| 17 | + |
| 18 | +### Lessons Learned from the Front Lines: The Echokit Experience |
| 19 | + |
| 20 | +Our understanding of this architectural divide is forged through experience building complex, scalable voice platforms. In the early days of advanced voice interaction—systems like **[echokit](https://echokit.dev/)**—we tackled the challenge of delivering functional, high-quality, and reliable Voice AI using the available modular components. |
| 21 | + |
| 22 | +These pioneering efforts, long before current E2E models were mainstream, taught us a crucial lesson: **The ability to inspect, isolate, and optimize each stage (ASR, NLU/LLM, TTS) is non-negotiable for achieving enterprise-level accuracy and customization.** We realized that while assembling the pipeline was complex, the resulting control over domain-specific accuracy, language model behavior, and distinct voice output ultimately delivered superior business results and a truly unique brand experience. |
| 23 | + |
| 24 | +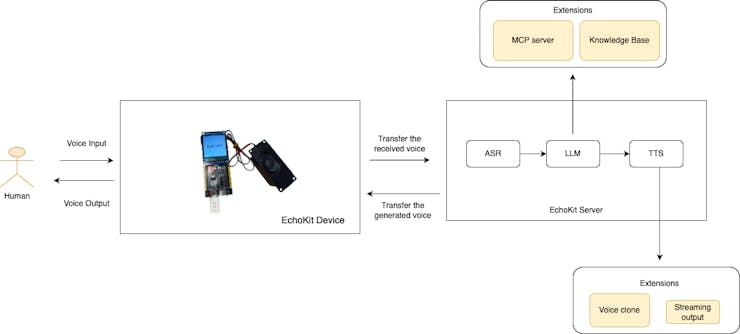 |
| 25 | + |
| 26 | +More importantly, EchoKit, which is [open source](https://github.com/second-state/echokit_server), ensures complete transparency and adaptability. |
| 27 | + |
| 28 | +### The Power of the Modular Pipeline: Control and Precision (Higher Latency, Full Control) |
| 29 | + |
| 30 | +The ASR-LLM-TTS pipeline breaks the Voice AI process down into three discrete, controllable stages. While this sequential process often results in **higher overall latency** compared to E2E solutions, this modularity is a **deliberate architectural choice** that grants businesses the power to optimize every single touchpoint. |
| 31 | + |
| 32 | +1. **ASR (Acoustic and Language Model Fine-tuning):** You can specifically train the ASR component on your **industry jargon, product names, or regional accents**. This is crucial in sectors like finance, healthcare, or manufacturing, where misrecognition of a single term can be disastrous. The pipeline allows you to correct ASR errors before they even reach the LLM, ensuring higher fidelity input. |
| 33 | +2. **LLM (Knowledge Injection and Logic Control):** This is the brain. You have the **flexibility to swap out the LLM** (whether it's GPT, Claude, or a custom model) and deeply integrate your **proprietary knowledge bases (RAG), MCP servers, business rules, and specific workflow logic**. You maintain complete control over the reasoning path and ensure responses are accurate and traceable. |
| 34 | +3. **TTS (Brand Voice and Emotional Context):** This is the face and personality of your brand. You can select, fine-tune, or even **clone a unique voice** that perfectly matches your brand identity, adjusting emotional tone and pacing. Your agent should sound like *your* company, not a generic robot. |
| 35 | + |
| 36 | +### Voice AI Architecture Comparison: E2E vs. ASR-LLM-TTS |
| 37 | + |
| 38 | +The choice boils down to a fundamental trade-off between **Latency vs. Customization**. |
| 39 | + |
| 40 | +| Feature | End-to-End (E2E) Model (e.g., Gemini Live) | ASR-LLM-TTS Pipeline (Modular) | |
| 41 | +| :--- | :--- | :--- | |
| 42 | +| **Primary Advantage** | **Ultra-Low Latency & Fluidity.** Excellent for fast, generic conversation. | **Maximum Customization & Control.** Optimized for business value. | |
| 43 | +| **Latency** | **Significantly Lower.** Integrated processing minimizes delays. | **Generally Higher.** Sequential processing introduces latency between stages. | |
| 44 | +| **Architecture** | **Integrated Black Box.** All components merged. | **Three Discrete Modules.** ASR $\to$ LLM $\to$ TTS. | |
| 45 | +| **Customization** | **Low.** Limited ability to adjust individual components or voices. | **High.** Each module can be independently trained and swapped. | |
| 46 | +| **Brand Voice** | **Limited.** Locked to vendor's available TTS options. | **Full Control.** Can implement custom voice cloning and precise emotion tagging. | |
| 47 | +| **Optimization Path** | **All-or-Nothing.** Optimization requires waiting for the vendor to update the entire model. | **Component-Specific.** Allows precise fixes and continuous improvement on any single module. | |
| 48 | +| **Strategic Lock-in** | **High.** Tightly bound to the single End-to-End vendor/platform. | **Low.** Flexibility to integrate best-of-breed components from different vendors. | |
| 49 | + |
| 50 | +### The Verdict: Choosing a Strategic Asset |
| 51 | + |
| 52 | +While the **ultra-low latency** of an End-to-End agent is undoubtedly attractive, it is crucial to ask: **Does speed alone deliver business value?** |
| 53 | + |
| 54 | +For most enterprise use cases—where the Agent handles critical customer service, sales inquiries, or technical support—the ability to be **accurate, on-brand, and deeply integrated** is far more valuable than shaving milliseconds off the response time. |
| 55 | + |
| 56 | +The **ASR-LLM-TTS architecture**, validated by our experience with systems like **echokit**, is the strategic choice because it treats the Voice AI Agent not as a simple conversational tool, but as a **controllable, customizable, and continuously optimizable business asset.** By opting for modularity, you retain the control necessary to adapt to market changes, ensure data compliance, and, most importantly, deliver a unique and expert-level experience that truly reflects your brand. |
| 57 | + |
| 58 | +Which solution delivers the highest long-term **ROI** and the strongest **brand experience**? The answer is clear: **Control is the key to enterprise Voice AI.** |
| 59 | + |
0 commit comments