|
| 1 | +--- |
| 2 | +title: "缘起|蚂蚁应用级服务发现的实践之路" |
| 3 | +authorlink: "https://github.com/sofastack" |
| 4 | +description: "缘起|蚂蚁应用级服务发现的实践之路" |
| 5 | +categories: "SOFAStack" |
| 6 | +tags: ["SOFAStack"] |
| 7 | +date: 2023-04-11T15:00:00+08:00 |
| 8 | +cover:"https://mdn.alipayobjects.com/huamei_soxoym/afts/img/A*MqBZTo4wB7IAAAAAAAAAAAAADrGAAQ/original" |
| 9 | + |
| 10 | +--- |
| 11 | + |
| 12 | + |
| 13 | +文|肖健(花名:昱恒) |
| 14 | + |
| 15 | +蚂蚁集团技术专家、SOFARegistry Maintainer |
| 16 | + |
| 17 | +*专注于服务发现领域,目前主要从事蚂蚁注册中心 SOFARegistry 的设计和研发工作。* |
| 18 | + |
| 19 | +**本文 8339 字 阅读 15 分钟** |
| 20 | + |
| 21 | +**PART. 1** |
| 22 | + |
| 23 | +**前言** |
| 24 | + |
| 25 | +**什么是服务发现?** |
| 26 | + |
| 27 | +我们今天主要聊的话题是“应用级服务发现”的实践,聊这个话题之前,我们先简单介绍一下什么是“服务发现”,然后再聊聊,为什么需要“应用级服务发现”。 |
| 28 | + |
| 29 | +在微服务的体系中,多个应用程序之间将以 RPC 方式进行相互通信,而这些应用程序的服务实例是动态变化的,我们需要知道这些实例的准确列表,才能让应用程序之间按预期进行 RPC 通信。这就是服务发现在微服务体系中的核心作用。 |
| 30 | + |
| 31 | +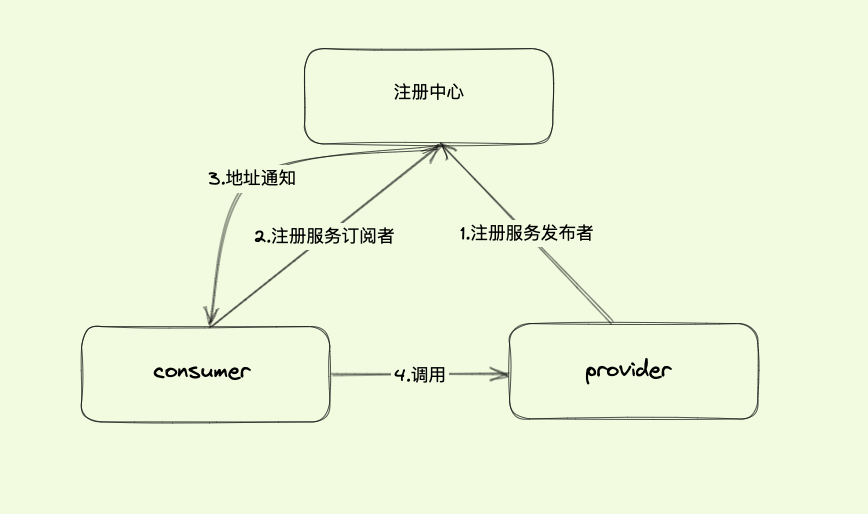 |
| 32 | + |
| 33 | +图 1(点击图片查看大图) |
| 34 | + |
| 35 | +SOFARegistry 是蚂蚁集团在生产大规模使用的服务注册中心,经历了多年大促的考验,支撑了蚂蚁庞大的服务集群,具有分布式可支撑海量数据、可云原生部署、推送延迟低、高可用等特点。 |
| 36 | + |
| 37 | +**PART. 2** |
| 38 | + |
| 39 | +**应用级服务发现的设想** |
| 40 | + |
| 41 | +介绍完什么是服务发现之后,我们来看看什么是“**接口级服务发现**”,以及与之相对应的“**应用级服务发现**”。 |
| 42 | + |
| 43 | +**从 RPC 框架说起** |
| 44 | + |
| 45 | +根据上述描述,我们先看看业界常用的 RPC 框架,是如何进行服务的发布和订阅的。以 [SOFARPC 编程界面](*https://www.sofastack.tech/projects/sofa-rpc/programing-sofa-boot-xml/*)为例: |
| 46 | + |
| 47 | +**|服务发布** |
| 48 | + |
| 49 | +```bash |
| 50 | +package com.alipay.rpc.sample; |
| 51 | + |
| 52 | +@SofaService(interfaceType = FooService.class, bindings = { @SofaServiceBinding(bindingType = "bolt") }) |
| 53 | +@Service |
| 54 | +public class FooServiceImpl implements FooService { |
| 55 | + @Override |
| 56 | + public String foo(String string) { |
| 57 | + return string; |
| 58 | + } |
| 59 | +} |
| 60 | + |
| 61 | +@SofaService(interfaceType = BarService.class, bindings = { @SofaServiceBinding(bindingType = "bolt") }) |
| 62 | +@Service |
| 63 | +public class BarServiceImpl implements BarService { |
| 64 | + @Override |
| 65 | + public String bar(String string) { |
| 66 | + return string; |
| 67 | + } |
| 68 | +} |
| 69 | +``` |
| 70 | +
|
| 71 | +**|服务使用** |
| 72 | +
|
| 73 | +```bash |
| 74 | +@Service |
| 75 | +public class SampleClientImpl { |
| 76 | + |
| 77 | + @SofaReference(interfaceType = FooService.class, jvmFirst = false, |
| 78 | + binding = @SofaReferenceBinding(bindingType = "bolt")) |
| 79 | + private FooService fooService; |
| 80 | + |
| 81 | + @SofaReference(interfaceType = BarService.class, jvmFirst = false, |
| 82 | + binding = @SofaReferenceBinding(bindingType = "bolt")) |
| 83 | + private BarService barService; |
| 84 | + |
| 85 | + public String foo(String str) { |
| 86 | + return fooService.foo(str); |
| 87 | + } |
| 88 | + |
| 89 | + public String bar(String str) { |
| 90 | + return barService.bar(str); |
| 91 | + } |
| 92 | +} |
| 93 | +``` |
| 94 | +
|
| 95 | +上述两个编程界面,完成了两个服务 FooService 和 BarService 的发布、订阅、调用。 |
| 96 | +
|
| 97 | +**微服务面临的挑战** |
| 98 | +
|
| 99 | +上述的服务发布、订阅、调用功能,离不开注册中心的服务发现提供准确的服务地址。将图 1 的服务发现场景进一步展开,此时的工作原理如下图: |
| 100 | +
|
| 101 | +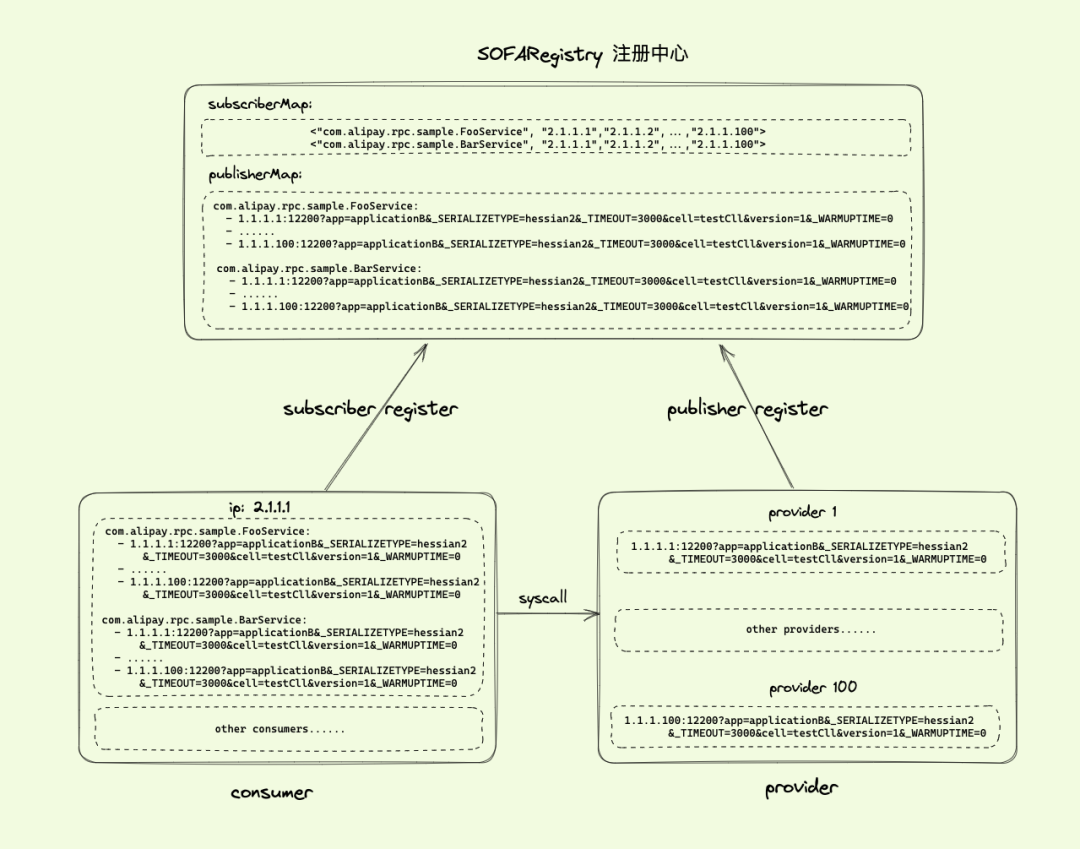 |
| 102 | +
|
| 103 | +图 2(点击图片查看大图) |
| 104 | +
|
| 105 | +服务发布者 |
| 106 | +
|
| 107 | +**-** 集群内部署了 100 个 pod,IP 分别为:1.1.1.1 ~ 1.1.1.100; |
| 108 | +
|
| 109 | +**-** 服务发布者的 URL:1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0,12200 端口为 sofarpc-bolt 协议默认的端口。 |
| 110 | +
|
| 111 | +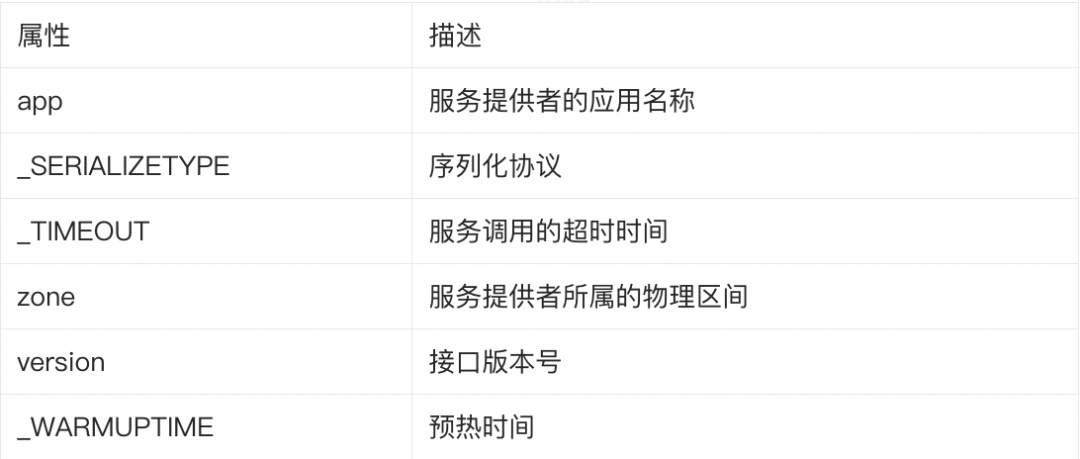 |
| 112 | +
|
| 113 | +服务订阅者:集群内部署了 100 个 pod,IP 分别为:2.1.1.1 ~ 2.1.1.100。 |
| 114 | +
|
| 115 | +基于上述的集群部署情况,我们来看看微服务的场景面临的挑战。 |
| 116 | +
|
| 117 | +**|挑战 1:注册中心 publisher 存储的挑战** |
| 118 | +
|
| 119 | +在上面的集群部署中,可以看到注册中心的数据存储模型,集群内部署了 100 个 provider pod,每个 provider 发布了 2 个服务,即每个 pod 有 2 个 publisher,以 provider1 为例: |
| 120 | +
|
| 121 | +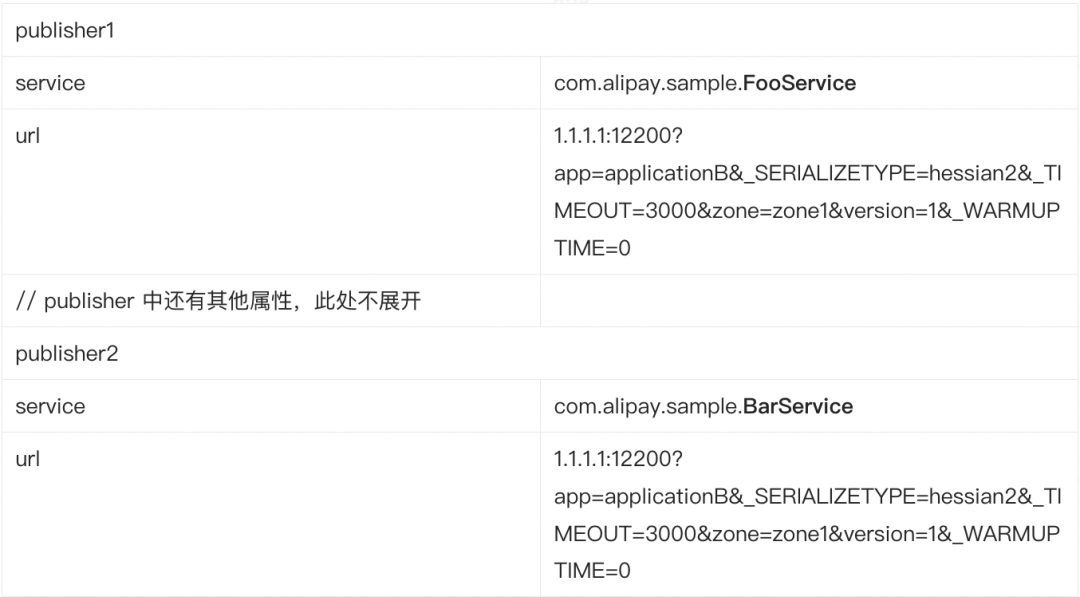 |
| 122 | +
|
| 123 | +如果在每个 provider 提供更多服务的情况下呢?比如每个 provider 提供了 50 个服务,这样的量级在微服务场景中并不少见,那么此时注册中心对于 provider1,就需要存储 50 个 publisher,分别是: |
| 124 | +
|
| 125 | +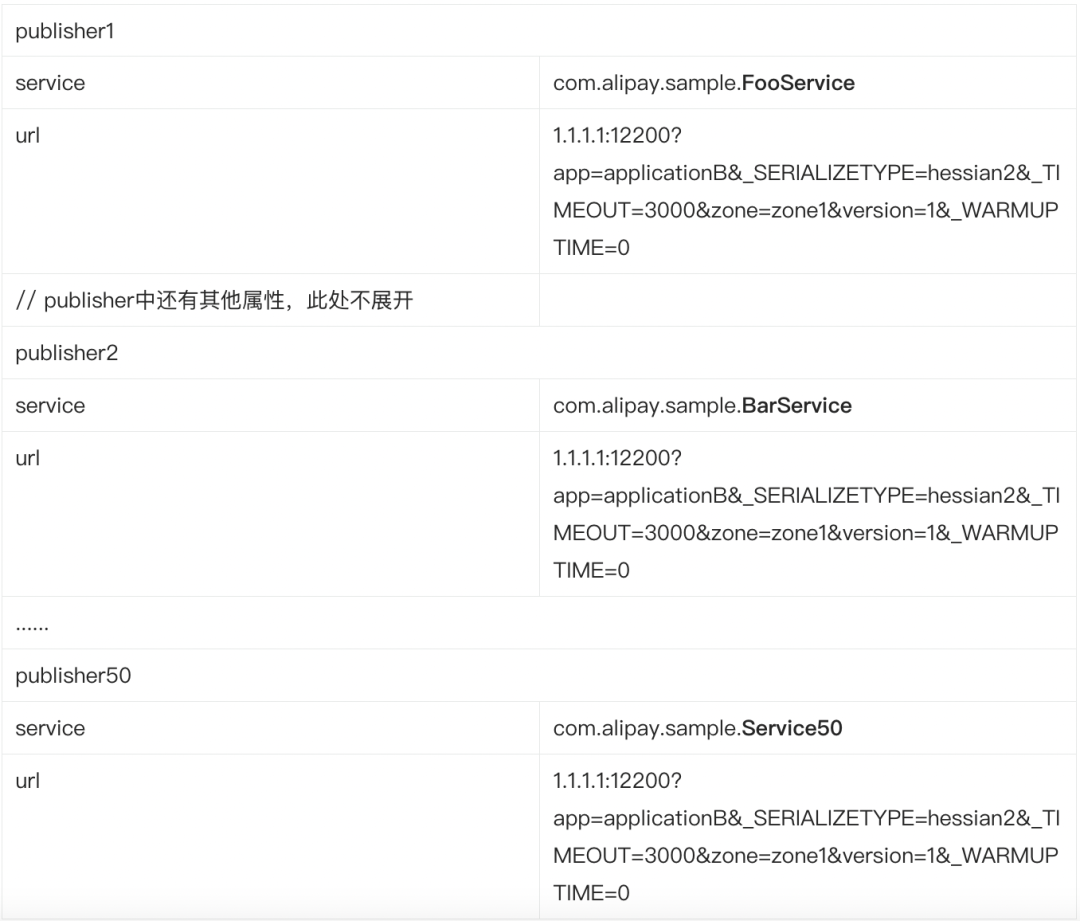 |
| 126 | +
|
| 127 | +可以看到,随着 provider 的扩容,注册中心存储的 publisher 数据量是以 50 倍于 provider 的速度在增长。 |
| 128 | +
|
| 129 | +如果您对 SOFARegistry 有过了解,就会知道 SOFARegistry 是支持数据存储分片,可以存储海量数据的。 |
| 130 | +
|
| 131 | +但是数据量上涨带来的是 SOFARegistry 本身的服务器数量增涨,如果我们有办法可以降低 SOFARegistry 的数据存储量,那么就能节约 SOFARegistry 本身的服务器成本,同时 SOFARegistry 整个集群的稳定性也会得到提升。 |
| 132 | +
|
| 133 | +**|挑战 2:注册中心 subscriber 存储的挑战** |
| 134 | +
|
| 135 | +在上述的集群部署中,集群内部署了 100 个 consumer pod,每个 consumer 订阅了 2 个服务,即每个 pod 有 2 个 subscriber,同理于 publisher 的存储挑战,随着 consumer 订阅的接口持续增加,例如 consumer 订阅了 provider 的 10 个 service,此时注册中心存储 consumer1 的 10 个 subscriber 如下: |
| 136 | +
|
| 137 | + |
| 138 | +
|
| 139 | +随着 consumer 的扩容,注册中心内的 subscriber 存储同样面临着挑战。 |
| 140 | +
|
| 141 | +**|挑战 3:服务变更通知的挑战** |
| 142 | +
|
| 143 | +随着 publisher 和 subscriber 数量增长,除了对存储的挑战以外,对于数据变更通知同样面临着极大的挑战,让我们来看看如下的场景:provider 下线了 1 台,从 100 台减少到了 99 台,次数集群内发生了哪些变化呢? |
| 144 | +
|
| 145 | +1、首先是在注册中心存储方面,需要将 provide 50 个 service 中的 publishers 列表都减少 1 个,每个 service 剩余 99 个 publisher; |
| 146 | +
|
| 147 | +2、然后注册中心需要将这 50 个 service 的变更,都通知给相应的 subscriber;我们上述假设是 consumer 订阅了 10 个 service,分别是:["com.alipay.sample.FooService", "com.alipay.sample.BarService", "com.alipay.sample.Service00", ..., "com.alipay.sample.Service07"]; |
| 148 | +
|
| 149 | +3、那么对于 consumer1,我们需要将如下的数据推送给 consumer1: |
| 150 | +
|
| 151 | +```bash |
| 152 | +com.alipay.sample.FooService: |
| 153 | + - 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 154 | + - ... |
| 155 | + - 1.1.1.99:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 156 | + |
| 157 | +com.alipay.sample.BarService: |
| 158 | + - 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 159 | + - ... |
| 160 | + - 1.1.1.99:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 161 | + |
| 162 | +//...中间省略 |
| 163 | + |
| 164 | +com.alipay.sample.Service07: |
| 165 | + - 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 166 | + - ... |
| 167 | + - 1.1.1.99:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 168 | +``` |
| 169 | +
|
| 170 | +可以看到一台 provider 的扩缩容,就需要对 consumer1 进行如此大量的数据推送,如果 com.alipay.sample.FooService 的 publisher 的数量更大,达到 1 千个、1 万个呢?此时注册中心的服务变更通知,也面临着网络通信数据量大的挑战。 |
| 171 | +
|
| 172 | +**是否有方式在 provider 的变更时,降低需要通知的数据量呢?** |
| 173 | +
|
| 174 | +**|挑战 4:consumer 的内存挑战** |
| 175 | +
|
| 176 | +介绍完注册中心面临的挑战后,我们再从图 1 来看看 consumer 存储服务列表时,内存面临的挑战,对于注册中心推送下来的数据,consumer 也需要进行存储,然后再发起 RPC 服务调用的时候,就可以直接从 consumer 内存中获取到服务地址进行调用,consumer 中存储的数据,简化来看是如下的数据: |
| 177 | +
|
| 178 | +```bash |
| 179 | +com.alipay.sample.FooService: |
| 180 | + - 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 181 | + - ... |
| 182 | + - 1.1.1.99:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 183 | + |
| 184 | +com.alipay.sample.BarService: |
| 185 | + - 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 186 | + - ... |
| 187 | + - 1.1.1.99:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 188 | + |
| 189 | +//...中间省略 |
| 190 | + |
| 191 | +com.alipay.sample.Service07: |
| 192 | + - 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 193 | + - ... |
| 194 | + - 1.1.1.99:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 195 | +``` |
| 196 | +
|
| 197 | +此时 privoder 只有 99 个 IP,但是因为订阅了 10 个 service,所以在 consumer 中存储了 99 * 10 = 990 个 publisher 列表;如果订阅的 service 更多,provider 的数量更大呢*(比如达到 10 万)*?此时 consumer 内存中存储了近 100 万个 publisher,内存将面临着极大的挑战。 |
| 198 | +
|
| 199 | +**微光:应用级服务发现的提出** |
| 200 | +
|
| 201 | +**|应用级服务发布** |
| 202 | +
|
| 203 | +经过上一个章节的描述,对于一次简单的 RPC 调用背后,服务发现面临的挑战相信各位读者已经有所感受,那么可能得突破方向到底在哪里呢? |
| 204 | +
|
| 205 | +初步看,我们不难发现的是,对于一个 provider1,在注册中心存储的 publisher 数据如下: |
| 206 | +
|
| 207 | +```bash |
| 208 | +com.alipay.sample.FooService: |
| 209 | + - 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 210 | + |
| 211 | +com.alipay.sample.BarService: |
| 212 | + - 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 213 | + |
| 214 | +//...中间省略 |
| 215 | + |
| 216 | +com.alipay.sample.Service100: |
| 217 | + - 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 218 | +``` |
| 219 | +
|
| 220 | +每个 publisher 中,除了 serviceName 不相同,url 存储了相同的 100 份,这里是否可以简化为存储 1 份?这是应用级服务发布最初的想法。 |
| 221 | +
|
| 222 | +按照这个模型我们继续推演,可以得到如下演进模型: |
| 223 | +
|
| 224 | +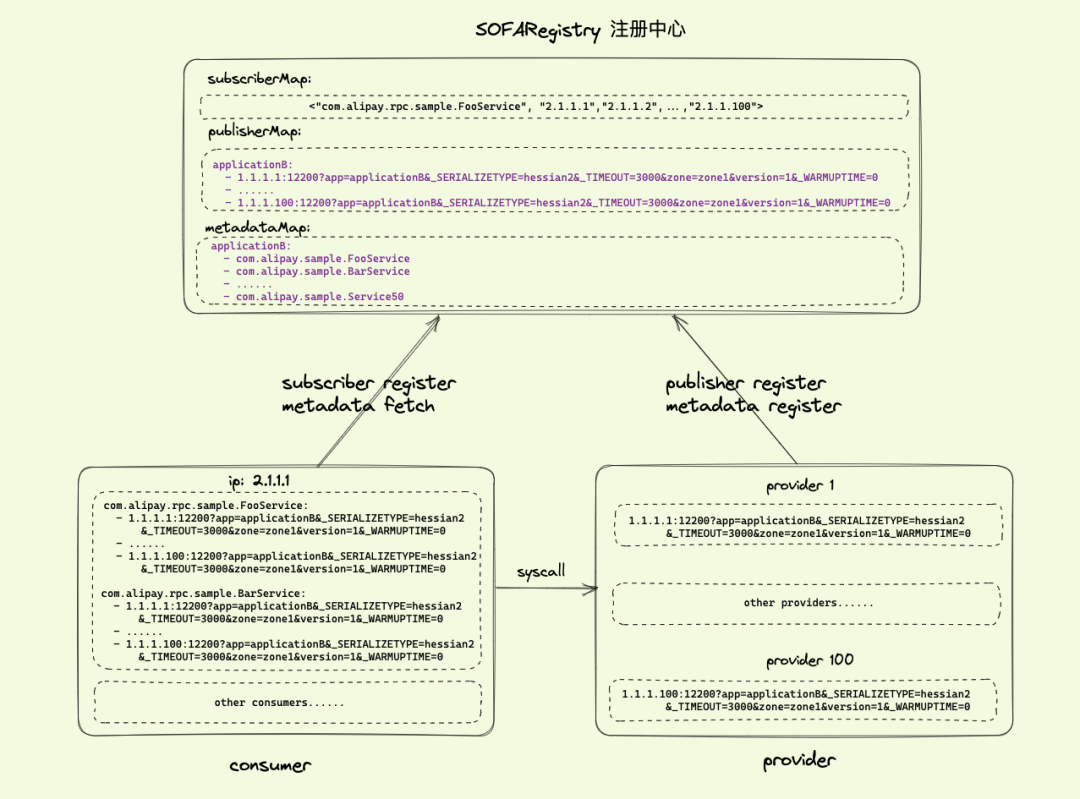 |
| 225 | +
|
| 226 | +图 3(点击图片查看大图) |
| 227 | +
|
| 228 | +对比图 2 和图 3,我们设想: |
| 229 | +
|
| 230 | +1、prodiver 不再以 service=com.alipay.sample.FooService 向注册中心发布服务,而是以 service=applicationB 进行服务发布,那么注册中心对于 provide1,此时 publisher 存储的数据量从 50 个下降到 1 个,注册中心的整个集群的 publisher 存数量,也将下降 50 倍,这将使得注册中心 SOFARegistry 的服务器成本极大降低,同时注册中心的稳定性也将得到大幅度提升。 |
| 231 | +
|
| 232 | +2、对于 prodiver 发布了哪些服务,这个关系维护在 metadataMap 中,供后续的应用级服务订阅使用。 |
| 233 | +
|
| 234 | +**|应用级服务订阅** |
| 235 | +
|
| 236 | +在上一节中我们将服务发现,演进到了应用级服务发布,那么此时的服务订阅与服务调用,应该怎样进行呢?我们继续从图 3 中展开: |
| 237 | +
|
| 238 | +1、对于 comsumer1,启动时先根据接口进行一次 metadata fetch 的元数据获取,根据 metadataMap 中的数据,可以知道此时 service=com.alipay.sample.FooService 映射的 app=applicationB;同理其他 9 个 service 映射的 app 也是 applicationB; |
| 239 | +
|
| 240 | +2、然后以 applicationB 为 dataid,向注册中心发起订阅,注册中心此时不再是存储 consumer1 的 10 个 subscriber,而是存储一个 dataid=applicationB 的 subscriber;注册中心的 subscriber 数量也降低了 10 倍; |
| 241 | +
|
| 242 | +3、consumer1 发起服务订阅后,注册中心进行数据推送,此时注册中心推送的数据为: |
| 243 | +
|
| 244 | +```bash |
| 245 | +applicationB: |
| 246 | + - 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 247 | + - ... |
| 248 | + - 1.1.1.100:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 249 | +``` |
| 250 | +
|
| 251 | +4、可以看到,此时注册中心给 consumer1 的数据推送量,相比于**【Part.2 挑战 3】**中推送的数据,网络的数据量交互也下降了 10 倍。 |
| 252 | +
|
| 253 | +**|应用级路由** |
| 254 | +
|
| 255 | +经过上述的“应用级服务发布”和“应用级服务订阅”,我们解决了注册中心的数据量存储瓶颈,注册中心的变更通知网络瓶颈,最后我们来看看 consumer1 中的内存瓶颈如何解决。 |
| 256 | +
|
| 257 | +通过上面的步骤,consumer1 中拿到了一些数据,分别是:metadataMap 和 publishMap: |
| 258 | +
|
| 259 | +```bash |
| 260 | +applicationB: |
| 261 | + - com.alipay.sample.FooService |
| 262 | + - com.alipay.sample.BarService |
| 263 | + - ... |
| 264 | + - com.alipay.sample.Service50 |
| 265 | + |
| 266 | +applicationB: |
| 267 | + - 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 268 | + - ... |
| 269 | + - 1.1.1.100:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0 |
| 270 | + |
| 271 | +``` |
| 272 | +
|
| 273 | +此时我们可以在 consumer1 进行“应用级路由”的信息封装,如下图: |
| 274 | +
|
| 275 | +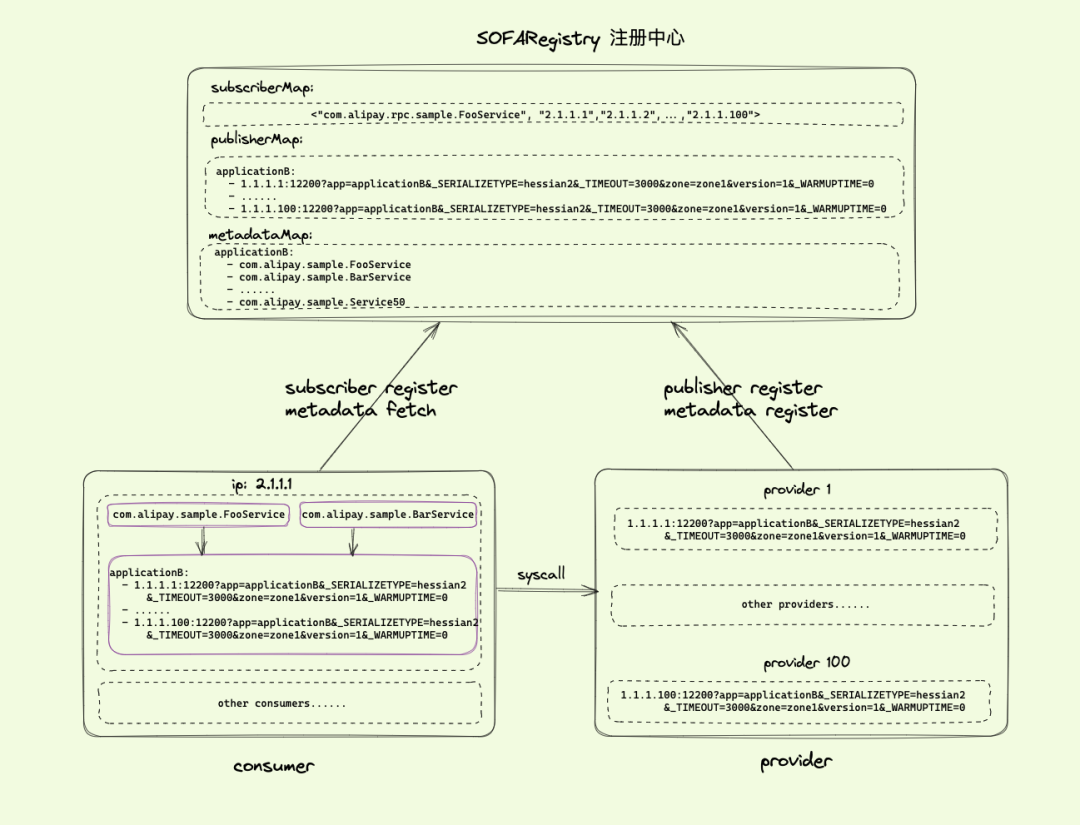 |
| 276 | +
|
| 277 | +图 4(点击图片查看大图) |
| 278 | +
|
| 279 | +如图 4 所示,此时 consumer 中只需要保存 applicationB 的 100 个 publisher,而不再是保存 10(假设订阅了 10 个 service)* 100 = 1000 个 publisher,consumer1 中的服务路由表的内存使用,也降低了 10 倍。 |
| 280 | +
|
| 281 | +**PART. 3** |
| 282 | +
|
| 283 | +**长路漫漫** |
| 284 | +
|
| 285 | +在上述的微服务模型中,经过上面的应用级服务发现方案推演,我们做到了: |
| 286 | +
|
| 287 | +**-** 注册中心存储的 publisher 数据量下降了 **50** 倍; |
| 288 | +
|
| 289 | +**-** 注册中心存储的 subscriber 数据量下降了 **10** 倍; |
| 290 | +
|
| 291 | +**-** 注册中心服务变更通知,网络通信数据量下降了 **10** 倍; |
| 292 | +
|
| 293 | +**-** 服务订阅端 consumer 中,服务路由表的内存 insue 使用降低了 **10** 倍; |
| 294 | +
|
| 295 | +这个推演结果是令人激动的,然而实际的场景要比上述这个数据更复杂。这个推演模型,要进行真正线上实施,并且进行大规模落地,仍然是长路漫漫。这里先抛出几个问题: |
| 296 | +
|
| 297 | +1、如果不同的接口之间,参数并不是完全相同的,我们要如何处理?例如 FooService 的 _TIMEOUT=3000,BarService的_TIMEOUT=1000,Service100的_TIMEOUT=5000; |
| 298 | +
|
| 299 | +2、provider 的不同 pod 之间,发布的服务列表有差异,要如何处理?例如 provider1 发布的服务列表是 ["com.alipay.sample.FooService","com.alipay.sample.BarService", ..., "com.alipay.sample.Service50"];provider2 发布的服务列表是 ["com.alipay.sample.FooService","com.alipay.sample.BarService", ..., "com.alipay.sample.Service51"]; |
| 300 | +
|
| 301 | +3、无论是上述的 provider 还是 consumer,都需要进行 SDK 的代码改造,如何保证线上从“接口级服务发现”,平滑过渡到“应用级服务发现”; |
| 302 | +
|
| 303 | +4、如果部分应用无法升级 SDK,方案如何继续演进,拿到期望的效果收益; |
| 304 | +
|
| 305 | +5、两个方案过度期间,如何确保注册中心服务的一致性。 |
| 306 | +
|
| 307 | +这些问题,我们将在下一篇文章《技术内幕|蚂蚁的应用级服务发现实践之路》中详细解答,敬请期待。 |
| 308 | +
|
| 309 | +**|参考链接|** |
| 310 | +
|
| 311 | +Dubbo 迈向云原生的里程碑 | 应用级服务发现:[*https://lexburner.github.io/dubbo-app-pubsub/*](https://lexburner.github.io/dubbo-app-pubsub/) |
| 312 | +
|
| 313 | + **了解更多...** |
| 314 | +
|
| 315 | +**SOFARegistry Star 一下✨:** |
| 316 | +[*https://github.com/sofastack/sofa-registry/*](https://github.com/sofastack/sofa-registry/) |
0 commit comments